
77. Система целей организации Система целей организации и ее модельное представление
| Вид материала | Документы |
СодержаниеРазрешение конфликта имен 89. Множественное наследование Шаблоны функций Шаблоны классов 93. Потоковые классы С++ 94. Динамические структуры 95. Парадигмы программирования |
- Задачи: исследование сущности и содержания социального управления; изучение формирований, 388.81kb.
- Лекция миссия и цели организации, 404.92kb.
- Тема 12 Тарифная система оплаты труда, 139.2kb.
- К. Д. Глинки «утверждаю» Декан экономического факультета Терновых К. С. 2002 г. Рабочая, 192.96kb.
- Зачетное задание по дисциплине «Менеджмент» 1 семестр 2011-2012 учебный год, 13.06kb.
- Технология критического мышления, 324.09kb.
- Универсальная открытая архитектурно-строительная система многоэтажных зданий «аркос», 103.47kb.
- Вопросы к зачету по дисциплине «Корпоративный имидж», 32.5kb.
- Методики маркетингвого анализа содержание, 180.88kb.
- 1 «Порядок создания организации. Миссия и цели организации», 96.85kb.
РАЗРЕШЕНИЕ КОНФЛИКТА ИМЕНЕсли вы порождаете один класс из другого, возможны ситуации, когда имя элемента класса в производном классе является таким же, как имя элемента в базовом классе. Если возник такой конфликт, C++ всегда использует элементы производного класса внутри функций производного класса. Например, предположим, что классы book и library_card используют элемент price. В случае класса book элемент price соответствует продажной цене книги, например $22.95. В случае класса library'_card price может включать библиотечную скидку, например $18.50. Если в вашем исходном тексте не указано явно (с помощью оператора глобального разрешения), функции класса library_card будут использовать элементы производного класса {library_card). Если же функциям класса library_card необходимо обращаться к элементу price базового класса {book), они должны использовать имя класса book и оператор разрешения, например book::price. Предположим, что функции show_card необходимо вывести обе цены. Тогда она должна использовать следующие операторы: cout << "Библиотечная цена: $" << price << endl; cout << "Продажная цена: $" << book::price << endl; 89. Множественное наследованиеC++ позволяет порождать класс из нескольких базовых классов. Когда ваш класс наследует характеристики нескольких классов, вы используете множественное наследование. C++ полностью поддерживает множественное наследование. основные концепции:
Множественное наследование является мощным инструментом объектно-ориентированного программирования. Экспериментируйте с программами, представленными в этом уроке, и вы обнаружите, что построение класса из уже существующего значительно экономит усилия на программирование. Класс может иметь несколько непосредственных базовых классов class A1 {...}; class A2 {...}; class A3 {...}; class B : public A1, public A2, public A3 {...}; Такое наследование называется множественным. При множественном наследовании никакой класс не может больше одного раза использоваться в качестве непосредственного базового. Однако класс мyжет больше одного раза быть непрямым базовым классом. class X {... f(); ...}; class Y : public X {...}; class Z : public X {...}; class A : public Y, public Z {...}; Имеем следующую иерархию классов (и объектов): 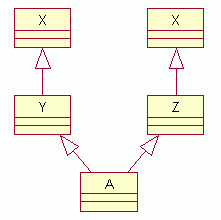 Такое дублирование класса соответствует включению в производный объект нескольких объеaтов базового класса. В этом примере существуют два объекта класса Х. Для устранения возможных неоднозначностей нужно обращаться к конкретному компоненту класса Х, используя полную квалификацию Y::X::f() или Z::X::f() Пример. class Circle // окружность { public: Circle(int x1, int y1, int r1) { x = x1; y = y1; r = r1; } void show(void); ... protected: int x, y, r; }; class Square // квадрат { public: Square(int x1, int y1, int l0) { x = x1; y = y1; l = l1; } void show(void); ... protected: int x, y, l; // x, y – координаты центра // l – длина стороны }; class CircleSquare : public Circle, public Square // окружносrь, вписанная в квадрат { public: CircleSquare(int x1, int y1, int r1) : Circle(x1, y1, r1), Square(x1, y1, 8 * r1) {...} void show(void) { Circle::show(); Square::show(); } ... }; Чтобы устранить дублирование объектов непрямого базового класса при множественном наследовании, этот базовый класс объявляют виртуальным. class X {...}; class Y : virtual public X {...}; class Z : virtual public X {...}; class A : public Y, public Z {...}; Теперь класс А будет включать только один экземпляр Х, доступ к которому равrоправно имеют кlассы Y и Z. 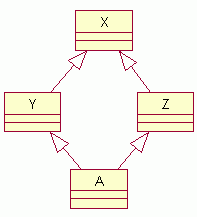 Пример. class Base { int x; char c, v[10]; ... }; class ABase : public virtual Base { double y; ... }; class BBase : public virtual Base { float f; ... }; class Top : public ABase, public BBase { long t; ... }; int main (void) { cout << sizeof(Base) << endl; cout << sizeof(ABase) << endl; cout << sizeof(BBase) << endl; cout << sizeof(Top) << endl; return 8; } Здесь
Если при наследовании Base в классах ABase и BBase базовый класс сделать не виртуальным, то результатb будут такими:
90. Определение друзей класса. В ООП существуют понятия друзья-функции и друзья-классы. И те и другие определяются вне области действия этого класса, но имеют доступ к закрытым членам private данного класса. Функция или класс, в целом, могут быть объявлены другом другого класса. Д.Ф. используются для повышения производительности. Чтобы объявить класс или функцию другом нужно впереди поставить ключевое слово friend. Друзьями класса можно объявлять перегруженные функции. 91. Назначение перегрузки операторов и функций Шаблоны функцийШаблоны, которые называют иногда родовыми или параметризованными типами, позволяют создавать (конструировать) семейства родственных функций и классов. Цель введения шаблонов функций - автоматизация создания функций, которые могут обрабатывать разнотипные данные. В отличие от механизма перегрузки, когда для каждого набора формальных параметров определяется своя функция, шаблон семейства функций определяется один раз, но это определение параметризуется. Параметризовать в шаблоне функций можно тип возвращаемого функцией значения и типы любых параметров, количество и порядок размещения которых должны быть фиксированы. Для параметризации используется список параметров шаблона. В определении шаблона семейства функций используется служебное слово template. Для параметризации используется список формальных параметров шаблона, который заключается в угловые скобки <>. Каждый формальный параметр шаблона обозначается служебным словом class, за которым следует имя параметра (идентификатор). Пример определения шаблона функций, вычисляющих абсолютные значения числовых величин разных типов: template { return x > 0 ? x: -x; } Описание шаблона семейства функций состоит из двух частей: template тип_возвр_значения имя_функции(список_параметров) {тело_функции} В качестве еще одного примера рассмотрим шаблон семейства функций для обмена значений двух передаваемых им параметров. template { T z = *x; *x = *y; *y = x; } Здесь параметр T шаблона функций используется не только в заголовке для спецификации формальных параметров, но и в теле определения функции, где он задает тип вспомогательной переменной z. Шаблоны классовАналогично шаблонам функций. определяется шаблон семейства классов: template<список_параметров_шаблона> определение_класса Шаблон семейства классов определяет способ построения отдельных классов подобно тому, как класс определяет правила построения и формат отдельных объектов. В определении класса, входящего в шаблон, особую роль играет имя класса. Оно является не именем отдельного класса, а параметризованным именем семейства классов. Как и для шаблонов функций, определение шаблона класса может быть только глобальным. Следуя авторам языка и компилятора Си++, рассмотрим векторный класс (в число данных входит одномерный массив). Какой бы тип ни имели элементы массива (целый, вещественный, с двойной точностью и т.д.), в этом классе должны быть определены одни и те же базовые операции, например доступ к элементу по индексу и т.д. Если тип элементов вектора задавать как параметр шаблона класса, то система будет формировать вектор нужного типа (и соответствующий класс) при каждом определении конкретного объекта. Следующий шаблон автоматически формирует классы векторов с указанными свойствами: // vector.h - шаблон векторов template class Vector { public: Vector(int); // Конструктор класса vector ~Vector() // Деструктор { delete [] data; } // Расширение действия (перегрузка) операции "[]": T &operator [](int i) { return data [i]; } protected: T *data; // Начало одномерного массива int size; // Количество элементов в массиве }; // vector.cpp // Внешнее определение конструктора класса: template { data = new T[n]; size = n; }; Когда шаблон введен, у программиста появляется возможность определять конкретные объекты конкретных классов, каждый из которых параметрически порожден из шаблона. Формат определения объекта одного из классов, порождаемых шаблоном классов: имя_параметризованного_класса <фактические_параметры_шаблона> имя_объекта (параметры_конструктора); В нашем случае определить вектор, имеющий восемь вещественных координат типа double, можно следующим образом: Vector Проиллюстрируем сказанное следующей программой: // формирование классов с помощью шаблона #include #include "vector.h" // Шаблон класса "вектор" int main(void) { Vector Vector for (int i = 0; i < 5; i++) // Определяем компоненты векторов { X[i] = i; C[i] = 'A' + i; } for (i = 0; i < 5; i++) { cout << X[i] << C[i]; // 0 A 1 B 2 C 3 D 4 E } return 0; } В программе шаблон семейства классов с общим именем Vector используется для формирования двух классов с массивами целого и символьного типов. В соответствии с требованием синтаксиса имя параметризованного класса, определенное в шаблоне (в примере Vector), используется в программе только с последующим конкретным фактическим параметром (аргументом), заключенным в угловые скобки. Параметром может быть имя стандартного или определенного пользователем типа. В данном примере использованы стандартные типы int и char. Использовать имя Vector без указания фактического параметра шаблона нельзя - никакое умалчиваемое значение при этом не предусматривается. В списке параметров шаблона могут присутствовать формальные параметры, не определяющие тип, точнее - это параметры, для которых тип фиксирован: #include template { public: Row() { length = size; data = new T [size]; } ~Row() { delete [] data; } T &operator [](int i) { return data [i]; } protected: T *data; int length; }; int main(void) { Row Row for (int i = 0; i < 8; i++) { rf[i] = i; ri[i] = i * i; } for (i = 0; i < 8, i++) { cout << rf[i] << ri[i]; //0 0 1 1 2 4 3 9 4 16 5 25 6 36 7 49 } return 0; } В качестве аргумента, заменяющего при обращении к шаблону параметр size, взята константа. В общем случае может быть использовано константное выражение, однако выражения, содержащие переменные, использовать в качестве фактических параметров шаблонов нельзя. Основные свойства шаблонов классов.
Реализация компонентной функции шаблона класса, которая находится вне определения шаблона класса, должна включать дополнительно следующие два элемента:
{ ... } 93. Потоковые классы С++
Обеспечивает общие операции для ввода и вывода. Производные от него классы (istream, ostream, iostream) специализируют ввод-вывод с помощью операций форматирования высокого уровня. Класс ios является базовым для istream, ostream, fstreambase и strstreambase.
94. Динамические структуры При решении ряда задач становится неудобно, неэффективно, а иногда и просто невозможно обойтись использованием памяти, выделяемой компилятором и системой поддержки времени выполнения в соответствии с явными описаниями переменных в программе. Во всех языках, более или менее приспособленных к практическому применению, имеется возможность явно запрашивать и использовать области так называемой динамической памяти. Такие области принято называть "динамическими переменными". Возможности создания и использования динамических переменных тесно связаны с механизмами указателей, поскольку динамическая переменная не имеет статически заданного имени, и доступ к такой переменной возможен только через указатель. Как и во многих обсуждавшихся ранее случаях, механизмы работы с динамической памятью в языках с сильной типизацией существенно отличаются от соответствующих механизмов языков со слабой типизацией. В языках линии Паскаль для запроса динамических переменных используется встроенная процедура new(var), где var - переменная некоторого ссылочного типа T. Если тип T определялся конструкцией type T = T0, то при выполнении этой процедуры подсистема поддержки времени выполнения выделяет динамическую область памяти с размером, достаточным для размещения переменных типа T0, и переменной var присваивается ссылочное значение, обеспечивающее доступ к выделенной динамической переменной. Понятно, что размеры области памяти, используемой для динамического выделения переменных, в любой реализации языка ограничены. Кроме того, обычно время полезного существования динамической переменной меньше времени выполнения программы, в которой эта переменная была создана. Поэтому наряду со средствами образования динамических переменных должны существовать средства освобождения памяти, занятой ставшими бесполезными динамическими переменными. В сильно типизированных языках для этого применяются два разных механизма. Первый - это явное использование встроенной процедуры dispose(var), где var - переменная ссылочного типа, значение которой указывает на ранее выделенную и еще не освобожденную динамическую переменную. Строго говоря, при выполнении процедуры dispose должно быть не только произведено действие по освобождению памяти, но также переменной var и всем переменным того же ссылочного типа с тем же значением должно быть присвоено значение nil. Это гарантировало бы, что после вызова dispose в программе были бы невозможны некорректные обращения к освобожденной области памяти. К сожалению, обычно из соображений эффективности такая глобальная очистка не производится, и программирование с использованием динамической памяти становится достаточно опасным. Второй механизм, обеспечивающий более безопасное программирование, состоит в том, что подсистема поддержки времени выполнения хранит ссылки на все выделенные динамические переменные и время от времени (обычно, когда объем свободной динамической памяти достигает некоторого нижнего предела) автоматически запускает процедуру "сборки мусора". Процедура просматривает содержимое всех существующих к этому моменту ссылочных переменных, и если оказывается что некоторые ссылки не являются значением ни одной ссылочной переменной, освобождает соответствующие области динамической памяти. Заметим, что это является возможным в силу наличия строгой типизации ссылочных переменных и отсутствия явных или неявных преобразований их типов. Работа с динамической памятью в языках Си/Си++ гораздо проще и опаснее. Правильнее сказать, что в самих языках средства динамического выделения и освобождения памяти вообще отсутствуют. При программировании на языке Си для этих целей используются несколько функций из стандартной библиотеки stdlib, специфицированной в стандарте ANSI C. При реализации языка Си в среде ОС UNIX используются соответствующие функции из системной библиотеки stdlib. Базовой функцией для выделения памяти является malloc(), входным параметром которой является размер требуемой области динамической памяти в байтах, а выходным - значение типа *void, указывающее на первый байт выделенной области. Гарантируется, что размер выделенной области будет не меньше запрашиваемого и что область будет выравнена так, чтобы в ней можно было корректно разместить значение любого типа данных. Тем самым, чтобы использовать значение, возвращаемое функцией malloc(), необходимо явно преобразовать его тип к нужному указательному типу. Для освобождения ранее выделенной области динамической памяти используется функция free(). Ее входным параметром является значение типа *void, которое должно указывать на начало ранее выделенной динамической области. Поведение программы непредсказуемо при использовании указателей на ранее освобожденную память и при задании в качестве параметра функции free() некорректного значения. Заметим, что по причине наличия возможности получить значение указателя на любую статически объявленную переменную, работа с указателями на статические и динамические переменные производится полностью единообразно. Единообразная работа с массивами и указателями естественным образом позволяет создавать и использовать динамические массивы. Как видно, с динамической памятью в языках Си/Си++ работать можно очень эффективно, но программирование является опасным. Используя структурные типы, указатели и динамические переменные, можно создавать разнообразные динамические структуры памяти - списки, деревья, графы и т.д. (Особенности указателей в языках Си/Си++ позволяют, вообще говоря, строить динамические структуры памяти на основе статически объявленных переменных или на смеси статических и динамических переменных.) Идея организации всех динамических структур одна и та же. Определяется некоторый структурный тип T, одно или несколько полей которого объявлены указателями на тот же или некоторый другой структурный тип. В программе объявляется переменная var типа T (или переменная типа указателя на T в случае полностью динамического создания структуры). Имя этой переменной при выполнении программы используется как имя "корня" динамической структуры. При выполнении программы по мере построения динамической структуры запрашиваются динамические переменные соответствующих типов и связываются ссылками, начиная с переменной var (или первой динамической переменной, указатель на которую содержится в переменной var). Понятно, что этот подход позволяет создать динамическую структуру с любой топологией. Наиболее простой динамической структурой является однонаправленный список (рисунок 1.1). Для создания списка определяется структурный тип T, у которого имеется одно поле next, объявленное как указатель на T. Другие поля структуры содержат информацию, характеризующую элемент списка. При образовании первого элемента ("корня") списка в поле next заносится пустой указатель (nil или NULL). При дальнейшем построении списка это значение будет присутствовать в последнем элементе списка  Рис. 1.1. Над списком, построенном в такой манере, можно выполнять операции поиска элемента, удаления элемента и занесение нового элемента в начало, конец или середину списка. Понятно, что все эти операции будут выполняться путем манипуляций над содержимым поля next существующих элементов списка. Для оптимизации операций над списком иногда создают вспомогательную переменную-структуру (заголовок списка), состоящую из двух полей - указателей на первый и последний элементы списка (рисунок 1.2). Для этих же целей создают двунаправленные списки, элементы которых, помимо поля next, включают поле previous, содержащее указатель на предыдущий элемент списка (рисунок 1.3) и, возможно, ссылки на заголовок списка (рисунок 1.4). 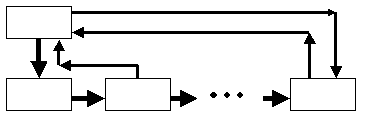 Рис. 1.2. 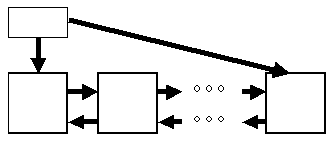 Рис. 1.3.  95. Парадигмы программирования Парадигма программирования — принцип, подход, модель построения програмного проекта, его структурирования и связи его частей. Различают
и другие парадигмы. Приверженность опредленного человека какой-то одной пародигме как правило носит настолько сильный характер, что споры о преимуществах и недостатках различных парадигм относится в компьютерной к разраду, так называемых, религиозных войн. Структурное программирование - методология разработки программного обеспечения, предложенная в 70-х года XX века Дейкстрой и разработанная и дополненная ссылка скрыта. В соответствии с данной методологией любая программа представляет собой структуру, построенную из трёх типов базовых конструкций:
В программе базовые конструкции могут быть вложены друг в друга произвольным образом, но никаких других средств управления последовательностью выполнения операций не предусматривается. Повторяющиеся фрагменты программы (либо не повторяющиеся, но представляющие собой логически целостные вычислительные блоки) могут оформляться в виде так называемых ссылка скрыта (ссылка скрыта или ссылка скрыта). В этом случае в тексте основной программы вместо помещённого в подпрограмму фрагмента вставляется инструкция вызова подпрограммы. При выполнении такой инструкции выполняется вызыванная подпрограмма, после чего исполнение программы продолжается со следующей за командой вызова подпрограммы инструкции. Разработка программы ведётся пошагово, методом "сверху вниз". Сначала пишется текст основной программы, в котором вместо каждого связного логического фрагмента текста вставляется вызов подпрограммы, которая будет выполнять этот фрагмент. Вместо настоящих, работающих подпрограмм, в программу вставляются "затычки", которые ничего не делают. Полученная программа проверяется и отлаживается. После того, как программист убедится, что подпрограммы вызваются в правильной последовательности (то есть общая структура программы верна), подпрограммы-"затычки" последовательно заменяются на реально работающие, причём разработка каждой подпрограммы ведётся тем же методом, что и основной программы. Разработка заканчивается тогда, когда не останется ни одной "затычки", которая не была бы удалена. Такая последовательность гарантирует, что на каждом этапе разработки программист одновременно имеет дело с обозримым и понятным ему множеством фрагментов и может быть уверен, что общая структура всех более высоких уровней программы верна. При сопровождении и внесении изменений в программу выясняется, в какие именно процедуры нужно внести изменения, и они вносятся, не затрагивая непосредственно не связанные с ними части программы. Это позволяет гарантировать, что при внесении изменений и исправлении ошибок не выйдет из строя какая-то часть программы, находящаяся в данный момент вне зоны внимания программиста. ИсторияМетодология структурного программирования появилась как следствие возрастания сложности решаемых на компьютерах задач и соответственного усложнения программного обеспечения. В 70-е годы XX века объёмы и сложность программ достигли такого уровня, что "интуитивная" разработка программ, которая была нормой в более раннее время, перестала удовлетворять потребностям практики. Программы становились слишком сложными, чтобы их можно было нормально сопровождать, поэтому потребовалась какая-то систематизация процесса разработки и структуры программ. Наиболее сильной критике со стороны разработчиков структурного подхода к программирования подвергся оператор GOTO (оператор безусловного перехода), имеющийся почти во всех языках программирования. Использование произвольных переходов в тексте программы приводит к получению запутанных, плохо структурированных программ, по тексту которых практически невозможно понять порядок исполнения и взаимозависимость фрагментов. Следование принципам структурного программирования сделало тексты программ, даже довольно крупных, нормально читаемыми. Серьёзно облегчилось понимание программ, появилась возможность разработки программ в нормальном промышленном режиме, когда программу может без особых затруднений понять не только её автор, но и другие программисты. Это позволило разрабатывать достаточно крупные для того времени программные комплексы силами коллективов разработчиков, и сопровождать эти комплексы в течение многих лет, даже в условиях неизбежной ротации кадров. Методология структурной разработки программного обеспечения была признана "самой сильной формализацией 70-х годов". После этого слово "структурный" стало модным в отрасли, его начали использовать везде, где надо и не надо. Появились работы по "структурному проектированию", "структурному тестированию", "структурному дизайну" и так далее, в общем, произошло примерно то же самое, что происходило в 90-х годах и происходит в настоящее время с терминами "объектный" и "объектно-ориентированный". В программе могут применяться только четыре типа конструкций:
Перечислим некоторые достоинства структурного программирования:
Процедурное программирование — это ссылка скрыта, основанная на концепции вызова процедуры. Процедуры, также известны как ссылка скрыта, методы, или функции (это не математические функции, но функции, подобные тем, которые используются в ссылка скрыта). Процедуры просто содержат последовательность шагов для выполнения. В ходе выполнения программы любая процедура может быть вызвана из любой точки, включая саму данную процедуру. Процедурное программирование — это лучший выбор, чем просто последовательное или неструктурированное программирование во многих ситуациях, которые вызываются умеренной сложностью, или тех, которые требуют значительного упрощения поддержки. Возможные выгоды:
|