
Лекция №7. Атрибутивная информация Лекция №7. Атрибутивные данные в гис
| Вид материала | Лекция |
- Концепция тренажера уровня установки. Требования к тренажеру (лекция 3, стр. 2-5), 34.9kb.
- Лекция №10. Инструментальные средства гис лекция №10. Инструментальные средства гис, 499.17kb.
- «Социальная стратификация и социальная мобильность», 46.19kb.
- Тема Лекция, 34.13kb.
- Лекция №4. Модели данных > Лекция №4. Модели данных Вопросы организации данных в гис,, 462.87kb.
- Лекция №16. Применение гис по сфере использования гис не имеют себе равных. Они применяются, 429.39kb.
- Первая лекция. Введение 6 Вторая лекция, 30.95kb.
- Лекция Сионизм в оценке Торы Лекция Государство Израиль испытание на прочность, 2876.59kb.
- Доступны из любых функций программы. Сокрытие данных (инкапсуляция) применяется для, 89kb.
- Лекция 1 Информация, свойства информации. Информация, 136.63kb.
Лекция №7. Атрибутивная информация
Лекция №7. Атрибутивные данные в ГИС.
7.1.Численные и информационные прикладные системы
Во всей истории вычислительной техники можно проследить две основных области ее использования. Первая область - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Развитие этой области способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Вторая область, которая непосредственно относится к теме наших лекций, - это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. В самом широком смысле информационная система представляет собой программно-аппаратный комплекс, функции которого состоят в надежном хранении информации в памяти компьютера, выполнении специфических для данного приложения преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса. Обычно такие системы имеют дело с большими объемами информации, и эта информация имеет достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т. д.
Вторая область использования вычислительной техники возникла несколько позже первой. Это связано с тем, что на заре вычислительной техники возможности компьютеров по хранению информации были очень ограниченными.
Потребности информационных систем
Информационные системы главным образом ориентированы на хранение, выбор и модификацию постоянно хранимой информации. Структура информации обычно очень сложна, и хотя структуры данных различны в разных информационных системах, между ними часто бывает много общего. На начальном этапе использования вычислительной техники проблемы структуризации данных решались индивидуально в каждой информационной системе. Производились необходимые надстройки (библиотеки программ) над файловыми системами, подобно тому, как это делается в компиляторах, редакторах и т. д.
Но поскольку в информационных системах требуется поддержка сложных структур данных, эти индивидуальные средства управления данными составляли существенную часть информационных систем, практически повторяясь (как программные компоненты) от одной системы к другой. Стремление выделить общую часть информационных систем, ответственную за управление сложно структурированными данными явилось, на наш взгляд, первой побудительной причиной создания СУБД, которая, возможно, могла бы представлять некоторую общую библиотеку программ, доступную каждой информационной системе.
Однако очень скоро стало понятно, что невозможно обойтись такой общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данными.
Современные системы управления файлами и управления базами данных представляют собой весьма совершенные инструменты, каждый из которых может быть очень успешно применен в соответствующей области деятельности. Но всегда необходимо помнить, что каждый инструмент приносит максимальную пользу именно в той области, для которой он создан.
Важнейшая задача компьютерных систем - хранение и обработка данных. Для ее решения были предприняты усилия, которые привели к появлению в конце 60-х - начале 70-х годов специализированного программного обеспечения - систем управления базами данных (DataGBase Management Systems - DBMS). СУБД позволяют структурировать, систематизировать и организовать данные для их компьютерного хранения и обработки. Сегодня невозможно представить себе деятельность любого современного предприятия или организации без использования профессиональных СУБД. Несомненно, они составляют фундамент информационной деятельности во всех сферах - начиная c производства и заканчивая финансами и телекоммуникациями.
Обращаясь к истории развития и совершенствования систем управления базами данных, можно условно выделить три основных этапа. Начальный этап был связан с созданием первого поколения СУБД, опиравшихся на иерархическую и сетевую модели данных (на основе спецификаций CODASYL). По времени он совпал с периодом, когда на рынке вычислительной техники доминировали большие ЭВМ (mainframe), например, система IBM 360/370, которые в совокупности с СУБД первого поколения составили аппаратно-программную платформу больших информационных систем.
К сожалению, СУБД первого поколения были в подавляющем большинстве закрытыми системами: отсутствовал стандарт внешних интерфейсов, не обеспечивалась переносимость прикладных программ. Они не обладали средствами автоматизации программирования и имели массу других недостатков, оцениваемых с точки зрения сегодняшних требований к СУБД. Кроме того, они были очень дороги. В то же время СУБД первого поколения оказались весьма долговечными: разработанное на их основе программное обеспечение используется и по нынешний день и большие ЭВМ по-прежнему хранят огромные массивы актуальной информации.
С созданием реляционной модели данных был начат новый этап в эволюции СУБД. Простота и гибкость модели привлекли к ней внимание разработчиков и снискали ей множество сторонников. Несмотря на некоторые недостатки (у кого их нет?), реляционная модель данных стала доминирующей. Условно эту группу систем можно назвать "вторым поколением СУБД". Его характеризовали две основные особенности - реляционная модель данных и язык запросов SQL. Представители второго поколения в настоящее время еще сохраняют определенную популярность среди производителей СУБД, в большинстве своем развившись в системы третьего поколения, к которому и относятся современные СУБД.
Для них характерны использование идей объектно-ориентированного подхода, управления распределенными базами данных, активного сервера БД, языков программирования четвертого поколения, фрагментации и параллельной обработки запросов, технологии тиражирования данных, многопотоковой архитектуры и других революционных достижений в области обработки данных. СУБД третьего поколения - это сложные многофункциональные программные системы, функционирующие в открытой распределенной среде. Сегодня они уже доступны для использования в деловой сфере, то есть они выступают не просто в качестве технических и научных решений, но как завершенные продукты, предоставляющие разработчикам мощные средства управления данными и богатый инструментарий для создания прикладных программ и систем.
На эволюции СУБД сильно сказался процесс перехода от больших ЭВМ к открытым распределенным системам на компьютерах RISC-архитектуры. По темпам развития RISC-компьютеры за последнее десятилетие существенно превзошли большие ЭВМ. Причинами того, что более половины обладателей больших ЭВМ заявили о намерении в ближайшее время отказаться от них в пользу открытых систем, послужили три фактора. Во-первых, цена RISC-компьютеров значительно ниже цены больших ЭВМ, и эта разница постоянно растет. Во-вторых, по функциональным возможностям RISC-компьютеры превзошли большие ЭВМ. В третьих, фактически сравнялась их производительность. Кроме того, архитектура систем на основе RISC-компьютеров оказалась более простой, гибкой и мобильной, а сфера их использования - значительно шире области применения больших ЭВМ.
Общая тенденция движения от отдельных mainframe-систем к открытым распределенным системам, объединяющим компьютеры среднего класса, получила название DownSizing. Этот процесс оказал огромное влияние на развитие архитектур СУБД и поставил перед их разработчиками ряд сложных проблем. Главная проблема состояла в технологической сложности перехода от централизованного управления данными на одном компьютере и СУБД, использовавшей собственные модели, форматы представления данных и языки доступа к данным и т.д., к распределенной обработке данных в неоднородной вычислительной среде, состоящей из соединенных в глобальную сеть компьютеров различных моделей и производителей.
В то же время происходил встречный процесс - UpSizing. Бурное развитие персональных компьютеров, появление локальных сетей также оказали серьезное влияние на эволюцию СУБД. Высокие темпы роста производительности и функциональных возможностей PC привлекли внимание разработчиков профессиональных СУБД, что привело к их активному распространению на платформе настольных систем.
Сегодня возобладала тенденция создания информационных систем на такой платформе, которая точно соответствовала бы ее масштабам и задачам. Она получила название RightSizing (помещение ровно в тот размер, который необходим).
Однако и по нынешнее время большие ЭВМ сохраняются и сосуществуют с современными открытыми системами. Причина этого проста - в свое время в аппаратное и программное обеспечение больших ЭВМ были вложены огромные средства: в результате многие продолжают их использовать несмотря на морально устаревшую архитектуру. В то же время перенос данных и программ с больших ЭВМ на компьютеры нового поколения представляет сам по себе сложную техническую проблему и требует значительных затрат.
Как же использовать ресурсы больших ЭВМ в современной организации? Один из возможных подходов заключается в интеграции больших ЭВМ и работающих на них СУБД в открытую распределенную среду обработки данных с помощью шлюзов (gateway). В этом случае большая ЭВМ может временно выполнять роль центрального компьютера, хранящего данные и предоставляющего их для обработки RISC-компьютерам, что будет происходить то тех пор, пока не будут созданы все условия для замены ее на высокопроизводительные компьютеры среднего класса.
Таким образом, в широком смысле слова база данных - это совокупность описаний объектов реального мира и связей между ними, актуальные для конкретной прикладной области.
В традиционной терминологии объекты реального мира, сведения о которых хранятся в базе данных, называются сущностями - entities (пусть это слово не пугает читателя - это общепринятый термин), а их актуальные признаки - атрибутами (attributes).
Теперь необходимо понять, как сущности, атрибуты и связи отображаются на структуры данных. Это определяется моделью данных.
Традиционно все СУБД классифицируются в зависимости от модели данных, которая лежит в их основе. Принято выделять иерархическую, сетевую и реляционную модели данных. Иногда к ним добавляют модель данных на основе инвертированных списков. Соответственно говорят о иерархических, сетевых, реляционных СУБД или о СУБД на базе инвертированных списков.
По распространенности и популярности реляционные СУБД сегодня - вне конкуренции.
Поэтому кратко рассмотрим реляционную модель данных, не вникая в ее детали.
Она была разработана Коддом еще в 1969-70 годах на основе математической теории отношений и опирается на систему понятий, важнейшими из которых являются таблица, отношение, строка, столбец, первичный ключ, внешний ключ.
Реляционной считается такая база данных, в которой все данные представлены для пользователя в виде прямоугольных таблиц значений данных, и все операции над базой данных сводятся к манипуляциям с таблицами. Таблица состоит из строк и столбцов и имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка - конкретный объект.
Каждый столбец имеет имя, которое обычно записывается в верхней части таблицы (рис.1). Оно должно быть уникальным в таблице, однако различные таблицы могут иметь столбцы с одинаковыми именами. Любая таблица должна иметь по крайней мере один столбец; столбцы расположены в таблице в соответствии с порядком следования их имен при ее создании. В отличие от столбцов, строки не имеют имен; порядок их следования в таблице не определен, а количество логически не ограничено.
Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции - среди них не существует "первой", "второй", "последней". Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом (primary key). В нем значения не могут дублироваться - в таблице. Если таблица удовлетворяет этому требованию, она называется отношением (relation).

Взаимосвязь таблиц является важнейшим элементом реляционной модели данных. Она поддерживается внешними ключами (foreign key). Рассмотрим пример, в котором база данных хранит информацию о рядовых сотрудниках (таблица Сотрудник) и руководителях (таблица Руководитель) в некоторой организации (рис.2). Первичный ключ таблицы Руководитель - столбец Номер (например, табельный номер). Столбец Фамилия не может выполнять роль первичного ключа, так как в одной организации могут работать два руководителя с одинаковыми фамилиями. Любой сотрудник подчинен единственному руководителю, что должно быть отражено в базе данных. Таблица Сотрудник содержит столбец Номер руководителя, и значения в этом столбце выбираются из столбца Номер таблицы Руководитель (см. рис.2). Столбец Номер Руководителя является внешним ключом в таблице Сотрудник.
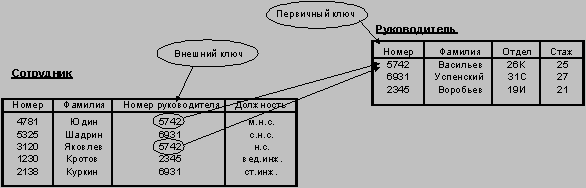
Таблицы невозможно хранить и обрабатывать, если в базе данных отсутствуют "данные о данных", например, описатели таблиц, столбцов и т.д. Их называют обычно метаданными. Метаданные также представлены в табличной форме и хранятся в словаре данных (data dictionary).
Помимо таблиц, в базе данных могут храниться и другие объекты, такие как экранные формы, отчеты (reports), представления (views) и даже прикладные программы, работающие с базой данных.
Для пользователей информационной системы недостаточно, чтобы база данных просто отражала объекты реального мира. Важно, чтобы такое отражение было однозначным и непротиворечивым. В этом случае говорят, что база данных удовлетворяет условию целостности (integrity).
Для того, чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints).
Существует несколько типов ограничений целостности. Требуется, например, чтобы значения в столбце таблице выбирались только из соответствующего домена. На практике учитывают и более сложные ограничения целостности, например, целостность по ссылкам (referential integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице. Ограничения целостности реализуются с помощью специальных средств
7.1.1.Язык SQL
Сами по себе данные в компьютерной форме не представляют интерес для пользователя, если отсутствуют средства доступа к ним. Доступ к данным осуществляется в виде запросов к базе данных, которые формулируются на стандартном языке запросов. Сегодня для большинства СУБД таким языком является язык SQL.
Его появление и развитие как средства описания доступа к базе данных связано с созданием теории реляционных баз данных. Прообраз языка SQL возник в 1970 году в рамках научно-исследовательского проекта System/R, работа над которым велась в лаборатории Санта-Тереза фирмы IBM. Сегодня SQL - это фактический стандарт интерфейса с современными реляционными СУБД. Популярность его настолько велика, что разработчики не-реляционных СУБД (например, Adabas), снабжают свои системы SQL-интерфейсом.
Язык SQL имеет официальный стандарт - ANSI/ISO. Большинство разработчиков СУБД придерживается этого стандарта, однако часто расширяют его для реализации новых возможностей обработки данных. Новые механизмы управления данными, которые будут описаны в Разделе 2, могут быть использованы только через специальные операторы SQL, в общем случае не включенные в стандарт языка.
SQL не является языком программирования в традиционном представлении. На нем пишутся не программы, а запросы к базе данных. Поэтому SQL - декларативный язык. Это означает, что с его помощью можно сформулировать, что необходимо получить, но нельзя указать, как это следует сделать. В частности, в отличие от процедурных языков программирования (СИ, Паскаль, Ада), в языке SQL отсутствуют такие операторы, как if/then/else, for, while, break, continue и т.д.
Мы не будем подробно рассматривать синтаксис языка. Коснемся его лишь в той мере, которая необходима для понимания простых примеров. С их помощью будут проиллюстрированы наиболее интересные механизмы обработки данных.
Запрос на языке SQL состоит из одного или нескольких операторов SQL, следующих один за другим и разделенных точкой с запятой. Наиболее важные операторы SQL, которые входят в стандарт ANSI/ISO SQL, перечислены в табл.1.
| SELECT | Выбрать данные из базы данных | ВЫБРАТЬ |
| INSERT | Добавить данные в базу данных | ВКЛЮЧИТЬ |
| UPDATE | Обновить данные в базе данных | ОБНОВИТЬ |
| DELETE | Удалить данные из базы данных | УДАЛИТЬ |
| GRANT | Предоставить привилегии пользователю | РАЗРЕШИТЬ |
| REVOKE | Отменить привилегии пользователя | ОТМЕНИТЬ |
| COMMIT | Зафиксировать текущую транзакцию | ЗАФИКСИРОВАТЬ |
| ROLLBACK | Прервать текущую транзакцию | ПРЕРВАТЬ |
Каждый столбец в любой таблице хранит данные определенных типов. Различают базовые типы данных - строки символов фиксированной длины, целые и вещественные числа, и дополнительные типы данных - строки символов переменной длины, денежные единицы, дата и время, логические данные (два значения - "ИСТИНА" и "ЛОЖЬ"). В языке SQL можно использовать числовые, строковые, символьные константы и константы типа "дата" и "время".
Название и Количество, которые взяты из исходной таблицы Деталь. По сути, этот запрос позволяет получить вертикальную проекцию исходной таблицы (более строго, вертикальное подмножество множества строк таблицы). Из всех строк таблицы Деталь образуются строки, которые включают значения, взятые из двух столбцов - Название и Количество.
Запрос "какие детали, изготовленные из стали, хранятся на складе?", сформулированный на языке SQL, выглядит так:
SELECT *
FROM Деталь
WHERE Материал = "Сталь";
Завершая обсуждение языка SQL, еще раз подчеркнем, что это - язык запросов. На нем нельзя написать сколько-нибудь сложную прикладную программу, которая работает с базой данных. Для этой цели в современных СУБД используется язык четвертого поколения (Forth Generation Language - 4GL), обладающий как основными возможностями процедурных языков третьего поколения (3GL), таких как СИ, Паскаль, Ада, так и возможностью встроить в текст программы операторы SQL, и средствами управления интерфейсом пользователя (меню, формами, вводом пользователя и т.д.). Сегодня язык 4GL - это один из фактических стандартов средств разработки приложений, работающих с базами данных.
7.2.Что есть СУБД в целом - функции и структура
Поддержание логически согласованного набора файлов; обеспечение языка манипулирования данными; восстановление информации после разного рода сбоев; реально параллельная работа нескольких пользователей. Можно считать, что если прикладная информационная система опирается на некоторую систему управления данными, обладающую этими свойствами, то эта данными является системой управления базами данных (СУБД). Тем не менее, на наш взгляд, полезно сформулировать эти (и другие) важные функции отдельно.
7.2.1.5.1 Основные функции СУБД
К числу функций СУБД (с пользой для пользователей систем) принято относить следующее:
Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения непосредственных данных, входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы).
Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно превышает доступный объем оперативной памяти. Понятно, если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Единственным же способом реального увеличения этой скорости является буферизация данных в оперативной памяти. И даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов. При управлении буферами основной памяти приходится разрабатывать и применять согласованные алгоритмы буферизации, журнализации и синхронизации. З
Управление транзакциями
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные ею, во внешней памяти, либо ни одно из этих изменений никак не отражается в состоянии БД.
Журнализация
Одно из основных требований к СУБД - надежное хранение данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая особо тщательно (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД.
Языки БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). В нескольких лекциях этого курса язык SQL будет рассматриваться достаточно подробно, а пока мы перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т.е. функции, поддерживаемые при реализации интерфейса SQL).
7.2.2.Типовая организация современной СУБД
Естественно, организация типичной СУБД и состав ее компонентов соответствует рассмотренному нами набору функций. Напомним, что мы выделили следующие основные функции СУБД:
- управление данными во внешней памяти;
- управление буферами оперативной памяти;
- управление транзакциями;
- журнализация и восстановление БД после сбоев;
- поддержание языков БД.
Логически в современной реляционной СУБД можно выделить наиболее внутреннюю часть - ядро СУБД (часто его называют Data Base Engine), компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит. В некоторых системах эти части выделяются явно, в других - нет, но логически такое разделение можно провести во всех СУБД.
Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и журнализацию. Ядро СУБД является основной резидентной частью СУБД. При использовании архитектуры "клиент-сервер" ядро является основным составляющим серверной части системы.
Основная функция компилятора языка БД - компиляция операторов языка БД в некоторую выполняемую программу.
Основной проблемой реляционных СУБД является то, что языки этих систем (а это, как правило, SQL) являются непроцедурными, т.е. в операторе такого языка специфицируется некоторое действие над БД, но эта спецификация не процедура, она лишь описывает в некоторой форме условия совершения желаемого действия. Поэтому компилятор должен решить, каким образом выполнять оператор языка, прежде чем произвести программу. Применяются достаточно сложные методы оптимизации операторов. Результатом компиляции является выполняемая программа, представляемая в некоторых системах в машинных кодах, но более часто в выполняемом внутреннем машинно-независимом коде. В последнем случае реальное выполнение оператора производится с привлечением подсистемы поддержки времени выполнения, представляющей собой, по сути дела, интерпретатор этого внутреннего языка.
Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно выполнять с использованием языка БД, например, загрузка и разгрузка БД, сбор статистики, глобальная проверка целостности БД и т.д. Утилиты программируются с использованием интерфейса ядра СУБД, а иногда даже с проникновением внутрь ядра.
7.3.Ранние средства управления базами данных
Остановимся коротко на ранних (дореляционных) СУБД. В этом есть смысл по трем причинам: во-первых, эти системы исторически предшествовали реляционным и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь об их предшественниках; во-вторых, внутренность реляционных систем во многом основана на использовании методов ранних систем; в-третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Мы ограничиваемся рассмотрением только общих подходов к организации трех типов ранних систем, а именно, систем, основанных на инвертированных списках, иерархических и сетевых систем управления базами данных.
Начнем с наиболее общих характеристик ранних систем:
a) Эти системы активно использовались в течение многих лет, дольше, чем какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование их совместно с современными системами.
b) Все ранние системы не основывались на каких-либо абстрактных моделях. Понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем.
c) В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
e) Навигационная природа ранних систем и доступ к данным на уровне записей заставляли производить всю оптимизацию доступа к БД самого пользователя, без какой-либо поддержки системы.
f) После появления реляционных систем большинство ранних систем было оснащено "реляционными" интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме.
7.3.1.Основные особенности систем, основанных на инвертированных списках.
К числу наиболее известных и типичных представителей таких систем относятся Datacom/DB, ориентированная на использование на машинах основного класса фирмы IBM, и Adabas компании Software AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам). Кстати, когда мы будем рассматривать внутренние интерфейсы реляционных СУБД, вы увидите, что они очень близки к пользовательским интерфейсам систем, основанных на инвертированных списках.
Структуры данных
База данных, организованная с помощью инвертированных списков, похожа на реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям. При этом:
a) Строки таблиц упорядочены системой в некоторой физической последовательности.
b) Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB).
c) Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
Манипулирование данными
Поддерживаются два класса операторов:
a) Операторы, устанавливающие адрес записи, среди которых:
- прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа);
- операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа.
b) Операторы над адресуемыми записями.
7.3.2.Иерархические системы
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом как на новую технологию БД, так и на новую технику.
Иерархические структуры данных
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи.
Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
- Найти указанное дерево БД (например, отдел 310);
- Перейти от одного дерева к другому;
- Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
- Перейти от одной записи к другой в порядке обхода иерархии;
- Вставить новую запись в указанную позицию;
- Удалить текущую запись.
7.3.3.Сетевые системы
Типичным представителем является Integrated Database Management System (IDMS), предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем.
Сетевые структуры данных
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Сетевая БД состоит из набора записей и набора связей между ними, а если говорить более точно: из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи.
Тип связи определяется для двух типов записи: предка и потомка.
Манипулирование данными
Примерный набор операций может быть таковым:
- Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
- Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
- Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
- Перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
- Создать новую запись;
- Уничтожить запись;
- Модифицировать запись;
- Включить в связь;
- Исключить из связи;
- Переставить в другую связь и т.д.
7.3.4.Достоинства и недостатки
Достоинства ранних СУБД:
- Развитые средства управления данными во внешней памяти на низком уровне;
- Возможность построения вручную эффективных прикладных систем;
- Возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Недостатки:
- Слишком сложно пользоваться;
- Фактически необходимы знания о физической организации;
- Прикладные системы зависят от этой организации;
- Их логика перегружена деталями организации доступа к БД.
7.4.Реляционные СУБД
Концепция реляционной базы данных впервые выдвинута в 50-е годы, но первые реализации появились в 70-х, а широкую популярность эта модель завоевала только в 80-х. СУБД реляционного типа освобождает пользователей от всех ограничений, связанных с организацией хранения данных и спецификацией аппаратуры. Изменение физической структуры базы данных не влияет на работоспособность прикладных программ, работающих с нею.
Эти СУБД автоматически выполняют такие системные функции как: восстановление после сбоя и одновременный доступ нескольких пользователей к разделяемым данным. Преимущества реляционной базы данных заключаются в следующем:
- В распоряжение пользователя предоставляется простая структура данных – они рассматриваются как таблицы.
- Пользователь может не знать, каким образом его данные структурированы в базе – это обеспечивает независимость данных.
- Возможно использование простых непроцедурных языков запросов.
Но у реляционной базы данных есть один недостаток: организовать работу с такой СУБД достаточно сложно, поскольку не существует способов быстрого доступа к данным. Эта проблема решается заданием вспомогательных путей, поскольку традиционно в реляционной модели пути доступа к данным заранее не определяются и при обработке запросов приходится просматривать практически всю базу. В современных СУБД допускается задание вспомогательных описаний путей доступа.
В реляционных БД имеется механизм блокировки, предотвращающий переход системы в противоречивое состояние в результате одновременного доступа двух и более запросов к одному и тому же элементу данных.
Пользователь реляционной базы данных может:
- заносить в базу новые данные
- создавать и уничтожать таблицы
- добавлять строки и столбцы к ранее создаваемым таблицам
- создавать и уничтожать индексы
- определять и отменять представления хранимых данных
- изменять привилегии различных пользователей.
Способ описания и представления данных пользователю, принятый в реляционных системах, радикально отличается от принятых в иерархических и сетевых системах. Манипулирование данными осуществляется при помощи операций, порождающих таблицы. Комбинируя таблицы, выбирая отдельные столбцы и строки, пользователь может одной операцией сформировать новые таблицы для отображения на экране терминала, для дальнейшей обработки.
7.5.Компоненты СУБД. Командный язык
7.6.Интерпретаторы и компиляторы
7.7.СУБД, применяемые в ГИС
В ГИС применяются разные подходы к использованию СУБД: часть ГИС реализуют собственные встроенные СУБД, другие используют готовые системы, такие как PARADOX, dBase и др., третье применяют смешанный способ – внутренние СУБД, пока общий объем баз не превысит определенной величины, и СУБД, предназначенные для больших объемов данных (обычно ORACLE), если информации очень много.
В таких реляционных СУБД файл БД состоит из записей, а запись – из совокупности полей.
Записью называют компьютерный аналог информации, содержащейся, например, на библиотечной карточке или бланке. Совокупность записей является простой базой данных.
Полем называется графа такой карточки или бланка, в которой записывается единица информации. Поле имеет имя и содержание. В компьютере такие записи запоминаются в виде таблиц, где запись представляет из себя строку, а поле – столбец. Каждая запись в таблице пронумерована.
Несколько баз данных может содержать общую информацию. (Например, одна база данных содержит информацию о фамилии, имени, адресе, а другая о доходах). При этом общая информация записывается только один раз (фамилия), однако одновременно можно узнать о содержимом другой базы. Данные из них связываются через общие поля.
Связи записей в основном относятся к трем типам: одной записи соответствует одна запись, одной записи соответствуют несколько, нескольким соответствуют несколько. Примером однозначного соответствия может служить, например, название учреждения и его адрес. Ко второму типу связи можно отнести студента и список предметов, изученных во время обучения. К третьему типу относятся записи, связанные с перекрестными ссылками.
7.7.1.Стандартные форматы
В ГИС системе должны быть средства, позволяющие перевести данные из одного стандартного формата БД или считать тематическую информацию из популярных баз. К числу таких форматов принадлежит: DBF, SQL, INREGS, SYBASE, MIMER, RDB и др. Практически все зарубежные ГИС обладают такими средствами.
7.7.2.Поиск в базе данных
Любая база данных обладает возможностями поиска. Его быстрота зависит от организации данных. Поиск в базе осуществляется при помощи запросов, которые производят задавая параметры или группу параметров поиска. Например, найти все города с численностью населения больше 500 тыс. В запросе может присутствовать целое арифметическое выражение, которое составляется по маске или вручную. Результаты обработки запроса могут быть отображены на экране, отправлены в файл или стать основой для составления отчета.
7.8.Реляционные операции связывания и соединения
Изложенная выше концепция приложима не только к связыванию объектов и их атрибутов. Любые две таблицы, имеющие общий атрибут, могут быть соединены. Операция relate использует общий атрибут для установления временной связи между соответствующими записями в обеих таблицах. При связывании каждая запись одной таблицы соединяется с той строкой другой таблицы, которая имеет такое же значение общего атрибута. Связывание временно расширяет таблицу атрибутов объектов, как бы добавляя атрибуты, которые на самом деле не хранятся в таблице, например
| № | собственник |
| 34 | Иванов |
| 35 | Петров |
| 36 | Сидоров |
| № | Площадь | зона |
| 34 | 12 | К1 |
| 35 | 15 | М2 |
| 36 | 22 | Л2 |
При связывании таблицы соединяются временно, а при операции реляционного соединения таблицы связываются и сливаются по общему атрибуту.
| № | Собственник | Зона | Площадь |
| 34 | Иванов | К1 | 12 |
| 35 | Петров | М2 | 15 |
| 36 | Сидоров | Л2 | 22 |
В ARC/INFO файлы данных, содержащих описательные атрибуты могут быть связаны или соединены с таблицей атрибутов объектов. При использовании связывания связанные файлы могут поддерживаться и обновляться порознь. Например, записи в файлах налоговой инспекции могут быть связаны с картой участков, содержащей уникальные номера участков, общие для всех файлов.
Связывание и соединение – это концептуально простые, но часто используемые фундаментальные операции ГИС. Например, при выполнении пространственного наложения каждый вновь получаемый объект имеет атрибуты обоих исходных наборов объектов. В сущности наложение полигонов – это пространственное соединение. В этом случае соответствие записей в таблице основывается не на общем атрибуте таблиц, а на положении связанных с ними географических объектов.

участки типы землепользования

Объединенная карта
| ID | зоны |
| 101 | res |
| 102 | res |
| 103 | res |
| 104 | com |
| 105 | ind |
| 106 | com |
| ID | Землепользование |
| 10 | res |
| 11 | com |
| 12 | ind |
| ID | Зоны | Землепользование |
| 1 | res | res |
| 2 | res | res |
| 3 | res | com |
| 4 | com | com |
| 5 | ind | ind |
| 6 | com | ind |
Слой участков с атрибутом зонирования, объединяется со слоем землепользования. Создается новая таблица, содержащая атрибуты обоих слоев, которая отчетливо выявляет различия между принадлежностью каждого участка к какой-либо зоне и фактическим типом землепользования.
При выводе карты ее объекты могут отображаться с помощью условных обозначений, содержащихся в связанном файле. Например, типы землепользования могут быть классифицированы как жилая застройка, коммерческое и промышленное, причем в связанной таблице каждому типу поставлен в соответствие номер штриховки. При выводе карты закраска каждого полигона землепользования выполняется штриховкой, соответствующей этому типу.
При использовании такого типа связи (называемого в теории СУБД многие-к-одному) несколько записей одной таблицы могут быть связаны с одной строкой другой таблицы, что экономит объем памяти для хранения данных.
- Если отношения один-к-одному (объект имеет один и только один адрес и адрес принадлежит одному и только одному объекту), тогда один или оба объекта могут нести внешний ключ
- Если отношения один-ко-многим (переписной район содержит много блоков, но блок может принадлежать одному и только одному переписному району), тогда объект, который участвует только однажды будет нести внешний ключ
- Если отношения многих-ко-многим (объект может иметь много собственников, а собственник может обладать несколькими объектами), тогда требуется новая таблица перекрестных ссылок.
7.9.Стадии ввода атрибутивных данных
7.9.1.Создание нового файла данных для хранения атрибутов
Информация об атрибутах хранится в табличном файле базы данных, названном таблицей атрибутов объектов. Для каждого географического объекта (точки, дуги или полигона) имеется отдельная запись в этом файле. В каждом записи имеется несколько видов информации (атрибутов, полей) объекта.
Таблица атрибутов объекта – это файл данных, содержащий некоторые заранее определенные стандартные характеристики объектов. ГИС создает и поддерживает связи между записями в таблице атрибутов объектов и объектами на карте.
Чтобы добавить дополнительные атрибуты в эту таблицу, нужно сначала создать другой файл данных для хранения значений новых атрибутов. Вам необходимо определить, какие там будут атрибуты объектов, и создать файл данных перед тем, как добавлять значения атрибутов.
| LN | LUCODE |
| | |
| | |
7.9.2.Добавление значений атрибутов во вновь созданный файл
Если значения атрибутов, которые вы вводите, представлены в виде списка на бумаге, можно ввести их прямо в файл данных на компьютере. Если значения атрибутов уже есть в файле компьютера, можно поместить их в файл данных без повторного набора.
| ln | LUCODE |
| 59 | 400 |
| 60 | 200 |
| 61 | 400 |
| 62 | 200 |
Проект
7.9.3.Связывание или соединение атрибутов с таблицей атрибутов объектов
Когда значения атрибутов добавлены в файл данных, можно присоединить их к таблице атрибутов объектов покрытия, используя общий атрибут объекта как ключ. Так как записи таблицы атрибутов могут быть связаны с соответствующими записями нового файла данных, новые атрибуты будут также связаны с объектами. Таким образом, можно запрашивать и анализировать данные, создавать карты, используя значения атрибутов из таблицы атрибутов.
Контрольные вопросы
- Что такое база данных?
- Что такое реляционная база данных
- Особенности связывания таблиц в ГИС базе данных