
Дисциплина «Инженерия знаний» Реферат Агенты и мультиагентные системы. Системы поиска в Интернет
| Вид материала | Реферат |
- "Программные агенты и мультиагентные системы", 138.64kb.
- Поисковые системы, 429.87kb.
- «Мультиагентные системы». Школу посетит дружная команда исследователей — Петр Скобелев,, 12.72kb.
- Дисциплина «Инженерия знаний» Реферат Онтологии, 257.23kb.
- Модель автоматизированной системы розничной торговли с использованием средств радиочастотной, 18.5kb.
- Рабочая программа учебной дисциплины (модуля) в справочно-правовые системы и правовые, 548.78kb.
- Говоря простым языком, системы баз знаний это искусство, которое использует достижения, 267.75kb.
- 2. Лекция: Системы представления знаний, 171.88kb.
- К. П. Бутусов Вданной статье излагаются некоторые результаты 40-летней работы автора, 347.22kb.
- Поисковые системы в интернет, 565.6kb.
4.1.Модель МАС информационного поиска в глобальной сети
П
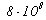 о мере развития глобальной компьютерной сети Интернет и увеличения объема содержащейся в ней информации, все более актуальной становится проблема информационного поиска. Существующие информационно-поисковые сервисы и системы (ИПС) недостаточно хорошо справляются со своими задачами. Так, по последним исследованиям, ни одна из глобальных ИПС не покрывает более чем 16% из содержащихся во всемирной сети страниц.
о мере развития глобальной компьютерной сети Интернет и увеличения объема содержащейся в ней информации, все более актуальной становится проблема информационного поиска. Существующие информационно-поисковые сервисы и системы (ИПС) недостаточно хорошо справляются со своими задачами. Так, по последним исследованиям, ни одна из глобальных ИПС не покрывает более чем 16% из содержащихся во всемирной сети страниц.По всей вероятности, традиционные системы поиска не смогут обеспечить достаточного охвата информационных ресурсов на протяжении всего периода лавинообразного разрастания сети, который будет продолжаться ближайшие 10–20 лет.
В последнее время начали разрабатываться поисковые системы, основанные на концепции интеллектуальных агентов. В первую очередь следует отметить систему "Amalthaea" – "развивающуюся мультиагентную экосистему для индивидуализированной фильтрации, обнаружения и наблюдения". Amalthaea использует методы машинного обучения и изучает интересы и привычки пользователей, приспосабливаясь к ним через какое-то время, одновременно исследуя новые области, которые могут быть интересны пользователю. Взаимодействие агентов реализовано путем создания экологической/экономической системы согласно. Другая интересная система – проект SAIRE – масштабируемый, основанный на агентах механизм информационного поиска. SAIRE обеспечивает интегрированный доступ пользователя к распределенным источникам данных, включая цифровые библиотеки NASA и NOAA.
Основными недостатками подобных систем является, в первую очередь, недостаточность возможности предварительного обучения агентов на уже имеющемся материале, а также невозможность коррекции поиска с помощью материалов из других источников.
Кроме того, при разработке системы информационного поиска необходимо учитывать наличие так называемых “сообществ” – хорошо связанных групп сайтов, содержащих материалы близкой тематики. Выделяются “центральные” страницы – содержащие большие списки ссылок и страницы, на которые ведут многие ссылки, – “авторитетные” страницы.
В данной работе рассматривается проект мультиагентной системы, которая является частью системы автоматизированного поиска информации в глобальной сети.
4.1.1.Структура системы информационного поиска
Многие этапы процесса поиска информации в глобальной сети поддаются автоматизации. Рассмотрим структуру автоматизированной системы поиска информации в сети Интернет. Между пользователем и информационным наполнением сети располагаются три слоя систем поиска информации (рис. 4).
Первый слой — это ИПС глобальной сети. К ним относятся списки ссылок на ресурсы сети, универсальные и тематические каталоги ресурсов и информационно-поисковые системы. ИПС осуществляют первичный сбор информации о ресурсах Интернет и фактически обеспечивают доступ к большей их части через сравнительно небольшое — порядка 103 количество входов для поиска. Все системы первого слоя расположены на серверах глобальной сети и полностью автономны по отношению к системам последующих слоев.
Второй слой представляет собой мультиагентную систему (МАС), выполняющую поисковые операции. Основные задачи данной системы: динамическое распределение поискового процесса по различным ИПС; осуществление всех фаз взаимодействия с ними (формализация поискового запроса, обращение к ИПС и получения результата – списков ссылок на ресурсы сети);проверка актуальности ссылок и получении выбранных документов; проверка полученных документов на релевантность и ранжирование (совместно с системой третьего слоя). МАС осуществляет адаптацию поискового процесса, как к источникам, так и к потребителю информации. Оптимальное место расположения МАС - сервер локальной сети, обслуживающий группу п
ользователей.
Третий слой — это система управления документами (СУД), ориентированная на работу в глобальной сети. Основной задачей СУД, в данном контексте, является автоматизация составления поискового запроса (также должны быть реализованы функции взаимодействия с системами обработки документов, с надсистемой управления деловыми процессами, с подсистемой архивации и с подсистемой публикации документов в сети). СУД должна быть расположена на компьютере пользователя, однако, некоторые ее подсистемы могут находиться на сервере.
Основная идея использования СУД заключается в создании поискового Рис.4. Общая структура системы автоматизированного поиска в глобальной сети Интернет.
запроса на основе анализа имеющихся у пользователя документов по искомой тематике.
Система производит автоматическую индексацию всего массива текстовых документов пользователя с использованием словаря стоп-слов, и нормализацией словоформ.
На основании индексов строится векторное представление документов. Тексты среднего и большого объема подвергаются декомпозиции на отдельные поддокументы. В дальнейшем будем употреблять термин "документ" в смысле "текстовый документ или часть большого текстового документа (поддокумент), выделенная по некоторым правилам", где "большой документ" есть нечеткое понятие. На основе векторного представления осуществляется иерархическая кластеризация, приводящая к разбиению множества документов на тематические группы.
К методу кластеризации предъявляются следующие требования: устойчивость при добавлении документов, устойчивость к ошибкам в документах, независимость от первоначального порядка документов. СУД осуществляет включение поступающих от МАС новых документов в построенную иерархическую кластерную структуру.
Автоматизированное построение поискового запроса происходит в диалоговом режиме. Пользователь выбирает уровень иерархии кластеров и релевантный кластер этого уровня (либо несколько кластеров, указывая их релевантность), а также, при необходимости, осуществляет корректировку разбиения, путем добавления или исключения из выбранного кластера отдельных документов.
4.1.2. Организация МАС
Предполагается использовать три типа агентов: агенты данных (D–агенты); поисковые агенты (S–агенты) и новостные агенты (N–агенты). Кроме того, система включает подсистемы репозитория и арбитра ресурсов.
Агенты данных составляют важнейшую часть системы, они служат интерфейсом с СУД, взаимодействуют с поисковыми агентами и непосредственно с содержательными ресурсами глобальной сети. Каждому документу, содержащемуся в СУД поставлен в соответствие агент данных. Будем называть такие агенты легитимными. Также могут существовать D–агенты, для которых нет соответствующего документа СУД – нелигитимные агенты.
Легитимные D–агенты создаются немедленно после добавления в СУД нового документа. Уничтожаются они только при удалении документа из СУД. Агент может находиться в трех основных состояниях – спящем, активном и состоянии сохраненного поиска (рис. 5). Нелегитимные D–агенты могут создаваться во время поискового процесса и уничтожаются после его завершении.
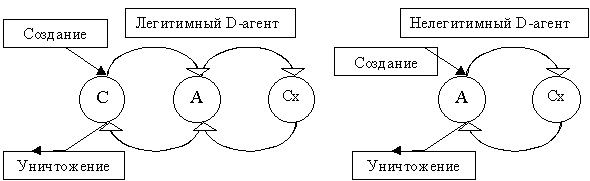
Рис.5. Состояние D-агента и переходы между ними.
D
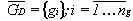 –агент в спящем состоянии характеризуется идентификационным номером и двумя независимыми векторами. Первый вектор (генотип агента) есть набор ключевых слов соответствующего документа, т. е. является вектором документа. Количество компонент вектора не фиксировано и может изменяться в границах от одного до нескольких десятков терминов. Порядок следования указывает на вес термина и определяется его частотой в исходном документе. Таким образом, этот вектор является неизменным для каждого D–агента.
–агент в спящем состоянии характеризуется идентификационным номером и двумя независимыми векторами. Первый вектор (генотип агента) есть набор ключевых слов соответствующего документа, т. е. является вектором документа. Количество компонент вектора не фиксировано и может изменяться в границах от одного до нескольких десятков терминов. Порядок следования указывает на вес термина и определяется его частотой в исходном документе. Таким образом, этот вектор является неизменным для каждого D–агента. Второй вектор есть упорядоченный набор ссылок на S–агентов. Будем называть его фенотипом D–агента. Порядок ссылок определяет очередность обращения к соответствующим поисковым агентам. На протяжении своего существования агент может адаптироваться к внешним условиям путем изменения своего фенотипа. Длина вектора фиксирована для всех D–агентов. Длина вектора должна быть на порядок меньше количества используемых S–агентов.
В активном состоянии D–агенту принадлежит также список – очередь, состоящая из адресов ресурсов сети (URL), подлежащих исследованию, величин, характеризующих априорную релевантность этих адресов Ripri , а также указателей на S–агента, нашедшего этот адрес. Кроме этого задан массив флагов S–агентов, которые указывают, происходило ли уже успешное обращение к данному поисковому агенту. Каждому активному D–агенту назначена некоторая изменяющаяся скалярная величина Re Sd , необходимая для организации экономической модели.
Поисковые агенты обеспечивают интерфейс между МАС и глобальными ИПС. Каждой используемой в системе ИПС поставлен в соответствие S–агент. В некоторых, особых случаях, когда соответствующая ИПС вырабатывает исключительно качественные результаты, ей могут быть поставлены в соответствие несколько копий одного S–агента. Поисковые агенты создаются при разработке системы. Во время использования системы пользователем либо разработчиком могут как создаваться новые S–агенты, при появлении новых глобальных ИПС, так и изменяться старые, для отражения изменений в интерфейсах существующих ИПС. Уничтожение поисковых агентов производится, главным образом при прекращении существования соответствующей глобальной ИПС. Основное назначение S–агентов состоит в выполнении полученного посредством D–агентов запросов на соответствующих ИПС и предварительной обработки их ответов, с преобразованием результатов в единую форму. Поисковые агенты выполняют свою задачу на основании имеющейся у них информации об интерфейсе и о реализации информационно-поискового языка (ИПЯ) соответствующей ИПС
Новостные агенты обеспечивают интерфейс между МАС и обнаруженными в сети ценными (высокоинформативными) источниками информации. Одному такому источнику информации ставится в соответствие один N–агент. Новостные агенты создаются пользователем или автоматически, при обнаружении системой множества релевантных запросам документов, локализованного на некотором узле сети либо часто обновляющегося списка ссылок на релевантные документы. Некоторое количество N–агентов может быть создано при разработке. Уничтожение N–агентов может осуществляться при прекращении существования источника информации.
Репозиторий представляет собой СУБД, содержащую несколько баз данных. Главная из них – это БД адресов найденных документов, со следующими полями: адрес (URL); состояние процесса обработки документа; текущее значение релевантности Ricur; количество нахождений данного адреса; номер агента, в очереди которого находится в данный момент этот адрес. Следующая БД содержит список созданных N–агентов, заданные пространства относящихся к ним адресов, флаг состояния и прочее. Имеется БД по D–агентам, с полем, указывающим на их состояние. Также задана БД по S–агентам. Через ссылки, содержащиеся в этих базах, осуществляется адресация агентов. Репозиторий необходим для эффективного разделения работы агентов и исключения дублирования. Репозиторий также служит для выявления авторитетных источников информации.
Арбитр ресурсов осуществляет перераспределение ресурсов МАС между отдельными D–агентам для обеспечения эволюции путем отбора наиболее приспособленных. Арбитр ресурсов следит за численностью популяции D–агентов.
4.1.3. Поисковый процесс.
Процесс поиска начинается с того, что построенный в результате взаимодействия СУД с пользователем запрос, в виде множества ссылок на документы СУД, поступает в МАС. Соответствующие D–агенты переходят из спящего состояния в активное. D–агенты поочередно, в некотором порядке, определяемом экономической моделью, обращаются к S–агентам, сначала к тому, который указан первой ссылкой в фенотипе. Если соответствующий поисковый агент занят обработкой другого запроса, то происходит обращение к следующему S–агенту в порядке, указанном в фенотипе, до тех пор, пока не будет найден первый свободный поисковый агент (рис. 6).
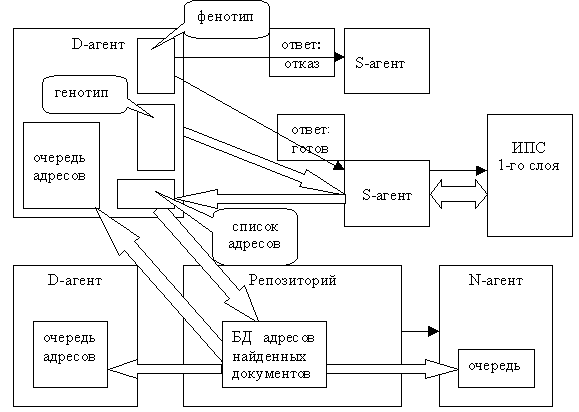
Рис.6.Поисковый процесс.Этап формирования очереди адресов.
Определенный таким образом S–агент преобразует переданный ему вектор генотипа D–агента на ИПЯ и обращается к ИПС. ИПС возвращает агенту список ссылок. S–агент на основе знаний о своей ИПС присваивает каждой ссылке некоторые значения априорной релевантности Ripri . Список ссылок и значения релевантности передаются D–агенту, от которого был получен запрос.
Затем D–агент обращается в репозиторий, где проверяется новизна полученных ссылок. Далее возможны несколько вариантов развития событий. Если указанный адрес уже занесен в репозиторий, то он не будет исследоваться данным агентом (кроме того случая, когда он приписан к данному агенту). В этом случае если исследование адреса еще не закончено, то производится увеличение текущего значения априорной релевантности на величину, полученную обратившимся D–агентом от нашедшего ссылку S–агента Ricur:=Ricur+Ripri . Полученный результат сохраняется в репозитории и передается обрабатывающему этот адрес D–агенту. Счетчик обнаружений этого адреса в репозитории увеличивается на 1.
Неизвестные ранее адреса добавляются в репозиторий. Счетчик обнаружений данного адреса устанавливается в 1. Если указанный адрес не был внесен ранее, но находится в области, относящейся к какому-либо N–агенту, то происходит активизация этого новостного агента, который и исследует данный адрес. В противном случае адрес признается новым и разрешается его исследование. В репозитории остается также ссылка на этот D–агент. Кроме того, разрешается исследование известных, но не исследованных ранее адресов, которые не находятся в очередях активных агентов.
Первоначально каждый D–агент обращается к нескольким свободным S–агентам. Разрешенные для исследования адреса создают очередь. Порядок в очереди определяется величинами Ripri . Первыми обрабатываются адреса с большими значениями. Адреса с низким значением Ripri обрабатывать не следует – т. к. вероятность того, что они будут релевантны чрезвычайно мала. Когда исследованы все адреса из начала списка, D–агент производит следующий сеанс обращений к S–агентам. При этом помимо добавления в очередь новых адресов может также происходить увеличение значений для уже известных адресов, если они будут найдены повторно. Изменение порядка очереди может также происходить вследствие обнаружения имеющихся в ней адресов другими агентами.
Если через какое-то время будет обнаружено, что данным D–агентом уже задействованы все доступные в системе поисковые агенты, т. е. для всех S–агентов установлены соответствующие флаги, и в очереди нет адресов с высокой априорной релевантностью, то дальнейшая деятельность агента нецелесообразна. Если агент легитимен, то он переходит в спящее состояние, иначе уничтожается. В репозиторий вносится информация о том, что оставшиеся в очереди адреса не были исследованы.
Обработка адреса из очереди состоит из нескольких этапов. Вначале D–агент проверяет наличие документа по данному адресу. Если несколько попыток обратиться к документу были безуспешны, документ помечается как (временно) недоступный и исключается из очереди. В репозиторий вносится информация о типе возникшей ошибки.
Если документ обнаружен, то он доставляется в систему с места его нахождения. Документ индексируется, при необходимости, разбивается на поддокументы, после чего осуществляется его сравнение с генотипом. Результат сравнения (расстояние между соответствующими точками векторного пространства) есть апостериорная релевантность Ripost рассматриваемого документа. Эта величина заносится в репозиторий и передается арбитру ресурсов для оценки эффективности деятельности агента.
Если Ripost > R0 превышает некоторое пороговое значение , то исследуемый документ добавляется в СУД, после чего на его основе происходит создание нового легитимного D–агента (рис. 4). Генотип нового агента однозначно определяется документом. Фенотип строится на основе фенотипа нашедшего его D–агента с некоторыми изменениями: на первое место ставится S–агент, давший адрес этого документа, остальные элементы сдвигаются и некоторая их часть, находящаяся ближе к концу вектора, с определенной вероятностью заменяется ссылками на других, случайным образом выбранных, S–агентов (т. е. происходит мутация). В фенотипе исходного D–агента происходят аналогичные изменения. Таким образом осуществляется адаптация D–агентов к глобальным ИПС. Новый D–агент сразу после создания переходит в активное состояние. Впоследствии, пользователь может признать релевантность документа недостаточной и исключить его из системы.
Обнаруженные в теле документа ссылки подлежат той же обработке, что и ссылки, полученные от S–агентов. Значения априорной релевантности ссылок, принимается равным апостериорной релевантности рассмотренного документа Ripri := Ripost .
Процесс поиска прекращается после нахождения некоторого, заданного пользователем, количества релевантных документов, либо по истечении некоторого времени.
Поиск может быть сохранен для дальнейшего использования. В этом случае нелегитимные агенты не уничтожаются, но сохраняются, вместе со всеми текущими значениями, кроме, быть может,. массива флагов S–агентов. Для легитимных агентов также сохраняются данные их активного состояния.
4.1.4. Экономическая модель
Присвоенная каждому активному D–агенту величина ReSd, которую будем называть ресурсом агента, используется для оценки эффективности деятельности агента. Ресурс агента имеет смысл уровня жизни или количества денег и показывает, какое количество машинного времени – вычислительных и иных ресурсов, в том числе емкости канала связи, может быть выделена данному агенту.
Совершение агентом каких-либо действий приводит к уменьшению его ресурса. Для упрощения будем рассматривать только один укрупненный тип действий – исследование документа. Исследование одного документа приведет к уменьшению ресурса агента на некоторую фиксированную величину, которую примем за единицу ресурса.
Для обеспечения устойчивости системы, ресурсы агентов должны пополняться. Каждый D–агент после выполнения исследования документа сообщает арбитру ресурсов результаты этой операции – Ripost . После получения некоторого количества подобных сообщений, зависящего от числа активных агентов, арбитр осуществляет перераспределение ресурсов. Вся сумма затраченных ресурсов распределяется между несколькими агентами, показавшими наибольшую релевантность в этой выборке.
Величина потока ресурсов ограничена сверху ресурсами компьютера и системного ПО. При хорошо определенном запросе, выполняемом на достаточно мощном компьютере, начальное количество легитимных D–агентов существенно меньше допустимого ND<
4.1.5. Процедура СОЗДАНИЕ НОВЫХ D–АГЕНТОВ
Д
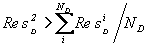
ля создания новых нелегитимных D–агентов необходимо применить стандартный для эволюционного программирования алгоритм. Используются два активных агента: первый, с максимальным ReS1d, и другой, случайным образом выбранный среди агентов первой половины распределения :
Н
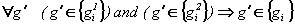
овый агент получает свой уникальный номер и два вектора. Вектор генотипа образуется с помощью кроссинговера. Длина генотипа определяется как целое от среднего арифметического длин генотипов родителей: ng=[(n1g+ng2)/2]. В генотип обязательно заносятся компоненты, присущие генотипам обеих предков. Остальные компоненты выбираются из компонентов генотипов родителей случайным образом:
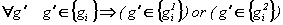
сохраняя при этом очередность.
Ф
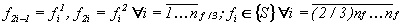
енотип на две трети формируется из первых элементов фенотипов родителей, и на одну треть – случайным образом, из ссылок на все доступные S–агенты. Таким образом для получения фенотипа используется как кроссинговер, так и мутация. .
Новый агент изначально находится в активном состоянии и получает ресурс, равный среднему по популяции. Одновременно, при необходимости, агенты с минимальным ресурсом исключаются из популяции.