
Курс лекций по дисциплине «Базы данных в гис» для студентов факультета «Геодезия картография и землеустройство» Николаев 2008 г
| Вид материала | Курс лекций |
- Курс лекций по дисциплине «Компьютерные сети и телекоммуникации» для студентов факультета, 1959.57kb.
- Лекция №3. Организация данных в гис первым шагом к проекту гис является создание пространственной, 268.29kb.
- Учебно-методический комплекс по дисциплине «Базы данных» для студентов специальности, 536.91kb.
- Мирончик Игорь Янович ClipperIgor@gmail com (496)573-34-22 курс лекций, 28.92kb.
- Методические указания к самостоятельной работе студентов по курсу "Базы данных" Москва, 92.31kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция Язык sql. Создание таблиц и ограничений, 146.46kb.
- Лекций для студентов 4 курса педиатрического факультета, переведенных на контролируемую, 18.72kb.
- Курсовая работа по дисциплине «Базы данных» на тему: «Разработка базы данных для учета, 154.05kb.
- Курс лекций для студентов заочного факультета самара, 1339.16kb.
- Конспект лекций по курсу "базы данных" (Ч., 861.92kb.
Модуль 3. Ресурси баз даних
Закон Букера.
Навіть маленька практика варта великої теорії
3.1.Модели данных в ГИС
Информационное обеспечение в ГИС основывается на применении банков данных. СУБД – это программное обеспечение, предназначенное для манипулирования информацией в базе данных. Манипулирование – извлечение, уничтожение, перемещение.
База данных – структурная информация, записанная в определённом виде на магнитные носители. Банк данных – это совокупность СУБД и баз данных.
Различаются три вида СУБД. По общему виду структуры представления данных – так называемые модели данных: иерархические, сетевые и реляционные. Среди них наибольшее распространение получили последние. В настоящее время иерархические и сетевые модели значительно уступают реляционным по количеству реализаций в коммерческих СУБД, поэтому ограничимся здесь их кратким описанием
В иерархических моделях данные организованы в виде иерархической структуры (имеющей вид "дерева"), в которой исходные элементы порождают другие элементы, причем эти элементы в свою очередь порождают следующие элементы и т.д. Элементы (поля), связывающие верхние и нижние уровни иерархии, отражают принципиальную особенность иерархической организации данных: каждая запись приобретает смысл лишь тогда, когда она рассматривается в определенном контексте. Иными словами, любой подчиненный элемент не может существовать без своего предшественника по иерархии. Иерархические модели БД чрезвычайно привлекательны для целей географических исследований, так как обеспечивают естественный и адекватный метод информационного моделирования реальных, иерархически организованных географических объектов: экономических районов и природных ландшафтов, систем расселения и гидрографических сетей, систем обслуживания и административно-территориальных единиц. В то же время, несмотря на то, что иерархическая модель по самой своей сути ориентирована на организацию данных в территориальном разрезе, любые другие выборки (отраслевые, классификационные) хотя и возможны, но связаны со значительными затратами времени на поиск необходимой информации. В этом состоит основной недостаток иерархической модели данных.
Сетевые модели допускают любые группировки данных и произвольные связи между ними, и в этом смысле являются универсальными. Однако структура сетевой модели обычно намного сложнее иерархической, и для переходов (навигации) в такой БД необходимы дополнительные вычислительные ресурсы. В отличие от иерархической, в сетевой структуре можно легко производить удаление устаревшей информации без риска потерять нужные сведения. "Узкое место" сетевого подхода состоит в необходимости выбора стратегии поиска необходимой информации (эта проблема аналогична нахождению кратчайшего пути между двумя пунктами сложной и разветвленной сети), что сопряжено с трудностями программного и вычислительного характера.
Несмотря на отмеченные недостатки, иерархическая и сетевая модели будут существовать и использоваться еще в течение достаточно длительного времени, так как на создание соответствующих БД затрачены значительные средства и здесь уже накоплен большой опыт.
Реляционная модель базы данных была предложена в 1970 году американским ученым Коддом. Она основана на представлении данных в виде отношений между ними. При этом представление этих отношений подвергается нормализации - пошаговому процессу приведения к двухмерной табличной форме, причем информация об отношениях сохраняется полностью. Представление данных в виде двухмерных таблиц является естественным и хорошо воспринимается пользователями. Под таблицами в данном случае понимают прямоугольные массивы, обладающие следующими свойствами:
- элементу данных соответствует единственный вход в таблицу;
- в каждой из колонок таблицы располагаются элементы некоторого вида;
- каждой колонке присваивается имя;
- не допускаются строки таблиц с совпадающими значениями всех колонок;
- колонки и строки таблиц могут просматриваться в любой последовательности.
- Отношения в реляционной модели базы данных представлены таблицами, в которых каждая из строк содержит значения свойств (или атрибутов), которыми обладает некоторый объект данного типа;
- каждый из столбцов соответствует множеству значений, которые принимает некоторый атрибут этого типа.
- Совокупность значений одного атрибута (соответствующая столбцу таблицы) называется его доменом. Для описания отношений и манипуляций над ними в реляционной модели данных используется строгий математический язык, основанный на алгебре отношений и исчислении отношений. При этом возможны три уровня сопряжения пользователя с базой данных: на высшем уровне пользователь формулирует свои запросы в терминах реляционного исчисления, определяя, какие новые отношения он желает образовать из существующих; на среднем уровне запрос формулируется как последовательность операций реляционной алгебры, выполняемых над отношениями;
- на самом низком уровне пользователь определяет шаги получения некоторого кортежа отношения (кортежами называются строки таблицы отношения), т.е. полностью управляет поиском данных в базе данных.
Основное свойство реляционных моделей данных - связи между кортежами разных отношений прослеживаются только в одинаковых значениях атрибутов, извлеченных из общего домена. Таким образом, реляционный подход реализует оригинальную идею - рассматривать связи между объектами как специальные типы объектов. Следовательно, вся информация в базе данных, как "объекты", так и "связи", могут быть представлены в единой унифицированной форме (информационно-логическая модель базы данных). Этим преимуществом не обладают иерархический и сетевой подходы.
Розуміння суті БД необхідне для ефективного звернення із запитами до різних видалених БД, для усвідомлення дисципліни колективного використання БД, а також для орієнтації в особливостях проектування схем БД.
Один кінцевий користувач може мати справу з інформаційними ресурсами (базами даних) декількох рівнів. Він може створювати і модифікувати персональні БД, використовувати і поповнювати БД робочих груп та БД корпорації, звертатися із запитами до зовнішніх БД, які поповнюються і ведуться іншими організаціями.
Всі дії з БД забезпечуються програмною системою управління базами даних (СУБД). СУБД необхідні менеджеру для створення і модифікації персональних БД, а також для вільного виконання ситуативних (ad-hoc) запитів до особистості та інших БД (робочих груп, організації, корпорації, зовнішніх). Якщо на робочому місці створюється багато однорідних структурованих даних, то особисту БД ефективніше вести засобами СУБД, а не засобами електронних таблиць.
Кожна СУБД звичайно має власну мову програмування додатків, що використовують базу даних. Для комп'ютеризації функціональних завдань, що засновані на базах даних всі програми розробляються програмістами. Тут програмування має максимальну ефективність, оскільки масові початкові вихідні дані та алгоритми, визначені наперед, жорстко регламентовані, мають стабільну структуру. Цей вид завдань, що називалися раніше рутинними, зараз називають завданнями, які визначені наперед.
На середньому ж і вищому рівнях менеджменту програмується лише частина задач, оскільки тут практично немає масових і визначених наперед завдань. Тут менеджерам понад усе необхідні засоби ситуативних запитів до різних баз даних, а також системи підтримки ухвалення рішень (СПУР) і електронні таблиці для оперативного формування проблемної аналітичної інформації.
3.2.Основні поняття БД
Активна діяльність щодо пошуку прийнятних способів узагальнення обсягу інформації, що безперервно зростає, призвела до створення на початку 60-х років спеціальних програмних комплексів, які стали називатися "Системи управління базами даних" (СУБД).
Основна особливість СУБД – це наявність процедур для введення і зберігання не тільки самих даних, але й описів їх структури. Файли, забезпечені описом даних, що зберігаються в них, і СУБД, що знаходяться під управлінням, стали називати банки даних, а потім "Бази даних" (БД).
Поняття "база даних означає сукупність даних, призначених для спільного використання. Розрізняють документальну БД (сукупність текстових документів вільних форматів) і фактографічну БД (сукупність відомостей, що зберігаються в інформаційній системі і організованих відповідно до вимог будь-якого фіксованого набору форматів). Дані, що зберігаються в документальних і фактографічних БД, заносяться в ці сховища, модифікуються і використовуються за допомогою СУБД.
СУБД відноситься до набору засобів програмного забезпечення, створених для роботи з фактографічними даними, структура яких набагато складніша, ніж структура неформатованих текстових документів. Проте існують СУБД, які можуть працювати з різними типами БД (у цих випадках звичайно домовляються, що до складу СУБД включений текстовий редактор). Існують СУБД, створені спеціально для зберігання і пошуку текстових документів, а також СУБД для зберігання графічних об'єктів (карт, креслень).
Ключовими поняттями БД і СУБД є фізичне і логічне подання даних, незалежність даних, моделі даних.
Фізичні дані, або фізичне подання даних, це дані, які зберігаються в пам'яті комп'ютера на фізичних носіях (магнітних дисках, оптичних дисках і т. ін.).
Дані можуть зберігатися і безпосередньо в оперативній пам'яті, якщо їх небагато або якщо вони повинні використовуватися в терміново. Великі обсяги даних зберігаються у вторинній швидкодіючій пам'яті, на пристроях, що запам'ятовують, з прямим доступом, перш за все на дисках. Послідовний доступ до даних магнітних стрічок не забезпечує необхідної швидкості роботи з БД, тому БД на магнітних стрічках застаріли, але їх продовжують використовувати для зберігання архіву БД і дублювання дискової БД. Коли інженери говорять про фізичне подання даних, йдеться про номери дисків, сектори й доріжки дисків, про номери блоків і байтів. Це серйозно ускладнювало б роботу кінцевого користувача БД - економіста, менеджера. Головна перевага СУБД в тому і полягає, що користувач звільняється від розуміння фізичного подання даних і управляє даними на рівні логічного подання.
Логічне подання відповідає фізичному, але оперує звичними для користувача назвами документів, таблиць, стовпців (полів, елементів, атрибутів). На логічному рівні наочно відображаються взаємозв'язки між даними і задаються відношення "суть - зв'язок".
Поняття незалежності даних означає, що сучасні СУБД забезпечують користувачу незалежність від організації фізичних даних. У традиційних файлових системах немає незалежності даних, що призводить до жорсткості системи і викликає труднощі при внесенні змін у прикладні програми при додаванні нових даних або зміні структури файлу.
Логічно подати дані можна по-різному, у зв'язку з цим велике значення має поняття моделі даних.
Модель даних - це спосіб визначення логічного подання фізичних даних, що зберігаються для певних цілей. Моделлю даних називається також формалізований опис структури одиниць інформації і операцій над ними в інформаційній системі з метою подання основних категорій реального світу - об'єктів, їх зв'язків і властивостей. У британському тлумачному словнику з обчислювальних систем модель даних (data model) визначається так: "Термін, використовуваний в різних випадках у зв'язку із зберіганням даних на фізичному або логічному рівні, частіш на першому. Звичайно йдеться про формально певну структуру, яка використовується для подання даних".
Наведені вище визначення доповнюють один одного. Важливо розуміти, що модель даних - це не самі дані, а дані про дані (метадані), які характеризують принцип організації одиниць інформації і допустимі операції над ними.
Відомі різні типи моделей даних, з яких найбільш поширені реляційна, мережева та ієрархічна. Проте з теоретичної точки зору дві останні моделі є окремими випадками загального реляційного подання. Основою багатьох високопродуктивних СУБД стала реляційна модель даних (суть трьох моделей зображена на рис. 5.1.1 на прикладі організації взаємопов’язаної порції даних:
СЛУЖБОВЕЦЬ, НАЧАЛЬНИК, ТЕЛЕФОН.
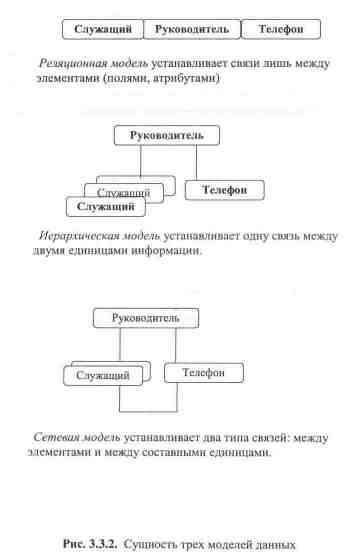
Рис 5.1.1 Суть трьох моделей даних
В основі реляційного подання даних є проста таблиця, тому далі ми можемо говорити про таблиці і реляційну модель.
Модель даних має три компоненти;
- структуру даних користувача,
- допустимі операції з метою визначення нових БД;
- обмеження для контролю цілісності даних з метою охорони БД і її захисту від некоректного оновлення і обігу.
Наприклад, реляційна модель даних не допускає в таблиці існування двох однакових записів (кортежів). Т. б. обмеження вимагає, щоб кожен кортеж (ланцюг взаємопов'язаних полів) був унікальним екземпляром. Якщо ж користувач введе в таблицю два однакові кортежі, то СУБД знайде їх і, принаймні, сповістить користувача про це, а також автоматично запитає, який з екземплярів необхідно видалити. У СУБД заборона викликана необхідністю коректного пошуку й операцій, пов'язаних з модифікацією даних. Якщо СУБД дозволяє користувачу мати дублікати рядків, то її називають псевдореляційною, підкреслюючи тим самим, що користувачу надається обмежене коло операцій з даними.
До основних термінів БД входить також поняття схеми бази даних. У зарубіжних публікаціях частіше використовують термін "схема", але застосовують також і термін "модель БД". Є небезпека переплутати модель даних з моделлю бази даних, тому краще використовувати термін "схема БД". Модель даних задає для СУБД єдиний принцип опису структури будь-якої одиниці даних, а модель (схема) бази даних дає узагальнене подання структури всіх необхідних одиниць. За допомогою схеми зміст логічної БД робиться більш досяжним і зручним для сприйняття його людиною. Проте неможливо обійтися одним поняттям схеми БД, коли є декілька користувачів, і у кожного з них - свої потреби в даних і своє уявлення про частину використовуваних загальних даних, що зберігаються, наприклад, на сервері.
Схема бази даних відображає співвідношення частин і цілого, тобто уявлень користувачів БД про "власну частину" з глобальним, концептуальним подання БД всієї інформаційної системи.
Це відображено на рис. 5.1.2.
Наприклад, якщо дані про наявність товарів на складі, що зберігаються в таблиці з ім'ям "С", необхідні трьом користувачам (завідувачу складом, адміністратору магазину і керівнику підприємства), то в узагальненій схемі, так званій концептуальній схемі, файл наявності товарів присутній лише один раз із вказівками про обмеження на допуск до файлу: всі три користувачі мають право читати дані і лише один з них (завідувач складу) має право модифікувати записи у файлі. Концептуальна і зовнішні схеми БД є найважливішими інструментами для адміністратора БД, який адмініструє права кожного користувача БД в інформаційній системі (ІС).
Коло даних окремого користувача, тобто таблиць, з якими він має право працювати, утворює зовнішню схему БД. В ІС існує єдина концептуальна схема і декілька зовнішніх схем БД. Характерним є те, що концептуальна схема не є простим поєднанням зовнішніх схем. Розраховані на велику кількість користувачів дані (ситуація з таблицею "С" на рис. 6.2.2) в концептуальній моделі відображаються одноразово з додатковими обмеженнями на допуск до даних (повноваженнями). Крім того, в концептуальній схемі відображаються логічні взаємозв'язки (відносини) між елементами даних на рівні полів (елементів даних).
р
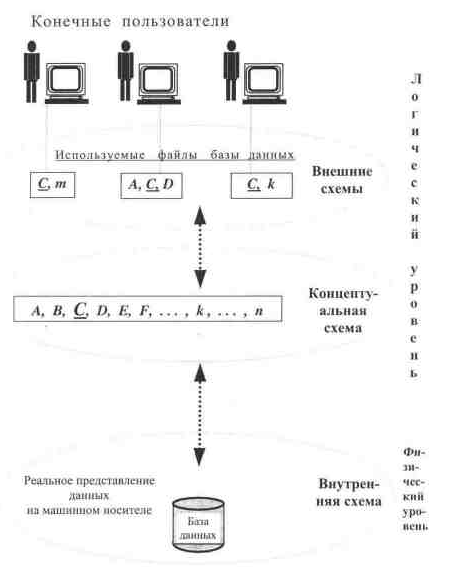
ис 5.1.2. Ієрархія схем і рівнів баз даних в інформаційних системах
У вітчизняній і зарубіжній літературі, що стосується даних, існує багато синонімів основних понять. Інформаційні об'єкти (товари, склади і т. ін.) називають суттю; властивості об'єктів називають реквізитами, полями, елементами, атрибутами суті; зовнішні схеми називають операційними схемами і даталогічними моделями, а концептуальну схему - концептуальною моделлю або інфологічною моделлю. Поняття логічного і фізичного подання, зовнішньої і концептуальної схем відносять до сфери опису архітектури СУБД, також як і поняття внутрішньої схеми, яка забезпечує відповідність логічної структури зовнішньої моделі і фізичного подання даних на носіях.
3.3. Архітектура СУБД
СУБД повинна надавати доступ до даних будь-яким користувачам, включаючи і тих, які практично не мають і (або) не хочуть мати уявлення про:
- фізичне розміщення в пам'яті даних та описів;
- механізми пошуку даних, що в процесі запиту;
- проблеми, що виникають при одночасному запиті одних і тих же даних багатьма користувачами (прикладними програмами);
- способи забезпечення захисту даних від некоректних оновлень і (або) несанкціонованого доступу;
- підтримку баз даних в актуальному стані;
- та безліч інших функцій СУБД.
При виконанні основних з цих функцій СУБД повинна використовувати різні описи даних. А як створювати ці описи?
Природно, що проект бази даних треба починати з аналізу предметноїнаочної області і виявлення вимог до неї окремих користувачів (співробітників організації, для яких створюється база даних). Докладніше цей процес буде розглянутий нижче, а тут зазначимо, що проектування звичайно доручається людині (групі осіб) – адміністратору бази даних (АБД). Ним може бути як спеціально обраний співробітник організації, так і майбутній користувач бази даних, достатньо добре знайомий з машинною обробкою даних.
О
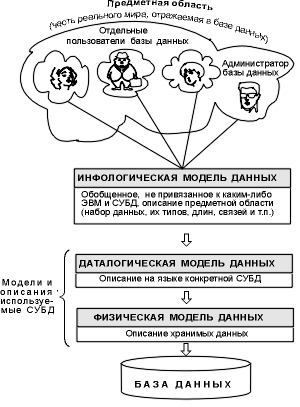
б'єднуючи особисті подання про вміст бази даних, одержані в результаті опиту користувачів, і свої уявлення про дані, які можуть знаходитись в майбутніх додатках, АБД спочатку створює узагальнений неформальний опис створюваної бази даних. Цей опис, виконаний з використанням природної мови, математичних формул, таблиць, графіків та інших засобів, зрозумілих всім людям, що працюють над проектуванням бази даних, називають інфологічною моделлю даних (рис. 5.1.3).
Рис. 5.1.3. Рівні моделей даних
Така людино-орієнтована модель повністю незалежна від фізичних параметрів середовища зберігання даних. Врешті-решт цим середовищем може бути пам'ять людини, а не ЕОМ. Тому інфологічна модель не повинна змінюватися до тих пір, поки якісь зміни в реальному світі не зажадають зміни в ній певного визначення, щоб ця модель продовжувала відображати предметну область.
Решта моделей, зображених на рис. 5.1.3, є комп’ютерно-орієнтовними. З їх допомогою СУБД дає можливість програмам і користувачам здійснювати доступ до даних, що зберігаються, лише за їх іменами, не турбуючись про фізичне розміщення цих даних. Потрібні дані відшукуються СУБД на зовнішніх пристроях, що запам'ятовують, по фізичною моделлю даних.
Оскільки зазначений доступ здійснюється за допомогою конкретної СУБД, то моделі повинні бути описані на мові даних цієї СУБД. Такий опис, створюваний АБД за інфологічною моделлю даних, називають даталогічною моделлю даних.
Трирівнева архітектура (інфологічний, даталогічний і фізичний рівні) дозволяє забезпечити незалежність даних, що зберігаються, від програм які їх використовують. АБД може при необхідності переписати дані, що зберігаються, на інші носії інформації і (або) реорганізувати їх фізичну структуру, змінивши лише фізичну модель даних. АБД може підключити до системи будь-яку кількість нових користувачів (нових додатків), доповнивши, якщо треба, даталогічну модель. Вказані зміни фізичної і даталогічної моделей не будуть помічені існуючими користувачами системи (виявляться "прозорими" для них), так само як не будуть помічені і нові користувачі. Отже, незалежність даних забезпечує можливість розвитку системи баз даних без руйнування існуючих додатків.
Інфологічна модель відображає реальний світ в деякі зрозумілі людині концепції, повністю незалежні від параметрів середовища зберігання даних. Існує безліч підходів до побудови таких моделей: графові моделі, семантичні мережі, модель "суть-зв'язок" і т.ін. Найпопулярнішою з них виявилася модель "суть-зв'язок", яка буде розглянута нижче.
Інфологічна модель повинна бути відображена в комп'ютерно-орієнтовній даталогічній моделі, "зрозумілій" СУБД. В процесі розвитку теорії і практичного використання баз даних, а також засобів обчислювальної техніки створювалися СУБД, що підтримують різні даталогічні моделі.
Спочатку стали використовувати ієрархічні даталогічні моделі. Простота організації, наявність наперед заданих зв'язків між суттю, подібність з фізичними моделями даних дозволяли добиватися прийнятної продуктивності ієрархічних СУБД на повільних ЕОМ з вельми обмеженими обсягами пам'яті. Але, якщо дані не мали деревовидної структури, то виникало безліч труднощів при побудові ієрархічної моделі і бажанні добитися потрібної продуктивності.
Мережеві моделі також створювалися для мало ресурсних ЕОМ. Це достатньо складні структури, що складаються з "наборів" – так званих дворівневих дерев. "Набори" з'єднуються за допомогою "записів-зв'язок", утворюючи ланцюжки і т.ін. Один із розробників операційної системи UNIX сказав "Мережева база – це найвірніший спосіб втратити дані".
Труднощі у практичному використанні ієрархічних і та мережевих СУБД примушували шукати інші способи подання даних. У кінці 60-х років з'явилися СУБД на основі інвертованих файлів, що відрізнялися простотою організації і наявністю вельми зручних мов маніпулювання даними. Проте таким СУБД притаманний ряд обмежень на кількість файлів для зберігання даних, кількість зв'язків між ними, довжину запису і кількість її полів. Сьогодні найбільш поширені реляційні моделі, які будуть детально розглянуті в наступних розділах.
Фізична організація даних в основному впливає на експлуатаційні характеристики БД. Розробники СУБД намагаються створити найпродуктивніші фізичні моделі даних, пропонуючи користувачам той або інший інструментарій для піднастройки моделі під конкретну БД. Різноманітність способів коректування фізичних моделей сучасних промислових СУБД не дозволяє розглянути їх в цьому посібнику.
3.4. Інфологічна модель даних "Суть-зв'язок". Основні поняття
Мета інфологічного моделювання – забезпечення найприродніших для людини способів збору і подання тієї інформації, яку передбачається зберігати в створюваній базі даних. Тому інфологічну модель даних намагаються будувати за аналогією з природною мовою (остання не може бути використана через складність комп'ютерної обробки текстів і неоднозначності будь-якої природної мови). Основними конструктивними елементами інфологічних моделей є суть, зв'язки між ними та їх властивості (атрибути).
Суть – це будь-який відмітний об'єкт (об'єкт, який ми можемо відрізнити від іншого), інформацію про який необхідно зберігати в базі даних.
Суттю можуть бути люди, місця, літаки, рейси, смак, колір і т.ін. Необхідно розрізняти такі поняття, як тип суті та екземпляр суті. Поняття тип суті відноситься до набору однорідних осіб, предметів, подій або ідей, які є цілим. Екземпляр суті відноситься до конкретної речі в наборі. Наприклад, типом суті може бути МІСТО, а екземпляром – Москва, Київ і т.ін.
Атрибут – пойменована характеристика суті. Його найменування повинне бути унікальним для конкретного типу суті, але може бути однаковим для різного типу суті (наприклад, КОЛІР може бути визначений для багатьох сутностей: СОБАКА, АВТОМОБІЛЬ, ДИМ і т.ін.).
Атрибути використовуються для визначення того, яка інформація повинна бути зібрана про суть. Прикладами атрибутів для суті АВТОМОБІЛЬ є ТИП, МАРКА, НОМЕРНИЙ ЗНАК, КОЛІР і т.ін. Тут також існує відмінність між типом і екземпляром. Тип атрибуту КОЛІР має багато екземплярів або значень: Червоний, Синій, Банановий, Біла ніч і т.ін., проте кожному екземпляру суті привласнюється тільки одне значення атрибуту.
Абсолютна відмінність між типами суті і атрибутами відсутня. Атрибут є таким тільки у зв'язку з типом суті. У іншому контексті атрибут може виступати як самостійна суть. Наприклад, для автомобільного заводу колір – це тільки атрибут продукту виробництва, а для лакофарбної фабрики колір – тип суті.
Ключ – мінімальний набір атрибутів, за значенням яких можна однозначно знайти необхідний екземпляр суті. Мінімальність означає, що вилучення з набору будь-якого атрибуту не дозволяє ідентифікувати суть за тими, що залишаються.
Для суті Розклад ключем є атрибут Номер рейсу або набір: Пункт відправлення, Час вильоту і Пункт призначення (за умови, що з пункту в пункт вилітає в певний момент часу один літак).
Зв'язок – асоціювання двох або більше сутностей.
Якби призначенням бази даних було тільки зберігання окремих, не пов'язаних між собою даних, то її структура могла б бути дуже простою. Проте одна з основних вимог до організації бази даних – це забезпечення можливості пошуку однієї суті за значенням інших, для чого необхідно встановити між ними певні зв'язки. А оскільки в реальних базах даних нерідко містяться сотні або навіть тисячі сутностей, то теоретично між ними може бути встановлено більше мільйона зв'язків. Наявність такої безлічі зв'язків і визначає складність інфологічних моделей.
Характеристика зв'язків і мова моделювання
При побудові інфологічних моделей можна використовувати мову ER-діаграм (від англ. Entity-Relationship, тобто суть-зв'язок). У них суть зображена позначеними прямокутниками, асоціації – ромбами або шестикутниками, атрибути – поміченими овалами, а зв'язки між ними – ненаправленими ребрами, над якими може проставлятися ступінь зв'язку (1 або буква, що замінює слово "багато") і необхідне пояснення.
Між двома сутностями, наприклад, А і В можливі чотири види зв'язків.
Перший тип – зв'язок ОДИН-ДО-ОДНОГО (1:1): у кожен момент часу кожному представнику (екземпляру) суті А відповідає 1 або 0 представників суті В:

Студент може не "заробити" стипендію, одержати звичайну або одну з підвищених стипендій.
Другий тип – зв'язок ОДИН-ДО-БАГАТЬОХ (1:Б): одному представнику суті А відповідають 0, 1 або декілька представників суті В.

Квартира може бути порожньою, в ній може проживати один або кілька мешканців.
Оскільки між двома сутностями можливі зв'язки в обох напрямах, то існує ще два типи зв'язку БАГАТО-ДО-ОДНОГО (Б:1) і БАГАТО ДО-БАГАТЬОХ (М:N).
Приклад 1. Якщо зв'язок між сутностями ЧОЛОВІКИ і ЖІНКИ називається ШЛЮБ, то існує чотири можливих подання такого зв'язку:
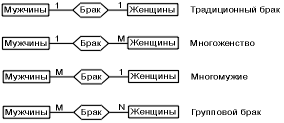
Характер зв'язків між сутностями не обмежується переліченими. Існують і складніші зв'язки:
- безліч зв'язків між однією і тією ж суттю

(пацієнт, маючи одного лікаря, який його лікує, також може мати кількох лікарів-консультантів; лікар може бути лікувати одних пацієнтів, а також давати консультації кільком іншим);
- тринарні зв'язки
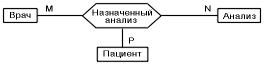
(лікар може направити кількох пацієнтів на здавання кількох аналізів, аналіз може бути призначений кількома лікарями кільком пацієнтам і пацієнт може бути призначений на кілька аналізів кількома лікарями);
- зв'язки вищих порядків, семантика (значення) яких іноді дуже складна.
У наведених прикладах для підвищення ілюстративності даних зв'язків не подані атрибути суті і асоціацій у всіх ER-діаграмах. Так, введення лише декількох основних атрибутів в опис шлюбних зв'язків значно ускладнить ER-діаграму. У зв'язку з цим мова ER-діаграм використовується для побудові невеликих моделей та ілюстрації окремих фрагментів великих. Частіше ж застосовується менш наочна, але змістовніша мова інфологічного моделювання (МІМ), в якій суть і асоціації подаються у вигляді пропозицій:
СУТЬ (атрибут 1, атрибут 2, ..., атрибут n)
АСОЦІАЦІЯ [СУТЬ S1, СУТЬ S2, ...]
(атрибут 1, атрибут 2, ..., атрибут n)
де S – ступінь зв'язку, а атрибути, що належать до ключа, повинні бути відзначені за допомогою підкреслювання.
Так, розглянутий вище приклад з безліччю зв'язків між суттю, може бути описаний на МІМ таким чином:
Лікар (Номер_лікаря, Прізвище, Ім'я, По батькові, Спеціальність)
Пацієнт (Реєстраційний_номер, Номер ліжка, Прізвище,
Ім'я, По батькові, Адреса, Дата народження, Стать)
Лікар, що лікує [Лікар 1, Пацієнт M]
(Номер_лікаря, Реєстраційний_номер)
Консультант [Лікар M,Пацієнт N]
(Номер_лікаря, Реєстраційний номер).
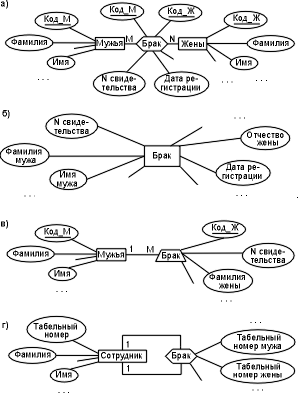
рис. 5.1.4. Приклади ER-діаграм
Для виявлення зв'язків між суттю необхідно, принаймні, визначити саму суть. Але це не просте завдання, оскільки в різних предметних областях один і той же об'єкт може бути суттю, атрибутом або асоціацією. Проілюструємо таке твердження на прикладах, пов'язаних з описом шлюбних зв'язків.
Приклад 2. Відділ записів актів громадянського стану (ЗАГС) займається реєстрацією шлюбу, народження або смерті. Тому в країнах, де допускаються лише традиційні шлюби, відділи ЗАГС можуть містити відомості про реєстрацію шлюбу в єдиній суті:
ШЛЮБ (Номер_свідоцтва,Прізвище чоловіка, Ім’я чоловіка, По батькові чоловіка,
Дата народження чоловіка, Прізвище дружини, Дата реєстрації, Місце реєстрації, ...),
ER-діаграма якої наведена на рис. 5.1.4 (б)
Приклад 3. Тепер розглянемо ситуацію, коли відділ ЗАГС знаходиться в країні, яка дозволяє багатоженство. Якщо для реєстрації шлюбів використовувати суть "Шлюб" прикладу 2., то дублюватимуться відомості про чоловіків, що мають кількох дружин (див. табл. 5.1).
Таблиця 5.1
| Номер свідоцтва | Прізвище чоловіка | ... | Прізвище дружини | ... | Дата реєстрації |
| 1-ЮБ 154745 | Пєтухов | ... | Курочкіна | ... | 06/03/1991 |
| 1-ЮБ 163489 | Пєтухов | ... | Пеструшкіна | ... | 11/08/1991 |
| 1-ЮБ 169887 | Пєтухов | ... | Рябова | ... | 12/12/1992 |
| 1-ЮБ 169878 | Селезнєв | ... | Уточкіна | ... | 12/12/1992 |
| 1-ЮБ 154746 | Парасюк | ... | Свинюшкіна | ... | 06/03/1991 |
| 1-ЮБ 169879 | Парасюк | ... | Хавронія | ... | 12/12/1992 |
| ... | ... | ... | ... | ... | ... |
Дублювання можна виключити створенням додаткової суті "Чоловіки"
Чоловіки (Код_М, Прізвище, Ім'я, По батькові, Дата народження, Місце народження)
і заміною суті "Шлюб" характеристикою (див. п.3) з посиланням на відповідний опис по суті "Чоловіки".
Шлюб (Номер свідоцтва, Код_Ч, Прізвище дружини, ...,
Дата реєстрації, ...){Чоловіки}.
ER-діаграма зв'язку цієї суті показана на рис. 5.1.4. в, а приклад їх екземплярів в табл. 5.2 і 5.3.
Таблиця 5.2
| Код Ч | Прізвище | Ім'я | По батькові | Рік/нар. | Місце народж. |
| 111 | Пєтухов | Альфред | Остапович | 1971 | м. Цапелька |
| 112 | Селезнєв | Вавила | Абрамович | 1973 | м. Гусєв |
| 113 | Парасюк | Горацій | Федулович | 1972 | м. Свиньїн |
Таблиця 5.3
| Номер свідоцтва | Код -Ч | Прізвище дружини | Ім’я дружини | Дата реєстрації |
| 1-ЮБ 154745 | 111 | Курочкина | Августина | 06/03/1991 |
| 1-ЮБ 163489 | 111 | Пеструшкина | Маріана | 11/08/1991 |
| 1-ЮБ 169887 | 112 | Рябова | Мілана | 12/12/1992 |
| 1-ЮБ 169878 | 112 | Уточкина | Вероніка | 12/12/1992.. |
| 1-ЮБ 154746 | 113 | Свинюшкіна | Ельвіра | 06/03/1991.. |
| 1-ЮБ 169879 | 113 | Хавронія | Руфіна | 12/12/1992.. |
Приклад 4. Нарешті, розглянемо випадок, коли якій-небудь організації знадобились дані про наявність в ній сімейних пар, а для зберігання відомостей про співробітників вже є суть
Співробітники (Табельний_номер, Прізвище, Ім'я, ...).
Використання, розглянутої в прикладі 2, суті Шлюб" недоцільне: у сутті" Співробітники" вже є прізвища, імена, по батькові подружжя. Тому створимо асоціацію
Шлюб [Співробітник 1, Співробітник 1]
(Табельний номер чоловіка, Табельний номер дружини, ...),
з'єднуючи між собою певні екземпляри суті "Співробітники" (рис. 5.1.4, г).
Зазначимо, що ER-діаграма рис. 5.1.4,а описує структуру розміщення даних про шлюби у відділах ЗАГС країн, що допускають групові шлюби, а ER-діаграми прикладу 5.1.4, описи будь-яких видів шлюбів у організаціях, де є суть "чоловіка" і "жінки", включаючи неодружених.
Що ж таке "зв'язок"? У ER-діаграмах це лінія, що з’єднує геометричні фігури, що відображають суть, атрибути, асоціації та інші інформаційні об'єкти. У тексті ж цей термін використовується для вказівки на взаємозалежність суті. Якщо ця взаємозалежність має атрибути, то вона називається асоціацією.
На завершення розглянемо приклад побудови інфологічної моделі бази даних "харчування", де повинна зберігатися інформація про страви (рис. 5.1.5.), їх щоденне споживання, продукти, з яких готуються ці страви, і постачальників цих продуктів. Інформація буде використовуватись кухарем і керівником невеликого підприємства громадського харчування, а також його відвідувачами.
Ламану очищену квасолю, нашаткований лук посолити, посипати перцем і припустити в маслі з невеликою кількістю бульйону; додати кинзу, зелень петрушки, рейган (базилік) і довести до готовності. Потім запекти в духовці. Квасоля стручкова (свіжа або консервована) 200, Цибуля зелена 40, Масло вершкове 30, Зелень 10.Вихід 210. Калорій 725. |
Рис. 5.1.5. Приклад кулінарного рецепту
За допомогою зазначених користувачів виділені такі об'єкти і характеристики бази, що проектується:
- Страви, для опису яких потрібні дані, що входять до складу кулінарних рецептів: номер страви (наприклад, з книги кулінарних рецептів), назва та вид (закуска, суп, cмаженина т.ін.), рецепт (технологія приготування блюда), вихід (вага порції), назва, калорійність і вага кожного продукту, що є інгредієнтом страви.
- Для кожного постачальника продуктів: найменування, адреса, назва продукту, що постачається, дата поставки і ціна на момент поставки.
- Щоденне споживання страв (витрати): страва, кількість порцій, дата.
Аналіз об'єктів дозволяє виділити:
- Основи: Страви, Продукти і Міста;
- асоціації: Склад (пов'язує Страви з Продуктами) і
Поставки (пов'язує Постачальників з Продуктами);
- позначення Постачальники;
- характеристики Рецепти і Витрати.
ER-діаграма моделі наведена на рис. 5.1.6. а модель на мові ЯІМ має наступний вигляд:
Страви (СТ, Страва, Вигляд)
Продукти (ПР, Продукт, Калорійність)
Постачальники (ПОС, Місто, Постачальник) [Місто]
Склад [Страви M, Продукти N] (Ст, ПР, Вага (г))
Поставки [Постачальники M, Продукти N] (ПОС, ПР, Дата П, Ціна, Вага (кг)
Міста (Місто, Країна)
Рецепти (Ст, Рецепт) {Страви}
Витрати (БЛ, Дата Р, Порцій) {Страви}
У цих моделях Страва, Продукт і Постачальник – найменування, а СТ., ПР і ПОС – цифрові коди блюд, продуктів і організацій, що постачають ці продукти.
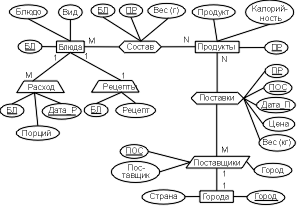
Рис. 5.1.6. Інфологічна модель бази даних "Харчування"
3.5.Реляційна структура даних
В кінці 60-х років з'явилися роботи, в яких обговорювалися можливості застосування різних табличних даталогічних моделей даних, тобто можливості використання звичних і подання способів подання даних. Найбільш значною була стаття співробітника фірми IBM д-ра Е.Кодда (Codd E.F., А Relational Model of Data for Large Shared Data Banks. CACM 13: 6, June 1970), де, ймовірно, вперше був застосований термін "реляційна модель даних".
Будучи математиком за освітою Е.Кодд запропонував використовувати для обробки даних апарат теорії множин (об'єднання, перетин, різниця, декартовий твір). Він показав, що будь-яке подання даних зводиться до сукупності двовимірних таблиць особливого виду, відомого в математиці як відношення – relation (англ.)
У реляційній моделі даних предметну область подають у вигляді певної кількості однорідних таблиць. Таблицю можна в думках уявляти собі як файл, а базу даних - як набір таблиць. Таблиця є складовою одиницею інформації, яка фіксує деякі відносини її елементів (реквізитів, полів, атрибутів). У цьому значенні термін "таблиця" замінюють терміном "відношення".
Число стовпців в таблиці називається порядком відношення. Значення всіх стовпців, пов’язані в одному рядку таблиці, називають кортежем, а значення всіх рядків, що знаходяться в одному стовпці - доменом.
Фундаментальною характеристикою баз даних є можливість опису властивостей відносин. Реляційне відношення має такі властивості:
• Відносини нормалізовані, якщо кожна клітина кортежу є простим значенням, що не складається з груп. (Альтернатива: у таблиці СЛУЖБОВЕЦЬ може існувати стовпець ДІТИ, що є групою реквізитів (ім'я, рік народження, місяць, дата народження). Це викликає необхідність заміни поля ДІТИ іншою таблицею, що порушує вимоги реляційної моделі даних і призводить до мережевого або ієрархічного відношення.
• Нормалізовані відносини подаються у вигляді таблиці, що має ім'я (ім'я відношення), порядок (кількість стовпців), а також імена стовпців, які відповідають іменам атрибутів. Рядки таблиці відповідають кортежам.
• Впорядкування кортежів необов'язкове, хоча це може відображатися на ефективності пошуку кортежів.
• Всі кортежі повинні відрізнятися хоча б в одному символі.
• Декілька одиночних атрибутів (полів) однозначно ідентифікують кортеж. Наприклад, у відношенні СЛУЖБОВЕЦЬ - це прізвище, ім'я і по батькові; у відношенні ТОВАР - код товару і найменування товару; у відношенні ПОСТАВКА - код постачальника. Це рольові атрибути, один з яких приймається за первинний ключ.
• Нормалізовані відносини реляційної БД можуть мати зв'язки між собою через загальні домени. БД – це сукупність відносин, які змінюються в часі.
Ключ - це основне поле БД, по якому в ній сортують записи або ведеться пошук даних. Не слід зберігати одні і ті ж дані в кількох місцях БД, оскільки це неекономна витрата дискового простору і збільшення вірогідності помилки. Дані повинні міститися в БД в одному екземплярі. Теоретичну ідею і практичну процедуру звільнення від зайвих даних в БД називають нормалізацією. Пошук даних в СУБД базується на складному теоретико-множинному формальному апараті, який прихований за зовнішньою простотою пошукових діалогів з ЕОМ призначені для користувача.
Найменша одиниця даних реляційної моделі – це окреме атомарне для даної моделі значення даних. Так, в одній предметній області прізвище, ім'я і по батькові можуть розглядатися як єдине значення, а в іншій – як три різні значення.
Доменом називається безліч атомарних значень одного і того ж типу. Так, домен пунктів відправлення (призначення) – безліч назв населених пунктів, а домен номерів рейса – безліч цілих позитивних чисел. Доменом називається безліч атомарних значень одного і того ж типу. Так, домен пунктів відправлення (призначення) – безліч назв населених пунктів, а домен номерів рейсу – безліч цілих позитивних чисел.
Значення доменів полягає в наступному. Якщо значення двох атрибутів беруться з одного і того ж домена, то, ймовірно, мають сенс порівняння, що використовують ці два атрибути (наприклад, для організації транзитного рейсу можна дати запит "Видати рейси, в яких час вильоту з Києва до Сочі більше часу прибуття з Архангельська до Одеси"). Якщо ж значення двох атрибутів беруться з різних доменів, то їх порівняння, ймовірно, позбавлене значення: чи варто порівнювати номер рейса з вартістю квитка?
Відношення на доменах D1, D2, ..., Dn (не обов'язково, щоб всі вони були різні) складається із "заголовка" і "тіла". На рис. 5.1.7. наведений приклад відношення для розкладу руху літаків.
Заголовок складається з такої фіксованої безлічі атрибутів A1, A2, ..., An, що існує взаємно однозначна відповідність між цими атрибутами Ai і визначальними їх доменами Di (i=1,2,...,n).
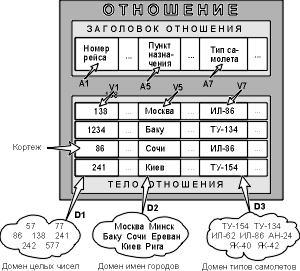
Рис.5.1.7. Відношення з математичної точки зору (Ai - атрибути, Vi - значення атрибутів)
"Тіло" складається зі змінної в часі безлічі кортежів, де кожен кортеж складається в свою чергу з безлічі пар атрибут-значення (Ai:Vi) , (i=1,2,...,n), по одній такій парі для кожного атрибуту Ai в заголовку. Для будь-якої заданої пари атрибут-значення (Ai:Vi) Vi є значенням з єдиного домена Di, який пов'язаний з атрибутом Ai.
Ступінь відношення – це число його атрибутів. Відношення ступеня один називають унарним, ступеня два – бінарним, ступеня три – тринарним, ..., а ступеня n – n-арным. Ступінь відношення "Рейс" – 8.
Кардинальне число або потужність відношення – це число його кортежів. Потужність відношення "Рейс" рівна 10. Кардинальне число відношення змінюється в часі на відміну від його ступеня.
Оскільки відношення – це множина, а множини за визначенням не містять елементів, що співпадають, то ніякі два кортежі відношення не можуть бути дублікатами один одного в будь-який довільно-заданий момент часу. Нехай R – відношення з атрибутами A1, A2, ..., An. Говорять, що безліч атрибутів K=(Ai, Aj, ..., Ak) відношення R є можливим ключем R тоді і тільки тоді, коли задовольняються два незалежних від часу умови:
- Унікальність: у довільний заданий момент часу ніякі два різні кортежі R не мають одного і того ж значення для Ai, Aj, ..., Ak.
- Мінімальність: жоден з атрибутів Ai, Aj, ..., Ak не може бути виключений з Ко без порушення унікальності.
Кожне відношення має хоча б один можливий ключ, оскільки, щонайменше, комбінація всіх його атрибутів задовольняє умові унікальності. Один з можливих ключів (вибраний довільним чином) приймається за його первинний ключ. Решта можливих ключів, якщо вони є, називається альтернативними ключами.
Вищезгадані і деякі інші математичні поняття стали теоретичною базою для створення реляційних СУБД, розробки відповідних мовних засобів і програмних систем, що забезпечують їх високу продуктивність, і створення основ теорії проектування баз даних. Проте для масового користувача реляційних СУБД можна з успіхом використовувати неформальні еквіваленти цих понять:
Відношення – Таблиця (іноді Файл),
Кортеж – Рядок (іноді Запис),
Атрибут – Стовпець, Поле.
При цьому приймається, що "запис" означає "екземпляр запису", а "поле" означає "ім'я і тип поля".
3.6. Реляційна база даних
Реляційна база даних – це сукупність відношень, що містять всю інформацію, яка повинна зберігатися в БД. Проте користувачі можуть сприймати таку базу даних як сукупність таблиць.
1. Кожна таблиця складається з однотипних рядків і має унікальне ім'я.
2. Рядки мають фіксоване число полів (стовпців) і значень (множинні поля і групи, що повторюються, недопустимі). Інакше кажучи, в кожній позиції таблиці на перетині рядка і стовпця завжди є в точності одне значення або нічого.
3. Рядки таблиці обов'язково відрізняються один від одного хоча б єдиним значенням, що дозволяє однозначно ідентифікувати будь-який рядок такої таблиці.
4. Стовпцям таблиці однозначно привласнюються імена, і в кожному з них розміщуються однорідні значення даних (дати, прізвища, цілі числа або грошові суми).
5. Повний інформаційний зміст бази даних подається у вигляді явних значень даних і такий метод подання є єдиним. Зокрема, не існує будь-яких спеціальних "зв'язків" або покажчиків, що з’єднують одну таблицю з іншою.
6. При виконанні операцій з таблицею її рядки і стовпці можна обробляти у будь-якому порядку безвідносно до їх інформаційного змісту. Цьому сприяє наявність імен таблиць і їх стовпців, а також можливість виділення будь-якого їх рядка або будь-якого набору рядків із зазначеними ознаками (наприклад, рейсів з пунктом призначення "Париж" і часом прибуття до 12 годин).
Створені мови маніпулювання даними, що дозволяють реалізувати всі операції реляційної алгебри і практично будь-які їх поєднання. Серед них найбільш поширені SQL (Structured Query Language – структурована мова запитів) і QBE (Quere-By-Example – запити за зразком). Обидві належать до мов дуже високого рівня, за допомогою яких користувач зазначає, які дані необхідно одержати, не уточнюючи процедуру їх отримання.
За допомогою єдиного запиту на будь-якій з цих мов можна з'єднати декілька таблиць в тимчасову таблицю і вилучити з неї необхідні рядки і стовпці (селекція і проекція).