
Базы данных и файловые системы
| Вид материала | Лекция |
- Информационные системы, использующие базы данных: оборудование, программное обеспечение,, 102.98kb.
- Методическое пособие по курсу «Базы данных и информационные системы» 2011, 489.34kb.
- 1 научиться создавать таблицу базы данных в режиме таблицы, 54.71kb.
- Ms access Создание базы данных, 34.31kb.
- Программа дисциплины «Базы данных», 395.38kb.
- Программа дисциплины «Базы данных», 380.05kb.
- Лекция 2 10. Полнотекстовые базы данных, 133.46kb.
- Практическая работа № «Создание базы данных», 21.96kb.
- Конспект лекций по курсу "базы данных" (Ч., 861.92kb.
- Реферат на тему: Access. Базы данных, 274.77kb.
ЛЕКЦИЯ №1
Базы данных и файловые системы
Предметом курса являются системы управления базами данных (СУБД). Начнем с того, что с самого начала развития вычислительной техники образовались два основных направления ее использования. Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало разработке методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов.
Второе направление, которое непосредственно касается темы нашего курса, это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. В самом широком смысле информационная система представляет собой программный комплекс, функции которого состоят в поддержке надежного хранения информации в памяти компьютера, выполнении различных преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т.д.
Предшественницей баз данных являются файловые системы.
Файловые системы – это набор программ, которые выполняют для пользователей некоторые операции, например, создание отчетов. Каждая программа определяет свои собственные данные и управляет ими.
Прежде всего, конечно, файлы применяются для хранения текстовых данных: документов, текстов программ и т.д. Такие файлы обычно образуются и модифицируются с помощью различных текстовых редакторов. Структура текстовых файлов обычно очень проста: это либо последовательность записей, содержащих строки текста, либо последовательность байтов, среди которых встречаются специальные символы (например, символы конца строки). Файлы с текстами программ, объектные модули. С точки зрения файловой системы, такие файлы также обладают очень простой структурой - последовательность записей или байтов. Аналогично обстоит дело с файлами, содержащими графическую и звуковую информацию.
Одним словом, файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию прикладным программам.
Существует ряд недостатков, присущих файловым системам. Отметим их:
- Разделение и изоляция данных. Поскольку данные хранятся в разных файлах, то собрать информацию из разных файлов достаточно сложно, приходится создавать некоторый временный файл, в который собирается вся необходимая информация, т.к. приходится организовывать синхронную обработку данных сразу в нескольких файлах.
- Дублирование данных. Опять-таки, из-за того, что данные хранятся в разных файлах, то очень часто приходится повторять некоторую информацию, чтобы не потерять смысл. Например, один файл содержит информацию о людях (ФИО, дату рождения, номер паспорта и т.д.), во втором файле содержится вся информация о заработной плате и прочих начислениях. Приходится дублировать информацию по ФИО. А дублирование информации сопровождается неэкономичным расходованием ресурсов (как с точки зрения памяти компьютера, так и с точки зрения человека, который тратит больше времени на внесение информации).
- Зависимость от данных. В файловых системах все данные, а также их структура жестко прописаны, поэтому любое изменение в данных или в структуре требует значительных усилий для внесения такого изменения.
- Несовместимость форматов файлов. Поскольку структура файла определяется кодом приложения, она также зависит от языка программирования этого приложения. Поэтому зачастую нельзя говорить о совместной обработке файлов, написанных на разных языках.
- Фиксированные запросы/быстрое увеличение количества приложений. С увеличением информации появлялось все большее количество файлов в файловой системе и с течением времени становилось тяжело уже обрабатывать такой объем. Кроме этого, чтобы получить необходимый отчет составлялись фиксированные программы, т.е. писался код программы, а потому для каждого другого отчета также приходилось разрабатывать программу, выполняющую запрос.
Все перечисленные недостатки являются следствием двух факторов:
- Определение данных содержится внутри приложений, а не хранится отдельно и независимо от них.
- Помимо приложений не предусмотрено никаких других инструментов доступа к данным и их обработки.
Для повышения эффективности работы используют базы данных и систему управления базами данных, или СУБД.
База данных – это совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации.
Другими словами, база данных – это единое, большое хранилище данных, которое однократно определяется, а затем используется одновременно многими пользователями.
СУБД – это программное обеспечение, с помощью которого пользователи могут определять, создавать и поддерживать базу данных, а также осуществлять к ней контролируемый доступ.
По-другому, СУБД – это программное обеспечение, которое взаимодействует с прикладными программами пользователя и базой данных и обладает следующими возможностями:
- Позволяет определять базу данных; обычно это осуществляется с помощью языка определения данных (DDL – Data Definition Language). Язык DDL предоставляет пользователям средства указания типа данных и их структуры, а также средства задания ограничений для информации, хранимой в базе данных.
- Позволяет вставлять, обновлять, удалять и извлекать информацию из базы данных, что обычно осуществляется с помощью языка управления данными (DML – Data Manipulation Language). Наличие централизованного хранилища данных и их описаний позволяет использовать язык DML как общий инструмент организации запросов, который иногда еще называют языком запросов. Этот инструмент позволяет снять такую проблему, как фиксированный набор запросов.
Отметим также, что следует различать описание базы данных и саму базу данных. Описанием базы данных является схема базы данных. Схема создается в процессе проектирования базы данных и изменяется, как правило, очень редко.
Как выше уже было сказано БД – это хранилище данных. При этом, как правило, данными могут пользоваться одновременно несколько пользователей. И к тому же, каждому пользователю могут понадобиться разные данные из одной БД. Для удовлетворения этих потребностей архитектура большинства современных баз данных представляет собой трехуровневую структуру.
Трехуровневая архитектура БД
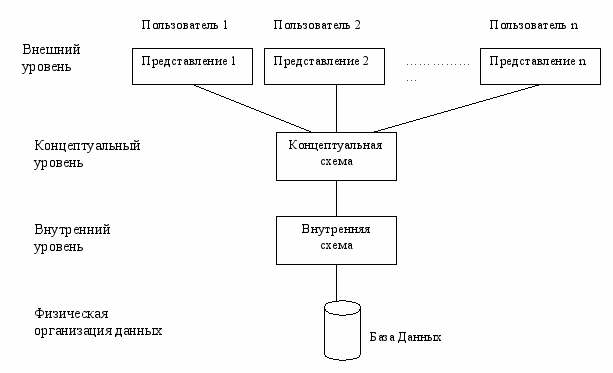
Внешний уровень – это представление базы данных с точки зрения пользователей. Этот уровень описывает ту часть базы данных, которая относится к каждому пользователю.
Концептуальный уровень – это обобщающее представление базы данных. Этот уровень описывает то, какие данные хранятся в БД, а также связи, существующие между ними.
Иными словами, этот уровень содержит всю логическую структуру базы. На данном уровне представлены следующие компоненты:
- Все сущности, их атрибуты и связи;
- Накладываемые на данные ограничения;
- Семантическая информация о данных;
- Информация о мерах обеспечения безопасности и поддержки целостности данных.
Дадим определения некоторых терминов баз данных.
Сущность – это отдельный тип объекта (например, человек, место, вещь, событие и т.д. и т.п.), который необходимо представить в БД.
Атрибут – это свойство, которое описывает некоторую характеристику описываемого объекта.
Связь – это то, что объединяет несколько сущностей.
Пример.
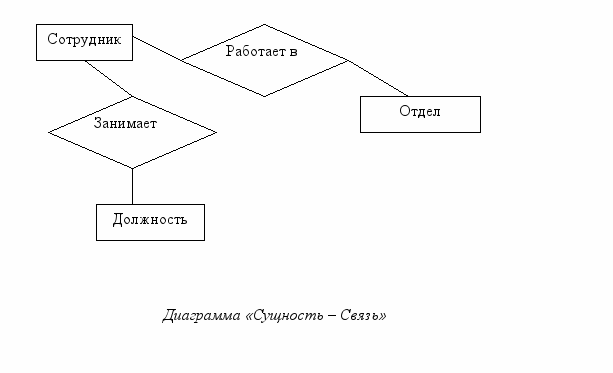
В данном примере отображено 3 сущности: «Сотрудник», «Отдел», «Должность» и две связи: «Работает в» и «Занимает».
Внутренний уровень – это физическое представление базы данных в компьютере. Этот уровень описывает, как информация хранится в базе данных.
На этом уровне хранится следующая информация:
- Распределение дискового пространства для хранения данных и индексов;
- Описание подробностей сохранения записей;
- Сведения о размещении записей;
- Сведения о сжатии данных и выбранных методах их шифрования.
Основным назначением трехуровневой архитектуры является обеспечение независимости от данных, которая означает, что изменения на нижних уровнях никак не влияют на верхние уровни (например, добавление или удаление новых записей никак не влияет на схему БД).
Как уже упоминалось, БД имеет еще схему БД, а потому все эти уровни характерны и для схем БД. Т.е., различают внешнюю схему, концептуальную схему и внутреннюю схему БД.
Иерархические, сетевые и реляционные базы данных.
По моделям представления данных базы данных делят на:
- Иерархические;
- Сетевые;
- Реляционные;
- Объектно-реляционные.
Иерархические БД – это самая первая модель представления данных, в которой все записи базы данных представлены в виде дерева, с отношениями предок-потомок. Такая модель представления данных связана с тем, что на ранних этапах базы данных часто использовались для планирования производственных процессов: каждое выпускаемое изделие состоит из узлов, каждый узел из деталей и т.д. Для того чтобы узнать, сколько и каких деталей необходимо заказать и строили дерево.
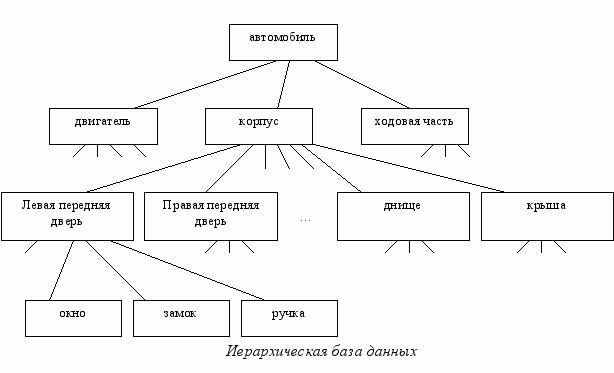
Однако, стоит отметить, что иерархическая БД не является оптимальной. Допустим, что один и тот же тип болтов в автомобиле используется 300 раз в различных узлах. При использовании иерархической модели этот тип болтов будет использоваться не один раз, а 300 (на примере рисунка можно провести аналогию для дверей, где для каждой двери нарисовать свои «окно», «замок», «ручка»). Налицо дублирование информации. Чтобы устранить этот недостаток была введена сетевая модель представления данных.
Сетевая база данных – это база данных, в которых одна запись может участвовать в нескольких отношениях предок-потомок. Т.е. фактически база данных представляет собой не дерево, а граф.
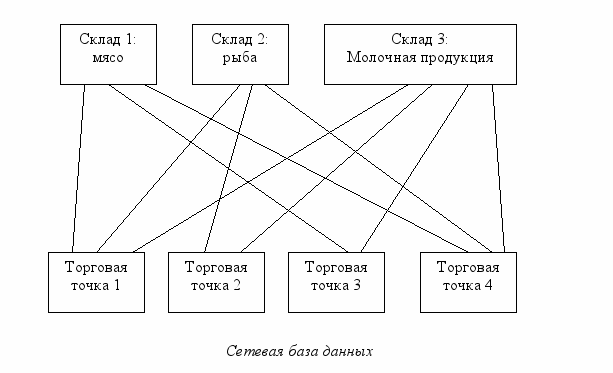
И
Торговая точка 1
иерархическая, и сетевая модель достаточно просты, однако они имеют общий недостаток: для того, чтобы получить ответ даже на самый простой вопрос, программисту необходимо было писать программу, которая бы просматривала базу данных, двигаясь по указателям от записи к записи. И очень часто, пока такая программа писалась, необходимость в получении информации уже отпадала. Поэтому была разработана новая модель данных, а именно: реляционные базы данных.
В реляционной базе данных вся информация представляется в виде таблиц и любые операции над данными – это операции над таблицами. Таблицы состоят из строк и столбцов. Строки – это записи, а столбцы представляют структуру записи (каждый столбец имеет тип данных, длину данных). Строки в столбце не упорядочены, т.е. не существует первой или десятой строки. Однако, поскольку на строки надо как-то ссылаться, то вводится понятие «первичный ключ». Первичный ключ – это столбец, значения которого во всех строках разные. Используя первичный ключ можно однозначно сослаться на какую либо строку таблицы. Отношения предок-потомок в реляционной БД организуется за счет внешних ключей. Внешний ключ – это столбец таблицы, значения которого совпадают со значениями первичного ключа некоторой другой таблицы.
Пример.
Внешний уровень.
| ФИО | Номер сотрудника | Дата рождения | Должность | Отдел | Стаж работы |
| Артемьев А.Н. | 100 | 12.03.1970 | Программист | IT | 5 |
| Воронова А.М. | 51 | 05.12.1975 | Маркетолог | Маркетинг | 2 |
| Григорьев Н.А. | 12 | 06.07.1979 | Программист | IT | 1 |
| Денисова Р.М. | 110 | 10.05.1966 | Бухгалтер | бухгалтерия | 3 |
| Ежов М.А. | 97 | 12.03.1975 | Программист | IT | 4 |
| Королева А.М. | 80 | 15.10.1968 | Бухгалтер | бухгалтерия | 3 |
Концептуальный уровень.
Таблица «Сотрудники»
| ID_sotr | Name_sotr | Num_sotr | Birthday |
| 1 | Королева А.М. | 80 | 15.10.1968 |
| 2 | Артемьев А.Н. | 100 | 12.03.1970 |
| 3 | Денисова Р.М. | 110 | 10.05.1966 |
| 4 | Григорьев Н.А. | 12 | 06.07.1979 |
| 5 | Воронова А.М. | 51 | 05.12.1975 |
| 6 | Ежов М.А. | 97 | 12.03.1975 |
Таблица «Должность»
| ID_staff | Name_staff |
| 1 | Программист |
| 2 | Бухгалтер |
| 3 | Маркетолог |
Таблица «Отдел»
| ID_dep | Name_dep |
| 1 | Бухгалтерия |
| 2 | IT |
| 3 | Маркетинг |
Таблица «Связь»
| ID_sotr | ID_staff | ID_dep | Period |
| 1 | 2 | 1 | 3 |
| 2 | 1 | 2 | 5 |
| 3 | 2 | 1 | 3 |
| 4 | 1 | 2 | 1 |
| 5 | 3 | 3 | 2 |
| 6 | 1 | 2 | 4 |
Внутренний уровень
Таблица «Сотрудники»
| Field | Type | Defaults | Extra | KeyName | Unique |
| ID_sotr | Int(5) | | auto_increment | primary | Yes |
| Name | Char(35) | | | | |
| Birthday | Data | | | | |
и т.д.
Важным моментом является использование значения NULL в таблицах реляционных баз данных. NULL – это отсутствующее значение, отсутствие информации по данной позиции. Не допускается использования 0 или «пробела» вместо NULL, поскольку, например нулевой объем продаж и неизвестный объем продаж – это разные вещи. По этой же причине ни одно значение NULL не равно другому значению NULL и при запросах, группировке, сравнениях и т.д. значения NULL обрабатываются особым образом.
Объектно-реляционные базы данных появились в последнее время у значительного числа производителей СУБД и сочетают в себе реляционную модель данных с концепциями объектно-ориентированного программирования.
Существующие архитектуры СУБД.
По способу организации взаимодействия с базой данных через сеть, СУБД делят на:
- СУБД с централизованной архитектурой;
- СУБД с архитектурой файл-сервер;
- СУБД с архитектурой клиент-сервер;
- СУБД с трехуровневой архитектурой: «тонкий клиент» - сервер приложений – сервер базы данных.
В СУБД с централизованной архитектурой, СУБД и сама БД располагаются и функционируют на центральном компьютере (мэйнфрейме), а пользователи получают доступ к БД при помощи обычных терминалов: компьютер рассматривается просто как устройство ввода и отображения информации: на мэйнфрейм передаются нажатия клавиш, в обратном направлении передаются данные, отображаемые непостредственно на мониторах пользователей.
В СУБД с архитектурой файл-сервер база данных хранится на сервере, а копии СУБД устанавливаются на компьютерах пользователей. Файл базы данных, находящийся на сервере, совместно используется всеми пользователями одновременно, при помощи сетевого программного обеспечения и самой операционной системы. Такая архитектура позволяет добиться приемлемой производительности, т.к. в распоряжении каждой копии СУБД находятся все ресурсы компьютера пользователя. С другой стороны, производительность такой схемы для каждого пользователя зависит от характеристик компьютера пользователя. Кроме этого, такая архитектура значительно нагружает работу сети, поскольку при такой схеме пользователю передается вся копия БД.
При архитектуре клиент-сервер база данных хранится на сервере, а СУБД подразделяется на две части: клиентскую и серверную. Клиентская часть СУБД выполняется на стороне пользователя (клиента) и обеспечивает интерактивное взаимодействие с пользователем и формирование запросов к БД (на языке SQL). Серверная часть работает на сервере и взаимодействует с БД, обеспечивая выполнение запросов клиентской части. При этом пользователю будут переданы только запрашиваемые строки, а не вся БД. Недостаток заключается в том, что ели необходимо часто изменять деловую логику, то приходится переделывать и переустанавливать клиентскую часть. Если рабочих мест много, то это уже несет большие затраты.
При трехуровневой архитектуре в функции клиентской части («тонкий клиент») входит только интерактивное взаимодействие с пользователем, а вся деловая логика вынесена на сервер приложений, который собственно и обеспечивает формирование запросов к БД, передаваемых на выполнение серверу БД. «Тонкий клиент» чаще всего находится на стороне пользователя и представляет собой Web-броузер с применением в соответствующей HTML-странице Java-апплетов или компонентов ActiveX. Сервер приложений находится на сервере и может являться специализированной программой или обычным web-сервером, который вызывает для обработки запроса внешнюю программу CGI.
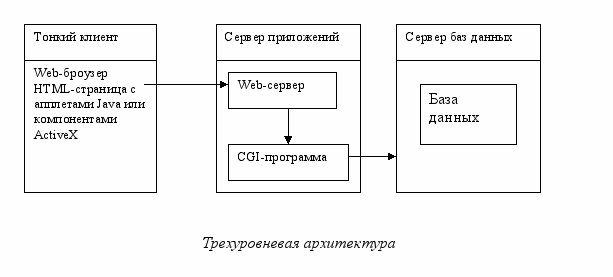
Преимущества трехуровневой архитектуры очевидны: при необходимости изменений в деловой логике, изменения вносятся на сервере приложений, переустанавливать клиентские части не надо.