
Учебное пособие по курсу «Технология программирования»
| Вид материала | Учебное пособие |
Содержание4. Блок-схемы и алгоритмы, программы и подпрограммы. Как всё это выглядит на языках программирования. |
- Курсовой проект по курсу «Технология программирования», 147.33kb.
- Учебное пособие для студентов специальности 260202 «Технология хлеба, кондитерских, 1941.61kb.
- О. М. Мышалова общая технология мясной отрасли учебное пособие, 1355.07kb.
- Учебное пособие Иркутск 2006 Рецензент, 2159.1kb.
- Учебное пособие Иркутск 2006 Рецензент, 2160.36kb.
- Учебное пособие Кемерово 2004 удк, 1366.77kb.
- Учебное пособие Тамбов 2009 удк 339. 138, 1882.57kb.
- А. Ю. Просеков С. Ю. Юрьева технология молочных продуктов детского питания учебное, 4980.6kb.
- А. Н. Петров А. Г. Галстян А. Ю. Просеков С. Ю. Юрьева технология продуктов детского, 2728.08kb.
- Учебное пособие Йошкар-Ола, 2008 ббк п6 удк 631. 145+636: 612. 014., 7797.37kb.
4. Блок-схемы и алгоритмы, программы и подпрограммы.
Результатом процесса проектирования, как мы уже отмечали выше, будет «Техническое задание на программирование» (ТЗ). Отметим, что ТЗ необходимо передать программисту и пользователю/заказчику. Кроме того, ТЗ должно быть как можно более подробным для программиста и, с другой стороны, достаточно обобщенным. То есть должны быть видны и деревья и лес. Отсюда видно, что форма представления документа вопрос далеко не праздный.
Наиболее известная форма представления проекта – блок-схема. И в США и в Советском Союзе были приняты общенациональные стандарты на рисовку блок-схем.
Блок-схема графическое представление проекта решения задачи. Действия описаны в прямоугольниках, условные выборы в ромбиках, последовательность действий передаётся стрелками, соединяющих прямоугольники или ромбики. Принципиально можно изобразить и CASE-структуру (switch), кроме того, существует множество условных знаков предающих процессы ввода/вывода, межстраничные коннекторы и прерывания. При этом проект может выглядеть, например, следующим образом: (Р. Гласс) рис. 4.1
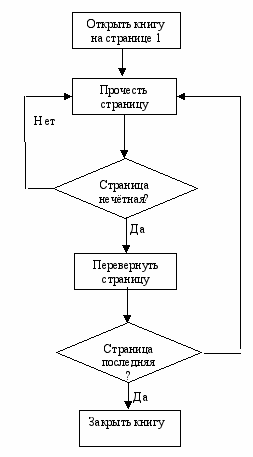
Нет
Рис. 4.1 Блок-схема алгоритма чтения книги
Блок-схема как средство, облегчающее проектирование, признаётся одной из разумных альтернатив. Однако часто точно такие же блок-схемы используются для оформления программ и включаются в программную документацию. Когда требуется «укрупнённый» взгляд на проект, блок-схема несомненна удобна. Когда же требуется достаточно подробно описать структуру и данные программы, блок-схемы неудобны.
Для программиста нет ничего лучше хорошо откомментированного листинга программы.
Блок-схемы трудно корректировать или модифицировать. На них достаточно сложно отобразить структуры данных. В большинстве своём блок-схемы отображают некий обобщённый взгляд на действия, без достаточной детализации и при внимательном рассмотрении обнаруживается, что блок-схема содержит ошибки. Например, вышеприведённая (рис. 4.1) блок-схема.
Тем не менее, блок – схемы «выжили» и часто применяются до сих пор, хотя и не так категорично, как этого требует национальный стандарт. Дело в том, что блок-схемы, прежде всего, отображают алгоритм решения задачи.
Что такое алгоритм? Существует строгое математическое определение понятия алгоритм и раздел математики «теория алгоритмов». Мы не будем рассматривать этого определения. Для нас алгоритм – последовательность «шагов» или действий решающих поставленную задачу. В этом смысле, понятие алгоритм очень близко к понятию «рецепт», «процесс», метод, способ и т.д. В конце концов, что такое программа как не отображение алгоритма. Однако само понятие алгоритм содержит нечто другое. Для того чтобы способ или метод стал алгоритмом он должен обладать, по крайней мере, пяти свойствами.
1. Конечность (финитность). Алгоритм всегда должен заканчиваться после конечного числа шагов.
Кнут сообщает, что процедуру, обладающую всеми свойствами алгоритма, за исключением свойства конечности, можно назвать вычислительным методом. Например, можно применить алгоритм Евклида для получения единой меры двух отрезков, но существуют несоизмеримые отрезки.
2. Определённость. Каждый шаг алгоритма должен быть точно определён. Действия, которые необходимо произвести, должны быть строго и однозначно определены. Если, что чаще всего и бывает, действия описаны на естественном языке, то всегда есть возможность, что выполняющий неправильно поймёт описание алгоритма. Именно по этой причине программы реализуются на неких алгоритмических языках исключающих двусмысленность.
Опять-таки, если рассматривать алгоритм Евклида, то определённость в нём означает, что он применяется для целых положительных чисел.
3. Ввод. Алгоритм имеет некоторое, возможно равное нулю, число входных данных. Эти величины заданы до начала работы.
4. Вывод. Алгоритм имеет одну или несколько выходных величин, определённым образом связанных с входными данными.
5. Эффективность. Все операции, которые необходимо выполнить должны быть достаточно простыми; чтобы их в принципе можно было выполнить карандашом на бумаге за конечный отрезок времени.
Для практических целей требование конечности недостаточно жёсткое: Используемый алгоритм должен иметь не просто конечное число шагов, а разумное число шагов. Уже сейчас можно предсказать погоду на завтра с указанием температуры с точностью до одной десятой градуса, но для этого потребуется месяц счёта на машине. Другой пример шахматная партия.
Для программиста очень важен выбор правильного алгоритма для решения поставленной задачи. Ясно, что для решения задачи нередко можно найти несколько алгоритмов. Например, вам необходимо генерировать заданное число промежуточных точек отрезка заданного координатами своих концов. Самый прямолинейный выход: найти тангенс угла наклона отрезка, разделить разницу X – координат на заданное число, и сгенерировать Y – координату, вычислив её из простой формулы – X * tg (φ).
Всё бы ничего, да существуют углы в 90º и близко к 90º. То есть, используя этот алгоритм, мы будем при углах близких к 90º применять другие методы генерации промежуточных точек, кроме того, нам всегда надо будет проверять величину угла φ на 90º. Однако существует метод деления отрезка в данном отношении, где используются только координаты вершин отрезка: этим методом мы можем сгенерировать любое число промежуточных точек отрезка, не контролируя угол наклона.
Конечно, алгоритмы обладают множеством других свойств. Кратко рассмотрим некоторые из них. Видим, что если применять алгоритм с вычислением тангенса, то необходимо проверять угол на близость к 90 градусам, так как при этом тангенс не существует, но промежуточные точки отрезка существуют. Назовём проверку особых ситуаций алгоритма особенностью алгоритма. Ясно, что алгоритм без особенностей всегда предпочтительней алгоритма с особенностями. Видим, что деление отрезка в данном отношении всегда даёт нам любое число промежуточных точек. Второе достоинство этого алгоритма в том, что мы можем получить точки не только отрезка, но и продолжения отрезка – прямой. То есть мы можем применить алгоритм для других целей. Условно назовём это свойство мощностью алгоритма. Использование алгоритма для целей, для решения которых он, вообще говоря, не предназначался можно назвать мощностью алгоритма. Хотя, скорее всего, это понятие отражает мощность идеи.
Есть такое свойство как красота алгоритма – достаточно интуитивное понятие. Я не настолько знаком с математической теорией алгоритмов, но полагаю, что формально оно не определяется. Тем не менее, алгоритмы бывают красивые и некрасивые. Если у вас имеется дерево, на вершине которого висит плод, а вам необходимо достать этот плод, то вы можете сделать это, по крайней мере, тремя способами: а) спилить дерево; б) долго и нудно насыпать пирамиду из камней или земли, так чтобы потом, взобравшись по пирамиде, просто сорвать плод; в) метким выстрелом перебить черенок плода. Конечно же, последний алгоритм доступа к плоду красивее двух предыдущих. В данном случае мы можем перечислить конкретные признаки того, почему он красивее первых двух: он требует гораздо меньше ресурсов для достижения поставленной цели; цель достигается гораздо быстрее; достижение цели не разрушает окружение и через какое-то время можно будет снова получать плоды. По ходу дела мы получили некоторые косвенные признаки красивого алгоритма. К сожалению, этим красота не исчерпывается и более точного определения мы дать не сможем. Единственное, что мы можем сказать, что если придётся выбирать из нескольких алгоритмов, то лучше выбрать из них наиболее красивый. Однако само восприятие красоты алгоритма индивидуально и зависит от программиста. Кроме того, очень часто более красивые алгоритмы более трудны для понимания и требуют большей грамотности.
Очень интересный аспект насколько влияет объём входных данных на алгоритм. То что объём входных данных важен ясно без обсуждения, чем больше входных данных, тем дольше работает алгоритм. Если допустить, что время работы алгоритма растёт линейно с ростом объёма, то, увеличив объём данных в десять раз, мы увеличиваем время счёта также в десять раз. Однако если на хранение объёмов данных практически нет ограничений, то ко времени работы программы предъявляются часто очень жёсткие требования. Программист должен быть готов к тому, что время работы программы растёт гораздо быстрее, чем линейно. Поэтому следует помнить: увеличение (изменение) объёма данных на порядок приводит к необходимости смены алгоритма счёта (или доступа к данным!). Лучше всего это видно на примере сортировок. Десяток чисел можно рассортировать и «методом пузырька»: время сортировки всё равно маленькое, а операций организующих алгоритм мало (почти нет). Однако несколько тысяч чисел уже лучше сортировать другим методом, например, сортировкой Шелла. Там гораздо больше число организующих операций, зато значительно падает число сравнений. Таким образом, время потраченное на организацию алгоритма уравновешивается уменьшением времени числа сравнений и общее время сортировки достаточно удовлетворительно. Но несколько сот тысяч чисел лучше сортировать, например уже методом Хоара. Но в методе Хоара общий массив разбивается на подмассивы, которые, начиная с некоторой величины, сортируются вновь методом Шелла. Если же потребуется сортировка массива, который не умещается в память машины, то мы вступаем в область совершенно других сортировок: внешних сортировок; все предыдущие методы в отличии от внешних называются внутренними.
Отметим, что здесь мы сталкиваемся не только с ограничениями собственно алгоритма, но и с ограничениями окружающей среды. Узкие возможности техники – одни возможности программного обеспечения; большие ресурсы техники – другие возможности ПО: сравните возможности ЕС и современной ПЭВМ.
Обратите внимание, что смена алгоритма в зависимости от объёма данных закон общий и применим везде. Например: представьте, что необходимо поделить некую сумму между некоторым числом «голодных». Ясно, что способ распределения этой суммы зависит от соотношения суммы и «голодных».
Как мы уже отмечали, блок-схемы отображают алгоритм решения задачи. Чем примечательны алгоритмы? На что мы прежде всего обращаем внимание при построении алгоритма решения задачи? Очевидно, что, прежде всего, мы выделяем действия, которые нам необходимо выполнить и их последовательность. Последовательность действий отображается в виде стрелок и блоков; сами действия указываются текстом в блоке. Поскольку текст задействован на описания действий, то отобразить данные и их структуру чем-то существенно выделявшимся нечем. Трудность отображения структуры данных, как уже отмечалось выше, один из недостатков блок-схем. Теперь мы видим, что это один из «недостатков» алгоритмизации. Так оно и должно быть, так как один и тот же алгоритм нередко можно применить ко многим типам и структурам данных. То есть, алгоритмизируя задачу, мы некоторым образом абстрагируемся от данных. С другой стороны, мы разбиваем задачу на более мелкие блоки. Когда блок превращается в отображение только одного шага (одного действия), дальнейшее его разбиение невозможно. Однако, до такого состояния блок-схемы доводят редко, так как необходимость в пошаговом разбиении появляется только на этапе программирования отдельных модулей. Но тогда блок-схема отображает модульную структуру разрабатываемой программы. То есть, строя обобщённую блок-схему программы мы выполняем предварительное разбиение программы на модули, на подпрограммы. Почему предварительное? Да потому, что окончательное разбиение будет сделано только на этапе программирования и отладки. В свою очередь, на этапе сопровождения станут видны «тонкие» места программы: какие модули неудобны в работе; какие медленны, а употребляются часто; какие, возможно, имеют ошибки, не выявленные на этапе реализации и сдачи программы и т.п.
Обнаружив, что разбиение на модули начинается уже на этапе алгоритмизации, нам следует более досконально обсудить понятие подпрограммы и модуля.
Вернувшись на сорок лет назад к программированию в коде, мы обнаружим большое стремление тогдашних программистов, повторно использовать уже написанный код. Тогда это выполнялось двумя путями.
Повторно используемые коды назывались стандартными программами. Машина приходила с некоторым списком стандартных программ прошитых в заданное место памяти. То есть часть программ была реализована аппаратно, их нельзя было поменять, но можно было использовать. С заданных ячеек (адресов) памяти эти стандартные программы принимали входные данные, результат также заносили в заранее согласованное место памяти. Обратите внимание, что, прежде всего здесь имело определённое соглашение об использовании некоторых адресов памяти.
Кроме того, многие вычислительные центры имели свои библиотеки стандартных программ. Мы должны представлять, что иметь такую библиотеку, прежде всего, означало иметь некое соглашение об общем использовании памяти ЭВМ.
1. Необходимо было согласовать, где можно располагать входные данные стандартной программы или адреса входных данных. Это обязательно приводило к соглашению: как передавать данные в программу. Отметим, что входных данных могло быть более десятка переменных, то есть входных данных могло быть «очень много»; число входных данных могло быть как фиксированным, так и переменным.
В условиях ограниченных возможностей техники это были далеко не праздные вопросы.
2. Точно такое же соглашение должно было быть и по поводу выходных данных программы: где и как?
3. Где, с какого адреса должна была быть размещена стандартная программа? Этот вопрос, в каком-то смысле, оказался не очень сложным, поскольку достаточно быстро программисты обнаружили, что можно писать, так называемый, перемещаемый код: код который можно было очень просто откорректировать перед выполнением на конкретные адреса. Обычно, такая корректировка сводилась к прибавлению ко всем адресам программы адреса начала программы (адреса загрузки).
4. Каким образом стандартная программа должна была попасть в память машины? Именно тогда появились первые загрузчики программного кода и понятие адрес загрузки.
5. Как программа могла использовать общие ресурсы машины?! Речь шла уже не об ОЗУ, а о некоторых постоянно распределённых ячейках памяти; некоторых внешних устройствах.
Вот так идея иметь библиотеку стандартных программ приводила к странной административно реализованной системной среде! Отметим, что, фактически, такого понятия как подпрограмма не было. Все программы были в каком-то смысле равноправны. Условно можно было выделить главную программу: та программа, ради функционирования которой и вызывались другие программы. Нередко эта программа имела некие управляющие функции, но, в общем, она была точно такой же, как и остальные.
Появление алгоритмических языков, трансляторов и операционной системы существенно изменили состояние дел. Теперь распределение памяти было возложено на транслятор, согласование расположения программы в памяти и разрешение внешних адресных ссылок на редактор, загрузка программы на загрузчик, слежение за состоянием и использованием ресурсов на операционную систему. Программист (проблемщик) мог сосредоточиться на программировании собственно задачи.
Но транслятор каждого языка по-своему использовал (распределял) память машины. Кроме того, для выполнения определённых действий, например, запуск операций ввода/вывода, преобразования типов данных транслятор встраивал в программу программиста свои собственные модули, которые в каждом трансляторе назывались по-своему. Таким образом, чтобы запустить программу, оттранслированную с алгоритмического языка надо сначала создать определённую окружающую среду. Делать это надо только один раз, при запуске самой первой программы. Соответственно, при завершении работы программы необходимо выполнить действия, сообщающие операционной среде, что программа прекратила своё существование и освободить занимаемые ресурсы. Опять-таки делать это надо один раз, когда последний модуль программы завершает свою работу.
Так в программах появился «пролог» и «эпилог» в которых и выполнялись выше означенные действия, а поскольку выполнить их надо только один раз, то и появилась так называемая главная программа и подпрограммы.
На языке Cи главная программа main – функция или WinMain для Windows. Главная программа «готовит» среду работы для себя и для работы остальных подпрограмм. При завершении она освобождает все занятые ранее ресурсы. Точнее выполняют все необходимые функции модули/программы и т.п. вставляемые в программу транслятором. Предполагается, что программист знает об этом, но не вмешивается в процесс. Во многих языках в главную программу нельзя передать параметры. В Cи можно передать в main – функцию параметры, но делается это немного сложнее, чем в других случаях. А вот в функцию WinMain могут быть и обязаны быть переданы только вполне определённые параметры. Заметим, что программист даже не имеет права изменить имя главной программы. Это создаёт трудности при вызове одной главной программы другой такой же. Главная программа «считает», что она одна в том выделенном для неё пространстве. Тогда другую главную программу можно запустить, только выделив ей такое же пространство. Но это уже другая задача или другой процесс на уровне операционной системы. Поэтому внутри главной программы вы не можете вызвать другую главную программу обычным образом, как обычную функцию. Для этого существуют специальные функции: функции управления процессами! Наконец, как уже должно быть понятно, существуют трудности при сборе разноязыковых модулей в единую программу.
Все остальные процедуры и функции называются подпрограммами. Подпрограмма – программа, вызываемая другой программой или подпрограммой.
Основное отличие от главной программы, то, что в прологе подпрограмма не устанавливает окружающую среду для работы, она предполагает, что это выполнила главная программа. Подпрограмма использует уже установленную среду. Пролог и эпилог, конечно же, есть. Только в прологе, подпрограмма выполняет действия по распределению памяти для собственных переменных и самой себя. Если все внутренние переменные подпрограммы живут только пока есть сама подпрограмма (языки Cи и Algol), то разумеется где-то должны выполняться действия по запросу и распределению памяти для переменных, а по завершению работы необходимо удалить из памяти ранее распределённые переменные. Кроме того, на входе подпрограммы выполняется «распаковка» входных параметров, а на выходе «упаковка» возвращаемого значения, если оно есть.
Отсюда видно, что подпрограмма не может быть запущена самостоятельно! Она должна быть вызвана другой подпрограммой или главной программой. При этом вызывающая программа обязана обеспечить среду функционирования подпрограммы.
Если подпрограмма могла быть вызвана повторно, до окончания её работы при предыдущем вызове или по-другому, если одна копия подпрограммы в памяти могла быть одновременно использована несколькими подпрограммами, то такая подпрограмма называлась повторновходовой или реентерабельной.
Если подпрограмма по ходу выполнения могла прямо или косвенно обратиться к самой себе, то такая программа называлась рекурсивной, а подобное обращение к подпрограмме рекурсивным вызовом.
Для того, чтобы работать с подпрограммой необходимо знать как ей подать на вход переменные. Но при работе с подпрограммами возникает ещё один очень важный вопрос: где видны/известны те переменные, которые объявлены в подпрограмме. Общее правило гласит: переменные видны в пределах только той единицы, в пределах которой они объявлены. Однако некоторые вопросы видимости переменных различные языки решают по-разному. Основные различия касаются видимости переменных объявленных внутри программных единиц, которые в свою очередь объявлены внутри других программных единиц. Более подробно мы остановимся на этом при рассмотрении конкретного синтаксиса языков.
Использование подпрограмм экономит память, программа в целом становится короче, но работает такая программа чуть-чуть медленнее, так как тратится время на вызов подпрограммы. С другой стороны, при разбиении программы на подпрограммы лучше просматривается структура больших и сложных программ. Подпрограммы обеспечивают логическую сегментацию программы, облегчают отладку, снижают общее время отладки. Но самая главная ценность грамотно написанных подпрограмм в том, что их могут использовать другие программисты в других программах!
Для этого достаточно знать какими должны быть входные параметры и как их подать на вход подпрограммы; какой будет выход подпрограммы и иметь хотя бы её объектный модуль, полученный трансляцией с того же языка, что и вызывающая программа. Если нет объектного модуля, то можно иметь исходный модуль программы. Впрочем, исходный модуль всегда предпочтительней любого другого.
Основной недостаток этой схемы в том, что нельзя вызвать напрямую подпрограмму, написанную на другом языке. Точнее, это сделать можно, но не просто.
Связь с подпрограммами можно наладить не только посредством передаваемых параметров. Существует по-крайней мере ещё две идеи, как это сделать.
Во-первых, возможны программы реализующие действия, использующие значительное количество общих констант. Представьте программу, которая в процессе счёта использует несколько сотен констант, практически, любая программа по термодинамике. Сами константы можно задать как в тексте программы, так и хранить на внешнем устройстве в файле. Однако, в процессе счёта очень удобно все эти константы сразу ввести в память, чтобы не обращаться к внешнему устройству многократно. Тогда возникает вопрос, каким образом сделать видимыми эти константы вызываемым подпрограммам. Передавать несколько сотен параметров нереально. Загрузить их в один массив, чтобы передавать только адрес этого массива: чрезвычайно неудобно во время отладки – попробуйте различить, где какая константа, если они все имеют одно имя и различаются только индексами. Очевидная идея сделать эти переменные глобальными, так чтобы они были видны из всех программ. В C для этого достаточно объявить переменные вне программы.
Практика показала, что с этим решением проблемы связано громадное число ошибок. Поскольку мы разрешили доступ к некоторой области памяти множеству программ, а все они писались разными программистами, то, как бы они не согласовывали между собой использование общей области, всё равно кто-то наделает ошибок и что потом находится в этой общей области памяти никто не берётся определить. Тем не менее, это решение осталось и даже сейчас вы можете им воспользоваться со следующими рекомендациями:
- если есть возможность обойтись без глобальных переменных, обойдитесь без них;
- стремитесь минимизировать число глобальных переменных;
- старайтесь не изменять глобальные переменные, используя их в качестве общих констант;
- имена глобальных переменных старайтесь задавать так, чтобы по имени можно сразу определить, что это именно глобальная переменная.
Следует заметить, что современные средства программирования выполнены таким образом, что провоцируют, и можно даже сказать, стимулируют использование глобальных переменных.
Другая идея, которая может использоваться параллельно с первой выделение некоторого общего объёма памяти, к которому все части программы имеют доступ и через который все они обмениваются необходимыми данными. Идея хороша тем, что заранее не оговаривается структура этой области. В каждый момент времени она может быть именно такой, какой это надо обращающейся к ней программе. Но именно этим идея и плоха. Тем не менее, общая область памяти, называемая буфером обмена, используется довольно часто, причём не только для связи между подпрограммами, но для связи между процессами операционной системы. На сегодня в Windows, нажатием клавиш Shift - Del вы любой объект можете поместить в буфер обмена, а по Shift – Ins вы получаете объект из буфера обмена себе в программу. Всё это можно выполнить и программно.
Подведём некоторые итоги. Разбиение программы на подпрограммы иногда называют процедурной абстракцией. Процесс разбиения программы на подпрограммы сильно напоминает процесс алгоритмизации. В некотором смысле это одно и тоже. Мы выделяем действия и программные единицы, выполняющие эти действия, при этом мы определённым образом абстрагируемся от данных. Структура программы, будучи определённым образом отражена, похожа на структуру алгоритма
Программы, выполняющиеся таким образом, называются последовательными программами, как программные единицы, выполняющие последовательность действий. Здесь очень важно то, что последовательность действий заранее определена. Во всех до Windows – системах работают именно такие программы.
Единственным отвлечением от последовательности действий могло быть только прерывание. Обработка прерывания появилась в алгоритмических языках относительно поздно. При этом строилась она тоже по последовательному принципу. При возникновении прерывания управление передавалось программе обработки прерывания. По завершению работы обработчика прерывания, управление, как правило, возвращалось в точку возникновения прерывания, хотя и не обязательно. Важно то, что прерывание могло возникнуть в любой точке последовательности действий.
Естественным образом выделялась главная программа и подпрограммы. Запуск главной программы для операционной системы означал запуск задачи. Запуск подпрограммы для операционной системы мог ничего не значить, то есть операционная система могла и не знать о запуске вашей подпрограммы, если вы специальным образом не оформляли вызов подпрограммы. Для того чтобы запустить из одной главной программы другую, вообще говоря, необходима была мультизадачная операционная система.
Программный запуск другой главной программы в Cи называется запуском процесса. Возможны несколько схем запуска процесса.
Программа запускает процесс на то место в оперативной памяти, где расположена сама. То есть запускаемый процесс, затирает вызывающую программу или процесс. Здесь также возможны, как минимум, две ситуации: с сохранением окружающей среды и с изменением её. Обратим внимание, что такой запуск возможен и однозадачной операционной среде.
Программа запускает процесс в дополнительной области памяти, полностью сохраняя свою работопригодность. Теперь также возможны две ситуации. Вызывающий процесс запускает другой процесс и продолжает функционировать. Оба процесса функционируют независимо друг от друга. Такой запуск другого процесса называется асинхронным вызовом. Понимаем, что такой вызов процесса требовал реальной мультизадачной среды. Вызывающая программа могла породить процесс и по каким-либо причинам ждать его завершения или некоторых результатов его работы, то есть при вызове вызывающая программа переходит в состояние ожидания и ждёт. Это синхронный вызов процесса или задачи. Принципиально, так как не требуется одновременная работа нескольких задач, такой вызов можно было осуществить в однозадачной среде. Именно так вызывался Windows под DOS.
Очень важно знать каким образом наша программа могла размещаться в памяти машины. Были (и остаются) две основные схемы. Обычная последовательная структура программы или линейная структура. Модули программы расположены впритык друг к другу. Общая длина программы без данных будет равна сумме длин всех модулей. Структура программы с перекрытием или корневая структура. Некоторая часть программы, обычно это главная программа, постоянно находится в памяти и называется корнем. Начиная с некоторой точки памяти располагаются вызываемые подпрограммы. Подпрограммы, если позволяет алгоритм загружаются в с одной начальной точкой, затирая друг друга. Длина программы будет определяться как сумма длин корневой части программы и самой длинной из подпрограмм. Отметим, что в этом случае необходимы определённые действия вызывающей программы по смене (загрузке) подпрограмм, зато общая длина программы становилась меньше: опять-таки правило рычага: выигрываем память – проигрываем время.
Связь между подпрограммами могла быть организована передачей параметров, совместно используемой областью памяти с заданной структурой или передачей данных через буфер обмена. Принципиально можно организовать передачу данных и через внешние носители, записав данные в файл, а затем прочитав их оттуда.
^ Как всё это выглядит на языках программирования.
В Cи любая программа рассматривается как функция. При этом программа может вернуть только одно значение, а входные параметры передаются по значению. Массив вернуть невозможно, но структуру можно, причём по значению. Это приводит к некоторым нелогичностям, так как в структуру могут входить массив и прочие агрегаты. Для вызова подпрограммы достаточно указать имя её, а в списке параметров перечислить передаваемые переменные.
Например: MyFunction (A, Bd, 5, “ передача параметров”); или NoPara();
или, если функция возвращала значение: u = RetFunc (Clv);
функции, возвращающие значения можно использовать в вычислительных выражениях: X = RetFunc(Clv) + 10;
А.Я. Архангельский [2] обращает наше внимание на различие между Cи и Cи++. Если в Cи вы указываете пустой список параметров, то это означает, что проверки аргументов нет. В Cи++ пустой список параметров указывает на отсутствие аргументов.
массивы передаются по адресу или как теперь принято говорить по ссылке:
double A[34][34]; TransMatr (A); - то есть имя массива используется как указатель! А TransMatr должна быть описана как void TransMatr (double * * A); Это приводит к несколько неуклюжему синтаксису при работе со строками. Пример:
int strcmp(char * A, char * B); так может быть описана программа сравнения двух строк, а обращаться к ней можно
if (strcmp(“ первая строка “, “ вторая строка “)) ……… или
if (strcmp(A, B)) ……
Однако в Cи можно передать параметры и по ссылке:
Пусть подпрограмма описана как: void Ut (int * d, char * G);
Тогда обращаться к ней можно следующим образом Ut (&f, “ список “);
где f ::= int. & - операция взятия адреса.
В Cи++ существует аппарат передачи параметров по ссылке.
Вам можно описать функция следующим образом:
void Fun (int & D, double & F); & перед именами переменными указывает, что на вход передаются адресные ссылки на переменные. Транслятор, принимая такое описание функции, будет строить передачу параметров в неё по ссылке. При обращении к такой функции не надо выполнять операцию получения адреса переменной, а требуется просто указать имена переменных: Fun (Ha, Da);
Если необходимо передать переменное число параметров, то функция описывается следующим образом (например):
int DF (список постоянных параметров, …);
Все постоянные параметры обязательно предшествуют переменным. В объявлении функции необходимо указывать именно три точки, иначе транслятор выдаёт ошибку.
Возникает вопрос, каким образом обратиться к переменным параметрам, если в функции неизвестно имя и тип входного параметра.
В файле stdarg.h определён тип списка va_list и три макроса: va_start, va_arg и va_end.
Объявляем переменную типа va_list: va_list lp;
Макросом va_start начинаем работу со списком. Им мы указываем последний обязательный аргумент: va_start(lp, last_Argument);
Далее последовательно обращаемся к va_arg, которая нам возвращает аргумент и устанавливает указатель на следующий аргумент: va_arg(lp, тип)
S = va_arg(lp, double);
Мы сами так или иначе должны считать аргументы и следить за их типами. Тип, указываемый в списке аргументов, фактически, указывает тип переменной, которой присваивается значение.
Завершаем работу вызовом va_end(lp);
Пример программы:
/* передача в функцию переменного числа параметров.
Гатин Г.Н. 10.10.2002г. */
#include
#pragma hdrstop
#include "Tu101022.h"
//-----------------------------------------------------------------
#pragma package(smart_init)
#pragma resource "*.dfm"
void TestVari (double & S, int & Si, int N, ...);
TForm1 *Form1;
__fastcall TForm1::TForm1(TComponent* Owner)
: TForm(Owner)
{
double Su;
int sI;
TestVari (Su, sI, 3, 1.1, 2, 3.3);
MessageDlg (" полученные суммы: "+FloatToStr(Su)+" "+IntToStr(sI), mtInformation, TMsgDlgButtons() << mbOK, NULL);
TestVari (Su, sI, 3, 1, 2.2, 3);
MessageDlg (" полученные суммы: "+FloatToStr(Su)+" "+IntToStr(sI), mtInformation, TMsgDlgButtons() << mbOK, NULL);
TestVari (Su, sI, 5, 1.1, 2, 3.3, 4, 5.5);
MessageDlg (" полученные суммы: "+FloatToStr(Su)+" "+IntToStr(sI), mtInformation, TMsgDlgButtons() << mbOK, NULL);
TestVari (Su, sI, 1, 1.1);
MessageDlg (" полученные суммы: "+FloatToStr(Su)+" "+IntToStr(sI), mtInformation, TMsgDlgButtons() << mbOK, NULL);
TestVari (Su, sI, 0);
MessageDlg (" полученные суммы: "+FloatToStr(Su)+" "+IntToStr(sI), mtInformation, TMsgDlgButtons() << mbOK, NULL);
Application -> Terminate();
}
//-----------------------------------------------------------------void TestVari (double & S, int & Si, int N, ...)
{
va_list lipa;
double p;
int v, i;
S = 0; Si = 0;
va_start(lipa, N);
for (i = 0; i < N; i++)
if (i%2 != 0) { v = va_arg (lipa, int);
Si += v;
}
else { p = va_arg (lipa, double);
S += p;
}
va_end(lipa);
}
Точно также эти макросы определены в Visual Cи++.
В Cи++ вы можете объявить входные параметры с умалчиваемым значением:
Для этого при определении функции вы задаёте их умалчиваемое значение:
Например: double MfYm (double A, int C, double My = 0, int Gi = 1);
Параметры с умалчиваемыми значениями, как и опускаемые, все находятся после списка обязательных параметров.
В Cи++ можно объявить inline функцию: функция, текст которой встраивается непосредственно в текст программы, а затем программа транслируется. Это очень удобно с точки зрения разработки программы. Нет накладных расходов на вызов функции, но при корректировке не надо менять текст в нескольких местах, достаточно изменить текст определения функции. Однако, транслятор «сам» решает вставлять функцию в текст программы или оставить обычной вызываемой функцией. Это необходимо для того, чтобы значительные по величине inline-функции не вставлялись в текст.
Согласно общему правилу все переменные видны только в пределах того блока, внутри которого они объявлены. Если переменные объявлены вне текста программы (чаще всего до начала программы), то они автоматически становятся глобальными: то есть известными всем ниже встречающимся программам. В C мы не имеем права объявлять функцию внутри другой функции. Любая функция может иметь спецификатор класса памяти: static или extern. По умолчанию функция имеет класс памяти extern и будет видна из других модулей. Функция, объявленная с классом памяти static видна только в пределах модуля (файла) объявления. Если внутри функции объявлены переменные одноимённые глобальным, то внутри функции видны именно локальные переменные, а не глобальные. Однако можно обратиться и к глобальным, располагая перед именем переменной :: применив операцию разрешения области видимости.
Эти правила работают, если программист не будет сам управлять видимостью переменных, что возможно в Cи++.
Если переменные объявляются вне программы, то они автоматически становятся глобальными и видны всюду ниже объявления.
Как вопросы вызова и определения функций решены в Pascalе?
Первое отличие от Cи то, что в Pascale два вида подпрограмм: procedure и function. Отличие первой от второй только в том, что function возвращает значение, а procedure нет. В остальном объявление и определение процедуры и функции идентично:
procedure ИМЯ (входные параметры : тип);
function ИМЯ (входные параметры : тип) : тип функции;
Возвращая значение из функции, вам необходимо использовать либо специальную переменную либо имя функции:
Result = …. либо ИМЯ функции = ……
Поместив объявления наших подпрограмм в разделе interface, мы делаем нашу подпрограмму доступной для других модулей. Если нам требуется ограничить видимость нашей подпрограммы только текущим модулем, то следует поместить определение подпрограммы в разделе implementation.
В Pascale вы можете объявить подпрограмму в разделе var. Подпрограмма, объявленная таким образом называется локальной. Она становится невидимой для всех других единиц кода. Локальная подпрограмма «видит» все переменные, объявленные в этой единице кода и, конечно, может ими воспользоваться. Это очень важное отличие от Cи, где нельзя объявлять вложенных функций.
Управление типом передачи параметров в Pascale возложено на программиста.
Если просто перечислить входные параметры в объявлении функции, то параметры будут передаваться по значению. Если перед именем переменной указать ключевое слово var, то параметры будут передаваться по ссылке.
Точно так же, как в Cи, с поправкой на синтаксис Pascal, можно передавать параметры с умалчиваемыми значениями.
Visual Basic очень сильно разнится от версии к версии. Понятно стремление фирмы Microsoft не сделать, а хотя бы приблизить Basic к нормальным программистским инструментам, но родовые травмы очень тяжело лечатся и чаще всего остаются на всю жизнь. Тем не менее, рассмотрим кратко механизмы передачи и объявления подпрограмм в Visual Basic 6.
Visual Basic, как и большинство других языков рассматривает процедуры и функции. Процедура начинается ключевым словом Sub и заканчивается End Sub.
Вызывается процедура оператором Call ИМЯ (список параметров). Функции описываются точно также как и процедуры, только вместо Sub вы пишете Function.
Функция вызывается обычным способом. Но в Visual Basic функция может быть вызвана и оператором Call, как процедура, при этом теряется её значение. Синтаксис возвращения значения: присвоить имени функции возвращаемое значение. Особенность: функция может вернуть массив! Но только в Visual Basic 6. Кроме того, возвращение массива выполняется по другому синтаксису, который здесь рассматривать не требуется.
Параметры, по умолчанию, передаются по ссылке. Ранее это был единственный способ передачи параметров. В Visual Basic 6 параметры можно передавать по значению, добавляя перед именами передаваемых переменных ключевое слово ByVal. Передача необязательных параметров возможна; используется ключевое слово Optional. Но в Visual Basic возможен и другой способ передачи переменного числа входных параметров. Построение массива входных параметров по ключевому слову ParamArray.
Особенностью Basica будет передача параметров по имени. Это для чайников. То есть, при вызове подпрограммы вы перед параметрами можете указать их имена, поменяв при этом порядок входных параметров.
При межъязыковом программировании следует ещё учитывать порядок упаковки входных параметров в стек. Си первым в стек отправляет последний параметр, а Basic и Pascal всё делают наоборот: то есть в стек первым отправляется первый входной параметр. Поэтому существуют модификаторы доступа:
cdecl – параметры упаковываются как в Cи
pascal - параметры упаковываются как в Рascal
Модификаторы доступа используются перед объявлениями функций.
Мы видим, что в той или иной степени вопросы вызова подпрограмм и передачи параметров решены примерно одинаково во всех языках, даже в таком как Basic. Наличие аппарата подпрограмм позволило писать большие проекты в реальные сроки. Основные недостатки:
1. Как уже отмечалось невозможно вызвать напрямую модуль, оттранслированный другим транслятором. Принципиально этот вопрос решался тем, что разрабатывалась программа-переходник: она создавала среду выполнения для вызывающей подпрограммы и передавала управление подпрограмме. Так можно было подключить объектный модуль, написанный на другом языке. Однако, уже из вышесказанного видно, что лучше всего было иметь текст программы и переписать его на языке вызывающей программы.
2. Поскольку типы данных, чаще всего, обязательно задавались заранее, то необходимо было писать несколько функций с разными типами и разными именами,
хотя делали они одно и то же: int abs(int), long int labs(long int), double fabs (double): все эти функции возвращают абсолютное значение. Хотелось бы хотя бы в тексте программы иметь только одну функции – abs.
Вторая проблема решается перегрузкой функций. Дело в то, что транслятор всё равно даёт внутренние имена всем объявленным переменным и функциям в том числе. Следовательно, если транслятор будет различать функции по входным параметрам, то он может сгенерировать для каждой из функций своё внутреннее имя, после чего возможна идентификация каждого экземпляра функции. Другими словами, можно объявить несколько функций с одним именем, но разным списком входных параметров и, возможно разными типами выходных значений.
Например в Cи++: int abs (int);
float abs (float);
char MyF (char, int);
char MyF (char, char, float);
Таким образом, появляется возможность иметь функцию с одним названием для разных типов и количества входных параметров и разных типов выходных параметров. Предполагается, что функции, имеющие одинаковые названия делают одно и то же, только с разными типами входных параметров. Программист должен очень внимательно использовать перегруженные функции. Дело в том, что транслятор должен иметь возможность однозначно различить такие функции. Г. Шилдт [ 10 ] приводит примеры, в общем, правильно объявленных перегруженных функций, тем не менее, употребление их может привести к неоднозначности:
имеем: float Func (float);
double Func (double);
Какую функцию использовать для следующего обращения:
j = Func (10); где int j;
В Pascale вы также можете перегружать функции, указывая сзади описания overload:
function MyFu (N, A, B : Integer) : Integer; overload;
function MyFu (N, A, B : Double) : Double; overload;
В обоих языках нельзя перегрузить функцию у которой различаются только тип выходного параметра. Обязательно должен различаться список входных параметров.
Конечно, нам всё равно приходится писать несколько экземпляров одной и той же программы, но, во-первых, очень часто это только смена заголовка, так как в остальном программа выглядит совершенно одинаково. Во-вторых, программа использующая перегруженные функции намного легче читается, она становится более проста для понимания, а следовательно и для отладки: в ней сохраняется концептуальное единство, что очень важно при отладке больших программных сред.
Возможно другое решение проблемы одной функции, работающей со многими типами данных, - написание так называемых «шаблонов функций», но это мы рассмотрим ниже.
По ходу дела мы не рассмотрели очень важный вопрос: как всё-таки включать необходимые нам подпрограммы в нашу программу? Другими словами, мы не рассмотрели вопросы компоновки программ.
В пакетных системах и в DOS, как мы ранее рассмотрели, включение можно было сделать на уровне исходного модуля и на уровне объектного модуля. Обычно у грамотных программистов существовали библиотеки исходных, объектных и загрузочных модулей. Отметим, что всё сказанное может касаться и DOSa, но там уже было большее разнообразие вариантов. Кроме того, библиотеки существовали системные, библиотеки транслятора и личные. Считалось крайне неприличным что-нибудь своё помещать в системные библиотеки или библиотеки транслятора, если, конечно, у вас не было специального задания. Личные библиотеки программным средам необходимо было указывать. Трансляторы, редакторы, загрузчики были построены так (только не в DOS), что поиск необходимых модулей выполнялся сначала в личных библиотеках, затем в библиотеках транслятора и, наконец, в системных библиотеках.
Исходные модули можно было либо «сцепить» вместе, указав имена библиотек и исходных модулей, либо включить исходный модуль по директиве препроцессора, но последнее возможно было не во всех языках.
Препроцессор: часть транслятора, вызываемая на нулевой фазе трансляции (то есть первой) и меняющая заданным образом транслируемый текст и опции трансляции. Отметим, что препроцессор меняет текст, подаваемый на трансляцию. Собственно директивы препроцессора не являются элементами языка и зависят от реализации, а в частности от возможностей конкретного транслятора. Однако основная масса директив препроцессора одинакова для всех трансляторов языка.
Появились препроцессоры рано. Уже, фактически, Fortran имел некоторые директивы препроцессора, но там это не было систематизировано. Но уже такой язык, как PL/1 имел понятие препроцессора и его директив. В частности этот язык имел директиву # include ИМЯ, по которой в текст транслируемой программы вставлялся другой исходный текст. Имя библиотек или, в совремённой трактовке, пути не указывались по вышеперечисленным причинам. Что интересно, что PL/1, это язык- оболочка и согласно идеи в нём было всё! Тем не менее, лучше всего было включить общие для программы переменные и описания в некий исходный текст и подавать его в необходимые модули. Единственный недостаток этого решения, что вставляемый текст всегда транслировался, что несколько замедляло время трансляции.
Язык Cи – язык-ядро. В самом Cи нет даже ввода/вывода, математических функций и т.д. На самом деле всё это есть, иначе было б невозможно работать, но указанные модули расположены по библиотекам, поставляемым с транслятором, а значит, сильно зависят от реализации. Безусловно, есть часть реализованная одинаково во всех трансляторах, но, во-первых, имеются разночтения, а во-вторых, есть существенно по-разному реализованные части.
Программа на Cи состоит из двух частей: заголовка программы и текста программы. Заголовки имеют расширение .h и помещаются в текст программы по директиве препроцессора #include ИМЯ. Все директивы препроцессора начинаются с «решётки» (#) в первой позиции и, обычно, помещаются перед началом текста программы. Запрета на помещение директив в любое место программы нет, но чаще всего вышеуказанное размещение.
#include может быть в двух вариантах:
#include < имя > исходный текст ищется в стандартной библиотеке INCLUDE, где хранятся все стандартные заголовки. Обычно эта библиотека находится в директории установки транслятора.
#include “путь\имя” исходный текст ищется в указанной директории.
В обоих случаях имя – имя включаемого заголовка.
Предполагается, что в заголовке размещены объявления всех наиболее часто используемых функций и констант, а также определены используемые объявленными функциями структуры данных. Тексты очень коротких функций также могут быть помещены в заголовок. Опять-таки, нет запрета на помещение в заголовки какого-либо текста, есть негласное практическое правило, что может содержать заголовок. Рекомендуем посмотреть Бьёрна Срауструпа [8] стр.246
Такая система приводит к тому, что программисту, а очень часто и пользователю, необходимо знать, в каких заголовочных файлах помещены необходимые ему функции. При этом следует иметь в виду, что от транслятора к транслятору имена заголовочных файлов могут меняться, тем не менее:
stdio.h – основные функции ввода/вывода
stdlib.h – форматные преобразования данных
math.h – математические функции
string.h – операции со строками
malloc.h & alloc.h – запросы памяти у операционной системы.
Разумеется в Cи++ эти заголовочные файлы можно использовать, но тут имеются и собственные заголовочные файлы. Таким образом, включая в свою программу стандартную функцию вам необходимо, прежде всего, указать её заголовочный файл.
В Cи++ заголовочный файл может иметь расширение .hpp. Cи++Builder разработан так, что сам включает основные заголовочные файлы, но иногда программисту приходится самому заботиться о заголовочных файлах.
Тексты программ хранятся в файлах, имеющие расширения .c; в Cи++ - .cpp
Тексты программ также можно включить по директиве #include. Вставляя все заголовки вверху программы, программист задаёт все необходимые ему описания, а помещая в нужное место программы файлы .c и .cpp, программист вставляет все необходимые ему тексты. Всё это достаточно удобно и просто, почему и получило раcпространение.
Недостатки: все тексты транслируются при каждом проходе программы. Это неудобство частично устранено директивой #pragma hdrstop. Некоторые трансляторы, в частности Cи++Builder, создают так называемые предварительно откомпилированные заголовки (расширение .csm). Это часть общих файлов, которые всегда включены по директиве #include. Указанные заголовки предварительно оттранслированы в некоторую промежуточную между исходным и объектным кодом форму и помещены в рабочую библиотеку. Все заголовки (тексты), включённые в исходный модуль выше pragmы, не транслируются. Вся необходимая информация выбирается из файлов .csm.
Второй серьёзный недостаток: программист, в общем-то, должен знать, где находится описание применяемой им функции, хотя она и описана, как стандартная.
Среды визуального программирования сделаны так, что сами вставляют все необходимые заголовки, но иногда приходится работать вне визуальной среды, кроме того, при нестандартной работе также приходится о некоторых заголовках заботиться самому. Конечно, совремённые средства поиска информации на компьютере существенно сглаживают это неудобство, но представьте, что средства поиска дали вам несколько заголовков, в которые входят необходимые вам описания – какой вставлять вам в текст?
Третье: такая система, а именно – язык-ядро, провоцирует различия от транслятора к транслятору и даже от версии к версии одного транслятора.
Таким образом, система подключения текстов на уровне «исходников» при пользовании требует наличия исходного модуля или текста программы. Кроме того, как уже ранее отмечалось, при вставке исходного модуля необходимо всякий раз его транслировать. Существует другая схема компоновки: программа подключается на уровне объектного модуля. Выполняется это редактором связей. У редактора связей существует свой язык описания входных данных. На этом языке программист может указать, какой объектный файл ему необходимо включить при редактировании. Таким образом, подпрограмма может быть заранее оттранслирована, сохранена в библиотеке объектных модулей, а во время редактирования подключена к компонуемой программе. Все модули, вставляемые транслятором, поставляются именно на уровне объектных модулей. При этом достигается две цели: исходный текст скрывается от пользователя, а время трансляции не зависит от величины программы, так как все стандартные функции и подпрограммы уже оттранслированы. В связи с особенностями функционирования DOSa объектные модули редко хранятся «поодиночке». Обычно они собраны в библиотеки программ и хранятся в заданном месте. Библиотеки программ имеют расширение .lib и чаще всего хранятся в библиотеке транслятора LIB. Тем не менее, программист имеет возможность подключить одинокий объектный модуль к своей программе. В Cи++Buildere это можно выполнить с помощью Project Manager (меню View), указав включаемый объектный модуль. Также можно в свойствах проекта указать дополнительную библиотеку lib. Для получения объектного модуля в Cи++Buildere необходимо транслировать исходный текст в любом проекте.
На совремённом этапе, всё чаще идёт речь о подключении подпрограмм на уровне загрузочных модулей. Рассмотрение этого вопроса требует предварительного обзора функционирования самой операционной системы. Хотим мы того или нет, но принципы работы Windows существенно отличаются от работы Unix – подобных систем. Поэтому эту тему мы будем изучать позже, после обзора данных и их структур, используемых в программировании.
Последнее замечание по теме подпрограммы: мы нигде никоим образом не рассмотрели, каким же всё-таки образом разбивать программу на составные части. Ясно, что здесь нет общих правил. Мы не можем указать единого алгоритма разбиения программы на модули, хотя можно указать, что может повлиять на разбиение программа:
1. Прежде всего, сама задача. Задача может быть исследовательской или технической; формализованной – не формализованной; эпизодической, требующей однократной реализации, или регулярно «считаемой»; простой или сложной; разрабатываемой для использования самим программистом или разрабатываемой на продажу и т.д. Всё это в какой-то мере влияет на разбивку задачи на подзадачи, но, прежде всего, возможность разбиения задачи на подзадачи определяется самой сутью задачи и тут нет общих готовых рецептов.
Кроме того, все задачи в программировании условно делятся на следующие категории: вычислительные, “асушные”, системные, управляющие и смешанные.
Вычислительные, обычно, характеризуются большим объёмом вычислений и незначительным объёмом ввода/вывода. В вычислительных задачах, как правило, используется достаточно серьёзная математика и программисту специализирующемуся на вычислительных задачах (методах) просто необходимы знания математики в объёмах превышающих общеинженерные курсы математики.
В “асушных” задачах относительно незначительные объёмы простых вычислений, но со значительным объёмом ввода/вывода. Основные используемые технологии работа с базами данных. В большинстве случаев, это преобразование одного множества таблиц в другое множество таблиц с тем или иным объёмом ввода данных и вывода. Задачи, почти всегда простые, но критичные ко времени выполнения.
Системные: реализация модулей операционной системы, трансляторов, программ СУБД (системы управления базами данных), программы взаимодействия в сети и т.д. Как правило, требуются серьёзные знания вычислительной техники и особенностей её функционирования, а также операционных сред.
Управляющие: программы управляющие работой технических устройств или технологией протекания технических процессов. Почти всегда работают в режиме реального времени, чаще всего реализуются на Assemblere (в последнее время используется и Cи++). Высокие требования по надёжности функционирования.
Смешанные: задачи, обладающие характеристиками нескольких ранее выделенных групп, например – реализация серьёзной графической среды требует значительных объёмов непростых вычислений и значительного объёма операций по вводу/выводу или реализация операционной системы реального времени.
2. Программист. Обычно при рассмотрении абстракций выполняется абстрагирование не только от данных, например, или действий, но и от самого программиста. С одной стороны это понятно, поскольку строится некая формальная схема абстракции, где нет места такому глубоко неформальному элементу, как программист. Однако, в техническом задании алгоритм решения может быть определён достаточно отвлечённо, сортировать данные, например, а конкретный выбор алгоритма переложен на плечи программиста. Не надо объяснять, что программисты бывают разные и соответственно они по-разному сделают выбор алгоритма и разбиение задачи. Очень важно учитывать тип задачи и склонность программиста к решению именно этого типа задач.
3. Объёмом данных и соответственно выбираемым алгоритмом.
4. Технической и программной средой решения. Структура программы будет существенно разной в последовательной системе или в системе управляемой событиями (Unix или Windows). Вы можете работать в многопроцессорной среде с параллельными вычислениями или в однопроцессорной системе; в сети, используемой только для передачи данных или в существенно распределённой среде. Выбранный алгоритм может допускать параллельную обработку или нет.
5. Условиями конфиденциальности.
Обратите внимание, что формализованной частью в указанных феноменах будет только пункт № 3 – объём данных и алгоритм, и тот грешит неформальным определением алгоритма.
Вопросы к главе 4.
1. Формы представления постановки.
2. Блок-схема программы.
3. Алгоритм. Что такое алгоритм? Привести пример.
4. Пять основных свойств алгоритма.
5. Продемонстрируйте на примерах свойства мощности, особенности и красоты алгоритма.
6. Влияние объёма данных на используемый алгоритм.
7. Сущность алгоритмизации.
8. Необходимые соглашения для реализации библиотеки стандартных программ.
9. Основные различия между программой и подпрограммой.
10. Достоинства разбиения программ на подпрограммы.
11. Глобальные переменные; достоинства и недостатки.
12. Общая используемая область памяти; достоинства и недостатки.
13. Процедурная абстракция: что это такое?
14. Схемы запуска других процессов.
15. Вызов подпрограмм: передача параметров.
16. Вызов в Си++ программ с переменным числом параметров.
17. Передача в подпрограммы параметров с умалчиваемыми значениями.
18. Перегрузка функций?
19. Схема включения подпрограмм в программу.
20. Что такое препроцессор? Зачем он нужен?
21. Достоинства и недостатки схемы язык-ядро.
22. Достоинства и недостатки схемы язык-оболочка.
23. Что влияет на разбиения программы на модули?