
Предисловие Системы управления базами данных (субд) – это программные комплексы, предназначенные для работы со специально организованными файлами (массивами данных, долговременно хранимыми во внешней памяти вычислительных систем), которые называются
| Вид материала | Документы |
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Программа курса лекций "Базы данных в научных исследованиях", 49.32kb.
- Система управления базами данных это комплекс программных и языковых средств, необходимых, 150.5kb.
- Лекция 2 Базы данных, 241.25kb.
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
- Вопросы к государственному экзамену по специальности «Информационные системы и технологии», 39.93kb.
- Лекция № Технологии баз данных, 92.24kb.
- Проектирование базы данных, 642.58kb.
- Системы управления базами данных, 313.7kb.
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
4.3.2. Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием ее в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева.
Преобразование связи типа "один ко многим" между предком и потомком осуществляется практически автоматически в том случае, если потомок имеет одного предка, и происходит это следующим образом. Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа "один ко многим". Сегмент со стороны "много" становится потомком, а сегмент со стороны "один" становится предком.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Пусть концептуальная модель имеет вид, как на рис. 4.14, а. Тогда соответствующая ей иерархическая структура должна содержать два дерева, как показано на рис. 4.14, б. Реализация подобной структуры напрямую требует Дублирования информации. В приведенном примере это касается информации о группах. Но дублирование информации — это нежелательное явление в информационных системах. Из-за его присутствия возникает возможность нарушения непротиворечивости данных, при этом и объем памяти расходуется неэффективно, а значит, оно должно быть минимизировано.
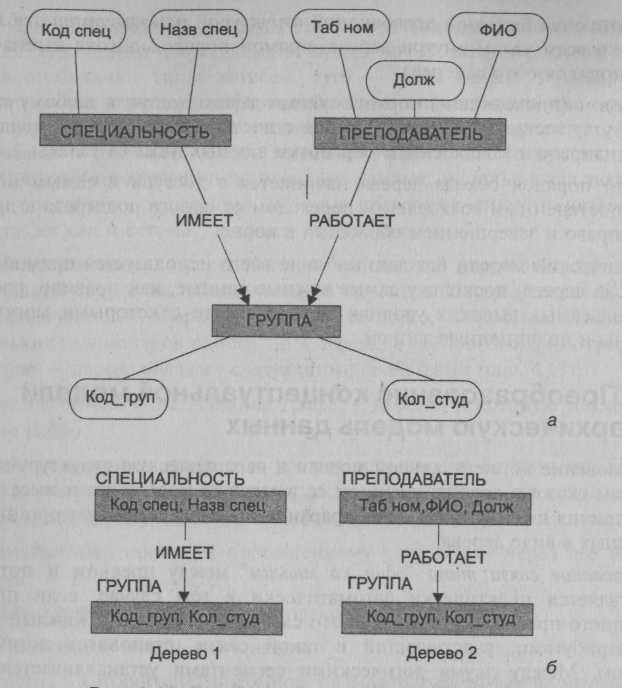
Рис. 4.14. Преобразование связи с двумя предками (а — концептуальная модель; б — иерархическая модель)
Вносимая полученной структурой избыточность данных может быть ограничена при помощи виртуальных сегментов и указателей следующим образом. Сегмент запоминается полностью только один раз. Когда сегмент должен дублироваться в двух или более деревьях все последующие вхождения сегмента запоминаются как указатели на место хранения данного сегмента. Такие вхождения называются виртуальными сегментами. При их использовании избыточности данных не возникает, а требуется лишь дополнительная память для хранения указателей.
Преобразование бинарной связи шипа "многие ко многим" осуществляется по следующему правилу. Каждый объект, участвующий в такой связи, с его атрибутами становится логическим сегментом. Пусть это сегменты С1 и С2. В отражаемой структуре данных производят преобразования, которые сводятся к замене одного дерева двумя деревьями. Первое дерево включает оба сегмента, между которыми устанавливается связь типа "один ко многим", где С1 — предок, а С2 — потомок. Второе дерево включает опять оба этих егмента, между которыми устанавливается связь типа "один ко многим", но только в этом случае С2 - предок, а С1 - потомок.
Описанная ситуация хорошо просматривается на приведенном примере (рис 4.15), где каждый преподаватель может работать в разных группах, а одна и та же группа занимается с разными преподавателями. Здесь для исходной концептуальной модели (рис. 4.15, а) приведена соответствующая ей иерархическая структура (рис. 4.15, б).
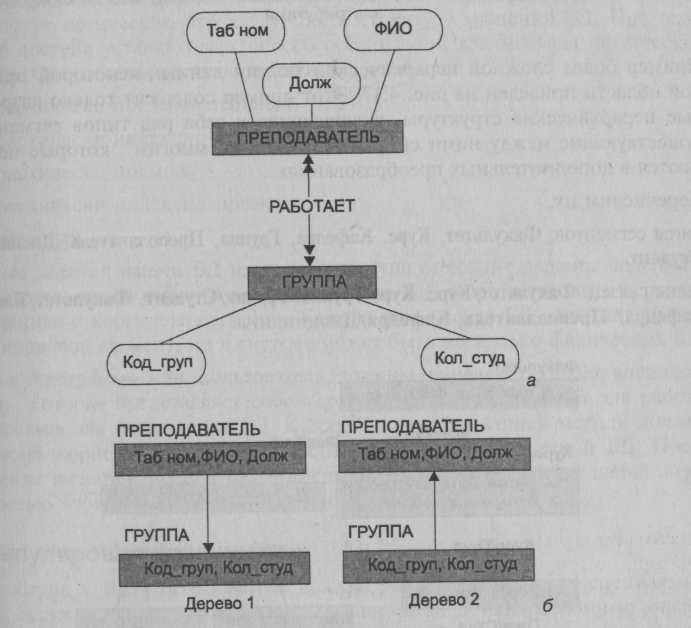
Рис. 4.15. Преобразование типа связи "многие ко многим" (а — концептуальная модель; б — иерархическая модель)
В том случае, когда тип связи сам имеет атрибуты, при преобразованиях в иерархическую структуру данных создается дополнительный тип сегмента пересечения. Например, преподаватель со студентами группы занимается в определенной аудитории (рис 4.16). Каждый из типов сегментов, созданных из объектов, будет функционировать как корень отдельного дерева. Между типами сегментов двух объектов вставляется новый сегмент. Между сегментами предка и потомка устанавливается связь типа "один ко многим".
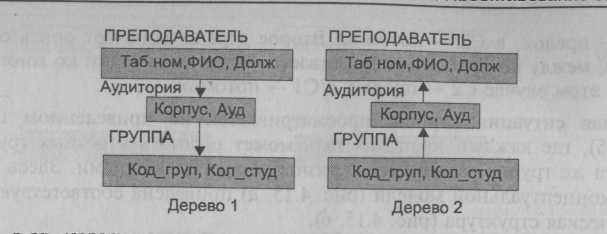
Рис. 4.16. Иерархическая структура представления связи "многие ко многим"
Пример более сложной иерархической модели данных некоторой предметной области приведен на рис. 4.17. Этот пример содержит только разрешенные иерархические структуры, включающие в себя ряд типов сегментов и существующие между ними связи типа "один ко многим", которые не нуждаются в дополнительных преобразованиях.
Перечислим их.
Типы сегментов: Факультет, Курс, Кафедра, Группа, Преподаватель, Дисциплина, Студент.
Типы связей: Факультет/Курс, Курс/Группа, Группа/Студент, Факультет/Кафедра, Кафедра/ Преподаватель, Кафедра/Дисциплина.
Факультет
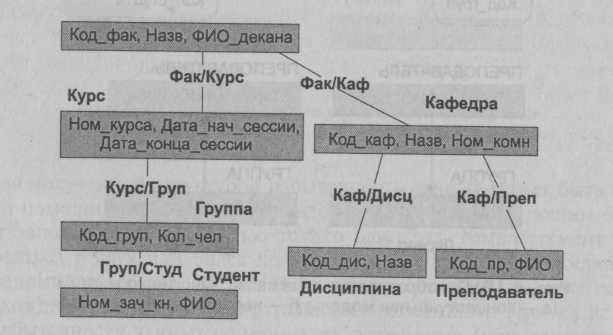
Рис. 4.17. Иерархическая модель Факультет
Следует отметить, что экземпляры потомки одного типа, связанные с одним экземпляром сегмента предка, называют близнецами, а набор всех экземпляров сегментов, подчиненных одному экземпляру корневого сегмента, — физической записью. Физические записи иерархических графов различаются по длине и по структуре.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД).
Описание данных
Каждая физическая база описывается набором операторов, обусловливающих как ее логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Каждая программа или пользователь должны определить свою внешнюю модель, которая представляет собой совокупность необходимых для работы поддеревьев для физических БД. Каждый подграф внешней модели должен содержать корневой тип сегмента соответствующей физической БД. Представление внешней модели называется логической БД и определяется совокупностью блоков связи данного приложения с физической БД.
Манипулирование данными
Для доступа к БД у пользователя должна быть сформирована специальная среда окружения, поддерживающая в явном виде навигационные операции, которые связаны с перемещением указателя, определяющего текущий экземпляр конкретного сегмента. Для этого в среде окружения должны храниться:
- шаблоны всех записей логических БД, доступных пользователю;
- указатели на текущий экземпляр сегмента данного типа — для всех типов
сегментов.
Среди операторов манипулирования данными можно выделить операторы Поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии. Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр
сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
При выполнении операций модификации необходимо помнить:
- исключение какого-то сегмента из иерархической базы влечет исключе
ние всех им порожденных экземпляров сегментов-потомков;
- включение в иерархическую модель какого-либо сегмента требует, чтобыдля него обязательно был исходный сегмент.
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что целостность по ссылкам между сегментами, не входящими в одну иерархию, не поддерживается.
Как уже упоминалось, типичным представителем (наиболее известным и распространенным), использующим указанную модель данных, является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, использующих иерархическую модель данных, что создает существенные проблемы с переходом как на новую технологию БД, так и на новую технику.
В заключение обзора ранних СУБД необходимо дать оценку их сильных и слабых сторон.
Достоинства и недостатки ранних СУБД
Достоинства ранних СУБД:
- развитые средства управления данными во внешней памяти на низком уровне;
- возможность построения вручную эффективных прикладных систем;
- возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Недостатки ранних СУБД:
- сложность использования;
- высокий уровень требований к знаниям о физической организации БД;
- зависимость прикладных систем от физической организации БД;
- перегруженность логики прикладных систем деталями организации доступа к БД.
Как иерархическая, так и сетевая модель данных предполагает наличие высококвалифицированных программистов. И даже в таких случаях реализация пользовательских запросов часто затягивается на длительный срок.
Преимущества:
- Простота идеи
- Безопасность БД-Обеспечивает СУБД, поэтому безопасность едина для всей системы и не требует никаких усилий от программистов
- Независимость данных (независимость данных имеет место, если изменение типа данных вызывает его автоматическое изменение с помощью СУБД во всей БД, исключая таким образом , необходимость модифицировать участки программ, которые используют эти данные)
- Целостность данных – взаимоотношение предок/потомок всегда предпологает наличие связи между ними.
- Эффективность-когда Бд содержит большой объем данных со связью 1:М и когда пользователи выполняют большое количество транзакций, используя юбъекты, связи между которыми фиксированы во времени.
Сетевая модель данных.
Сети — естественный способ представления отношений между объектами, всевозможных их взаимосвязей. Сетевая модель опирается на математическую структуру, которая называется направленным графом. Направленный граф состоит из узлов, соединенных ребрами. В контексте моделей данных узлы представляют собой объекты в виде типов записей данных, а ребра — связи между объектами со степенью кардинальности "один к одному" или "один ко многим". Если говорить более точно, сетевая БД состоит из набора экземпляров каждого типа из заданного в схеме БД набора типов записей и набора экземпляров каждого типа из заданного набора типов связи. Основное отличие графовых форм представления данных в сетевой структуре данных от иерархической структуры данных состоит в том, что потомок в графе может иметь любое число предков. Таким образом, сетевая модель данных, снимая основное ограничение уже использующейся к тому времени иерархической структуры данных, является результатом действий по обобщению ситуаций моделирования существующих реалий и попыток установления подробных стандартов в этой области.
Сетевая модель имеет богатую историю и является основой нескольких удачных СУБД. Если говорить о практической реализации сетевой модели данных, то в первую очередь необходимо упомянуть одну из самых первых СУБД — Integrated Data Store (IDS), созданную компанией General Electric. Именно архитектура этой СУБД легла в основу деятельности фуппы Database Task Group (DTBG), которой конференция по языкам систем данных (CODASYL) в конце 60-х годов поручила разработать стандарты систем управления базами данных. Отчет по этой работе, рекомендовавший к использованию сетевую модель данных, был представлен в Американский национальный институт стандартов в 1971 году для возможного принятия в качестве национального стандарта СУБД. Этот документ в дальнейшем послужил основой при разработке других сетевых систем управления базами данных и сейчас остается главной формулировкой сетевой модели.
Разработанная сетевая модель DTBG имеет трехуровневую архитектуру, соответствующую рекомендациям ANSI/SPARC следующим образом. Концептуальный уровень, определяющий глобальную структуру базы данных, называется схемой. Конечные пользователи на внешнем уровне осуществляют доступ к базе данных посредством прикладной программы на базовом языке, использующей только одну некоторую подсхему БД. Подсхема — это подмножество схемы, которое определяется пользовательским представлением данных БД. Внутренний уровень (физические подробности хранения данных) явно содержится в реализации.
Несколько программ могут параллельно использовать одну и ту же подсхему. СУБД может поддерживать несколько различных баз данных. Рассмотрим основные концепции CODASYL-совместимых СУБД.
Структуры данных сетевой модели
В технологии, разработанной CODASYL, используются несколько различных типовых структур данных, главными из которых являются типы записей и наборы. Для построения этих структур применяются такие конструктивные элементы, как элемент данных и агрегат

Рис. Основные структуры сетевой модели данных
Структуризация данных базируется на концепциях агрегации и обобщения. Агрегация используется для композиции элементов данных в запись. Обобщение используется для объединения однотипных записей файлов. Рассмотрим основные элементы сетевой модели данных.
Элемент данных — это наименьшая поименованная информационная единица данных, доступная пользователю (аналог — поле в файловой системе). Элемент данных должен иметь свой тип (не структурный, простой).
Агрегат данных соответствует следующему уровню обобщения — поименованная совокупность элементов данных внутри записи или другого агрегата.
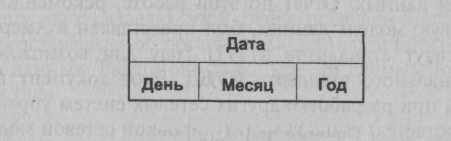
Рис. Агрегат Дата
Запись — конечный уровень агрегации. Каждая запись представляет собой именованную структуру, содержащую один или более именованных элементов данных, каждый из которых обладает своим особым форматом.
Агрегат данных Дата входит в состав записи Сотрудник (рис. 4.3).
| | | | | | | | |||||
| | | | | | | | |||||
| | Сотрудник | | |||||||||
| | Табельный номер | ФИО | Дата | Адрес | | ||||||
| | | | День | Месяц | Год | | | ||||
Рис. 4.3. Запись Сотрудник
Тип записей — это совокупность логически связанных экземпляров записей. Тип записей моделирует некоторый класс объектов реального мира.
В качестве элемента данных могут быть использованы только простые типы, а в качестве агрегатов могут быть использованы сложные типы: вектор и повторяющаяся группа.
Агрегат типа вектор соответствует линейному набору элементов данных (рис. 4.2). Агрегат типа повторяющаяся группа соответствует совокупности векторов данных. Так, например, в заказе может быть указано несколько видов товаров с числом повторений 10 (рис. 4.4).
| Заказ | ||||||
| Номер заказа | Дата заказа | Товар | ||||
| | День | месяц | Год | Шифр товара | Количество товара | Наименование товара |
| | i | |||||
| | Повторяющаяся группа | |||||
Рис. Запись Заказ
Набор — это поименованная двухуровневая иерархическая структура, которая содержит запись владельца и записи членов. Наборы выражают связи "один ко многим" или "один к одному" между двумя типами записей. Тип набора поддерживает работу с внутренними структурами типов записей.
Тип набора — это не аналог файла, он определяет связь между типами записей. Каждый экземпляр типа набора может содержать только один экземпляр записи владельца и сколько угодно экземпляров записей членов. Набор может быть пустым, т. е. в нем может находиться только одна запись-владелец. Тип набора является основным композиционным элементом, с помощью которого по технологии CODASYL строится в сетевой модели структура всей БД.
Набор, приведенный на рис., определяет тип записи-владельца Отдел и тип записи-члена набора Сотрудник, а также тип связи между ними "один ко многим" — с именем Работает. Имя набора — это метка, присвоенная стрелке. Связь типа "один ко многим" допускает возможность того, что с данным экземпляром записи-владельца может быть связан ноль, один, или несколько экземпляров записи-члена.
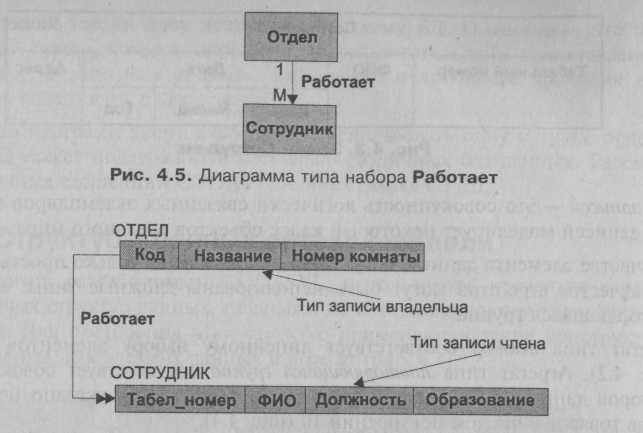
Рис. Набор Работает между двумя типами записей Отдел и Сотрудник
Используя понятия сетевой модели данных, можно получить другое изображение такого набора (рис.), где представлены логические типы записей Отдел и Сотрудник, их структура и связь между типами записей Работает. Для обозначения связи в направлении "много" можно использовать альтернативное обозначение показателя кардинальности — двойные стрелки, опуская буквенное.
Типы записей и наборы используются для построения на концептуальном уровне сетевого графа, отражающего глобальную структуру базы данных. Учитывая все вышесказанное, уточним понятие база данных в сетевой модели данных.
База данных в сетевой модели данных — это поименованная совокупность экземпляров записей различного типа и экземпляров наборов, содержащих связи между ними.
Сетевой граф БД
Сетевой граф строится по определенным правилам:
- БД может содержать любое количество наборов и записей;
- между двумя типами записей может быть любое количество наборов; на пример, преподаватель может не только заниматься с группой, но и быть куратором этой группы (рис. 4.7);
- тип записи может быть владельцем в одних типах наборов и членом в других типах наборов;
- только один тип записи может быть владельцем в каждом наборе;
- типы наборов могут быть определены так, что в результате они образуют циклическую структуру;
- Тип записи не обязательно должен быть членом какого-либо типа набора;
- один и тот же тип записи может быть владельцем нескольких типов наборов и одновременно может быть членом нескольких типов наборов.
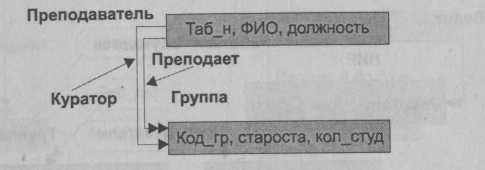
Рис. Наборы между двумя типами записей
Преобразование концептуальной модели в сетевую
Сетевая модель данных может быть без осложнений получена из концептуальной модели. Для этого надо предположить, что в последней используются только бинарные связи. Причем они должны принадлежать к типам "один к одному" или "один ко многим". При этом вместо объектов концептуальной модели необходимо использовать типы записей сетевой модели, где имена объектов становятся именами типов записей, атрибуты объектов становятся полями записей, связь между объектами превращается в связь между типами записей.
Бинарные связи, принадлежащие к типу "один ко многим", переносятся в сетевую модель следующим образом: тип записи со стороны "один" становится владельцем, а тип записи со стороны "много" становится типом записи-члена. Для связи типа "один к одному" выбор типа записи-владельца и типа'записи-члена может быть осуществлен произвольно. На рис. представлена схема базы данных Факультет, которая содержит ряд типов записей и ряд типов наборов.
Присущие сетевым моделям внутренние ограничения не позволяют напрямую моделировать некоторые реально существующие в предметной области типы связей. К таким типам связей относятся рекурсивные связи и связи типа M:N. Для того чтобы их отразить в сетевой модели, применяют различные подходы, которые приводят к определенным преобразованиям графа. Рекурсивная связь возникает тогда, когда экземпляр типа записи участвует в связи с другим экземпляром того же типа записи, например один из сотрудников подразделения является его руководителем. Рекурсивные связи могут иметь тип 1:1, 1:М, M:N. Рекурсивная связь представляется с помощью диаграммы Бахмана так, как это показано на рис.
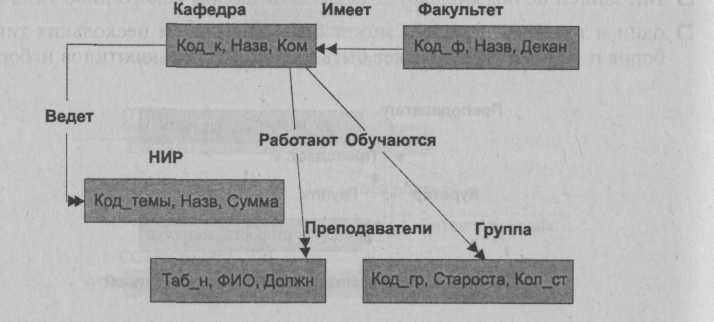
Рис. Схема базы данных Факультет
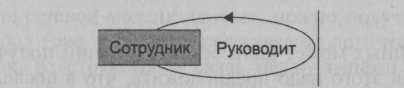
Поскольку в сетевой модели ситуация, при которой один и тот же тип записи является владельцем и членом одного и того же набора, недопустима, то для моделирования в ней рекурсивных связей прибегают к некоторым ее преобразованиям.
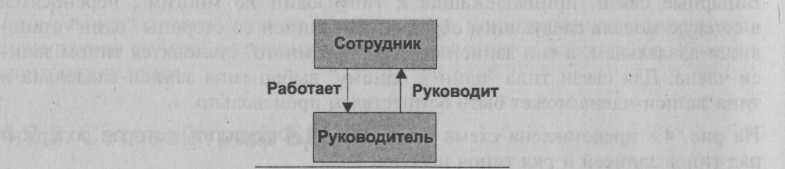
Один из возможных вариантов представления рекурсивной связи изображен на рис., где использован связующий тип записи, который не содержит никаких элементов и с помощью которого определены два типа набора.
Поскольку в конкретном экземпляре набора экземпляр записи-члена набора не может иметь более одного экземпляра владельца набора, то в сетевой модели не существует прямого способа представления связи типа M:N. И в этом случае также необходимо что-то изменить, чтобы можно было полученную структуру вписать в те рамки, которые определяет сетевая модель.
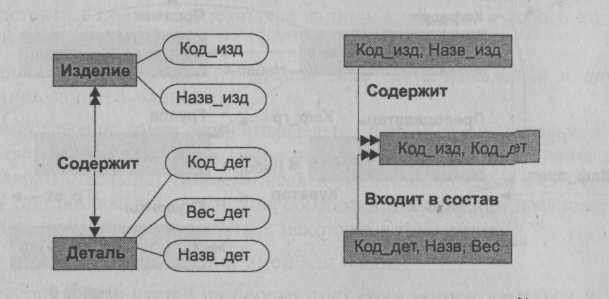
Рис Диаграмма представления связи типа М:N.
Проводимые в таких случаях преобразования приводят к увеличению количества типов записей, так как в подобных моделях связь должна быть представлена самостоятельным типом записи. В результате вместо одной недопустимой для сетевой модели связи типа M:N появятся две связи типа 1:N, с помощью которых можно будет легко управлять типами наборов. Графические диаграммы, приведенные на рис., иллюстрируют эти преобразования.
Рассмотрим пример сетевой модели данных небольшой локальной ПрО, включающей шесть объектов Факультет, Кафедра, Преподаватель, Предмет, Группа, Студент.
Указанные объекты могут быть использованы для формирования ряда наборов данных, часть которых ниже перечислена и показана на рис. 4.12:
- Факультет — Кафедра (Фак_Каф);
- Кафедра — Преподаватель (Каф_Преп);
- Кафедра — Предмет (Каф_Предм); П Кафедра — Группа (Каф_Гр);
- Группа — Студент (Гр_Ст);
- Преподаватель — Группа (Куратор).
Все представленные наборы содержат разрешенные для сетевой модели связи типа "один ко многим" или "один к одному". Все вместе данные наборы представляют собой простую сеть. В отличие от простых сетей сложные сети, включающие одну или несколько связей типа "много ко многим", нуждаются в дополнительных преобразованиях, осуществляющих замену связи "много ко многим" на более простые разрешенные связи.
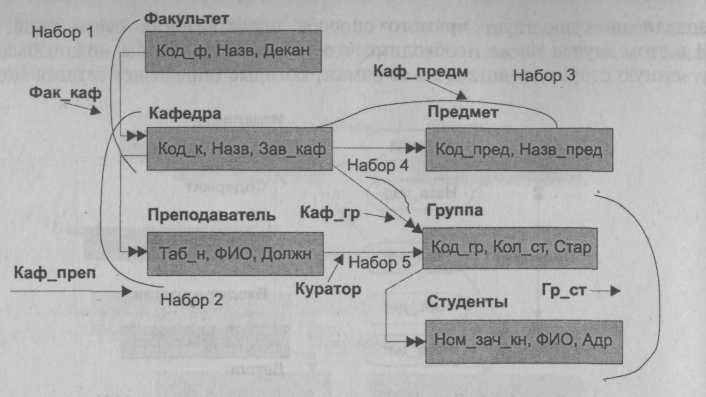
Рис. 4.12. Подсхема сетевой модели ПрО Учебный процесс
Тип записи Группа включен в два набора Кафедра-Группа (Каф_Гр) и Преподаватель — Группа (Куратор). Причем в обоих наборах ему отведена роль члена набора. Таким образом, тип записи Группа имеет двоих владельцев, что также разрешено к использованию в сетевой модели данных.
Подводя итоги проблемам преобразования концептуальной модели в сетевую модель данных, следует обратить внимание и на следующий факт. Некоторые концептуальные модели содержат не только бинарные связи, но и связи более высоких порядков. Преобразование таких связей в сетевую модель данных требует создание нового типа записи — записи связи, состоящей из ключевых полей каждого объекта. Причем тип связи между существующими записями и записью связи всегда имеет показатель кардинальности "один ко многим" и запись связи всегда является записью-членом набора.
Реализация наборов
Экземпляр набора обычно реализуется с помощью указателей в виде кольцевого списка, в котором головным элементом является экземпляр записи-владельца. Установленные таким образом связи позволяют последовательно совершать переходы между всеми записями набора с возвратом к исходной записи-владельцу.
Списки могут быть как однонаправленные, так и двунаправленные. Двунаправленные связанные списки позволяют производить обход записей в обоих направлениях. Кроме этого, могут иметься ссылки в элементах списка на запись владельца (для этого предусмотрены специальные поля).
Наборы делятся на одночленные, многочленные и сингулярные.
Одночленный набор состоит из одного типа записи-владельца и одного типа записи-члена. В то же время конкретный экземпляр одночленного набора может состоять из одного экземпляра записи-владельца и любого количества экземпляров записи-члена.
Многочленный набор состоит из одного типа записи-владельца и двух или более типов записей-членов.
Сингулярный набор не имеет записи-владельца, в этом случае владельцем набора является система. Сингулярный набор является средством обеспечения доступа к экземплярам отдельных типов записей и представляет собой очень полезную структуру при реализации алгоритмов обработки информации, предполагающих обеспечение произвольного доступа к некоторому типу записи.
Есть три способа формирования имен для набора:
- имя набора формируется из первых трех букв записи владельца и записи членов;
- имя набора связывается со смысловым содержанием;
- набор обозначается каким-либо символом; например: X, Y, Z. В этом случае строится таблица для пояснения этих обозначений (таблица кодирования смыслового содержания).
Для описания фундаментальных структур схемы базы данных в CODASYL-совместимых СУБД используется язык описания данных (ЯОД). Язык определения схемы описывает концептуальную модель предметной области, представленную в виде сетевого графа. Это описание должно включать:
- описание схемы, задающей имя схемы;
- описание записей, определяющее структуру каждой записи (элементов агрегатов);
- описание наборов, определяющее все наборы (каждый в отдельности), включая тицы записей владельцев и членов.
Внешняя (пользовательская модель) при сетевой организации данных поддерживается путем описания в основном части общего связного графа (пользовательского представления), для чего применяется другой язык описания — язык определения подсхем. Однако если это требуется пользователю, в подсхеме могут быть сгруппированы новые данные, записи и наборы могут быть переименованы, порядок описания может быть изменен.
Управляющая часть сетевой модели
Гибкость управления БД определяется множеством операций, разрешенных над данными. С помощью этих операций БД переводится из одного состояния в другое. Реализуется такой переход с помощью языка манипулирования данными (ЯМД).
Из множества операций над данными можно выделить следующие группы:
- операции селекции;
- действия над данными.
Селекция — это поиск некоторого данного по заданному условию. После осуществления селекции это данное становится текущим.
Действия над данными:
- выборка — чтение экземпляра записи из БД;
- включение — ввод экземпляра записи в БД с установкой соответствующих связей;
- удаление — исключение экземпляра записи из БД с установкой новых связей;
- модификация — изменение содержимого экземпляра записи и коррекция связей при необходимости.
Для манипулирования данными в сетевой модели данных определен ряд типичных операций, которые можно подразделить на две группы: навигационные операции и операции модификации.
Навигационные операции осуществляют перемещение по БД путем прохождения по связям и. определенным в схеме БД.
В результате таких операций определяется запись, которая называется текущей. К подобным операциям относятся:
- найти конкретную запись в наборе однотипных записей и сделать ее текущей;
- перейти от записи-владельца к записи-члену в некотором наборе;
- перейти к следующей записи в некоторой связи;
- перейти от записи-члена к владельцу по некоторой связи.
Операции модификации осуществляют как добавление новых экземпляров отдельных типов записей, так и экземпляров новых наборов, удаление экземпляров записей и наборов, модификацию отдельных компонентов самой записи. Для реализации этих операций в системе текущее состояние детализируется путем запоминания трех его составляющих: текущего набора, текущего типа записи, текущего экземпляра типа записи. В такой ситуации возможны следующие операции:
- извлечь текущую запись в буфер прикладной программы для обработки;
- заменить в извлеченной записи значения указанных элементов данных на заданные новые их значения;
- запомнить запись из буфера в БД;
- создать новую запись;
- уничтожить запись;
- включить текущую запись в текущий экземпляр набора;
- исключить текущую запись из текущего экземпляра набора.
В сетевой модели имеют большое значение средства автоматики для многошаговой навигации и распространения изменений по структуре данных. Сетевые модели обладают тем неоценимым достоинством, что они могут содержать любые петли; это означает, что возможно без проблем отобразить любую концептуальную модель в датологическую модель. Недостатком этой модели является сложность реализации.
Поддержание ограничений целостности в сетевых моделях в принципе не требуется.
Типичным представителем СУБД, использующих сетевую модель данных, является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем.
Проведем сравнение модели CODASYL DBTG с реляционной моделью, для выяснения их сравнительно сильных и слабых сторон.
Существенная разница между реляционной и сетевой моделями состоит в способе представления данных. В реляционной модели связи между двумя реляционными таблицами устанавливаются включением в эти две таблицы атрибутов с одной и той же областью значения, а часто, и с одним и тем же именем. Строки двух таблиц, которые логически связаны, будут иметь равные значения этого атрибута. В сетевой модели CODASYL DBTG отношения мощности один-ко-многим между двумя типами записей устанавливаются при помощи явного определения типа набора. Затем СУБД связывает записи каждого типа набора физическими указателями.
Это означает, что записи физически связаны, если они входят в один и тот же элемент набора. Это явное представление типов наборов было принято рассматривать как преимущество сетевой модели. Контраргумент состоит в том, что в сетевой модели используется два модельных понятия – тип записи и тип набора, тогда как в реляционной модели используется всего одно простое понятие – реляционная таблица.
Операции передвижения и извлечения ЯМД CODASYL DBTG выполняются над отдельными записями, в отличие от операций реляционной модели, которые выполняются над целыми таблицами. Эти операции CODASYL DBTG должны быть погружены в базовый язык программирования, такой как Кобол. Поскольку ориентированная на записи манипуляция основана на традиционных операциях обработки файлов, программист обязан хорошо разбираться в индикаторах текущего положения и их смысле, чтобы избежать ошибок.
Можно сделать вывод, что реляционная модель обладает преимуществами в области ЯМД. Положение несколько выровнено добавлением к CODASYL DBTG некоторых реляционных пользовательских интерфейсов, превративших ее в IDMS/R. Реляционные языковые системы обеспечивают высокий уровень возможностей оперирования множествами кортежей. Коммерческие реализации этих систем получили дополнительные возможности группировки, упорядочивания и арифметических вычислений. Кроме того, команды реляционных ЯМД могут применяться непосредственно или погружаться в базовый язык.
Сетевая модель CODASYL DBTG обладает полезным набором ограничений целостности. Они особенно сильны в вопросе сохранения целостности наборов. Опции удержания в наборе позволяют проектировщику определить, как записи-владельцы должны себя вести по отношению к записям-членам и наоборот. Опции обязательного и фиксированного удержания требуют, чтобы у каждой записи был владелец, тогда как при необязательном удержании это не требуется. Возможности смысловых ограничений, таких как ограничение часов работы, в записи служащего шестьюдесятью часами, могут быть реализованы только в прикладной программе, обрабатывающей эти записи.
Сетевая модель CODASYL DBTG особенно хорошо подходит для информационных систем, которые характеризуются:
- Большим размером;
- Хорошо определенными, повторяющимися запросами;
- Хорошо определенными транзакциями;
- Хорошо определенными предложениями.
Если все эти факторы присутствуют, то пользователи и проектировщики системы базы данных могут сосредоточить усилия на обеспечении того, чтобы приложения были написаны наиболее эффективным образом. Негативная сторона состоит в том, что не предвиденные заранее приложения в будущем могут работать плохо; они даже могут потребовать трудоемкой реорганизации структуры базы данных.
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- Каждый экземпляр типа P является предком только в одном экземпляре L;
- Каждый экземпляр C является потомком не более, чем в одном экземпляре L.
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации:
Тип записи потомка в одном типе связи L1 может быть типом записи предка в другом типе связи L2 (как в иерархии).
- Данный тип записи P может быть типом записи предка в любом числе типов связи.
- Данный тип записи P может быть типом записи потомка в любом числе типов связи.
Может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L1 и L2 - два типа связи с одним и тем же типом записи предка P и одним и тем же типом записи потомка C, то правила, по которым образуется родство, в разных связях могут различаться.
Типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком - в другой.
Предок и потомок могут быть одного типа записи.
Простой пример сетевой схемы БД:

Манипулирование данными
Примерный набор операций может быть следующим:
- Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
- Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
- Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
- Перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
- Создать новую запись;
- Уничтожить запись;
- Модифицировать запись;
- Включить в связь;
- Исключить из связи;
- Переставить в другую связь и т.д.
Ограничения целостности
В принципе их поддержание не требуется, но иногда требуют целостности по ссылкам (как в иерархической модели).
Несмотря на то что сетевая модель базы данных имеет значительные преимущества перед иерархической моделью, она все же обладает и целым рядом недостатков.
Сложность системы в целом. Обеспечение целостности и эффективность, с которой сетевая БД управляет отношениями, иногда становятся причиной сложности всей системы. Так же как и иерархическая, сетевая модель предоставляет навигационные средства доступа к данным, когда доступ к записи осуществляется за один раз. Поэтому администраторы БД, программисты и конечные пользователи для получения доступа к данным должны хорошо знать внутреннюю структуру базы. Говоря кратко, сетевую модель базы данных, как и иерархическую, нельзя считать дружественной системой.
Недостаточная структурная независимость. Поскольку сетевая модель базы данных также обеспечивает доступ к данным с помощью средств навигации, то в ней, как и в иерархической модели, трудно производить структурные изменения, а некоторые из них просто невозможны. Если в структуре БД делаются какие-то изменения, то придется проверить все прикладные программы, перед тем как разрешить им доступ к БД. В конечном счете, хотя в сетевой модели и достигается независимость по данным, все же она не обеспечивает структурной независимости.
Вследствие имеющихся серьезных недостатков в 1980-х годах сетевая модель была вытеснена реляционной моделью.
Достоинства и недостатки ранних СУБД
Сильные места ранних СУБД:
- Развитые средства управления данными во внешней памяти на низком уровне;
- Возможность построения вручную эффективных прикладных систем;
- Возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Недостатки:
- Слишком сложно пользоваться;
- Фактически необходимы знания о физической организации;
- Прикладные системы зависят от этой организации;
- Их логика перегружена деталями организации доступа к БД.
Реляционная модель данных.
Использование физических указателей было одновременно и сильной, и слабой стороной иерархических и сетевых систем управления БД. Сильной, поскольку они позволяли извлекать данные, связанные определенными отношениями. Слабой, поскольку эти отношения должны быть определены до запуска системы. Извлечь данные на основе других отношений было сложно, если вообще возможно. Как только пользователи освоили информационные системы, использующие БД, и разобрались их возможностями работы с данными, они сочли такие ограничения неприемлемыми.
В 1970 году Е.Ф. Кодд опубликовал революционную по содержанию статью (Codd, 1970), которая всерьез поколебала устоявшиеся представления о БД. Он выдвинул идею, что данные нужно связывать в соответствии с их внутренними логическими взаимоотношениями, а не физическими указателями. Таким образом, пользователи смогут комбинировать данные из разных источников, если логическая информация, необходимая для такого комбинирования, присутствует в исходных данных. Это открыло новые возможности для информационно-управляющих систем, поскольку запросы к БД теперь не были ограничены физическими указателями.
В своей статье Кодд предложил простую модель данных, согласно которой все данные сведены в таблицы, состоящие из строк и столбцов. Эти таблицы получили название реляций, а модель стала называться соответственно реляционной. Кодд также предложил пользоваться для работы с данными в таблице двумя языками:
- реляционной алгеброй
- и реляционным исчислением.
Оба этих языка обеспечивают работу с данными на основе логических характеристик, а не физических указателей, которыми пользовались в иерархических и сетевых моделях.
Кодд предложил еще одну революционную идею. В реляционных системах БД целые файлы данных могут обрабатываться одной командой, тогда как в традиционных системах за один раз обрабатывается только одна запись. Подход Кодда чрезвычайно повысил эффективность программирования в БД.
Логический подход к данным сделал также возможным создание языков запросов, более доступных для пользователей, не являющихся специалистами по компьютерам. Хотя создать язык, которым могли бы пользоваться все, не зависимо от опыта работы с компьютером, довольно сложно, однако реляционные языки запросов сделали БД доступными для более широкого круга пользователей, чем раньше.
Публикация работ Кодда в начале семидесятых вызвало взрыв активности, как среди ученых, так и среди разработчиков коммерческих систем по созданию реляционной системы управления БД. Результатом этой деятельности явилось создание во второй половине семидесятых реляционных систем, которые поддерживали такие языки, как Structured Query Language (SQL, язык структурированных запросов), Query Language (Quel, язык запросов) и Query-by-Example (QBE, запросы по образцу). С широким распространением персональных компьютеров в 80-е годы также появились реляционные БД для микрокомпьютеров. В 1986 году SQL был принят в качестве стандарта ANSI языков реляционных БД. Этот стандарт обновлялся в 1989 и в 1992 годах.
Все эти новшества сильно расширили возможности систем управления БД и повысили доступность информации в корпоративных БД. Реляционный подход оказался весьма плодотворным. Более того, продолжающиеся исследования обещают значительный прогресс с точки зрения интересов пользователей систем управления БД.
На сегодняшний день реляционные БД рассматриваются как стандарт для современных коммерческих систем работы с данными. Разумеется, файловые системы, иерархические и сетевые БД все еще многочисленны, и во многих случаях именно их применение является наиболее выгодным. Тем не менее, среди компаний прослеживается очевидная тенденция при первой же возможности переходить на реляционные системы.
Неверным, однако, было бы полагать, что современные реляционные системы управления БД являются последним словом в развитии СУБД. Реляционные БД продолжают совершенствоваться, и их внутренняя природа значительно меняется, представляя пользователям возможность решать все более сложные задачи.
Базовые понятия реляционных баз данных
В основе реляционных БД лежит реляционная алгебра. Само слово «реляционная» означает – отношение. Но в случае реляционных БД слово «отношение» выражает не взаимосвязь между таблицами – сущностями, а определение самой таблицы, как математического отношения доменов.