
Рабочая программа дисциплины по специальности магистратуры 230100 «Информатика и вычислительная техника» Курс 2
| Вид материала | Рабочая программа |
- Образовательный стандарт по направлению 230100. 62 Информатика и вычислительная техника, 328.94kb.
- Рабочая учебная программа дисциплины Моделирование рассуждений (наименование дисциплины), 166.66kb.
- Рабочая программа учебной дисциплины днн. 02 Современные научные проблемы автоматизированных, 221.23kb.
- Рабочая учебная программа по дисциплине вычислительная математика специальность: 230100, 133.73kb.
- Рабочая учебная программа по дисциплине «Базы данных» Направление №230100 «Информатика, 115.03kb.
- Программа государственного экзамена по направлению 230100 «Информатика и вычислительная, 60.5kb.
- Рабочая программа по курсу «Высокопроизводительные вычислительные системы» по направлению, 95.97kb.
- Образовательный стандарт по направлению 552800 «Информатика и вычислительная техника», 168.8kb.
- Рабочая учебная программа по дисциплине «Информатика» Направление №230100 «Информатика, 91.73kb.
- Образовательный стандарт по направлению бакалавриата 552800 (230100) «Информатика, 288.84kb.
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
Государственное образовательное учреждение
высшего профессионального образования
«ХАКАССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
им. Н.Ф.КАТАНОВА»
_______________________________________________________________________
Кафедра Программного обеспечения, вычислительной техники, и автоматизированных систем (ПОВТиАС)
ДВМ.02
Автоматизированные информационно-поисковые системы
Рабочая программа
дисциплины по специальности магистратуры 230100 «Информатика и вычислительная техника»
Курс 2
Учебный план набора 2010 года
Форма обучения: очная
Общая трудоемкость дисциплины по ГОС СПО: 150 часов
20011 г.
1. Рабочая программа составлена в соответствии с ГОС ВПО по направлению подготовки специальности магистратуры 230100 «Информатика и вычислительная техника»
(код и наименование)
утвержденного ______________________________________________________________________.
(дата)
2. Разработчик рабочей программы
профессор____ ПОВТиАС_ ____________ Яцко Вячеслав Александрович
(должность) (кафедра) (подпись) (ФИО)
3. УТВЕРЖДЕНА на заседании кафедры
ПОВТиАС
(наименование кафедры)
_______________________ протокол № ___________
(дата)
Зав. кафедрой_______________________ Швец Срегей Викторович
(подпись) (ФИО)
ПЕРЕУТВЕРЖДЕНА на заседании кафедры __________________________________________________________________________________
(наименование кафедры)
_______________________ протокол № ___________
(дата)
Зав. кафедрой_______________________ _______________________________________________
подпись) (ФИО)
4. Рабочая программа СОГЛАСОВАНА с выпускающими кафедрами; СООТВЕТСТВУЕТ действующему учебному плану.
Зав. выпускающей кафедрой __________________ ________________________________
(подпись) (ФИО)
_________________________________________
(дата)
5. В рабочую программу внесены изменения и дополнения на заседании кафедры ______________________
_____________________________________________ протокол № ____ дата __________________________
Зав. кафедрой_______________________________ ________________________________________________
(подпись) (ФИО)
Пояснительная записка
- Цели учебной дисциплины.
Данная программа предназначена для магистрантов 2 курса Института информатики и телематики Хакасского государственного университета им. Н.Ф.Катанова, обучающихся по специальности 552800 - Информатика и вычислительная техника. Программа может быть использована магистрантами в процессе подготовки к лекциям, лабораторным занятиям, а также для самостоятельной работы по курсу.
Цель курса – ознакомить магистрантов с предметной областью теории информационного поиска и лингвистической информатики. Лекционный курс охватывает её основные разделы: теорию индексирования, теорию реферирования, теорию кластеризации социтирования, теорию логико-смыслового моделирования.
2. «Требования к уровню освоения содержания дисциплины»
После прохождения обучения магистрант должен:
а) иметь представление о:
– подходах к интерпретации понятия "информация" в различных областях знания;
– принципах системного подхода как общенаучного метода исследования;
– основных этапах исторического развития теории и практики информационного поиска;
– особенностях анализа иерархической и тематической структуры текста;
б) знать:
– законы Бредфорда и Ципфа;
– признаки понятия "информационно-лингвистическая модель";
– структуру лингвистической информатики;
– основные понятия теории индексирования и теории реферирования;
– архитектуру и алгоритмы функционирования автоматизированных информационно-поисковых систем (АИПС);
– архитектуру и алгоритмы функционирования автоматизированных информационно-поисковых систем Интернета (ИАИПС);
– архитектуру и алгоритмы функционирования систем автоматического реферирования различных уровней.
– основные критерии оценки эффективности функционирования АИПС, ИАИПС и систем автоматического реферирования;
– алгоритмы лексического анализа, аннотирования и декомпозиции текста.
в) уметь применять:
– методы разработки информационно-поисковых систем;
– методы составления словарей тематической и нетематической лексики;
– методы и алгоритмы взвешивания терминов;
– методы оценки эффективности функционирования АИПС и систем автоматического реферирования.
«Место дисциплины в профессиональной подготовке выпускника»
Особенностью курса является акцент на теорию и методы информационного поиска, изучение которых позволит магистрантам приобрести как теоретические знания, так и практические навыки, позволяющие уверенно ориентироваться в современной информационной среде.
Курс "Автоматизированные информационно-поисковые системы" изучается в 3 семестре и включает 16 лекционных часов, и 16 часов лабораторных занятий. В процессе лекционных занятий студенты знакомятся с основными понятиями и принципами изучаемых разделов лингвистической информатики, критериями их дифференциации, закономерностями и методами соответствующих областей деятельности. Лабораторные занятия направлены на закрепление теоретического материала; в процессе лабораторных занятий применяются на практике принципы и методы информационного поиска.
Курс " Автоматизированные информационно-поисковые системы" предполагает связь с такими дисциплинами, как: "История информатики и вычислительной техники", "Информационные технологии в науке и образовании", "Современные направления развития информатики".
Изучение курса завершается зачётом, в процессе которого студенты должны проявить знание основных понятий, указанных в плане лекций, ответить на контрольные вопросы и выполнить тест.
"Автоматизированные информационно-поисковые системы"
Организационно-методический план
Таблица №1
| Вид учебной работы | Количество часов |
| I. Аудиторная: | |
| 1.1 Лекции | 16 |
| 1.2. Лабораторные работы | 16 |
| ИТОГО: | 32 |
| II. Внеаудиторная: | |
| 2.1. Рефераты | 10 |
| 2.2. Самостоятельное изучение тем разделов | 40 |
| 2.3. Домашние контрольные работы | 40 |
| 2.4. Проработка и повторение лекционного материала и учебных пособий | 10 |
| 2.5. Подготовка к зачету | 18 |
| ИТОГО: | 118 |
| III. Промежуточный и итоговый контроль по дисциплине (экзамен, зачет): | |
| Зачет | |
| ИТОГО: | |
| Общая трудоемкость дисциплины | 150 |
Тематический план учебной дисциплины
| Наименование разделов и тем курса | Количество часов | ||||
| Всего | Аудиторные занятия | Самос- тоятель-ная работа | |||
| лекции | лабора-торные | практичес кие | |||
| 1 | 2 | 3 | 4 | 5 | 6 |
| Семестр 3 | | | | | |
| 1. Алгоритмы и программы автоматического анализа текста. Морфологический анализ и аннотирование | | 2 | 4 | | 20 |
| 2. Алгоритмы и программы автоматического анализа текста. Аннотирование и взвешивание терминов | | 2 | | | 20 |
| 3. Алгоритмы и программы автоматического анализа текста. Декомпозиция и синтаксический парсинг | | 2 | | | 8 |
| 4. Индексирование как вид информационно-лингвистического моделирования. ИПС и ИПЯ | | 3 | 4 | | 10 |
| 6. Особенности информационно-поисковых систем Интернета | | 2 | | | 14 |
| 7 Лексикографические ресурсы и закономерности | | 2 | 4 | | 12 |
| 8. Системы автоматического реферирования. | | 3 | 4 | | 14 |
| ИТОГО: | 150 | 16 | 16 | 0 | 118 |
Содержание лекционного курса
"Автоматизированные информационно-поисковые системы"
Лекция 1
NLP. Алгоритмы и программы автоматического анализа текста и уровни языковой системы. Морфологический анализ. Стемминг и стеммеры. Алгоритмические и словарные стеммеры. Недостаточное и избыточное стеммирование. Y- стеммер. Отличие стемминга от лемматизации.
Понятие лексической декомпозиции и токена. Особенности токенизации. Необходимость распознавания единиц больше и меньше чем слово.
Аннотирование. Понятие POS-тегов. Теггеры,основание на правилах и стохастические теггеры. Алгоритм двунаправленной инференции. Семантические и когнитивные теги. Использование семантических тегов в фактографических ИПС. Использование когнитивных тегов в системах интеллектуального анализа текста.
Лекция 2.
Аннотирование. Понятие POS-тегов. Теггеры,основание на правилах и стохастические теггеры. Алгоритм двунаправленной инференции. Обобщённая архитектура POS-теггера.
Семантические и когнитивные теги. Использование семантических тегов в фактографических ИПС. Использование когнитивных тегов в системах интеллектуального анализа текста.
Алгоритмы взвешивания терминов и фильтры. Интертекстуальные и интратекстуальные методы взвешивания. Определение вероятностных величин. Проблема сопоставления с эталонным корпусом. Алгоритм TF*IDF и возможности его применения для фильтрации стоп слов и классификации и категоризации текстов.
Лекция 3.
Понятие n-gram: биграмм, триграмм, тетраграм. Алгоритм распознавания n-gram в тексте. Возможности использования n-gram для автоматической классификации текстов.
Понятие синтаксического парсинга. Распознавание иерархической структуры предложения на основе выделения словосочетаний. Lexparser (Стэнфордский университет). Значение парсинга для моделирования структуры текста.
Программы-чанкеры. Значение распознавания словосочетаний различных типов. Noun-phrase chankers.
Понятие клаузы. Алгоритмы распознавания клауз. Значение разбивки текста на клаузы для моделирования его логико-семантической структуры.
Лекция 4.
Дискурсивный анализ текста. Понятие дискурса в системах автоматической обработки текста. Значение разрешение анафоры для систем реферирования и ИПС. Алгоритмы и правила разрешения анафоры. Семантическая структура текста и концепция У. Манна. Программа RST-Tool.
Лексикографические ресурсы для систем NLP. Онтологии, словари и тезаурусы. Структура тезауруса WordNet. Значение использования тезаурусов в ИПС и системах реферирования.
Закономерности предметной области. Закон Ципфа, его предсказательная сила. Закон Брэдфорда. Трактовка информации в кибернетике и информатике; различия между объёмным и вероятностными подходами к определению количества информации. Методика расчёта количества информации для текстов.
Лекция 5
Историческое развитие предметной области. Т.Кун и закономерности исторического развития научных дисциплин. Историческое развитие лингвистической информатики.
Александрийская библиотека и первые рефераты; появление реферативных журналов в XIX веке. М. Дюи и универсальная десятичная классификация (1873). Г.Тейлор и механизация информационного поиска с помощью перфокарт. Появление первых систем автоматического индексирования. Г.Лун и системы автоматического реферирования. А.И.Михайлов, А.И.Черный, Р.С.Гиляревский и термин "информатика" в 60-е гг. ХХ века. Кластеризация социтирования и логико-смысловое моделирование в 70-х гг. ХХ века.
Информационный взрыв конца ХХ века, его особенности. Интеграционные тенденции в современной лингвистической информатике.
Лекция 6
Предметная область лингвистической информатики.
Признаки информационно-лингвистических моделей (ИЛМ). Отличие информационно-лингвистических моделей от лингвистических и информационных моделей. Виды ИЛМ: лексико-семантические, логико-грамматические, дискретные, непрерывные. Виды информационно-лингвистического моделирования.
Гносеологический и онтологический планы лингвистической информатики. Единство онтологического плана лингвистической информатики,
Соотношение лингвистической информатики со смежными дисциплинами. Значение терминов "компьютерная лингвистика", "прикладная лингвистика", "корпусная лингвистика", "информатика", "прикладная информатика".
Лекция 7
Индексирование как вид информационно-лингвистического моделирования. Понятие информационно-поискового языка (ИПЯ). Дескрипторные и классификационные ИПЯ. УДК как пример классификационного языка. Ключевые слова и дескрипторы; информационно-поисковые тезаурусы. Понятие нормализации и примеры нормализации.
Основные процедуры, выполняемые в процессе индексирования. Структура базы данных АИПС; первичные и вторичные документы. Поисковый образ; поисковое предписание как поисковый образ запроса (ПОЗ). Критерий смыслового соответствия и формула его вычисления. Интерпретация индексирования в терминах теории множеств.
Алгоритмы взвешивания терминов в процессе индексирования: tf/idf, хи-квадрат.
Архитектура классической АИПС.
Документальные, фактографические, информационно-логические АИПС.
Лекция 8
Оценка эффективности функционирования АИПС. Понятия пертинентности, релевантности, полноты и точности поиска, информационного шума, потери информации.
Количественные методы определения информационного шума и потерь информации; коэффициенты полноты и точности поиска. Информационно-поисковые системы Интернета (ИАИПС).
Особенности электронных баз данных и поведения пользователей Интернета. Виды ИАИПС: предметные каталоги и индексные ИАИПС, их особенности; распределённые ИАИПС типа Copernic; мета- ИАИПС.
Архитектура индексных ИАИПС и её отличие от архитектуры традиционных АИПС; особенности функционирования поисковой машины и робота-индексировщика. Полнотекстовые базы данных; понятия инвертированного файла и пост-листов.
Способы повышения эффективности функционирования АИПС: двухступенчатость выдачи, эшелонирование выдачи, приписывание весовых коэффициентов дескрипторам.
Кластеризация социтирования; понятия кластера и социтирования, примеры кластеров социтирования. Значение кластеризации социтирования для отслеживания развития научных идей и научной дисциплины. Г.Смолл, Ю.Гарфилд, И.В.Маршакова.
Гипертекстовые системы. Примеры гипертекстов. М.М.Субботин и логико-смысловое моделирование.
Темы лабораторных работ
- Интерпретация понятия информации в кибернетике и информатике. Подсчёт количества информации с точки зрения двух подходов.
- Методы взвешивания терминов, статистические и позиционные параметры. Взвешивание по алгоритму tf/idf. Взвешивание терминов и распределения закона Ципфа.
- Общая характеристика и алгоритмы функционирования современных систем автоматического реферирования текста. Метод симметричного реферирования.
- Методы оценки качества современных систем автоматического реферирования текста. Метод сопоставления с эталонным словарём. Метод сопоставления с эталонным рефератом.
Программа самостоятельной познавательной деятельности студента
Текущий и итоговый контроль
Текущий контроль осуществляется на лабораторных занятиях в виде опроса, письменных тестов по основным темам, а также в ходе выполнения работ над ошибками и написания рефератов.
На завершающем этапе формой контроля является семестровый компьютерный тест соответственно. Компьютерный тест состоит из заданий.
Темы рефератов
1. Соотношение между законами Бредфорда и Ципфа
–ЧУРСИН Н Законы царства документов rg/ri/ch/pi05.htm
–И.В. Успенский ИНТЕРНЕТ-МАРКЕТИНГ Учебник.- СПб.: Изд-во СПГУЭиФ, 2003 oks/m80/4.htm
–Попов А. Поиск в Интернете -- внутри и снаружи. Эффективная методика поиска информации в сети Интернет rum.ru/pp/search_03.shtml
2. Структура и функционирование АИПС
–Информатика и программирование. Часть 2. krgtu.ru/do/3e/infnprog/infnprog/part2.php">
–Медведева Г.А. Из опыта РГАНТД по вопросам влияния использования на структуру ––НСА /n_tr/med2.htm
–Розина И.Н., Соколова О.И Поиск информации в интернет на основе автоматизированных информационно-поисковых систем. ru/resource/sok_roz.php
–Ягджан В.Г., Джавадян А.Ю. Методика построения интеллектуальной информационно-поисковой системы , основанной на модульно- распределённой архитектуре // НТИ. Сер.2. 2002. № 2 С. 20-24
3. Системный подход в информатике
–Нестеров А.В. Философия систем // НТИ Сер.1. 2002. № 4. С.1-8.
–Исупова З.Г. Системный подход как метод познания мира. Екатеринбург, 1997 /monika/doklad/view/zip-1271-1.php
–Введение в системный подход pb.ru/publications/other/metodology/introduction_in_system_approach.shtml
–Системный подход при изучении физической картины мира. e.ru/book/id=4018
4. Индекс цитирования и ранжирование страниц Интернета
–Индекс цитирования Яндекса x.ru/info/cy.php
–Индекс цитирования. Роль индекса цитирования в раскрутке сайта. usiness.ru/bizinet/st31.htm
–Как поднять Индекс цитирования сайта в поисковых системах sterpro.com.ua/pro/3/31_1.php
–Менделеев Д. Эволюция релевантности сайтов. От индекса цитирования до "Subject-Specific PopularitySM" searchengines/link_popularity.php
–Индекс цитирования и PageRank web.ru/blogs/posts/798.php?sid=
–Плющ М.А. О некоторых предпосылках создания указателя цитирования научной литературы // НТИ. Сер1. 2003. № 7. С. 18-22.
5. Различные подходы к интерпретации информации
–Горшков В.В. и др. Информация в живой и неживой природе // НТИ. Сер. 1. 2001. № 5. С. 1-6
–Курбаков К.И. Компьютика, информатика, информациология: проблемы различия и соотношения // НТИ. Сер1. 2003. № 2. С.1-5.
–Бриллюэн Л. Наука и теория информации. — М.: Физматгиз, 1960.
–Быховский А. Информация и живые организмы// Наука и жизнь. — 1976. — N8.
–Суханов А.П. Мир информации. — М.: Мысль, 1986.
–Урсул А.Д. Проблема информации в современной науке. Философские очерки. М.: Наука, 1975.
6. Проблемы категоризации текстов в процессе информационного поиска
–Харламов А. Автоматический структурный анализ текстов u/os/2002/10/062.htm
–Реализация и области применения системы ВААЛ-2000 ru/proekt/vaal2000.php
-Волкова И.А. Программный комплекс для лингвистической обработки текстов на русском языке g-21.ru/archive_article.asp?param=7530&y=2002&vol=6078
–Компьютерный корпус текстов русских газет конца XX-ого века l.msu.ru/~lex/corpus/corp_descr.php
–Кулик С.Д. Исследование поискового робота для фактографического поиска // НТИ Сер.2. 2003. №.3. С.21-27.
7. Оценка эффективности функционирования АИПС Интернета
–Терещенко С.С. Тенденции развития автоматизированных информационных систем // НТИ. Сер.1. 2001. № 6. С. 8-18.
–Кулик С.Д. Исследование поискового робота для фактографического поиска // НТИ Сер.2. 2003. №.3. С.21-27.
-Миронов Г.А. Способы повышения качества информационного обслуживания в сетях (Интернете) // НТИ. Сер.1. 2001. №3. С.10-17.
–Антонов А.В. ИПС Galaktika ZOOM с элементами анализа на гипермассивах информации // НТИ. 2001. № 8 . С.12-20.
8. Проблемы разработки информационно-поисковых тезаурусов
–Архангельская В.А. Информационно-поисковый тезаурус по экономике и демографии // НТИ. Сер.1. 2001. № 7. С 24-32.
–Принципы составления списков основных ключевых слов по различным отраслям науки и техники // НТИ.Сер.1. 2002. № 12. с. 20-22.
–Скороходько Э.Ф. Роль системно-и – текстообразующих характеристик термина в частотном индексировании научных текстов // НТИ. Сер.2. № 8. 2002. С. 1-7.
9. АИПС "Коперник" и поиск через интранет.
–Copernic 2000 Первый среди равных p.ua/ru/manuals/EncInternet/ch3cop2000.htm
–Copernic - еще одно средство "интеллектуального поиска" в Интернете u/news/it/soft/01/09/10_002.htm
-Орлов С. Copernic + браузер = лучший поисковый инструмент rod.ru/release32/pub/copernic.htm
10. Структурно-тематическое реферирование в концепции Н.В.Лукашевич
–Лукашевич Н.В. Добров Б.В. Структурное аннотирование rg.uk/siggroup/nalatran/mtreview/mtr-11/mtr-11-8.htm
-Автоматическое аннотирование www.cir.ru
-*Loukashevitch N. V. Dobrov B.V. Construction of structural thematic summary of text // Proceedings of the 1st workshop on text, speech, dialogue. Brno, 1998.- P.85-90.
–Н. В. Лукашевич Б. В. Добров Ттезаурус русского языка для автоматической обработки болтьших текстовых коллукцийg-21.ru/archive_article.asp?param=7619&y=2002&vol=6078
-Loukachevitch N., Dobrov B., Thesaurus-Based Structural Thematic Summary in Multilingual Information Systems // Machine Translation Review. 2000. No. 11. P. 10-20. rg.uk/siggroup/nalatran/mtreview/mtr-11/mtr-11-8.htm
-Лукашевич Н.В., Добров Б.В.Исследование тематической структуры текста на основе большого лингвистического ресурса. g-21.ru/archive_article.asp?param=6521&y=2000&vol=6078
11. Некоторые особенности современных систем автоматического реферирования.
–InnerSpace Company, Smart Search System , 2001. space.ru
–Textar. Golden Key, 1998. r.ru/gkey.php
–ЗАО «Компания CPS». Либретто, 2001. u/vendors_ru/medialing/libretto.shtml
–SoftLine. МЛ Аннотатор 1. 0 для Windows 95 и Windows NT, 2001. ine.ru/products/MediaLingua/MLAnnotator/MLAnnotator1Win_full.asp
–Inxight — ht.com/
–Prosum Summarizer — labs.bt.com/cgi-bin/prosum/prosum
–Extractor — c.ca/II_public/extractor.php
–TextAnalyst — ru/~analyst/
12. Индикативные и информативные рефераты
–Яцко В.А. Логико-лингвистические проблемы анализа и реферирования научного текста. Абакан: Изд-во ХГУ. – 1996 г.
–**Saggion H., Lapalme G. Selective analysis for automatic abstracting: evaluating indicativeness and accessibility.
–* РЖ "Информатика"
13. Классификация рефератов и методов реферирования
–Хан У., Мани И. Системы автоматического реферирования, 15.12.2000. u/os/2000/12/067.htm
–Яцко В.А. Симметричное реферирование: теоретические основы и методика // НТИ. Сер.2. 2002. № 5. С.18-28
–Кристи Эссик Документ - это еще не информация u/cw/1998/25/31.htm
–Дёмин В.А. Re-Fine: средство интеллектуального анализа текстов на основе методологии воссоздания объектов g-21.ru/archive_article.asp?param=6879&y=2001&vol=6078
–Блюменау Д.И., Афанасова Л.Н. Индикаторный метод компьютерного свертывания в процессе обучения аналитико-синтетической переработке информации .ru/win/ntb/ntb2001/12/f12_03.htm
Пример заданий итогового компьютерного теста:
Подчеркните правильный вариант
- Т.Кун (T.Kuhn) –
-известный британский ученый
- известный немецкий ученый
- известный американский ученый
- . Т.Кун (T.Kuhn) раскрыл
-закономерности развития информатики
- закономерности развития научных дисциплин
- закономерности рассеяния информации
- Основным понятием концепции Т.Куна является
- понятие энигмы
- понятие парадигмы
- крипточипа
- Понятие информации отображается с помощью
- логического треугольника
- философского треугольника
- семантического треугольника.
- Количество информации, вычисленное на основе объёмного подхода
- больше количества информации, вычисленного на основе вероятностного подхода
- меньше количества информации, вычисленного на основе вероятностного подхода
- всегда равно количеству информации, вычисленного на основе вероятностного подхода
- Термин «информатика» был введён в
- 1966 г.
-1961 г.
- 1956 г.
- Одним из авторов, которые ввели термин «информатика», был
- Гиляровский
- Гиляревский
- Голяровский
- Чанкеры (Chunkers) – это
- программы для распознавания слов
- программы для распознавания словосочетаний
программы для распознавания структуры предложения
- Предварительная обработка текста включает
- стемминг
- взвешивание терминов
- генерацию выходного текста
- Теггеры – это программы для
- морфологического анализа
- синтаксического анализа
- аннотирования
- М.Портер (M.Porter) разработал одноимённый
- стеммер
-теггер
-парсер
- Алгоритм tf/idf позволяет фильтровать
- стоп слова
- собственные имена
- нарицательные имена
- Хи-квадрат применяется для
- вычисления частотностей
- вычисления смыслового соответствия
- вычисления весовых коэффициентов
- Эшелонирование выдачи предусматривает
- двуступенчатость
- разбивку результатов на группы по релевантности
- приписывание весовых коэффициентов
- Точность поиска определяется соотношением между
- ПОЗ и ПОД
- количеством релевантных документов в выдаче и в базе данных
- количеством релевантных документов в выдаче и общим количеством документов в выдаче
- Потери информации происходят, если
- не выдаётся релевантная информация, содержащаяся в базе данных
- выдаётся релевантная информация, содержащаяся в базе данных
- выдаётся нерелевантная информация, содержащаяся в базе данных.
- Величина R применяется для
- определения соответствия между ПОЗ и ПОД
- определения соответствия между ИПЯ и ИПС
- определения соответствия между ИПС и АИПС
- Алгоритм двунаправленной инференции применяется в
- стеммере
- теггере
- парсере
- Под инференцией понимается
- логический вывод
- наложение радиоволн
- помехи
- Информационный шум имеет место если
- не выдаётся релевантная информация, содержащаяся в базе данных
- выдаётся релевантная информация, содержащаяся в базе данных
- выдаётся нерелевантная информация, содержащаяся в базе данных.
- Дж.Ципф (J. Zipf) открыл
- закон рассеяния информации
- закон распределения информации по документальным источникам
- зависимость между рангом слова и его частотностью
- Пост-листы используются
- в полнотекстовых базах данных
- в двухуровневых базах данных
- в СУБД
- Наиболее распространены
- документальные ИПС
- классификационные ИПС
- фактографические ИПС
- Query parser применяется в ИПС для
- индексирования
- реферирования
- морфологического анализа
- Принцип контактной связи применяется для
- повышения когерентности выходного текста
- повышения релевантности
- повышения пертинентности
1. В чём различие между формулами Хартли и Шеннона? Для чего применяются эти формулы?
Формула Хартли
H = log2 N
Формула Шеннона

2. Назовите различия между вероятностным и объёмным подходами к измерению количества информации.
3. Опишите семантический треугольник. Что он репрезентирует?
Семантический треугольник Огдена – Ричардса (Ogden-Richards)
З
 нак (сигнификат)
нак (сигнификат)Значение Обозначаемый объект (денотат)
интенсионал экстенсионал
4. Кто разработал УДК? Для чего она применяется?
5. Опишите закон Бредфорда. Для чего он применяется?
N=J1/J=J2/J1
R= 220/8=27.5, R1= 220/40=5.5, R2=220/200=1.1.
N1=R/R1=R1/R2. N=27.5/5.5=5.5/1.1=5; N=N1
6. Опишите закон Ципфа Для чего он применяется?
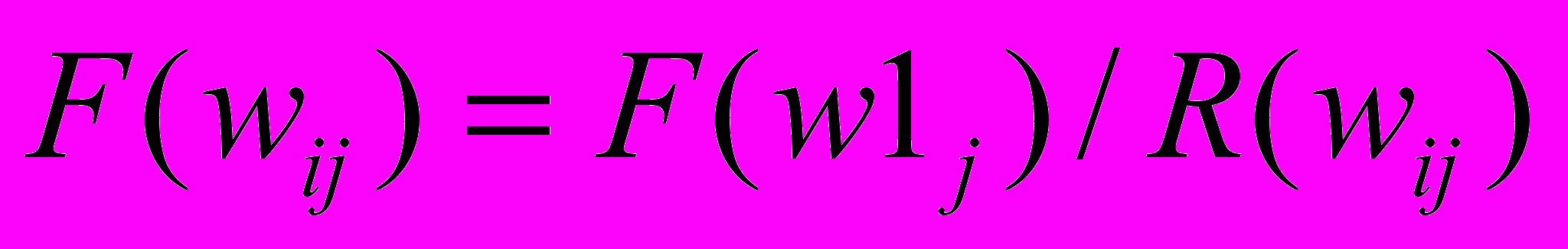
Ранг частотность
W1 1 7000
W2 2 3500 = 7000/2
W3 3 2333= 7000/3
7. Для чего применяется интерпретация закона Ципфа?
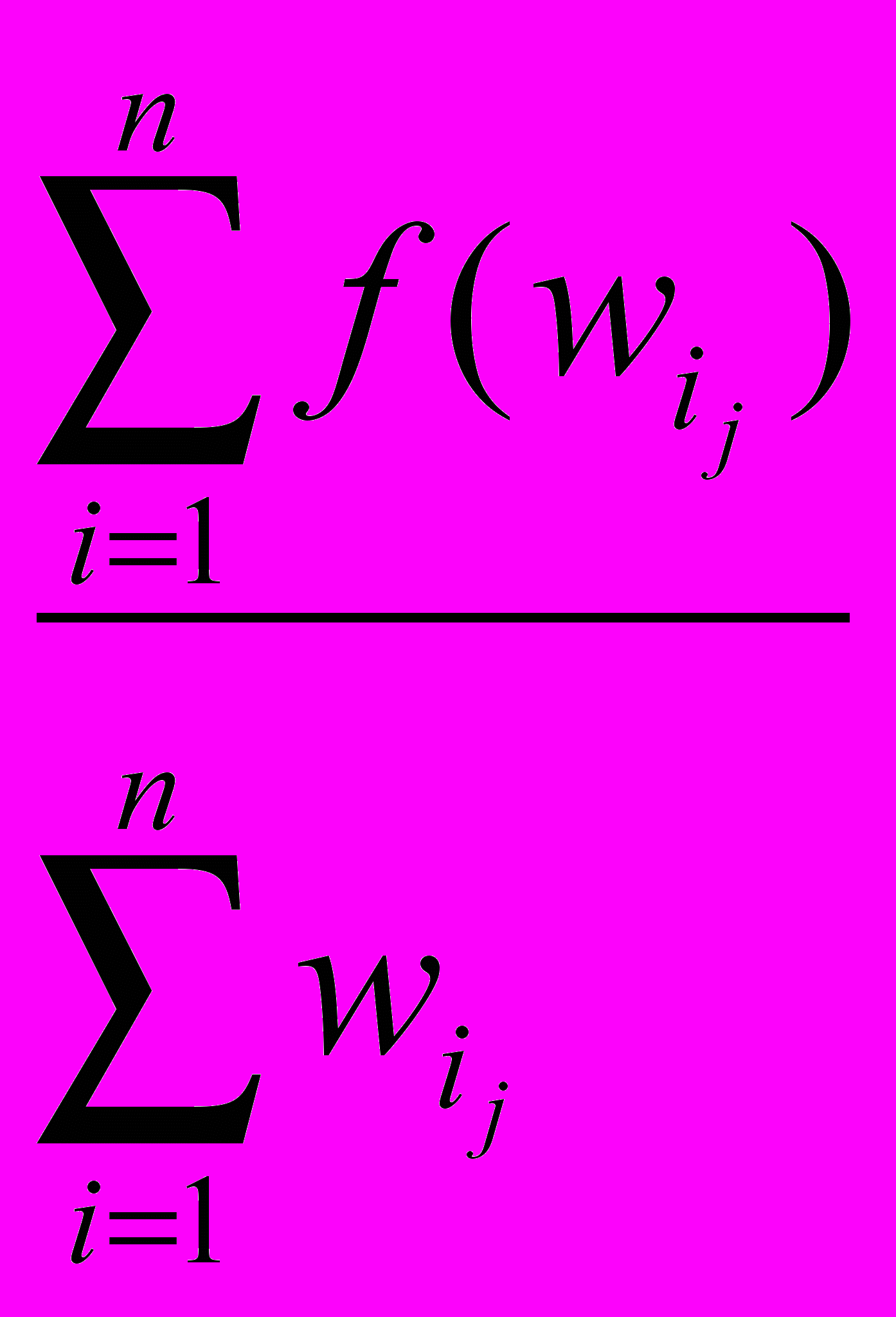 =K
=K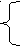
wij
 S if
S iff (wij) К,
где f – частотность лингвистической единицы wi в документе j – ом, а S – некоторое множество отбираемых лингвистических единиц.
8. Что такое кластер социтирования? Для чего применяется кластеризация социтирования?
9.Когда появился и как интерпретировался термин "информатика" в СССР?
10. Каковы особенности информационного взрыва 90-х гг. ХХ века?
Лингвистические алгоритмы
| N atural L anguage P rocessing | Algorithms | programs | Levels | URL |
| stemming | stemmers | Morphological | ссылка скрыта | |
| Lemmatization | Lemmatizers | ссылка скрыта | ||
| tokenization | tokenizers | lexical | ссылка скрыта | |
| Tagging | taggers | ссылка скрыта | ||
| Term-weighting | weighting filters | ссылка скрыта | ||
| word/string matching | comparers | ссылка скрыта | ||
| chunking | chunkers | Syntactic | ссылка скрыта | |
| Parsing | Parsers | ссылка скрыта | ||
| syntactic decomposition | Text splitters clause splitters | ссылка скрыта | ||
| ссылка скрыта | ||||
| discourse segmentation | discourse segmenters | discoursive | ссылка скрыта |
11. Объясните смысл формулы TF*IDF Gerald Salton. Для чего она применяется?
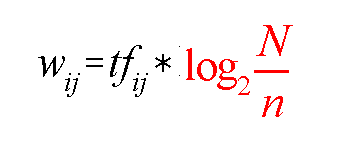
12. В чем состоит недостаток классификационных ИПЯ?
6 техника
63 сельское хозяйство
- Полеводство
- хлебные злаки. Зерновые
- хлебные злаки. Зерновые
- орудия, машины
- уборка урожая
13. Чем отличается дескриптор от ключевого слова?
14 Что такое стемминг и стеммер? Каковы виды стеммеров? С какой целью проводится морфологический анализ в процессе информационного поиска
15. Что такое критерий смыслового соответствия в ИПС?
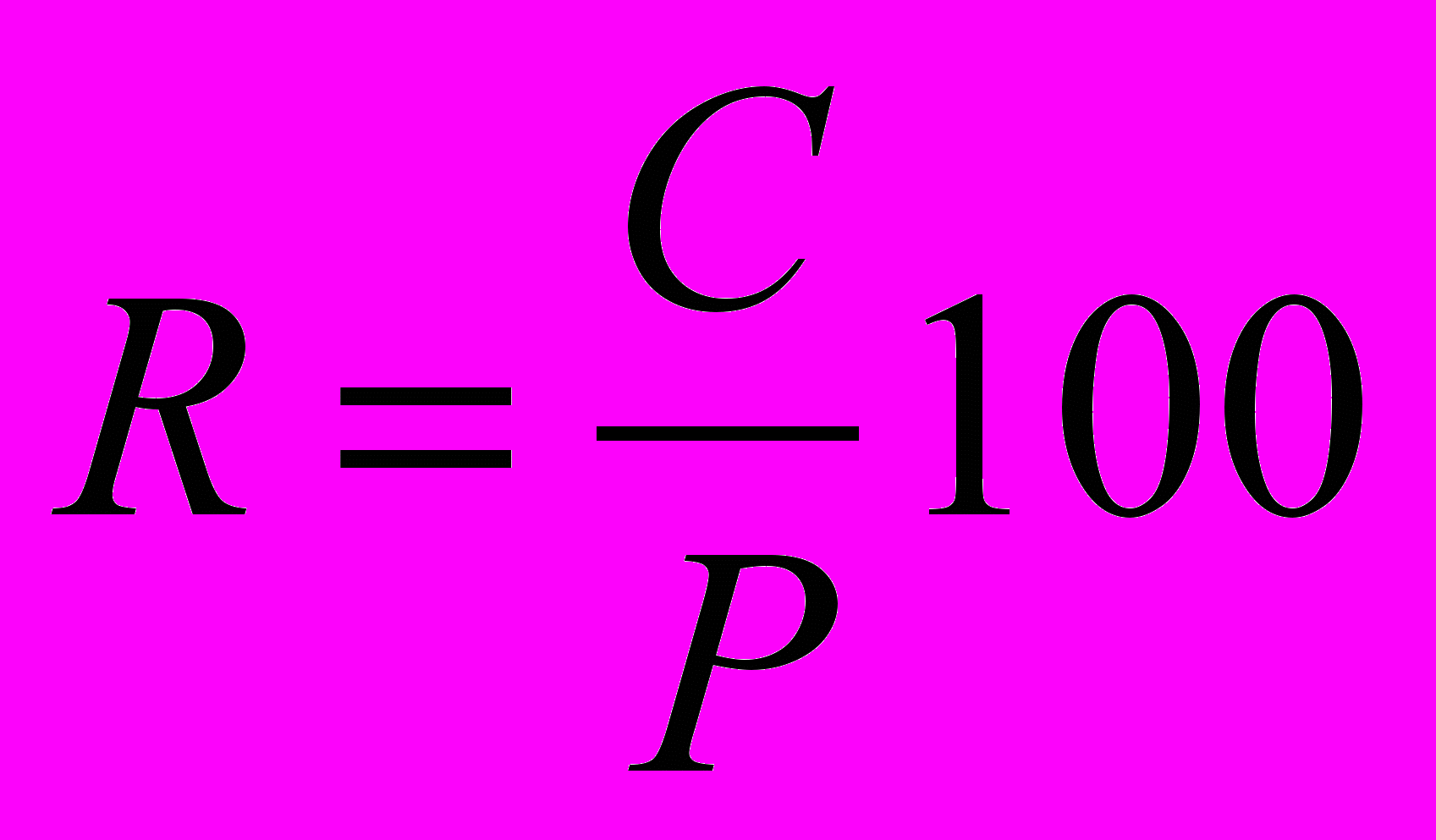
Что такое точность поиска? Что такое полнота поиска? Опишите способы повышения эффективности поиска.
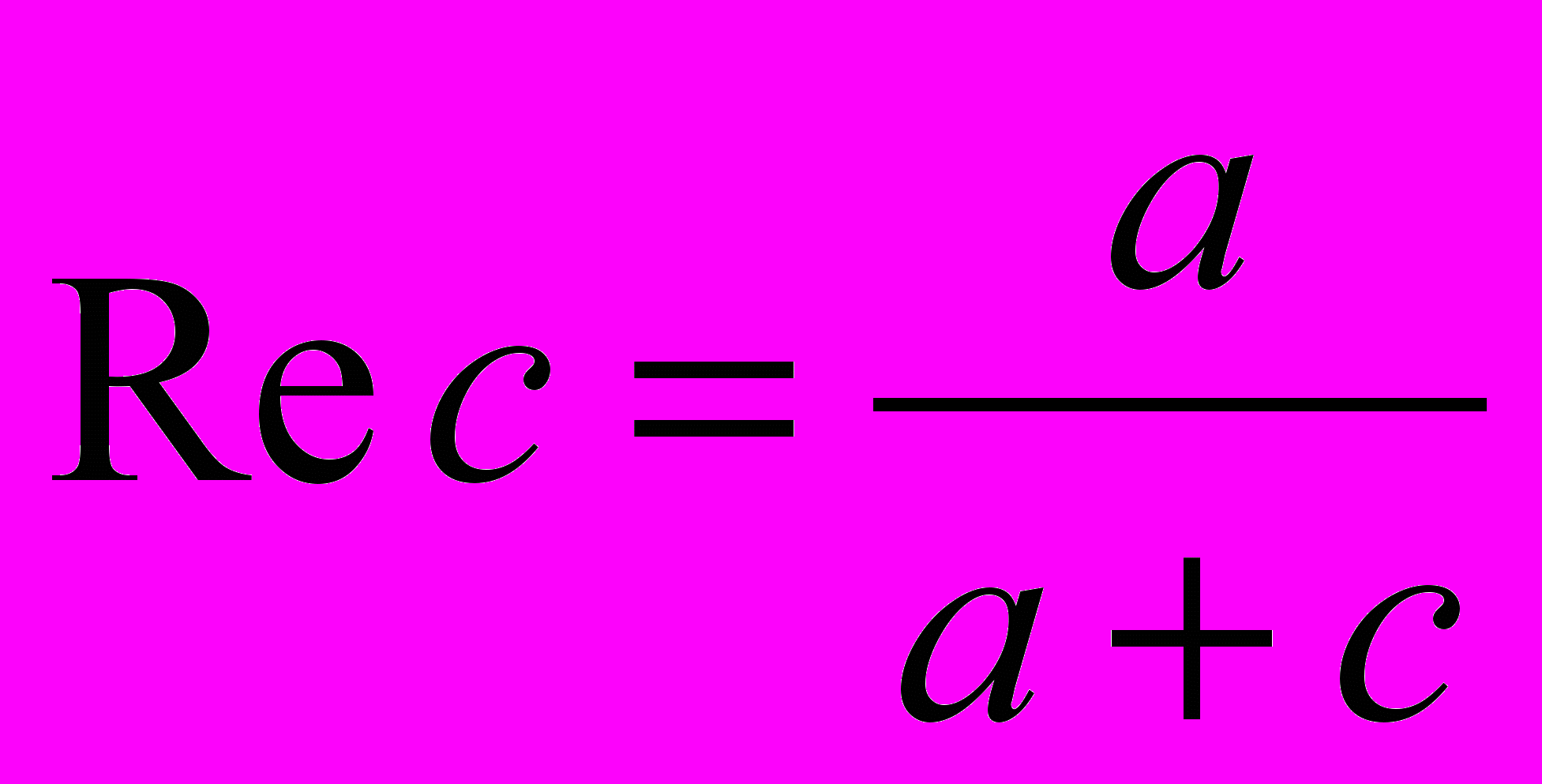
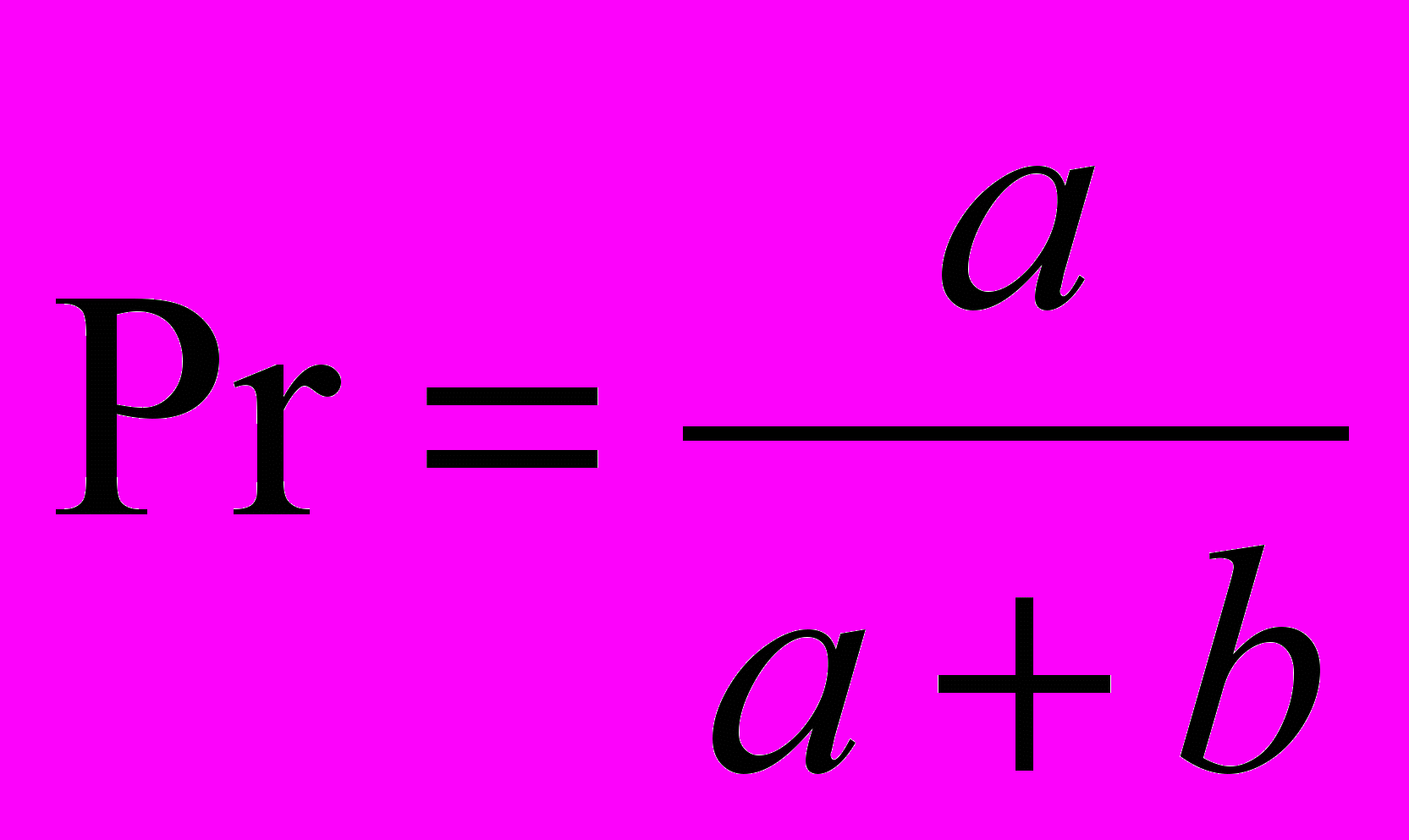
1. R≥25
2. 15 R 25
3. 10 R 15
16. Что такое тезаурус и как он используется в ИПС? Назовите основные компоненты архитектуры ИПС. Опишите функционирование ИПС
17. Дайте интерпретацию сущности информационного поиска в терминах теории множеств.
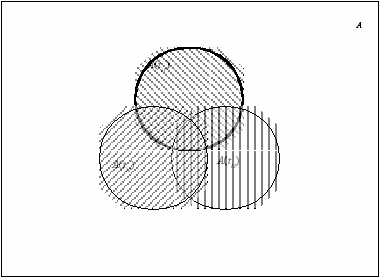
18. Назовите особенности Интернета, которые обуславливают особенности ИПС Интернета.
19. Каковы особенности пользовательского интерфейса ИАИПС? Какие факторы учитываются в ИАИПС при ранжировании результатов поиска? Какие функции выполняет робот-индексировщик?
20. В чем сущность полнотекстовых баз данных?
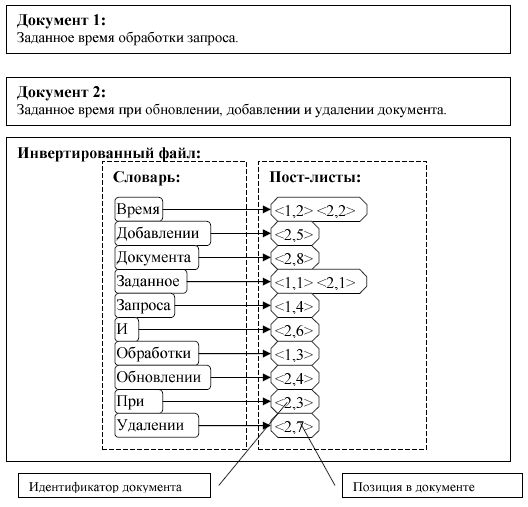
21. Назовите отличия ИПС и ИАИПС.
23. В чём сущность оценки эффективности ИАИПС по глубине поиска?
Результаты тестирования ИАИПС по методу глубины пользовательского поиска
| Ключевые термины | ссылка скрыта m/c | Жанр релевантного документа | ссылка скрыта m/c | Жанр релевантного документа |
| TF IDF weighting formula | 3/1 | Энциклопедия | 2/2 | Энциклопедия |
| Indicative and informative summaries | 1/6 | Глава диссертации | 1/1 | Журнальная статья |
22. Опишите сущность реферирования, используя семантический треугольник.
23. Опишите принципы и методику симметричного реферирования
(1) The basis for Western literacy was the invention of alphabetic writing by the Greeks. (2) Around 1100 B.C. the Phoenicians invented a syllabary, a writing system representing spoken syllables. (3) It is conjectured that the impetus for the Phoenician invention was probably commerce. (4) The Greeks, building on the syllabary, developed alphabetic writing where the written symbols represent meaningful sounds (phonemes) of the language.
24. Опишите основные алгоритмы и процедуры, применяемые в системах автоматического реферирования поверхностного уровня
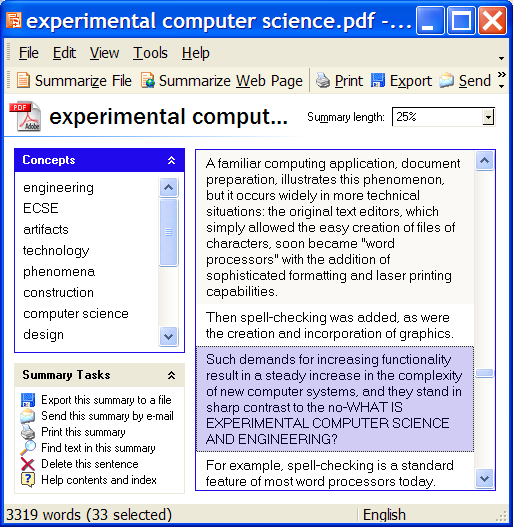
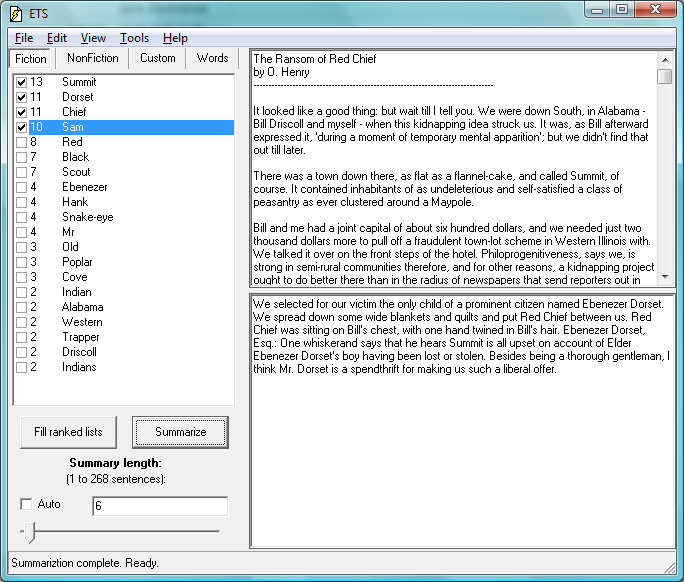
25. Опишите интерфейс программы ETS. На основе какой базы данных функционирует система?
28. Опишите обобщенную архитектуру систем автоматического реферирования поверхностного уровня
29. Каковы отличия разных видов рефератов
Индикативный реферат
В монографии проводится философско-методологический анализ, связанных с применением понятий семиотики. Рассматривая возможность и результаты использования понятий «знак» и «язык» в изучении чувственного до сознательного отражения. Выявляются функции понятия «язык» в формировании научного понятия.
Информативный реферат
ИПС «Стандарты» представляет собой стандартную систему. Она предназначена для проведения ретроспективного поиска. ИПС выдаёт обычные описания документа.
Индикативно-информативный реферат
(а). Рассмотрены методологические основы оценки качества работы автоматизированных систем. (б). Предложен перечень показателей качества, охватывающий основные этапы функционирования. (в). Перечень включает единичные, комплексные и обобщенные показатели. (г). К последним относятся показатели качества документального массива, оперативности, себестоимости.
30. Опишите систему FociSum. К какому уровню она относится?*
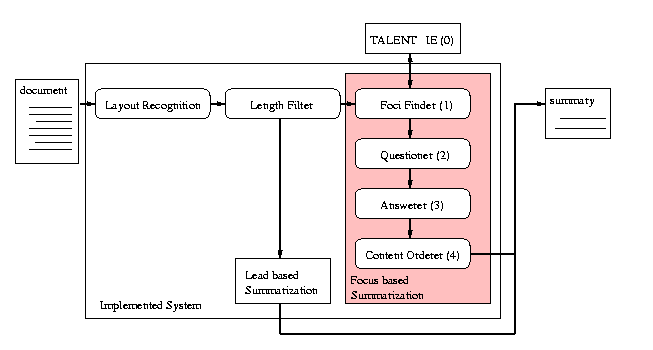
31. По каким критериям проводится взвешивание терминов в системе FociSum?
Terms from the article (via IBM's Talent)
# Length: 89 sentences
# Paragraph beginnings are located at sentences 1 2 3 4 5 8 9 11 13 16 18 19 23 24 26 27 28 29 31 32 33 34 36 37 39 41 42 44 46 47 48 51 52 53 54 55 56 57 58 60 62 63 64 65 67 68 69 70 72 74 75 76 78 79 80 82 84 86 88
# Term Types to Length Ratio: 0.528089887640449
# Total Terms Found: 81
11 Mongolia (UNAME): Loc 4|5|8|11|18|28|44|50|63|68|82|
4 Oleg F. Gorelik (PERSON): Loc 31|43|63|69|
3 China (PLACE): Loc 1|32|41|
3 stock market (UTERM): Loc 4|6|86|
3 stock exchange (UTERM): Loc 8|10|52|
3 Miss Munkhtsetseg (PERSON): Loc 10|22|89|
3 Erdenet (UNAME): Loc 45|46|54|
3 Mongolians (UNAME): Loc 61|67|88|
2 Asia (PLACE): Loc 5|82|
2 pro-business government (UTERM): Loc 5|82|
2 radical privatisation programme (UTERM): Loc 6|11|
Article Foci (and Questions)
# Length: 89 sentences
# Paragraph beginnings are located at sentences 1 2 3 4 5 8 9 11 13 16 18 19 23 24 26 27 28 29 31 32 33 34 36 37 39 41 42 44 46 47 48 51 52 53 54 55 56 57 58 60 62 63 64 65 67 68 69 70 72 74 75 76 78 79 80 82 84 86 88
# Term Types to Length Ratio: 0.528089887640449
# Total Terms Found: 81
1. Mongolia 147.574055158325 3|11|0.610827374872319|0.344228804902962|UNAME [4 5 8 11 18 28 44 50 63 68 82 ]
2. stock exchange 81.4082397003745 7|3|0.737827715355805|0.172284644194756|UTERM [8 10 52 ]
3. radical privatisation programme 79.3089887640449 7|2|0.904494382022472|0.0280898876404494|UTERM [6 11 ]
4. stock market 76.9662921348315 7|3|0.640449438202247|0.314606741573034|UTERM [4 6 86 ]
32. На основе какой базы функционирует система FociSum?
| 1. Person . | 2. Organization | 3. Place | 4. Multiword Term |
| A. Who is X? H B. What did X say? C. What did X do D. How old is X? | E. Is X a nonprofit or governmental or corporate agency? F. What did X say? G. What did X do? | Н. Is X the setting of the story? I. Is X the governing agency of X? | J. What does X mean? K. Are there synonyms for X? |

Х (PERSON)
Y (UTERM) a. X developed Y
b. X uses Y
c. X does Y
d. X is a type of Y
33. Опишите обобщённую архитектуру систем автоматического реферирования текста
| к о м п р е с с и я | ||||
| пользователь | р е ф е р а т | структура словаря | первичный документ | |
| Функция | структура | |||
| 1.общие 2.пользовательские | 1.информативные 2.индикативные 3.индикативно-информативные | 1. фрагмент 2.связный текст | 1.тематические 2.внетематические | 1.дискретные 2.непрерывные |
| А Н А Л И З ТРАНСФОРМАЦИЯ с и н т е з реферат | ||||
Перечень рекомендуемой литературы
Основная литература
1. Козлов М.В. Яцко В.А. Метод оценки эффективности функционирования современных информационно-поисковых систем Интернета // Компьютерная лингвистика и интеллектуальные технологии – М., 2006. – С.259-264. ссылка скрыта
2. Яцко В.А., Вишняков Т.Н. Некоторые проблемы разработки современных систем автоматического реферирования текста // Научно-техническая информация. Сер.2. - 2008 г. - No. 9. - С. 7–13. 3. Вейзе А.А Чтение, реферирование и аннотирование иностранного текста. - М.: Высшая школа, 1985. - 127 с.
4. Яцко В.А., Вишняков Т.Н. Метод оценки эффективности функционирования современных систем автоматического реферирования текста // Научно-техническая информация. Сер.2. - № 5. - c. 18-26
5. Яцко В.А. и др. Автоматическое распознавание жанра и адаптивное реферирование текста // Научно-техническая информация. Сер. 2, Информационные процессы и системы. - 2010, N 5. - С.9-18.
6. Яцко В.А. и др. Алгоритмы предварительной обработки текста: декомпозиция, аннотирование, морфологический анализ // Научно-техническая информация. Сер. 2, Информационные процессы и системы. - 2009, N 11. - С.24-30.
7. Яцко В.А. Опыт разработки онтологии для автоматического анализа мнений пользователей о коммерческих продуктах // Научно-техническая информация. Сер. 2, Информационные процессы и системы. - 2011, N 7.
8. Яцко В.А. Алгоритмы и программы автоматического анализа текста. // Научно-техническая информация. Сер. 2, Информационные процессы и системы. - 2011, N 9.
12. Яцко В.А. Логико-лингвистические проблемы анализа и реферирования научного текста. - Абакан: Изд-во Хакасского гос. ун-та, 1996. - 128 с.
13. Яцко В.А. Симметричное реферирование: теоретические основы и методика // НТИ. Сер.2. 2002. № 5. С.18-28.
Дополнительная литература
14. Блюменау Д.И., Гендина Н.И., Добронравов И.С. и др. Формализованное реферирование с использованием словесных клише // Науч.- тех. информ. Сер. 2. - 1981. - № 2. - С. 16-20.
15. Кара-Мурза С.Г. Цитирование в науке и подходы к оценке научного вклада // Вестник АН СССР. - 1981. - № 5. - С. 68-75.
16. Леонов В.П. Реферирование и аннотирование научно-технической литературы. - Ново-сибирск: Наука, 1986. - 175 с.
17. Мак Кьюин К. Дискурсивные стратегии для синтеза текста на естественном языке // Новое в зарубежной лингвистике. - М, 1989. - Вып. XXIV. - С. 311- 356.
18. Маршакова И.В. Система цитирования научной литературы как средство слежения за развитием науки. - М.: Наука, 1988. - 188 с.
19. Миронов Г.А. Способы повышения качества информационного обслуживания в сетях (Интернете) // НТИ. Сер.1. 2001. №3. С.10-17.
20. Новиков А.И., Нестерова Н.М. Реферативный перевод научно-технических текстов. - М.: Наука, 1991. - 148 с.
21. Радзиевская Т.В. Реферативный текст в лингво-прагматическом аспекте // Науч.-тех.информ. Сер.2. - 1986. - № 8. - С.1 - 5.
22. Севбо И.П. Структура связного текста и автоматизация реферирования. - М.: Наука, 1969. - 135 с.
23. Скороходько Э.Ф. Семантические сети и автоматическая обработка текста. - Киев: Нау-кова думка, 1983. - 219 с.
24. Субботин М.М. Гипертекст - новая форма письменной коммуникации / ВИНИТИ. - М., 1994. - 158 с. - (Итоги науки и техники. Сер. "Информатика". Т.18).
25. Яцко В.А. Рассуждение как тип научной речи. – Абакан: Изд-во Хакасского гос. ун-та им. Н.Ф.Катанова, 1998. 182 с.
26. DuRoss Liddy E. The discourse level structure of empirical abstracts: an exploratory study // Information processing and management. -1991. - V. 27. - ¹ 1. - P. 55-81.
27. Heidrun C., Manecke H. I. Entwiklung eines algorithmus fur das referieren russischsprachiger zeitschriftenartikel des fachgebietes informationstechnik // Informatik. - 1989. - V. 36. - ¹ 1. - S.29-30.
28. Iatsko V. Linguistic aspects of summarization. Philologie im Netz. 2001. N 18. www.fu-berlin.de/ phin/phin18/p18i.htm
29. Luhn H.P. The automatic creation of literature abstracts. The IBM journal.1958. P. 159-165.
30. Trawinsky B.A. A methodology for writing problem structured abstracts // Information proc-essing and management. - 1989. - V. 25. - ¹ 6. - P. 693-702.