
Удк система интеллектуального обхода web-сайтов
| Вид материала | Доклад |
- Конспект лекции «Основы Web-дизайна», 197.14kb.
- Учебно-методический комплекс дисциплины технологии создания корпоративных сайтов Специальность, 207.68kb.
- Прика з, 37.87kb.
- Современный web-дизайн, 106.2kb.
- Тематический план занятий по Web-Дизайну и оптимизации сайтов, 991.38kb.
- Лекция Использование программных средств для создания Web-сайтов Обзор программных, 172.93kb.
- «Создание и использование таблиц на Web-страницах», 223.42kb.
- Общие требования к web-сайту публикуемому в сети Интернет Практика создания web-сайтов, 38.62kb.
- Сценарий занятия «html-проектирование: Достопримечательности Мурманской области», 72.96kb.
- Новикова Елена Юрьевна, учитель информатики моу «фтл №1» пояснительная записка, 169.26kb.
УДК ---
СИСТЕМА ИНТЕЛЛЕКТУАЛЬНОГО ОБХОДА WEB-САЙТОВ
В.В. Муравьев1.
Доклад посвящен системе интеллектуального обхода web-сайтов. Разработан метод автоматического обнаружения web-форм, являющихся точками входа в «скрытый веб». Метод основан на классификации web-форм при помощи дерева решений. Предложена модификация стандартной схемы обхода сайтов с учетом метода. Представлена разработанная автором система обхода сайтов, работающая с применением описанного метода.
Введение
Постоянно возрастающее количество информации в сети Интернет, наряду с непрерывной эволюцией используемых технологий, привели к появлению большого числа способов доступа к данным в Интернет. Доступ к некоторым документам часто возможен только через web-формы (см. рис. 1), при этом на документы отсутствуют прямые ссылки. Следовательно, для их обхода поисковым роботом и последующей индексации не подходят стандартные алгоритмы. Часть сети Интернет, скрытая за web-формами и не доступная по прямым ссылкам, носит название «скрытый веб» (Hidden Web) [Raghavan и др., 2001] или «глубокий веб» (Deep Web) [Bergman, 2001].
Согласно исследованию [Lyman и др., 2003] Hidden Web содержит до 100 тысяч терабайт информации высокого качества. Следовательно, актуальным является разработка методов и программных средств для автоматического извлечения этой информации поисковым роботом.

Рисунок 1: Пример поисковой web-формы (www.auto.ru)
Частично решить задачу обхода Hidden Web позволяет протокол Sitemap [Sitemap]. Для каждого сайта можно явно указать список ссылок, которые поисковый робот должен обойти на сайте. Место расположения списка ссылок задается директивой Sitemap в файле robots.txt [Koster, 1996]. Тем не менее, протокол Sitemap позволит извлекать только те документы, на которые указал создатель сайта и не гарантирует полноты обхода сайтов. Полноту обхода может гарантировать только моделирование поведения пользователя через автоматическую отправку web-форм.
Задачу извлечения информации из Hidden Web можно разбить на две ключевые подзадачи. Первая задача состоит в автоматическом обнаружении точек входа в Hidden Web, через которые поисковый робот получает доступ к документам. Это необходимо в силу того, что многие web-формы предназначены для целей отличных от доступа к информации – для регистрации, авторизации, присоединения файла и т.д. В то время как для поискового робота представляют интерес только поисковые web-формы [Barbosa и др., 2005]. После того как точка входа в Hidden Web обнаружена, возникает вторая задача – извлечение через нее информации посредством различных поисковых запросов. Запросы могут создаваться поисковым роботом автоматически, или пользователем вручную для каждого сайта. Исследование на данную тему сделано в работе [Ntoulas и др., 2004].
В работе предложен метод решения первой задачи, основанный на классификации web-форм при помощи дерева решений. Дерево решений строится в процессе предварительного обучения с учителем по алгоритму C4.5. Web-формы, через которые невозможно извлечь информацию после классификации отбрасываются. Также автором разработаны архитектура и модифицированная схема работы поискового робота. Интеллектуальность поискового робота заключается в автоматической классификации web-форм по алгоритму С4.5 и обнаружении идентичных точек входа в Hidden Web.
- Метод автоматического обнаружения точек входа в Hidden Web
Для обнаружения точек входа в Hidden Web через web-формы предлагается производить их автоматическую классификацию – определять является ли web-форма поисковой или нет. Построение классификатора производится на основе тестового набора web-форм, предварительно классифицированных человеком. Свойства, на основании которых производится классификация, обусловлены особенностями HTML-разметки. Для построения классификатора в данной работе, по аналогии с работой [Barbosa и др., 2005], использовались следующие свойства:
- число скрытых полей ввода (тип hidden);
- число флажков (checkbox);
- число «радио»-кнопок (radio button)
- число полей для загрузки файла;
- число полей для загрузки изображения;
- число полей submit;
- число кнопок;
- число кнопок сброса (reset);
- число полей ввода пароля;
- число текстовых полей ввода;
- суммарный размер отправляемого текста;
- метод отправки web-формы (get или post);
- присутствие строки «поиск» или «search» внутри тега form.
Для классификации использовано дерево решений, из-за простоты его интерпретации и модифицикации в случае выявления новых закономерностей поисковых web-форм. Для построения классификатора используется алгоритм C4.5.
Во время проведения классификации, web-форма не только анализируется, но и отправляется. Получение ответа после отправки web-формы используется как дополнительное свойство для классификации.
На одном и том же или разных web-сайтах, могут существовать web-формы, которые запрашивают информацию из одной и той же базы данных. В связи с этим необходимо не только уметь идентифицировать точки входа в Hidden Web, но и определять идентичные. Это необходимо для того, чтобы избежать повторной работы по извлечению данных из одного источника. Предлагается для идентификации точек входа использовать следующий набор параметров:
- значение атрибута action тега form;
- набор полей web-формы (для каждого поля хранится тип, имя и значение).
После обнаружения поисковым роботом очередной web-формы, строится ее внутреннее представление, которое затем ищется в множестве уже идентифицированных точек входа в Hidden Web. Если внутреннее представление встречается впервые, оно добавляется в множество обнаруженных точек входа.
2. Компонентная модель и алгоритм работы поискового робота
На рис. 2 приведена компонентная модель поискового робота. Система состоит из 4 главных компонент: Crawling Manager, Frontier, Crawler, Learning System.
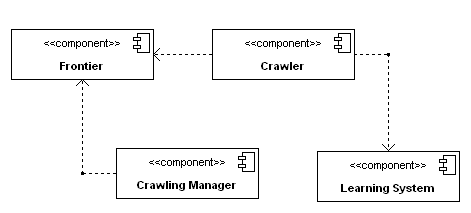
Рисунок 2: Компонентная модель поискового робота
Компонент Crawling Manager инициирует процесс обхода сайтов, помещая в Frontier список начальных URL. Frontier определяет порядок обхода web-страниц, выдавая по запросу компонента Crawler список URL на обход. Помимо этого Frontier хранит множество обнаруженных точек входа в Hidden Web. Learning System строит классификатор web-форм в виде дерева решений, описанного в первом разделе. Один или несколько компонентов Crawler выполняют основную работу по обходу сайтов и обработке web-форм. Crawler регулярно запрашивает список URL у Frontier и отдает во Frontier список новых ссылок и web-форм.
Поисковый робот поддерживает следующие возможности:
- обработка файла правил robots.txt;
- возможность задания максимальной глубины обхода web-сайта (максимальное число вложенных директорий);
- регулирование частоты обращений к web-сайту для избежания его перегрузки;
- обработка документов различных форматов (html, pdf, ps, doc, xls, ppt).
Работа поискового робота основана на концепции заданий на обход частей сети Интернет. Каждое задание определяется ограничением на область Интернет, частотой повторного обхода этой области, набором начальных URL и рядом других параметров. Поисковый робот может обрабатывать одновременно любое число заданий на обход.
Ниже приведен алгоритм работы поискового робота с учетом обработки web-форм.
- Построение классификатора web-форм при помощи компонента Learning System.
- Помещение списка начальных URL в Frontier.
- Запрос компонентом Crawler URL-адреса из Frontier.
- Скачивание документа по URL-адресу.
- Извлечение ссылок и web-форм из документа.
- Построение внутреннего представления web-формы.
- Классификация web-формы.
- Помещение новых ссылок и web-форм в Frontier. Если есть URL-адреса в Frontier, переход к шагу 3.
3. Результаты работ
Представленный в работе метод обнаружения точек входа в Hidden Web, реализован в разработанном авторе поисковом роботе. Использование метода вместе с одним из методов генерации запросов к поисковым web-формам достаточно для извлечения информации из Hidden Web и позволяет значительно повысить качество работы поисковой системы. Для конечного пользователя это отразится в повышении полноты и точности поиска.
Целями дальнейших исследований являются:
- Разработка метода автоматической генерации запросов к поисковым web-формам, позволяющих эффективно извлекать информацию.
- Экспериментальная проверка методов извлечения информации на большом сегменте сети Интернет.
Список литературы
[Raghavan и др., 2001] Raghavan S., Garcia-Molina H. Crawling the hidden web. // Proceedings of the Twenty-seventh International Conference on Very Large Databases, 2001.
[Bergman, 2001] Bergman M.K. The Deep Web: Surfacing Hidden Value. // The Journal of Electronic Publishing from the University of Michigan, 2001.
[Lyman и др., 2003] Lyman P., Varian H.R. How Much Information? // Technical Report. – UC Berkley, 2003.
[Barbosa и др., 2005] Barbosa L., Freire J. Searching for Hidden-Web Databases. // Eight International Workshop on the Web and Databases (WebDB), 2005.
[Ntoulas и др., 2004] Ntoulas A., Zerfos P., Cho J. Downloading Hidden Web Content. // Technical report. – UCLA, 2004.
[Koster, 1996] Koster M. A standard for robot exclusion. – 1996
[Sitemap] Sitemap protocol. [электронный ресурс] rg.
1 117312, Россия, Москва. Институт системного анализа РАН, muraviev@isa.ru