
Предисловие Системы управления базами данных (субд) – это программные комплексы, предназначенные для работы со специально организованными файлами (массивами данных, долговременно хранимыми во внешней памяти вычислительных систем), которые называются
| Вид материала | Документы |
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Программа курса лекций "Базы данных в научных исследованиях", 49.32kb.
- Система управления базами данных это комплекс программных и языковых средств, необходимых, 150.5kb.
- Лекция 2 Базы данных, 241.25kb.
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
- Вопросы к государственному экзамену по специальности «Информационные системы и технологии», 39.93kb.
- Лекция № Технологии баз данных, 92.24kb.
- Проектирование базы данных, 642.58kb.
- Системы управления базами данных, 313.7kb.
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
Таблица 9.8. Неоднозначный поиск
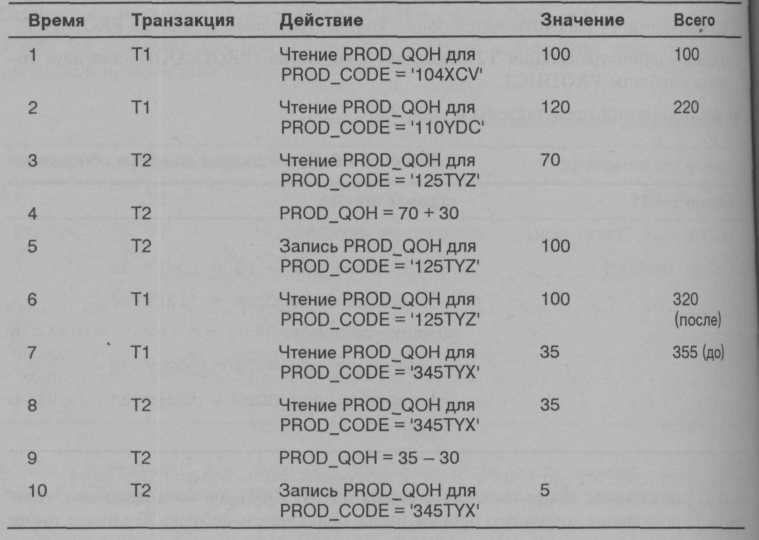
Таблица 9.8 (окончание)
 Время Транзакция Действие Значение Всего
Время Транзакция Действие Значение Всего- Т2 ***** COMMIT *****
- Т1 Чтение PROD_QOH для 100 455
PROD_CODE = '350TYX'
13 Т1 Чтение PROD_QOH для 30 485
P
ROD_CODE = '355TYX'Рассчитанный ответ 455 очевидно ошибочен, поскольку мы знаем правильный ответ 455. Если СУБД не будет управлять параллельным выполнением транзакций, то многопользовательская база данных может полностью разрушить информационную
систему.
Планировщик
Теперь вы понимаете, какие могут возникнуть проблемы при одновременном выполнении двух или более транзакций. Вы узнали, что в транзакцию базы данных входит серия операций ввода/вывода, которые переводят БД из одного устойчивого состояния в другое. Наконец, теперь вы знаете, что непротиворечивость базы данных может обеспечиваться только перед выполнением или после выполнения транзакции. В процессе выполнения транзакций база данных неизбежно проходит через временные неустойчивые состояния. Такие временные состояния существуют из-за того, что компьютер не может выполнять две операции одновременно и должен, следовательно, выполнять их последовательно. Во время этого последовательного процесса свойство изолированности транзакций предохраняет их от доступа к данным, которые все еще используются другими транзакциями.
В предыдущих примерах мы выполняли операции в рамках транзакции в произвольном порядке. Пока две транзакции Т1 и Т2 получают доступ к несвязанным данным, конфликтов не возникает и порядок выполнения транзакций не влияет на конечный результат. Но если транзакции оперируют связанными (или одними и теми же) данными, возможен конфликт между компонентами транзакции, и выбор порядка операций может привести к нежелательным последствиям. Как же определить правильный порядок, и кто должен установить этот порядок? К счастью, СУБД предоставляет такую возможность с помощью встроенного планировщика.
Планировщик (scheduler) устанавливает порядок, в котором выполняются операции в параллельных транзакциях. Планировщик чередует выполнение операций базы данных для обеспечения последовательности. Чтобы определить должный порядок, планировщик действует на основе алгоритмов управления параллельным выполнением, таких как блокировка или метки времени, которые мы рассмотрим в следующих разделах.
Планировщик также обеспечивает эффективную работу центрального процессора компьютера (CPU). Если невозможно спланировать выполнение транзакций, то все транзакции будут выполняться по принципу "первый пришел — первым обслужен". Проблема такого подхода в том, что время центрального процессора тратится попусту на время ожидания окончания операций READ (чтение) или WRITE (запись! I Короче говоря, порядок обработки по принципу "первый пришел — первым обслу-1 жен" приводит к увеличению времени отклика в многопользовательских СУБД. Поэтому необходим иной метод, который помог бы увеличить общую производительность системы, задействовав время простоя процессора.
Операции с базой данных, в которых используются чтение и/или запись, могут привести к конфликтам. Например, в табл. 9.9 представлены возможные конфликты при одновременном выполнении двух транзакций Т1 и Т2 над одними и теми же данными. На основе табл. 9.9 можно сделать вывод, что две операции конфликтуют при получении доступа к одним и тем же данным, по крайней мере, во время одной из операций записи (WRITE).
Таблица 9.9. Конфликт чтения/записи: матрица конфликтов базы данных
Т

 РАНЗАКЦИИ
РАНЗАКЦИИТ
 1 Т2
1 Т2Операции Read Read
Read Write
Write Read
Write Write
П
 римечание: в таблице жирным курсивом выделены неконфликтующие операции.
римечание: в таблице жирным курсивом выделены неконфликтующие операции.Есть несколько методов планирования выполнения конфликтующих операций в параллельных транзакциях. Сюда относятся блокировка, метки времени и оптимистические методы. Поскольку методы блокировки используются чаще всего, рассмотрим их в первую очередь.
Управление параллельным выполнением транзакций методом блокировки
Блокировка (lock) гарантирует эксклюзивное использование данных только в данной транзакции. Другими словами, транзакция Т2 не получит доступа к данным, которые в настоящий момент используются в транзакции Т1. Транзакция предварительно блокирует доступ к данным; блокировка снимается после завершения транзакции, вот почему следующая транзакция может блокировать данные для выполнения своих действий.
Вы должны помнить из предыдущих рассуждений, что в процессе транзакции не обеспечивается непротиворечивость данных: база данных может временно находиться в неустойчивом состоянии при выполнении обновления. Следовательно, блокировки необходимы для того, чтобы другие транзакции не считывали противоречивую информацию.
Триггеры
Триггеры представляют собой методы, с помощью которых можно обеспечивать целостность базы данных даже в том случае, если она используется множеством приложений. Посмотрим, как эти методы реализованы в СУБД MS SQL Server.
Основные сведения
Триггер — это специальный тип хранимой процедуры, которая автоматически выполняется при каждой попытке изменить защищаемые ей данные. Триггеры обеспечивают целостность данных, предотвращая их несанкционированное или неправильное изменение.
Допустим, что в базе данных есть таблицы, связанные через поле Surname. Например, это могут быть таблица клиентов предприятия и их заказов. Разумно определить триггер, который при каждой попытке удалить запись клиента проверит наличие у него заказов и позволит удалить эту запись только при их отсутствии. Конечно, подобную задачу можно решить при помощи средств декларативной ссылочной целостности. Однако при помощи триггеров можно создавать значительно более сложные рабочие правила. Можно создать триггер, который при каждом добавлении записи в таблицу заказов анализирует предыдущие заказы этого же клиента и определяет приемлемый срок оплаты этого заказа.
Триггеры не принимают параметров и не возвращают значений. Они выполняются неявно. То есть триггер запускается только при попытке изменения данных.
Триггеры могут иметь до 32 уровней вложенности. Вложенные триггеры работают следующим образом: пусть при создании записи о новом заказе триггер добавляет информацию в таблицу неоплаченных счетов. При этом выполняется другой триггер, который проверяет, имеет ли клиент просроченные неоплаченные счета и, если они есть, триггер выводит сообщение об этом. В этом примере один триггер обновляет таблицу, вызывая при этом выполнение другого триггера.
По умолчанию все триггеры (insert, delete, update) срабатывают сразу после выполнения операции изменения данных. Эти триггеры относятся к типу after (после). Начиная с SQL Server 2000 появилась еще одна группа триггеров — instead of (вместо), которые выполняются вместо оператора, предполагающего изменение данных.
С точки зрения быстродействия триггеры не имеют никаких преимуществ. Выполнение триггера связано с постоянными обращениями к различным таблицам. Соответственно его работа быстрее, если используемые таблицы находятся в оперативной памяти, и медленнее — если данные считываются с диска.
Триггер является частью транзакции, следовательно, если триггер терпит неудачу, отменяется вся транзакция. И наоборот, если какая-то часть транзакции не удалась, то и триггер будет отменен.
В своей работе триггеры используют таблицы Inserted и Deleted. Это логические таблицы, они постоянно находятся в оперативной памяти и имеют ту же структуру, что и таблица, для которой создан триггер. Каждая добавленная к защищаемой триггером таблице строка добавляется и в таблицу Inserted. Обновление производится почти так же, как и удаление с последующей вставкой. Когда строка обновляется, старая строка записывается в таблицу Deleted, затем обновленная строка записывается в базовую таблицу и в таблицу Inserted.
Создание триггера
Триггер создается оператором create trigger. Рассмотрим его синтаксис:
CREATE TRIGGER [владелец.] имя_триггера
ON [владелец.]имя_таблицы | имя_представления
FOR {AFTER | INSTEAD OF} {INSERT | UPDATE | DELETE}
[WITH ENCRYPTION]
AS onepaTop_SQL
Таблица может иметь произвольное количество триггеров любых типов (insert, update или delete). По умолчанию триггер выполняется после изменения данных, однако, если указать параметр insead of, to создается триггер, выполняющийся вместо изменения данных.
Каждая операция (insert, update и delete) может вызывать выполнение произвольного количества триггеров. С единственным ограничением — имена триггеров, вызываемых одной операцией, должны быть уникальными. Изменить триггер можно, удалив его и создав заново в другом виде или при помощи оператора alter trigger. При удалении таблицы, имеющей триггеры, все они также удаляются. При создании триггеров необходимо придерживаться следующих правил:
- Триггеры создаются для поддержания целостности данных, ссылочной
целостности и рабочих правил.
- Нельзя создавать триггеры для временных таблиц. Однако триггеры могут
к таким таблицам обращаться так же, как и к представлениям.
- Триггер не может возвращать результирующих наборов данных. Это значит, что к использованию оператора select при его создании нужно подходить крайне осторожно. Обычно в этих случаях используется оператор SELECT С ДИреКТИВОЙ IF EXISTS.
- С помощью опции with encryption исходный код триггера, хранящийся
в таблице syscomments, можно зашифровать.
- Операторы writetext не инициализируют триггеры. Они используются
для изменения данных типа Text или Image, а эти изменения не заносят
ся в журнал транзакций.
- В триггерах нельзя использовать следующие операторы: все операторы create, все операторы drop, alter table, alter database, truncate
TABLE, GRANT И REVOKE, RECONFIGURE, LOAD DATABASE ИЛИ TRANSACTION, UPDATE STATISTICS, SELECT INTO И ВСе Операторы DISK.
- Операторы отмены транзакций, входящие в состав триггера, могут стать
причиной непредсказуемого поведения операторов вызывающей про
граммы.
Следующий пример демонстрирует использование триггера, срабатывающего при вставке или обновлении таблицы. По умолчанию это триггер after.
USE pubs
GO
CREATE TRIGGER trAddAuthor
ON authors
FOR INSERT, UPDATE
AS raiserror ('%d rows have been modifed', 0, 1
@@rowcount)
RETURN
Данный триггер будет стартовать при каждой вставке или изменении данных и возвращать сообщение о количестве измененных строк. Рассмотрим результат его работы:
USE pubs GO
INSERT authors
(au_id, au_name, au_fname, phone, address, city, state, zip, contract) VALUES
('777-66-555', 'Vasiliy', 'Sidorov', '+7000666666', '666 hell-street', "Magadan', 'Magad. Obi.', '874763',0)
После выполнения этого кода на экран будет выведено:
1 rows have been modified (1 row(s) affected).
Где первая строка и есть результат работы триггера.
Триггер удаления
Рассмотрим триггеры удаления (delete). Стоит отметить, что при использовании оператора truncate table (удаляющего все строки таблицы) триггер не сработает. Для демонстрации создадим еще одну запись в таблице authors, отличающуюся от предыдущей только значением поля au_id.
USE pubs GO
INSERT authors
(au_id, au_name, au_fname, phone, address, city, state, zip, contract) VALUES
('777-66-555', 'Vasiliy', 'Sidorov', '+7000666666', '666 hell-street',
'Magadan', 'Magad. Obi.', ' 874763',0)
После выполнения этого кода на экран будет выведено:
1 rows have been modified
(1 row(s) affected).
Теперь создадим триггер delete, подсчитывающий количество удаленных строк:
CREATE TRIGGER trDelAuthors
ON authors
FOR DELETE AS reiserror
('%d rows are going to be deleted from this table', 0, 1, @@rowcount)
Теперь при удалении всех строк со значением поля au_fname равным Sidorov:
DELETE FROM authors
WHERE au_fname = 'Sidorov'
После выполнения этого кода на экран будет выведено:
2 rows are going to be deleted from this table
(2 row(s) affected).
Основным применением триггеров является обеспечение целостности данных (ссылочная целостность, поддержка правил, каскадное изменение данных). Операция каскадного изменения легко программируется в триггере. Допустим, закрывается книжный магазин. Можно создать триггер, удаляющий его из таблицы shops и все относящиеся к нему строки из таблицы sales. Такой триггер называется каскадным триггером delete.
Для начала можно создать две таблицы:
sp_dboption pubs , 'SELECT INTO', TRUE
GO
SELECT * INTO tblShops FROM pubs..stores
SELECT * INTO tblSales FROM pubs..sales
После выполнения этого кода на экран будет выведено:
CHECKPOINTing database that was changed. (6 row(s) affected) (21 row(s) affected)
Просмотреть содержимое полученных таблиц можно, выполнив команду:
SELECT sa.stor_id, st.stor_name FROM tblShops st, tblSales sa WHERE st.stor_id = sa.stor_id
Будем удалять 4 строки с stor_id, равным 7 067. Перед этим создадим для таблицы tblSales триггер, сообщающий, сколько удаляется строк при удалении записи о магазине из таблицы tblStores:
CREATE TRIGGER trDelSales ON tblSales FOR DELETE AS
Raiserror ( (%d rows are going to be deleted frOom the sales table', 0, 1, @@rowcount)
Теперь создается триггер для таблицы tblShops:
CREATE TRIGGER trDelShops
ON tblShops
FOR DELETE AS
DELETE tblSales FROM deleted WHERE deleted.stor_id = tblShops.stor_id
Удаление из таблицы tblShops, например, магазина под названием News&Brews наглядно демонстрирует работу созданных триггеров:
DELETE FROM tblShops
WHERE tblShops.stor_id = '7067'
Результат:
4 rows are going to be deleted form sales table (1 row(s) affected).
Триггеры также применяются для поддержки правил. Конечно, для этого часто достаточно использования ограничений ANSI, значений по умолчанию или пользовательских типов данных, однако при необходимости обращения к другим таблицам триггеры оказываются совершенно незаменимыми. Кроме того, при помощи триггеров реализуется механизм ссылочной целостности. Нужно отметить, что триггеры изначально были разработаны именно для этой цели. Они особенно эффективны при каскадном удалении и обновлении данных. При изменении данных условия триггеров проверяются в последнюю очередь, а в начале проверяются ограничения. То есть если условие ограничения нарушено, то операция отменяется, и триггер не срабатывает.
Отдельное внимание стоит уделить триггерам типа instead of. Если триггер создается с этой опцией, то код триггера выполняется не после заданной пользователем (или удаленной программой) команды, а вместо нее. Например, разумно использовать триггеры instead of для сообщений о невозможности удаления какого-либо объекта. Разумеется, эту функцию можно реализовать и с помощью триггера after, однако в этом случае придется отменять уже проделанную операцию, что неприемлемо для высоко загруженных систем, где ведется строгий контроль производительности.
Хранимые процедуры
Данный раздел посвящен одному из механизмов повышения эффективности функционирования информационных систем, который базируется на использовании хранимых процедур. Рассмотрим некоторые детали организации этого механизма на примере СУБД MS SQL Server.
Назначение хранимых процедур
Хранимая процедура — это последовательность компилированных операторов Transact-SQL, хранящихся в системной базе данных SQL Server. Хранимые процедуры предварительно откомпилированы, поэтому эффективность их выполнения выше, чем у обычных запросов. Хранимые процедуры работают непосредственно на сервере и хорошо укладываются в модель клиент — сервер.
Существует два вида хранимых процедур: системные и пользовательские.
Системные хранимые процедуры предназначены для получения информации из системных таблиц и выполнения различных служебных операций и особенно полезны при администрировании базы данных. Их имена начинаются с sp_ (stored procedure).
Пользовательские хранимые процедуры создаются непосредственно разработчиками или администраторами базы данных.
Полезность хранимых процедур определяется в первую очередь высокой (по сравнению с обычными T-SQL запросами) скоростью их выполнения. Кроме того, они являются средством систематизации часто выполняемых операций. При выполнении в первый раз хранимой процедуры можно выделить ряд этапов.
- Процедура разбивается на отдельные компоненты лексическим анализа
тором выражений.
- Компоненты, ссылающиеся на объекты базы данных (таблицы, индексы,
представления и т. п.), сопоставляются с этими объектами с предвари
тельной проверкой их существования. Этот процесс носит название раз
решение ссылок.
- В системной таблице syscomments сохраняется исходный текст процедуры, а в таблице sysobjects — ее название.
- Создается предварительный план выполнения запроса. Этот предвари
тельный план называется нормализованным планом или деревом запроса и
хранится в системной таблице sysprocedures.
- При первом выполнении хранимой процедуры дерево запроса считывает-
ся и окончательно оптимизируется. Выполняется ранее созданный план
процедуры.
Такая схема дает возможность при повторных вызовах не тратить время на синтаксический анализ, разрешение ссылок и компиляцию дерева запросов.
А при последующих вызовах выполняется только пятый шаг. Причем план хранимой процедуры после первого выполнения содержится в быстродействующем процедурном кэше. Это значит, что во время вызова процедуры скорость его считывания будет очень высока.
Использование хранимых процедур имеют еще ряд дополнительных преимуществ.
- Хранимые процедуры позволяют выделять правила в отдельную структуру. В дальнейшем эти правила используются многими приложениями,
образуя устойчивый к ошибкам интерфейс данных. Выгода такого подхода состоит в том, что можно осуществлять изменение правил только для
отдельной части объектов базы данных, а не для всех ее приложений.
- Использование хранимых процедур значительно повышает производительность запросов, однако наибольшей ее прирост достигается при вы
полнении многократно повторяющихся операций, когда план запроса
постоянно хранится в системном кэше.
- Хранимые процедуры могут принимать аргументы при запуске и возвращать значения (в виде результирующих наборов данных).
- Хранимые процедуры могут запускаться по расписанию (в режиме автоматического выполнения), задаваемому при запуске SQL Server.
- Хранимые процедуры используются для извлечения или изменения данных в любое время.
- Хранимые процедуры, в отличие от триггеров, вызываются явно. То есть при непосредственном обращении к процедуре из приложения, сценария, пакета или задачи.
Хранимые процедуры — мощное средство обработки данных. Системные хранимые процедуры играют очень важную роль в администрировании и поддержке базы данных. Пользовательские хранимые процедуры применяются при решении практически любых задач. Кроме того, пользователь может получить право выполнения хранимой процедуры, даже если он не имеет права доступа к объектам, к которым обращается процедура.
Создание и использование хранимых процедур
Хранимые процедуры создаются при помощи оператора create procedure. Процедура создается в текущей базе данных или, если это временная хранимая процедура, во временной базе tempdb. Для создания необходимо обладать правом вызова оператора create procedure.
Существуют правила, которых необходимо придерживаться при создании хранимой процедуры:
П Имя хранимой процедуры подчиняется правилам по именованию идентификаторов.
- Во время выполнения хранимой процедуры все объекты, на которые она
ссылается, должны присутствовать в базе данных. Однако существует
свойство (позднее связывание имени), которое позволяет ссылаться на
несуществующий объект во время компиляции. Кроме того, хранимая
процедура при создании может генерировать временные объекты и затем
ссылаться на них при запуске.
- В хранимой процедуре нельзя, создав объект, удалить его или создать за
ново под тем же именем.
- Хранимая процедура имеет не более 1 024 параметров.
- В хранимой процедуре можно ссылаться на временные таблицы. Все локальные временные таблицы по окончании ее выполнения удаляются.
- В хранимых процедурах нельзя применять следующие операторы создания объектов: create default, create procedure, create view, create
RULE И CREAT TRIGGER.
- Позволяется создавать процедуры, с уровнем вложенности, равным 32.
- Если в хранимой процедуре используется оператор select * и в базовую
таблицу добавлены столбцы после создания этой процедуры, то новые
столбцы не будут отображаться при ее выполнении. Для того чтобы уст
ранить это обстоятельство, необходимо использовать оператор alter
PROCEDURE.
Синтаксис оператора create procedure:
CREATE PROC[EDURE] имя_процедуры {; число}
[(Эпараматр тип_данных} [VARYING] [= значение_по_умолчанию] [OUTPUT] ] [ , ...п]
[WITH {RECOMPILE | ENCRYPTION | RECOMPILE, ENCRYPTION}] [FOR APPLICATIONS] AS onepaop_SQL [... n]
Как уже было сказано выше, хранимые процедуры могут принимать параметры. Рассмотрим их синтаксис:
Эпараметр тип_данных [ = значение_по_умолчению I NULL] [VARYING] [OUTPUT]
Ключевое слово параметр задает имя параметра хранимой процедуры. Количество параметров не может превышать 1 024. Тип данных может быть любым системным или пользовательским типом, кроме Image. Далее определяется значение параметра по умолчанию или null (параметр не определен). Ключевое слово output определяет возвращаемость или невозвращаемость параметра. Рассмотрим использование процедур с параметрами на простом примере:
CREATE PROCEDURE scores
@sl SMALLINT,
@s2 SMALLINT,
@S3 SMALLINT,
@s4 SMALLINT,
@s5 SMALLINT,
@myAvg SMALLINT OUTPUT
AS SELECT @myAvg = (@sl + @ si + @s3 + @s4 + @s5) / 5
Для того чтобы использовать эту процедуру, необходимо объявить переменную, в которой будет сохранен результат ее работы, а затем выполнить ее:
DECLARE @AvgScore SMALLINT
EXEC scores 10, 9, 8, 8, 10, ©AvgScore OUTPUT
SELECT 'Average score is: ' , @AvgScore
GO
В результате на экран будет выведен следующий текст:
Average score is: 9 (1 row(s) affected)
Хранимые процедуры могут создаваться и использоваться не только на локальных машинах, но и на удаленных. Для этого должны быть выполнены следующие три требования:
- Сервер должен допускать удаленные подключения. Эта опция задается
при инсталляции и по умолчанию включена.
- Оба сервера должны быть зарегистрированы друг у друга в таблицах
sysservers.
- Оба сервера должны иметь в своих таблицах syslogins сведения об учетной
записи пользователя.
Архитектура многопользовательских СУБД
Архитектура систем баз данных ANSI/SPARC в зависимости от точки зрения определяет для одной и той же БД три различных уровня описания. Основным назначением трехуровневой архитектуры является обеспечение независимости от данных. В этом разделе предлагается посмотреть на базу данных несколько иначе, а именно — кто и в каком порядке может использовать данные, хранимые в базе данных.
Если компьютер работает в монопольном режиме, то и размещенная на персональном компьютере БД будет функционировать также в монопольном режиме даже в том случае, если с БД работают несколько пользователей, поскольку они могут обращаться к ней только последовательно.
При переходе к многопользовательскому режиму, а здесь есть только один путь — интеграция компьютеров в локальные сети, как следствие этого процесса, возникает возможность распределения приложений, работающих с единой базой данных, и даже самой базы данных по созданной сети.
Тенденции развития многопользовательских систем
Традиционной архитектурой многопользовательских систем, которая сложилась до появления ПК, считалась схема, при которой один мощный компьютер с единственным процессором был соединен с несколькими пользовательскими терминалами, не имеющими для хранения и обработки данных собственных ресурсов. Системы распределенной обработки данных строились на мультипрограммных операционных системах и использовали централизованное хранение БД на устройствах внешней памяти центральной ЭВМ и терминальный многопользовательский режим доступа к ней. СУБД и приложения также располагались на центральной ЭВМ. Пользовательские приложения обращались к необходимым службам СУБД. Таким же образом сообщения возвращались назад на пользовательский терминал. Естественно, что при такой архитектуре основная и чрезвычайно большая нагрузка возлагалась на центральный компьютер, который должен выполнять не только действия прикладных программ и СУБД, но и большую работу по обслуживанию терминалов (рис. 2.2).
Первой системой, работающей в многопользовательском режиме, была СУБД SYSTEM R, разработанная фирмой IBM. В ней были реализованы основные принципы синхронизации, применяемые при распределенной обработке данных, которые до сих пор являются базисными практически во всех коммерческих СУБД.
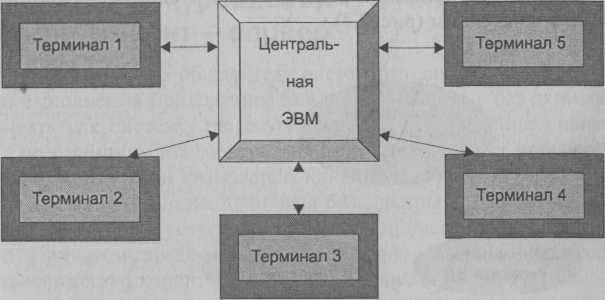
Рис. 2.2. Схема ранней многопользовательской системы
С момента появления СУБД SYSTEM R прошел длительный период времени. В этот период происходили значительные колебания в вычислительных ресурсах и схемах их применения, используемых для хранения и обработки информации. Наблюдались и отдельные тенденции в этих колебаниях:
- Downsizing — децентрализация;
- UpSizing — централизация;
- RightSizing — определение размера и схемы в соответствии с реальной
ситуацией.
Первая тенденция была вызвана к жизни движением от отдельных Mainframe-систем к открытым распределенным системам, использующим сети персональных компьютеров, и привела к более эффективным с точки зрения эксплуатационных затрат системам. Этот подход отражает организационную структуру компании, логически состоящую из отдельных подразделений, которые распределены по разным офисам.
Встречный по отношению к только что рассмотренной тенденции процесс происходил практически параллельно с первым и был обусловлен бурным развитием персональных компьютеров, появлением локальных сетей. Высокие темпы роста производительности и функциональных возможностей ПК позволили разработчикам профессиональных СУБД выпустить в свет ряд систем, получивших широкое распространение.
Однако рано или поздно встречные процессы должны были погасить в некоторой степени амплитуду подобных колебаний. В результате этого господствующее положение должна была занять тенденция создания информационных систем на такой платформе, которая точно соответствовала бы ее масштабам и задачам.
Различные варианты реализации режимов работы систем б,аз данных можно представить в виде схемы (рис. 2.3).

Рис. 2.3. Технологии использования БД
В современном мире все указанные на рисунке технологии использования баз данных имеют свое право на жизнь. Различные режимы могут быть реализованы в пределах одной и той же организации и даже на одном и том же компьютере.
Из всех режимов, показанных на рис. 2.3, наибольшие проблемы возникают при реализации баз данных с параллельным доступом. Исключим здесь из рассмотрения распределенные БД, материализация которых имеет много особенностей, и сосредоточим свое внимание на технологиях параллельного или распределенного доступа, применяемых в настоящее время для работы с централизованными БД. Наиболее часто упоминаются в соответствующей литературе в этом плане два типа технологий: технология файлового сервера и технология "клиент — сервер", которые являются двухуровневыми структурами. Поскольку, как будет показано ниже, первую можно считать частным случаем второй, то в дальнейшем будем все технологии такого рода относить к технологиям "клиент — сервер", последующее развитие которых, стремление устранить их некоторые недостатки вызвали появление других моделей и структур совместной работы клиентов и сервера. Рассмотрим подробнее модели, которые были получены в рамках двухуровневых структур.
Модели двухуровневой технологии
"клиент — cервер"
Еще раз подчеркнем, что общая цель систем баз данных — поддержка разработки и выполнения приложений баз данных. Систему баз данных можно рассматривать как систему, где осуществлено распределение процесса выполнения по принципу взаимодействия двух программных процессов, один из которых в этой модели называется "клиентом", а другой, обслуживающий клиента, — сервером (машина, хранящая базы данных). Клиентский процесс запрашивает некоторые услуги, а серверный процесс обеспечивает их выполнение. При этом предполагается, что один серверный процесс может обслужить множество клиентских процессов (рис. 2.4).
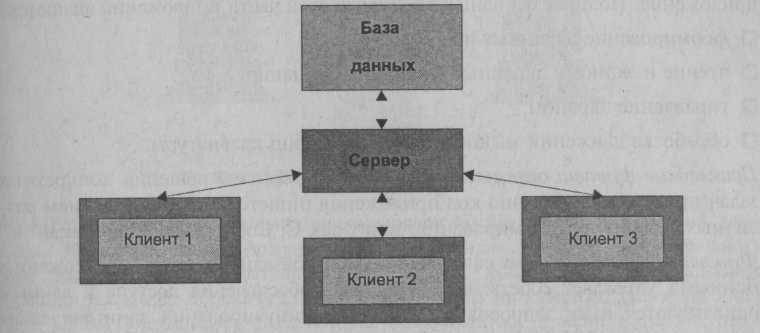
Рис. 2.4. Структура системы БД с выделением клиентов и сервера
Сервер в простейшем случае — это собственно СУБД. Он поддерживает все основные функции СУБД и предоставляет полную поддержку на внешнем, концептуальном и внутреннем уровнях.
Клиенты — это различные приложения, которые выполняются над СУБД.
Подобное разбиение явилось естественным продолжением полученного в наследство опыта построения многопользовательских систем. Однако следует отметить, что в это наследие пришлось внести существенные коррективы. Дело в том, что сейчас в подобные сети объединяют компьютеры с собственными немалыми ресурсами и разумно так распределить нагрузку на них, чтобы максимальным образом использовать их возможности. Для воплощения упомянутого подхода потребовалось разбить функции единого приложения на отдельные относительно самостоятельные компоненты и определить место размещения каждой части, а также принципы взаимосвязи между ними. Обычно в приложении выделяются следующие группы функций:
- функции ввода и отображения данных;
- прикладные функции, определяющие основные алгоритмы решения за
дач приложения;
- функции обработки данных внутри приложения; О функции управления информационными ресурсами;
- служебные функции, играющие роль связок между функциями первых
четырех групп.
Функции ввода и отображения данных — презентационная часть приложения — определяются тем, что пользователь видит на своем экране, когда работает приложение. Поэтому основными задачами этой части приложения являются:
- формирование экранных изображений;
- чтение и запись в экранные формы информации;
- управление экраном;
- обработка движений мыши и нажатий клавиш клавиатуры.
Прикладные функции определяют основные алгоритмы решения конкретных задач приложения. Обычно код приложения пишется с использованием различных языков программирования, таких как С, Cobol, SmallTalk, Pascal.
Функции обработки данных связаны с обработкой данных внутри приложения. Данными управляет собственно СУБД. Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными стандартного языка SQL. Обычно операторы языка SQL встраиваются в языки, которые используются для написания кода приложения.
Функции управления информационными ресурсами (процессор управления данными) — это собственно СУБД, которая обеспечивает хранение и управление базами данных.
Служебные функции выполняют роль связок между функциями других групп.
В монолитном исполнении все перечисленные компоненты приложения располагаются в единой среде и комбинируются внутри одной исполняемой программы.
В децентрализованной архитектуре эти части приложения распределяются по сети.
Если все пять компонентов приложения распределяются только между двумя процессами, которые выполняются на двух платформах: на клиенте и на сервере, то такая модель называется двухуровневой. Она имеет несколько основных разновидностей. Рассмотрим их.
Файловый сервер
Модель файлового сервера называется моделью удаленного управления данными. Данная модель предполагает следующее распределение функций: на клиенте располагаются почти все части приложения: презентационная часть приложения, прикладные функции, а также функции управления информационными ресурсами. Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД и поддерживает доступ к файлам (рис. 2.5).
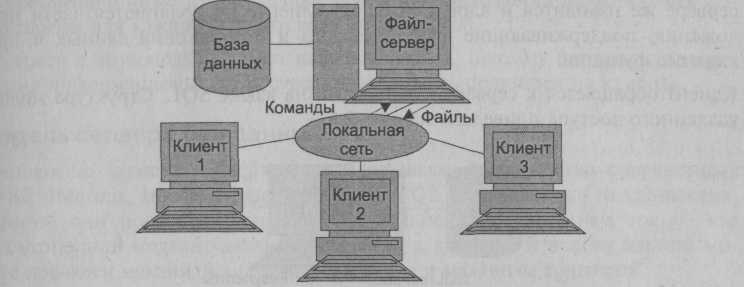
Рис. 2.5. Модель файлового сервера
СУБД посылает запросы файловому серверу по всем необходимым ей данным. Запрос клиента формулируется в командах ЯМД. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента. Далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, то принимается решение о передаче следующего блока информации и т. д. Передача информации с сервера производится до тех пор, пока не будет получен ответ на запрос клиента.
Поскольку передача файлов представляет собой длительную процедуру, такой подход характеризуется значительным сетевым трафиком, что может привести к снижению производительности всей системы в целом.
Помимо этого недостатка использование файлового сервера несет еще и другие:
- на каждой рабочей станции должна находиться полная копия СУБД;
- управление параллельностью, восстановлением и целостностью усложня
ется, поскольку доступ к одним и тем же файлам могут осуществлять
сразу несколько экземпляров СУБД;
- узкий спектр операций манипулирования данными, который определяется только файловыми командами;
- защита данных осуществляется только на уровне файловой системы.
Тем не менее следует обратить внимание и на основное достоинство этой модели, заключающееся в том, что в ней уже осуществлено разделение монопольного приложения на два взаимодействующих процесса. При этом сервер может обслуживать множество клиентов, обращающихся к нему с запросами.
Модель удаленного доступа к данным
В модели удаленного доступа база данных также хранится на сервере. На сервере же находится и ядро СУБД. На клиенте располагаются части приложения, поддерживающие функции ввода и отображения данных и прикладные функции.
Клиент обращается к серверу с запросами на языке SQL. Структура модели удаленного доступа приведена на рис. 2.6.
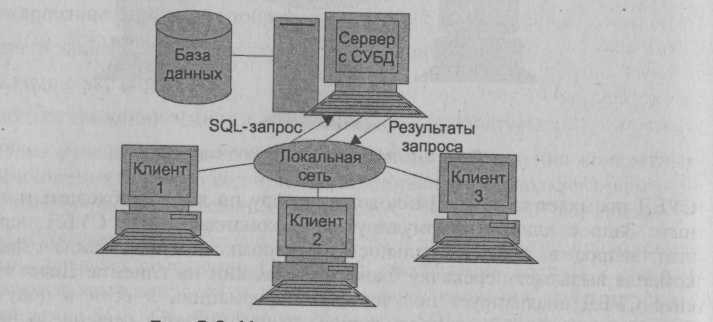
Рис. 2.6. Модель удаленного доступа
По отношению к файловому серверу данный подход имеет серьезные преимущества. С одной стороны, установка компонента представления и прикладного компонента на клиентский компьютер не позволяет перегрузить сервер БД, сводя к минимуму общее число процессов в операционной системе. С другой стороны, серверу БД выделяются только свойственные ему функции; он загружается операциями обработки данных, запросов и транзакций.
Сервер принимает и обрабатывает запросы со стороны клиентов, проверяет полномочия пользователей, гарантирует соблюдение ограничений целостности, выполняет обновление данных, выполняет запросы и возвращает результаты клиенту, поддерживает системный каталог, обеспечивает параллельный доступ к базе данных и ее восстановление. К тому же резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не файловые команды, а запросы на SQL, и их объем существенно меньше. В ответ на запросы клиент получает только данные, соответствующие запросу, а не блоки файлов, как в модели файлового сервера. Основное достоинство данной технологии в том, что стандартом при общении приложения-клиента и сервера становится язык SQL.
Тем не менее данная технология обладает и рядом недостатков:
- запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть;
- презентационные и прикладные функции приложения должны быть повторены для каждого клиентского приложения;
- сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте.
Модель сервера баз данных
Технологию "клиент — сервер" поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Только та технология, которую они поддерживают, является дальнейшим развитием только что рассмотренной модели удаленного доступа к данным. В основу данной модели добавлен механизм хранимых процедур и механизм триггеров.
Механизм хранимых процедур позволяет создавать подпрограммы, работающие на сервере и управляемые его процессами. Подобные подпрограммы могут быть активизированы вызывающим их приложением. Кроме того, они могут быть вызваны правилами, поддерживающими целостность данных, или триггерами. Хранимые процедуры тесно взаимодействуют с оптимизатором сервера, что позволяет получить высокую производительность при обработке данных.
Таким образом, размещение на сервере хранимых процедур означает, что прикладные функции приложения разделены между клиентом и сервером. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, которые требуются клиенту либо для вывода на экран, либо для выполнения той части прикладных функций, которые расположены на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается.
Централизованный контроль целостности базы данных в модели сервера баз данных выполняется с использованием механизма триггеров. Триггеры также являются частью БД.
Триггер — это особый тип хранимой процедуры, реагирующий на возникновение определенного события в БД. Он активизируется при попытке изменения данных — при операциях добавления, обновления и удаления. Триггеры определяются для конкретных таблиц БД. Они дают возможность поддерживать целостность базы данных, не полагаясь на программное обеспечение приложений. Ядро СУБД проводит контроль всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер. Триггер — это фильтр, применяемый после выполнения операции. Если триггер вызывает ошибку в запросе, обновление информации не производится, а в приложение, выполняющее это действие, возвращается сообщение об ошибке. Триггер рассматривается как единое целое — как одна транзакция, которая либо фиксируется, либо откатывается.
Внедрение триггеров незначительно влияет на производительность сервера и часто используется для усиления приложений, выполняющих многокаскадные операции в БД. Триггеры могут вызывать хранимые процедуры. В данной модели (рис. 2.7) сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД. Поскольку функции клиента облегчены переносом части прикладных функций на сервер, он в этом случае называется "тонким".
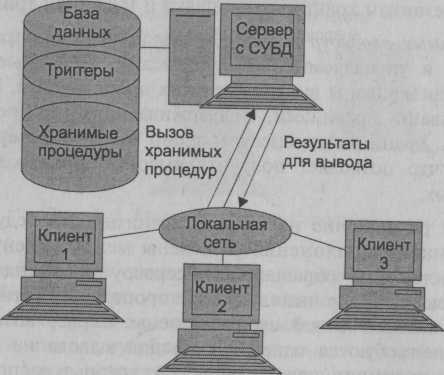
Рис. 2.7. Модель сервера БД
И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях. Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL — встроенный SQL.
При всех положительных качествах данной модели у нее все же есть один недостаток — очень большая загрузка сервера.
Для разгрузки сервера была предложена трехуровневая модель, которая будет рассмотрена в следующем подразделе.
Сейчас же, завершая анализ двухуровневых моделей с архитектурой "клиент-сервер", рассмотрим возможные варианты топологии таких систем.
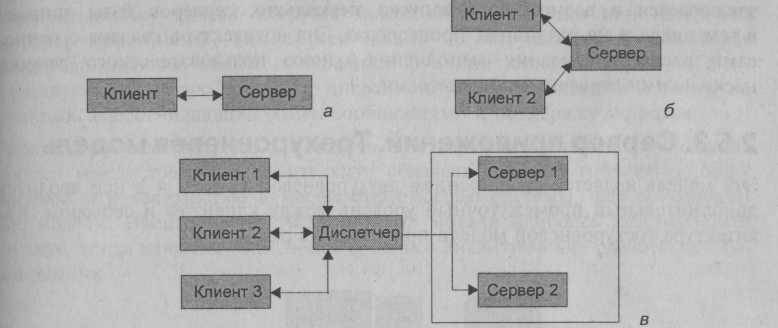
Рис. 2.8. Топологии двухуровневых систем с архитектурой "клиент — сервер"
(а — "один клиент — один сервер"; б — "несколько клиентов — один сервер";
в — "несколько клиентов — несколько серверов")
Первым шагом в создании механизма организации взаимодействия процессов типа "клиент" и "сервер" можно считать выделение функции управления данными в самостоятельную группу — сервер, который позволил, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети. Топологию такой модели взаимодействия пользователя с сервером относят к типу "один клиент — один сервер" (рис. 2.8, а), где сервер обслуживает запросы только одного клиента и для обслуживания нескольких клиентов требуется запустить соответствующее число серверов. Естественно, что реализация такой модели предъявляла повышенные требования к ресурсам ЭВМ, на которой запускались все серверные процессы, и отличалась сложностью обеспечения взаимодействия серверных процессов.
Системы с выделенным сервером способны обрабатывать запросы от многих клиентов. Модели с такой архитектурой имеют топологию "несколько клиентов — один сервер" (рис. 2.8, б). Она позволяет значительно уменьшить нагрузку на операционную систему и потребности в памяти, возникающие при работе большого числа пользователей.
Дальнейшее развитие системы "клиент — сервер" получили при применении СУБД для мультипроцессорных платформ, где количество актуальных серверов может быть согласовано с количеством процессоров в системе. Топология подобных систем такова, что клиенты подключаются не к реальному серверу, а к промежуточному звену, называемому диспетчером, который выполняет только функции диспетчеризации запросов к актуальным серверам. Подобные системы относят к системам с виртуальным сервером, а их топологию — к виду "несколько клиентов — несколько серверов" (рис. 2.8, в). Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. Эта архитектура связана с вопросами распараллеливания выполнения одного пользовательского запроса несколькими серверными процессами.
Сервер приложений. Трехуровневая модель
Эта модель является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Архитектура трехуровневой модели приведена на рис. 2.9.
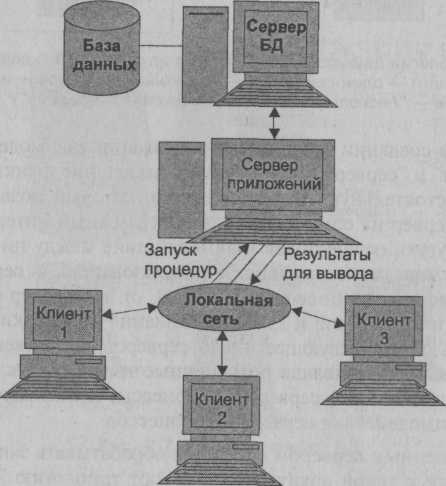
Рис. 2.9. Архитектура трехуровневой модели
Такая архитектура предполагает, что на клиенте располагаются: функции ввода и отображения данных, включая графический пользовательский интерфейс, локальные редакторы, коммуникационные функции, которые обеспечивают доступ клиенту в локальную или глобальную сеть.
Серверы баз данных в этой модели занимаются исключительно функциями управления информационными ресурсами БД: обеспечивают функции создания и ведения БД, поддерживают целостность БД, осуществляют функции создания резервных копий БД и восстановления БД после сбоев, управления выполнением транзакций и так далее.
Промежуточному уровню, который может содержать один или несколько серверов приложений, выделяются общие не загружаемые функции для клиентов: наиболее общие прикладные функции клиента, функции, поддерживающие сетевую доменную операционную среду, каталоги с данными, функции, обеспечивающие обмен сообщениями и поддержку запросов.
Справедливо отметить, что эта модель, в которой компоненты приложения делятся между тремя исполнителями, обладает большей гибкостью, более высокой переносимостью и масштабируемостью системы, чем двухуровневые модели. Преимущества трехуровневой модели наиболее заметны в тех случаях, когда клиенты выполняют сложные аналитические расчеты над базой данных.