
1. Введение Основы анализа данных. Методология построения моделей сложных систем. Модель «черного ящика». Основные этапы построения моделей. Методика анализа данных
| Вид материала | Закон |
- Лекции по дисциплине «Математическое моделирование» для студентов и магистрантов специальности, 21.92kb.
- Учебное пособие Допущено Министерством образования Российской Федерации в качестве, 2582.59kb.
- Пример рабочей программы дисциплины ооп основы построения современных систем, 65.27kb.
- Статья, опубликованная в журнале Физика волновых процессов и радиотехнические системы,, 201.83kb.
- Тема 1 Машинное моделирование, 153.56kb.
- Рабочая программа дисциплины методы построения и анализа сложных математических моделей, 104.9kb.
- Вопросы к экзамену, 54.74kb.
- Экзаменационные вопросы по дисциплине " Имитационное моделирование" для студентов группы, 9.83kb.
- Реферат "Принципы проектирования и использования многомерных баз данных" Введение, 295.28kb.
- Концепция баз данных уже давно стала определяющим фактором при создании эффективных, 293.58kb.
Тема 1. Введение
Основы анализа данных. Методология построения моделей сложных систем. Модель «черного ящика». Основные этапы построения моделей. Методика анализа данных.
Основой для анализа данных служит моделирование. Построение моделей является универсальным способом изучения окружающего мира. Построение моделей позволяет обнаруживать зависимости, извлекать новые знания, прогнозировать, управлять и решать множество других задач.
Модели и моделирование тесно связаны с таким базовым понятием, как система.
Система - центральное понятие в теории систем и системном анализе. Под системой принято понимать совокупность объектов, компонентов или элементов произвольной природы, образующих некоторую целостность в том или ином контексте. Каждая система несет в себе принцип эмерд-жентности - у системы появляются новые свойства, которые не имеют составляющие ее элементы.
Выделяется несколько типов систем: простые, малые, большие, сложные. Отличие между ними заключается в количестве элементов и типе связи между ними, а также ресурсной и информационной обеспеченности (рис. 1.1).
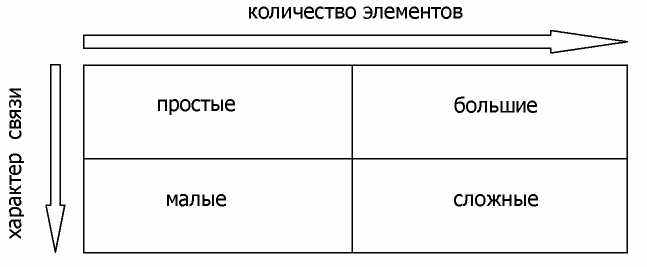
Рис. 1.1. Классификация систем
Сложная система является наиболее трудной из всех для изучения. Это обусловлено следующими причинами:
- Закон распределения воздействующих на систему параметров неизвестен, или на его
получение требуется потратить значительное количество временных и финансовых
ресурсов.
- Функционирование системы происходит в условиях неопределенности, которую вно
сит главным образом человеческий и случайный факторы.
3. Переменные системы могут иметь количественно-качественное описание.
Большинство экономических систем относятся к категории сложных.
Наиболее общей информационной моделью системы является модель «черного ящика». Система представляется в виде прямоугольника с множеством входных и выходных переменных, внутреннее устройство которого скрыто от исследователя, а чаще всего неизвестно (рис. 1.2).
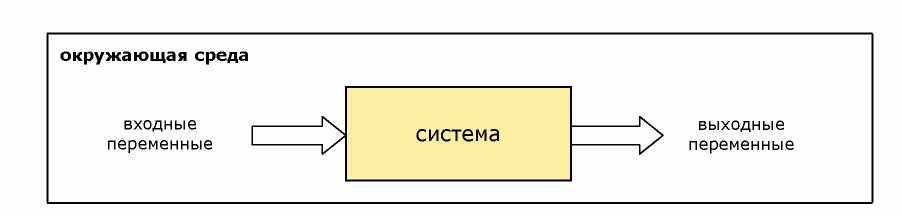
Рис. 1.2. Модель «черного ящика»
Определив входные и выходные воздействия и имея в наличии набор данных, связывающий их, уже можно говорить о модели системы, даже если не известен закон, связывающий между собой входы и выходы системы. Существуют специальные методы, позволяющие изучать такие системы без знания математических, экономических и других зависимостей между переменными системы и даже извлекать знания. Такие методы относятся к категории интеллектуальных методов анализа данных.
Перед построением модели следует отталкиваться от задачи. Задачу можно рассматривать как ответ на интересующий исследователя вопрос. Например, в розничной торговле такими вопросами могут быть следующие:
- Какова структура продаж за определенный период? Как можно классифицировать
осуществляемые компанией продажи?
- Какие клиенты приносят наибольшую прибыль?
- Какие товары продаются или заказываются вместе?
- Как оптимизировать товарные остатки на складах и т.п.?
Тогда можно говорить о создании модели прогнозирования продаж, модели выявления ассоциаций и т.д.
Данный этап еще называется анализом проблемной ситуации.
Следующий шаг - систематизация и консолидация всех доступных ресурсов (материальных, финансовых, информационных), необходимых для построения модели. В случае отсутствия требуемых ресурсов на данном этапе может быть принято решение либо о сужении требований к результатам, либо вообще отказ от построения модели. Здесь встает вопрос о точности будущей модели интересующему процессу или системе. Поскольку процесс построения модели носит итерационный характер (рис. 1.3), в процессе которого она корректируется и уточняется, то нет смысла на первых шагах требовать высокую точность модели. Гораздо правильнее говорить об адекватности модели. Первоначальная модель может быть грубой, но адекватной.
Адекватность означает, что при построении модели исследователь учел наиболее важные, существенные факторы, влияющие на конечный результат. Можно утверждать, что с ростом количества факторов увеличивается сложность модели.
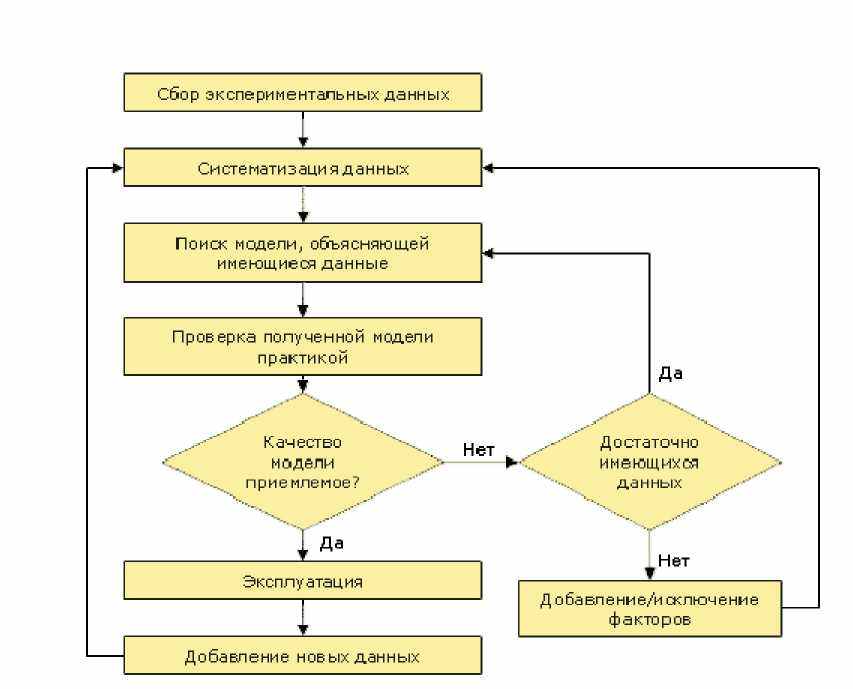
Рис. 1.3. Процесс построения модели
После систематизации данных переходят к поиску модели, которая объясняла бы имеющиеся данные, позволила бы добиться эмпирически обоснованных ответов на интересующие вопросы. Существует огромное множество готовых моделей систем, в том числе экономических. Большинство из них формальны, т.е. представляются в виде совокупности математических формул, законов, распределений и т.п. Однако на практике часто они не применимы, и имеют мало общего с действительностью. Нередко исследователь сталкивается с ситуацией, когда трудно сделать какие-либо четкие предположения относительно поставленной задачи. Модель не известна, и единственным источником сведений для ее построения является таблица экспериментальных данных типа «вход-выход», т.е. «черный ящик». В результате аналитик вынужден использовать различные эвристические предположения о выборе информативных признаков, о классе и параметрах выбранной модели. Эти предположения аналитика основываются на его опыте, интуиции, проникновении в смысл анализируемого процесса.
Логично, что на данном этапе может возникнуть не одна, а несколько моделей системы-оригинала, в чем проявляется принцип многомодельности. В этом случае необходимо остановиться на какой-то одной, наиболее адекватной решаемой задаче модели, либо пытаться комбинировать подходы для получения полной модели, состоящей из комплекса взаимосвязанных моделей. При выборе конкретной модели из нескольких предложенных снова эффективен опрос специалистов предметных областей, или экспертов. В спорных случаях для принятия обоснованного решения могут придти на помощь методы проведения сложных экспертиз, включающие в себя такие алгоритмы, как ранжирование, парные оценки и др.
Рассмотрим этапы построения модели на примере. Возьмем актуальную задачу розничной торговли - прогнозирование объема продаж. Для ее решения необходимо построить модель про-
гноза продаж. Воспользуемся схемой на рис. 1.3. Выполнение первого этапа, как правило, не представляет трудностей - необходимые данные по продажам за периоды (неделя, месяц) извлекаются из существующих в организации учетных систем. Это при условии, что сделано предположение о том, что на будущие продажи влияют продажи за предыдущие периоды.
На следующем этапе - систематизации данных - необходимо получить ответы на вопросы.
Достаточно ли данных для построения модели прогноза продаж?
Дело в том, что при малом количестве данных любое прогнозирование бессмысленно и никакая модель не уловит закономерности в продажах. Так, для временного ряда истории продаж на 1,5 года прогноз следует осуществлять максимум на 1 месяц; для данных за 2-3 года - максимум на 2 месяца.
По каким товарам строить прогноз?
Проблема заключается в том, что иногда прогноз продаж для каждого наименования товара строить бессмысленно. Как правило, это касается продукции с высокой степенью обновления модельного ряда (телефоны, плееры, компьютерная техника и др.). Как вариант, возможно построение прогноза по группам товаров со схожими потребительскими свойствами.
Далее необходимо сделать выбор модели прогнозирования продаж, что в данном случае сводится к выбору метода прогнозирования. Их существует огромное множество. Например, метод среднего, согласно которому прогноз вычисляется на основе усредненных величин продаж за несколько предыдущих месяцев (периодов). Такая модель прогноза получится простой и грубой, т.к. не учитывает фактор сезонности. Возможно, для каких-то товаров сезонность в продажах отсутствует, и модель будет адекватной. Для других товаров она не подойдет, и придется обратиться к более сложным методам, учитывающим сезонность - к примеру, метод Хольта, или дополнительно ввести в модель коэффициенты сезонности, возможно, учитывать остатки на складе, количество выходных дней в месяце и т.п.
Таким образом, во-первых, универсальных моделей не бывает, а во-вторых, сложность модели не гарантирует ее точность. Мастерство исследователя заключается в том, чтобы найти компромисс между простотой, прозрачностью с одной стороны и приемлемым качеством результатов с другой. При этом не следует гнаться за абсолютной точностью и начинать использование модели при получении первых приемлемых результатов.
У изложенного механизма построения моделей есть как сильные, так и слабые стороны. Использование методов построения моделей позволяет получать новые знания, которые невозможно извлечь другим способом. Кроме того, полученные результаты являются формализованным описанием некоего процесса, а, следовательно, поддаются автоматической обработке. Недостатком же является то, что такие методы более требовательны к качеству данных, знаниям эксперта и формализации самого изучаемого процесса. К тому же почти всегда имеются случаи, не укладывающиеся ни в какие модели.
Подводя итог над всем вышесказанным, можно выделить главные принципы построения моделей сложных систем, к каким относятся модели экономических процессов:
- Решение проблемы начинать с построения модели.
- При анализе отталкиваться от опыта эксперта.
- Рассматривать проблему под разными углами и комбинировать подходы.
- Не стремиться к высокой точности модели, а двигаться от более простых и грубых моделей
к более сложным и точным.
- По прошествии времени и накоплению новых сведений нужно повторять цикл моделирова
ния - процесс познания бесконечен.
К
 онтрольные вопросы
онтрольные вопросы- Дайте определение сложной системы.
- Почему процесс моделирования имеет итерационный характер?
- Перечислите основные этапы построения моделей.
- Как оценивается адекватность модели?
 Тема 2. Методы интеллектуального анализа данных
Тема 2. Методы интеллектуального анализа данныхПредпосылки развития автоматических методов добычи данных. Определения OLAP, Data Mining, KDD и взаимосвязи между ними. OLAP. Аналитическая отчетность и многомерное представление данных. Хранилище данных. Измерения и факты. Типы задач, решаемые методами Data Mining. Алгоритмы, получившие наибольшее распространение для каждого типа задач.
2.1. Предпосылки развития автоматических методов анализа данных
Существует два способа получения информации: документальный и экспертный. В первом случае данные содержатся во всевозможных информационных источниках (книги, документы, базы данных, информационные системы и т.п.). Экспертный способ предполагает извлечение и структурирование знаний из памяти человека - эксперта, или специалиста в предметной области. Часто их называют методами, направленными на использование интуиции и опыта специалистов.
Среди методов первой группы в экономике распространены методы математической статистики. Данные методы решают большой спектр задач, однако не позволяют находить и извлекать знания из массивов данных. Кроме того, высокие требования к квалификации конечных пользователей ограничивают их использование.
Среди второй группы распространены так называемые экспертные системы, представляющие собой специальные компьютерные программы, моделирующие рассуждения человека. Например, экспертная система принятия решений на рынке ценных бумаг, экспертная система оценки кредитных рисков и т.п. Высокая стоимость создания и внедрения экспертных систем, неспособность людей обнаруживать сложные и нетривиальные зависимости, часто отсутствие специалистов, способных грамотно структурировать свои знания также затрудняют тиражирование такого подхода.
Специфика современных требований к обработке информации (огромный объем данных и их разнородная природа) делает бессильными как статистические, так и экспертные подходы во многих практических областях, в том числе и экономических. Поэтому для анализа информации, накопленной в современных базах данных, методы должны быть эффективными, т.е. простыми в использовании, обладать значительным уровнем масштабируемости и определенным автоматизмом. Это концепция лежит в основе двух современных технологий Data Мттд и KDD - Knowledge Dis-соуегу т ОайЬазез.
Классическое определение технологии «добычи данных» (Оа1а Мттд) звучит следующим образом: это обнаружение в исходных («сырых») данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний. То есть информация, найденная в процессе применения методов Data Mining, должна быть нетривиальной и ранее неизвестной, например, средние продажи не являются таковыми. Знания должны описывать новые связи между свойствами, предсказывать значения одних признаков на основе других.
П
 римеры
римерыПриведенные ниже примеры из разных областей экономики демонстрируют основное преимущество методов Ра(:а Мттд - способность обнаружения новых знаний, которые невозможно получить методами статистического, регрессионного анализа или эконометрики.
1. Множество клиентов компании с помощью одного из инструментов Data Мттд были объединены в группы,
или сегменты со схожими признаками. Это позволило проводить компании различную маркетинговую политику и строить отдельные модели поведения для каждого клиентского сегмента. Наиболее значимыми факторами для разделения на группы оказались следующие: удаленность региона клиента, сфера деятельности, среднегодовые суммы сделок, количество сделок в неделю.- Автоматический анализ банковской базы данных кредитных сделок физических лиц выявил правила, по
которым потенциальным заемщикам отказывалось в выдаче кредита. В частности, решающими факторами
при выдаче кредитов на небольшие суммы, оказались: срок кредита, среднемесячный доход и расход заем
щика. В дальнейшем это учитывалось при экспресс-кредитовании наиболее дешевых товаров.
- При анализе базы данных клиентов страховой компании был установлен социальный портрет человека,
страхующего жизнь - это оказался мужчина 35-50 лет, имеющий 2 и более детей и среднемесячный доход
выше $2000.
О
 бнаружение знаний в базах данных (Кпсм1ес1де 015ссл/егу т ОайЬазез, КОО) - это последовательность действий, которую необходимо выполнить для построения модели (извлечения знания). Эта последовательность не описывает конкретный алгоритм или математический аппарат, не зависит от предметной области. Это набор атомарных операций, комбинируя которые, можно получить нужное решение.
бнаружение знаний в базах данных (Кпсм1ес1де 015ссл/егу т ОайЬазез, КОО) - это последовательность действий, которую необходимо выполнить для построения модели (извлечения знания). Эта последовательность не описывает конкретный алгоритм или математический аппарат, не зависит от предметной области. Это набор атомарных операций, комбинируя которые, можно получить нужное решение.КОО включает в себя этапы подготовки данных, выбора информативных признаков, очистки данных, применения методов Data Mining, постобработки данных, интерпретации полученных результатов. Сердцем всего этого процесса являются методы Data Mining, позволяющие обнаруживать закономерности и знания (рис. 2.1).
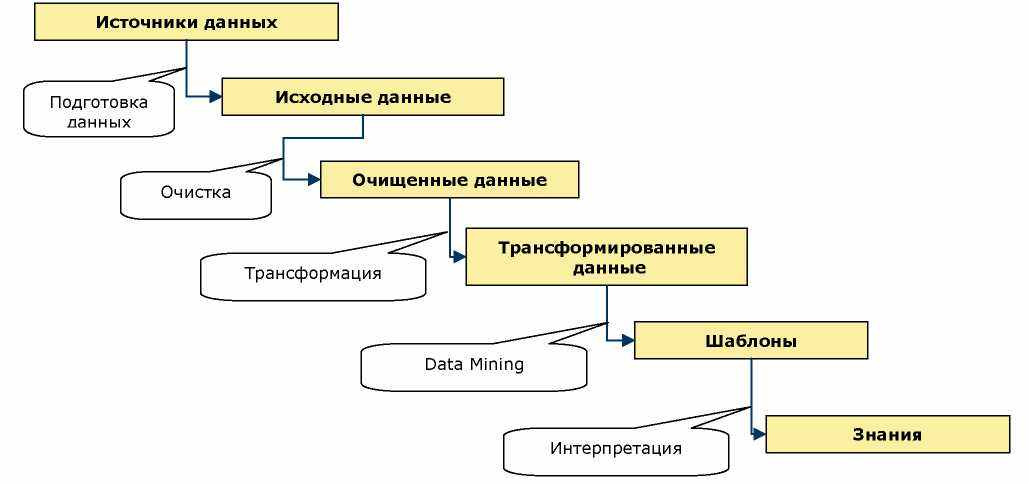
Рис. 2.1. Этапы KDD
Кратко рассмотрим последовательность шагов, выполняемых на каждом этапе KDD.
Подготовка исходного набора данных. Этот этап заключается в подготовке набора данных, в том числе из различных источников, выбора значимых параметров и т.д. Для этого должны существовать развитые инструменты доступа к различным источникам данных.
Предобработка данных. Для эффективного применения методов Data Мттд следует обратить серьезное внимание на вопросы предобработки данных. Данные могут содержать пропуски, шумы, аномальные значения и т.д. Кроме того, данные могут быть избыточны, недостаточны и т.д. В некоторых задачах требуется дополнить данные некоторой априорной информацией. Ошибочно
предполагать, что если подать данные на вход системы в существующем виде, то на выходе будут получены полезные знания. Входные данные должны быть качественны и корректны.
Трансформация, нормализация данных. Этот шаг необходим для тех методов, которые требуют, чтобы исходные данные были в каком-то определенном виде. Дело в том, что различные алгоритмы анализа требуют специальным образом подготовленные данные, например, для прогнозирования необходимо преобразовать временной ряд при помощи скользящего окна или вычисление агрегируемых показателей. К задачам трансформации данных относятся: скользящее окно, приведение типов, выделение временных интервалов, преобразование непрерывных значений в дискретные и наоборот, сортировка, группировка и прочее.
па1а Mining. На этом шаге применяются различные алгоритмы для нахождения знаний. Это нейронные сети, деревья решений, алгоритмы кластеризации и установления ассоциаций и т.д.
Постобработка данных. Интерпретация результатов и применение полученных знаний в бизнес приложениях.
Например, требуется получить прогноз объемов продаж на следующий месяц. Имеется сеть магазинов розничной торговли. Первым шагом будет сбор истории продаж в каждом магазине и объединение ее в общую выборку данных. Следующим шагом будет предобработка собранных данных: их группировка по месяцам, сглаживание кривой продаж, устранение факторов, слабо влияющих на объемы продаж. Далее следует построить модель зависимости объемов продаж от выбранных факторов. Это можно сделать с помощью линейной регрессии или нейронных сетей. Имея такую модель, можно получить прогноз, подав на вход модели историю продаж. Зная прогнозное значение, его можно использовать, например, в приложениях оптимизации для лучшего размещения товара на складе.
Самое главное преимущество KDD в том, что полученные таким способом знания можно тиражировать. Т.е. построенную одним человеком модель могут применять другие, без необходимости понимания методик, при помощи которой эти модели построены. Найденные знания должны быть использованы на новых данных с некоторой степенью достоверности.
2.2. Хранилища данных. Основы OLAP
Методы интеллектуального анализа информации, Data Mining, часто рассматриваются как естественное развитие концепции хранилищ данных, поэтому перед их изложением необходимо иметь представление о хранилищах данных и многомерном представлении информации.
В чем отличие хранилища от базы данных? В первую очередь в том, что их создание и эксплуатация преследуют различные цели. База данных играет роль помощника в оперативном управлении организации. Это каждодневные задачи получения актуальной информации: бухгалтерской отчетности, учета договоров и т.д. В свою очередь хранилище данных консолидирует всю необходимую информацию для осуществления задач стратегического управления в среднесрочном и долгосрочном периоде. Например, продажа товара и выписка счета производятся с использованием базы данных, а анализ динамики продаж за несколько лет, позволяющий спланировать работу с поставщиками, — с помощью хранилища данных.
Таким образом, хранилище данных - это специальным образом систематизированная информация из разнородных источников (базы данных учетных систем компании, маркетинговые данные, мнения клиентов, исследования конкурентов и т.п.), необходимая для обработки с целью принятия стратегически важных решений в деятельности компании.
Для того чтобы получить качественный прогноз, нужно собрать максимум информации об исследуемом процессе, описывающей его с разных сторон. Например, для прогнозирования объемов продаж может потребоваться следующая информация:
- история продаж;
- состояние склада на каждый день - если спад продаж часто связан с отсутствием товара
на складе, а вовсе не из-за отсутствия спроса;
- сведения о ценах конкурентов;
- изменения в законодательстве;
- общее состояние рынка;
- курс доллара, инфляция;
- сведения о рекламе;
- сведения об отношении к продукции клиентов;
- различного рода специфическую информацию. Например, для продавцов мороженого -
температуру, а для аптечных складов - санитарно-эпидемиологическую обстановку, и мно
гое другое.
Проблема заключается в том, что обычно в системах оперативного учета большей части этой информации просто нет, а та, что есть, искаженная и(или) неполная. Лучшим вариантом в этом случае будет создание хранилища данных, куда бы с определенной заданной периодичностью поступала вся необходимая информация, предварительно систематизированная и отфильтрованная (рис. 2.2).
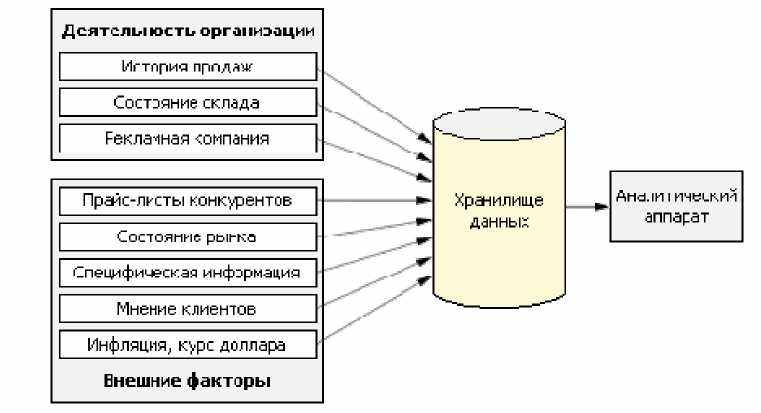
Рис. 2.2. Хранилище данных
Эффективная архитектура хранилища данных должна быть организована таким образом, чтобы быть составной частью информационной системы управления предприятием.
Наиболее распространен случай, когда хранилище организовано по типу «звезда», где в центре располагаются факты и агрегатные данные, а «лучами» являются измерения. Каждая «звезда»
описывает определенное действие, например, продажу товара, отгрузку, поступления денежных средств и прочее (рис. 2.3).
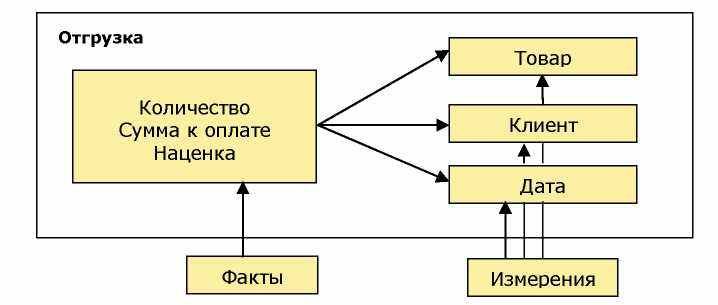
Рис. 2.3. Измерения и факты
Обычно данные копируются в хранилище из оперативных баз данных и других источников согласно определенному расписанию.
О1.АР (Оп-Ыпе Апа1уйса1 Processing) является ключевым компонентом организации хранилищ данных. Эта технология основана на построении и визуализации многомерных кубов данных с возможностью произвольного манипулирования информации, содержащейся в кубе. Это позволяет представить информацию для анализа в любом разрезе.
Вернемся к примеру с анализом продаж. Пусть руководителя интересуют объемы продаж за некоторый период, к примеру, за только что завершившийся месяц. Компания продает не один, а множество товаров и имеет большое число клиентов, «разбросанных» по разным городам страны. Первые два простейших вопроса, на которые нам сразу же хотелось бы иметь ответы, - это объемы продаж по объемы продаж товаров по каждому городу за каждый месяц.
Очевидно, что «ответ» на каждый из этих вопросов будет оформлен в виде двумерной таблицы. В первом случае строками и столбцами этой таблицы соответственно будут названия товаров, месяцы и суммы, а во втором - названия городов и суммы.
Однако анализировать информацию в таком виде неудобно. Возникает потребность «соединить» данные нескольких таблиц. В итоге в таком отчете будет фигурировать три равноправных аналитических измерения (город, товар и месяц), и вместо двумерных таблиц появляется трехмерная модель представления данных, так называемый куб (рис. 2.4, 2.5).
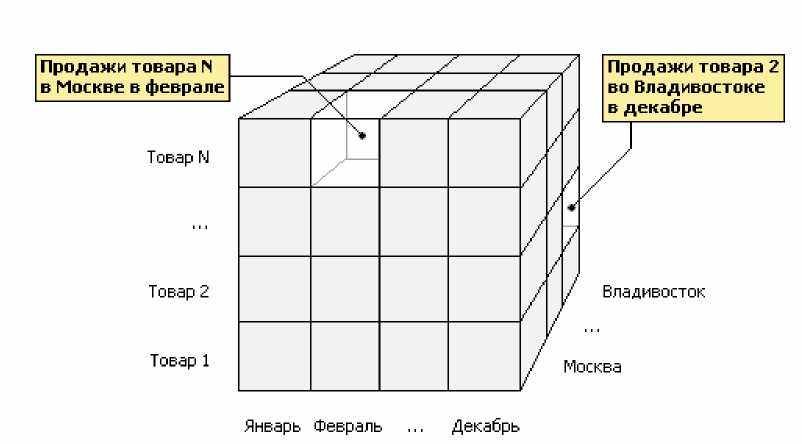
Рис. 2.4. Данные в трехмерном кубе
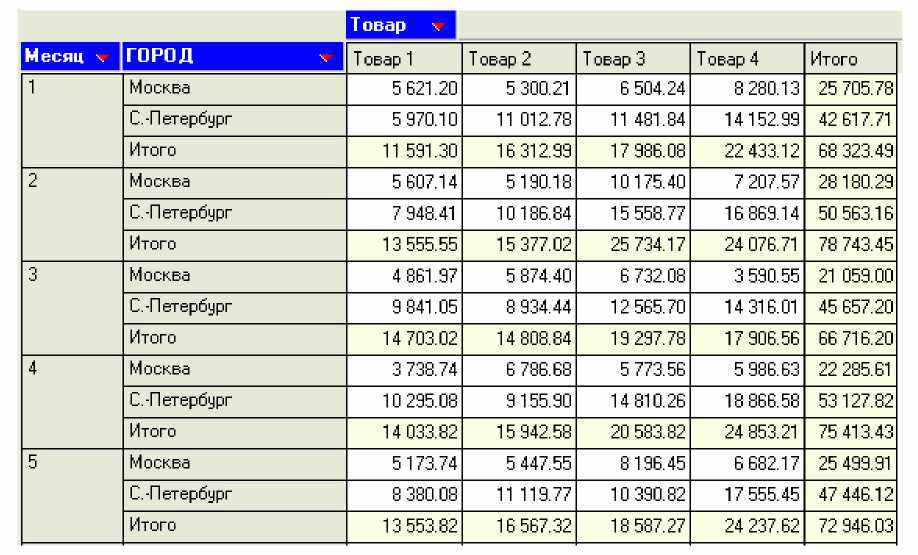
Рис. 2.5. Пример многомерного отчета
2.3. Методы извлечения знаний и области их применения в экономике
Оа1а Мттд - это не один, а совокупность большого числа различных методов обнаружения знаний. Все задачи, решаемые методами Data Mining, можно условно разбить на пять классов.
- Классификация - отнесение объектов (наблюдений, событий) к одному из заранее из
вестных классов. Это делается посредством анализа уже классифицированных объектов и
формулирования некоторого набора правил.
- Кластеризация - это группировка объектов (наблюдений, событий) на основе данных
(свойств), описывающих сущность объектов. Объекты внутри кластера должны быть «по
хожими» друг на друга и отличаться от объектов, вошедших в другие кластеры. Чем боль
ше похожи объекты внутри кластера и чем больше отличий между кластерами, тем точнее
кластеризация. Часто применительно к экономическим задачам вместо кластеризации употребляют термин сегментация.
- Регрессия, в том числе задача прогнозирования. Это установление зависимости непре
рывных выходных переменных от входных. К этому же типу задач относится прогнозирова
ние временного ряда на основе исторических данных.
- Ассоциация - выявление закономерностей между связанными событиями. Примером та
кой закономерности служит правило, указывающее, что из события X следует событие Y.
Такие правила называются ассоциативными. Впервые это задача была предложена для на
хождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее
еще называют анализом рыночной корзины (market basket analysis).
- Последовательные шаблоны - установление закономерностей между связанными во
времени событиями.
Укажем наиболее известные применения этих задач в экономике.
Классификация используется в случае, если заранее известны классы отнесения объектов. Например, отнесение нового товара к той или иной товарной группе, отнесение клиента к какой-либо категории. При кредитовании это может быть, например, отнесение клиента по каким-то признакам к одной из групп риска.
Кластеризация может использоваться для сегментации и построения профилей клиентов (покупателей). При достаточно большом количестве клиентов становится трудно подходить к каждому индивидуально. Поэтому клиентов удобно объединить в группы - сегменты с однородными признаками. Выделять сегменты клиентов можно по нескольким группам признаков. Это могут быть сегменты по сфере деятельности, по географическому расположению. После сегментации можно узнать, какие именно сегменты являются наиболее активными, какие приносят наибольшую прибыль, выделить характерные для них признаки. Эффективность работы с клиентами повышается за счет учета их персональных предпочтений.
Регрессия используется для установления зависимостей в факторах. Например, в задаче прогнозирования зависимой величиной является объемы продаж, а факторами, влияющими на эту величину, могут быть предыдущие объемы продаж, изменение курса валют, активность конкурентов и т.д. Или, например, при кредитовании физических лиц вероятность возврата кредита зависит от личных характеристик человека, сферы его деятельности, наличия имущества.
Ассоциации помогают выявлять совместно приобретаемые товары. Это может быть полезно для более удобного размещения товара на прилавках, стимулирования продаж. Тогда человек, купивший пачку спагетти, не забудет купить к ним бутылочку соуса.
Последовательные шаблоны могут быть использованы при планировании продаж или предоставлении услуг. Пример последовательного шаблона: если человек приобрел фотопленку, то через неделю он отдаст ее на проявку и закажет печать фотографий.
Для решения вышеперечисленных задач используются различные методы и алгоритмы Data Mining. Ввиду того, что Data Мттд развивался и развивается на стыке таких дисциплин, как математика, статистика, теория информации, машинное обучение, теория баз данных, вполне законо-
мерно, что большинство алгоритмов и методов Data Мттд были разработаны на основе различных методов из этих дисциплин.
В общем случае, не принципиально, каким именно алгоритмом будет решаться одна из пяти задач Data Мттд - главное иметь метод решения для каждого класса задач.
На сегодня наибольшее распространение получили самообучающиеся методы и машинное обучение. Рассмотрим кратко наиболее известные алгоритмы и методы, применяющиеся для решения каждой задачи Data Mining.