
База данных демографических показателей по регионам России и странам мира: принципы построения
| Вид материала | Документы |
- Достоверные запасы нефти по странам и регионам мира, 180.66kb.
- Ms access База данных (БД), 134.51kb.
- «внешняя торговля россии», 1693.04kb.
- Принципы построения интегрированной системы обработки данных 3C 3d всп, 36.01kb.
- Лекция на тему «Что такое база данных. Реляционная база данных ms access», 67.11kb.
- Система показателей, оценивающих процессы в мировой экономике частные показатели, 92.92kb.
- План. Общие принципы построения системы национальных счетов. Система показателей результатов, 184.88kb.
- История возникновения и принципы построения системы национальных счетов, 20.91kb.
- Должна быть конкретной, кратко сформулированной и соответствовать современному уровню, 20.13kb.
- 1. Введение Основы анализа данных. Методология построения моделей сложных систем. Модель, 399.94kb.
База данных демографических показателей по регионам России и странам мира: принципы построения
Сороко Е.Л.
кандидат физико-математических наук, старший научный сотрудник,
Институт демографии Национального исследовательского университета Высшая школа экономики (Москва, Россия)
Рассматриваются некоторые принципы разработки Базы данных демографических показателей в рамках исследовательского проекта Института демографии, поддержанного Научным Фондом НИУ ВШЭ №11-04-0039. Обсуждается специфика демографической информации и особенности формирования информационных массивов в Базе данных. Обоснован принцип построения базы данных путем формирования БД на основе минимальных порций информации, представляющих собой многомерные таблицы, так называемые «data cubes». Обоснован вывод о необходимости предусмотреть множественность значений показателя в Базе данных. Обсуждается принцип гибкости и расширяемости мета-описания информационных массивов. Доказывается необходимость подробного анализа имеющихся источников данных, используемых для пополнения Базы данных. Обсуждается принцип формирования результата запроса пользователя к Базе данных «на лету». Рассматриваются принципы кодирования демографических признаков и формирования нормативно-справочной информации в Базе данных.
§1. Рассмотрим следующий важнейший вопрос, встающий при разработке баз данных демографических показателей: является ли связь показателя и его значения однозначной? Традиционное понимание и восприятие этой связи в первом приближении может быть названа как связь 1:1, то есть каждый конкретный демографический показатель может принимать только одно единственное значение. Каждый такой показатель является с одной стороны, динамической характеристикой, то есть описывает ту или иную сторону происходящих в населении процессов в некоторый данный момент времени. Оно, вполне естественно, относится не к населению вообще или какому-то абстрактному населению, а к населению некоторой территории или страны. Это соотношение можно схематически изобразить следующим образом:
Рисунок 1. Традиционное соотношение демографического показателя и его значения
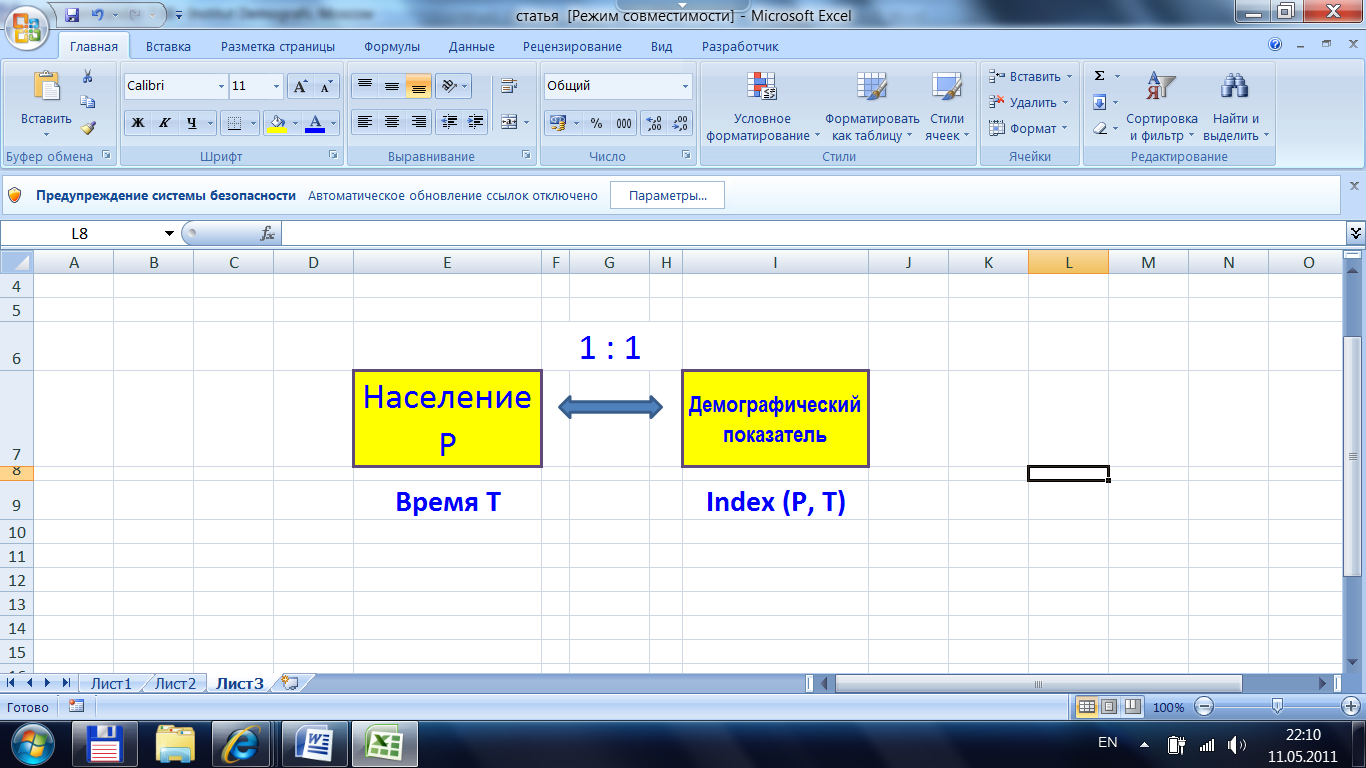
На первый взгляд это действительно именно так. Чтобы убедиться в этом, достаточно воспользоваться существующими демографическими базами данных. Возьмем, к примеру, базу данных INED [8] и найдем там значение такого показателя, как общий коэффициент рождаемости населения Дании в 2009 г. Он равен 11,4 на 1000 населения в год. Еще пример: из статистического ежегодника Японии [5] определим значение брутто-коэффициент воспроизводства населения в 2008 году, равного 0,67. Все происходит аналогично по другим показателям, странам, периодам, если мы находимся в пределах одного конкретного источника демографической информации. Соотношение на схеме Рис.1. действительно выполняется. Рассмотрим, однако, теперь, что же происходит, если попытаться определить значение одного и того же показателя для населения некоторой территории из разных источников.
Возьмем такой показатель, как ожидаемая продолжительность жизни при рождении для женщин в Российской Федерации в 2005 г. По данным базы данных «Здоровье для всех» HFADB [6] (доступ 17 04 2011) ее значение - 72,4 года. По данным Демографического ежегодника России 2009 [2] ее значение почти не отличается (72,39). Однако уже PRB World population datasheet 2005 [9] дает уже совсем другое значение - 72 года. Рассмотрим более детально значение этого показателя еще из одного источника – Демографического ежегодника России – 2002 [1], а также для трех других периодов (1997, 1998, и 2007 гг.). Результаты сведены в Таб.1
Таблица 1. Значение показателя ожидаемой продолжительности жизни женщин в России по данным различных источников, лет*
| | Год | 1997 | 1998 | 2005 | 2007 |
| Источник | № п/п | 5 | 6 | 7 | 8 |
| ВОЗ | 1 | 72,96 | 73,27 | 72,40 | - |
| ДЕ 2002 | 2 | 72,89 | 72,93 | | |
| ДЕ 2009 | 3 | 72,84 | 73,13 | 72,39 | 73,90 |
| PRB | 4 | | | 72,00 | 72,00 |
* 1 – База данных «Здоровье для всех» Европейского Бюро ВОЗ [6], доступ 17.04.2011, 2, 3 – Демографический ежегодник России, 2002, 2009 [1], [2], 4 – Population Reference Bureau, World population Data Sheet, 2005, 2007 [9].
Первоначальный анализ Табл.1 позволяет сделать несколько следующих предварительных выводов.
1) Значение демографического показателя для данного населения и периода не является однозначным. Оно различно для различных источников данных. Более того, для показателя, рассчитанного одним ведомством, в данном случае, Федеральной службой государственной статистики (Росстатом), может различаться для различных изданий.
2) Пополнение различных баз данных происходит с различной степенью оперативности. Так, по прошествии более трех лет в базе данных HFADB [6] (клетка 1-8 Табл.1) отсутствует значение показателя.
3) Различия, существующие для значения показателя в разных источниках, могут иметь различные причины. Часть из этих различий могут иметь свое конкретное объяснение, часть же поддается такому объяснению с большим трудом.
4) Например, различия в клетках 3-7 и 4-7 могут быть вызваны просто потерей точности из-за того, что PRB дает значение только в целых годах. Это, однако, не может служить причиной расхождений в клетках 3-8 и 4-8, поскольку различие составляет почти 2 года и намного превосходит возможную ошибку округления до целого, не превосходящую полгода. В данном случае причина состоит в смысле того значения, который приводит PRB. Необходимо напомнить, что это значение было опубликовано PRB в середине 2007 года, то есть задолго до того, как становится фактом конкретное число событий смерти в данном населении. Значение это может в таком случае явиться лишь оценкой показателя, полученной в результате краткосрочного прогноза или экстраполяции.
5) Возникает также вполне естественный вопрос: можно ли рассматривать значение показателя из одного из источников «правильным», «истинным», а другие, отличные от него – ошибочными? К сожалению, по-видимому, однозначного ответа на данный вопрос нет. Можно лишь сделать заключение, что различия в значениях могут быть обусловлены комплексом факторов: исходными данными, использованными для расчета показателя, методикой расчета значения показателя, точностью показателя при публикации в данном источнике. Таблицы смертности, которые используются для расчета такого показателя, как ожидаемая продолжительность жизни при рождении, не могут отличаться принципиально при расчетах разными авторами – это «демографическая классика», но вот некоторые предварительные этапы, предшествующие расчету ТС, могут, конечно, различаться. Это может относиться, например, к процедуре сглаживания возрастных чисел умерших, коэффициентов смертности или методике оценки численности населения данного пола и возраста.
При разработке Базы данных демографических показателей Института демографии НИУ ВШЭ одним из принципов ее построения предполагается реализация принципа множественности значений конкретного демографического показателя для данного населения и данного периода, полученных из различных источников. В качестве его обоснования можно привести следующие соображения. 1) Любые решения об «истинности» или «правильности» значения показателя из одного конкретного источника по сравнению с другими, принятые при наполнении Базы данных в некоторый момент, могут с течением времени оказаться ошибочными или необоснованными, в связи с тем, что методики расчетов или исходные данные для расчета этого показателя в других источниках изменятся, и, соответственно, изменятся и значения данного показателя в этих источниках. 2) Различия значения одного и того же показателя в разных источниках могут представлять собой самостоятельный интерес, в том числе в историческом плане, для сравнения различных источников и баз данных, оценки их качества по широкому спектру критериев. 3) Ответ на вопрос о том, какой из источников является более предпочтительным для определения значения показателя для данного населения и периода, может оказаться неоднозначным из-за его зависимости от постановки задачи. Например, один из источников может оказаться более пригодным для анализа динамики показателя в отельной стране или регионе, другой или другие – будут более подходящими для того, чтобы выполнить межстрановые сравнения трендов, а в случае ранжирования стран в отдельно взятом периоде может оказаться более подходящим совсем другой источник.
§2. Следующий принцип, который необходимо обсудить, состоит в специфике демографической информации, которая существует в настоящее время, которую можно и нужно учесть при наполнении ее конкретным содержимым. Основной отличительной особенностью этой информации является длительный характер получения значений характеристик населения в большинстве развитых стран в последние 50-60 лет. Происходит это в результате регулярного проведения переписей населения, компьютеризацией обработки демографической информации, усилиям научных кругов и статистических ведомств в широкой публикации и распространении этих сведений. В результате большинство из демографических показателей удобно представлять в виде многомерных таблиц, имеющих прямоугольную форму, так называемых «data cubes», которые заполнены полностью или почти полностью. Как загрузка, так и получение фрагмента таких данных оказывается значительно более экономным, чем единичные запросы или загрузки.
Рассмотрим следующий пример. Пусть имеется некоторый показатель, который в самом простом случае требует для задания его значения для конкретной страны и периода пять характеристик: наименование показателя, название страны, год, источник данных, значение показателя. Тогда, если такая информация имеется по 50 странам за 60 лет, то при формировании базы данных по каждой отдельной комбинации страна*период потребуется задать 15 тысяч таких характеристик (5*50*60). Рассмотрим вариант, когда такая информация имеется в одном источнике (например, Eurostat [7]) по всем странам за весь период. При загрузке информационного массива данного показателя в виде двухмерного прямоугольного массива потребуется всего 3 тысячи значений показателя, 4 характеристики для описания названия показателя, источника, названия одной категории (страны) и названия второй категории (период) и 110 характеристик (50+60) для описания значений категории стран и категории периода в данном информационном массиве. Во втором случае общее число таких параметров, относящихся к данному показателю, окажется существенно меньше: 3114, то есть почти в 5 раз меньше. Таким образом, мы приходим к еще одному принципу формирования базы данных в режиме загрузки многомерных информационных массивов прямоугольной формы.
Размерность информационных массивов может быть не только и не всегда 2. Он может быть и трехмерным, и даже пятимерным. Так, в случае задания структуры населения по полу и возрасту это будет уже четырехмерный массив (пол*возраст*страна*период).
§3. Следующий принцип формирования Базы данных относится к мета-описанию информационных массивов. Это описание относится не к отдельному значению в конкретной клетке этого массива, а к массиву как целому. В настоящий момент это описание состоит из следующих частей: наименование демографического показателя, название информационного массива (предполагается, что один и тот же показатель может иметь несколько массивов значений, например, для разных периодов, из разных источников, подготовленных в разное время и т.д.), размерность информационного массива (поскольку один и тот же показатель может быть представлен массивами различной размерности), название каждой из категорий, изменяемой в данном массиве по каждой из размерностей, дата загрузки массива в Базу данных, источник данных для данного конкретного информационного массива и ряд других. Здесь специально не приводится весь список компонент мета-описания. Причина состоит в том, что мета-описание обязательно должно удовлетворять принципу гибкости и расширяемости. Что именно и в каком виде должно в него войти крайне трудно предусмотреть с самого начала разработки Базы данных и возможности дополнения списка характеристик в мета-описании представляется не только желательным, но и необходимым.
Рассмотрим в качестве примера такой параметр, как год издания. Первоначально он отсутствовал в мета-описании. Почему же он оказался столь необходимым? Рассмотрим такой источник, как демографический ежегодник. Они издаются как в России, так и в других странах, например, Японии, а также, например, Демографический ежегодник ООН [10]. Недавно был опубликован уже 51-й его выпуск. При отсутствии такой отдельной компоненты мета-описания, как год издания, могло получиться, что ежегодники, выпущенные одним автором-издателем в разные годы, стали бы представлять собой различные источники. Это было приемлемо, если бы их число было невелико, однако, при достижении числа источников только из ежегодников в несколько десятков, организовать приемлемый обозримым интерфейс пользователя для работы с ними представляется затруднительным. Что же нового может привнести описатель год издания? В этом случае в Базе данных такие источники, как например, Демографический ежегодник России – 2002 и ДЕ – 2009 могут быть представлены в системе как один источник – «Демографический ежегодник России», отличающиеся, однако, годом издания, - соответственно, 2002 и 2009. Другим примером, подтверждающим целесообразность введения такого описателя, служит база данных ООН «World Population Prospects» [11], содержание которой меняется один раз в два года. Оно пересматривается в соответствии с новыми статистическим данными и новыми сценариями перспективного демографического развития, так называемым «ревизиями» (revision). При этом адрес самой базы данных не изменяется. По этой причине, ссылка на эту базу данных без указания года издания, то есть в данном случае ревизии, представляется не вполне точным: ее пользователи могут получить различные значения одного и того же показателя для разных моментов доступа к этой базе. Таким образов для данного источника такой указатель становится важным уточняющим описателем.
§4. Обсудим откуда может быть получена информация для загрузки в Базу данных демографических показателей. В настоящее время число различных источников этих данных стремительно растет, а их общее число превышает несколько сотен. Их можно разделить на следующие основные крупные группы: базы данных и «бумажные» публикации национальных статистических служб, базы данных и публикации международных организаций, базы данных научных организаций. Представляется достаточно обоснованным стремление использовать для загрузки в Базу данных только те источники, которые позволят обеспечить наиболее достоверные, свежие и точные сведения. Перечисленные характеристики представляют собой отнюдь не полный список критериев, которые могут быть использованы для оценки различных источников. Необходимо отметить, что a priori составить список таких критериев для оценки качества источников достаточно проблематично. Большинство из них, конечно, «лежат на поверхности» и известны достаточно давно (см, например, [4]). Они включают такие характеристики, как периодичность обновления, точность, научная прозрачность, форматы данных. Однако ряд важных характеристик может появиться лишь в процессе их использования различных источников, в том числе не только для загрузки в Базу данных. Одним из принципов разработки Базы данных становится обязательность анализа источников демографической информации по максимально возможному и постоянно расширяемому списку критериев. Такая работа уже выполняется и одним из примеров полученных результатов может служить описание базы данных Statistics Sweden [3].
§5. Следующий важный принцип – формирование нормативно-справочной информации и кодирование демографических признаков в Базе данных. Речь идет об альтернативе, которая может появиться на первоначальном этапе загрузки информационных массивов в Базу данных, между тем, вводить ли значения категорий или их коды. Если бы исходные массивы демографических показателей были взяты из одного источника, вполне возможно, подошел бы первый вариант. Однако, поскольку уже в самом начале становится ясным, что число источников будет довольно значительным, придется остановиться на втором варианте. В этом случае, оказывается практически невозможным обойтись без кодирования, прежде всего значений категорий. Действительно, опыт использования многочисленных баз данных показывает, что одна и та же категория может иметь одинаковые по смыслу значения, которые, однако, формально, с точки зрения предстоящей компьютерной обработки, могут оказаться различными, неравными при их посимвольном сравнении. Примерами могут служить случаи синонимии в названии стран (Белоруссия и Беларусь, Республика Корея и Южная Корея, Россия и Российская Федерация, и т.д.), случаи различного написания одного и того же значения категории (возраст: «80+», «80 и старше», «80 лет и старше»). В свою очередь, потребность кодирования категорий приводит к необходимости создания справочников категорий, которые должны содержать все осмысленные, распространенные синонимы значений каждой категории, которые считаются допустимыми с содержательной демографической точки зрения. В настоящий момент в состав нормативно-справочной информации включены справочники стран мира, регионов Российской Федерации, возрастных групп, причин и классов причин смерти, пола, городских и сельских поселений, периодов, и других. При разработке Базы данных предполагается, что кодирование категорий должно производиться до загрузки каждого конкретного информационного массива. Это должно позволить выявить возможные ошибки в значениях категорий. С другой стороны, при наличии новых категорий, это позволяет своевременно уточнить или расширить существующие справочники, используемые для кодирования.
§6. Наконец, последний принцип – возможность формирования результата запроса к Базе данных с учетом уточнений пользователя в том случае, когда База данных содержит множественные значения. Чтобы пояснить существующую проблему, вернемся к §1, где приведен пример ситуации, когда База данных содержит более одного значения конкретного показателя для указанной категории. В этом случае должны быть предусмотрены следующие варианты получения результата запроса к Базе данных: 1) одно единственное значение показателя исходя из «стандартных» критериев отбора наиболее точного, свежего, достоверного значения (по умолчанию в системе); 2) все значения, имеющиеся в Базе данных (с указанием источников и других описателей); 3) значение, сформированное «на лету» из всех имеющихся в Базе данных, на основании критериев, указанных пользователем при запросе.
Литература
- Демографический ежегодник России 2002. Статистический сборник. М., Госкомстат России, 2002.
- Демографический ежегодник России 2009. Статистический сборник. М., Росстат, 2009.
- Исследовательский проект "Разработка Базы данных демографических показателей по регионам России и странам мира" №11-04-0039 по конкурсу Программы "Научный фонд ГУ-ВШЭ" "Учитель-Ученики" 2011-2012 гг. Источники демографической информации. База данных Statistics Sweden (ссылка скрыта).
- Исследовательский проект "Разработка Базы данных демографических показателей по регионам России и странам мира" №11-04-0039 по конкурсу Программы "Научный фонд ГУ-ВШЭ" "Учитель-Ученики" 2011-2012 гг. Источники демографической информации. База данных Statistics Sweden (ссылка скрыта).
- Сороко Е.Л. Критерии качества демографической информации в Интернете. Доклад на Международном конгрессе "Проблемы демографии и безопасности жизни" (Минск, 14-15 ноября 2002 г.)
- Japan Statistical Yearbook 2011. Edited by Statistical Research and Training Institute, MIC, Japan (ссылка скрыта).
- Европейское региональное бюро Всемирной организации здравоохранения. База данных «Здоровье для всех» HFADB (ссылка скрыта).
- Eurostat (ссылка скрыта).
- INED. Population in figures database (ссылка скрыта).
- Population Reference Bureau (ссылка скрыта). World population Data Sheet, 2005, 2007. На русском языке см. Демографический еженедельник Демоскоп Weekly, Приложения (ссылка скрыта, ссылка скрыта).
- United Nation Demographic Yearbook 2008 (ссылка скрыта).
- United Nations World Population Prospects (ссылка скрыта).