
Курсовая работа
| Вид материала | Курсовая |
- Методические рекомендации по выполнению курсовых работ курсовая работа по «Общей психологии», 54.44kb.
- Курсовая работа Социокультурные лакуны в статьях корреспондентов, 270.94kb.
- Курсовая работа, 30.27kb.
- Курсовая работа тема: Развитие международных кредитно-финансовых отношений и их влияние, 204.43kb.
- Курсовая работа+диск + защита, 29.4kb.
- Курсовая работа+диск + защита, 118.7kb.
- Курсовая работа на математическом, 292.45kb.
- Методические указания к выполнению курсовой работы курсовая работа по курсу «Менеджмент», 159.91kb.
- Курсовая работа по предмету "Бухгалтерский учёт" Тема: "Учёт поступления и выбытия, 462.23kb.
- Курсовая работа по управлению судном, 128.72kb.
| Белорусский Государственный Университет | ||
| Факультет радиофизики и электроники | ||
| Кафедра информатики | ||
| | ||
| | ||
| | ||
| | ||
| | ||
| | ||
| | ||
| | ||
| | ||
| Разработка и анализ эффективности программы | ||
| нахождения интегралов методом Монте-Карло | ||
| на кластере MPI | ||
| | ||
| | ||
| Курсовая работа | ||
| | ||
| | ||
| | ||
| | | |
| | | |
| | | |
| | | |
| | | |
| | | Выполнил: |
| | | студент 4 группы 3 курса |
| | | Строев В.Г. |
| | | |
| | | |
| | | |
| | | Научный руководитель: |
| | | доцент Шпаковский Г.И. |
| | | |
| | | |
| | | |
| | | |
| | | |
| | г. Минск, 2004 | |
ОГЛАВЛЕНИЕ
| ВВЕДЕНИЕ……………………………………………………………... | 3 |
| Раздел 1. Многопроцессорные системы. cтандарт MPI………………………………………... | 4 – 11 |
| 1.1. Организация и эффективность параллельных ЭВМ………. | 4 – 6 |
| 1.2. Разновидности многопроцессорных систем……………...... | 6 – 8 |
| 1.3. Техническая реализация параллельных ЭВМ……….……... | 8 – 9 |
| 1.4. Системы программирования для многопроцессорных систем. Стандарт MPI………………………………………... | 9 – 11 |
| Раздел 2. Метод Монте-Карло……………………………... | 12 – 15 |
| 2.1. Применение метода статистического моделирования…….. | 12 – 13 |
| 2.3. Способы получения случайных чисел……………………… | 13 – 14 |
| 2.4. Идея и суть метода Монте-Карло........................................... | 14 – 15 |
| Раздел 3. Алгоритмы вычисления интегралов методом Монте-Карло……………………........ | 16 – 27 |
| 3.1. Определенный интеграл……………………………………... | 16 – 18 |
| 3.2. Параллельные алгоритмы вычисления...…………………… | 18 – 25 |
| 3.3. Эксперимент. Анализ эффективности некоторых из реализованных алгоритмов………………………………….. | 25 – 27 |
| Заключение………………………………………………………… | 28 |
| Литература………………………………………………………….. | 29 |
| ПриложениЯ………………………………………………………... | 30 – 41 |
ВВЕДЕНИЕ
Классическое понимание алгоритма включает в себя в неявном виде утверждение о том, что процедура, которая может быть названа алгоритмом, имеет последовательный пошаговый характер. Поскольку человек, который решает задачу, и ЭВМ, построенная по классической схеме, выполняют программы вычислений последовательно, то и в информатике на первых порах рассматривались только последовательные методы вычислений.
Однако развитие архитектуры ЭВМ привело к появлению структур, в которых вычислительный процесс может протекать по нескольким ветвям параллельно. Параллелизм возник естественным образом, как средство увеличения производительности вычислительных машин. Идея параллелизма была технически реализована в многопроцессорных системах, однородных средах, локальных вычислительных сетях и в ряде других аппаратных решений.
Появление технических средств, способных организовать параллельное протекание вычислительного процесса, поставило две задачи. Одна из них – создание специальных программных средств для записи параллельных процессов в форме, которую может использовать операционная система вычислительной машины, системы или сети, чтобы фактически организовать параллельный процесс. Появление этой задачи породило новое направление в программировании – параллельное программирование.
Другая задача была связана с созданием специальных методов решения задач, ориентированных на параллельную реализацию, поиском численных методов, которые допускали бы распараллеливание вычислительных процедур.
Прежде всего, специалистов привлекли методы, опирающиеся на идею независимых статистических испытаний. Их еще называют методами Монте-Карло. Главное преимущество применения метода Монте-Карло в параллельных вычислениях состоит в том, что вычислительные процессы не зависят друг от друга, обеспечивая наибольший выигрыш во времени по сравнению с другими методами [5].
Цель данной работы – нахождение алгоритмов вычисления интегралов методом Монте-Карло, без обменов сообщениями между процессами на этапе накопления статистического материала.
Раздел 1. Многопроцессорные системы.
Стандарт MPI
1.1. Организация и эффективность параллельных ЭВМ
Под параллельной ЭВМ понимают ЭВМ, состоящую из множества связанных определенным образом вычислительных блоков, которые способны функционировать совместно и одновременно выполнять множество арифметико-логических операций, принадлежащих одной задаче (программе) [8].
Классифицировать параллельные ЭВМ можно по различным критериям: виду соединения процессоров, способу функционирования процессорного поля, области применения и т.п.
Однако наиболее употребительная классификация параллельных ЭВМ была предложена Флинном [8, 9] и отражает форму реализуемого ЭВМ параллелизма. Основными понятиями классификации являются «поток команд» и «поток данных». Под потоком команд упрощенно понимают последовательность команд одной программы. Поток данных – это последовательность данных, обрабатываемых одной программой.
Согласно классификации Флинна имеется четыре больших класса ЭВМ:
- ОКОД – Одиночный поток Команд – Одиночный поток Данных (SISD – Single Instruction – Single Data). Это последовательные ЭВМ, в которых выполняется единственная программа, т.е. имеется только один счетчик команд и одно арифметико-логическое устройство;
- ОКМД – Одиночный поток Команд – Множественный поток Данных (SIMD – Single Instruction – Multiple Data). В таких ЭВМ выполняется единственная программа, но каждая ее команда обрабатывает много чисел. Это соответствует векторной форме параллелизма;
- МКОД – Множественный поток Команд – Одиночный поток Данных (MISD – Multiple Instruction – Single Data). Подразумевается, что в данном классе несколько команд одновременно работает с одним элементом данных, однако эта позиция классификации Флинна на практике не нашла применения;
- МКМД – Множественный поток Команд – Множественный поток Данных (MIMD – Multiple Instruction – Multiple Data). В таких ЭВМ одновременно и независимо друг от друга выполняется несколько программных ветвей, в определенные промежутки времени обменивающихся данными. Такие системы обычно называют многопроцессорными. Далее, в работе будут рассматриваться только многопроцессорные ЭВМ.
Вопрос об эффективности параллельных ЭВМ возникает на разных стадиях исследования и разработки ЭВМ. Следует различать эффективность параллельных ЭВМ в процессе их функционирования и эффективность параллельных алгоритмов [8].
В зависимости от стадии разработки полезными оказываются различные характеристики эффективности ЭВМ. Одной из главных является ускорение r параллельной системы, которое определяется выражением:
| | 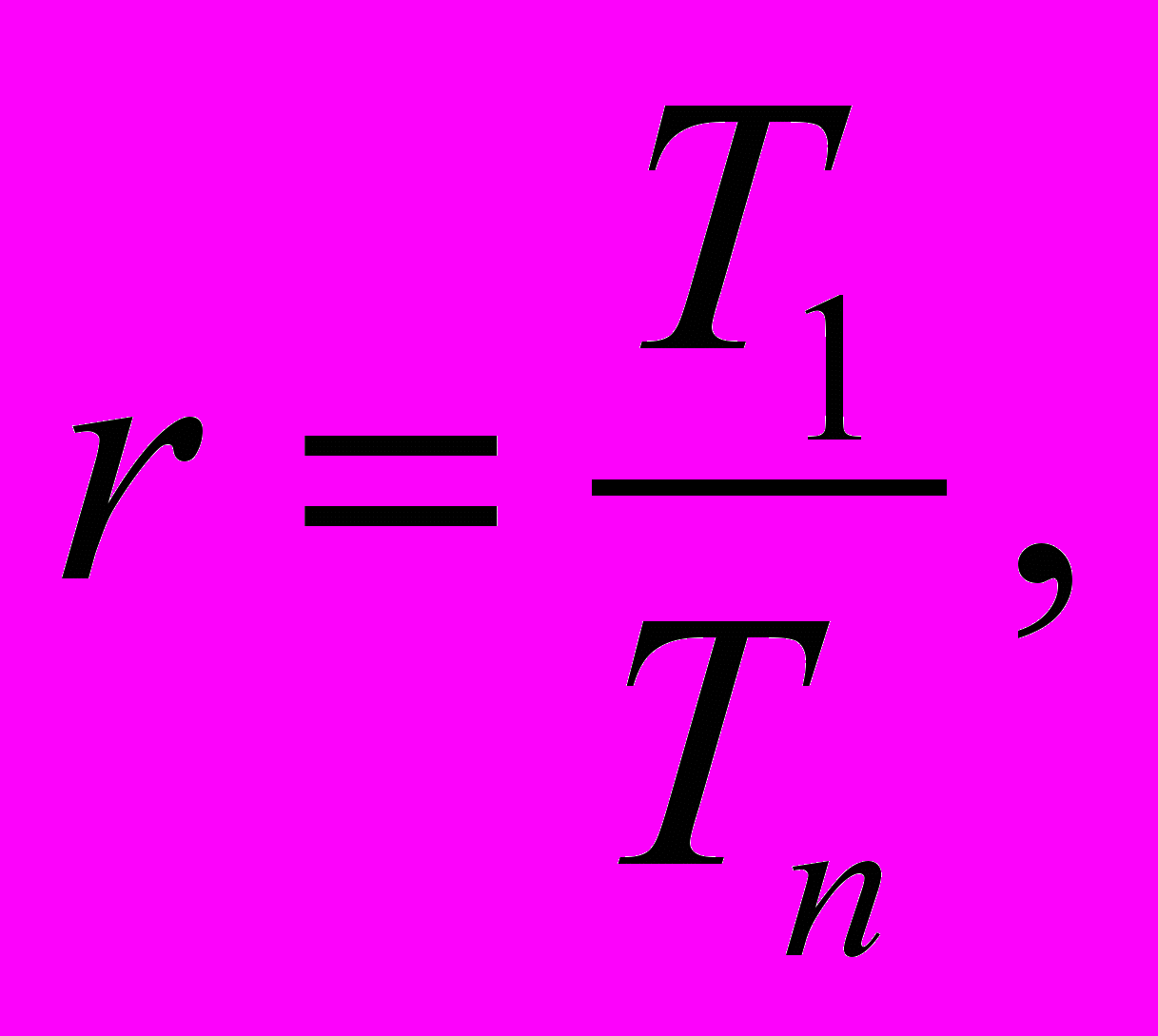 | (1.1.1) |
где T1 – время решения задачи на однопроцессорной системе, а Tn – время решения той же задачи на n-процессорной системе.
Если обозначить W = Wск + Wпр, где W – общее число операций в задаче, Wпр – число операций, которые можно выполнять параллельно, а Wск – число скалярных (нераспараллеливаемых) операций; t – время выполнения одной операции, то закон Амдала будет иметь вид [8, 9]:
| |  | (1.1.2) |
где a = Wск / W – удельный вес скалярных операций.
Закон Амдала определяет принципиально важные для параллельных вычислений положения:
1. Ускорение вычислений зависит как от потенциального параллелизма задачи (величина 1-a), так и от параметров аппаратуры (число процессоров n).
2. Предельное ускорение вычислений определяется свойствами задачи и не может превосходить 1/a при любом числе процессоров, то есть максимальное ускорение определяется потенциальным параллелизмом задачи и весьма чувствительно к изменению величины a.
Тем не менее закон Амдала не учитывает временных затрат на обмен сообщениями между процессорами. А ведь во многих случаях эти потери могут не только снизить ускорение вычислений, но и замедлить вычисления по сравнению с однопроцессорным вариантом.
П
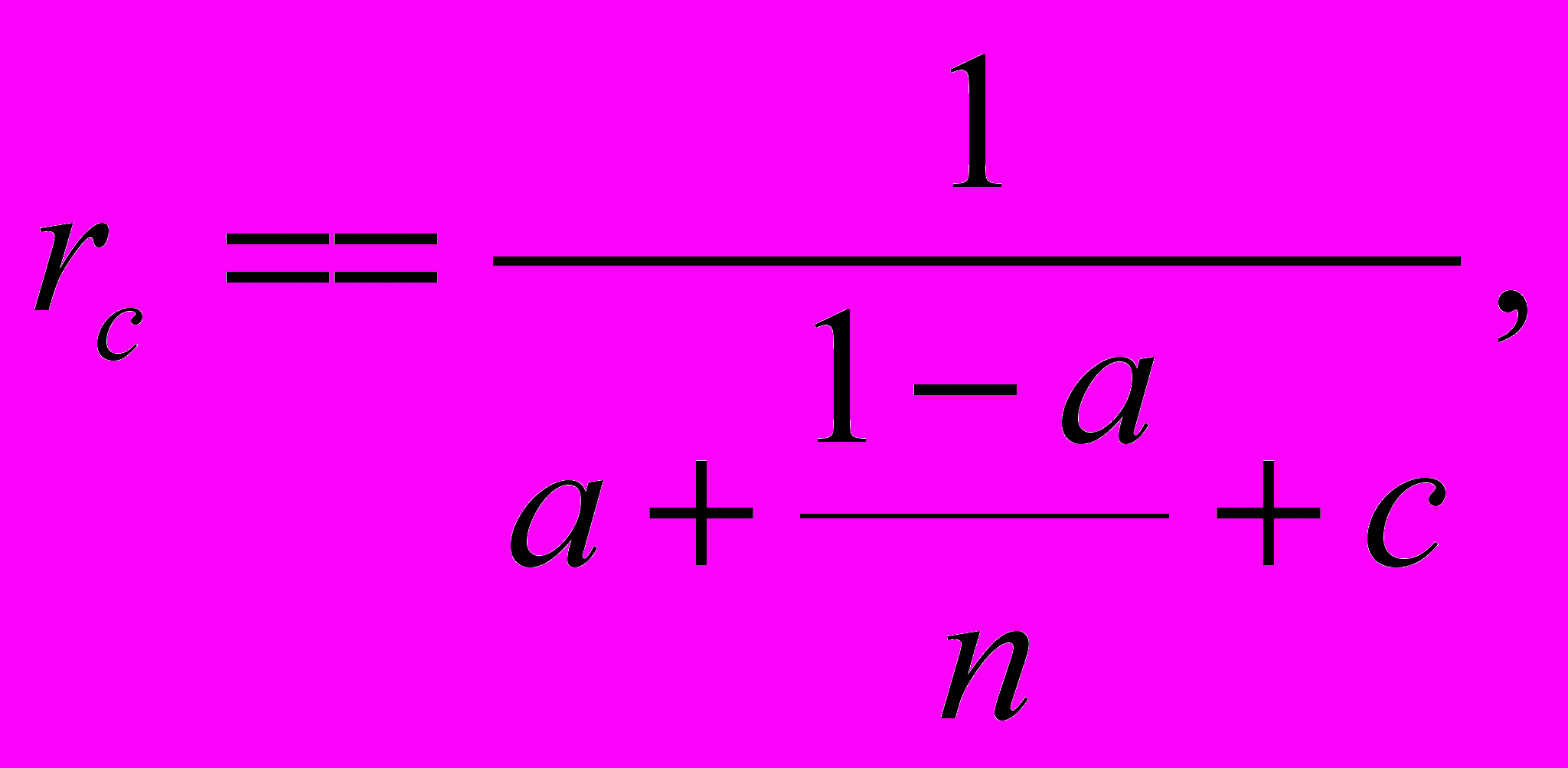 оэтому, необходимо ввести величины Wс – количество передач данных и tc – время одной передачи данных. Тогда модернизированный закон Амдала, называемый сетевым законом Амдала, будет выглядеть следующим образом:
оэтому, необходимо ввести величины Wс – количество передач данных и tc – время одной передачи данных. Тогда модернизированный закон Амдала, называемый сетевым законом Амдала, будет выглядеть следующим образом:| | | (1.1.3) |
где с = Wc·tc / W·t = cA·cT – коэффициент сетевой деградации вычислений определяет объем вычислений, приходящийся на одну передачу данных (по затратам времени). При этом cA определяет алгоритмическую составляющую коэффициента деградации, обусловленную свойствами алгоритма, а cT – техническую составляющую, которая зависит от соотношения технического быстродействия процессора и аппаратуры сети.
Из (1.1.3) видно, что для повышения скорости вычислений следует воздействовать на оба составляющие коэффициента деградации, которые зависят от множества факторов таких, как алгоритм задачи, размер данных, технические характеристики оборудования и пр.
1.2. Разновидности многопроцессорных систем
В соответствии с классификацией Флинна к многопроцессорным ЭВМ относятся ЭВМ с множественным потоком команд и множественным потоком данных (МКМД-ЭВМ или MIMD-ЭВМ).
В основе МКМД-ЭВМ лежит традиционная последовательная организация программы, расширенная добавлением специальных средств указания независимых, параллельно исполняемых фрагментов. Параллельно-последовательная программа привычна для пользователя и позволяет относительно просто собирать параллельную программу из обычных последовательных программ.
МКМД-ЭВМ имеют две разновидности: ЭВМ с разделяемой (общей) и распределенной (индивидуальной) памятью. Структура этих ЭВМ представлена на рис. 1.2.1 [8].
Главное различие между МКМД-ЭВМ с общей и индивидуальной (локальной, распределенной) памятью состоит в характере адресной системы.
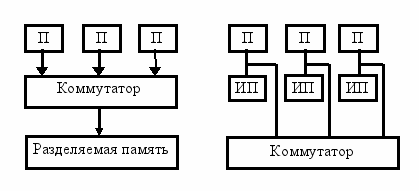
a b
Рис.1.2.1. Структура ЭВМ с разделяемой (а) и индивидуальной (b) памятью.
Здесь: П – процессор, ИП индивидуальная память.
В машинах с общей памятью адресное пространство всех процессоров является единым, следовательно, если в программах нескольких процессоров встречается одна и та же переменная VAL, то эти процессоры будут обращаться в одну физическую ячейку общей памяти. Это вызывает как положительные, так и отрицательные последствия [8, 9]:
1. Не нужно физически перемещать данные между взаимодействующими программами, которые параллельно выполняются в разных процессорах. Это исключает затраты времени на межпроцессорный обмен.
2. Поскольку одновременное обращение нескольких процессоров к общим данным может привести к получению неверных результатов, необходимо ввести систему синхронизации параллельных процессов (например, семафоры), что усложняет механизмы операционной системы.
3. Так как при выполнении каждой команды процессорам необходимо обращаться в общую память, то требования к пропускной способности коммутатора этой памяти чрезвычайно высоки, что ограничивает число процессоров в системах величиной 10...20.
МКМД-ЭВМ с индивидуальной памятью получили большое распространение ввиду относительной простоты их архитектуры. В таких ЭВМ межпроцессорный обмен осуществляется с помощью передачи сообщений.
Каждый процессор имеет независимое адресное пространство, и наличие одной и той же переменной VAL в программах разных процессоров приводит к обращению в физически разные ячейки индивидуальной памяти этих процессоров. Это вызывает физическое перемещение данных (обмен сообщениями) между взаимодействующими программами в разных процессорах, однако, поскольку основная часть обращений производится каждым процессором в собственную память, то требования к коммутатору ослабляются, и число процессоров в системах с распределенной памятью и скоростным коммутатором может достигать нескольких сотен и даже тысяч.
1.3. Техническая реализация параллельных ЭВМ
Современные многопроцессорные системы делятся на три группы:
симметричные мультипроцессоры (SMP); системы с массовым параллелизмом (МРР); кластеры [9].
Симметричные мультипроцессоры SMP (Symmetric Multi Processors) используют принцип разделяемой памяти. В этом случае система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой ячейке памяти с одинаковой скоростью. Процессоры подключены к памяти с помощью общей шины или коммутатора. Аппаратно поддерживается когерентность кэш-памяти. Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число – не более 32 в реальных системах. Вся система работает под управлением единой ОС.
Системы с массовым параллелизмом MPP (Massively Parallel Processing) содержат множество процессоров c индивидуальной памятью в каждом из них (прямой доступ к памяти других узлов невозможен), которые связаны через некоторую коммуникационную среду (высокоскоростная сеть, коммутатор и т.д.). Как правило, системы MPP благодаря специализированной высокоскоростной системе обмена, обеспечивают наивысшее быстродействие (и наивысшую стоимость).
Кластерные системы более дешевый вариант MPP-систем, поскольку они также используют принцип передачи сообщений, но строятся из компонентов высокой степени готовности. Базовым элементом кластера является локальная сеть. В качестве компьютеров могут выступать, например, рабочие станции. Оказалось, что на многих классах задач и при достаточном числе узлов такие системы дают производительность, сравнимую с суперкомпьютерной.
Первым кластером на рабочих станциях был Beowulf [10]. Проект Beowulf начался летом 1994 года сборкой в научно-космическом центре NASA 16-процессорного кластера на Ethernet-кабеле. С тех пор кластеры на рабочих станциях обычно называют Beowulf-кластерами. Любой Beowulf-кластер состоит из отдельных машин (узлов) и объединяющей их сети (коммутатора). Кроме ОС, необходимо установить и настроить сетевые драйверы, компиляторы, ПО поддержки параллельного программирования и распределения вычислительной нагрузки. В качестве узлов обычно используются однопроцессорные ПЭВМ с быстродействием 1 ГГц и выше или SMP-серверы с небольшим числом процессоров (обычно 2-4).
Для получения хорошей производительности межпроцессорных обменов, как правило, используют полнодуплексную сеть Fast Ethernet с пропускной способностью 100 Mбит/с. При этом для уменьшения числа коллизий устанавливают несколько "параллельных" сегментов Ethernet, или соединяют узлы кластера через коммутатор (switch).
В качестве операционных систем обычно используют OC Linux или Windows NT и ее варианты. В качестве языков программирования используются С, С++ и старшие версии языка Fortran.
Наиболее распространенным интерфейсом параллельного программирования в модели передачи сообщений является MPI (Message Passing Interface).
1.4. Системы программирования для многопроцессорных систем.
Стандарт MPI
Основными средствами программирования для многопроцеccорных систем являются две библиотеки, оформленные как стандарты: библиотека OpenMP для систем с общей памятью (для SMP-систем) и библиотека MPI для систем с индивидуальной памятью.
Библиотека OpenMP является стандартом для программирования на масштабируемых SMP-системах. В стандарт входят описания набора директив компилятора, переменных среды и процедур. За счет идеи "инкрементального распараллеливания" OpenMP идеально подходит для разработчиков, желающих быстро распараллелить свои вычислительные программы с большими параллельными циклами. Разработчик не создает новую параллельную программу, а просто добавляет в текст последовательной программы OpenMP-директивы.
Предполагается, что программа OpenMP на однопроцессорной платформе может быть использована в качестве последовательной программы, т.е. нет необходимости поддерживать последовательную и параллельную версии. Директивы OpenMP просто игнорируются последовательным компилятором, а для вызова процедур OpenMP могут быть поставлены заглушки, текст которых приведен в спецификациях. В OpenMP любой процесс состоит из нескольких нитей управления, которые имеют общее адресное пространство, но разные потоки команд и раздельные стеки. В простейшем случае, процесс состоит из одной нити.
Стандарт MPI. Система программирования MPI предназначена для ЭВМ с индивидуальной памятью, то есть для многопроцессорных систем с обменом сообщениями. MPI имеет следующие особенности:
1. MPI библиотека функций, а не язык. Она определяет состав, имена, вызовы функций и результаты их работы. Программы, которые пишутся на языках FORTRAN, C и C++, компилируются обычными компиляторами и связаны с MPI-библиотекой.
2. MPI описание функций, а не реализация. Все поставщики параллельных компьютерных систем предлагают реализации MPI для своих машин бесплатно, реализации общего назначения также могут быть получены из Internet. Правильная MPI-программа должна выполняться на всех реализациях без изменения.
В модели передачи сообщений процессы, выполняющиеся параллельно, имеют раздельные адресные пространства. Обмен происходит, когда часть адресного пространства одного процесса скопирована в адресное пространство другого процесса. Эта операция совместная и возможна только, когда первый процесс выполняет операцию передачи сообщения, а второй процесс операцию его получения.
Процессы в MPI принадлежат группам. Если группа содержит n процессов, то процессы нумеруются внутри группы номерами, которые являются целыми числами от 0 до n-l. Имеется начальная группа, которой принадлежат все процессы в реализации MPI.
Контекст есть свойство коммуникаторов, которое позволяет разделять пространство обмена. Сообщение, посланное в одном контексте, не может быть получено в другом контексте. Контексты не являются явными объектами MPI, они проявляются только как часть реализации коммуникаторов.
Понятия контекста и группы объединены в едином объекте, называемом коммуникатором. Таким образом, отправитель или получатель, определенные в операции посылки или получения, всегда обращается к номеру процесса в группе, идентифицированной данным коммуникатором.