
Программное обеспечение вычислительной системы
| Вид материала | Программа |
- «Программное обеспечение вычислительной техники и автоматизированных систем», 1790.14kb.
- Рабочая программа для специальности: 220400 Программное обеспечение вычислительной, 133.96kb.
- М. В. Ломоносова Факультет вычислительной математики и кибернетики Н. В. Вдовикина,, 2124.49kb.
- Рабочая программа по дисциплине "Программирование на языке высокого уровня" для специальности, 137.39kb.
- Рабочая программа по дисциплине "Вычислительная математика" для специальности 230105, 201.66kb.
- Рабочая программа по дисциплине: «Программное обеспечение сетей эвм» Для специальности, 72.13kb.
- Рабочая программа по дисциплине «Информатика» для специальности 230105(220400) «Программное, 259.13kb.
- Рабочая программа по дисциплине Архитектура вычислительных систем Для специальности, 122.63kb.
- С. А. Гайворонский 2010 г. Рабочая программа, 359.3kb.
- С. А. Гайворонский 2010 г. Рабочая программа, 251.55kb.
Почтовые ящики
Тесное взаимодействие между процессами предполагает не только синхронизацию – обмен временными сигналами, но и передачу, и получение произвольных данных – обмен сообщениями. В системе с одним процессором посылающий и принимающий процессы не могут работать одновременно. Следовательно, для хранения посланного, но еще не полученного сообщения необходимо место. Оно называется буфером сообщений или почтовым ящиком. Это информационная структура, поддерживаемая операционной системой. Она состоит из головного элемента, в котором находится информация о данном почтовом ящике, и из нескольких буферов (гнезд), в которые помещают сообщения. Размер каждого буфера их количество обычно задаются при образовании почтового ящика.
Основные достоинства почтовых ящиков:
- процессу не нужно знать о существовании других процессов до тех пор, пока он не получит сообщения от них;
- два процесса могут обмениваться более чем одним сообщением за один раз;
- операционная система может гарантировать, что никакой процесс не вмешается в «беседу» других процессов:
- очереди буферов позволяют процессу-отправителю продолжать работу, обращая внимания на получателя.
Основным недостатком буферизации сообщений является появление еще одного ресурса, которым нужно управлять.
- ^ Конвейеры (программные каналы)
Конвейер (pipe –программный канал, транспортер) является средством, с помощью которого можно производить обмен данными между процессами. Принцип работы конвейера основан на механизме ввода/вывода, который используется с файлами в UNIX – задача, передающая информацию, действует так, как будто она записывает данные в файл, в то время как задача, для которой предназначается эта информация, читает ее из этого файла. Операции записи и чтения осуществляются не записями, как это делается в обычных файлах, а потоком байтов, как это делается в UNIX-системах. Функции, с помощью которых выполняется запись в канал и чтение из него, являются теми же самыми, что и при работе с файлами. На самом деле конвейеры являются не файлами на диске, а представляют собой буферную память, работающую по принципу обычной очереди (FIFO – first input, first output)
Конвейер имеет максимальный размер 64 Кбайт и работает циклически.
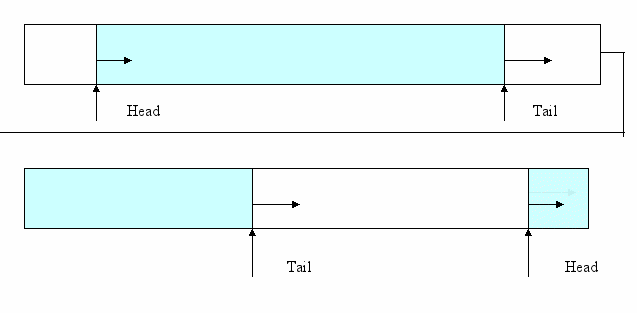


Рис. 2. Организация очереди на массиве.
Имеется некий массив и два указателя, равные нулю в начальный момент:
- один показывает на первый элемент – Head (Голова);
- второй – на последний – Tail (Хвост).
Запись (добавление) одного элемента в пустую очередь делает оба указателя, равными единице. В последующем при добавлении нового элемента увеличивается указатель Tail. Чтение (удаление) элемента производится, начиная с первого элемента созданной очереди. При этом, следовательно, будет увеличиваться указатель Head. Таким образом, в результате операций записи и чтения указатели будут перемещаться от начала массива к его концу. При достижении указателем значения индекса последнего элемента, значение указателя вновь становится равным единице. Массив как бы замыкается в кольцо, организуя круговое перемещение указателей. Сказанное проиллюстрировано на рис. 2.
Конвейеры представляют системный ресурс. Чтобы начать работу с конвейером, процесс должен заказать его у операционной системы и получить в свое распоряжение. Процессы, знающие идентификатор конвейера, могут через него обмениваться данными.
- ^ Очереди сообщений
Очереди сообщений (queue) являются более сложным методом связи между взаимодействующими процессами по сравнению с каналами. С помощью очередей также можно из одной или нескольких задач независимым образом посылать сообщения некоторой задаче-приемнику. При этом только процесс-приемник может читать и удалять сообщения из очереди, а процессы-клиенты имеют право лишь помещать в очередь свои сообщения. Таким образом, очередь работает в одном направлении. Если необходима двухсторонняя связь, то можно создать две очереди.
Отличия работы с очередями от работы с конвейерами:
- очереди предоставляют возможность использовать несколько дисциплин обработки сообщений:
- FIFO – сообщение, записанное первым, будет первым и прочитано;
- LIFO – сообщение, записанное последним, будет прочитано первым:
- приоритетный – сообщения читаются с учетом их приоритета;
- произвольный доступ, т.е. можно читать любое сообщение, тогда как конвейер обеспечивает только дисциплину FIFO.
- при чтении сообщения из конвейера оно из него удаляется. При чтении из очереди этого не происходит, сообщение при желании может быть прочитано несколько раз;
- в очередях присутствуют не непосредственно сами сообщения, а только их адреса в памяти и размер.
Каждый процесс, использующий очередь, должен предварительно получить разрешение на использование общего сегмента памяти с помощью системных запросов API (application program interface).
^ Проблема тупиков и методы борьбы с ними
При организации параллельного выполнения нескольких процессов одной из главных функций ОС является решение сложной задачи корректного распределения ресурсов между выполняющимися процессами и обеспечение последних средствами взаимной синхронизации и обмена данными.
При параллельном исполнении процессов могут возникать ситуации, при которых два или более процессов все время находятся в заблокированном состоянии. Самым простым является случай, когда каждый из двух процессов ожидает ресурс, занятый другим процессом. Эта тупиковая ситуация называется дедлоком (dead lock –смертельное объятие), тупиком или клинчем. Тупики чаще всего возникают из-за конкуренции несвязанных параллельных процессов за ресурсы вычислительной системы, но иногда к тупикам приводят и ошибки программирования.
Рассмотрим пример, поясняющий причину возникновения тупиков.
Пусть имеются три процесса ПР1, ПР2, ПР3, которые вырабатывают соответственно сообщения М1, М2, М3. Пусть процесс ПР1 является «потребителем» сообщения М3, процесс ПР2 получает сообщение М1, а ПР3 – сообщение М2 от процесса ПР2, то есть каждый из процессов является и «поставщиком» и «потребителем» одновременно и вместе они образуют «кольцевую» систему передачи сообщений через почтовые ящики (ПЯ) – рис.1.
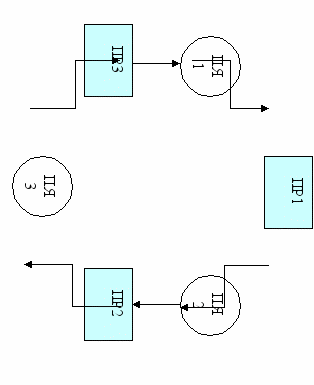
Рис.1. Кольцевая схема взаимодействия процессов
Если процедуры в каждом процессе выполняются в следующем порядке:
ПР1: …
Послать сообщение (ПР2, М1, ПЯ2);
Ждать сообщение (ПР3, М3, ПЯ1);
…
ПР2: …
Послать сообщение (ПР3, М2, ПЯ3);
Ждать сообщение (ПР1, М1, ПЯ2);
…
ПР3: …
Послать сообщение (ПР1, М3, ПЯ1);
Ждать сообщение (ПР2, М2, ПЯ3);
…,
то никаких трудностей не возникает. Однако перестановка этих двух процедур в каждом из процессов (Ждать….;Послать….;) вызывает тупик. В самом деле, в этом случае ни один из процессов не может послать сообщения до тех пор, пока сам его не получит, а этого события никогда не произойдет, поскольку ни один процесс не может этого сделать.
Проблема борьбы с тупиками становится все более актуальной и сложной по мере развития и внедрения параллельных систем. Борьба с тупиковыми ситуациями основывается на одной из трех стратегий:
- предотвращение тупика;
- обход тупика;
- распознавание тупика с последующим восстановлением.
Предотвращение тупиков
Предотвращение тупика основывается на предположении о чрезвычайно высокой его стоимости, поэтому лучше потратить дополнительные ресурсы системы, чтобы исключить вероятность возникновения тупика при любых обстоятельствах. Этот подход используется в наиболее ответственных системах, часто это системы реального времени.
Для того чтобы возник тупик необходимо, чтобы одновременно выполнялись следующие условия:
- ^ Взаимного исключения – процессы осуществляют монопольный доступ к ресурсам;
- Ожидания – процесс, запросивший ресурс, будет ждать, пока запрос не будет удовлетворен, продолжая удерживать все остальные ресурсы, которые он уже получил;
- Отсутствия перераспределения – никакие ресурсы нельзя отобрать у процесса, если они ему уже выделены;
- ^ Кругового ожидания – существует замкнутая цепь процессов, каждый из которых ждет ресурс, удерживаемый его предшественником в этой цепи.
Дисциплина, предотвращающая тупик просто должна гарантировать, что ни одно из четырех условий, необходимых для его наступления, не может возникнуть.
^ Условие взаимного исключения можно подавить путем разрешения неограниченного распределения ресурсов. Это совершенно неприемлемо к совместно используемым переменным в критических интервалах.
^ Условие ожидания можно подавить, предварительно выделяя ресурсы. При этом процесс может начать исполнение, только получив все необходимые ресурсы. Это может привести к снижению эффективности работы вычислительной системы в целом. Кроме того, это сделать зачастую невозможно, так как необходимые ресурсы становятся известны процессу только после начала исполнения.
^ Условие отсутствия перераспределения можно исключить, позволяя ОС отнимать у процесса ресурсы. Перераспределение процессора реализуется достаточно легко, в то время как перераспределение устройств ввода/вывода крайне нежелательно.
^ Условие кругового ожидания можно исключить, предотвращая образование цепи запросов. Это можно обеспечить с помощью принципа иерархического выделения ресурсов, если порядок использования ресурсов является иерархическим.
В целом стратегия предотвращения тупиков – это очень дорогое решение проблемы, и она используется нечасто.
^ Обход тупиков
Это можно интерпретировать как запрет входа в опасное состояние. Если ни одно из 4-х условий не исключено, то вход в опасное состояние можно все же предотвратить при наличии у системы информации о последовательности запросов, связанных с каждым параллельным процессом. Достаточно проверить, не приведет ли выделение затребованного ресурса к опасному состоянию. Если да, то запрос отклоняется. Если нет, то запрос выполняется. Проверка того, является ли состояние опасным или нет, требует анализа последующих запросов процессов. Существуют методы эффективного выполнения такого просмотра.
^ Распознавание тупика
За счет различных дорогостоящих вычислений можно установить, существуют ли процессы, находящиеся в состоянии тупика. Чтобы выполнить эти вычисления, ОС должна вести список тех ресурсов, которые ждет каждый заблокированный процесс, и список тех процессов, которые держат каждый недоступный ресурс. Алгоритм распознавания замкнутых цепей можно выполнять с любой нужной частотой. Как только тупик выявлен, должно быть выполнено восстановление. Существуют следующие методы восстановления:
- Самый простой – это принудительное завершение всех процессов и запуск ОС заново;
- Менее радикальный – принудительное завершение всех процессов, находящихся в тупике. В этом случае пользователи могут ввести их когда-нибудь снова;
- Принудительное завершение процессов, находящихся в тупике, по одному и после каждого завершения вызов алгоритма выявления тупика до тех пор, пока тупик не исчезнет;
- Запуск процессов, находящихся в тупике, со своих контрольных точек в предположении, что тупик больше не возникнет. Естественно, для этого должны быть контрольные точки;
- Перераспределение ресурсов одного или нескольких процессов, среди которых могут быть даже такие, которые не находятся в тупике. Ресурсы назначаются одному из оставшихся процессов, находящихся в тупике, и он возобновляет исполнение;
- Теоретически применим, если в момент, когда тупик выявлен, существует несколько пользовательских процессов, которые не находятся в тупике. Если этим процессам позволить доработать до конца и запретить образование новых процессов, то они могут освободить достаточно ресурсов, чтобы тупик исчез.
Стоимость стратегии распознавания тупика зависит от того, насколько часто выполняется алгоритм распознавания. Основная цена восстановления от тупика – это потери времени, которые могут быть существенными.
^ Современные операционные системы
На ПК типа IBM PC наиболее популярными являются ОС семейства Windows компании Microsoft. Это и Windows 95/98, и Windows NT, и Windows 2000, и Windows XP. Но, кроме этих ОС, на ПК используются ОС Unix, Linux, OS/2, QNX.
Изучая теорию ОС и работая на ПК, мы фактически познакомились с OC семейства Windows. Поэтому не будем отдельно описывать эти ОС.
Рассмотрим же кратко ОС UNIX, которая является примером исключительно удачной реализацией простой мультипрограммной и многопользовательской ОС.
^ Семейство операционных систем UNIX
UNIX проектировалась как инструментальная система для разработки программного обеспечения. Была создана по сути, двумя разработчиками (Кен Томпсон и Денис Ритчи) для себя и написана на языке С.
Unix-системы уже существуют 30 лет и сейчас поставляются с большим набором системных и прикладных программ, включающим редакторы текстов, программируемые интерпретаторы командного языка, компиляторы с нескольких популярных языков программирования, отладчики, многочисленные библиотеки системных и пользовательских программ, средства сортировки и ведения баз данных, многочисленные административные и обслуживающие программы.
- ^ Основные понятия системы UNIX
Система UNIX – многопользовательская. Каждому пользователю после регистрации предоставляется виртуальный компьютер, в котором есть все необходимые ресурсы: процессор (процессорное время выделяется на основе «карусельной» диспетчеризации – RR и с использованием динамических приоритетов), память, устройства, файлы. Текущее состояние такого виртуального компьютера называется образ. Образ состоит из:
- образа памяти;
- значений общих регистров процессора;
- состояния открытых файлов;
- текущего директория (каталога файлов) и другой информации.
Образ процесса во время его выполнения размещается в основной памяти.
Образ памяти делится на три логических сегмента:
- сегмент реентерабельных процедур – начинается с нулевого адреса в виртуальном адресном пространстве процесса;
- сегмент данных – располагается сразу за сегментом процедур;
- сегмент стека – начинается со старших адресов и растет в сторону младших.
Чтобы войти в систему пользователь должен со свободного терминала ввести свое учетное имя (account name) и, возможно, пароль (password). Каждый зарегистрированный пользователь получает неограниченный доступ к своему домашнему (home) каталогу.
Традиционный способ взаимодействия пользователя с системой UNIX – использование командных языков. Но сейчас работают все чаще с графическим интерфейсом X Window. Общее название для любого командного интерпретатора ОС UNIX – shell (оболочка). Вызванный командный интерпретатор выдает приглашение на ввод пользователем командной строки, которая может содержать простую команду, конвейер команд или последовательность команд.
Оболочкой (shell) называют механизм взаимодействия между пользователем и системой. Любой командный язык семейства shell состоит из трех частей:
- служебных инструкций;
- встроенных команд, выполняемых интерпретатором командного языка;
- команд, представляемых отдельными выполняемыми файлами.
Процессы в ОС UNIX понимаются в классическом смысле этого термина, т.е. как программа, выполняемая в собственном виртуальном адресном пространстве. Когда пользователь входит в систему, автоматически создается процесс. Для создания нового процесса и запуска в нем программы используются два системных вызова API – fork() и exec(имя_выполняемого_файла). Каждый процесс, за исключением нулевого, порождается в результате запуска другим процессом операции fork(). Каждый процесс имеет одного родителя, но может породить много процессов. Процесс с идентификатором 1, известный под именем unit является предком любого другого процесса в системе и связан с каждым процессом особым образом.
- ^ Функционирование системы UNIX
Процесс может выполняться в одном из двух состояний: пользовательском (выполняет пользовательскую программу) и системном (выполняет программы ядра и имеет доступ к системному сегменту данных).
Когда пользовательскому процессу требуется выполнить системную функцию, он создает системный вызов. Фактически происходит вызов ядра системы как подпрограммы. С этого момента процесс считается системным.
В UNIX- системах используется разделение времени, т.е. каждому процессу выделяется квант времени. Процессам, которые получили большое количество процессорного времени, назначают более низкие приоритеты, а процессам с небольшим процессорным временем – повышают приоритет. Все системные процессы имеют более высокие приоритеты по сравнению с пользовательскими процессами.
Функции ввода/вывода задаются в основном с помощью пяти системных вызовов:
- open – открыть файл;
- close – закрыть файл;
- read – чтение;
- write – запись;
- seek – операция поиска.
Механизм перенаправления ввода/вывода является одним из наиболее элегантных, мощных и одновременно простых механизмов OC UNIX.
Реализация этого механизма основывается на следующих свойствах OC UNIX:
- любой ввод/вывод трактуется как ввод из некоторого файла и вывод в некоторый файл;
- клавиатура и экран также интерпретируются как файлы (первый можно только читать, а во второй – только писать);
- доступ к любому файлу производится через его дескриптор (положительное целое число). Файл с дескриптором 1 – файл стандартного ввода (stdin), 2 – файл стандартного вывода (stdout) и 3 – файл стандартного вывода диагностического сообщения (stderr);
- программа, запущенная в некотором процессе, «наследует» от породившего процесса все дескрипторы открытых файлов.
Файлом стандартного ввода является клавиатура, а файлом стандартного вывода и вывода диагностических сообщений – экран. Однако при запуске любой команды можно сообщить какой файл или вывод какой программы должен служить соответствующим файлом. Тогда интерпретатор перед выполнением системного вызова exec открывает указанные файлы, подменяя смысл дескрипторов 1, 2, 3.
Функция printf неявно использует stdout, функция scan – stdin, функция error – stderr. Т.е. указывать дескриптор при использовании этих функций не надо.
- ^ Файловая система
Файл в UNIX представляет собой множество символов с произвольным доступом. Рассмотрим организацию файлов на диске.
Информация на диске размещается поблочно, по 512 байт в каждом блоке. Диск разбивается на области (см. рис.1):
- неиспользуемый блок;
- управляющий блок (суперблок), в котором содержится размер диска и границы других областей;
- i-ый список, состоящий из описаний файлов, называемых i-узлами;
- область для хранения содержимого файлов.
Каждый i-ый узел содержит:
- идентификацию владельца;
- идентификацию группы владельца;
- биты защиты;
- физические адреса на диске, где находится содержимое файла;
- размер файла;
- время создания файла;
- время последнего использования файла;
- время последнего изменения атрибутов;
- число связей-ссылок, указывающих на файл;
- индикацию, является ли файл директорией, обычным файлом или специальным файлом.
Следом за i-м списком идут блоки, предназначенные для хранения содержимого файлов. Пространство, оставшееся свободным от файлов, образует связанный список свободных блоков.
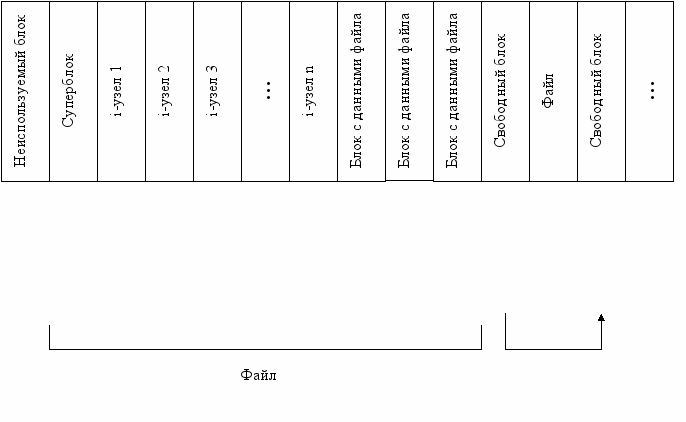
Рис.1. Организация файлов в UNIX на диске.
Каждый файл однозначно идентифицируется:
- старшим номером устройства (определяет массив входных точек в драйверы):
- младшим номером устройства (для выбора устройства из группы идентичных физических устройств):
- i-м номером ( индекс i-узла данного файла в массиве i-узлов).
- Межпроцессорные коммуникации
Для построения программных систем, работающих по принципам модели «клиент-сервер» в UNIX существуют следующие механизмы:
- сигналы;
- семафоры;
- программные каналы;
- очереди сообщений;
- сегменты разделяемой памяти;
- вызовы удаленных процедур.
Многие из этих механизмов уже нам знакомы. Рассматривать их не будем.