
И. М. Гонсалес Ортис. Конспект лекций по научному прогнозированию
| Вид материала | Конспект |
СодержаниеРис.1 Основные компоненты временного ряда Аддитивной моделью Yi и добавим к нему значения его «соседей» справа Y Аддитивная модель |
- И. М. Гонсалес Ортис. Конспект лекций по научному прогнозированию, 158.15kb.
- Конспект лекций 2010 г. Батычко Вл. Т. Муниципальное право. Конспект лекций. 2010, 2365.6kb.
- Конспект лекций 2008 г. Батычко В. Т. Административное право. Конспект лекций. 2008, 1389.57kb.
- Конспект лекций 2011 г. Батычко В. Т. Семейное право. Конспект лекций. 2011, 1718.16kb.
- Конспект лекций 2011 г. Батычко Вл. Т. Конституционное право зарубежных стран. Конспект, 2667.54kb.
- Конспект лекций 2010 г. Батычко В. Т. Уголовное право. Общая часть. Конспект лекций., 3144.81kb.
- Конспект лекций для студентов по специальностям 190302 «Вагоны», 783.17kb.
- Конспект лекций бурлачков в. К., д э. н., проф. Москва, 1213.67kb.
- Конспект лекций для студентов специальности 080504 Государственное и муниципальное, 962.37kb.
- Конспект лекций по курсу "Начертательная геометрия и инженерная графика" Кемерово 2002, 786.75kb.
И. М. Гонсалес – Ортис. Конспект лекций по научному прогнозированию. ISMA, Рига, 2010
Приемы прогнозирования
Любой прогноз основывается на переносе прошлых тенденций, выявленных в ходе анализа временного ряда, на будущее.
Период времени, для которого делается прогноз, называется горизонтом прогнозирования. Расстояние до него от текущего периода называется периодом упреждения.
Если период равен 1 ÷ 3 шагам в будущее, то говорят о краткосрочном прогнозе. При 4 ÷ 10 шагах прогноз называют среднесрочным. При более длинных периодах упреждения говорят о долгосрочных прогнозах.
Роль прогноза в экономике, в предпринимательской деятельности трудно переоценить. Объем производства, спрос, предложение, выручка, прибыль – все это требует прогноза.
В ходе прогнозирования приходится встречаться со следующим противоречием. Длинный исходный ряд позволяет хорошо погасить всякие случайные всплески и падения, но создает опасность переноса на будущее слишком старых закономерностей. Короткий ряд исключает такую опасность, но не избавляет от влияния случайностей. Прогноз не может считаться качественным, если на нем сказались случайности или очень старые закономерности.
Чтобы разрешить упомянутое противоречие, ищут компромисс между стремлением погасить случайности и не допустить переноса на будущее слишком старых закономерностей.
Известным выходом из такого затруднительного положения может служить применения для прогнозов так называемых адаптивных моделей. Их особенностью является то, что при каждом поступлении новой информации в параметры модели вносятся соответствующие коррективы. В результате этого модель постоянно адаптируется к новым условиям. При этом систематически проверяется близость ее расчетных данных к фактическим уровням ряда.
Самой сложной проблемой прогнозирования, до сих пор не имеющей удовлетворительного решения, является предсказание ломки тенденции, лежащей в основе прогнозных расчетов. Пока ломки нет, прогнозирование не представляет большого труда и дает минимальные ошибки. Когда же она происходит, то самые изощренные системы прогнозирования дают сбой и возникают большие ошибки. От этого не спасают никакие вычислительные программы, ибо все они хорошо работают только в условиях сохранения тенденций развития.
Анализ временного ряда: аддитивная и мультипликативная модели
Временной ряд (ряд динамики) – это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени.
Время, прошедшее от начального момента наблюдения до конечного, называют длиной временного ряда, а значения показателя в каждый конкретный момент времени - уровнями временного ряда.
Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно разделить на 3 группы:
факторы, формирующие тенденции ряда;
факторы, формирующие циклические колебания ряда;
случайные факторы.
Рассмотрим воздействие каждого фактора на временной ряд в отдельности.
Большинство временных рядов экономических показателей имеют тенденцию, характеризующую совокупное долговременное воздействие множества факторов на динамику изучаемого показателя. Все эти факторы, взятые в отдельности, могут оказывать разнонаправленное воздействие на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию. Если во временном ряду проявляется длительная тенденция изменения экономического показателя, то говорят, что имеет место тренд.
Также изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку экономическая деятельность ряда отраслей экономики зависит от времени года (например, цены на сельскохозяйственную продукцию в летний период выше, чем в зимний; уровень безработицы в курортных городах в зимний период выше по сравнению с летним). При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой конъюнктуры рынка.
Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень образуется как сумма среднего уровня ряда и некоторой (положительной или отрицательной) случайной компоненты.
На рисунке1 представлены все три фактора.

Рис.1 Основные компоненты временного ряда: а)- возрастающая тенденция;
б) – сезонная компонента; в) – случайная компонента.
Очевидно, что реальные данные не следуют целиком и полностью из каких-либо описанных выше моделей. Чаще всего они содержат все три компоненты. Каждый их уровень формируется под воздействием тенденции, сезонных колебаний и случайной компоненты.
Анализ временного ряда заключается в выделении отдельных компонент. Методика анализа зависит от того, какова связь между компонентами: аддитивная или мультипликативная.
Аддитивной моделью временного ряда называется такая модель, в которой изменение значений переменной во времени описывается через сложение отдельных компонент.
| Фактические значения уровня ряда | = | Трендовые значения | + | Сезонная компонента | + | Случайная компонента (ошибка) |
Y = T + S + E
Процедура анализа аддитивного временного ряда включает:
- расчет значений сезонной компоненты S;
- вычитание сезонной компоненты из фактических значений (десезонализация данных),
- т. е. Y – S;
- расчет тренда Т на основе десезонализированных данных;
- расчет ошибок как разностей между фактическими и трендовыми значениями
- E = Y – T;
- расчет ошибки аппроксимации – среднего отклонения, или MAD или среднеквадратичной ошибки MSE.
Для выделения сезонной компоненты производится устранение сезонных колебаний методом скользящей средней. На основе уровней временного ряда рассчитываются скользящие средние, которые освобождены от сезонных колебаний, но включают случайную компоненту.
Суть метода скользящего среднего − замена абсолютных данных средними арифметическими за определенные периоды. Расчет средних величин ведется способом скольжения, т.е. постепенным исключением из принятого периода скольжения первого уровня и включением следующего. Для метода скользящего среднего условно можно записать следующие процедуры:
− выполнить усреднение соседних наблюдений за определенный период (этот временной интервал принято называть «окном»), например, год;
− осуществить операцию скольжения, т.е. обеспечить переход к следующему среднему путем исключения из принятого «окна» первого уровня и включения следующего – получается, что выбранный интервал («окно») скользит вдоль ряда.
Найти скользящее среднее значение для поквартальных данных за определенный период времени можно следующим образом.
1. Начнем с текущего значения Yi и добавим к нему значения его «соседей» справа Yi+1 и слева Yi-1.
2. Прибавим затем половину значений следующих «соседей», т.е. получится
0,5 Yi+2 и 0,5 Yi-2 .
3. Имеющуюся сумму разделим на 4.
Такое взвешенное среднее нужно для того, чтобы интервал по обе стороны от базового периода времени был симметричным и вместе с тем охватывал в точности данные за один год. Взвешивая крайние точки коэффициентом 0,5, мы гарантируем, что этот квартал учтен в скользящем среднем точно так же, как и другие кварталы.
Следовательно, можно записать так:
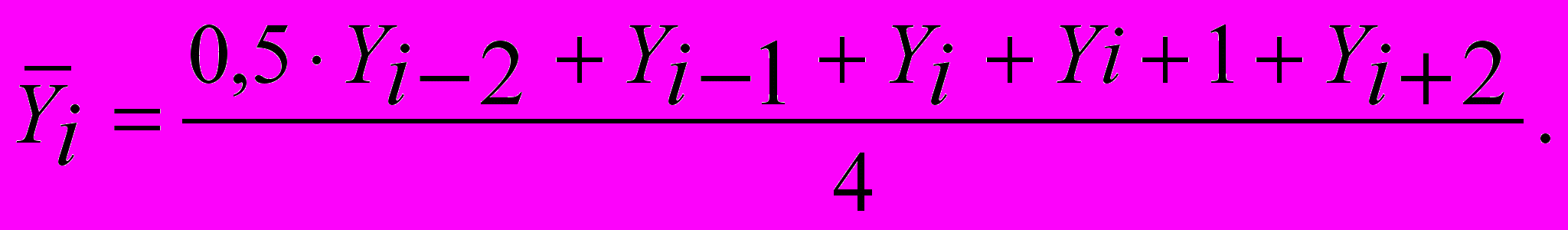
Например: для исключения сезонных колебаний из поквартальных данных находятся осредненные «скользящие» уровни:
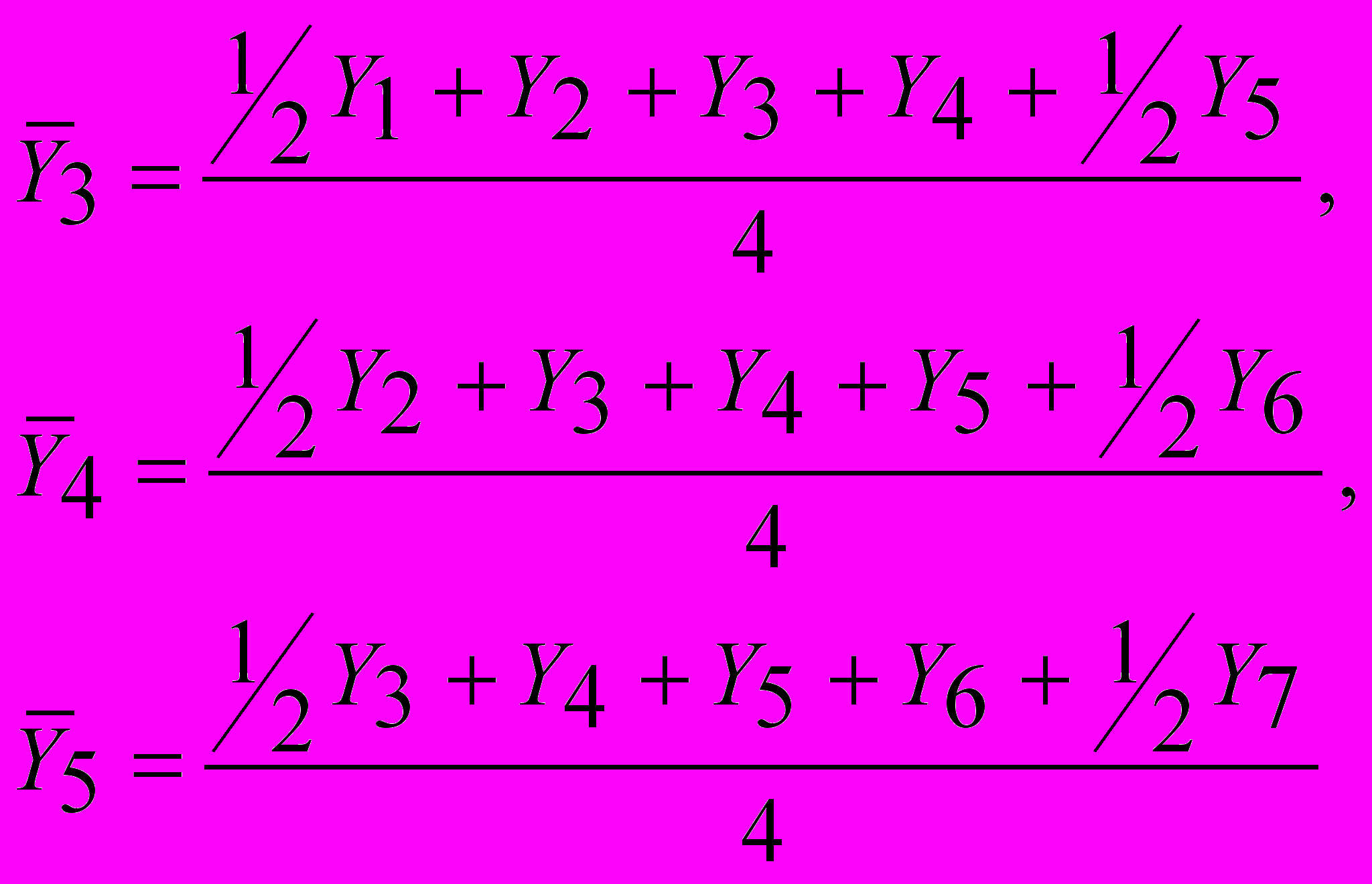
и т. д., где
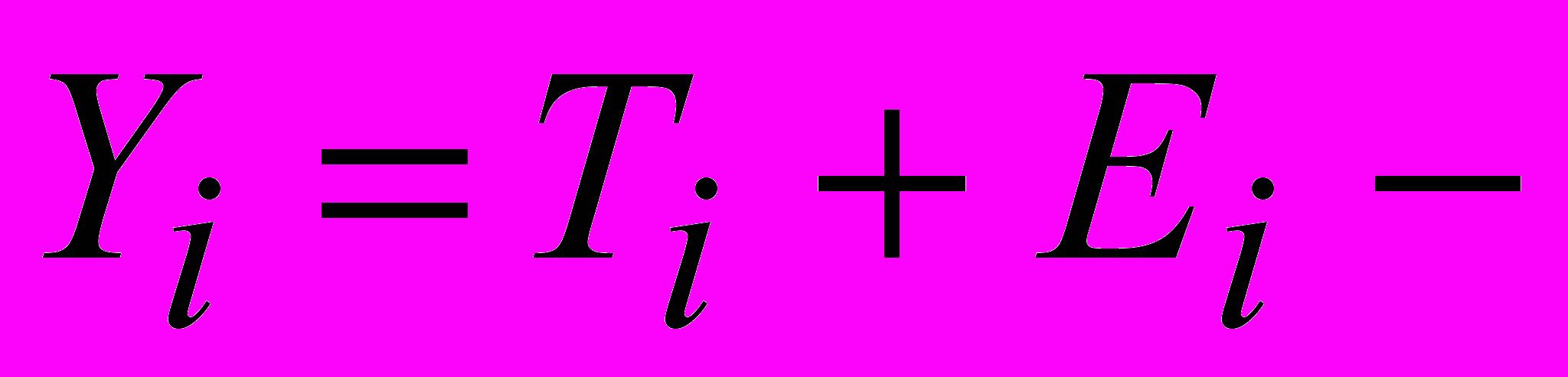 элемент временного ряда, содержащий тренд и случайную компоненту.
элемент временного ряда, содержащий тренд и случайную компоненту.Тогда выделение сезонной компоненты производится на основе равенства:
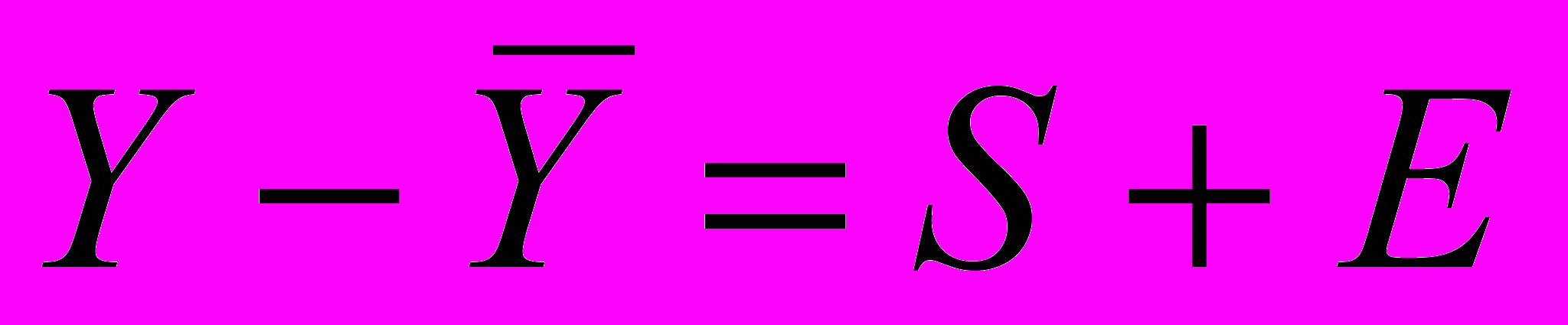 .
.Сезонная компонента находится как среднее значение сезонных оценок для каждого сезона независимо от особенностей года. Общая сумма сезонных оценок должна быть равна нулю
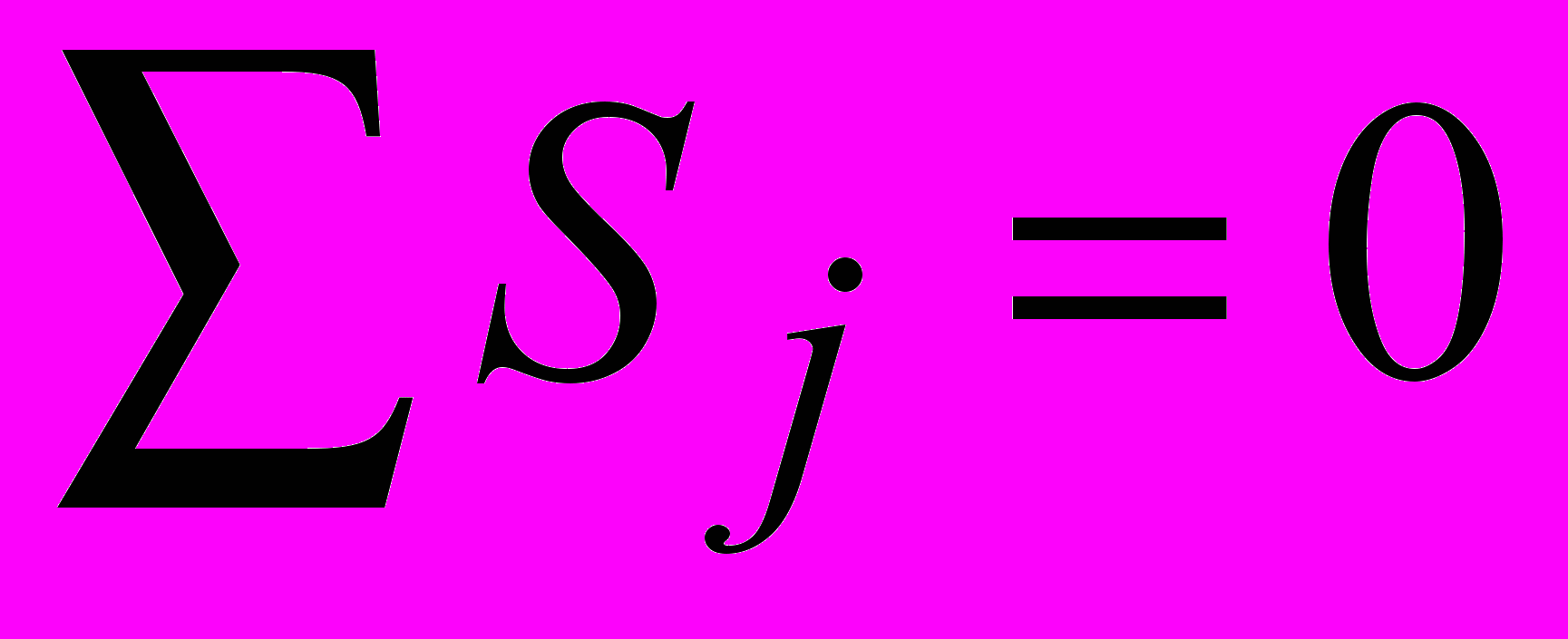 (здесь j – номер сезона). Это необходимо, чтобы усреднять значение сезонной компоненты в целом за год. Поэтому сезонные оценки приходится корректировать, чтобы выполнить это условие.
(здесь j – номер сезона). Это необходимо, чтобы усреднять значение сезонной компоненты в целом за год. Поэтому сезонные оценки приходится корректировать, чтобы выполнить это условие.После этого усредняем сезонную компоненту из фактических данных, т. е. находим
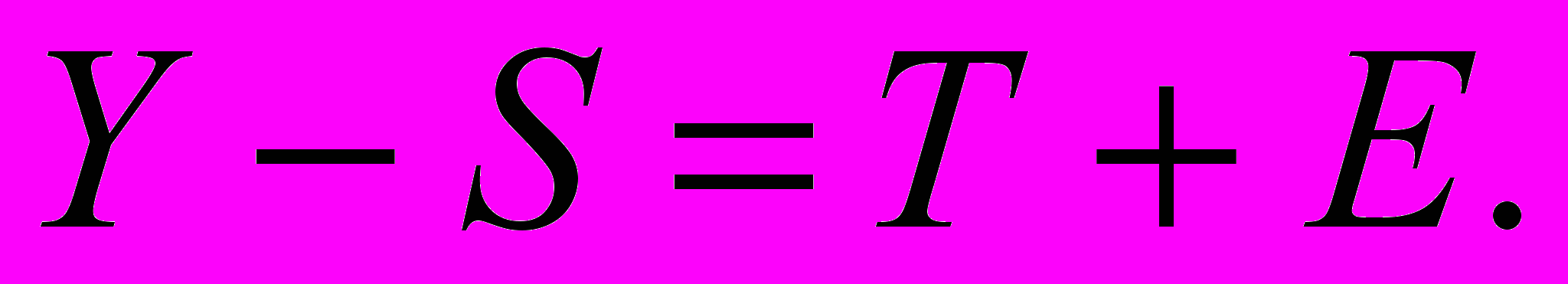
Такие данные называют десезонализированные. Они используются для построения уравнения тренда.
Уравнение линейного тренда имеет вид:
T = a + bt, где
t – номер квартала (или месяца),
a – отрезок, отсекаемый линией тренда при пересечении с осью ординат,
b – характеристика наклона линии тренда к оси абсцисс.
Параметры a и b находятся методом наименьших квадратов:
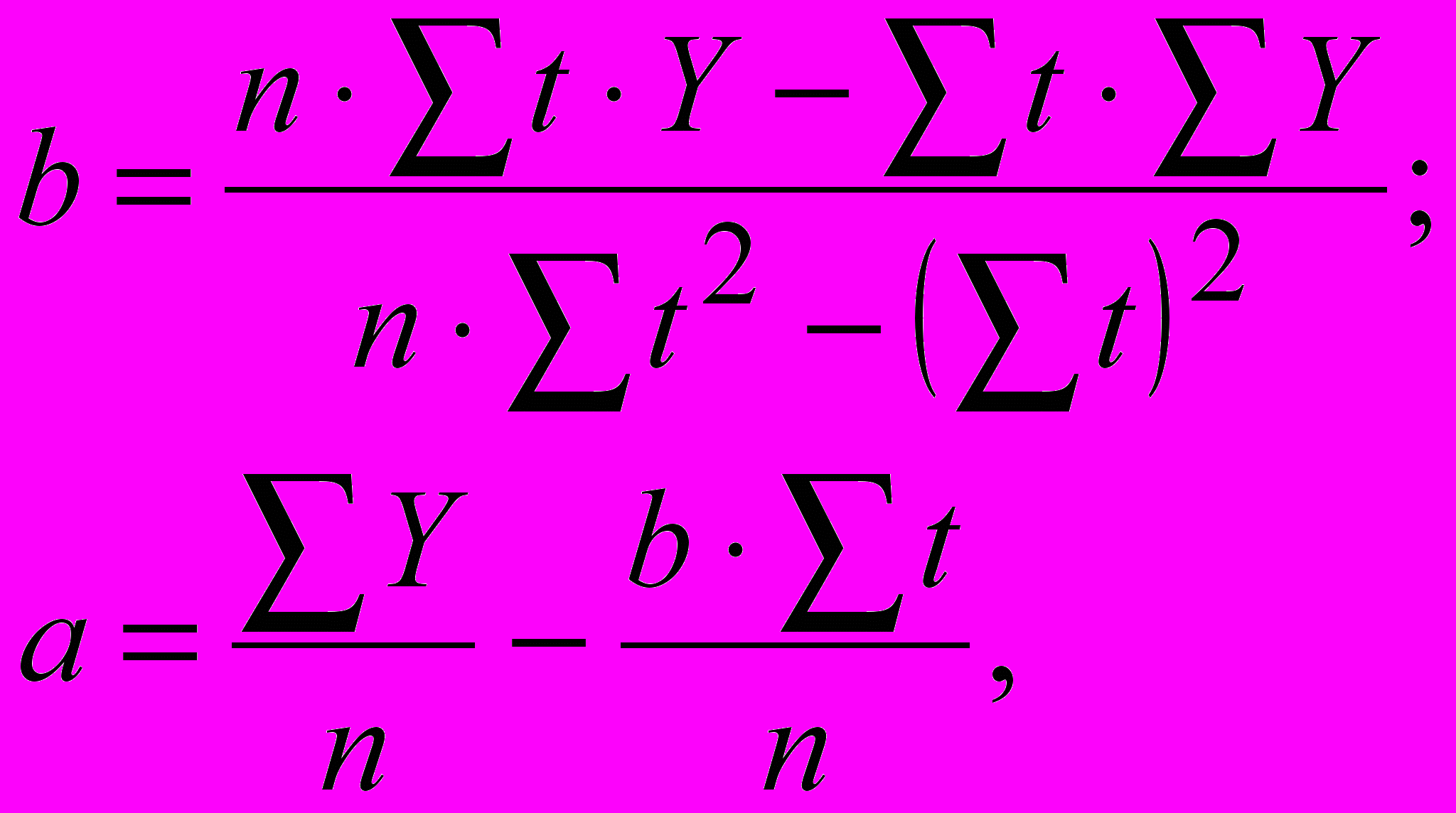
где t – порядковый номер квартала,
Y = T + E – десезонализированные уровни временного ряда.
Найдя сезонную компоненту и тренд, выделим случайную компоненту:
Y – S – T = E.
Значения случайной компоненты (ошибки) используются для расчета среднего абсолютного отклонения:
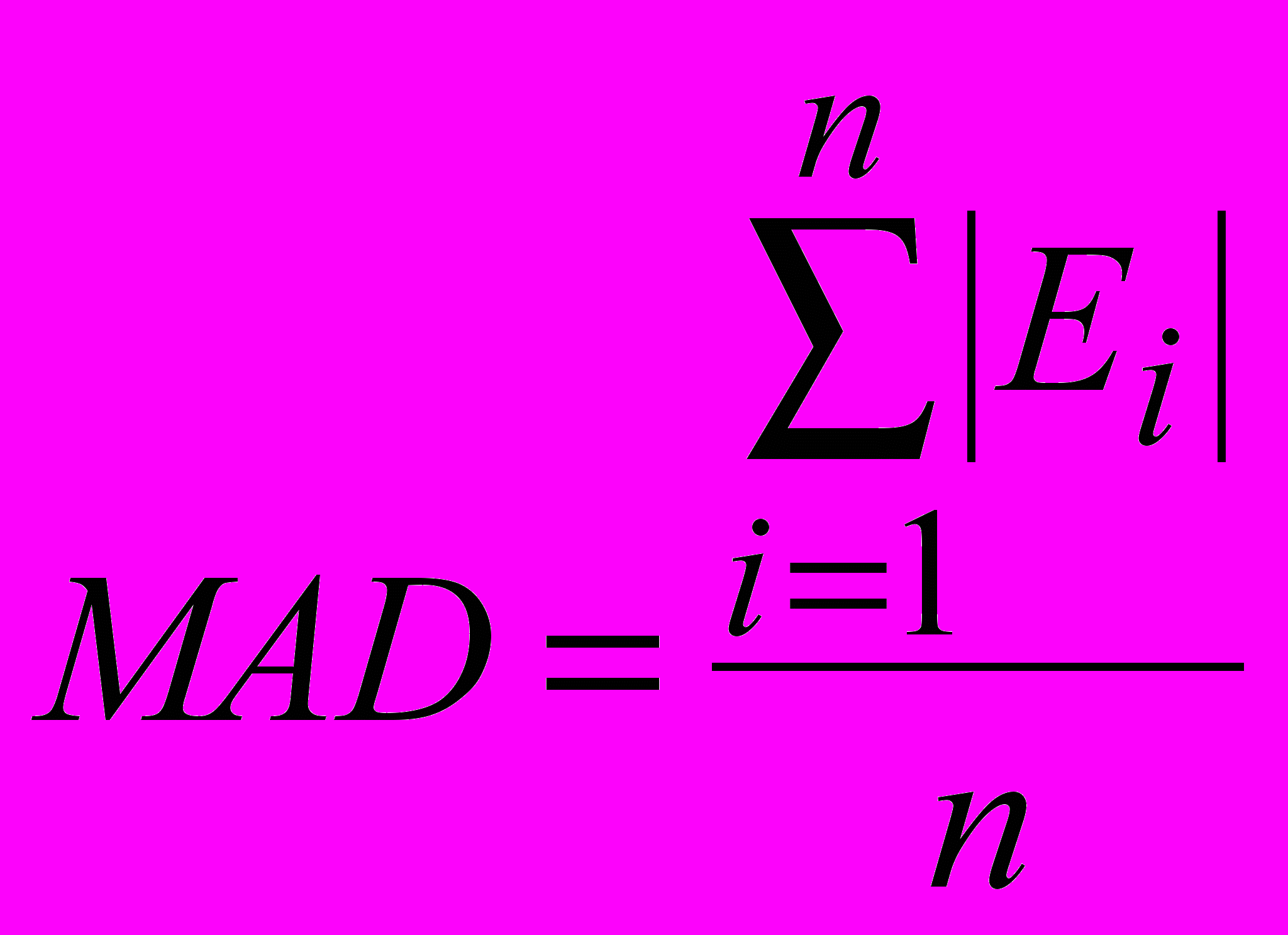
или среднеквадратической ошибки:
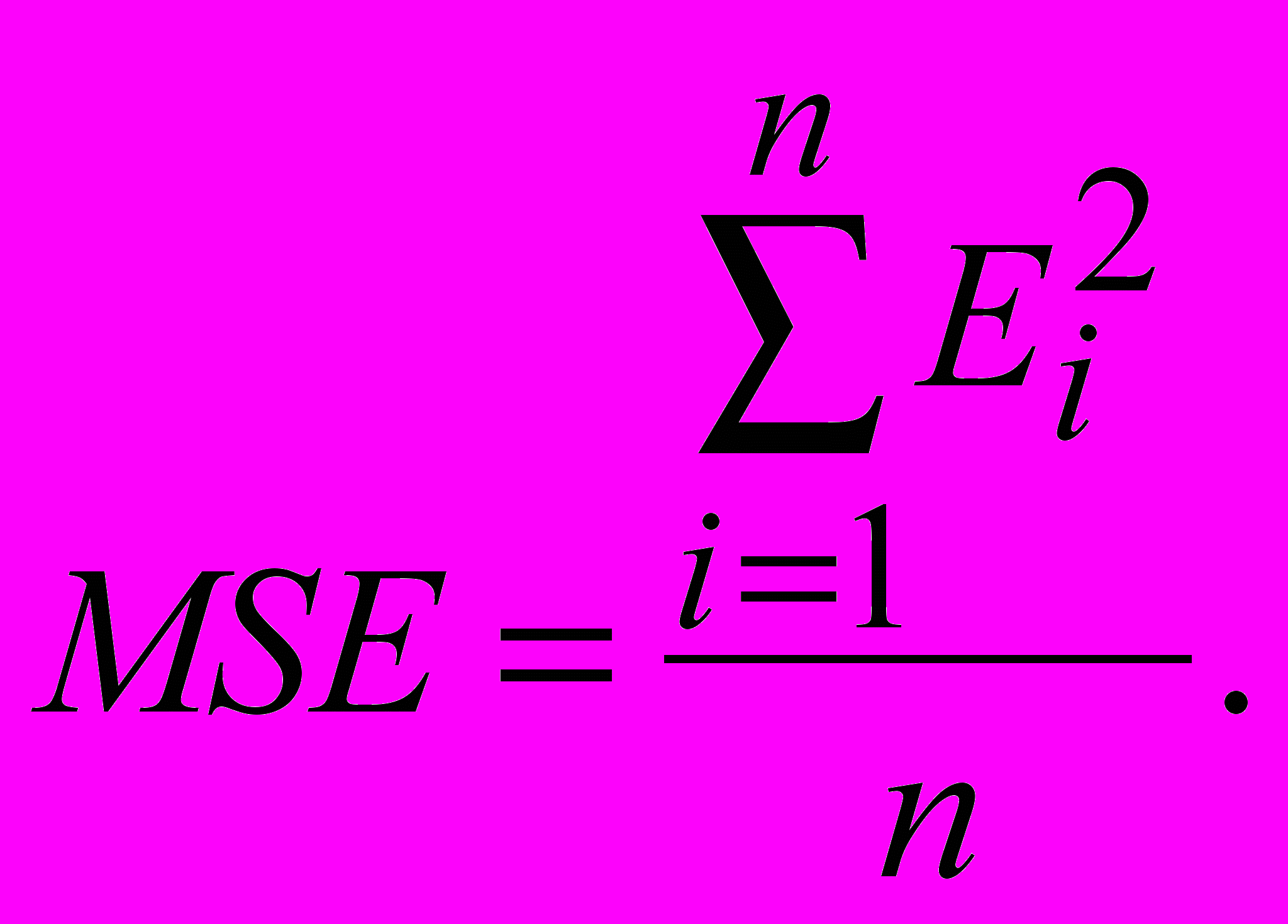
Если ошибки малы, то делают вывод о том, что тенденция устойчива и позволяет получить хорошие краткосрочные прогнозы. Прогнозные значения по аддитивной модели рассчитываются как:
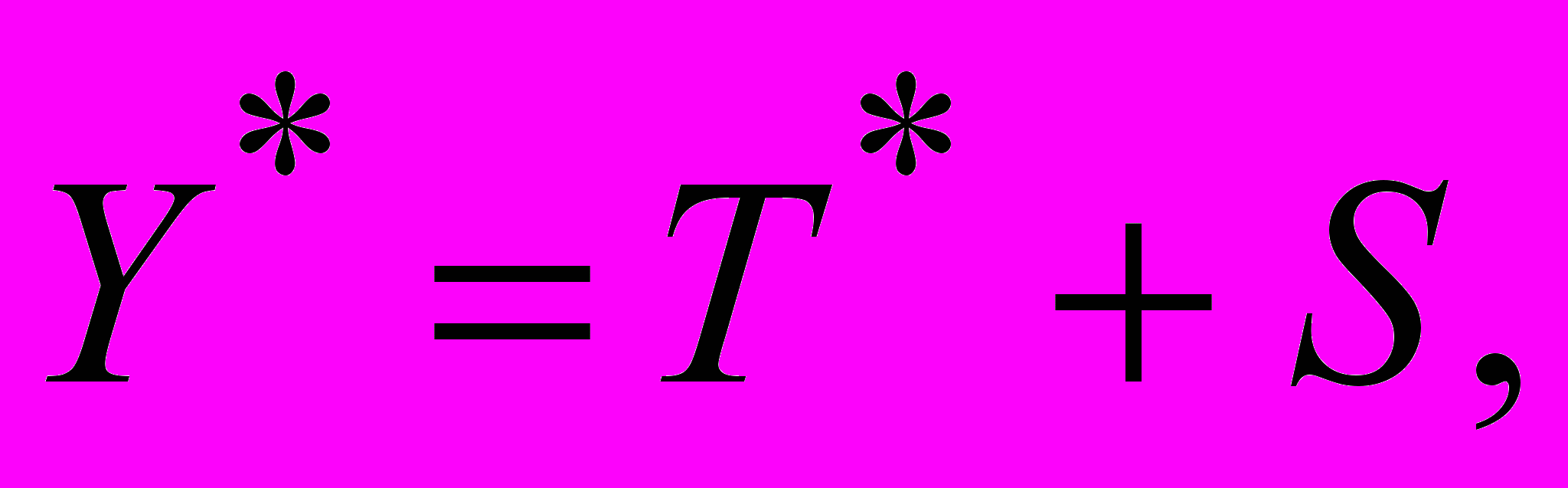
где Т* - трендовое значение для соответствующего квартала (месяца),
S – сезонная компонента для соответствующего квартала (месяца).
Трендовое значение для прогнозного квартала (месяца) рассчитывается по уравнению тренда:
T* = a + b·t.
Чем меньше период упреждения, тем более обоснованным окажется прогноз.
Аддитивная модель применяется при построении сезонной компоненты. Если она возрастает с возрастанием тренда, то лучший результат будет получен на базе мультипликативной модели
Y = T · S · E,
где Т – трендовая компонента,
S - коэффициент сезонной компоненты,
Е – относительное влияние случайной компоненты.
В этом случае производят выражение ряда методом скользящей средней и находят коэффициент сезонности
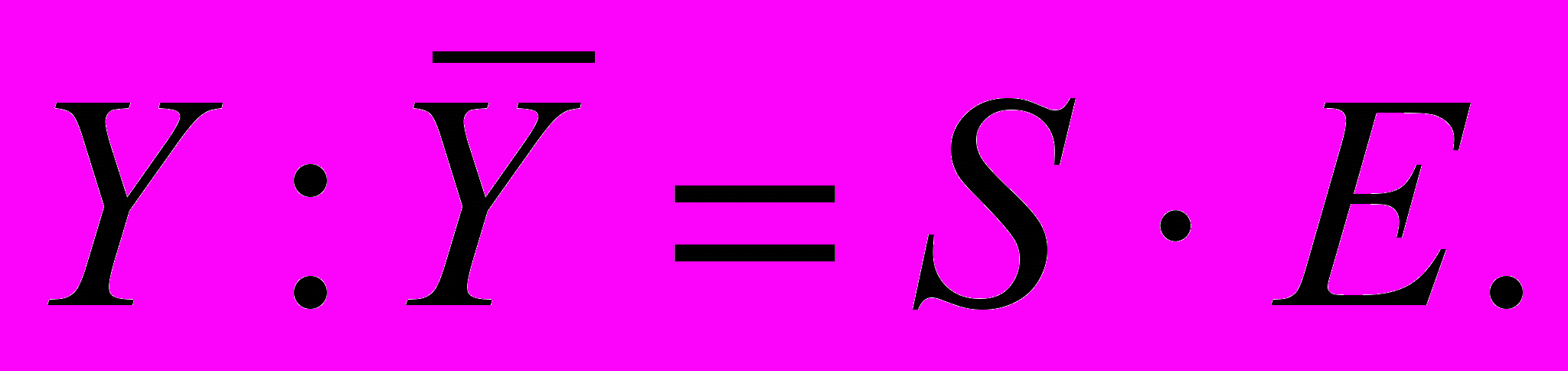
Если временной ряд построен по квартальным данным, то сумма коэффициентов сезонности должна быть равна 4, а если по месячным, то
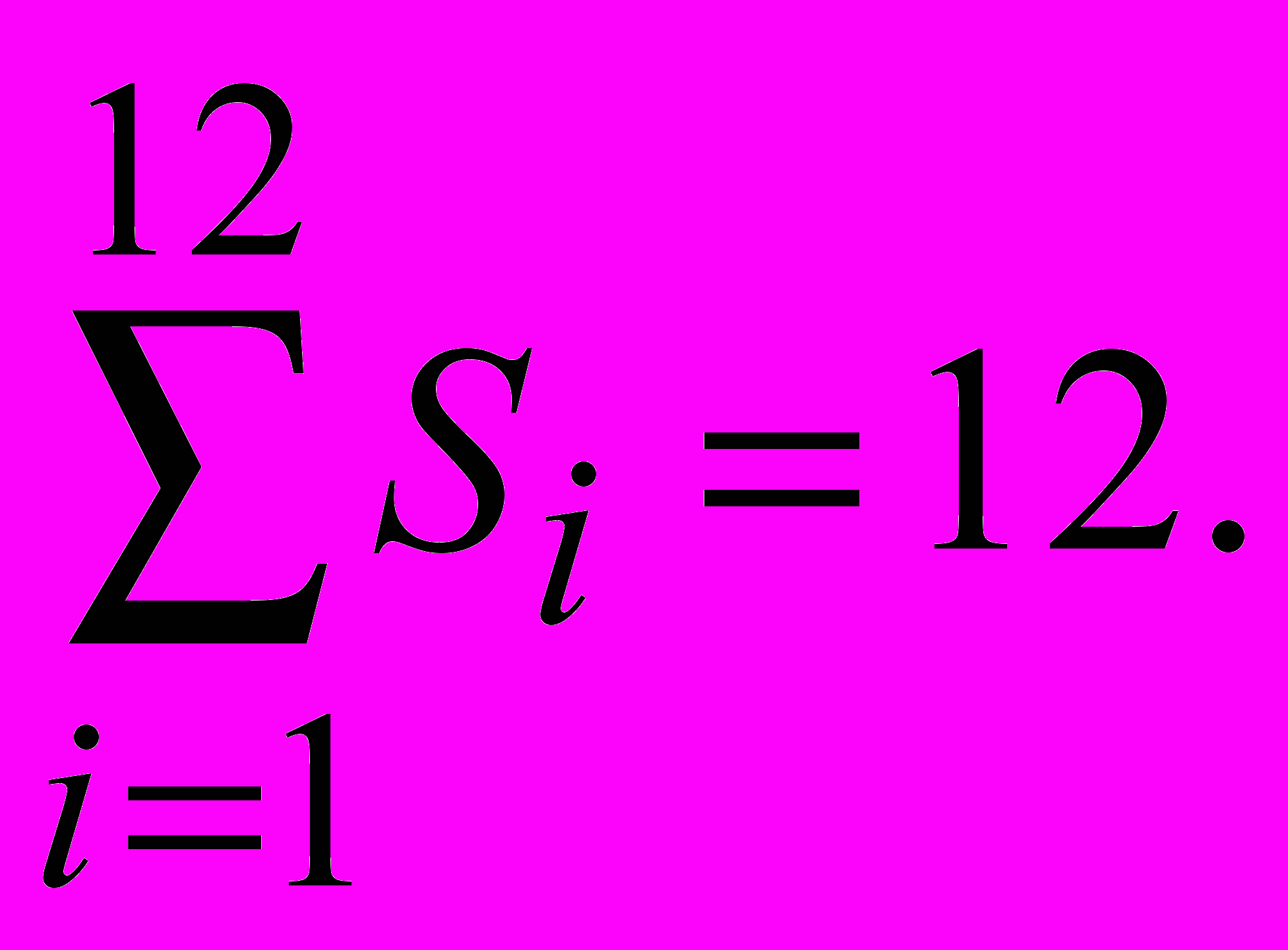 Если этого нет, то производят корректировку коэффициентов сезонности, чтобы выполнить это условие.
Если этого нет, то производят корректировку коэффициентов сезонности, чтобы выполнить это условие.На основе десезонолизированных данных рассчитывают уравнение тренда – линейное или нелинейное- и находят трендовые значения Т. Затем вычисляют ошибки:
относительную E = Y : (T · S),
абсолютную Ea = Y – (T · S).
Потом оценивается близость модели к фактическим данным с помощью показателей MAD и MSE.
Прогнозные значения определяются как
Y* = T* · S,
где Т* - прогнозное значение, найденное по уравнению тренда.
Например: T* = a + b·t, где t – порядковый номер прогнозного квартала (месяца).
Затем рассчитанное значение Т* корректируют на сезонную компоненту соответствующего квартала или месяца T* · S.
Пример: Определение сезонной составляющей.
После определения тренда можно переходить к нахождению сезонной составляющей. Существуют два подхода к построению сезонной составляющей: построение аддитивной и мультипликативной модели.
В аддитивной модели
Y = Ta + Sa + E – сумма всех составляющих.
Здесь Y – наблюдаемое значение,
Ta – значение тренда,
Sa – сезонная компонента.
Y = Tm · Sm · Em – произведение всех составляющих.
Тогда сезонная составляющая с учетом влияния случайного воздействия в аддитивной модели определяется
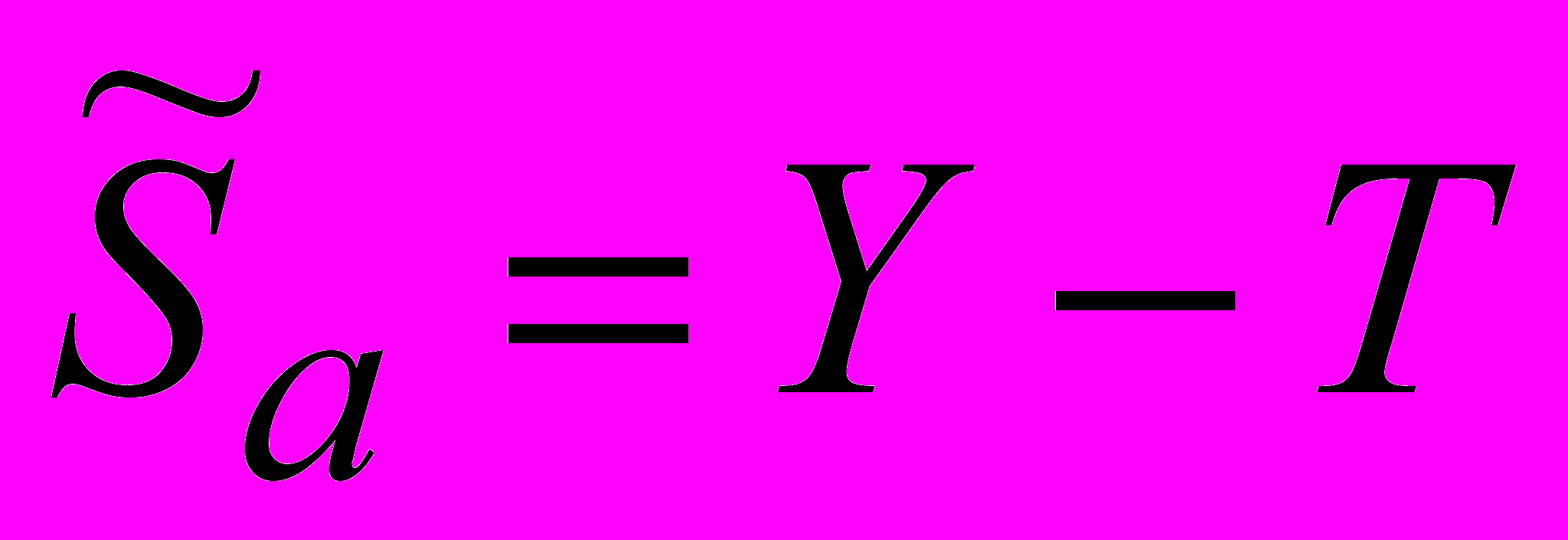 (как разность между фактическими значениями временного ряда и соответствующими значениями тренда).
(как разность между фактическими значениями временного ряда и соответствующими значениями тренда).В мультипликативной модели – как отношение фактических значений временного ряда к соответствующим значениям тренда
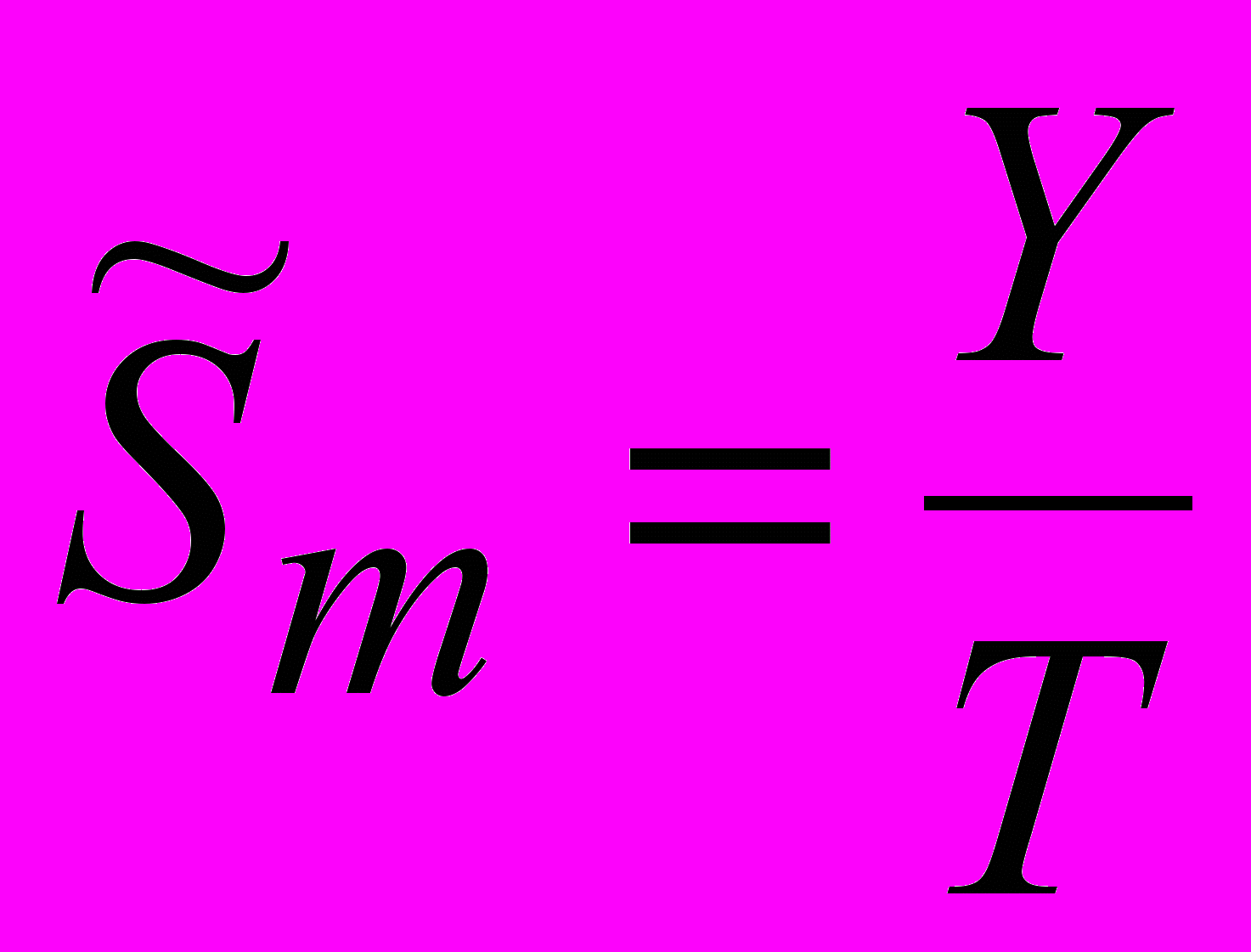 и называется индексом сезонности или коэффициентом сезонности.
и называется индексом сезонности или коэффициентом сезонности.Аддитивную модель удобно использовать, если сезонные колебания около тренда приблизительно постоянны для соответствующих моментов времени.
Мультипликативную модель удобно применять, когда сезонные отклонения равны определенному проценту от тренда.
Рассмотрим аддитивную модель Y = Ta + Sa + Ea.
Таблица 1.
| День недели | Объем продаж, Y | Скользящая средняя,Tmov |  | Скорректированная сезонная составляющая, Sa | Ta + Ea | Тренд,Ta (МНК) | Случайная составляющая, Ea |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1-неделя | | | | | | | |
| понедельник | 12 | - | - | - 0.728 | 12.728 | 12.660 | 0.068 |
| вторник | 14 | - | - | 1.422 | 12.578 | 12.826 | -0.248 |
| среда | 15 | 13 | 2 | 1.902 | 13.098 | 12.993 | 0.105 |
| четверг | 13 | 13.2 | -0.2 | -0.298 | 13.298 | 13.160 | 0.138 |
| пятница | 11 | 13.4 | -2.4 | -2.298 | 13.298 | 13.327 | -0.029 |
| 2-неделя | | | | | | | |
| понедельник | 13 | 13.5 | -0.5 | -0.728 | 13.728 | 13.493 | 0.235 |
| вторник | 15 | 13.62 | 1.38 | 1.422 | 13.578 | 13.660 | -0.082 |
| среда | 15.5 | 13.82 | 1.68 | 1.902 | 13.598 | 13.827 | -0.229 |
| четверг | 13.6 | 13.92 | -0.32 | -0.298 | 13.898 | 13.993 | -0.095 |
| пятница | 12 | 14.12 | -2.12 | -2.298 | 14.298 | 14.160 | 0.138 |
| 3-неделя | | | | | | | |
| понедельник | 13.5 | 14.38 | -0.88 | -0.728 | 14.228 | 14.327 | -0.099 |
| вторник | 16 | 14.46 | 1.54 | 1.422 | 14.578 | 14.494 | 0.084 |
| среда | 16.8 | 14.66 | 2.14 | 1.902 | 14.898 | 14.660 | 0.238 |
| четверг | 14 | - | - | -0.298 | 14.298 | 14.827 | -0.529 |
| пятница | 13 | - | - | -2.298 | 15.298 | 14.994 | 0.304 |
В первых двух столбцах представлены исходные данные наблюдаемых значений Y объема произведенной продукции за три недели.
В 3 – м столбце тренд вычислен по методу скользящей средней Tmov.
В 4 – м столбце рассчитаны значения суммы сезонной и случайной составляющих
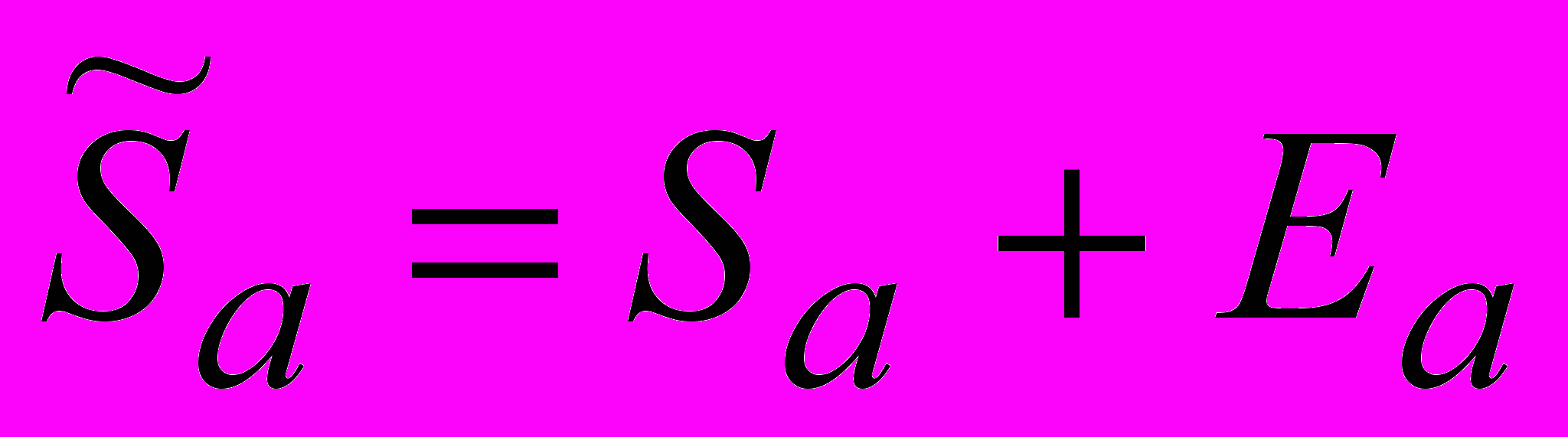 , полученные, как разность
, полученные, как разность  .
.Для устранения случайных воздействий берут средние значения величин
 , отстоящие за период (см. таблицу 2).
, отстоящие за период (см. таблицу 2).Таблица 2.
| День недели Неделя | Понедельник | Вторник | Среда | Четверг | Пятница | |
| 1 - я | - | - | 2.0 | -0.2 | -2.40 | |
| 2 - я | -0.5 | 1.38 | 1.68 | -0.32 | -2.12 | |
| 3 - я | -0.88 | 1.54 | 2.14 | - | - | |
| Среднее значение, | -0.69 | 1.46 | 1.94 | -0.26 | -2.26 |  |
| Скорректированная сезонная составляющая | -0.728 | 1.422 | 1.902 | -0.298 | -2.298 | 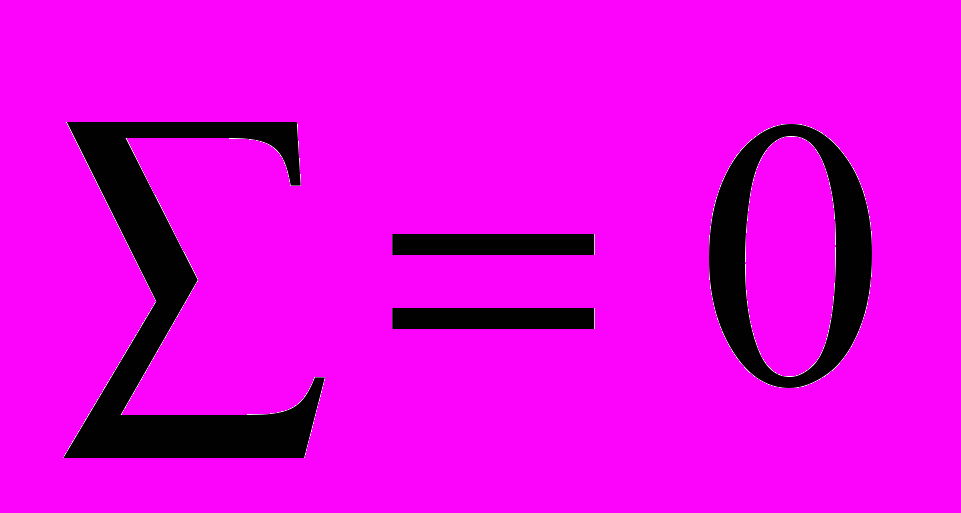 |
В аддитивной модели сумма колебаний вокруг тренда должна равняться нулю, но по различным причинам (случайные воздействия округления) она оказалась равной
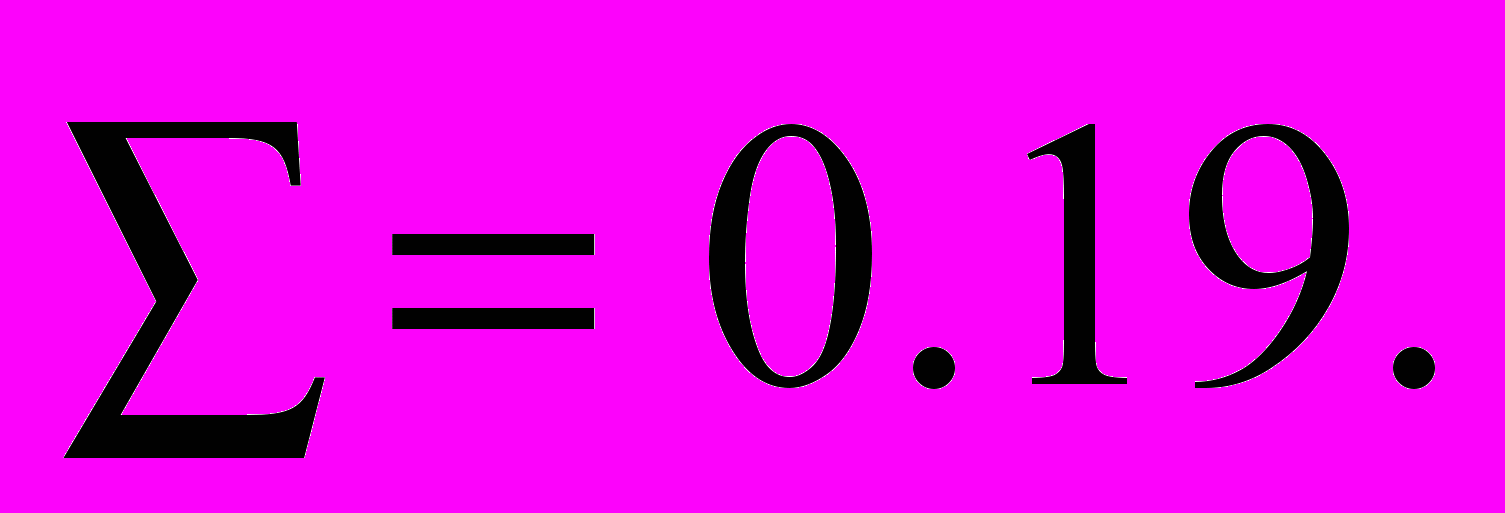 Поэтому введем поправку. Каждое среднее значение уменьшим на величину
Поэтому введем поправку. Каждое среднее значение уменьшим на величину 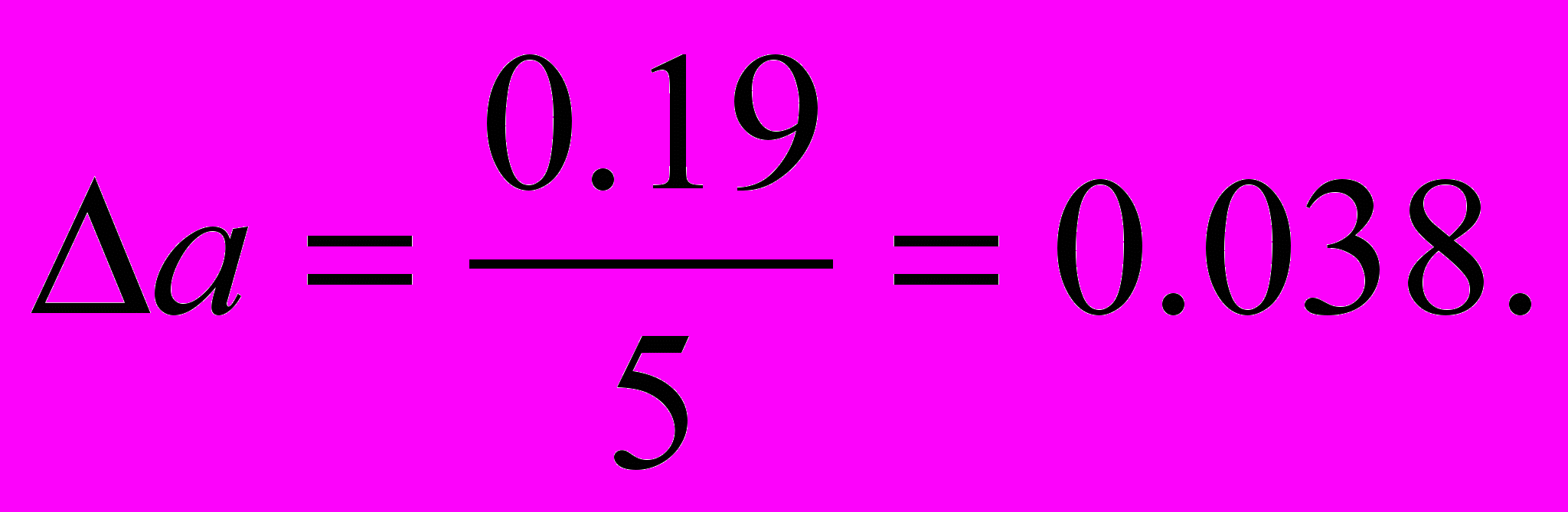
Результат, записанный в последней строке таблицы, принимается за сезонную составляющую Sa. Эта величина (Sa) расположена в столбце 5.
Результат удаления сезонной составляющей представляет собой сумму тренда и случайных воздействий: Y – Sa = Ta + Ea. Эти данные расположены в столбце 6 таблицы 1.
Используя данные столбца 6 с помощью метода наименьших квадратов находят сам тренд Та (столбец 7). Его уравнение имеет вид Та = 12.493 + 0.167·t. t – это номер дня, считая понедельник первой недели за 1 – й день, понедельник второй недели 6– й день и т.д..В таком случае разность данных столбцов 6 и 7 укажет случайную составляющую.
Аналогично строится мультипликативная модель Y = Tm × Sm × Em.
Таблица 3
| День недели | Объем продаж, Y | Скользящая средняя,Tmov | 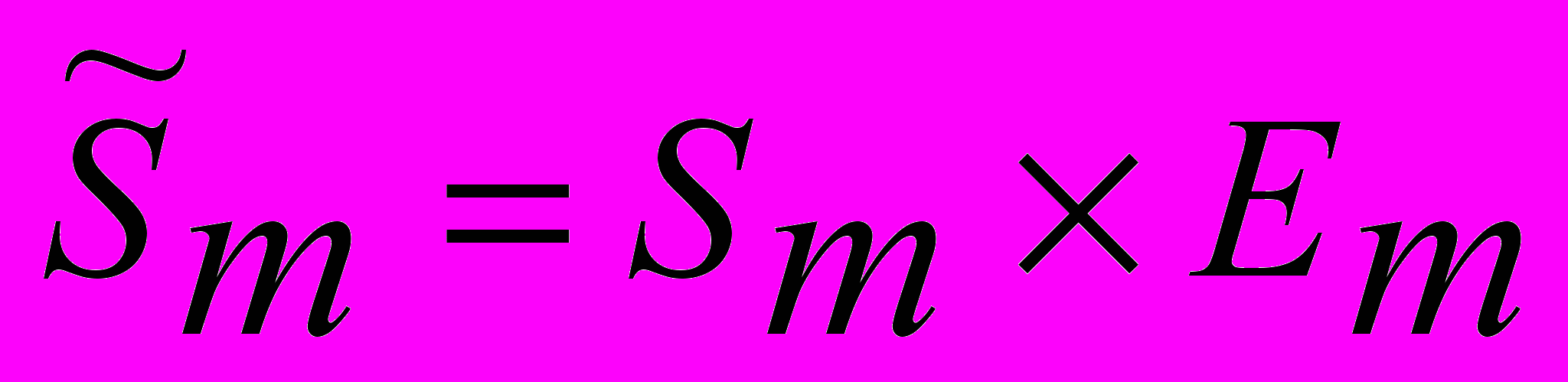 | Скорректированная сезонная составляющая, Sm | Tm × Em | Тренд,Tm (МНК) | Случайная составляющая, Em |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1-неделя | | | | | | | |
| понедельник | 12 | - | - | 0.949 | 12.651 | 12.649 | 1.0002 |
| вторник | 14 | - | - | 1.102 | 12.709 | 12.820 | 0.9913 |
| среда | 15 | 13 | 1.154 | 1.138 | 13.179 | 12.991 | 1.0145 |
| четверг | 13 | 13.2 | 0.985 | 0.979 | 13.284 | 13.162 | 1.0093 |
| пятница | 11 | 13.4 | 0.821 | 0.833 | 13.204 | 13.333 | 0.9903 |
| 2-неделя | | | | | | | |
| понедельник | 13 | 13.5 | 0.963 | 0.949 | 13.705 | 13.504 | 1.0149 |
| вторник | 15 | 13.62 | 1.101 | 1.102 | 13.617 | 13.675 | 0.9958 |
| среда | 15.5 | 13.82 | 1.122 | 1.138 | 13.619 | 13.846 | 0.9836 |
| четверг | 13.6 | 13.92 | 0.977 | 0.979 | 13.897 | 14.018 | 0.9914 |
| пятница | 12 | 14.12 | 0.850 | 0.833 | 14.405 | 14.189 | 1.0152 |
| 3-неделя | | | | | | | |
| понедельник | 13.5 | 14.38 | 0.939 | 0.949 | 14.232 | 14.360 | 0.9911 |
| вторник | 16 | 14.46 | 1.107 | 1.102 | 14.524 | 14.531 | 0.9995 |
| среда | 16.8 | 14.66 | 1.146 | 1.138 | 14.761 | 14.702 | 1.0040 |
| четверг | 14 | - | - | 0.979 | 14.306 | 14.873 | 0.9619 |
| пятница | 13 | - | - | 0.833 | 15.605 | 15.044 | 1.0373 |
Первые три столбца совпадают со столбцами для аддитивной модели. В четвертом столбце расположено произведение сезонной и случайной составляющих
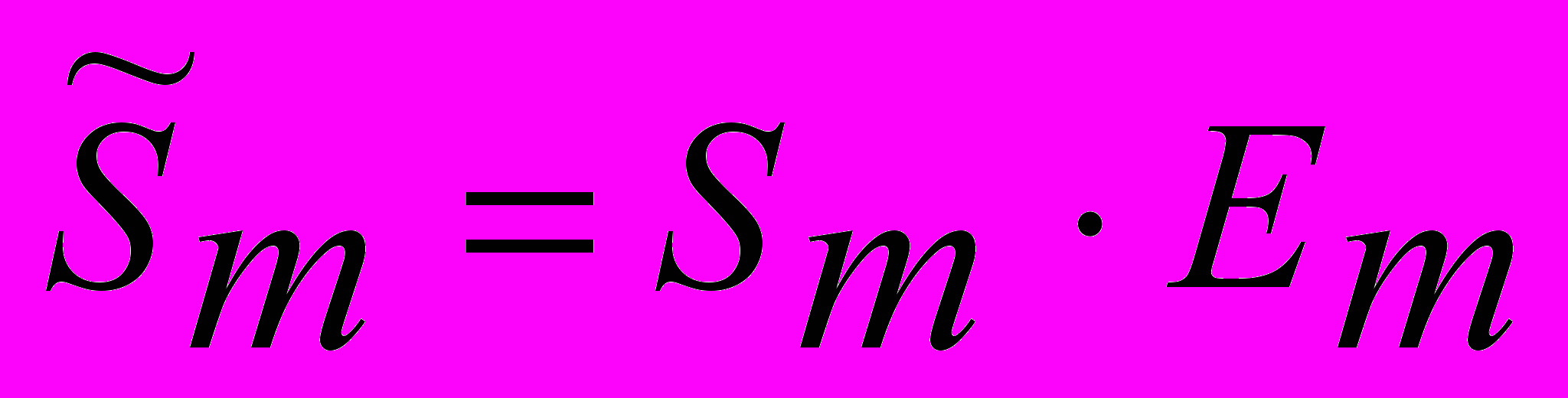 , полученное как отношение значений Y к значениям тренда, найденных с помощью метода скользящих средних
, полученное как отношение значений Y к значениям тренда, найденных с помощью метода скользящих средних 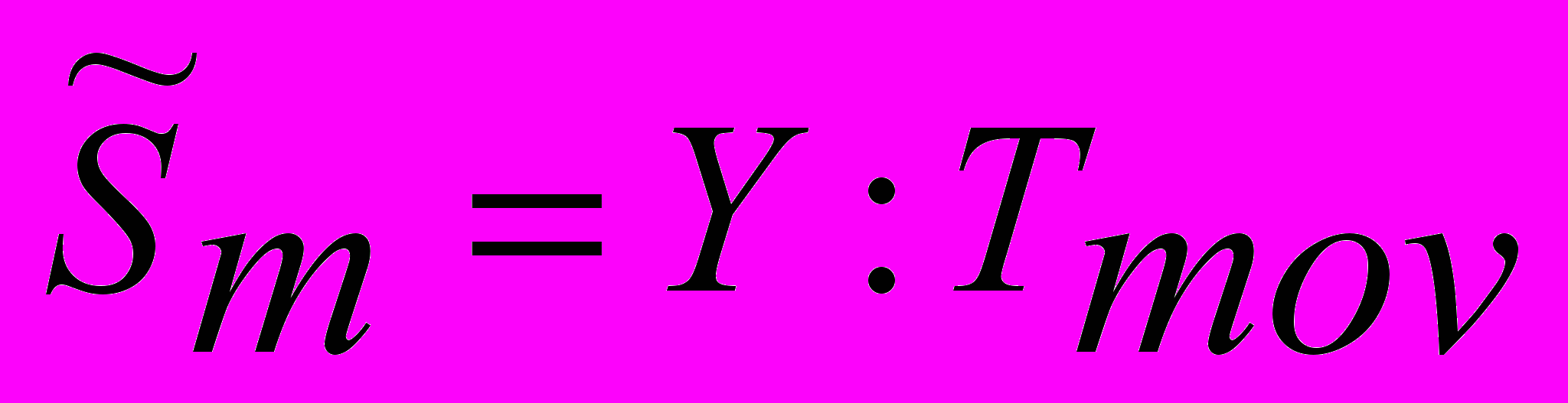 .
.Для устранения случайных воздействий берутся средние значения величины
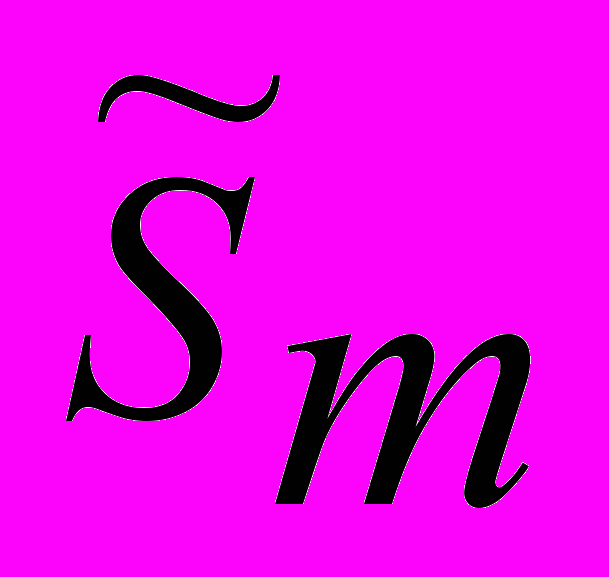 , отстоящие за период.
, отстоящие за период.В мультипликативной модели сумма средних значений 4 строка (табл. 4) должна быть равна 5. Реально эта сумма равна 5.0116.
Уменьшим каждое значение на величину
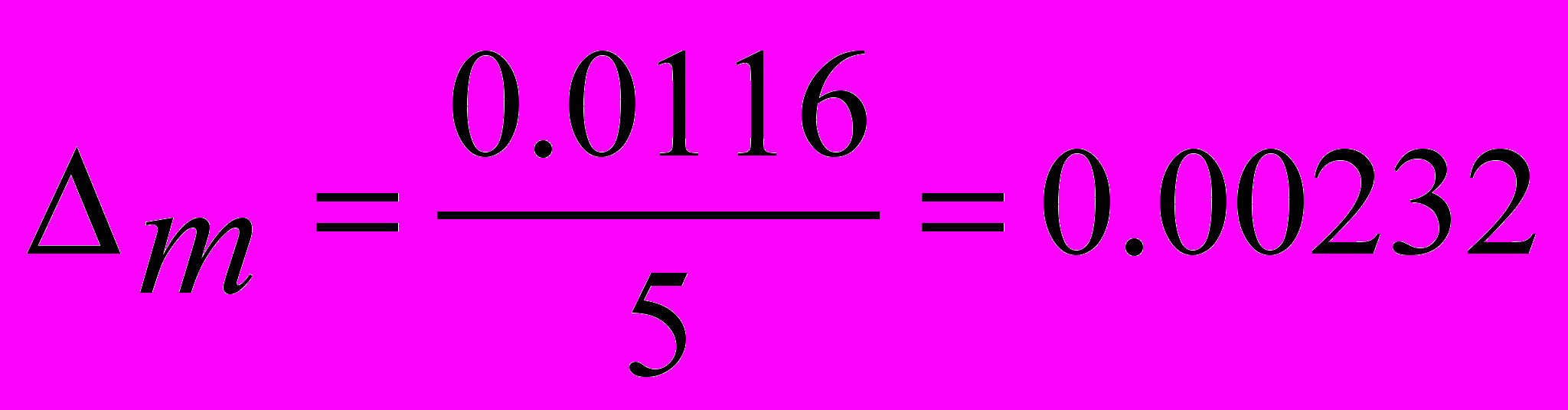 , получим сезонную составляющую в мультипликативной модели. Эти скорректированные результаты, взятые в качестве сезонной составляющей Sm, расположены в пятой строке табл. 4.
, получим сезонную составляющую в мультипликативной модели. Эти скорректированные результаты, взятые в качестве сезонной составляющей Sm, расположены в пятой строке табл. 4.Таблица 4
| День недели Неделя | Понедельник | Вторник | Среда | Четверг | Пятница | |
| 1 - я | - | - | 1.1538 | 0.9848 | 0.8209 | |
| 2 - я | 0.963 | 1.1013 | 1.1216 | 0.977 | 0.8499 | |
| 3 - я | 0.9388 | 1.1065 | 1.146 | - | - | |
| Среднее значение, | 0.9509 | 1.1039 | 1.1405 | 0.9809 | 0.8354 | 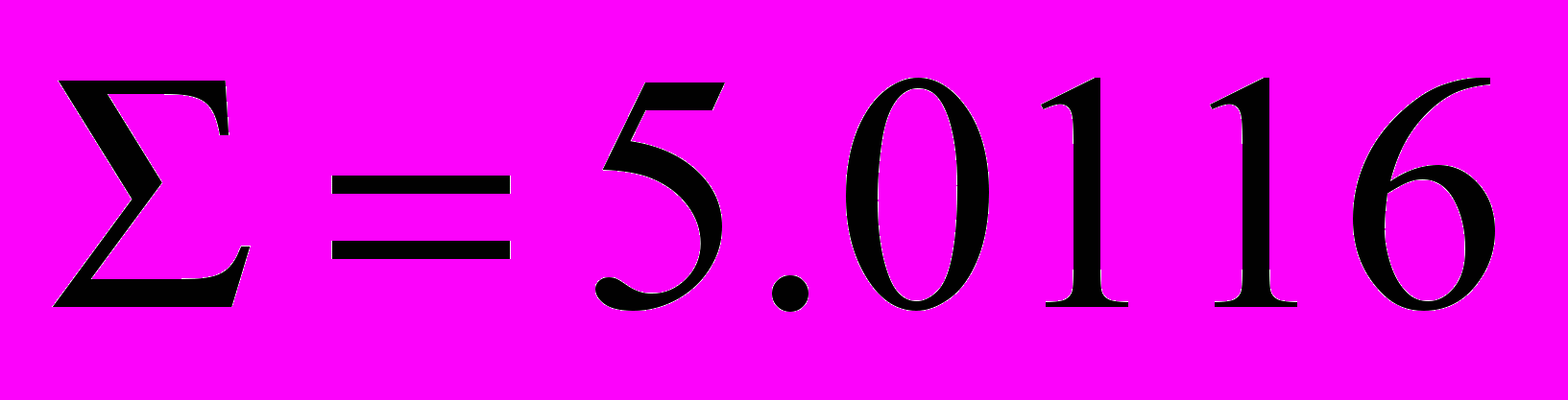 |
| Скорректированная сезонная составляющая | 0.94858 | 1.10158 | 1.13818 | 0.97858 | 0.83308 | 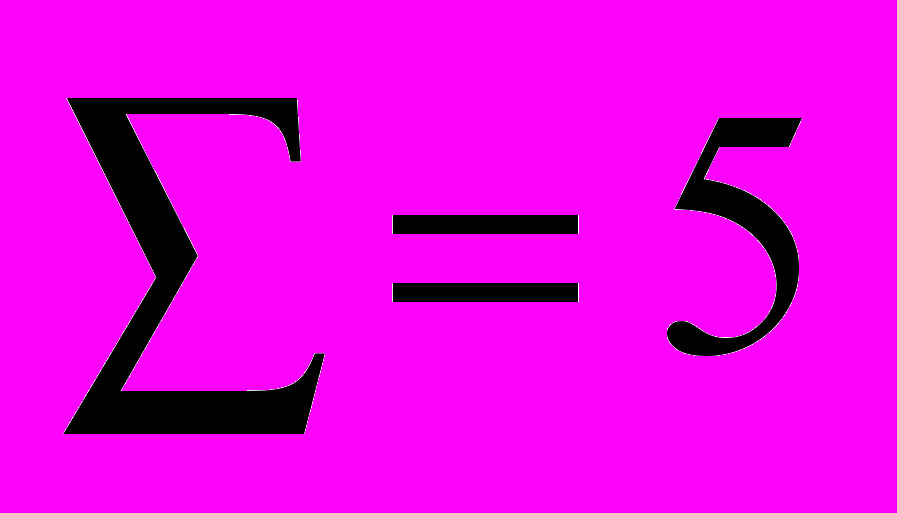 |
Частное от деления фактических данных на сезонный индекс равно произведению тренда на случайную составляющую. Действительно, так как Y = Tm × Sm × Em, то
Y : Sm = Tm × Sm. Результат деления находится в столбце 6 табл.3.
Тренд Tm (столбец 7) получается сглаживанием методом наименьших квадратов данных столбца 6. Его уравнение имеет вид: Tm = 12.478 + 0.171·t.
Частное от деления данных столбца 6 на соответствующие данные столбца 7 есть случайная составляющая мультипликативной модели.
Прогнозирование с помощью временных рядов
Роль прогноза в экономике, в предпринимательской деятельности трудно переоценить. Объем производства, спрос, предложение, выручка, прибыль – все это требует прогноза.
В данном пункте предлагается следующий алгоритм прогноза.
- Построение тренда и определение сезонной составляющей.
- Прогноз значения тренда.
- Уточнение полученного прогноза с помощью сезонной составляющей.
При этом для аддитивной модели:
Yпрогн = Та прогн + Sa
и для мультипликативной модели:
Yпрогн = Тm прогн + Sm
Рассмотрим на примере.
По данным примера №2 методом скользящей средней (см. Гринглаз Л.,
Копытов Е.) спрогнозировать объем продукции для среды 4 – ой недели.
Решение.
Сначала рассмотрим для аддитивной модели.
Для среды 4 – ой недели t = 18. Используется уравнение тренда
Та = 12.493 + 0.167·18 = 15.499.
Для среды сезонная составляющая равна 1.902. Поэтому прогнозируемое значение объема продукции Y = Ta + Sa = 15.499 + 1.902 = 17.401.
Аналогично для мультипликативной модели.
Используя уравнение тренда:
Tm = 12.478 + 0.171·18 = 15.556.
Для среды сезонный коэффициент равен 1.13818. Поэтому прогнозируемое значение:
Y = 15.556·1.13818 = 17.706.