
Алгоритм поиска в глубину наилучшей оценки в дереве решений конечной антогонистической игры двух лиц с нулевой суммой и полной информацией доц. Мамонтов Д. В., студ. Волошин С. Б
| Вид материала | Документы |
- Политическая оппозиция в России: вымирающий вид?, 384.58kb.
- План действий Отобрать группу лиц для генерации идей и группу лиц для оценки идей (по, 29.2kb.
- Программа Москва, 205.71kb.
- 3. Лекция: Методы поиска решений, 336.6kb.
- К. е н., доц. Воробйова Ірина Аркадіївна, студ., 39.08kb.
- Задачи урока: Воспитательная развитие познавательного интереса, логического мышления., 103.05kb.
- Рабочая программа дисциплины «Алгоритм принятия уголовно-процессуальных решений» Направление, 292.56kb.
- «Использование компьютерных технологий в обучении истории», 191.04kb.
- Теорема про суперпозицию (наложение) решений неоднородных линейных дифференциальных, 9.28kb.
- Методические рекомендации для выпускника рии алтгту «Алгоритм поиска работы», 133.91kb.
УДК 004.8
АЛГОРИТМ ПОИСКА В ГЛУБИНУ НАИЛУЧШЕЙ
ОЦЕНКИ В ДЕРЕВЕ РЕШЕНИЙ КОНЕЧНОЙ АНТОГОНИСТИЧЕСКОЙ ИГРЫ ДВУХ ЛИЦ С НУЛЕВОЙ СУММОЙ И ПОЛНОЙ ИНФОРМАЦИЕЙ
Доц. Мамонтов Д.В., студ. Волошин С.Б.
Кафедра теории и автоматизации
металлургических процессов и печей.
Северо-Кавказский горно-металлургический институт
(государственный технологический университет)
Представлен алгоритм поиска наилучшей оценки в дереве решений логической игры с полной информацией для двух лиц. Описаны использованные методы программирования решений задач подобного типа и сам алгоритм.
Введение
В современном мире часто встречаются явления, в которых те или иные участники имеют несовпадающие интересы и продвигаются различными путями к достижению целей. В теории игр такие явления называются конфликтами или проблемными средами. Частным и наиболее интересным случаем конфликта является игра. Игру можно рассматривать как упрощенную модель конфликта, являющуюся наилучшей для изучения многих сходных с ними практически важных задач.
Одним из самых простых видов игр являются антагонистические игры, т.е. игры двух и более игроков с прямо противоположными интересами. Если игроки для достижения победы располагают конечным числом возможных действий или стратегий, то такая игра называется конечной. Игра с полной информацией (perfect information game) позволяет просчитать как свои действия, так и действия соперника. Типичным примером игры с полной информацией являются шахматы – игроки видят расположение на доске и своих фигур и фигур противника, что позволяет каждому, руководствуясь игровой логикой, предсказать поведение оппонента на несколько ходов вперед.
Игру с нулевой суммой (zero-sum game) можно описать следующим математическим выражением:
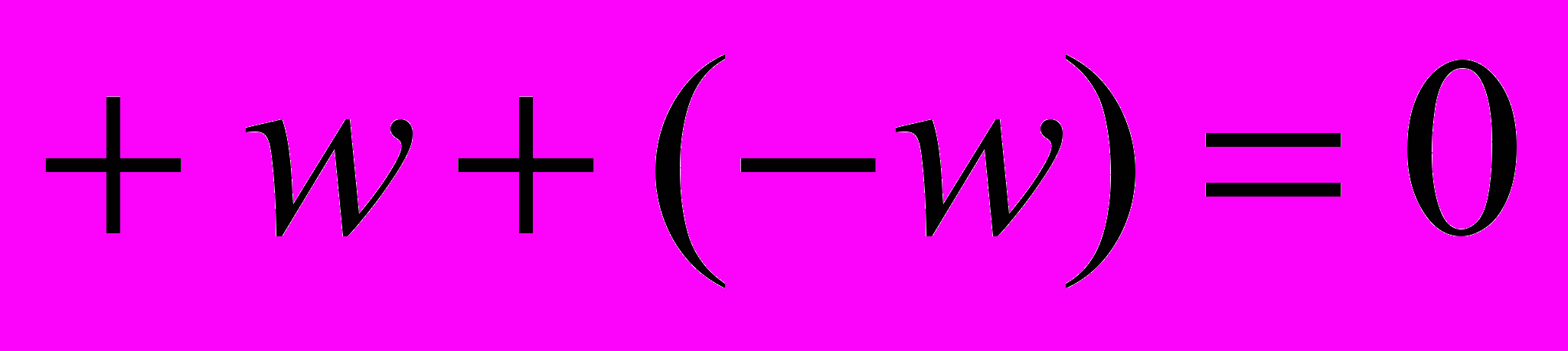 . (1)
. (1)Его можно объяснить так: предположим, что один из двух игроков победил и его выигрыш равняется (+w), тогда выигрыш проигравшего игрока составит (–w). Суммируя выигрыши двух игроков, получим формулу (1).
Весь процесс игры графически можно представить в виде дерева решений (decisions tree) – ориентированного графа, вершины которого отвечают различным игровым позициям, а дуги соединяют следующие одна за другой позиции и указывают порядок их следования [1]. Как правило, в задачах данного типа структура дерева изначально неизвестна и генерируется по определенным правилам, обусловленным правилами игры. Такие деревья называются заданными неявно [2]. Сгенерированное дерево всех возможных комбинаций в игре (так называемое полное дерево – full tree), как правило, имеет большое количество уровней. Обход такого дерева занимает очень много машинного времени и ресурсов, поэтому на практике используют не все дерево, а ограничивают количество просматриваемых уровней до числа, позволяющего алгоритму играть с приемлемым качеством.
Листам полного дерева соответствуют выигрышные/проигрышные позиции, означающие конец игры. В ограниченном дереве решений лист не всегда становится концом игры и может быть обычной игровой ситуацией.
Авторами была разработана программа поиска в глубину наилучшей оценки в дереве решений конечной антагонистической игры двух лиц с нулевой суммой и полной информацией. Программа имеет модульную структуру и состоит из четырех частей: алгоритма поиска (каркас программы) и трех оценочных функций.
В данной работе подробно рассматривается только один из модулей – алгоритм поиска.
Принципы работы алгоритма
Рекурсия. В основе разработанного алгоритма лежит рекурсивная процедура, которая выполняет метод прямого обхода дерева (preorder traversing). Данный метод относится к классу методов обхода дерева в глубину (depth-first traversing). Поиск по дереву начинается с прохода алгоритма от корня в глубь дерева, к возможному крайнему левому листу.
Необходимо учитывать, что уровни в дереве чередуются между игроками. Все нечетные уровни отражают возможные позиции после хода компьютера, нулевой (корень дерева) и четные – позиции после хода человека. В описываемом алгоритме заданная глубина просматриваемых уровней обязательно должна быть нечетным числом.
Оценочные функции. В алгоритме используются три оценочные функции. Первые две (ОФ1 и ОФ2) относятся к классу статических оценочных функций (функция, устанавливающая вес позиции без порождения потомков), а третья (ОФ3) – к классу функций формирования рабочих оценок (функция устанавливает вес позиции исходя из весов ее потомков).
ОФ1 служит для выявления листа дерева [1]. Определение, является ли узел листом, в рассматриваемом фрагменте дерева, осуществляется следующим образом: вызывается оценочная функция №1 (ОФ1), которая может возвращать только три значения (max – при победе, min – при поражении и 0 – при отсутствии чьей-либо победы).
ОФ2 вызывается алгоритмом при достижении заданной глубины рекурсии, возвращает значение в интервале (max-1, min+1). Функция возвращает оценку в зависимости от правил игры и заданной стратегии.
Одним из отличий представленного алгоритма от известных алгоритмов, решающих похожий тип задач, является использование двух статических оценочных функций вместо одной, что увеличивает скорость работы программы, так как алгоритму не надо тратить время на вычисление статической оценки в узле, которую все равно не планируется использовать, так как узел не является листом.
Основное предназначение ОФ3 состоит в выборе максимальной или минимальной (в зависимости от игрока) оценки из представленных. Данная функция сама не оценивает игровое поле, а оперирует данными, предоставленными ОФ1, ОФ2 или ОФ3 на более глубоком уровне дерева решений.
Минимакс. Определение наилучшей оценки, а, следовательно, и наилучшего хода, базируется на принципе минимаксного поиска (minimax search) [3]. Принцип работы минимакса достаточно прост. Предположим, что чем выше оценка, возвращаемая оценочной функцией, тем лучше эта позиция для компьютера (компьютер – максимизирующий игрок – max) и наоборот, чем меньше оценка, тем лучше эта позиция для человека (человек – минимизирующий игрок – min). Исходя из этого, алгоритм, чтобы не проиграть, из всех имеющихся вариантов должен выбрать позицию с максимально-возможной, из представленных, оценкой, а человек – с минимально-возможной оценкой. При таком подходе компьютер предполагает, что человек, как и сам компьютер, является идеальным игроком и всегда выбирает наилучший из всех возможных ходов.
Алгоритм
Исходный код алгоритма был составлен на высокоуровневом языке программирования MS VB.NET [4]. Для упрощения в данной работе приведена лишь поблочная структура алгоритма.
ПРОЦЕДУРА [Поиск]
БЛОК [Определение листа]
IF ОФ1 = 0 THEN
‘если нет ни победы, ни поражения
IF Глубина рекурсии = max THEN
‘если достигли листа
Value = ОФ2
ВЫХОД ИЗ ПРОЦЕДУРЫ [Поиск]
END IF
ELSE
‘если победа или поражение
Value = ОФ1
ВЫХОД ИЗ ПРОЦЕДУРЫ [Поиск]
End IF
КОНЕЦ БЛОКА [Определение листа]
БЛОК [Генерация дерева]
БЛОК [Ход]
РЕКУРСИВНЫЙ ВЫЗОВ ПРОЦЕДУРЫ [Поиск]
БЛОК [Возврат хода]
БЛОК [Формирование рабочих оценок] (ОФ3)
IF Глубина рекурсии = 0 THEN
БЛОК [Выбор координат для лучшего хода]
END IF
БЛОК [Подготовка рабочих оценок для передачи их вверх по дереву]
КОНЕЦ ПРОЦЕДУРЫ [Поиск]
Блоки алгоритма. Конструктивно алгоритм поиска состоит из нескольких блоков, объединенных в одну процедуру. Оценочные функции реализованы в виде двух внешних функций, вызываемых алгоритмом поиска при необходимости.
Блок [Определение листа]. Работа блока заключается в следующем: вызывается ОФ1 и проверяется значение, возвращенное ею. При возвращении функцией значений +Value или –Value функция присваивает значение данному листу и выходит из процедуры. Если же ОФ1 вернула значение 0, то проверяется не достиг ли алгоритм заданной глубины рекурсии. Если достиг, то вызывается ОФ2, и она присваивает листу оценку и опять выходит из процедуры. Если алгоритм не достиг максимальной глубины, то управление передается в блок [Генерация дерева].
Блок [Генерация дерева] и блок [Ход]. Дерево генерируется в зависимости от правил конкретной игры. В данном алгоритме результатом работы блока является номер позиции (или позиций), куда возможно сделать ход. Полученный результат передается в блок [Ход], в котором и происходит установка (перестановка) фишки (фигуры) в заданную позицию, после чего рекурсивно вызывается процедура [Поиск].
Блок [Возврат хода]. После завершения рекурсивного вызова управление передается в блок [Возврат хода]. Этот блок выполняет действия, прямо противоположные действиям, выполняемым в блоке [Ход]. То есть он возвращает игровое поле в то состояние, которое было до вызова [Ход].
Блок [Формирование рабочих оценок] (ОФ3). Блок является сердцем минимакса. В нем выбирается максимальная оценка для компьютера и минимальная – для человека на основе данных, полученных с помощью ОФ1, ОФ2 или ОФ3 путем анализа узлов на более глубоком уровне дерева решений.
Блок [Выбор координат для лучшего хода] начинает работать только тогда, когда процедура находится на нулевом уровне дерева. То есть алгоритм сгенерировал и “осмотрел” одну ветвь дерева, статические функции дали оценку листам, блок [Формирование рабочих оценок] выбрал из представленных оценок лучшую (для компьютера) или худшую (для человека), блок [Подготовка рабочих оценок для передачи их вверх по дереву] “поднял” оценку к корню дерева. Если она выше чем оценка у предыдущей ветви дерева, то Блок [Выбор координат для лучшего хода] отметит данную оценку как лучшую и запомнит координаты движения на один ход вперед. Так как при первом (нерекурсивном) запуске процедуры высшая оценка у ветви специально выходит за шкалу оценок (она занижена), то после обхода левой ветви полученная оценка всегда оказывается больше предыдущей, даже если она ведет к проигрышу компьютера. Это сделано для того, чтобы компьютер делал ход даже в заведомо проигрышной для него ситуации. После нахождения лучшего хода, процедура передает результат в вызвавший ее внешний блок кода.
Блок [Подготовка рабочих оценок для передачи их вверх по дереву] подготавливает оценку, определенную ОФ3 к передаче ее вверх по дереву. Процесс передачи основан на механизме рекурсии: а именно, на реверсивной передаче значений переменных-параметров функции, при завершении рекурсивного вызова.
Достоинства
К основным достоинствам алгоритма можно отнести модульную структуру, наличие двух статических функций, возможность добавления различных методов отсечений (альфа-бета, форсирование, кэширование и другие), достаточно высокая производительность, реализация примитивных методов отсечения (плавающая глубина рекурсии).
Применение
Описанный алгоритм, изначально спроектированный для компьютерной поддержки принятия игровых решений, может с небольшими изменениями использоваться в ситуациях, напрямую не связанных с игрой [5,6]. Это – разработка оптимальных компиляторов для языков программирования, решение управленческих проблем на предприятиях, анализ качества программного обеспечения, алгоритмы управления в системах автоматизации, системах автоматического регулирования и др.
литература
- Гроппен В. О. Основы теории принятия решений. Владикавказ, СКГМИ: Терек, 2004.
- Рафаэл Б. Думающий компьютер. М.: Мир, 1979.
- Слэйгл Дж. Искусственный интеллект. Подход на основе эвристического программирования. М.: Мир, 1973.
- Корнелл Г., Моррисон Дж. Программирование на VB.NET. СПб.: Питер, 2002.
- Мамонтов Д. В., Волошин С. Б. Машинно-ориентированный алгоритм анализа содержимого узлов n-нарного полного дерева, представленного в виде матрицы/Тезисы докладов всероссийской научной конференции “Перспектива 2005” , т. 2.
- Трахтендерц Э. А. Субъективность в компьютерной поддержке управленческих решений. М.: СИНТЕГ, 2001.