
Smp-архитектура
| Вид материала | Документы |
- Архитектура Вычислительных Систем», Университет «Дубна» лекция, 229.95kb.
- Неймана Термин «архитектура», 53.96kb.
- Реферат по Москвоведению на тему: "Архитектура Москвы ХХ века", 238.07kb.
- Архитектура ЭВМ. Лекция, 460.14kb.
- Учебно-тематическое планирование элективного курса по истории для 10 11-х классов, 217.51kb.
- «архитектура древнего рима», 450.36kb.
- Реферат «архитектура древнего рима», 449.39kb.
- Цикл лекций архитектура крито-микенского периода. Архитектура архаического периода, 12.87kb.
- Рабочая программа для высших учебных заведений По направлению: 270301- «Архитектура», 253.17kb.
- Рабочая программа для высших учебных заведений По направлению: 630100-«Архитектура», 148.24kb.
S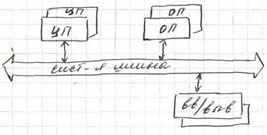 MP-архитектура
MP-архитектура
SMP - это один компьютер с несколькими равноправными процессорами. Все остальное - в одном экземпляре: одна память, одна подсистема ввода/вывода, одна операционная система. Слово "равноправный" (как и слово "симметричная" в названии архитектуры) означает, что каждый процессор может делать все, что любой другой. Каждый процессор имеет доступ ко всей памяти, может выполнять любую операцию ввода/вывода, прерывать другие процессоры и т.д. Но это представление справедливо только на уровне программного обеспечения. Умалчивается то, что на самом деле в SMP имеется несколько устройств памяти.
В традиционной SMP-архитектуре связи между кэшами ЦП и глобальной памятью реализуются с помощью общей шины памяти, разделяемой между различными процессорами. Как правило, эта шина становится слабым местом конструкции системы и стремится к насыщению при увеличении числа инсталлированных процессоров. Это происходит потому, что увеличивается трафик пересылок между кэшами и памятью, а также между кэшами разных процессоров, которые конкурируют между собой за пропускную способность шины памяти. При рабочей нагрузке, характеризующейся интенсивной обработкой транзакций, эта проблема является даже еще более острой.
В SMP оперативная память физически представляет последовательное адресное пространство, доступ к которому имеют одновременно все процессоры системы по единой коммуникационной среде: либо шинной архитектуры, либо коммутатором типа crossbar.
К основным достоинствам технологии однорангового доступа SMP относится следующие положения.
1. Простота организации вычислительного процесса, т.к. все процессоры обращаются к единой памяти по одному алгоритму.
2. Эффективность организации программного кода задачи, которая обеспечивается системным программным обеспечением, так как в процессе генерации кода нет необходимости учитывать разнообразие размещения данных в ОП.
3. Проверенное большим сроком эксплуатации программно-аппаратного решение, реализованное основными производителями вычислительных систем.
Наряду с достоинствами рассматриваемая технология обладает и рядом существенных недостатков.
1. Единый путь доступа к ОП, который становится узким местом, при увеличение числа процессоров в системе, т.е. достигается такой предельный трафик, при котором увеличение числа процессоров приводит к нелинейному росту производительности системы, либо, как предельный случай, к её снижению по причине конфликтных ситуаций возникающих на пути доступа к ОП. Попытка технологически решить эту проблему лишь отодвигает граничный трафик. Так архитектура с синхронной шиной доступа позволяла линейно увеличивать производительность системы в пределах до 8-ми процессоров. Пакетная организация системной шины, уменьшая количество взаимных блокировок, позволяет довести количество процессоров в системе до 16-ти. Технология crossbar, т.е. когда элементы вычислительной системы коммутируются напрямую друг с другом по протоколу точка-точка, позволила довести количество процессоров до 72-х. Однако, с увеличением количества коммутируемых элементов системы происходит резкий рост сложности crossbar и, как следствие, рост цены устройства.
2. Увеличение количества процессоров усложняет логическую часть вычислительной системы, которая отвечает за работу с кэшем, в частности за когерентность, что также влияет на производительность и цену системы.
Примеры компьютеров с SMP архитектурой: HP 9000 (до 32 процессоров), Sun HPC 100000 (до 64 проц.), Compaq AlphaServer (до 32 проц.)
MPP-архитектура
С
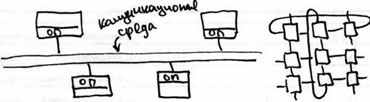 истема с массовым параллелизмом. В основе лежал транспьютер – мощный универсальный процессор, особенностью которого было наличие 4 линков (коммуникационные каналы связи). Каждый линк состоит из двух частей, служащих для передачи информации в противоположных направлениях, и используется как для соединения транспьютеров между собой, так и для подключения внешних устройств. Процессоры обмениваются между собой данными. После передачи байта данных пославший его транспьютер ожидает получения подтверждающего сигнала, указывающего на то, что принимающий транспьютер готов к дальнейшему приему информации. Большая прикладная задача разбивается на процессы (на отдельный процессор).
истема с массовым параллелизмом. В основе лежал транспьютер – мощный универсальный процессор, особенностью которого было наличие 4 линков (коммуникационные каналы связи). Каждый линк состоит из двух частей, служащих для передачи информации в противоположных направлениях, и используется как для соединения транспьютеров между собой, так и для подключения внешних устройств. Процессоры обмениваются между собой данными. После передачи байта данных пославший его транспьютер ожидает получения подтверждающего сигнала, указывающего на то, что принимающий транспьютер готов к дальнейшему приему информации. Большая прикладная задача разбивается на процессы (на отдельный процессор).MPP система начинается со 128 процессоров. Если число процессоров < 64 то это точно не MPP, хотя тоже оборудование, тот же компилятор. Сообщения пересылаются через ряд процессоров. Нет узкого горлышка как у SMP.
Р
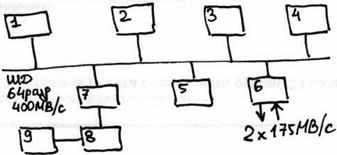
 ассмотрим MPP систему Paragon (Intel): Таких систем было выпущено несколько сотен, причем каждая из них была не похожа на другую (кол-во проц-в, размер ОП). Для реализации использовались проц-ры i860.
ассмотрим MPP систему Paragon (Intel): Таких систем было выпущено несколько сотен, причем каждая из них была не похожа на другую (кол-во проц-в, размер ОП). Для реализации использовались проц-ры i860.MRC (маршрутизатор) – набор портов, которые могут связываться между собой, и к каждому маршруту, может подключится компьютер.
Node – процессные узлы. 3 типа: 1) вычислительные 2) сервисные (UNIX-вые возможности для разработки программ, т.е. узлы для взаимодействия программиста). 3) узлы в/в (могут подключаться либо к общим ресурсам (дисковым), либо через них реализуется интерфейс с др. сетями).
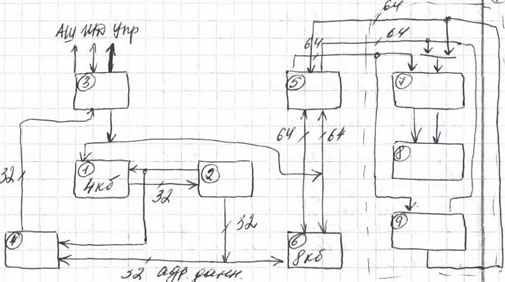
С
 хема процессорного ядра: 1) Исполнительный монитор (позволяет отлаживать, конролировать, записывать работу узла). 2) Проц-р приложений 3) ОП (32-64Mb) 4) Машины передачи данных (2 шт) Одна на прием др. на передачу. 5) проц-р сообщений (i860) 6) Контроллер сетевого интерфейса (порты которые выходят на MRC) 7) порт расширения, к которому через интерфейсные карты могли подкл-ся: 8) Интерфейс в/в 9) к которому подкл0сь либо ЛВС либо ЖД.
хема процессорного ядра: 1) Исполнительный монитор (позволяет отлаживать, конролировать, записывать работу узла). 2) Проц-р приложений 3) ОП (32-64Mb) 4) Машины передачи данных (2 шт) Одна на прием др. на передачу. 5) проц-р сообщений (i860) 6) Контроллер сетевого интерфейса (порты которые выходят на MRC) 7) порт расширения, к которому через интерфейсные карты могли подкл-ся: 8) Интерфейс в/в 9) к которому подкл0сь либо ЛВС либо ЖД.Число проц-ов для Paragon достигало 5000-8000.
Примерами MPP систем можно упомянуть: IBM RS/6000 SP, NCR WorldMark 5100M (До 128 узлов, 4096 процессоров).
К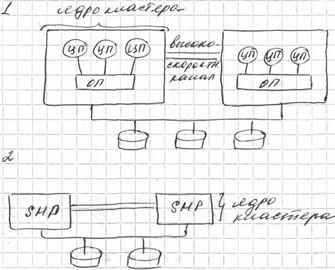 ластерная архитектура
ластерная архитектура
Кластерные системы представляют собой некоторое число недорогих рабочих станций или персональных компьютеров, объединенных в общую вычислительную сеть (подобно массивно-параллельным системам). Причиной возникновения кластерной архитектуры было то, что необходимую для пользователя работу было невозможно выполнить на одном компьютере или эта работа была настолько важна, чтобы приобрести дублирующее оборудование. Много позже этот подход удостоился общепринятого названия (термин "кластер" был введен в обиход компанией DEC), и его стали поддерживать поставщики систем. Сегодня кластерная архитектура является козырной картой практически каждого поставщика компьютерных систем, ориентированных на применение ОС UNIX, Novell Netware или Windows NT.
Кластер - это связанный набор полноценных компьютеров, используемый в качестве единого ресурса. Под словосочетанием "полноценный компьютер" понимается завершенная компьютерная система, обладающая всем, что требуется для ее функционирования, включая процессоры, память, подсистему ввода/вывода, а также операционную систему, подсистемы, приложения и т.д. Обычно для этого годятся готовые компьютеры, которые могут обладать архитектурой SMP и даже NUMA.
Словосочетание "единый ресурс" означает наличие программного обеспечения, дающего возможность пользователям, администраторам и даже приложениям считать, что имеется только одна сущность - кластер. У ведущих поставщиков систем баз данных имеются версии, работающие в параллельном режиме на нескольких машинах кластера. В результате приложения, использующие базу данных, не должны заботиться о том, где выполняется их работа. СУБД отвечает за синхронизацию параллельно выполняемых действий и поддержание целостности базы данных.
Кластеры демонстрируют высокий уровень доступности, поскольку в них отсутствуют единая операционная система и совместно используемая память с обеспечением когерентности кэшей. Кроме того, специальное программное обеспечение в каждом узле постоянно производит контроль работоспособности всех остальных узлов. Этот контроль основан на периодической рассылке каждым узлом сигнала "Я еще бодрствую". Если такой сигнал от некоторого узла не поступает, то этот узел считается вышедшим из строя; ему не дается возможность выполнять ввод/вывод, его диски и другие ресурсы переназначаются другим узлам (включая IP-адреса), а выполнявшиеся в вышедшем из строя узле программы перезапускаются в других узлах.
Возможность практически неограниченного наращивания числа узлов и отсутствие единой операционной системы делают кластерные архитектуры исключительно хорошо масштабируемыми. Успешно используются массивно параллельные системы с сотнями и тысячами узлов.
Примером кластерного решения можно назвать системы Compaq AlphaServer на базе своих серверов AlphaServer ES40.
RISC-архитектура
Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд (RISC). Признаки RISC: 1) Сокращен8ный набор команд 2) Большинство команд должно выполняться за 1 такт 3) Все команды обработки оперируют только содержимым Rg 4) RISC ‘похоронил’ принцип программного управления CPU 5) В RISC все команды имеют одинаковый формат(простой); мало способов адресации 6) RISC CPU имеют много Rg (100-200шт.) 7) Для использования RISC CPU нужны спец. анализирующие компиляторы + библиотеки функций для реализации функций, отсутствующих в CPU.
Структура Intel 860:
1-Кэш команд. 2-ЦП 3-блок управления шиной к кэш П 4-блок трансляции адреса 5-ППЗ + Файлы Rg (Проц-р Плав. Запятой) 6-Кэш Данных 7-блок умнож. ППЗ 8-блок суммир. ППЗ 9-граф.проц.
Проц. с част. 50МГц. Проц. векторный. Процессор с плавающей точкой поддерживает все скалярные операции, а к векторным конвейерным операциям относятся опер. +,-,*,преобразование к целому. Граф. проц. выполняет 64 разрядные логические операции над 8,16,32 разрядными числами. Rg файлы сод-т по 32Rg с плавающей точкой Это полно разрядный 64 разр. процессор. У блока 10 есть возможность выполнения 128 разрядной арифметики. Этот процессор реализован для: предполагается что i860 будет исполнен в качестве сопроцессора при работе с плавающей точкой.
Модель использования i860:
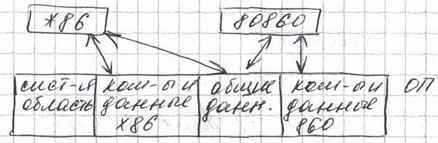
У i860 вся система работы с ОП была абсолютно идентична x86. ЦП (2) в i860 был 4 ступенчатый. Основное применение для i860 военное.
VLIW – “очень длинное слово инструкции”. (256/512 бит). VLIW предлагает: в спец. полях команды каждому устройству предписывается действ-е, множество исполнит. устройств размещается на кристалле, каждому устройству команд выделяется собственное поле, внутри поля заносится операторы, устанавливаются режимы конвейера и др. Загружается длинное слово, программная система записывает в поля битовую комбинацию и управление осуществляет программная система.
Нынешние тенденции применение технологии явного параллелизма на уровне команд (EPIC) – поля жестко не приписываются конвейерам, происходит организация очередей, планирование операций на нижнем уровне осуществляется внутри кристалла. В EPIC-архитектуре используется подход, базирующийся на применении команд переменной длины. Команда состоит из слогов длиной 32 разряда каждый. Число этих слогов может меняться от 2 до 16, причем данную архитектуру можно еще расширить – до 32 слогов. Любая команда всегда включает 1 слог заголовка и еще от 1 до 15 слогов, указывающих на операции, которые могут выполняться параллельно. Слог заголовка содержит информацию о структуре команды и ее длине, что облегчает дешифрацию команды переменной длины. Применение заголовка позволяет не проводить предварительного декодирования команд перед их помещением в кэш команд. Отрицательной стороной введения поля заголовка является некоторое увеличение длины команды.
Конвейерная организация
Основа (начало):
СловаП[Выборка команд][Декодирование][Выполнение]Рез
Tпосл ~ Снс – время одной операции. Tконв ~ С/N, где N-число ступеней конвейера. Ограничения: 1) нет возможности разбить на ∞ число ступеней (физически) 2) многоступенчатый конвейер работает неэффективно в случае частого изменения задач.
Явный конвейер – если выполнены условия: 1) Каждое вычисление базовой функции независимо от предыдущей 2) Вычисление каждой Функции треб-т одной и т.ж. цепочки подфункций. 3) Подфункции тесно связаны между собой вход связан с выходом 4) Времена выполнения различных подфункций приблизительно равны.
К
 онвейерное выполнение команд на примере операции +:
онвейерное выполнение команд на примере операции +:1) IFETCH – используется СК и выбирается очередная команда из П 2) DECODE – декодирование команд 3) EAGEN – выработка адреса П для операторов 4) OPER FETCH1 – выборка 1-го оператора 5) 2-го опер. 6) EXEC – выполнение операции 7) SAVE – сохранение результатов 8) END OP – завершение опер. (модиф. СК, выработка слово-состояния, установка флагов …)
Таблица занятости: строки = количество ступеней конвейера Столбцы = такты синхронизации ступеней конвейера.
| 1 | 2 | 3 | 4 | | |
| | 1 | 2 | 3 | 4 | |
| | | 1 | 2 | 3 | 4 |
Инициация таблицы занятости наступает тогда когда начинается вычисление которое проследует по определенному ею пути.
Попытка инициации операций использующих одну и туже ступень в один и тот же период времени называется столкновением.
Операции A и B выполняются на 3 ступени Конвейере:
| | | A | | A | | A | | B | B | | | | | B | | | B | B | |
| | A | | A | | A | | | | B | | B | | | | A | | B | ||
| A | | A | | A | | A | | | | B | | B | | A | | A | |
Латентность – временная задержка между 2 событиями.
Латентность – число единиц времени разделяющих инициации одной или различных таблиц занятости (>= 0)
Вычисление ср. L: берется среднее время выполнения некоторого количества операций и делится на количество операций. (может быть дробной)
Цель стратегии диспетчеризации: (управляющей стратегии) это выработка последовательности моментов t в кот. должны выполнятся инициации или выработка такой последовательности L между инициациями кот. минимизирует среднюю латентность.
Стратегия кот. всегда между 2 инициациями вводит минимальную из латентностей возможную в текущий момент времени называется жадной.
Пример A1, A2, A3 (пачка операций)
| 1 | 1 | | 2 | 2 | | 1 | 1 | | 2 | 2 | 3 | 3 | | |
| | | 1 | | 1 | 2 | | 2 | | | | | | 3 | |
| | | | 1 | | 1 | 2 | | 2 | | | | | | 3 |
↑ ↑ ↑
<3,8> - цикл латентности по “ж” стратегии. Lср = 5.5
MAL (Минимальная средняя латентность) – такая латентность которую можно достичь (теорит.) на любом из допустимых послед-й латентности.
ЛЕММА: для любого конвейера со статической конфигурацией величина MAL всегда >= max числу меток в любой строке этой таблицы.
Векторные процессоры
Особенности:
1) Наличие в системе команд операций над векторами. После трансляции исполнительный код состоит из: а) операций б) команды вычисляются значения индексов в) команды обращения к П г) проверка параметров операндов цикла.
2) желание программиста отказаться от использования циклов при работы с векторами.
Архитектура аппаратных средств:
1
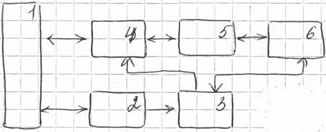 ) ОП. В ОП хранятся некоторые данные в состав которых входят вектора. И хранятся программы внутри которых встречаются векторные команды. 2) Скалярный процессор - обычный процессор который выполняет все обычные функции. Имеет дополнительное св-во: при получении векторной команды он передает ее векторному контроллеру. 3) Векторный контроллер – процессор который выполняет только векторные команды, декодирует, вычисляет адреса, настраивает для выполнения (6), отслеживает выполнение векторных команд. 4) Контроллер векторной П – принимает виртуальные адреса из векторного контроллера и по ним вычисляет физические адреса обращения к П, реализует эти запросы и передает их в Буферную память. 5) Локальная (буферная П) – содержит очередь. 6) аналитический конвейер – выполняет всю арифметику.
) ОП. В ОП хранятся некоторые данные в состав которых входят вектора. И хранятся программы внутри которых встречаются векторные команды. 2) Скалярный процессор - обычный процессор который выполняет все обычные функции. Имеет дополнительное св-во: при получении векторной команды он передает ее векторному контроллеру. 3) Векторный контроллер – процессор который выполняет только векторные команды, декодирует, вычисляет адреса, настраивает для выполнения (6), отслеживает выполнение векторных команд. 4) Контроллер векторной П – принимает виртуальные адреса из векторного контроллера и по ним вычисляет физические адреса обращения к П, реализует эти запросы и передает их в Буферную память. 5) Локальная (буферная П) – содержит очередь. 6) аналитический конвейер – выполняет всю арифметику.Архитектура команд машинного уровня
Любая команда задает для машины: 1) функцию 2) операнды 3) статус, фиксир. в рез-те 4) след. команда
В векторных компьютерах содержится большое кол-во векторных команд (в отличии от скалярных)
Спецификация операндов: Для адресации к вектору задают: 1) начало и конец вектора 2) тип данных 3) размер
При работе с векторами различной длины идет регулировка выполнения операций.
Зацепление команд – аппаратно программная реализация. (C=а+б, д=C*е) Осуществляется избежание записи C в П и тут же извлечение ее для выполнения следующей операции.
Общая архитектура:
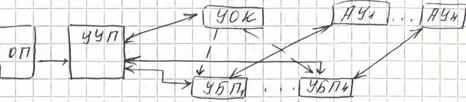
УОК – устройство обработки потока команд УБП – устройство буфера П АУ – конвейер УУП – устройство управления П
Конвейер:
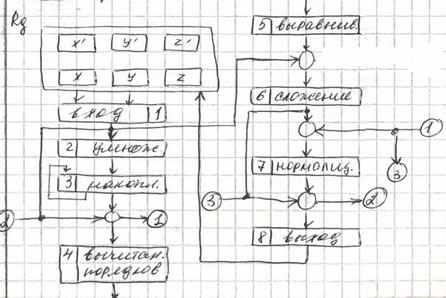
Таблица занятости:
| X | | | X | | | | X | | | | | | |
| | | | | | | | | | | | | ||
| | | | | | | | | | | | | ||
| | | | | | | | X | | | | | ||
| | | | | | | | | X | | | | ||
| | | | X | | | | | | X | | | ||
| | | | | | | | | | | X | | ||
| | X | | | X | | | | | | | X |
+-е с фиксированной точкой +-е с плаваю. точкой
Примерами векторных компьютеров можно назвать: 1) Intel 860 2) CRAY C90 (векторно-конвейерный компьютер, объединяющий в максимальной конфигурации 16 процессоров, работающих над общей памятью.) 3) NEC SX-5
О рганизация кэш-памяти
рганизация кэш-памяти
CASH – П. которая строится на статических элементах. (↓ объем,↑ стоим. произв.) В CASH располагаются копии блоков ОП. CASH-попадание – процессор нашел необходимые данные в CASH. CASH-промах – нужного адреса нет, происходит перекачка необходимой информации в кэш и снова обращение к кэш. Кэш вставляется между ОП и процессором. Т.ж. может быть кэширование винчестера.
1) Принцип локальности программ – поскольку обращение в П носит не случайный характер, а выполняется в соответствии спец. программы, то при считывании данных из П с высокой степенью вероятности можно предположить что программа вновь обратится к этим данным.
2) Принцип пространственной локальности – весьма вероятно что в ближайшем будущем программа обратится к ячейке которая следует за той к которой она обращается в текущий момент времени.
Tдоступа = Тобращение к кэш + Kпромаха * Tпотерь
Tпотерь – опре-ся t на подкачку CASH.
Усредненные данные: CASH-попадание: Tпопад.=1-4 такта. CASH-промах: Tпотери =8-32т. Kпромаха=1-20%.
Принципы размещения блоков в CASH-П:
1) Если каждый блок основной П имеет только одно фиксированное место, на котором он может появиться в CASH-П, то такая CASH-П называется кэшем с прямым отображением. Это наиболее простая организация CASH-П, при которой для отображение адресов блоков основной П на адреса CASH-П просто используются младшие разряды адреса блока. Т.О. , все блоки основной П, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок CASH-П, т.е. (адрес блока CASH-П) = (адрес блока основной П) mod (число блоков в CASH-П).
2) Если некоторый блок основной П может располагаться на любом месте CASH-П, то кэш называется полностью ассоциативным.
3) Если некоторый блок основной П может располагаться на ограниченном множестве мест в CASH-П, то кэш называется множественно-ассоциативным. Обычно множество представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами. Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока П (индексом): (адрес множества CASH-П)=(адрес блока основной П) mod (число множеств в CASH-П).
C
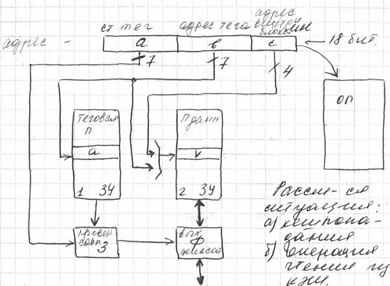 ASH с прямым отображением: Емкость CASH: 2Kслов=128 блоков. Размер блока: 16 слов. Емкость ОП: 256Кслов=16384 блоков. Адресация ОП 18 бит.
ASH с прямым отображением: Емкость CASH: 2Kслов=128 блоков. Размер блока: 16 слов. Емкость ОП: 256Кслов=16384 блоков. Адресация ОП 18 бит.1.ЗУ – теговая П. 2.ЗУ - П данных. a – тег. b – адрес тега. с – адресом внутри блока. 3 – проверка совпадения. Ф – выходной фиксатор.
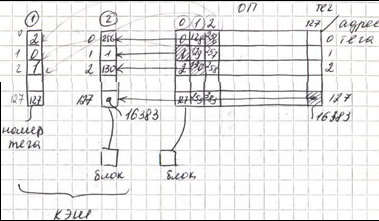
1-П тегов 2-П данных “-” все блоки одной стр. конкурируют друг с другом.
При возникновении промаха, контролер кэш-П должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание проверяется только один блок и только этот блок может быть замещен. Очень часто организация кэш-П в разных машинах отличается стратегией выполнения записи.
1) Сквозная запись – обновляется информация в ОЗУ и одновременно в кэш, при условии что этот блок в кэш есть.
2) Запись с обратным копированием – обновляется только содержимое кэш П. Если данного блока нет в кэш то он перекачивается в кэш, а затем обновляется.