
Программное обеспечение вычислительной системы
| Вид материала | Программа |
- «Программное обеспечение вычислительной техники и автоматизированных систем», 1790.14kb.
- Рабочая программа для специальности: 220400 Программное обеспечение вычислительной, 133.96kb.
- М. В. Ломоносова Факультет вычислительной математики и кибернетики Н. В. Вдовикина,, 2124.49kb.
- Рабочая программа по дисциплине "Программирование на языке высокого уровня" для специальности, 137.39kb.
- Рабочая программа по дисциплине "Вычислительная математика" для специальности 230105, 201.66kb.
- Рабочая программа по дисциплине: «Программное обеспечение сетей эвм» Для специальности, 72.13kb.
- Рабочая программа по дисциплине «Информатика» для специальности 230105(220400) «Программное, 259.13kb.
- Рабочая программа по дисциплине Архитектура вычислительных систем Для специальности, 122.63kb.
- С. А. Гайворонский 2010 г. Рабочая программа, 359.3kb.
- С. А. Гайворонский 2010 г. Рабочая программа, 251.55kb.
Рис.1. Дескриптор сегмента
При переключении микропроцессора в защищенный режим он начинает совершенно другим образом, чем в реальном режиме, вычислять физические адреса команд и операндов. Прежде всего, содержимое сегментных регистров интерпретируется иначе: считается, что там содержится не адрес начала сегмента, а номер соответствующего сегмента. Каждый сегментный регистр (в этом случае его называют селектор сегмента) разбивается на три поля:
- поле индекса ─ старшие 13 битов (3-15). Определяют номер сегмента:
- поле индикатора таблицы сегмента ─ бит с номером 2. Определяет часть виртуального адресного пространства.
- поле уровня привилегий ─ биты 0 и 1. Указывает запрашиваемый уровень привилегий.
Страничная организация виртуальной памяти состоит в том, что все фрагменты программы, на которые она разбивается произвольным образом, имеют одинаковую длину. Эти одинаковы части называют страницами и говорят, что память разбивается на физические страницы, а программа ─ на виртуальные страницы. Часть виртуальных страниц задачи размещается в оперативной памяти, а часть ─ во внешней. Величина страницы выбирается кратной степени двойки. Таким образом, вместо одномерного адресного пространства можно говорить о двумерном. Первая координата адресного пространства ─ это номер страницы, а вторая ─ номер ячейки внутри выбранной страницы (его называют индексом). Таким образом, физический адрес определяется парой (Pp,i), а виртуальный адрес ─ парой (Pν,i), где Pν ─ номер виртуальной страницы, Pp ─ номер физической страницы, i ─ индекс ячейки внутри страницы. Количество битов, отводимое под индекс, определяет размер страницы, а количество битов, отводимое под номер виртуальной страницы ─ объем возможной виртуальной памяти, которой может воспользоваться программа. При это нет необходимости ограничивать число виртуальных страниц числом физических, то есть не поместившиеся страницы можно размещать во внешней памяти, которая в этом случае служит расширением оперативной. Для отображения виртуального адресного пространства задачи на физическую память для каждой задачи, как и в случае сегментного способа, необходимо иметь таблицу страниц для трансляции адресных пространств. Для описания каждой страницы диспетчер памяти ОС заводит соответствующий дескриптор.
В микропроцессорах i80х86 размер страницы равен 212=4096=4Кбайт, а поле номера страницы, имеющей размер 20 битов, разбивается на два поля и осуществляется двухшаговая страничная трансляция. Для описания каждой страницы создается соответствующий 32-битовый дескриптор. Это дает возможность адресоваться к любому байту из 232, а шина адреса как раз и позволяет использовать физическую память с таким объемом. Так что можно отказаться от сегментного способа адресации. Т.е. можно считать, что задача состоит из одного сегмента, который разбит на страницы. Такой подход получил название «плоская память». При использовании плоской памяти упрощается создание ОС и систем программирования. Поэтому в большинстве 32-разрядных ОС для микропроцессоров i80х86 используется плоская модель памяти.
- ^ Система прерываний 32-разрядных микропроцессоров i80х86
В реальном режиме работы система прерываний работает так же, как и для 16-разрядного микропроцессора i8086/8088. Имеется 16 линий запросов на прерывания (IRQ – Interrupt ReQuest), реализуемых с помощью двух контроллеров прерываний i8259A, соединенных каскадным образом.
Линии IRQ:
1 – контроллер клавиатуры;
- 3 – COM2;
- 4 – COM1;
- 6 – контроллер FDD;
- 8 – часы реального времени с автономным питанием;
- 12 – контроллер мыши типа PS/2;
- 13 – математический сопроцессор;
- 14 – контроллер IDE (первый канал);
- 15 – контроллер IDE (второй канал);
- 16 – Intel (R) 82801DB/DBM USB Universal Host Controller – 24C2 ;
- 17 – SoundMax Integrated Digital Audio;
- 18 – Intel (R) 82801DB/DBM USB Universal Host Controller – 24C7;
- 19 – Intel (R) 82801DB/DBM USB Universal Host Controller – 24C4;
- 20 – ASUSTeK/Broadcom 440x10/100 Int…
- 22 – Microsoft ASPI – Compliant System
- 23 – Intel PCI to USB enhanced Host Controller
В защищенном режиме система прерываний действует совершенно иначе. Вместо таблицы векторов используется таблица дескрипторов прерываний IDT. Здесь хранятся не адреса обработчиков прерываний ISR, а специальные системные структуры данных, доступ к которым пользовательским программам запрещен. Каждый элемент в таблице дескрипторов прерываний имеет 8-байтовую структуру и может принадлежать к одному из трех типов:
- Коммутатор прерывания;
- Коммутатор перехвата;
- Коммутатор задачи.
При обнаружении запроса на прерывание и при условии, что прерывания сейчас разрешены, процессор действует в зависимости от типа дескриптора, соответствующего номеру прерывания. Первые два типа дескриптора прерываний вызывают переход на соответствующие сегменты кода, принадлежащие виртуальному адресному пространству текущего вычислительного процесса. Последний тип дескриптора вызывает полное переключение процессора на новую задачу.
Рассмотрим обработку прерываний в контексте текущей задачи. После анализа дескриптора процессор выполняет следующие действия:
- В стек на уровне привилегий текущего сегмента кода помещаются:
- значения SS и SP, если уровень привилегий в коммутаторе выше уровня привилегий ранее исполнявшегося кода;
- регистр флагов EFLAGS;
- регистры CS и IP.
- Если тип дескриптора – коммутатор прерывания, то другие прерывания запрещаются, если – коммутатор перехвата, новые прерывания на период обработки текущего прерывания не запрещаются;
- Поле селектора из дескриптора прерываний используется для индексирования таблицы дескрипторов задачи. Дескриптор сегмента заносится в теневой регистр, а смещение относительно начала нового сегмента определяется полем смещения из дескриптора прерывания.
Совершенно иначе обрабатываются прерывания, если дескриптор является коммутатором задачи. В этом случае происходит полное переключение на новую задачу, при этом сохраняются все регистры процессора.
В основном обработку прерываний осуществляют в контексте текущей задачи, так как это повышает быстродействие системы
^ Управление задачами в операционных системах
Время центрального процессора и оперативная память являются основными ресурсами при реализации мультипрограммных вычислений.
Операционная система выполняет следующие основные функции, связанные с управлением задачами:
- Создание и удаление задачи;
- Планирование процессов и диспетчеризация задач;
- Синхронизация задач, обеспечение их средствами коммуникации.
Система управления задачами обеспечивает прохождение их через компьютер. Создание и удаление задач осуществляется по соответствующим запросам от пользователей или от самих задач. Задача может породить новую задачу. Основным подходом к организации того или иного метода управления процессами является организация очередей и ресурсов.
На распределение ресурсов влияют конкретные потребности тех задач, которые должны выполняться параллельно. Можно столкнуться с ситуациями, когда невозможно эффективно распределять ресурсы с тем, чтобы они не простаивали. Например, устройство с последовательным доступом не может распределяться между параллельно выполняющимися процессами. Если же мы возьмем набор таких процессов, которые не будут конкурировать между собой за неразделяемые ресурсы при параллельном выполнении, то процессы смогут выполниться быстрее. Таким образом, возникает задача подбора такого множества процессов, что при выполнении они будут как можно реже конфликтовать из-за имеющихся в системе ресурсов. Такая задача называется планированием вычислительных процессов.
В настоящее время на первый план вышли задачи динамического (краткосрочного) планирования, т.е. текущего наиболее эффективного распределения ресурсов, возникающего практически при каждом событии. Задачи динамического планирования называют диспетчеризацией.
Долгосрочный планировщик решает, какой из процессов, стоящий во входной очереди, должен быть переведен в очередь готовых процессов в случае освобождения ресурсов памяти. Краткосрочный планировщик решает, какая из задач, находящихся в очереди готовых к выполнению, должна быть предана на исполнение. В большинстве современных ОС долгосрочный планировщик отсутствует.
^ Планирование процессов и диспетчеризация задач
- Стратегии планирования (диспетчеризации)
Стратегия планирования определяет, какие процессы планируются на выполнение, чтобы достичь поставленной цели. Существует много стратегий, можно назвать некоторые из них:
- по возможности заканчивать вычислительные процессы в том же самом
порядке, в котором они были начаты;
- отдавать предпочтение более коротким процессам;
- предоставлять всем процессам пользователей одинаковые услуги, в том
числе и одинаковое время ожидания.
Когда говорят о стратегии обслуживания, всегда имеют в виду понятие процесса, поскольку процесс может состоять из нескольких задач.
- ^ Дисциплины диспетчеризации
Известно большое количество правил (дисциплин) диспетчеризации, в соответствии с которыми формируется список (очередь) готовых к выполнению задач. Различают два больших класса таких дисциплин – бесприоритетные и приоритетные. При реализации приоритетных дисциплин отдельным задачам предоставляется преимущественное право попасть в состояние исполнения.
Рассмотрим кратко некоторые наиболее часто используемые дисциплины диспетчеризации.
Самой простой в реализации является дисциплина FCFS (first come – first served), согласно которой задачи обслуживаются в порядке очереди, т.е. в порядке их появления. Те задачи, которые были заблокированы в процессе работы, после перехода в состояние готовности ставятся в эту очередь перед теми задачами, которые еще не выполнялись, т.е. образуется две очереди – одна из новых задач, а вторая очередь – из ранее выполнявшихся, но попавших в состояние ожидания. Такой подход позволяет реализовать стратегию обслуживания «по возможности заканчивать вычислительные процессы в порядке их появления».
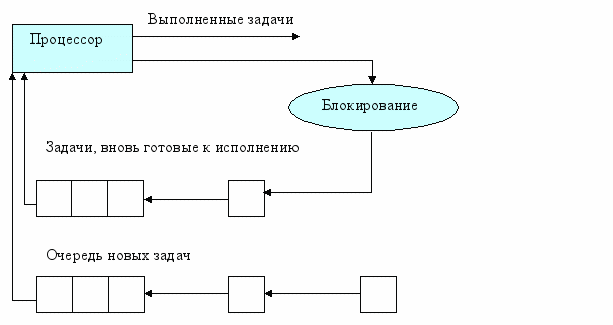
Рис.1. Дисциплина FCFS
К достоинствам этой дисциплины можно отнести простоту реализации и малые расходы системных ресурсов на формирование очереди задач.
Но она приводит к тому, что при увеличении загрузки вычислительной системы растет и среднее время ожидания обслуживания, причем короткие задания вынуждены ожидать столько же, сколько и трудоемкие задания. Избежать этого недостатка позволяют дисциплины SJN и SRT.
Дисциплина обслуживания SJN (shortest job next – следующим будет выполняться кратчайшее задание) требует, чтобы для каждого задания была известна оценка в потребностях машинного времени. Для этого были разработаны специальные языковые средства, например, язык JCL (job control language – язык управления заданиями). Пользователи должны были указывать предполагаемое время выполнения, а чтобы они не ловчили, ввели подсчет реальных потребностей. Если обнаруживался обман, то задание ставилось в конец очереди или оплата шла по более высоким тарифам.
Дисциплина обслуживания SJN предполагает, что имеется только одна очередь заданий, готовых к выполнению. И задания, которые в процессе своего выполнения были временно заблокированы, вновь попадают в конец очереди. Это приводит к тому, что задания, которым требуется очень немного времени для завершения, ожидают процессор наравне с длительными работами.
Для устранения этого недостатка была предложена дисциплина SRT (shortest remaining time) – следующее задание требует меньше всего времени для своего завершения.
Все эти три дисциплины могут использоваться для пакетных режимов обработки, когда пользователь сдает свое задание, не ожидает реакции системы, а ему нужен только результат вычислений. Для интерактивных вычислений желательно обеспечить приемлемое время реакции системы и равенство в обслуживании, если система является мультитерминальной. Для однопользовательских систем с возможностью мультипрограммной обработки желательно, чтобы программы, с которыми работают непосредственно, имели лучшее время реакции, чем фоновые задания. Для решения подобных проблем используется дисциплина обслуживания RR (round robin – круговая, карусельная) и приоритетные методы обслуживания.
Дисциплина RR предполагает, что каждая задача получает процессорное время порциями (квантами времени q). После окончания кванта времени q задача снимается с процессора, и он передается следующей задаче. Снятая задача ставится в конец очереди задач, готовых к исполнению. Для оптимальной работы системы необходимо правильно выбрать закон, по которому кванты времени выделяются задачам.
Величина кванта времени q выбирается как компромисс между приемлемым временем реакции системы на запросы пользователей и накладными расходами на частую смену контекста задачи (надо запоминать много информации для прерываний).
Дисциплина RR – это одна из самых распространенных дисциплин диспетчеризации. В своей простейшей реализации на предполагает, что все задачи имеют одинаковый приоритет. Для введения приоритетного обслуживания вводят несколько очередей. Процессорное время будет предоставляться в первую очередь тем задачам, которые стоят в самой привилегированной очереди. Если она пустая, то диспетчер задач начнет просматривать остальные очереди. По такому алгоритму действует диспетчер задач в Windows NT.
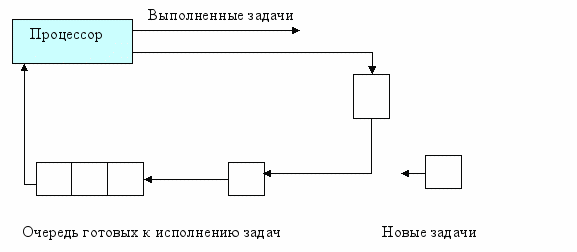
Рис.2. Дисциплина RR
Диспетчеризация без перераспределения процессорного времени, т.е. не вытесняющая многозадачность – это такой способ диспетчеризации процессов, при котором активный процесс выполняется до тех пор, пока он сам не отдаст управление диспетчеру задач. Дисциплины FCFS, SJN, SRT относятся к не вытесняющим.
Диспетчеризация с перераспределением процессорного времени между задачами, т.е. вытесняющая многозадачность – это такой способ, при котором решение о переключении с одного процесса на другой принимается диспетчером задач, а не самой активной задачей. Дисциплина RR относится к вытесняющим.
Для сравнения алгоритмов диспетчеризации обычно используют следующие критерии:
- использование (загрузка) CPU – центрального процессора;
- пропускная способность CPU – количество процессов, выполняющихся в
единицу времени;
- время оборота – интервал от момента появления процесса во входной
очереди до момента его завершения;
- время ожидания – суммарное время нахождения в очереди готовых
процессов;
- время отклика – время, прошедшее от момента попадания во входнуюъ
очередь до момента первого обращения к терминалу. Является важным для
интерактивных программ.
Правильное планирование сильно влияет на производительность всей системы.
- ^ Диспетчеризация задач с использованием динамических приоритетов
Во многих ОС, а в ОС реального времени обязательно, имеются средства для изменения приоритета программ. Введение механизмов динамического изменения приоритетов позволяет реализовать более быструю реакцию системы на короткие запросы пользователей, что очень важно при интерактивной работе, но при этом гарантировать выполнение любых запросов.
Например, в Windows NT каждый поток (задача) имеет базовый уровень приоритета, который лежит в диапазоне от двух уровней ниже базового приоритета процесса, его породившего, до двух уровней выше этого приоритета. Поток наследует этот базовый приоритет и может изменять его так, чтобы он стал немного меньше или немного больше. В результате получается приоритет планирования, с которым поток и начинает исполняться. Например, если поток обрабатывает пользовательский ввод, то диспетчер задач Windows NT поднимает его динамический приоритет, если он выполняет вычисления, то диспетчер постепенно снижает его приоритет до базового. Таким образом производится управление относительной приоритетностью потоков внутри процесса.
1

 5
514 Диапазон значений
13 динамического
12 приоритета потока
11
10
9
8
7

 6 Базовый приоритет
6 Базовый приоритет 5 потока
 4 Базовый приоритет
4 Базовый приоритет 3 процесса
 2
21
Рис.3. Схема динамического изменения приоритетов в Windows NT
Для определения порядка выполнения потоков диспетчер использует систему приоритетов, направляя на выполнение потоки с высоким приоритетом раньше потоков с низкими приоритетами.
Существует группа очередей – по одной для каждого приоритета. Windows NT поддерживает 32 уровня приоритетов; потоки делятся на два класса: реального времени и переменного приоритета. Потоки реального времени, имеющие приоритеты от 16 до 31, используются программами с критическим временем выполнения. Большинство потоков в системе относятся к классу переменного приоритета с уровнями приоритета от 1 до 15. Для собственно системных модулей, функционирующих в статусе задач, зарезервирован приоритет с номером 0.
Управление памятью в операционных системах
- Память и отображение, виртуальное адресное пространство
В настоящее время программист обращается к памяти с помощью некоторого набора логических имен, для которых отсутствует отношение порядка (в общем случае множество переменных неупорядочено). Имена переменных и входных точек программных модулей составляют пространство имен. С другой стороны, существует понятие физической памяти, с которой работает процессор, извлекая из нее команды и помещая в нее результаты вычислений. Физическая память – это упорядоченное множество пронумерованных ячеек. К каждой из них можно обратиться, указав ее номер (адрес). Количество ячеек физической памяти ограниченно и фиксировано.
Системное программное обеспечение должно связать каждое указанное пользователем имя с физической ячейкой памяти, т.е. осуществить отображение пространства имен на физическую память компьютера.
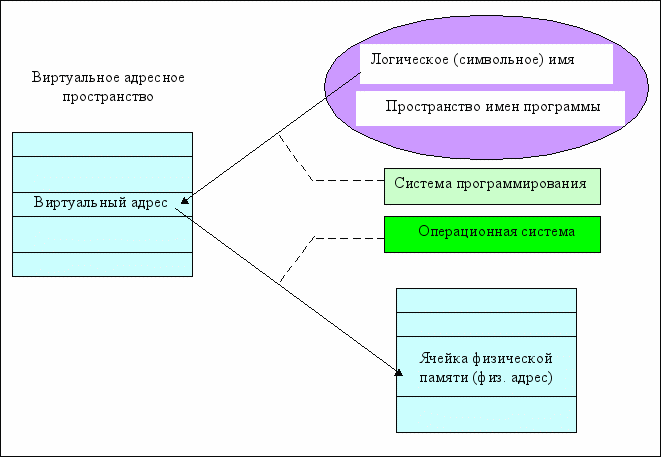
Рис. 1. Память и отображение
В общем случае это делается в два этапа (см. рис.1): сначала системой программирования, а затем операционной системой. Между этими этапами обращения к памяти имеют форму виртуального или логического адреса. Множество всех допустимых значений виртуального адреса для некоторой программы определяет ее виртуальное адресное пространство или виртуальную память.
Система программирования осуществляет трансляцию и компоновку программы и производит привязку основной части виртуальных адресов программы к физическим ячейкам (первое отображение), а окончательная привязка делается операционной системой на этапе загрузки программы в память для ее исполнения (второе отображение).
Возможны частные случаи отображения пространства имен на физическую память:
- тождественность виртуального адресного пространства физической памяти. Здесь нет необходимости осуществлять второе отображение. Система программирования генерирует абсолютно двоичную программу (адреса физические);
- тождественность виртуального адресного пространства исходному пространству имен. Здесь отображение осуществляется самой операционной системой, путем использования таблицы символьных имен.
В настоящее время даже на ПК объем виртуальной памяти больше объема физической памяти. Имеется несколько методов распределения памяти для этой ситуации.
- ^ Простое непрерывное распределение и распределение с перекрытием
Простое непрерывное распределение – это самое простая схема, при которой вся память условно разделена на три части:
- область, занимаемая операционной системой:
- область, в которой размещается исполняемая задача;
- свободная область памяти.
Эта схема предполагает, что ОС не поддерживает мультипрограммирование. Область памяти, отводимая под задачу, является непрерывной, что облегчает работу системе программирования.
Чтобы для задач отвести как можно больший объем памяти, ОС строится таким образом, что постоянно в оперативной памяти располагается самая нужная ее часть (ядро). Остальные модули ОС могут быть диск-резидентными, т.е. загружаются в память по необходимости, а после своего выполнения вновь освобождают память.
Такая схема распределения несет два вида потерь вычислительных ресурсов – потеря процессорного времени (процессор простаивает, ожидая завершения операций ввода-вывода) и потеря самой оперативной памяти, т.к. не каждая программа использует всю память, а режим работы в этом случае однопрограммный.
Если есть необходимость создать программу, логическое адресное пространство которой должно быть больше, чем свободная область памяти, то используется распределение с перекрытием (оверлейные структуры). При этом программа разбивается на сегменты. Каждая оверлейная программа имеет одну главную часть (main) и несколько сегментов (segment), причем в памяти одновременно могут находиться только ее главная часть и один или несколько не перекрывающих сегментов. Пока в оперативной памяти располагаются выполняющиеся сегменты, остальные находятся во внешней памяти.
Первоначально программисты сами должны были включать в тексты своих программ обращения к ОС для вызова сегментов и тщательно планировать, какие сегменты одновременно могут находиться в оперативной памяти. Сейчас, например, в Turbo Pascal достаточно указать, что данный модуль оверлейный и все обращения к ОС для загрузки оверлеев генерируются самой системой программирования.