
Методические указания к лабораторным работам для студентов специальности 210100 "Автоматика и информатика в технических системах"
| Вид материала | Методические указания |
| Лабораторная работа № 3 РАЗРАБОТКА ИНФОРМАЦИОННОЙ МОДЕЛИ ПРЕДМЕТНОЙ ОБЛАСТИ 1.Общие сведения Modify structure 2. Задание на работу |
- Методические указания к лабораторным работам №1-5 для студентов специальности 210100, 363.6kb.
- Методические указания по курсовому проектированию для студентов специальности 210100, 395.17kb.
- Образовательный стандарт томского политехнического университета по специальности 210100-Управление, 403.93kb.
- Рабочая программа для подготовки инженеров по специальности 210100 "Управление и информатика, 100.75kb.
- Рабочая программа для специальности 210100 "Управление и информатика в технических, 99.04kb.
- Программа для специальности 210100 "Управление и информатика в технических системах", 277.23kb.
- Программа для специальности 210100 "Управление и информатика в технических системах", 191.22kb.
- Методические указания к лабораторным работам по физике по практикуму «Вычислительная, 138.12kb.
- Рабочая программа для направления 550200 "Автоматизация и управление", для специальности, 305.49kb.
- Методические указания к лабораторным работам Самара 2007, 863.04kb.
Лабораторная работа № 3
РАЗРАБОТКА ИНФОРМАЦИОННОЙ МОДЕЛИ ПРЕДМЕТНОЙ ОБЛАСТИ
Цель работы: освоить технологию разработки информационной модели предметной области (ПО), изучить команды языка описания данных СУБД реляционного типа и разработать информационную модель заданной в рамках курсовой работы предметной области.
1.ОБЩИЕ СВЕДЕНИЯ
В информационной системе (ИС) реализуется определенная информационная технология по сбору, обработке, хранению, передаче и использованию информации. Если говорится о современной информационной технологии, то, как правило, подразумевают в составе ИС наличие вычислительной системы и такие ИС называют автоматизированными информационными системами (АИС). В класс АИС обычно включают(рис.3):
1. Автоматизированные системы управления (АСУ) различного назначения. Они предназначены для непрерывного динамичного отражения изменений в предметной области с целью обеспечения лиц, принимающих решения, объективной информацией. Основная функция – это систематизация информации о предметной области.
2. Автоматизированные рабочие места различного назначения (АРМ). Например, АРМ бухгалтера по начислению заработной платы, АРМ экономиста по калькуляции себестоимости, АРМ "Квартплата", АРМ "Ведение реестра акционеров", АРМ "Складское хозяйство", АРМ диспетчера АТП и т.п. Основная функция – это достаточно сложная обработка информации.
3. Информационно-справочные системы различного назначения (ИСС) . Например, ИСС для диагностики болезней, ИСС для продажи авиабилетов, ИСС "Расписание движения поездов". Основная функция – использование информации по назначению. В перечисленных системах наиболее ярко выделяется одна из составных частей информационной технологии.
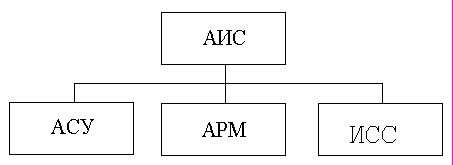
Рис. 3
Среди множества задач, решаемых разработчиком логической структуры БД, следующие являются наиболее важными:
1. Реализация возможности хранения всех необходимых данных о ПО.
2. Исключение избыточности данных. (Повторение данных в таблицах может явиться причиной ошибок при вводе и быть проявлением нерационального использования дисковой памяти.
3. Сведение числа хранимых в БД отношений к минимуму (обеспечение быстрого доступа к данным).
4. Обеспечение целостности данных. Обеспечить такие условия, чтобы при изменении одних данных автоматически происходило соответствующее изменение связанных с ними других данных.
В FoxPro целостность данных средствами СУБД не поддерживается, поэтому для упрощения проблем, связанных с модификацией и удалением данных, следует нормализовать все отношения БД. Нормализация также способствует исключению избыточности.
Третья и четвертая задачи, очевидно, являются противоречивыми.
Обычно содержание проектных работ при разработке АИС (такие системы в простейшем варианте являются предметом курсовой работы или дипломного проектирования) включает четыре относительно самостоятельных этапа.
1. Обоснование и выбор СУБД.
2. Разработка информационной модели предметной области.
3. Разработка прикладного программного комплекса.
4. Опытная эксплуатация и доводка.
Формальных методик выполнения работ по перечисленным этапам не существует, как их не существует для любых проектных работ, хотя отдельные проектные процедуры хорошо формализуются.
Второй этап проектирования распадается на две части, а именно: разработку логической структуры БД (разработку инфологической модели); описание логической структуры БД на языке описания данных выбранной СУБД (разработку датологической модели).
По существу разработка логической структуры БД - это поиск ответов на два следующих вопроса:
1. Какие объекты и какие их свойства отражать в БД?
2. Как объекты взаимосвязаны между собой в БД?
Другими словами, какие поля и сколько их будет назначено в БД; сколько отношений будет организовано и какие поля войдут в каждое отношение? Качество ответов на эти вопросы можно оценить следующими критериями:
1. Невозможностью проявления аномальных явлений при работе с БД.
2. Неизбыточностью информации в БД.
3. Объемом хранимых данных.
Для решения первой задачи существуют два подхода: "от запроса" и "от предметной области".
При выяснении перечня полей в будущей БД по подходу "от предметной области" ставят цель - задать такое множество полей, которое бы не пришлось в будущем дополнять даже при изменении функции БД. Например, при проектировании АРМа "Кадры" - учесть всю информацию о сотруднике, даже такую, которая не нужна отделу кадров, т.е. чтобы в будущем возможно было бы автоматизировать систему начисления заработной платы и др. Обычно, чтобы решить достаточно качественно такую сложную задачу, исследуется документооборот в данной предметной области. Формы документов (приказы, отчеты и карточки), как правило, содержат полные сведения об исследуемой ПО, существуют на длительном отрезке времени, и в них отражается вся необходимая информация.
Технология "от запроса" предполагает исследование потребностей в информации каждого будущего пользователя. Как правило, это исследование ведется в форме беседы, и разработчик БД старается максимально полно выяснить, какие запросы к БД интересуют потенциального пользователя. Опросив всех потенциальных пользователей, разработчик может задать перечень полей проектируемой БД. В этой технологии вероятность пропустить нужную информацию значительно больше, чем в первой технологии, т.к. пользователи чаще всего не представляют сами четко, что бы они хотели получать от БД. Реально технология проектирования БД обычно сочетает в себе идеи обоих подходов. Как правило, в ней приоритетное место отводится подходу "от запроса".
Результат решения второй задачи - назначение перечня отношений и полей в них. Это наиболее сложная часть процесса проектирования. Работа с базой, содержащей аномалии, может привести к негативным явлениям, к неверным ответам на запросы, к потери информации.
В литературе обсуждаются обычно только две технологии назначения отношений и их состава:
1. Метод декомпозиции.
2. Метод "сущность – связь".
Идея метода декомпозиции заключается в том, что на первом шаге строится универсальное отношение (одна большая таблица) и анализируются функциональные зависимости в этой таблице, ее разбивают на ряд подтаблиц так, чтобы каждая из них содержала одну функциональную зависимость (взаимооднозначное отображение).
Идея второго метода: в предметной области выделяются объекты или явления, анализируется как они взаимосвязаны, и информация о каждом объекте и каждой возможной связи хранится в отдельной таблице.
Приведем основные моменты технологии "сущность-связь".
Это неформальная технология разработки инфологической модели ПО. Модель отражает объекты и их свойства и взаимоотношения объектов в ПО.
Основными структурными элементами модели являются: сущность, атрибут и связь (такие понятия приняты традиционно). Эти элементы составляют содержание графических диаграмм, представляющих модель. Кроме того, неявно присутствует, как правило, для отражения динамики ПО такой элемент, как время. Неявное представление времени осуществляется атрибутами, например, "годом рождения", "датой поступления", "датой назначения" и т.п.
Сущность – это собирательный (обобщенный) термин для реально существующего объекта, процесса или явления, о котором необходимо хранить информацию в системе. Примеры сущностей:
материальные – предприятия, изделия, сотрудники;
нематериальные – описание явления, рефераты научных статей, платежные поручения и т.д.
В технологии каждая рассматриваемая конкретная сущность является опорной точкой сбора информации. С термином «сущность» связаны еще два понятия: тип сущности и экземпляр сущности.
Тип сущности – это набор (множество) однородных объектов. Например, "студенты – ХГТУ", "города – края", "квартиры – районы" и т.п.
Экземпляр сущности – это конкретный объект типа сущности.
Каждый рассматриваемый тип сущности должен быть поименован уникальным именем. Правило образования имен произвольно и назначается разработчиком модели.
Для идентификации экземпляров сущности в каждом типе следует назначить специальный атрибут(ы), который позволяет однозначно отличить один экземпляр от другого. Его называют идентификатором, ключом, ключевым атрибутом.
Атрибут – это поименованная характеристика (свойство) сущности, которая может принимать значения из некоторого множества значений. Например, для описания свойств сущности "книга" можно использовать атрибуты "название", "фамилия автора", "год издания" и др. Чтобы задать атрибут в модели следует:
– присвоить ему имя;
– дать смысловое описание;
– определить множество его допустимых значений;
– указать, для чего он используется;
Назначение атрибутов в модели – задать свойство объекта, идентифицировать экземпляры типов сущностей и, возможно, задать связи между сущностями (например, связь "отец"), т.к. связи характеризуют объекты, находящиеся в данном отношении.
Связь – это средство, с помощью которого представляют отношение между сущностями, имеющее место в ПО. Так как связь может рассматриваться только между типами сущностей, то принято говорить, что между этими типами сущностей существует такой-то тип связи. Связь между экземплярами сущностей принято называть экземпляром связи.
Связь между двумя типами сущностей – это бинарная связь; тремя – тернарная и в общем случае n – арная.
В реляционных СУБД связи бинарные специфицируются парами, компонентами которых являются ключевые атрибуты соответствующих сущностей. Кроме того, связь может иметь свои атрибуты. Например, связь "поставка товаров" между типами сущностей "поставщики" и "товары" может иметь атрибут "количество".
Результаты разработки модели оформляют в виде :
– спецификации сущностей; например
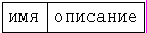
– спецификации атрибутов сущностей;
например
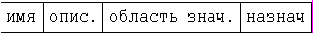
– спецификации связей; например
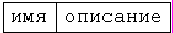
– графической диаграммы.
На графических диаграммах типы сущностей представляют обычно прямоугольниками; атрибуты – овалами, соединенными с соответствующими типами сущностей ненаправленными ребрами, ключевые атрибуты подчеркиваются; связи – ромбами, соединенными с соответствующими типами сущностей ненаправленными ребрами, за исключением бинарных связей, которые обозначаются направленными дугами.
При разработке информационной модели следует придерживаться общих правил:
1. Использовать только три типа элементов модели: сущность, атрибут и связь.
2. В модели каждый компонент ПО моделировать только одним элементом (исключать избыточность).
3. Использовать декомпозицию ПО (разбить ПО на ряд локальных областей, смоделировать каждую локальную область отдельно, а затем их объединить).
- Помнить об итерационном характере процесса проектирования.
Для представления информационной модели предметной области в вычислительной системе используется язык описания данных СУБД. В известных СУБД реляционного типа, ориентированных на использование с ПК, этот язык представлен в виде одной команды. Ниже приводится описание функциональных возможностей этой команды.
Ее формат
CREATE [файл].
Этот формат команды CREATE позволяет создавать новые файлы баз данных с использованием режима полноэкранного редактирования. Если имя файла [файл] не задано явно в составе команды, то будет выведен запрос на ввод имени создаваемого файла. Затем система управления запросит ввести имя, тип, длину и количество дробных десятичных знаков для каждого из полей создаваемого файла базы данных. Вы сообщаете системе о завершении создания файла базы данных путем нажатия
После того как создание базы данных будет завершено, система спросит, желаете ли вы вводить данные в новую базу немедленно. Если вы ответите 'Y'es (да), то система автоматически перейдет в режим APPEND и вы сможете выполнить ввод данных. Если вы ответите 'N'o (нет), то управление будет передано команде, следующей за командой CREATE в командном файле или просто в интерактивный режим. Возможен и другой формат команды, а именно:
CREATE <файл1> FROM <файл2>
В этом формате команды CREATE подразумевается, что файл <файл2> был создан в ручном режиме или с использованием команды COPY STRUCTURE EXTENDED и что этот файл был отредактирован соответствующим образом. Затем создается <файл1>, который имеет структуру, описанную в файле <файл2>. В результате вновь созданный файл базы данных заносится в область USE.
Доступ к существующему файлу базы данных осуществляется командой USE.
При необходимости структуру отношения можно изменить. Для этого можно воспользоваться командой
MODIFY STRUCTURE,
которая выводит структуру активного файла базы данных. Затем может быть выполнено редактирование структуры в полноэкранном режиме, включая введение новых и удаление старых полей, изменение имен, размеров и типов полей.
Система выполняет автоматическое копирование файла <файл> перед изменением структуры. Когда процесс редактирования будет завершен, данные, содержащиеся в скопированном файле базы данных (.BAK) будут введены в отредактированную структуру файла. Будет также создана копия файла примечаний (.FPT) с расширением .TBK, если в файле <файл> изменяется количество полей примечания.
Записи из копии файла не будут введены в новую структуру, если единовременно будут изменены и имя и длина поля (или общая длина записи). В связи с этим рекомендуется при первом сеансе работы в MODIFY STRUCTURE изменять имена полей, а затем со второго прохода изменять длину полей и/или вводить новые поля.
2. ЗАДАНИЕ НА РАБОТУ
2.1. Используя учебные пособия [4–15], материал первого раздела данной лабораторной работы, системную документацию по СУБД или информационную подсистему по языкам СУБД в автоматизированной справочной системе NG, сведения о предметной области из задания на курсовую работу, исследовать предметную область с позиции системного подхода и изучить функциональные возможности команды CREATE.
2.2.Разработать инфологическую модель заданной предметной области, применив технологию "сущность-связь". Используя команду CREATE, представить информационную модель на машинном носителе.
2.3.Оформить отчет, который должен включать спецификации сущностей, атрибутов и связей, а также графическую диаграмму инфологической модели предметной области. Представить для защиты датологическую модель в виде распечаток содержимого соответствующих файлов DBF.