
Дейт К. Д27 Руководство по реляционной субд db2/ Пер с англ и предисл. М. Р. Когаловского
| Вид материала | Руководство |
- Рич Р. К. Политология. Методы исследования: Пер с англ. / Предисл. А. К. Соколова, 6313.17kb.
- Рич Р. К. Политология. Методы исследования: Пер с англ. / Предисл. А. К. Соколова, 6313.29kb.
- Сорокин П. А. С 65 Человек. Цивилизация. Общество / Общ ред., сост и предисл., 11452.51kb.
- The guilford press, 6075kb.
- The guilford press, 6075.4kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Целостная часть реляционной, 213.79kb.
- Дэвид Дайчес, 1633.42kb.
- Mathematics and the search for knowledge morris kline, 498.28kb.
- Лекция №1: Стандарты языка sql, 1420.56kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Манипулирование реляционными, 276.31kb.
ГЛАВА 13
СТРУКТУРА ХРАНЕНИЯ ДАННЫХ
13.1. ВВЕДЕНИЕ
Как уже указывалось в главе 3, предложения определения данных языка SQL было бы удобно разделить на два класса— Предложения логические и физические. Логические предложения имеют дело с объектами, которые на самом деле представляют интерес для пользователя. В отличие от них физические предложения имеют дело с объектами, которые в большей степени представляют интерес для администраторов—системных администраторов и администраторов баз данных. В этой главе кратко обсуждается последний вид объектов. Соответствующие им предложения определения данных являются, однако, несколько более сложными благодаря тому, что они по необходимости включают множество деталей нижнего уровня. По этой причине указанные предложения (копия здесь подробно не описываются. Мы довольствуемся наблюдением, что они обладают в такой же мере широкими функциями, как и логические предложения, в том смысле, что для каждого вида объектов имеются предложения CREATE (создать), АLTER (изменить) и DROP (уничтожить). Это простое замечание на самом деле не является стопроцентной истиной—не для всех видов объектов допускаются все три вида операций. Оставим, однако, обсуждение всех этих подробностей за руководствами no системе DB2 фирмы IBM.
На рис. 13.1 схематически представлены основные объекты среды хранения и их взаимосвязи. Этот рисунок нужно интерпретировать следующим образом.
— Полная совокупность хранимых данных подразделяется на ряд непересекающихся баз данных, включающий в общем случае несколько пользовательских и несколько системных баз данных. Одна системная база данных—каталог базы данных— показана на рисунке.
— Каждая база данных подразделяется на ряд непересекающихся «пространств», состоящий из нескольких табличных пространств и, вообще говоря, нескольких индексных пространств. «Пространство» представляет собой динамически расширяемую совокупность страниц, где страница — это блок физической памяти (единица данных в операциях ввода-вывода, т. е. единица обмена между основной и внешней памятью в одиночной операции ввода-вывода).
— Каждое табличное пространство содержит одну или несколько хранимых таблиц (часто, но не всегда, именно одну). Хранимая таблица является физическим представлением некоторой базовой таблицы и должна полностью содержаться в одном табличном пространстве.
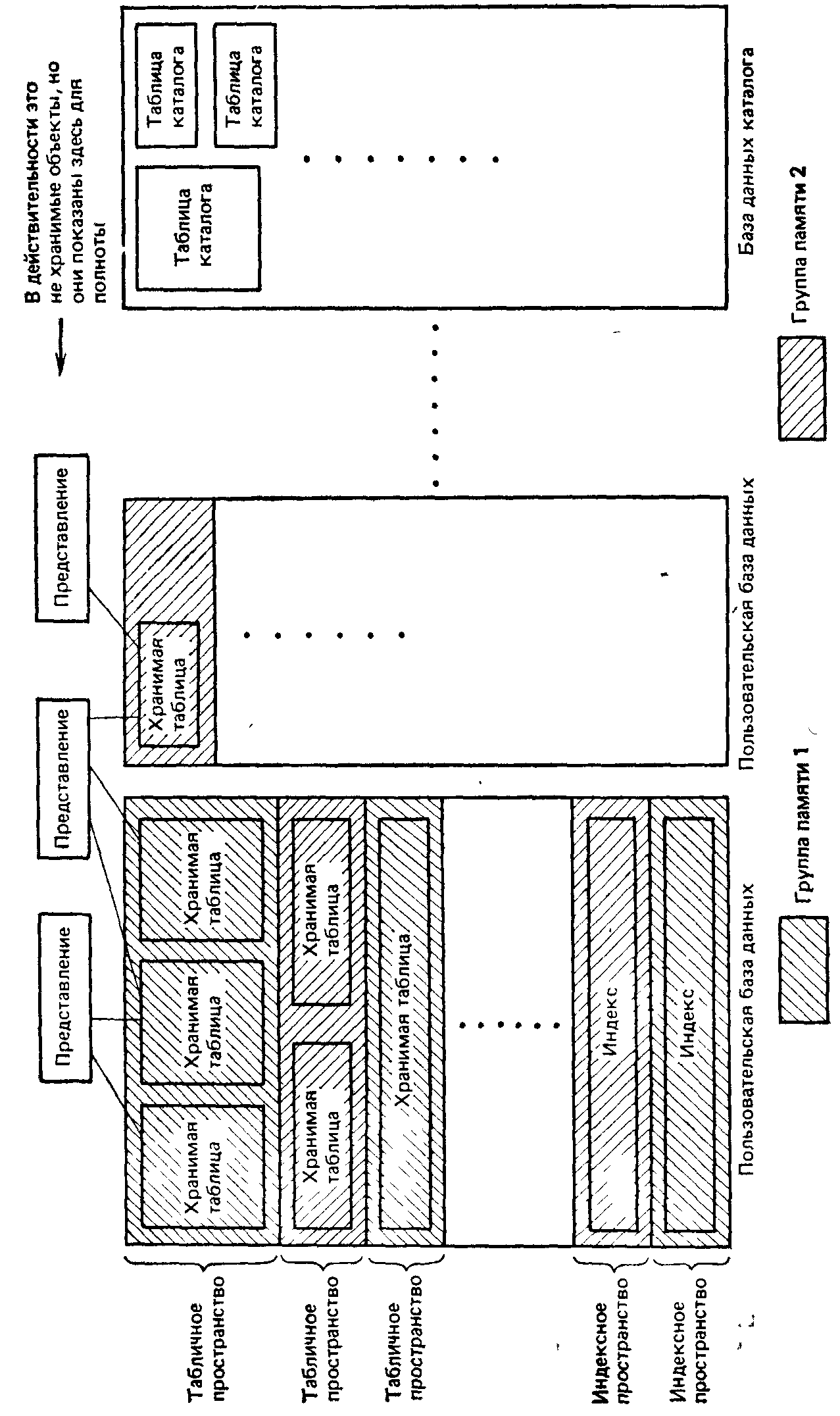
Рис. 13.1. Основные объекты среды хранения DB2
—Каждое индексное пространство содержит в точности один индекс. Заданный индекс должен полностью содержаться в одном индексном пространстве. Заданная хранимая таблица и связанные с нею индексы должны полностью содержаться в одной базе данных.
— Как уже указывалось в главе 8, представления вообще не являются хранимыми объектами. Они упоминаются на рисунке только для иллюстрации того факта, что данное представление может охватывать множество баз данных, т. е. оно может базироваться на множестве хранимых таблиц, и не все эти таблицы обязательно должны находиться в одной и той же базе данных.
— С каждым «пространством» (табличным или индексным) связана некоторая группа памяти22. Группа памяти—это совокупность томов с прямым доступом на устройствах одного и того же типа. Если требуется расширить данное пространство, то дополнительная память выделяется из соответствующей группы памяти. Не обязательно, чтобы все пространства заданной базы данных относились к одной и той же группе памяти. Точно так же не требуется, чтобы все пространства, составляющие данную группу памяти, относились к одной и той же базе данных. Отметим поэтому, что группы памяти являются в некотором смысле наиболее «физическими» из всего многообразия объектов среды хранения в системе DB2. В то же время базы данных, табличные пространства и др. представляют собой все же нечто «логическое».
Прежде чем перейти к более детальному обсуждению перечисленных выше понятий, сделаем еще одно вводное замечание относительно системных умолчаний. В основу системных умолчаний положено следующее соображение. На первый взгляд все множество объектов среды хранения—базы данных, табличные пространства, группы памяти и т. д.—является в значительной степени сложным, и было бы довольно неудачно, а на самом деле противоречило бы общей цели— обеспечению легкости использования, если бы пользователь должен был в полной мере понять все эти концепции прежде, чем они могли бы стать ему полезными. Например, нет необходимости знать о табличных пространстваx только лишь для того, чтобы иметь возможность создать и использовать новую таблицу. Полное предложение CREATE TABLE включает параметр, специфицирующий табличное пространство, в которое должна войти новая таблица. Однако всегда можно опустить этот параметр (и в действительности именно так мы и поступали до сих пор во всех примерах в этой книге). В этом случае DB2 автоматически создаст табличное пространство по умолчанию и поместит в него новую таблицу. Поэтому для того, чтобы быть способным создать новую таблицу, фактически нет необходимости знать о табличных пространствах. Подобные упрощения относятся к большинству других предложений определения данных и к большинству других объектов среды хранения. Полностью механизм умолчания описывается более подробно в разделе 13.8.
13.2. БАЗЫ ДАННЫХ
База данных в системе DB2 представляет собой совокупность логически связанных объектов — хранимых таблиц, некоторым образом связанных друг с другом, вместе с относящимися к ним индексами и с множеством пространств, содержащих эти таблицы и индексы. Таким образом, база данных состоит из множества табличных пространств, каждое из которых содержит одну или несколько хранимых таблиц, а также множества индексных пространств, содержащих в точности по одному индексу. Как указывалось ранее, данная хранимая таблица и все связанные с нею индексы должны полностью содержаться в одной базе данных.
База данных представляет собой «старт-стопное устройство» в том смысле, что оператор может с консоли сделать данную базу данных доступной или недоступной для обработки с помощью соответствующих команд START и STOP. Следует отметить поэтому, что объекты группируются в одной и той же базе данных, главным образом, по причинам операционального характера. Пользователи (в нашем понимании этого термина) вообще не обязаны иметь дело с базами данных, и могут просто сосредоточиться на данных, т. е. на таблицах — базовых таблицах и представлениях. Таблицы могут пересылаться из одной базы данных в другую, не оказывая какого-либо влияния на пользователей. И наконец, как уже указывалось в конце предыдущего раздела, база данных не является даже отдельным «физическим» объектом. В частности, она обычно не является отдельным диском или отдельным множеством дисков, а состоит, скорее, из частей многих дисков, другие части которых могут быть выделены для иных баз данных.
13.3. ТАБЛИЧНЫЕ ПРОСТРАНСТВА
Табличное пространство может рассматриваться как логическое адресное пространство во внешней памяти, используемое для размещения одной или нескольких хранимых таблиц («логическое» постольку, поскольку оно не является обычно множеством физически смежных областей). По мере того как растет объем данных в этих таблицах, для адаптации к такому росту из соответствующей группы памяти будет выделяться дополнительная память, которая добавляется к этому адресному пространству. Размер одного табличного пространства может достигать примерно 64 гигабайт, и нет никаких ограничений на число табличных пространств в базе данных, а также на количество баз данных23. Все страницы в заданном табличном пространстве имеют размер либо 4К, либо 32Кбайт (К=1024).
Существенно отметить, что табличное пространство является единицей памяти для целей реорганизации и восстановления. Это означает, что табличное пространство может быть восстановлено после отказов, связанных с носителями информации, или реорганизовано по команде с консоли оператора. Если, однако, табличное пространство очень велико, его реорганизация или восстановление потребовали бы очень много времени. Поэтому в DB2 предусматривается факультативная возможность сегментирования большого табличного пространства на более мелкие части. Для сегментированного табличного пространства единицей реорганизации и восстановления является отдельный его сегмент, а не полное табличное пространство.
Таким образом, различаются две разновидности табличных пространств — сегментированные и простые (несегментированные). Рассмотрим каждую из них.
Простые табличные пространства
Простое табличное пространство может содержать более одной таблицы, хотя обычный случай—это одна таблица. Возможность размещать в табличном пространстве более одной таблицы полезна тем, что хранимые записи могут группироваться в кластеры таким образом, чтобы улучшать времена доступа к логически связанным записям. Например, если таблицы S и SP хранились бы в одном и том же табличном пространстве, то было бы возможно (благодаря разумному использованию утилиты загрузки) хранить все записи поставок для поставщика S1 близко (т. е. на той же самой странице) к записи поставщика S1, все записи поставок для поставщика S2 близко к записи поставщика S2 и т. д. Тогда могут эффективно отрабатываться запросы вида «Выдать детали поставщика S1 и все соответствующие поставки», поскольку будет сокращаться число операций ввода-вывода.
3аметим, однако, что нелегко поддерживать такую кластеризацию в ситуации, когда произвольным образом осуществляются обновления. Кроме того, об этой кластеризации не имеют никакого понятия ни оптимизатор, ни утилита реорганизации. К тому же вполне возможно, что будет замедляться последовательный доступ, так как система должна будет просмотреть не только записи, относящиеся к данной таблице, но также и записи других таблиц, которые оказываются смешанными с первой таблицей. Вероятно, в большинстве ситуаций наиболее удовлетворительным является все-таки вариант организации, предусматривающей по одной таблице в каждом табличном пространстве.
Для каждой таблицы в данном табличном пространстве может иметься один или более индексов. Если таблица вообще имеет какие-либо индексы, то ровно один из них является индексом кластеризации для этой таблицы. Индексы кластеризации подробно обсуждаются в разделе 13.6. Поэтому ограничимся здесь следующим кратким пояснением. Индекс кластеризации, по существу,— это такой индекс, который используется для управления физическим размещением индексируемых записей таким образом, чтобы физическая последовательность записей в памяти была близка к логической последовательности этих записей, определяемой данным индексом. Если для таблицы имеется индекс кластеризации, то записи должны первоначально загружаться в эту таблицу в порядке кластеров с помощью утилиты загрузки. Они будут запоминаться в табличном пространстве в порядке поступления слева направо, т. е. по возрастанию последовательности адресов, с периодическими промежутками, которые позволят в будущем производить вставки. Заметим, что промежутки часто обусловливаются системой, а не пользователем. Если таблица не имеет индексов, то записи первоначально могут загружаться в произвольном порядке. И снова они будут запоминаться слева направо, но без каких-либо промежутков. Вставляемые впоследствии в эту таблицу записи будут запоминаться в каком-либо промежутке, если существует индекс кластеризации, и записи могут физически запоминаться вблизи их логических позиций. В противном случае они запоминаются в правом конце пространства.
Сегментированные табличные пространства
Сегментированное табличное пространство содержит в точности одну таблицу. Эта таблица сегментируется в соответствии с диапазоном значений поля или комбинаций полей сегментирования. Если, например, таблица поставок SP хранилась бы в сегментированном табличном пространстве, то она могла бы сегментироваться по значениям поля НОМЕР_ПОСТАВЩИКА таким образом, чтобы все поставки поставщика S1 запоминались в сегменте номер один, все поставки поставщика S2 — в сегменте номер два и т. д. Для поля или комбинации полей сегментирования нужен индекс кластеризации. Дополнительные индексы необязательны. Поле или комбинацию полей сегментирования нельзя обновлять. Записи первоначально должны загружаться в порядке кластеров с помощью утилиты загрузки. Они будут запоминаться слева направо в соответствующем сегменте с промежутками.
Как уже указывалось, отдельные сегменты сегментированного табличного пространства независимы друг от друга в том смысле, что их можно независимо восстанавливать и реорганизовывать. Они также могут быть связаны с различными группами памяти. Поэтому можно, например, хранить одни сегменты на более быстрых устройствах, а другие—на более медленных (различные группы памяти могут соответствовать различным типам устройств).
13.4. ХРАНИМЫЕ ТАБЛИЦЫ
Хранимая таблица — это хранимое представление базовой таблицы. Она состоит из множества хранимых записей, по одной для каждой строки данных в рассматриваемой базовой таблице. Каждая хранимая запись будет полностью содержаться на одной странице. Однако каждая хранимая таблица может размещаться на множестве страниц, и в простом табличном пространстве одна страница может содержать хранимые записи из многих хранимых таблиц.
Хранимая запись не идентична соответствующей записи базовой таблицы. Она состоит из строки байтов, включающей:
- префикс, содержащий управляющую информацию, например внутреннее системное имя для хранимой таблицы, частью которой является данная хранимая запись, за которым следует
- до N хранимых полей, где N — число столбцов в данной базовой таблице. Хранимых полей будет меньше, чем N, если хранимая запись имеет переменную длину, т. е. если в ней есть какие-либо поля переменной длины, и одно или несколько полей в правой части записи имеют неопределенные значения. Поля, имеющие неопределенные значения, в конце записи переменной длины физически не хранятся.
Каждое хранимое поле в свою очередь состоит из:
- префикса длины (если поле имеет переменную длину), который задает фактическую длину данных, в том числе префикса индикатора неопределенного значения, если он имеется (см. ниже);
- префикса индикатора неопределенного значения (если неопределенные значения допускаются), указывающего, должно ли значение в той части поля, которая отведена для данных: а) приниматься за действительное значение данных; б) игнорироваться, т. е. интерпретироваться как неопределенное значение;
- фактического значения данных в кодированном формате. Хранимые данные кодируются таким образом, что команда «сравнение логическое» (CLC) системы IBM/370 всегда будет давать подходящий ответ, когда она выполняется над двумя значениями данных одного и того же типа в SQL. Например, значения типа INTEGER хранятся вместе с их знаковым битом н обратном коде. Таким образом, все хранимые поля данных рассматриваются программой управления хранимыми данными просто как последовательности байтов. Любая интерпретация такой последовательности, например, как значения типа INTEGER, осуществляется указанным выше интерфейсом управления данными. Достоинство такого подхода заключается в том, что можно вводить новые типы данных, не оказывая какого-либо влияния на компоненты нижнего уровня системы. В качестве упражнения предлагаем читателю попытаться разработать подходящие способы кодирования для других типов данных SQL.
Все хранимые поля выравниваются по границе байта. Между полями не оставляется никаких промежутков. Данные переменной длины занимают ровно столько байтов, сколько это необходимо для хранения фактического их значения.
Примечание. Выше описано стандартное представление хранимых записей. Однако для любой заданной таблицы установка системы располагает факультативной возможностью предоставления «процедуры редактирования», которой будет передаваться управление каждый раз, когда осуществляется запоминание или выборка записи. При «запоминании» эта процедура редактирования может преобразовывать стандартное представление в какой-либо другой требуемый формат, и запись будет храниться именно в этом формате. При «выборке» процедура редактирования должна, конечно, выполнять обратное преобразование. Таким образом, конкретная установка системы может, например, решать, хранить ли данные в сжатом или в кодированном формате. Более того, такое решение она может принимать исходя из свойств каждой конкретной таблицы.
Для внутренней адресации записей используются идентификаторы записей (ID или RID ( Аббревиатура словосочетания «Record Identifier».— Примеч. пер. )). Например, все указатели в индексах представляют собой RID. Все RID являются уникальными в базе данных, содержащей соответствующие записи. На рис. 13.2 показано, каким образом реализованы RID. Для хранимой записи R RID состоит из двух частей: из номера Р страницы, содержащей R, и из байта смещения от конца страницы Р, указывающего участок, который в свою очередь содержит байт смещения записи R от начала страницы Р. Такой метод представляет собой хороший компромисс между быстрым доступом при прямой адресации и гибкостью косвенной адресации. Можно проводить реорганизацию записей в рамках содержащей их страницы, например ликвидировать промежуток при удалении записи или подготавливать пространство для вставки записи, не создавая необходимости изменения RID. Должны изменяться только локальные смещения, хранимые в конце данной страницы. И тем не менее доступ к записи при заданном ее RID является быстрым. Он требует доступа только к одной странице.
Примечание. В редких случаях может потребоваться доступ к двум (и никогда не требуется более чем к двум) страницам. Это может случиться, если запись переменной длины обновляется таким образом, что она становится длиннее, чем она была до этого. Пусть, например, расширяется значение в некотором поле, имеющем переменную длину. При этом на данной странице не оказалось достаточного свободного пространства для того, чтобы разместить более длинную запись. В такой ситуации обновленная запись помещается на другую страницу—страницу переполнения», а первоначальная запись замещается указателем (RID) на новое место. Если подобная ситуация возникает снова, то такая обновленная запись должна быть все же переслана на третью страницу, после чего указатель на первоначальной странице изменяется так, чтобы он указывал на новое местоположение записи.
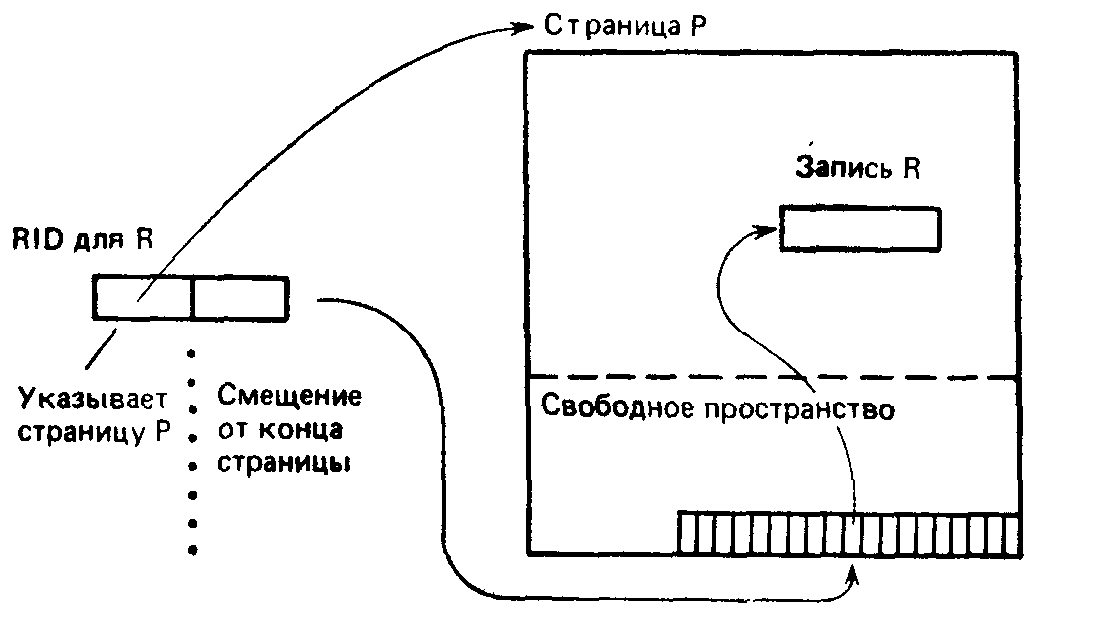
Рис. 13.2. Реализация указателей RID
Завершим обсуждение хранимых таблиц замечанием относительноo «процедуры проверки достоверности». Эта процедура напоминает процедуру редактирования тем, что ее можно специфицировать для заданной базовой таблицы системными средствами. Тогда каждый раз, когда указанная базовая таблица будет запоминаться, управление передается процедуре проверки достоверности этой таблицы. Задача такой процедуры состоит в том, чтобы контролировать достоверность для вновь вставляемой или обновляемой записи.
13.5. ИНДЕКСНЫЕ ПРОСТРАНСТВА
Индексное пространство играет такую же роль для индексов, как табличное пространство для таблиц. Однако в связи с тем, что соответствие между индексами и индексными пространствами всегда является взаимно однозначным (в отличие от соответствия между таблицами и табличными пространствами), нет никаких предложений определения данных для самих по себе индексных пространств. Вместо этого в предложениях определения соответствующих индексов специфицируются необходимые параметры индексных пространств. Так, например, нет предложения CREATE INDEXSPACE (создать индексное пространство), а индексное пространство создается автоматически при создании соответствующего индекса путем спецификации предложения CREATE INDEX (создать индекс). Указанное предложение может включать такие параметры, как имя связанной с этим индексом группы памяти и т. п.
Страницы в индексном пространстве всегда имеют размер 4К байт. Однако единица для целей блокирования может быть меньше, чем одна страница (это другое отличие от табличного пространства). Она может, например, составлять четверть страницы (1024 байта).
Подобно табличным пространствам индексные пространства могут реорганизовываться и восстанавливаться независимо. Индексное пространство, которое содержит требуемый индекс кластеризации для сегментированного табличного пространства, само предполагается сегментированным. Во всех других случаях индексное пространство рассматривается как простое (несегментированное). Сегмент сегментированного индексного пространства может быть реорганизован независимо. Отдельные сегменты могут быть связаны с различными группами памяти.
13.6. ИНДЕКСЫ
В системе DB2 индексы основываются на структуре, называемой В-деревом. B-дерево — это многоуровневый, имеющий древовидную структуру индекс, обладающий тем свойством, что это дерево всегда сбалансировано. Это означает, что все вершины — листья в такой структуре—равноудалены от корня дерева, и это свойство сохраняется, когда в дерево вставляются новые вершины и удаляются существующие. В результате такой индекс обеспечивает постоянную и прогнозируемую производительность для операций поиска. Подробное обсуждение вопроса о том, каким образом достигается такой результат, выходит за рамки этой книги. Однако на рис. 13.3 приводится простой пример, показывающий, как мог бы выглядеть такой индекс.
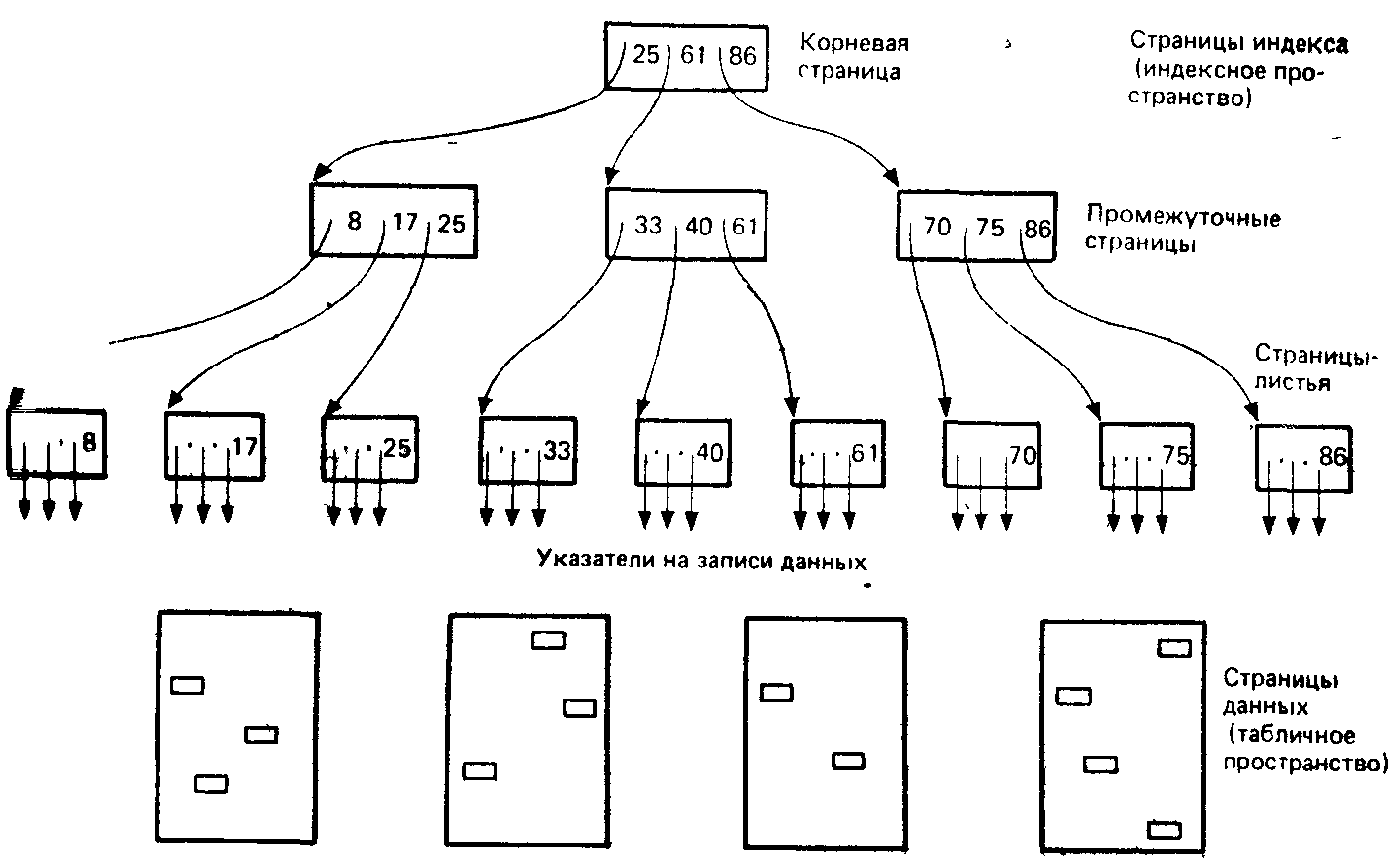
Рис. 13.3. Пример индекса
Как видно из рисунка, индекс состоит из корневой страницы, из нуля или более промежуточных страниц (образующих нуль или более промежуточных уровней, в примере имеется один такой промежуточный уровень), а также из некоторого множества страниц—листьев. На уровне листьев имеется по одной статье—значение индексируемого поля и указатель — для каждой записи в индексируемой таблице. Страницы — листья связываются между собой так, что они сами по себе могут использоваться для быстрого последовательного доступа к индексируемым данным в порядке, поддерживаемом индексом. Каждый уровень выше уровня листьев в свою очередь содержит по одной статье — наивысшее значение поля и указатель для каждой страницы статей более низкого уровня. Таким образом, корневая страница вместе с промежуточными страницами обеспечивают быстрый прямой доступ к страницам—листьям, а следовательно, быстрый прямой доступ также и к индексируемым данным.
Для заданной хранимой таблицы может иметься любое число связанных с нею индексов, и поэтому для нее может поддерживается любое число способов логического упорядочения. Конечно, всегда существует единственный способ физического упорядочения. Для того чтобы произвести полный просмотр таблицы в соответствии с заданным индексом, программа управления хранимыми данными будет обращаться ко всем записям в рассматриваемой таблице в последовательности, определяемой этим индексом. Поскольку такая последовательность может быть весьма отличной от физической последовательности, установленной для таблицы, обращение к любой странице данных может осуществляться много раз. (С другой стороны, вообще не будет обращений к страницам данных, не содержащих никаких записей таблицы.). Поэтому полный просмотр с помощью индекса потенциально может оказаться более медленным, чем полный просмотр в физической последовательности, если рассматриваемый индекс не является индексом кластеризации. Как уже указывалось ранее, индекс кластеризации—это такой индекс, для которого определяемая им последовательность совпадает с физической или близка к ней. Для каждой таблицы может быть создано не более одного индекса кластеризации. Этот индекс должен быть первым индексом, создаваемым для таблицы, и в идеальном случае должен создаваться прежде, чем в таблицу будут загружаться какие-либо данные. Индексы кластеризации имеют чрезвычайно важное значение с точки зрения оптимизации. Генератор планов прикладных задач всегда будет пытаться выбрать путь доступа, основанный на индексе кластеризации, если такой индекс имеется в распоряжении. На практике индекс кластеризации следует иметь для каждой таблицы, если только она не слишком мала, а возможно, даже и в этом случае.
13.7. ГРУППЫ ПАМЯТИ
Группа памяти—это именованная совокупность томов с прямым доступом, причем все они относятся к устройствам одного и того же типа. С каждым простым табличным пространством, простым индексным пространством, сегментом сегментированного табличного пространства и сегментом сегментированного индексного пространства связана некоторая группа памяти24. Когда для пространства или сегмента требуется память, она берется из специфицированной группы памяти. Таким образом, группы памяти предоставляют установке системы возможности для разделения и сближения данных. Они могут, например, обеспечить хранение двух таблиц на различных томах. В то же время они дают возможность возложить на систему управление большей частью детальных аспектов размещения наборов данных, экстентов и т. д.
Пространства и сегменты в каждой группе памяти поддерживаются с использованием наборов данных VSAM с последовательным входом. При этом одному пространству или сегменту, вообще говоря, соответствует множество наборов данных. Система DB2 использует VSAM также для управления пространствами с прямым доступом и для каталогизации наборов данных. Управление пространством внутри страниц, т. е. оперирование управляющими интервалами VSAM, осуществляется системой DB2, а не средствами VSAM, и индексирование VSAM вообще не используется. Таким образом, как уже упоминалось в главе 9, наборы данных системы DB2 не являются обычными наборами данных VSAM. Их внутренний формат не совпадает с форматом, предусмотренным для VSAM, и обращаться к этим наборам данных с использованием обычного VSAM невозможно. По тем же причинам невозможно обращаться к существующим наборам данных VSAM, используя возможности DB2, например язык SQL.
13.8. ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
В этой главе был представлен краткий обзор объектов среды хранения, поддерживаемых системой DB2. Как уже отмечалось в разделе 13.1, мы не ставили задачи описать в этой книге во всех подробностях соответствующие предложения определения данных. Отметим, однако, следующее.
– Табличное пространство для данной таблицы специфицируется и предложении CREATE TABLE, соответствующем этой таблице.
– База данных для данного табличного пространства специфицируется в предложении CREATE TABLESPACE, соответствующем этому табличному пространству; предполагается, что база данных для заданного индексного пространства—та же, что и для таблицы, над которой определяется этот индекс — индексное пространство должно быть частью той же базы данных, в которую входит соответствующее табличное пространство.
– Детальные аспекты сегментирования (диапазоны страниц и т. п.) табличного пространства специфицируются в предложении CREATE INDEX для требуемого индекса кластеризации. Подробности сегментирования соответствующего индексного пространства специфицируются также в этом предложении CREATE INDEX.
– Группа памяти для данного пространства или сегмента специфицируется в предложении CREATE TABLESPACE или CREATE INDEX, определяющем это пространство или этот сегмент.
– Тома, составляющие данную группу памяти, специфицируются и предложении CREATE, которое создает эту группу памяти.
Помимо всего перечисленного выше, а также указанного в разделе 13.1, DB2 обеспечивает исчерпывающую систему спецификации по умолчанию, которая разработана для того, чтобы облегчить «вхождение в контакт» с системой. Полный механизм умолчаний можно представить следующим образом:
– Предложение CREATE TABLE может специфицировать базу данных, а не табличное пространство. В этом случае DB2 автоматически создает табличное пространство в этой базе данных для новой таблицы. Это табличное пространство будет автоматически уничтожаться при уничтожении данной таблицы. При этом даже нет необходимости специфицировать базу данных. Если не специфицированы ни база данных, ни табличное пространство, DB2 создаст табличное пространство для новой таблицы в базе данных по умолчанию—базе данных, определяемой для таких целей при установке системы.
– Если в предложении CREATE TABLESPACE не специфицируется база данных, то новое табличное пространство будет назначаться в базе данных по умолчанию.
— Группа памяти может быть специфицирована на любом (или на всех) из следующих уровней:
— уровень базы данных (в предложении CREATE DATABASE)
— уровень пространства (в предложениях CREATE TABLESPACE и CREATE INDEX)
— уровень сегмента (в спецификации сегмента в предложениях CREATE INDEX и CREATE TABLESPACE).
Если для заданного сегмента не специфицирована группа памяти на уровне сегмента, то имеется в виду группа памяти, которая относится к пространству, содержащему данный сегмент. Если группа памяти не специфицирована для заданного пространства на уровне пространства, то для этого пространства имеется в виду группа памяти, которая относится к содержащей это пространство базе данных. Если же не специфицирована группа памяти на уровне базы данных для заданной базы данных, то для этой базы данных будет использоваться группа памяти по умолчанию — группа памяти, которая определяется для таких целей при установке системы.
Из всего сказанного выше следует, что приведенные в главе 3 предложения определения данных действительно адекватны потребностям «легкого вхождения в контакт». Однако в большинстве реальных ситуаций на установке потребуется, вероятно, осуществлять более жесткое управление, которое возможно без использования умолчаний. Назначение умолчаний состоит, главным образом, в том, чтобы дать пользователю возможность быстро научиться использованию системы, а не в обеспечении подходящего множества спецификаций для производственной обстановки.
В заключение следует кратко упомянуть о буферных пулах. Буферы в основной памяти группируются в ряд пулов. Заданное пространство может использовать только один такой пул. Буферный пул для заданного пространства специфицируется с помощью еще одного параметра в соответствующем предложении CREATE. Если этот параметр опущен, то, как обычно, предполагается, конечно, спецификация по умолчанию. Таким образом, установка системы может в некоторой степени управлять разделением и близостью данных в основной памяти. Например, можно было бы приписать данное индексное пространство и соответствующее ему табличное пространство к различным буферным пулам, повышая, таким образом, вероятность того, что статьи индекса и записи данных могут одновременно находиться в основной памяти.