
Удмуртский Государственный Университет реферат
| Вид материала | Реферат |
- «Удмуртский государственный университет», 302.5kb.
- Удмуртский Государственный Университет реферат, 203.39kb.
- Удмуртский Государственный Университет (наименование учебного заведения) Кафедра Информационной, 225.78kb.
- Удмуртский Государственный Университет Институт экономики и управления Кафедра финансов, 1976.72kb.
- Фгбоу впо «Удмуртский государственный университет», 68.29kb.
- Контрольная работа экз вопросы фгбоу впо «удмуртский государственный университет», 1136.39kb.
- Удмуртский государственный университет, 70.06kb.
- 57. Шквырина Анжелика Вячеславовна заявка на участие в I международном симпозиуме, 30.69kb.
- Субъективные основания социальной реальности: пространство смысла 09. 00. 11. социальная, 219.67kb.
- Представления об обществе в картине мира населения древней руси XI xiii вв. 07. 00., 653.67kb.
Министерство образования РФ
Удмуртский Государственный Университет
Реферат:
Настройка приложений под Oracle.
Оптимизация запросов Oracle.
Выполнил: студент гр.38-41
Сергеев А.С.
Проверил: Вотинцев А.А.
Ижевск - 2003
Введение
Понятие настройки производительности приложения (application tuning) относится к настройке используемых в приложении SQL-команд. Если приложение обладает графическим интерфейсом пользователя, то настройка приложения заключается также в настройке аналогов SQL-команд. Иначе говоря, все действия, выполняемые на уровне графического интерфейса пользователя, могут быть отображены на соответствующие SQL-команды (SELECT, INSERT, UPDATE и DELETE) различной сложности. В любом случае рекомендуется сначала настроить используемое приложение, а затем приступить к настройке остальных компонентов СУРБД.
По разным субъективным оценкам общая производительность системы в среднем на 80% зависит от приложения, а остальные 20% приходятся на собственно базу данных. Однако следует отметить, что такое распределение ответственности за производительность системы соблюдается не всегда. Иногда, все может быть как раз наоборот — основное влияние на производительность СУРБД могут оказывать не приложения, а базы данных.
Для администратора баз данных это означает, что производительность СУРБД зависит от конкретной ситуации и является величиной относительной. Несмотря на эти замечания, все же нужно еще раз подчеркнуть основное правило, которого следует придерживаться при выполнении настройки:
Прежде всего, необходимо настроить приложение. Необходимость выполнения этого условия определяется двумя причинами. Во-первых, производительность большинства современных СУРБД во многом определяется производительностью используемых приложений. Во-вторых, даже если это не так, администратор базы данных может классифицировать тип приложения, используемого для конкретной СУРБД. Это значит, что администратор должен просмотреть приложение и выделить в нем все, что касается транзакций: код доступа и SQL-код. Даже если код приложения является достаточно эффективным с точки зрения доступа к базам данных, этот анализ поможет глубже разобраться в используемых методах взаимодействия программы с базами данных.
Необходимо сосредоточить основное внимание на тех 20% текста программы, которые ответственны за 80% производительности всего приложения. А затем, если будет время и позволит руководство, можно приступить к работе над остальной частью приложения и попытаться извлечь из него максимум возможного.
Оптимизатор
Оптимизатор представляет собой программный продукт, который является частью СУРБД и предназначен для оптимизации — поиска наиболее эффективного способа доступа SQL-кода к данным. Для оптимизатора следует выбрать такую последовательность доступа, которая обеспечит самый эффективный в рамках СУРБД Oracle путь доступа к данным и формирование плана выполнения, основанного на найденных методах. Под методом доступа (access path) в нашем случае подразумевается вариант алгоритма доступа к затребованным из базы данным, а под планом выполнения (execution plan) — последовательность выполняемых действий, которые сопровождают выбранные методы доступа.
Технология оптимизатора Oracle, а также технологии, используемые для оптимизаторов другими разработчиками программного обеспечения, значительно развились за несколько последних лет. При работе с ранними версиями Oracle программисту приходилось быть очень внимательным при разработке SQL-кода, поскольку упорядочение операторов внутри SQL-выражения могло в значительной степени повлиять на его производительность. Аналогичную работу по оптимизации приходилось выполнять и администратору базы данных. Однако, чем лучше используемый оптимизатор, тем меньше оптимизирующих действий приходится выполнять пользователям, программистам и администратору базы данных; соответственно необходимая работа по оптимизации в OracleSi по сравнению с предыдущими версиями существенно уменьшилась. Тем не менее даже при наличии широкого круга современных оптимизаторов программистам следует знать основные принципы оптимизации и при необходимости уметь их применять. Однако современным программистам уже не нужно иметь те глубокие знания, которые были необходимы ранее для выполнения оптимизации вручную...
Существует два основных вида оптимизаторов.
• Оптимизатор, основанный на анализе заданных правил (rule-based optimizer). Этот оптимизатор выбирает методы доступа на основе предположения о статичности СУРБД и в соответствии с заданной разработчиком системой правил выбора методов доступа к данным. Хотя приоритеты разных правил зависят от самого разработчика, их можно довольно легко сравнить и найти соответствие между результатами, полученными с помощью разных оптимизаторов.
• Оптимизатор, основанный на анализе затрат (cost-based optimizer). Для этого оптимизатора выбор метода доступа основан на хранимой внутренней статистике, которая обычно используется совместно со словарем данных СУРБД. Администратор базы данных должен время от времени выполнять специальные процедуры обновления этих статистических данных.
В Oracle версий 7.х и выше оптимизаторы могут работать по принципу анализа, как правил, так и затрат одновременно. В Oracle б.х работа оптимизатора основана на анализе правил, и в полной мере реализовать технологию анализа затрат он не может. Во всех этих версиях для управления оптимизатором, программисту предоставляется возможность использовать специализированные указания (hint), которые размещаются непосредственно в строках кода SQL-выражения. Они принимаются во внимание оптимизатором, хотя и не всегда выполняются, поскольку носят рекомендательный характер. При отсутствии синтаксических ошибок оптимизатор обычно следует полученному указанию. Приведем пример выражения SELECT, содержащего указание оптимизатору об использовании индекса для таблицы, из которой извлекаются данные.
SQL> SELECT /*+ INDEX ПРОД_ПК*/ ИД FROM ПРОДАВЦЫ WHERE ИД =110; (1)
Заметим то, что указание следует сразу же после SQL-команды (SELECT, INSERT, UPDATE, DELETE). Указание для оптимизатора, как и любой другой комментарий SQL*Plus, начинается с символов /*, за которыми следует знак +, и заканчивается символами */. В данном примере предполагается, что для указанной таблицы существует только один индекс (первичный ключ); для задания конкретного индекса из нескольких имеющихся в указании следует использовать имя таблицы и имя нужного индекса.(SQL> SELECT /*+ INDEX ОФИС*/ ОФИС_КОД FROM ПРОДАВЦЫ WHERE ОФИС_КОД =И01;)
Оптимизатор воспринимает только одно указание для данного выражения или блока выражений; все остальные будут проигнорированы. Кроме того, все указания с неверным синтаксисом также игнорируются без вывода какого-либо сообщения об ошибке. Чтобы выявить факт игнорирования указания оптимизатором, необходимо воспользоваться планом выполнения, который более подробно описывается ниже
Ранжирование методов доступа
Оптимизатор Oracle при работе использует приведенные в таблице 1 ранги методов доступа – от самого быстрого в верхней части до самого медленного в нижней части этого перечня.
Таблица 1
Ранги | Метод доступа |
| 1 | Одна строка по ее идентификатору |
| 2 | Одна строка по объединению кластеров |
| 3 | Одна строка по хэш-ключу кластера с уникальным или первичным ключом |
| 4 | Одна строка по уникальному или первичному ключу |
| 5 | Объединение кластеров |
| 6 | Кэш-ключ кластера |
| 7 | Индекс кластера |
| 8 | Составной индекс |
| 9 | Индекс на основе одного столбца |
| 10 | Ограниченный диапазон поиска по индексированным столбцам |
| 11 | Неограниченный диапазон поиска по индексированным столбцам |
| 12 | Объединение с сортировкой и слиянием |
| 13 | Поиск максимального или минимального значения по индексированным столбцам |
| 14 | Упорядочение по индексированным столбцам |
| 15 | Полное сканирование таблицы |
Таким образом, если оптимизатор основан на анализе правил, то он будет выбирать из всех доступных для данного запроса методов самый быстрый. Покажем тот же запрос, который был приведен ранее, но без указания для оптимизатора и с изменением оператора WHERE. (Запрос с неограниченным диапазоном поиска без)
SQL> SELECT ИД FROM ПРОДАВЦЫ WHERE ИД >=110; (2)
При использовании в Oracle стратегии, основанной на анализе правил, и наличии первичного ключа поля ИД таблицы ПРОДАВЦЫ, для оптимизации кода в (1) будет применен метод доступа 11 (неограниченный диапазон поиска по индексированным столбцам). Неограниченный диапазон поиска проявляется в том случае, если в операторе WHERE использован один из операторов сравнения, за исключением проверки равенства (неравенства) — "больше" (>), "больше или равно" (>=), "меньше" (<) и "меньше или равно" (<=). В результате диапазон поиска ограничивается только с одной стороны— сверху или снизу. Вторая граница диапазона поиска до начала выполнения запроса неизвестна.
Если оператор WHERE содержит ограниченный диапазон поиска (т.е. содержит два условных оператора — по одному с каждой границы диапазона), то обе границы диапазона будут известны еще во время синтаксического анализа выражения. Превратить неограниченное WHERE в ограниченное можно и с помощью литерала максимального значения (если оно известно) или с помощью предполагаемого (теоретического) максимального значения для столбца, исходя из априорных знаний о данных в столбце. Однако использование оператора МАХ (оператора определения максимального значения) наряду с исходным неограниченным диапазоном поиска крайне нежелательно, так как в табл. 1 ранг этого метода поиска (13) ниже ранга неограниченного (11) и ограниченного (10) диапазонов поиска. Использование оператора МАХ для поиска максимального значения приведет только к замедлению выполнения запроса.
SQL> SELECT ИД FROM ПРОДАВЦЫ WHERE ИД >=103 and ИД <=110; (3)
5QL> SELECT ИД FROM ПРОДАВЦЫ WHERE ИД >103 AND ИД <=MAX(ИД);
Анализ запросов с целью повышения скорости их выполнения
Вся работа, связанная с попытками изменения формулировки запросов для повышения эффективности их выполнения, называется коррекцией запросов (query rewriting). Приведенные примеры являются достаточно стандартными, и с их помощью можно понять основные принципы оптимизации. Например, для извлечения максимального значения из столбца потребуется время, сравнимое со временем полного сканирования таблицы — независимо от того, индексирован ли этот столбец. Это становится ясным при ознакомлении с таблицей рангов методов доступа. Однако существуют менее очевидные и более экзотические способы коррекции запросов. Теперь, после знакомства с работой оптимизатора на основе анализа правил, можно приступить к рассмотрению работы оптимизатора, основанного на анализе затрат, на примерах, показанных далее:
SQL> SELECT ИД FROM ПРОДАВЦЫ WHERE ДОЛЖНОСТЬ='МЕНЕДЖЕР'', (4)
SQL> SELECT ИД FROM ПРОДАВЦЫ WHERE ДОЛЖНОСТЬ=' ПРОДАВЕЦ '', (5)
Допустим, что приведенные запросы созданы для достаточно большой торговой организации с 10 менеджерами, 1000 продавцов и общим числом сотрудников — около 6000. Анализируя эти запросы, можно заключить, что из двух типов оптимизации лучше выбрать оптимизацию, основанную на анализе затрат, а не оптимизацию, основанную на анализе правил. Действительно, если применяется оптимизация, основанная на анализе правил, то при наличии неуникального индекса по столбцу ДОЛЖНОСТЬ для обоих запросов будет выбран метод доступа 9 (индекс на основе одного столбца). С другой стороны, при использовании оптимизации, основанной на анализе затрат, знание некоторых характеристик распределения данных (например, того, что строки с данными о продавцах составляют 1/6 всех строк, а строки с данными о менеджерах составляют 1/600 часть всех строк) позволяет применять неуникальный индекс для запроса в (4). Однако для выполнения запроса в (5) будет уместно и эффективно полное сканирование таблицы (т.е. использование метода доступа 15). Таким образом, выбор вариантов методов доступа базируется на априорной информации о конкретной структуре данных.
При необходимости доступа к значительной части строк какой-либо таблицы полное сканирование является более эффективным, чем индексное. Дело в том, что для сканирования индекса и извлечения строки требуются, по крайней мере, две операции чтения для каждой строки, а в некоторых случаях и больше — в зависимости от количества уникальных данных в индексе. А при полном сканировании таблицы для извлечения строки требуется только одна операция чтения. При доступе к большому количеству строк — как, например, в запросе (5) — становится очевидной неэффективность использования индекса по сравнению с полным сканированием таблицы, при котором строки считываются непосредственно из таблицы. Помимо уменьшения общего количества операций чтения записей таблицы, полное сканирование при определенных обстоятельствах обладает еще одним преимуществом по сравнению с индексным сканированием. Дело в том, что большое количество строк таблицы часто требуется извлекать последовательно или в порядке, близком к последовательному. Очевидно, что если считывается индекс, потом таблица, потом опять индекс, а потом опять таблица, последовательный порядок извлечения данных соблюдаться не будет. Таким образом, для запроса, показанного в (5), использование индекса только замедлит выполнение.
Использование индекса гораздо предпочтительнее полного сканирования таблицы при работе с запросом, показанным в (4). В этом случае потребуется извлечь незначительное количество строк (10), а общее количество операций чтения будет равняться 20 ( т.е. по 2 операции чтения для извлечения каждой из 10 строк). При использовании полного сканирования таблицы придется выполнить
6000 операций чтения, поскольку при этом неизвестно точное расположение искомых строк и для их поиска придется просмотреть всю таблицу. Запрос, приведенный в (4), является классическим примером случая, когда необходимо использовать индекс, особенно если такой запрос выполняется часто. Из этого сравнительного анализа можно сделать следующий вывод. Пользователь и программист, которые привыкли применять оптимизацию только на основе анализа правил, могут даже не догадываться о существовании более эффективного способа выполнения запроса (5), выбор которого основан на оптимизации согласно анализу затрат.
Задание режима оптимизации
Одним из важнейших вопросов при работе с оптимизатором является способ выбора режима его работы. Дело в том, что описанные выше виды оптимизации могут быть заданы на уровне экземпляра, сеанса или выражения. Для указания режима оптимизации на уровне экземпляра в файле параметров init.ora следует использовать приведенные ниже значения параметра OPTIMIZER_MODE.
• CHOOSE. При установке этого значения будет выбрана оптимизация, основанная на анализе затрат, при наличии у администратора базы данных соответствующих статистических данных. В противном случае будет использована оптимизация, основанная на анализе правил.
• RULE. При установке этого значения будет использована оптимизация, основанная на анализе правил.
• FIRST ROWS. Это значение используется для минимизации времени отклика, т.е. для сведения к минимуму временного интервала между вводом запроса в СУРБД и появлением результатов на экране. При этом будет выбран вариант оптимизации, основанный на анализе затрат (при наличии соответствующих статистических данных). Это значение следует использовать только в интерактивном приложении с множеством экранных форм вывода информации. Типичный пример— OLTP-системы и некоторые DSS-системы.
• ALL ROWS. При установке этого значения будет использована оптимизация, основанная на анализе затрат (опять же, при наличии соответствующих статистических данных) для минимизации общего количества строк, проходящих через систему за единицу времени (в транзакциях за секунду). Это значение следует использовать при работе с системами пакетной обработки или большими DSS-системами.
Для указания режима оптимизации на уровне сеанса следует применить показанное ниже DDL-выражение, в котором для параметра режим задается одно из приведенных выше значений (CHOOSE, RULE, FIRST_ROWS, ALL_ROWS):
SQL> ALTER SESSION SET OPTIMIZER_GOAL=<;>
Однако заданный таким образом режим оптимизации будет использоваться только при работе в данном сеансе, а при работе в другом сеансе его следует указать вновь.
Для задания режима оптимизации на уровне выражения следует использовать перечисленные в табл. 2 ключевые слова методов доступа либо использовать одно из приведенных выше значений (CHOOSE0 RULE, FIRST ROWS,ALL ROWS).
Таблица 2
| Ключевое слово | Метод извлечения строк метода доступа |
| ROWID | Для извлечения строк используется их идентификатор |
| CLUSTER | Сканирование ключа кластера |
| HASH | Сканирование хэш-индекса |
| INDEX | Сканирование индекса |
| INDEX_ASC | Сканирование индекса в порядке возрастания |
NDEX_DESC | Сканирование индекса в порядке убывания |
| AND_EQUAL | Использование нескольких индексов со слиянием результатов |
| ORDERED | Использование порядка таблиц, указанного в предложении FROM, в качестве порядка их объединения |
| USE_NL | Использование вложенных циклов для объединения таблиц USE_MERGE Использование сортировки со слиянием для объединения таблиц FULL Полное сканирование таблицы |
| | |
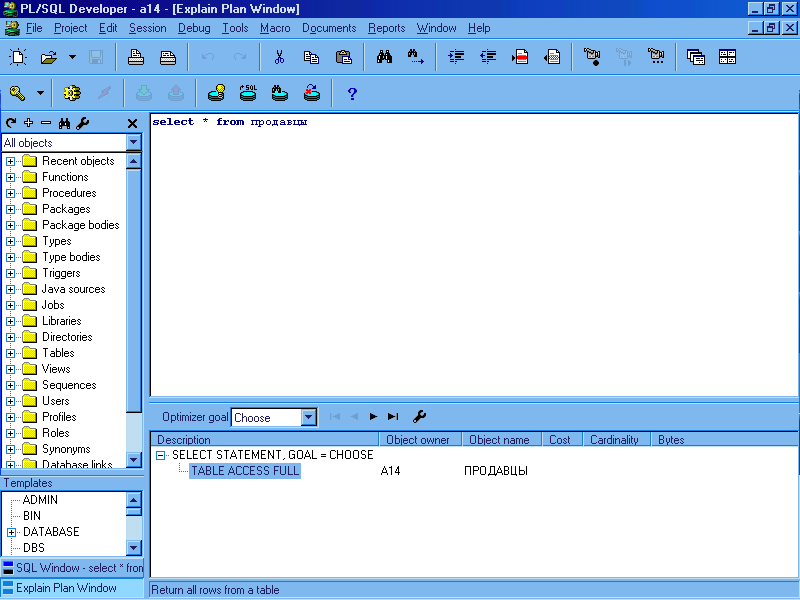
В Oracle есть средства позволяющие отслеживать метод выборки данных из таблицы, и режим работы оптимизатора (например Explain Plan в PL/SQL). Ниже на рисунке показано Explain Plan Window в котором видна распечатка запроса (select * from продавцы) и отображено следующее: режим оптимизации на уровне сеанса CHOOSE (также может быть RULE, FIRST_ROWS, ALL_ROWS), способ доступа к данным TABLE ACCESS FULL (полный доступ к таблице), а также название объекта и пользователь.
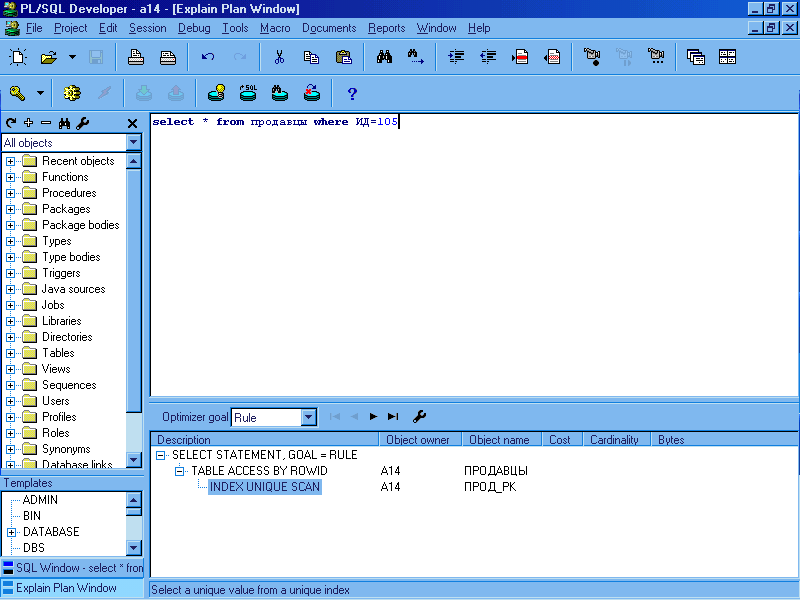
Ниже показан рисунок Explain Plan Window для запроса (select * from продавцы where ИД=105)
В данном случае: режим оптимизации на уровне сеанса RULE, способ доступа к данным TABLE ACCESS BY ROWID (доступ к таблице по идентификатору колонки), объект ПРОД_РК (идентификатор таблицы).
Заключение.
Таким образом использование оптимизатора в режиме анализа правил не всегда уместно, так как может привести к большим затратам по времени и ресурсам. При использовании оптимизатора следует сочетать и анализа правил и анализ затрат, а при необходимости вручную устанавливать наиболее подходящий для данного запроса режим работы оптимизатора.
Замечания:
- введение не проработано, взято без модификации, некоторые фразы введения не очень корректны
- недостаточно хорошо описаны hint, желательно более подробно описать каждый hint и привести примеры.
- Не очень последовательное изложение материала.
- Добавить больше примеров.
- Не описана настройка приложений?