
Методические указания к лабораторным работам по дисциплине «Интеллектуальные информационные системы» для студентов специальности 071900
| Вид материала | Методические указания |
- Методические указания по выполнению лабораторной работы №12 для студентов специальности, 141.78kb.
- Методические указания по выполнению лабораторной работы №14 для студентов специальности, 187.8kb.
- Методические указания к выполнению лабораторных работ по дисциплине «Интеллектуальные, 653.36kb.
- Методические указания по выполнению лабораторной работы №3 для студентов специальности, 177.77kb.
- Методические указания к лабораторным работам №1-5 для студентов специальности 210100, 363.6kb.
- Методические указания к лабораторным работам для студентов специальности 210100 "Автоматика, 536.56kb.
- Методические указания к курсовому проектированию по дисциплине Москва 2001 для студентов, 2418.6kb.
- Методические указания к лабораторным работам по физике по практикуму «Вычислительная, 138.12kb.
- Методические указания к лабораторным работам по курсу, 438.32kb.
- Рабочая программа и методические указания для самостоятельной работы студентов Vкурса, 220.77kb.
МИНИСТЕРСТВО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
государственное образовательное учреждение высшего профессионального образования
«Тюменский государственный нефтегазовый университет»
институт Геологии и Геоинформатики
кафедра Геоинформатики
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
к лабораторным работам по дисциплине
«Интеллектуальные информационные системы»
для студентов специальности 071900
«Информационные системы и технологии»
очной и заочной форм обучения
Тюмень 2007
Утверждено редакционно-издательским советом
Тюменского государственного нефтегазового университета
Составители: А.А. Яйлеткан, к.ф.н., доцент
Р. В. Пархимович, ассистент
Отв. редактор: С.К. Туренко, д.т.н., профессор
© Тюменский государственный нефтегазовый университет
2007 г.
1. НАЗНАЧЕНИЕ УКАЗАНИЙ
Методические указания к лабораторным занятиям по дисциплине «Интеллектуальные информационные системы» для студентов ИСТ очной и заочной формы обучения специальности 071900 – «Информационные системы и технологии» (учебный план 2003 г. на основании государственного образовательного стандарта высшего профессионального образования) / Составили кандидат философских наук Яйлеткан А. А., доцент кафедры геоинформатики ИГиГ, и Пархимович Р. В., ассистент кафедры геоинформатики ИГиГ.
Методические указания содержат задания и теоретические основы для их самостоятельного выполнения. Базовой основой методических указаний служат лекции по дисциплинам «Интеллектуальные информационные системы» и «Представление знаний в информационных системах».
Основная цель лабораторных работ: представление этапов технологии создания интеллектуальных информационных систем
2. ЛАБОРАТОРНАЯ РАБОТА №1. «Экспертные оболочки»
Цель работы:
1. Изучение языка процедурного программирования оболочки CLIPS.
2. Создание экспертной системы в оболочке CLIPS, содержащей базу правил, начальные факты и возможные исходы.
Теоретическое введение.
2.1. Общие сведения о CLIPS
CLIPS (С Language Integrated Production System) является одним из распространенных инструментальных средств разработки экспертных систем (ЭС). CLIPS использует продукционную модель представления знаний и поэтому содержит три основных элемента:
- список фактов (представляет исходное состояние проблемы)
- базу знаний (преобразуют состояние проблемы к решению)
- блок вывода
Отличием данной системы от аналогов является то, что она полностью реализована на языке С. В CLIPS используется оригинальный LIPS-подоб-ный язык программирования, ориентированный на разработку ЭС. Кроме того, CLIPS поддерживает еще две парадигмы программирования: объектно-ориентированную и процедурную. Аспекты объектно-ориентированного программирования в CLIPS рассматриваться не будут.
2.2. Программирование в CLIPS
2.2.1. Простые типы данных
В CLIPS предусмотрено восемь простых типов данных: float, integer, symbol, string, external-address, fact-address, instance-name и instance-address.
Для числовой информации используются типы float и integer, символьной – symbol и string. При записи числа используются цифры (0-9), десятичная точка (.), знак (+) или (-) и (е) при экспоненциальном представлении. Количество значащих цифр зависит от аппаратной реализации. Примеры целых чисел: 237, 15, +12, -32. Примеры чисел с плавающей точкой: 237е3, 15.09, +12.0, -32.3е-7.
Последовательность символов, которая не удовлетворяет числовым типам, обрабатывается как тип данных symbol. Тип данных symbol в CLIPS – последовательность символов, состоящая из одного или нескольких любых печатных символов кода ASCII. Примеры выражений символьного типа: foo, Hello, B76-HI, bad_value, 127А, 742-42-42, @+=-%, Search. Тип данных string - это последовательность символов, состоящая из нуля и более печатных символов и заключенная в двойные кавычки. Если внутри строки встречаются двойные кавычки, то перед ними необходимо поместить символ (\). Например: "foo", "a and b", "I number", "a\"quote".
2.2.2. Переменные
Идентификатор переменной всегда начинается с вопросительного знака, за которым следует ее имя. Примеры переменных: ?х, ?sensor, ?noun, ?color.
Переменные описываются (defrule make-quack
и получают значения (duck-sound ?sound)
в левой части правила. =>
(assert (sounds-is ?sound) )
Значение переменной (defrule addition
изменяется в правой части (numbers ?x ?y)
при помощи функции bind. =>
(assert (answer (+ ?x ?y)))
(bind ?answer (+ ?x ?y)
(printout t "answer is " ?answer crlf))
Переменной может быть (defrule get-married
присвоено значение адреса факта. ?duck <- (bachelor Dopey)
Это может оказаться удобным =>
при необходимости манипули- (retract ?duck))
ровать фактами непосредственно из правила. Для такого присвоения используется комбинация "<-".
Для определения глобальных переменных, которые видны всюду в среде CLIPS, используется конструкция defglobal. К глобальной переменной можно обратиться в любом месте, и ее значение остается независимым от других конструкций.
2.2.3. Функции
Существует несколько типов функций. Пользовательские и системные функции - это фрагменты кода, написанные на внешних языках (например, на С) и связанные со средой CLIPS. Системными называются те функции, которые были определены изначально внутри среды CLIPS. Пользовательскими называются функции, которые были определены вне CLIPS.
в CLIPS предусмотрен ряд стандартных арифметических и математических функций. Среди них: + (сложение ), - (вычитание ), * (умножение), / (деление), ** (возведение в степень), Abs (определение абсолютного значения), Sqrt (вычисление квадратного корня), Mod (взятие по модулю), Min (нахождение минимума), Мах (нахождение максимума). Конструкция deffunction позволяет пользователю определять новые функции непосредственно в среде CLIPS.
2.2.4. Конструкции
В CLIPS существует несколько описывающих конструкций: defmodule,
defrule, deffacts, deftemplate, defglobal, deffunction, defclass, definstances, defmessage-handler, defgeneric. При записи все они заключаются в скобки. Определение конструкции отличается от вызова функции главным образом по производимому эффекту. В отличие от функций конструкции никогда не возвращают значений.
2.2.5. Факты
Факты являются одной из основных форм представления информации в системе CLIPS. Каждый факт представляет фрагмент информации, который был помещен в текущий список фактов, называемый fact-list.
Сразу после запуска CLIPS-приложения на выполнение на экране появится приглашение, извещающее пользователя, что он работает с интерпретатором: CLIPS>.
Факты можно включить в базу CLIPS> (assert (today is Sunday))
фактов прямо из командной строки
с помощью команды assert CLIPS> (assert (weather is warm))
Для вывода списка фактов, CLIPS> (facts)
имеющихся в базе, используется f-0 (today is Sunday)
команда facts f-1 (weather is warm)
Для удаления фактов из базы CLIPS> (retract 1)
используется команда retract CLIPS> (facts)
f-0 (today is Sunday)
Команда clear очищает CLIPS> (clear)
базу фактов CLIPS> (facts)
В тексте программы факты (deffacts today
можно включать в базу массивом. (today is Sunday)
Используется команда deffacts (weather is warm))
Выражение начинается с команды deffacts, затем приводится имя списка фактов, который программист собирается определить (в примере — today), за ним следуют элементы списка.
Этот массив фактов можно CLIPS> (undeffacts today)
удалить из базы командой undef facts
Выражение deffacts лучше CLIPS> (load "my file")
записать в текстовый файл, а CLIPS> (reset)
затем загрузить. Команда reset сначала очищает базу фактов, а затем включает в нее факты из всех ранее загруженных массивов.
2.2.6. Правила
Блок вывода постоянно отслеживает все правила, условия которых выполняются, и, таким образом, правило может быть выполнено в любой момент, как только оно становится применимым.
В языке CLIPS правила имеют формат: Например:
(defrule <имя правила> (defrule chores
< необязательный комментарий > "Things to do on Sunday"
< необязательное объявление > (salience 10)
< предпосылка_1 > (today is Sunday)
< предпосылка_т > => (weather is warm) =>
< действие_1 > (assert (wash car))
< предпосылка_п >) (assert (chop wood))
В этом примере Chores — произвольно выбранное имя правила. Предпосылки в условной части правила (today is Sunday), (weather is warm) сопоставляются затем интерпретатором с базой фактов, а действия, перечисленные в выполняемой части правила (она начинается после пары символов =>), вставят в базу два факта (wash car), (chop wood) в случае, если правило будет активизировано. Приведенный в тексте правила комментарий "Things to do on Sunday" ("Что сделать в воскресенье") поможет в дальнейшем вспомнить, для чего это правило включено в программу.
Выражение (salience 10) указывает на степень важности правила. Пусть, например, в программе имеется другое правило:
Поскольку предпосылки обоих правил (defrule fun
одинаковы, то при выполнении оговоренных "Better things to do on Sunday"
условий они будут "конкурировать" за (salience 100)
внимание интерпретатора. Предпочтение (today is Sunday)
будет отдано правилу, у которого параметр (weather is warm) =>
salience имеет более высокое значение, (assert (drink beer))
в данном случае — правилу fun. (assert (play guitar)))
Параметру salience может быть присвоено любое целочисленное значение в диапазоне [-10 000, 10 000]. Если параметр salience в определении правила опущен, ему по умолчанию присваивается значение 0.
Обычно в определении правила (defrule pick-a-chore
присутствуют и переменные. Если, "Allocating chores to days"
например, правило (today is ?day)
(chore is ?job) =>
(assert (do ?job on ?day)) )
будет сопоставлено с фактами (today is Sunday) (chore is carwash)
то в случае активизации оно включит
в базу новый факт (do carwash on Sunday)
Аналогично, правило (defrule drop-a-chore
отменит выполнение работ "Allocating chores to days"
по дому (a chore). Оба эк- (today is ?day)
экземпляра переменной ?chore <- (do ?job on ?day) =>
?day должны получить (retract ?chore) )
одно и то же значение. Переменная ?chore в результате сопоставления должна получить ссылку на факт, который мы собираемся исключить из базы. Таким образом, если это правило будет сопоставлено с базой фактов, в которой содержатся (today is Sunday)
то при активизации правила (do carwash on Sunday)
из базы будет удален факт (do carwash on Sunday)
Отметим, что факт (do carwash on Sunday)
будет сопоставлен с любым из представленных ниже образцов
Учтите, что префикс $? (do ? ? Sunday)
является признаком (do ? on ?)
сегментной переменной, (do ? on ?when)
которая будет связана (do $?)
с сегментом списка. (do $? Sunday)
(do ?chore $?when)
Например, в приведенном выше примере переменная $?when будет связана с (on Sunday). Если за префиксами ? и $? не следует имя переменной, они рассматриваются как универсальные символы подстановки, которым соответственно может быть сопоставлен любой элемент или сегмент списка.
2.3. Наблюдение за процессом интерпретации
Теперь на простом примере познакомимся с возможностями, которые предоставляет среда разработки CLIPS в части отладки программы, состоящей из правил и фактов. Введите в текстовый файл правило, а затем загрузите этот файл в среду CLIPS.
(defrule start
(initial-fact)
(printout t "hello, world" crlf) )
Выполните команду reset. Для этого либо введите эту команду в командной строке интерпретатора
CLIPS> (reset)
либо выберите в меню команду Execution=>Reset, либо нажмите
Затем запустите интерпретатор. Для этого либо введите эту команду run в командную строку интерпретатора
CLIPS> (run)
либо выберите в меню команду ExecutionORun, либо нажмите
В ответ программа должна вывести сообщение hello, world, знакомое всем программистам мира. Для повторного запуска программы повторите команды reset и run.
Если в меню ExecutionWatch ранее был установлен флажок Rules или перед запуском программы на выполнение вы ввели в командную строку команду watch rules, то на экране появится результат трассировки процесса выполнения
CLIPS> (run) FIRE 1 start: f-0 hello, world
В этом сообщении в строке, начинающейся с FIRE, выведена информация об активизированном правиле: start — это имя правила, а f-0 — имя факта, который "удовлетворил" условие в этом правиле. Команда watch позволяет организовать несколько разных режимов трассировки, с деталями которых вы можете познакомиться в Руководстве пользователя. Если перед запуском программы вы ввели
CLIPS> (dribble-on "dribble.dp")
TRUE
то выведенный протокол трассировки будет сохранен в файле dribble.dp. Сохранение протокола прекратится после ввода команды
CLIPS> (dribble-off)
TRUE
Это очень удобная опция, особенно на этапе освоения языка.
2.4. Использование шаблонов
Для определения фактов можно использовать не только списочные структуры, но и шаблоны, которые напоминают простые записи. (Шаблоны в CLIPS не имеют ничего общего с шаблонами C++.) Шаблон выглядит примерно так:
(deftemplate student "a student record"
(slot name (type STRING)) (slot age (type NUMBER) (default 18))
Каждое определение шаблона состоит из произвольного имени шаблона, необязательного комментария и некоторого количества определений слотов. Слот включает поле данных, например name, и тип данных, например STRING. Можно указать и значение по умолчанию, как в приведенном выше примере.
Если в программу включено приведенное выше определение шаблона, то выражение
(deffacts students
(student (name fred))
(student (name freda) (age 19)) )
приведет к тому, что в базу фактов после выполнения команды reset будет добавлено
(student (name fred) (age 18)) (student (name freda) (age 19))
3. ЛАБОРАТОРНАЯ РАБОТА №2. «Логическое программирование»
Цель работы:
1. Изучение языка логического программирования Турбо-Пролог.
2. Создание экспертной системы на языке логического программирования PROLOG, содержащей базу правил, начальные факты и возможные исходы.
Теоретическое введение.
Синтаксис и семантика Пролог-программ
3.1. Объекты данных
Н
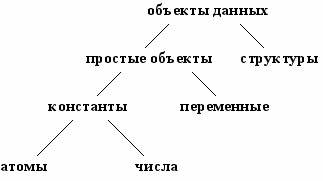 а Рис.3.1. приведена классификация объектов данных Пролога. Пролог-система распознает тип объекта по его синтаксической форме в тексте программы.
а Рис.3.1. приведена классификация объектов данных Пролога. Пролог-система распознает тип объекта по его синтаксической форме в тексте программы.Рис.3.1. Обьекты
данных Пролога.
3.1.1. Атомы и числа
Атомы и числа представляют собой цепочки следующих символов:
- прописные буквы А, В, ..., Z
- строчные буквы а, b, ..., z
- цифры 0, 1, 2, ..., 9
- специальные символы, такие как + - * / = : . & _ ~
Атомы можно создавать тремя способами:
(1) из цепочки букв, цифр и символа подчеркивания _, начиная такую цепочку со строчной буквы
(2) из специальных символов: <--->, ======>, ..., ., ..., : : =
(3) из цепочки символов, заключенной в одинарные кавычки.
'Том', 'Южная_Америка', 'Сара Джонс'
Числа в Прологе бывают целыми и вещественными. Синтаксис целых
чисел: 1, 1313, 0, -97, - допускается их диапазон от -16383 до 16383. Синтаксис вещественных чисел: 3.14, -0.0035, 100.2.
3.1.2. Переменные
Переменные - это цепочки, состоящие из букв, цифр и символов подчеркивания:
Х, Результат, Объект2, Список_участников, СписокПокупок, _х23, _23
Если переменная встречается в предложения только один раз, то можно использовать "анонимную" переменную, которая записывается в виде одного символа подчеркивания. Рассмотрим, например, следующее правило:
имеетребенка( X) :- родитель( X, Y).
Это правило гласит: "Для всех X, Х имеет ребенка, если X является родителем некоторого Y". Свойство имеетребенка определяется таким образом, что не зависит от имени ребенка. Следовательно, уместно использовать анонимную переменную. Вышеприведенное правило можно переписать так:
имеетребенка( X) :- родитель( X, _ ).
Всякий раз, когда в предложения появляется одиночный символ подчеркивания, он обозначает новую анонимную переменную. Например, можно сказать, что существует некто, кто имеет ребенка, если существуют два объекта, такие, что один из них является родителем другого:
некто_имеет_ребенка :- родитель( _, _ ).
Это предложение эквивалентно следующему:
некто_имеет_ребенка :- родитель( X, Y).
Однако оно имеет совершенно другой смысл, нежели
некто_имеет_ребенка :- родитель( X, X).
Если анонимная переменная встречается в вопросе, то ее значение не выводится при ответе системы на этот вопрос. Если нас интересуют люди, имеющие детей, но не имена этих детей, мы можем просто спросить:
?- родитель( X, _ ).
Лексический диапазон имени - одно предложение. Это значит, что если, например, имя Х15 встречается в двух предложениях, то оно обозначает две разные переменные. Однако внутри одного предложения каждое его появлений обозначает одну и ту же переменную. Для констант ситуация другая: один и тот же атом обозначает один и тот же объект в любом предложении.
3.1.3. Структуры
Структурные объекты (или просто структуры) - это объекты, которые состоят из нескольких компонент. Компоненты, в свою очередь, могут быть структурами. Например, дату можно рассматривать как структуру, состоящую из трех компонент: день, месяц, год. Хотя они и составлены из нескольких компонент, структуры в программе ведут себя как единые объекты. Для того, чтобы объединить компоненты в структуру, требуется выбрать функтор. Для нашего примера подойдет функтор дата. Тогда дату 1 мая 1983 г. можно записать: дата(1, май, 1983).
Все компоненты в данном примере являются константами (две компоненты - целые числа и одна - атом). Компоненты могут быть также переменными или структурами. Произвольный день в мае можно представить структурой: дата(День, май, 1983). Заметим, что День является переменной и ей можно приписать произвольное значение на некотором более позднем этапе вычислений. Такой метод структурирования данных прост и эффективен. Это является одной из причин широкого использования Пролога для обработки символьной информации.
Синтаксически все объекты данных в Прологе представляют собой термы. Например, май и дата( 1, май, 1983) – суть термы.
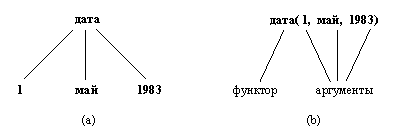
Рис.3.2. Дата - пример структурного объекта: (а) его представление в виде дерева; (б) запись на Прологе.
С
 труктурные объекты изображаются в виде деревьев. Корнем дерева служит функтор, ветвями, выходящими из него, - компоненты. Если некоторая компонента тоже является структурой, тогда ей соответствует поддерево в дереве, изображающем весь структурный объект.
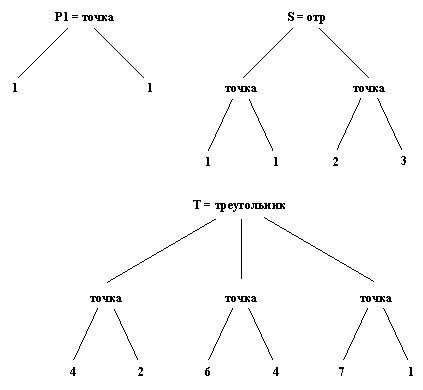
труктурные объекты изображаются в виде деревьев. Корнем дерева служит функтор, ветвями, выходящими из него, - компоненты. Если некоторая компонента тоже является структурой, тогда ей соответствует поддерево в дереве, изображающем весь структурный объект.Рассмотрим пример представления геометрических объектов (Рис.3.3). Точка в двумерном пространстве определяется двумя координатами; отрезок определяется двумя точками, а треугольник можно задать тремя точками. Введем функторы: точка (для точек), отрезок (для отрезков), треугольник (для
Рис.3.3. Простые геометрические объекты треугольников).
Тогда объекты, приведенные на Рис.3.3, можно представить следую-
щими термами: Р1 = точка( 1, 1)
P2 = точка(2, 3)
S = отрезок(P1, P2) = отрезок(точка(1, 1), точка(2, 3) )
Т = треугольник(точка(4, 2), точка(6, 4), точка(7, 1) )
Представление этих объектов в виде деревьев приводится на Рис.3.4. Функтор, служащий корнем дерева, называется главным функтором терма.
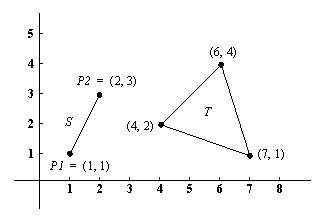
Рис.3.4. Представление объектов с Рис.3.3. в виде деревьев
Если бы в такой же программе фигурировали точки трехмерного пространства, то можно было бы для их представления использовать другой функтор, скажем точка3: точка3(X, Y, Z). Можно воспользоваться одним и тем же именем точка одновременно для точек двумерного и трехмерного пространств, например: точка(XI, Y1) и точка (X, Y, Z). Если одно и то же имя появляется в программе в двух различных смыслах, как в вышеупомянутом примере с точкой, то пролог-система будет различать их по числу аргументов и интерпретировать это имя как два функтора: один - двухаргументный; второй - трех. Т.е. каждый функтор определяется двумя параметрами:
(1) именем, синтаксис которого совпадает с синтаксисом атомов;
(
 2) n-арностью - т. е. числом аргументов.
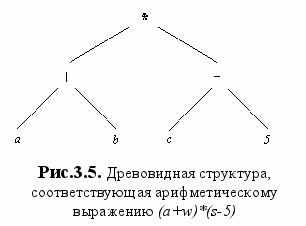
2) n-арностью - т. е. числом аргументов.Все структурные объекты в Прологе - это деревья, представленные в программе термами. Рассмотрим пример: на Рис.3.5 показана древовидная структура, соответствующая порядку вычисления арифметического выражения (а+в)*(с-5) польской записью *(+(а,в),-(с,5)).
3.2. Сопоставление
Наиболее важной операцией над термами является сопоставление.
Сопоставление само по себе может производить содержательные вы-
числения. Пусть даны два терма. Они сопоставимы, если: (1) они идентичны или (2) переменным в обоих термах можно приписать в качестве значений объекты (т.е. конкретизировать их) таким образом, чтобы после подстановки этих объектов в термы вместо переменных, последние стали идентичными.
Например, термы дата(Д, М, 1983) и дата(Д1, май, Y1) сопоставимы, так как Д заменяется на Д1, М заменяется на май, Y1 заменяется на 1983. Более компактно такая подстановка записывается в форме, в которой пролог-система выводит результаты: Д=Д1, М=май, Y1=1983. С другой стороны, дата(Д, М, 1983) и дата(Д1, Ml, 1944) не сопоставимы, как и термы дата(X, Y, Z) и точка(X, Y, Z).
Сопоставление - это процесс, на вход которого подаются два терма, а он проверяет, соответствуют ли эти термы друг другу. Если термы не сопоставимы, будем говорить, что этот процесс терпит неуспех. Если же они сопоставимы, тогда процесс находит конкретизацию переменных, делающую эти термы тождественными, и завершается успешно.
Рассмотрим еще раз сопоставление двух дат. Запрос на проведение такой операции можно передать системе, используя оператор '=':
?- дата(Д, М, 1983)= дата(Д1, май, Y1).
Мы уже упоминали конкретизацию Д=Д1, М=май, Y1=1983, на которой достигается сопоставление. Существуют, однако, и другие конкретизации, делающие оба терма идентичными. Вот две из них:
Д=1, Д1=1, М=май, Y1=1983
Д=третий, Д1=третий, М=май, Y1=1983
Эти конкретизации являются менее общими по сравнению с первой, поскольку они ограничивают значения переменных Д и Д1. Для того, чтобы сделать оба терма нашего примера идентичными, важно лишь, чтобы Д и Д1 имели одно и то же значение. Сопоставление в Прологе всегда дает наиболее общую конкретизацию. Таковой является конкретизация, которая ограничивает переменные в наименьшей степени. В качестве примера рассмотрим следующий вопрос:
?- дата(Д, М, 1983)= дата(Д1, май, Y1).
дата(Д, М, 1983)=дата(15, М, Y).
Для достижения первой цели система припишет переменным такие значения: Д=Д1, М=май, Y1=1983. После достижения второй цели, значения переменных станут более конкретными: Д=15, Д1=15, М=май, Y1=1983, Y=1983.
Общие правила выяснения, сопоставимы ли два терма S и Т, таковы:
(1) Если S и Т - константы, то S и Т сопоставимы, только если они являются одним и тем же объектом.
(2) Если S - переменная, а Т - произвольный объект, то они сопоставимы, и S приписывается значение Т. Наоборот, если Т - переменная, а S -произвольный объект, то Т приписывается значение S.
(3) Если S и Т - структуры, то они сопоставимы, только если
(а) S и Т имеют одинаковый главный функтор и
(б) все их соответствующие компоненты сопоставимы.
Результирующая конкретизация определяется сопоставлением компонент.
П
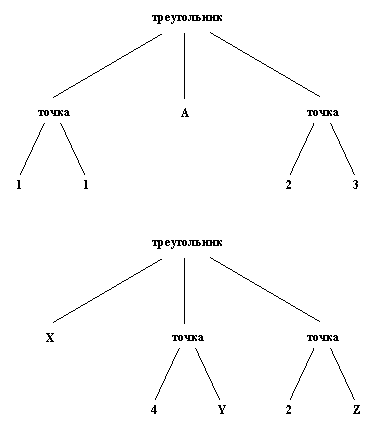 оследнее из этих правил можно наглядно представить себе, рассмотрев древовидное изображение термов, такое, например, как на Рис.3.6. Процесс сопоставления начинается от корня (главных функторов). Поскольку оба функтора сопоставимы, процесс продолжается и сопоставляет соответствующие пары аргументов. Таким образом, можно представить себе, что весь процесс сопоставления состоит из следующей последовательности операций сопоставления:
оследнее из этих правил можно наглядно представить себе, рассмотрев древовидное изображение термов, такое, например, как на Рис.3.6. Процесс сопоставления начинается от корня (главных функторов). Поскольку оба функтора сопоставимы, процесс продолжается и сопоставляет соответствующие пары аргументов. Таким образом, можно представить себе, что весь процесс сопоставления состоит из следующей последовательности операций сопоставления:треугольник= треугольник,
точка(1, 1)=X,
А=точка(4, Y),
точка(2, 3)=точка(2, Z).
Рис.3.6. Сопоставление
треугольник((точка(1, 1), А, точка(2, 3))=треугольник(Х, точка(4, Y), точка(2, Z))
Весь процесс сопоставления успешен, поскольку все сопоставления в этой последовательности успешны. Результирующая конкретизация такова:
Х=точка( 1, 1), А=точка( 4, Y), Z=3
В приведенном ниже примере показано, как сопоставление само по себе можно использовать для содержательных вычислений. Вернемся к простым геометрическим объектам с Рис.3.4 и напишем фрагмент программы для распознавания горизонтальных и вертикальных отрезков. "Вертикальность" - это свойство отрезка, поэтому его можно формализовать в Прологе в виде унарного отношения. Рис.3.7. помогает сформулировать это отношение.
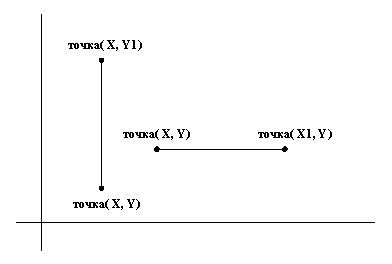
Рис.3.7. Пример вертикальных и горизонтальных отрезков прямых.
Отрезок является вертикальным, если x-координаты его точек-концов совпадают; никаких других ограничений на отрезок не накладывается. Свойство "горизонтальности" формулируется аналогично, нужно только в этой формулировке х и y поменять местами. Следующая программа, содержащая два факта, реализует эти формулировки:
верт(отр(точка(Х, Y), точка(Х, Y1))).
гор(отр(точка(Х, Y), точка(Х1, Y))).
С этой программой возможен такой диалог:
?- верт(отр(точка(1, 1), точка(1, 2))).
да
?- верт(отр(точка(1, 1), точка(2, Y))).
нет
?- гор(отр(точка(1, 1), точка(2, Y))).
Y=1
На первый вопрос система ответила "да", потому. что цель, поставленная в вопросе, сопоставима с одним из фактов программы. Для второго вопроса сопоставимых фактов не нашлось. Во время ответа на третий вопрос при сопоставлении с фактом о горизонтальных отрезках Y получил значение 1.
Сформулируем более общий вопрос к программе: " Существуют ли какие-либо вертикальные отрезки, начало которых лежит в точке (2,3)?"
?- верт(отр(точка(2, 3), Р)).
Р=точка(2, Y).
Такой ответ означает: "Да, это любой отрезок, с концом в точке (2,Y), т. е. в
произвольной точке вертикальной прямой х = 2". Ответ пролог-системы будет выглядеть не так красиво, как описано, а приблизительно следующим образом: Р=точка(2, _136). В данном случае _136 - это неинициализированная переменная. Имя _136 - законное имя прологовской переменной, которое система построила сама во время вычислений.
Другим содержательным вопросом к программe является следующий: " Существует ли отрезок, который одновременно и горизонтален в вертикален?"
?- верт(S), гор(S).
S=отр(точка(Х, Y), точка(Х, Y) ).
Такой ответ пролог-системы следует, понимать: "да, любой отрезок, выродившийся в точку, обладает как свойством вертикальности, так и свойством горизонтальности одновременно". Этот ответ получен из сопоставления. В ответе вместо Х и Y могут появиться некоторые имена, сгенерированные системой.
3.3. Декларативный смысл пролог-программ
Рассмотрим предложение Р :- Q, R.
где Р, Q и R имеют синтаксис термов. Приведем некоторые способы декларативной интерпретации этого предложения:
Р - истинно, если Q и R истинны,
из Q и R следует Р.
Варианты их "процедурного" прочтения:
Чтобы решить задачу Р, сначала решим подзадачу Q, а затем - подзадачу R.
Чтобы достичь Р, сначала достигни Q, а затем R.
Различие между "декларативным" и "процедурным" прочтениями заключается в том, что последнее определяет не только логические связи между головой предложения и целями в его теле, но еще и порядок обработки.
Формализуем теперь декларативный смысл.
Декларативный смысл программы определяет, является ли данная цель истинной (достижимой) и, если да, при каких значениях переменных она достигается. Конкретизацией предложения С называется результат подстановки в него на место каждой переменной некоторого терма. Вариантом предложения С называется такая конкретизация С, при которой каждая переменная заменена на другую переменную. Например:
имеетребенка(X) :- родитель(X, Y).
Два варианта этого предложения:
имеетребенка(А) :- родитель(А, В).
имеетребенка(X1) :- родитель(X1, Х2).
Примеры конкретизации:
имеетребенка(питер) :- родитель(питер, Z).
имеетребенка(барри) :- родитель(барри, маленькая(каролина)).
Пусть дана некоторая программа и цель G, тогда, в соответствии с декларативной семантикой, можно утверждать, что цель G истинна (т.е. достижима или логически следует из программы) тогда и только тогда, когда
(1) в программе существует предложение С, такое, что
(2) существует такая его (С) конкретизация I, что
(a) голова I совпадает с G и
(б) все цели в теле I истинны.
Это определение можно распространить на вопросы следующим образом. В общем случае вопрос к пролог-системе представляет собой список целей, разделенных запятыми. Список целей называется истинным (достижимым), если все цели в этом списке истинны (достижимы) при одинаковых конкретизациях переменных. Значения переменных получаются из наиболее общей конкретизации.
Таким образом, запятая между целями обозначает конъюнкцию целей: они все должны быть истинными. Однако в Прологе возможна и дизъюнкция целей: должна быть истинной, по крайней мере одна из целей. Дизъюнкция обозначается точкой с запятой. Например, Р :- Q; R. читается так: Р -истинно, если истинно Q или истинно R. Смысл такого предложения тот же, что и смысл следующей пары предложений: Р :- Q., Р :- R. Запятая связывает (цели) сильнее, чем точка с запятой. Предложение Р :- Q, R;S, Т, U. понимается как: Р :- (Q, R); (S, Т, U). и имеет тот же смысл, что и два предложения Р :- Q, R., Р :- S, T, U.
4. ЛАБОРАТОРНАЯ РАБОТА №3. «Разработка экспертной оболочки»
Цель работы:
1. Изучение компонент модели экспертной системы.
2. Создание экспертной оболочки с продукционным логическим выводом на любом языке программирования, содержащей модули, соответствующие всем компонентам модели экспертной системы.
Теоретическое введение.
Принципиальная архитектура (модель) экспертной системы может быть представлена в виде совокупности следующих компонентов и связей между ними (на Рис.4.1.):
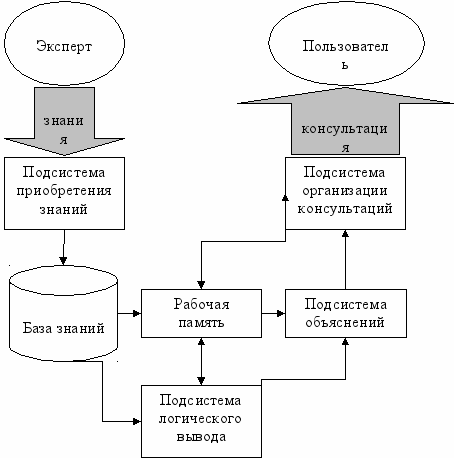
Рис.4.1. – Принципиальная архитектура экспертной системы
а) Рабочая память предназначена для хранения исходных и промежуточных данных решаемой в текущий момент задачи. Возможна организация постоянного хранения таких промежуточных данных в виде графов консультаций.
Данная подсистема реализуется обычно посредством СУБД или электронных таблиц.
б) База знаний в ЭС предназначена для хранения долгосрочных данных (фактов), описывающих рассматриваемую область, и правил, описывающих целесообразные преобразования данных этой области. Часто, база знаний представляет собой базу данных определенной структуры, позволяющей хранить все необходимые атрибуты фактов и правил.
в) Подсистема логического вывода, используя исходные данные из рабочей памяти и знания из базы знаний, формирует такую последовательность правил, которые, применяются к исходным данным и приводят к решению задачи.
По типам (или по способу логического вывода) экспертные системы можно классифицировать следующим образом:
1) продукционные
Основаны на представлении предметной области в виде фактов и правил. Правила состоят из условий срабатывания, связки посылка-заключение и сопутствующего действия. Логический вывод может быть:
– Прямым («от фактов к цели»). Каждое правило рассматривается от посылки к заключению. Заключение не принимается во внимание до тех пор, пока не определится, что посылка истинна. Если же посылка истинна, правило запускается, и выполняются действия заключения. Если посылка правила окажется ложной, тогда действия, указанные в заключении, не выполняются, а рассматривается другое правило.
– Обратным («от цели к фактам»). В основе – установление значения переменной, являющейся общей целью консультации, она является текущей целью. Начиная консультацию, механизм вывода определяет, заключения каких правил могут установить переменную цели и, затем, выбирая одно из них, рассматривает его посылку. Если посылка истинна, правило запускается и устанавливает значение переменной цели. Точно таким же образом обрабатываются и остальные правила, оказывающие влияние на значение переменной цели. Если посылка ложна, правило не запускается и для рассмотрения выбирается следующее правило. В случае, когда посылка рассматриваемого правила не известна, механизм вывода пытается определить значения неизвестных переменных в посылке.
– Смешанным. Суть метода состоит в том, что вывод основной цели начинается обратным методом с определением текущих целей и попыткой их вывода из других правил, однако, при успешной активизации какого-либо правила механизм вывода начинает действовать особым образом. В случае активизации правила, одна или несколько переменных принимают определенные значения. Для этих переменных механизм вывода начинает прямой вывод во всех правилах, где они встречаются в посылке правила. В случае активизации правил появляются новые известные переменные. При невозможности активизации правила, механизм вывода не строит никаких временных подцелей и не возвращается к данному правилу повторно в данной операции. После попыток активизации всех выявленных правил, механизм вывода возвращается к обратному выводу до тех пор, пока не будет активизировано еще какое-либо правило, тогда снова включается прямая цепочка вывода, и так до тех пор, пока не будет достигнута цель консультации.
2) фреймовые
Основаны на представлении знаний в форме специальных иерархически связанных шаблонов – фреймов, состоящих из слотов.
3) основанные на семантических сетях
Под семантической сетью подразумевают систему знаний некоторой предметной области, имеющую определенный смысл в виде целостного образа сети, узлы которой соответствуют понятиям и объектам, а дуги (концепты) – отношениям между объектами.
4) основанные на нечеткой логике
Нечеткая логика, выделившаяся из теории нечетких множеств – это разновидность непрерывной логики, в которой логические формулы могут принимать истинностные значения между 1 и 0. Следовательно все логические выводы осуществляются тоже с какой-то степенью уверенности.
5) использующие вероятностные выводы
6) использующие немонотонные рассуждения.
г) Подсистема приобретения знаний автоматизирует процесс наполнения ЭС знаниями, осуществляемый пользователем-экспертом. Приобретение знаний может осуществляться следующими способами:
1) Ввод знаний пользователем-инженером по знаниям (например, на специализированном внутреннем языке системы).
2) Ввод знаний пользователем-экспертом в текущей предметной области (на естественном языке в формализованном виде).
3) Автоматическое извлечение знаний из баз данных и других информационных систем (используются алгоритмы анализа данных).
д) Подсистема объяснений проводит трассировку вывода, формирует объяснение, содержащее комментарии и информацию о том, как система получила решение задачи, какие знания она при этом использовала. Это облегчает эксперту тестирование системы и повышает доверие пользователя к полученному результату.
Подсистема организации консультаций предназначена для обеспечения эффективной и удобной работы пользователя с системой, как в ходе решения задач, так и в процессе приобретения знаний или объяснения результатов работы. Данная подсистема отвечает за формулирование, а также возможное пояснение вопросов и вариантов ответов на них, обеспечивает наглядное отображение текущих результатов консультации, сохранение и использование графов консультаций, возможность корректировки ответов (фактов из рабочей памяти) с автоматическим изменением результатов текущей консультации, а также несет ряд управляющих функций. Например, выбор режима работы (ввод знаний – консультация) или выбор способа логического вывода (прямой – обратный – смешанный).
5. ЛАБОРАТОРНАЯ РАБОТА №4: «Нечеткая логика»
Цель работы:
1. Конструирование компонент модели экспертной системы.
2. В разработанной экспертной оболочке (Лабораторная работа №3) реализовать машину логического вывода, основанную на нечеткой логике.
Теоретическое введение.
В задачах, которые решают интеллектуальные системы, иногда приходится применять ненадежные знания и факты, представить которые двумя значениями — истина или ложь (1 или 0) — трудно. Существуют знания, достоверность которых, скажем, 0,7. Такую ненадежность в современной физике и технике представляют вероятностью, подчиняющейся законам Байеса, но в инженерии знаний было бы нелогично иметь дело со степенью надежности, приписанной знаниям изначально, как с байесовской вероятностью. Поэтому одним из первых был разработан метод использования коэффициентов уверенности для системы MYCIN. Подробно об обстоятельствах появления этого метода и возникшей дискуссии рассказано в работе Б. Бухенена и Э. Шортлиффа. Этот метод не имеет теоретического подкрепления, но стал примером обработки ненадежных знаний, что оказало заметное влияние на последующие системы. Так, на фирме SRI, США предложен метод выводов, названный субъективным байесовским методом, который использован в системе PROSPECTOR. Позже была введена теория вероятностей Демпстера-Шафера, которая имеет все признаки математической теории.
Связь между подзадачами, на которые разбита задача, оперирующая двумя понятиями — истина и ложь, может быть представлена через операции И и ИЛИ. В задачах с ненадежными исходными данными кроме И и ИЛИ важную роль играет комбинированная связь, которую будем обозначать как КОМБ. Такая связь независимо подкрепляет или опровергает цель на основании двух и более доказательств.
РАЗБИЕНИЕ ЗАДАЧ С НЕНАДЕЖНЫМИ ДАННЫМИ. Для решения сложных задач можно использовать метод разбиения их на несколько подзадач. Каждая подзадача в свою очередь разбивается на простые подзадачи, поэтому задача в целом описывается иерархически. Знания, которые по условиям подзадач определяют условия задач высшего уровня, накапливаются фрагментарно. В задачах с ненадежными данными знания могут не только иметь степень надежности, равную 1, но и промежуточные значения между истиной и ложью. Как отмечено выше, при разбиении на подзадачи возможно соединение И, ИЛИ и КОМБ (комбинированная связь). На рис.5.1 показано описание задачи в виде дерева И, ИЛИ, КОМБ.
Н
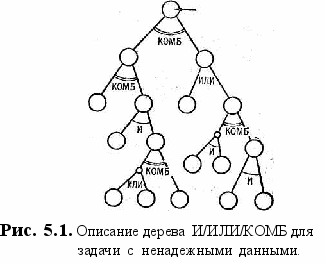 а основании двух и более доказательств цели независимо подтверждаются или опровергаются, если связь комбинированная.
а основании двух и более доказательств цели независимо подтверждаются или опровергаются, если связь комбинированная.Знания будем описывать с помощью правил как в системе продукций (рис.5.2.): пусть X, Y — результаты доказательств; А — цель пли гипотеза; И, ИЛИ и КОМБ — виды связей; С1, С2, С31, С32 — это степени надежности, приписанные правилам.
Д
 опустим, что уже определены степени надежности X и Y как результаты предыдущих выводов или наблюдений, и сделаем вывод или вычислим степень надежности А, используя правила из базы знаний. Кроме общеизвестных методов выбора минимального значения степеней надежности из нескольких выводов при связи И и максимального при связи ИЛИ, других подходящих методов не существует, а при связи КОМБ предложены метод MYCIN, субъективный байесовский метод, а также теория Демпстера — Шафера.
опустим, что уже определены степени надежности X и Y как результаты предыдущих выводов или наблюдений, и сделаем вывод или вычислим степень надежности А, используя правила из базы знаний. Кроме общеизвестных методов выбора минимального значения степеней надежности из нескольких выводов при связи И и максимального при связи ИЛИ, других подходящих методов не существует, а при связи КОМБ предложены метод MYCIN, субъективный байесовский метод, а также теория Демпстера — Шафера.НЕЧЕТКАЯ ЛОГИКА, выделившаяся из теории нечетких множеств, — это разновидность непрерывной логики. В нечеткой логике достоверность представляется как истинностное значение между 1 и 0, и значения, приписанные правилам на Рис.5.2., это и есть истинностные значения. Пусть tx и ty — истинностные значения предпосылок X и Y некоторого правила, тогда истинностное значение tпредпосылки в случае связей И и ИЛИ на рис.5.2.А),Б) определяется следующим образом.
1. При связи И tпредпосылки = min{tx, ty}. [5.1]
2. При связи ИЛИ tпредпосылки = max{tx, ty}. [5.2]
Если в общем случае tправила есть истинностное значение, приписанное правилу, то истинностное значение tА, распределенное на вывод, определяется как
tА = min{tпредпосылки, tправила}. [5.3]
Определение минимума — это идея, свойственная нечеткой логике и отличающая ее от других методов.
6. ЛАБОРАТОРНАЯ РАБОТА №5: «Алгоритмы нейронных сетей»
Цель работы:
1. Изучение компонент обучающихся информационных системы.
2. Создать программу, позволяющую распознавать графические изображения цифр, представленные в двоичном формате, с помощью алгоритма нейронной сети (63 входа, 18 нейронов на первом слое, 9 на втором).
Теоретическое введение.
Искусственный нейрон (Рис.6.1.) имитирует в первом приближении свойства биологического нейрона. Каждый вход умножается на соответствующий вес и все произведения суммируются, определяя уровень активации нейрона.
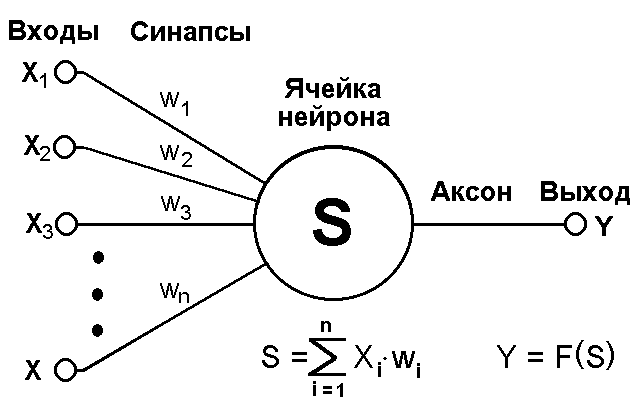
Рис.6.1. Ячейка нейрона, где S – взвешанная сумма входных параметров,
Xi – входные данные от i-ого входного элемента,
Wi – весовой коэффициент связи.
Выход нейрона является функцией его состояния Y = F(x).
Нелинейная функция F называется активационной и может иметь различный вид, что, в частности, показано на Рис.6.2.
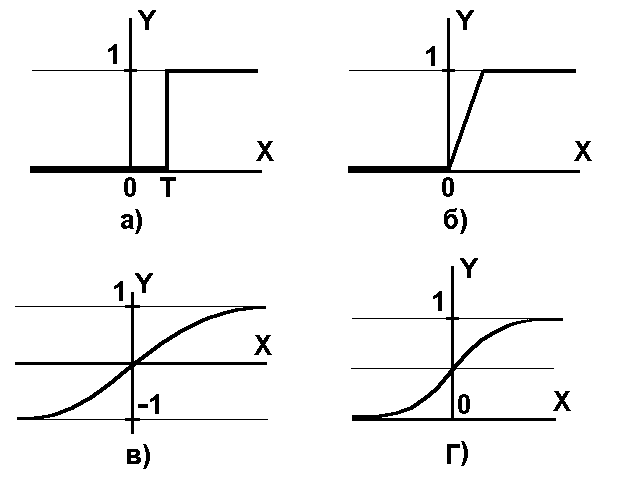
Рис.6.2. Виды активационных функций:
а) единичного скачка; б) линейного порога;
в) гиперболический тангенс; г) сигмоид.
В случае, когда функция активации одна и та же для всех нейронов сети, сеть называют однородной (гомогенной).
Одной из наиболее распространенных является нелинейная функция с насыщением, так называемая логистическая функция или сигмоид (т.е. функция S-образного вида):
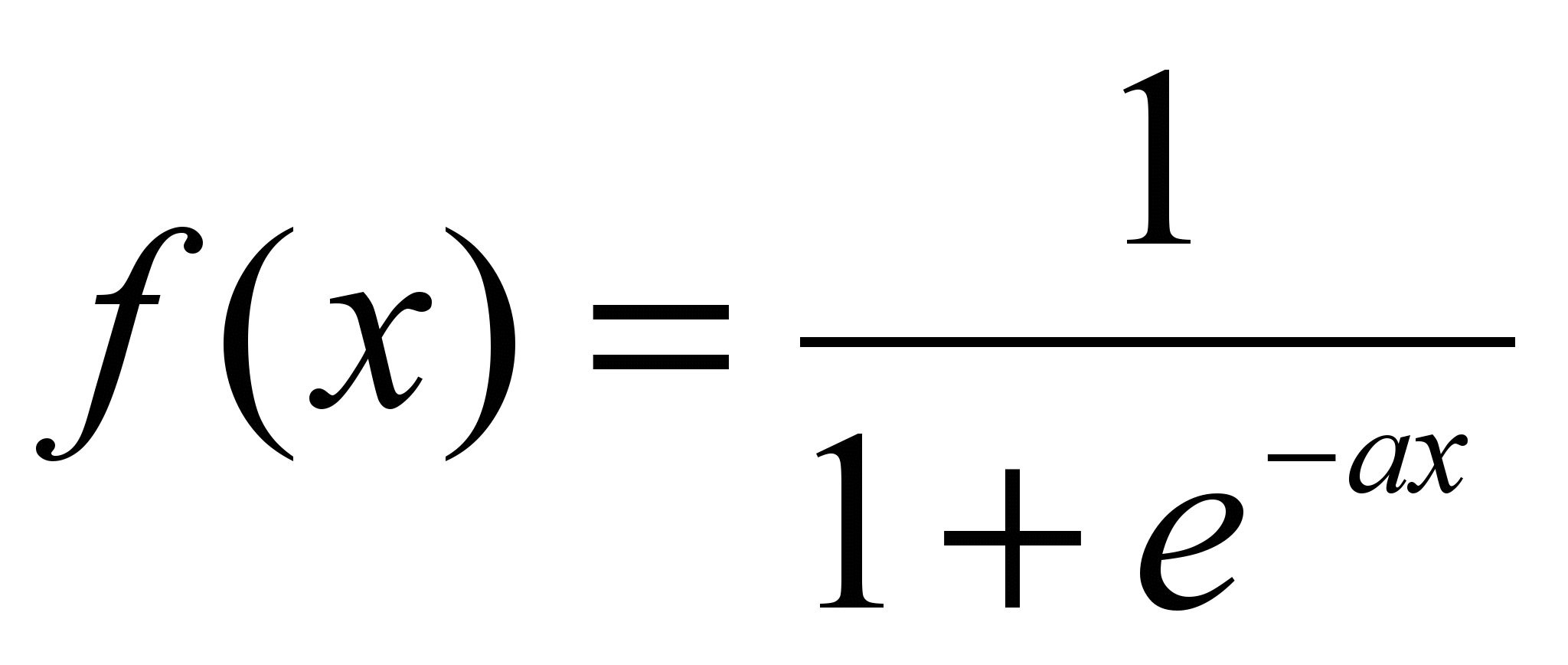 [6.1]
[6.1]При уменьшении сигмоид становится более пологим, в пределе при =0 вырождаясь в горизонтальную линию на уровне 0.5. При увеличении сигмоид приближается по внешнему виду к функции единичного скачка с порогом Т в точке х=0. Из выражения для сигмоида очевидно, что выходное значение нейрона лежит в диапазоне [0,1]. Одно из ценных свойств сигмоидной функции – простое выражение для ее производной:
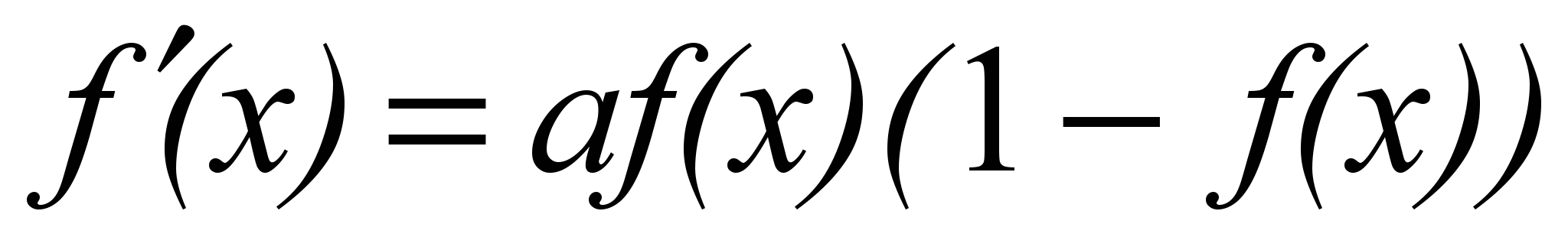 [6.2]
[6.2]Следует отметить, что сигмоидная функция дифференцируема на всей оси абсцисс, что широко используется во многих алгоритмах обучения. Кроме того, она обладает свойством усиливать слабые сигналы лучше, чем сильные, и предотвращает насыщение от сильных сигналов, так как они соответствуют областям аргументов, где сигмоид имеет пологий наклон.
Многослойные сети прямого распространения
К
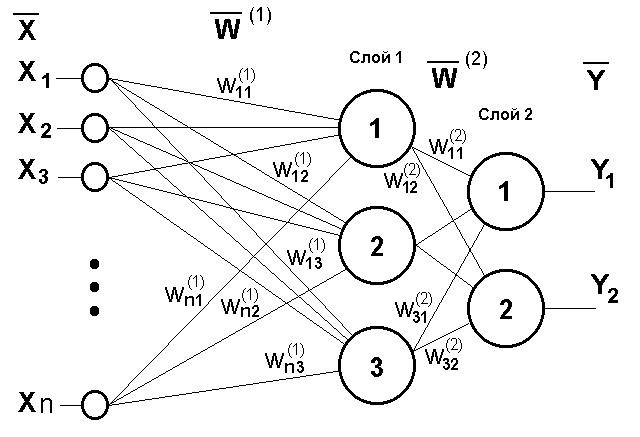 ласс нейронных сетей прямого распространения характеризуется наличием одного или нескольких скрытых слоев, узлы которых называются скрытыми нейронами, или скрытыми элементами. Функция последних заключается в посредничестве между внешним входным сигналом и выходом нейронной сети. Узлы источника входного слоя сети формируют соответствующие элементы шаблона активации (входной вектор), которые составляют входной сигнал, поступающий на нейроны (вычислительные элементы) второго слоя (т.е. первого скрытого слоя). Выходные сигналы второго слоя используются в качестве входных для третьего слоя и т.д. Обычно нейроны каждого из слоев сети используют в качестве входных сигналов выходные сигналы нейронов только предыдущего слоя. Набор выходных сигналов нейронов выходного (последнего) слоя сети определяет общий отклик сети на данный входной образ, сформированный узлами источника входного (первого) слоя.
ласс нейронных сетей прямого распространения характеризуется наличием одного или нескольких скрытых слоев, узлы которых называются скрытыми нейронами, или скрытыми элементами. Функция последних заключается в посредничестве между внешним входным сигналом и выходом нейронной сети. Узлы источника входного слоя сети формируют соответствующие элементы шаблона активации (входной вектор), которые составляют входной сигнал, поступающий на нейроны (вычислительные элементы) второго слоя (т.е. первого скрытого слоя). Выходные сигналы второго слоя используются в качестве входных для третьего слоя и т.д. Обычно нейроны каждого из слоев сети используют в качестве входных сигналов выходные сигналы нейронов только предыдущего слоя. Набор выходных сигналов нейронов выходного (последнего) слоя сети определяет общий отклик сети на данный входной образ, сформированный узлами источника входного (первого) слоя. Рис.6.3. Многослойные сети
прямого распространения.
Алгоритм обратного распространения
Согласно метода наименьших квадратов, минимизируемой целевой фун-
кцией ошибки НС является величина
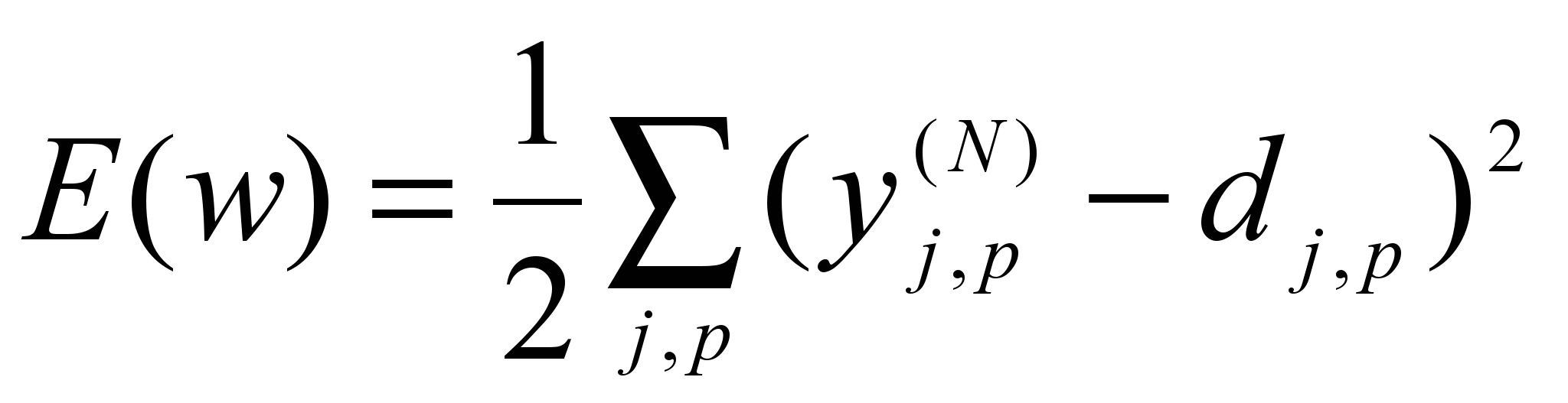 , где
, где 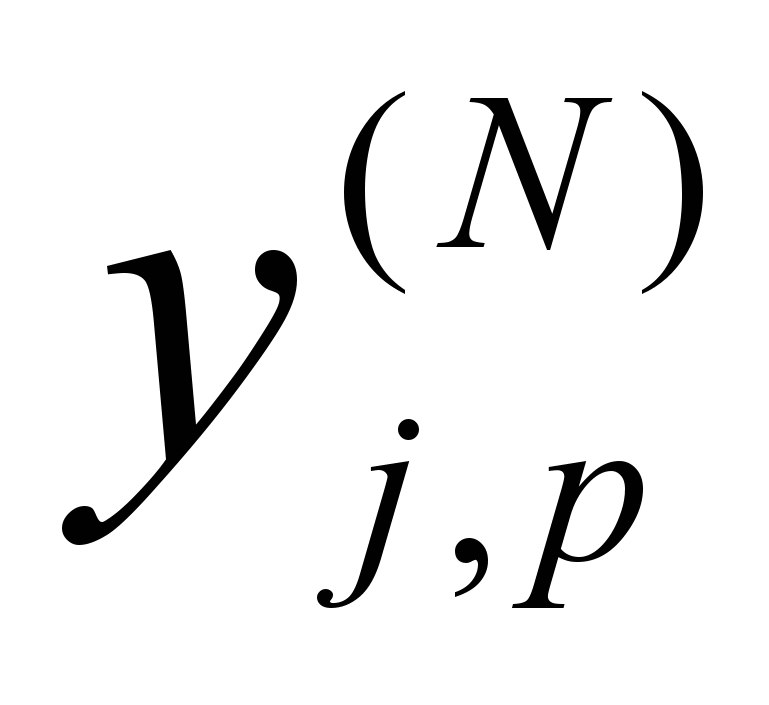 – ре-
– ре-альное выходное состояние нейрона j выходного слоя N нейронной сети при подаче на ее входы p-го образа; djp – идеальное (желаемое) выходное состояние этого нейрона.
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым сетью образам. Минимизация ведется методом градиентно-
го спуска, что означает подстройку весовых коэффициентов
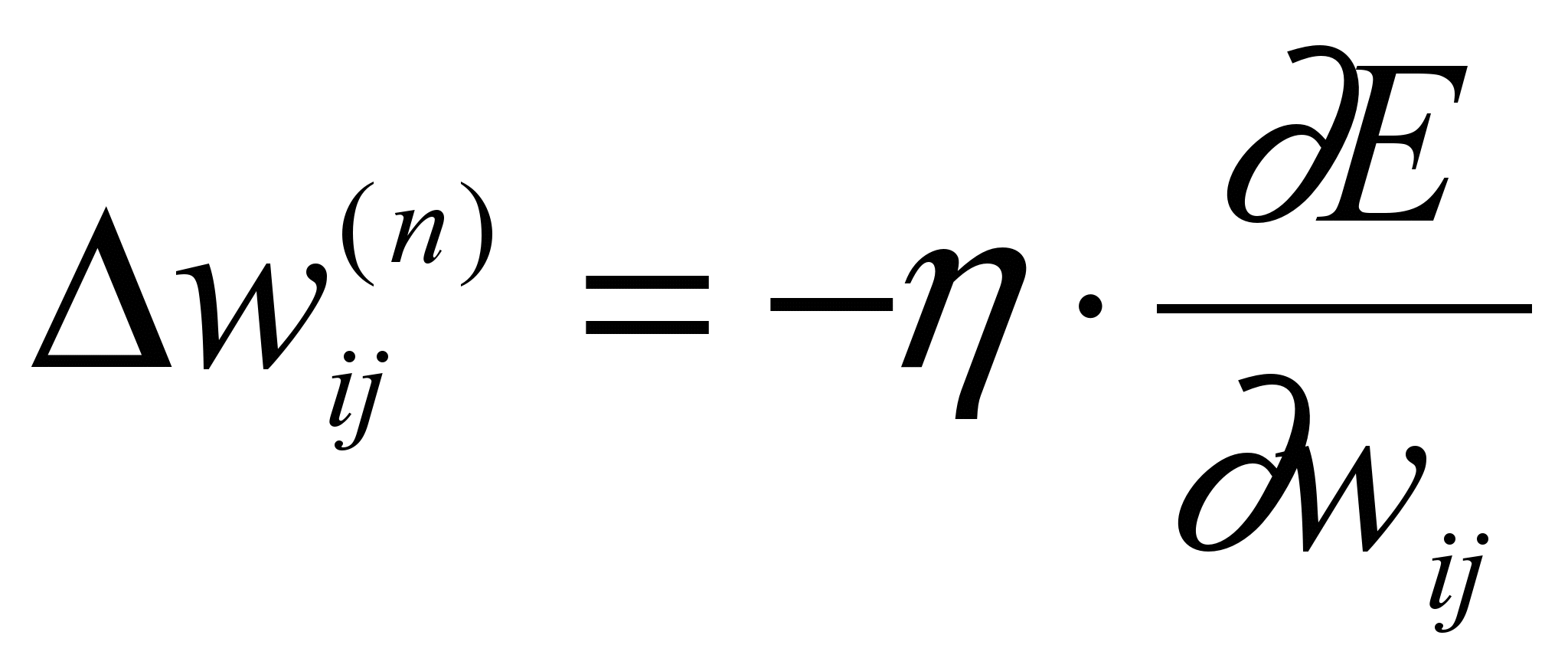 ,
,где wij – весовой коэффициент синаптической связи, соединяющей i-ый нейрон слоя n-1 с j-ым нейроном слоя n, – коэффициент скорости обучения,
0<<1. А производная определяется
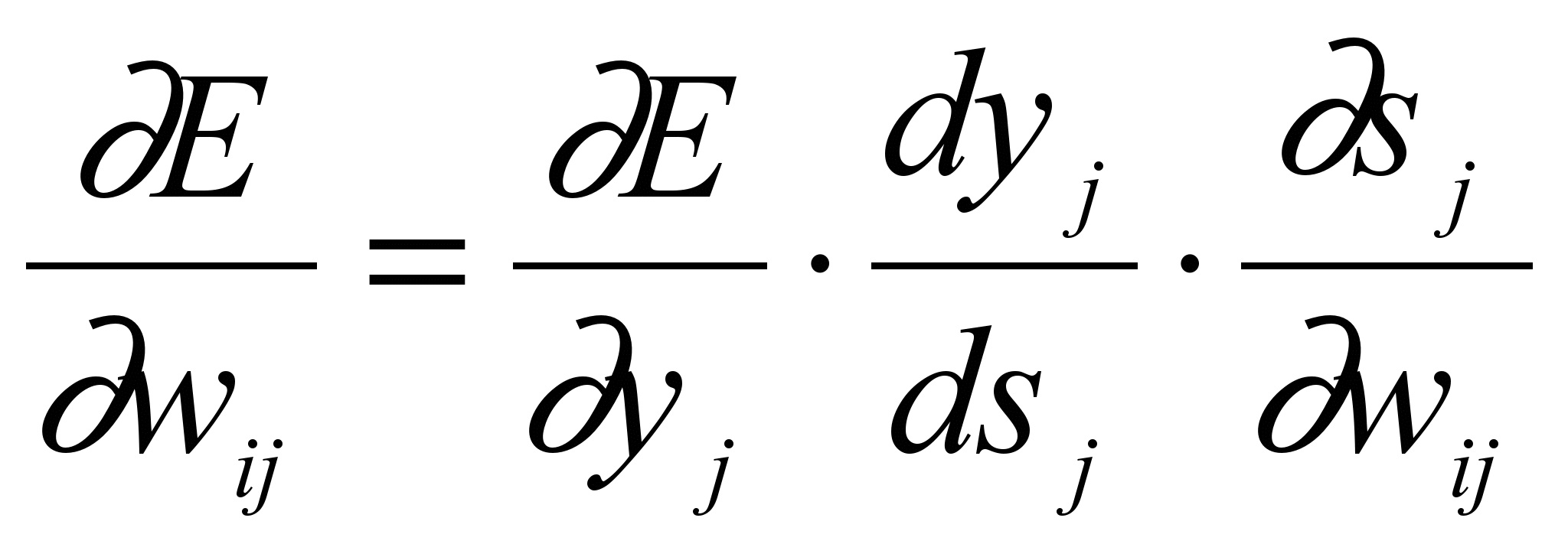 , где под yj, подра-
, где под yj, подра-зумевается выход нейрона j, а под sj – взвешенная сумма его входных сигналов, то есть аргумент активационной функции. Так как множитель dyj/dsj является производной этой функции по ее аргументу, из этого следует, что производная активационной функция должна быть определена на всей оси абсцисс. В связи с этим функция единичного скачка и прочие активационные функции с неоднородностями не подходят для рассматриваемых НС. В них применяются такие гладкие функции, как гиперболический тангенс или классический сигмоид с экспонентой.
Третий множитель sj/wij, очевидно, равен выходу нейрона предыдущего слоя yi(n-1).
Что касается первого множителя, он легко раскладывается следующим образом:
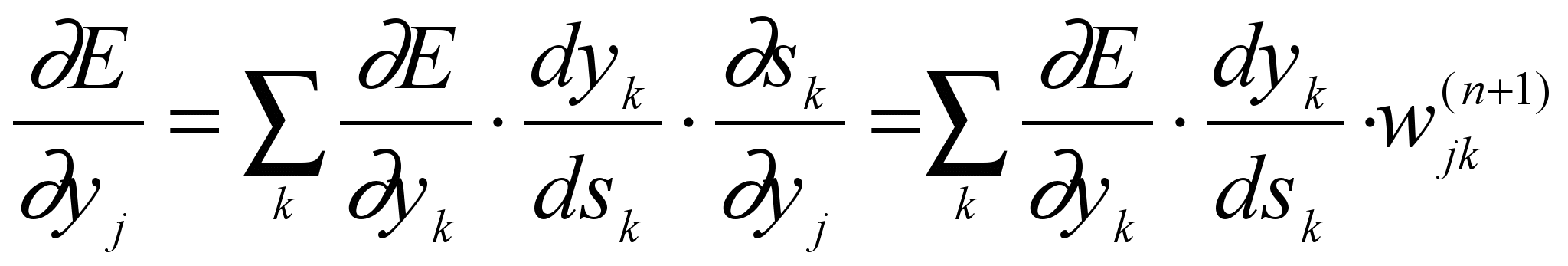
Здесь суммирование по k выполняется среди нейронов слоя n+1.
Введя новую переменную
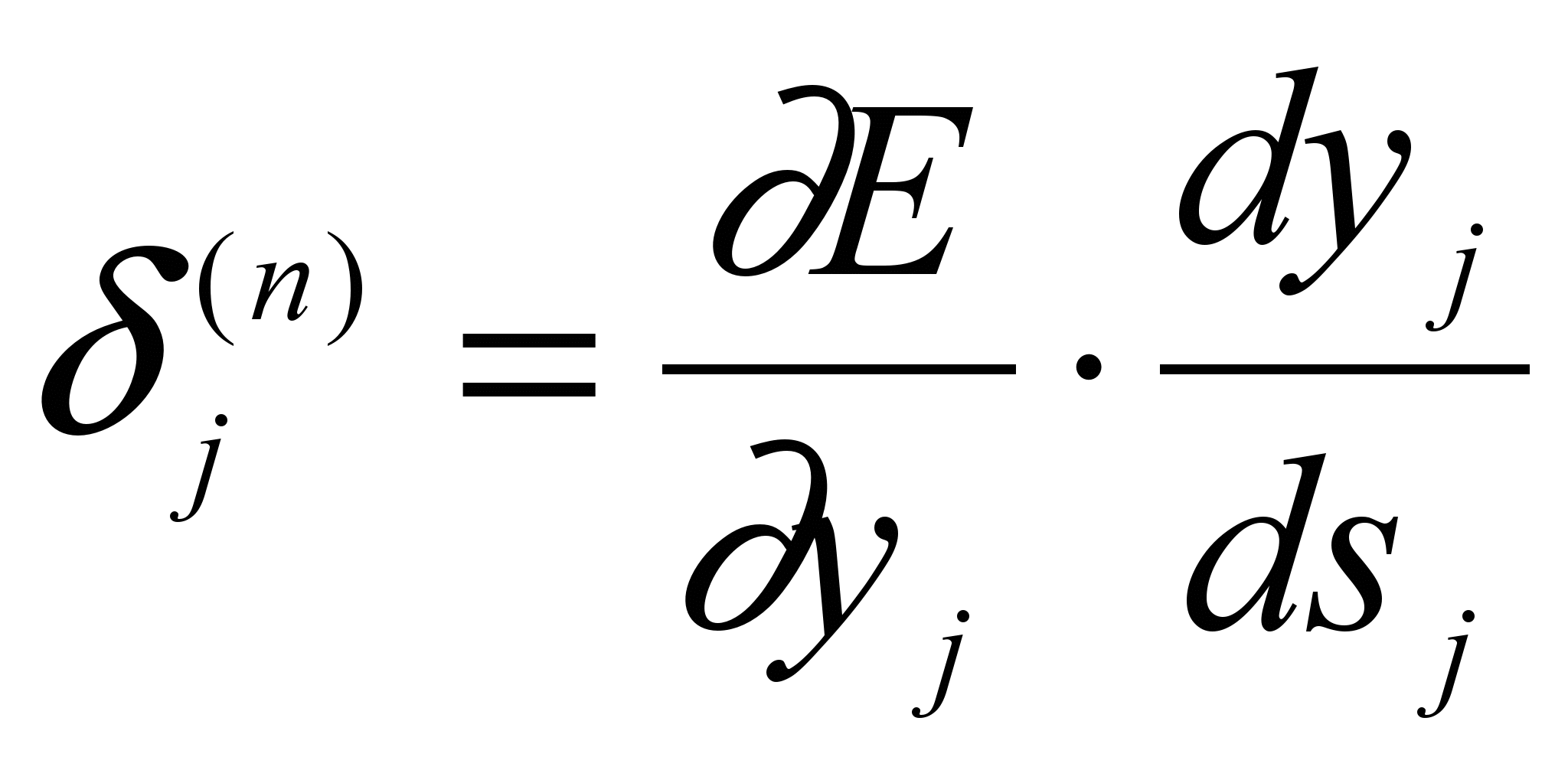 мы получим рекурсивную фор-
мы получим рекурсивную фор-мулу для расчетов величин j(n) слоя n из величин k(n+1) более старшего слоя n+1.
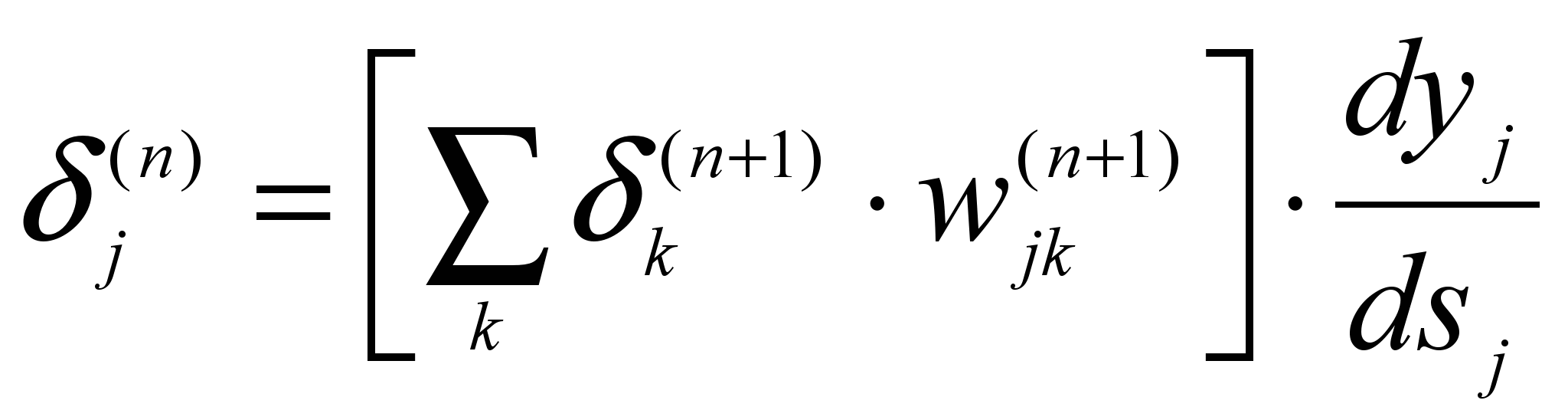 [6.3]
[6.3]Для выходного же слоя
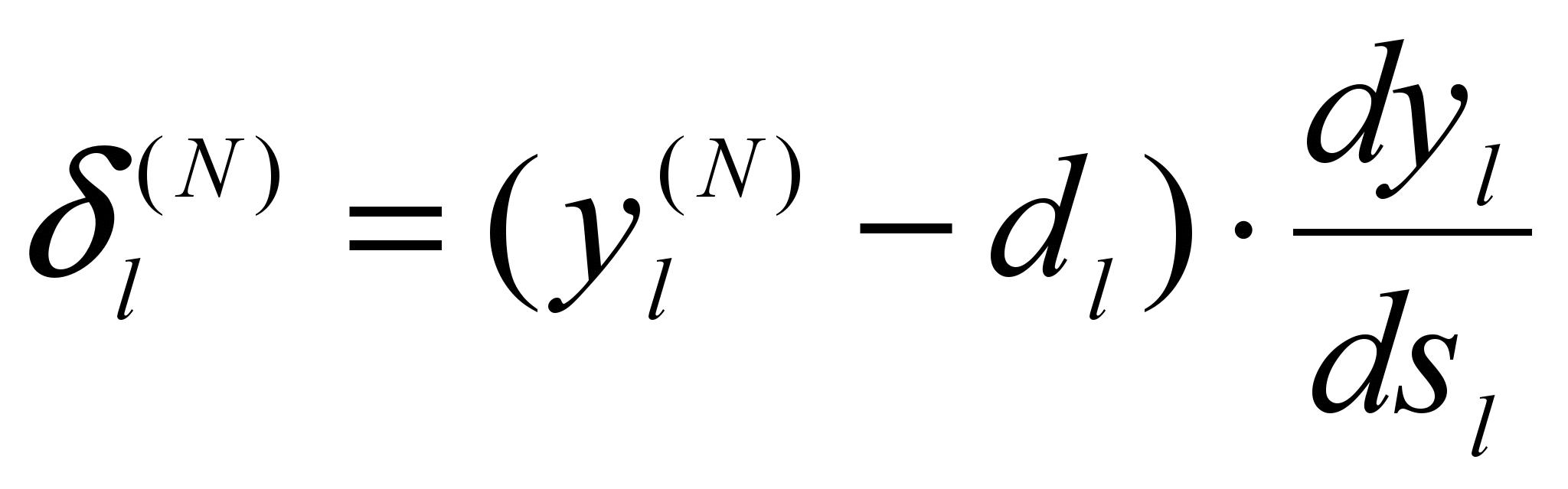 [6.4]
[6.4]В данном случае производная
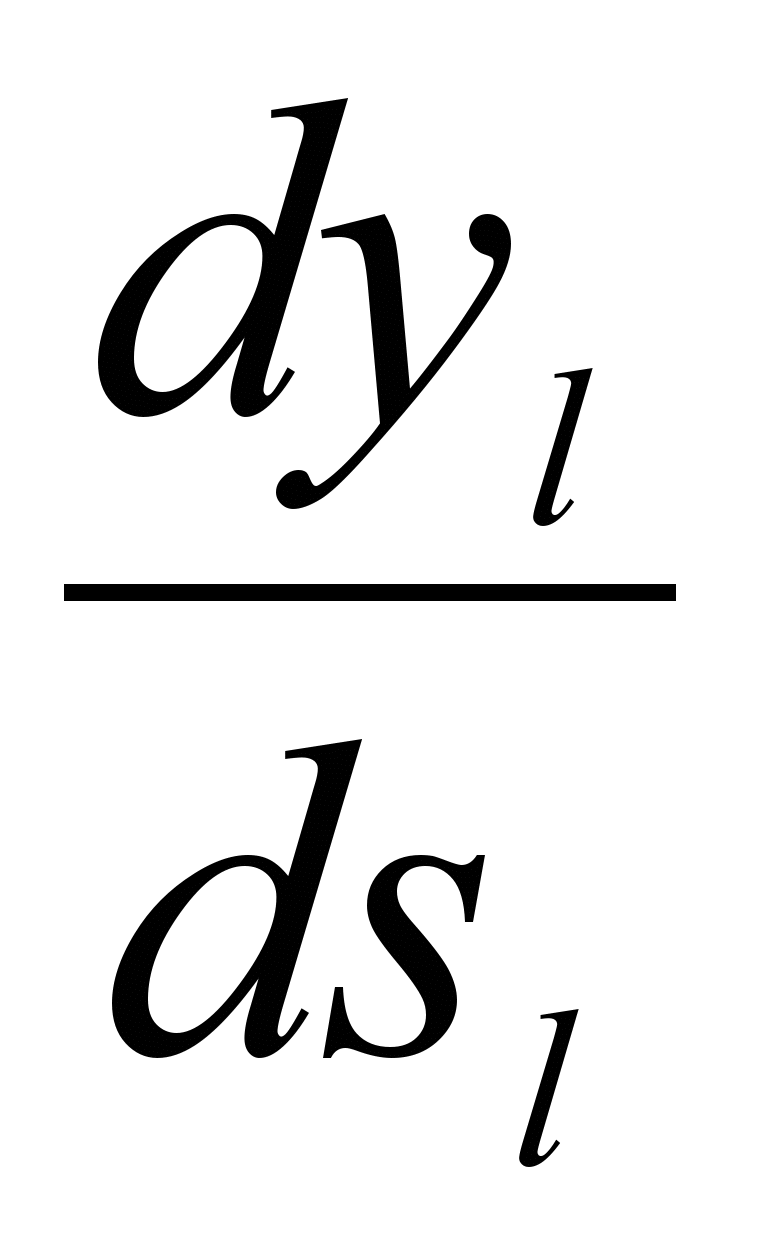 вычисляется по формуле [6.2]
вычисляется по формуле [6.2]Теперь мы можем записать в раскрытом виде:
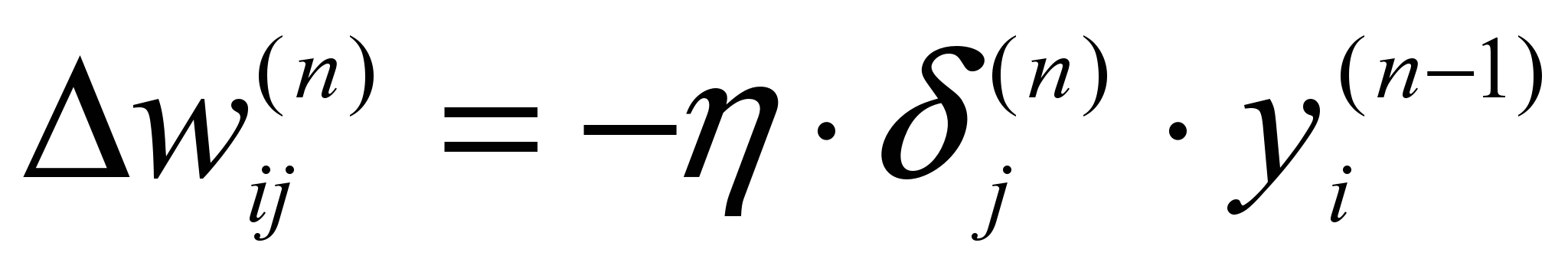 [6.5]
[6.5]Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, дополняется значением изменения веса на предыдущей итерации:
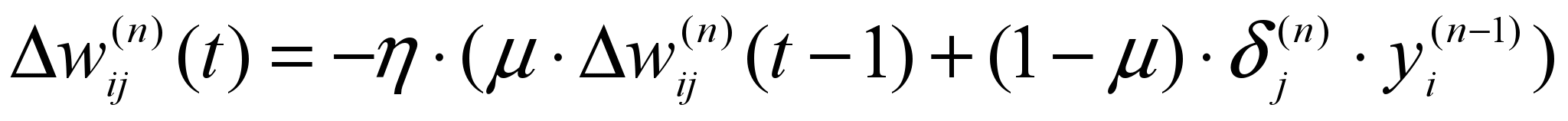 [6.6]
[6.6]где – коэффициент инерционности, t – номер текущей итерации.
Полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
Шаг 1.Подать на входы сети один из возможных образов и рассчитать результат. (Каждый нейрон вычисляет значение по формуле [6.1], в качестве функции активации использовать сигмоид.)
Шаг 2. Рассчитать (N) для выходного слоя по формуле [6.4]. Рассчитать по формуле [6.5] или [6.6] изменения весов w(N) слоя N.
Шаг 3. Рассчитать по формулам [6.3] и [6.5] (или [6.3] и [6.6]) соответственно (n) и w(n) для всех остальных слоев, n=N-1,...1.
Шаг 4. Скорректировать все веса в НС
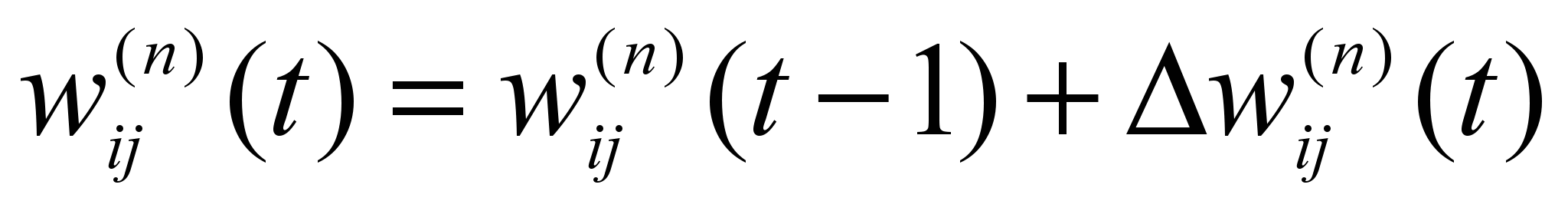 [6.7]
[6.7]где t – номер текущей итерации.
Шаг 5. Если ошибка сети существенна, перейти на Шаг 1. В противном случае – конец.
Принять:
– коэффициент инерционности принять равным 0.5,
– коэффициент скорости обучения принять равным 0.5,
– принять равным 0.3.
7. СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ
1. Андрейчиков А.В., Андрейчикова О.Н. Интеллектуальные информационные системы: Учебник. – М.: Финансы и статистика, 2004. – 424 с.
2. Гаврилова Т.А., Червинская К.Р. Извлечение и структурирование знаний для экспертных систем. – М.: Радио и связь, 1992 – 198 с.
3. Змитрович А.И. Интеллектуальные информационные системы. – Мн.: НТООО «ТетраСистемс», 1997 – 368 с.
4. Кофман А. Введение в теорию нечетких множеств. – М.: Радио и связь, 1982 – 432 с.
5. Лорьер Ж.-Л. Системы искусственного интеллекта. – М.: Мир, 1991 – 586 с.
6. Обработка знаний / Под ред. Осуга С. – М.: Мир, 1989 – 293 с.
7. Представление и использование знаний / Под ред. Уэно Т., Исидзука М. – М.: Мир, 1989 – 220 с.
8. Яйлеткан А.А. Логика BFSN или порождающие схемы логики. – Тюмень: ТОГИРРО, 2002 – 35 с.
9. Яйлеткан А.А. Обобщение и систематизация основ математической логики. – Тюмень: ТОГИРРО, 2002 – 373 с.
10. Яйлеткан А.А. Интеллектуальные информационные системы. – Тюмень: ТюмТГНГУ, 2007 – 128 с.
8. ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА
1. Амамия М., Танака Ю. Архитектура ЭВМ и ИИ. – М.: Мир, 1993.
2. Андрейчиков А.В., Андрейчикова О.Н. Компьютерная поддержка изобретательства (методы, системы, примеры, применения). – М.: Машиностроение, 1998.
3. Андриенко Г.Л., Андриенко Н.В. Игровые процедуры сопоставления в инженерии знаний // Сб. тр. III конференции по искусственному интеллекту. – Тверь, 1992.
4. Батищев Д.И. Генетические алгоритмы решения экстремальных задач: Учеб. пособие. – Воронеж: Изд-во ВГТУ, 1995.
5. Борисов А.Н., Крумберг О.А., Федоров И.П. Принятие решений на основе нечетких моделей. – Рига: Зинатне, 1990.
6. Букатова И.Л. Эволюционное моделирование и его приложения. – М.: Наука, 1979.
7. Гаврилова Т.А., Хорошевский В.Ф. Базы знаний интеллектуальных систем. – СПб.: Питер, 2000.
8. Искусственный интеллект: В 3 кн. Кн. 1. Системы общения и экспертные системы: Справочник / Под ред. Э.В. Попова. – М.: Радио и связь, 1990.
9. Искусственный интеллект: В 3 кн. Кн. 2. Модели и методы: Справочник / Под ред. Д.А. Поспелова. – М.: Радио и связь, 1990.
10. Искусственный интеллект: В 3 кн. Кн. 3. Программные и аппаратные средства: Справочник / Под ред. В.Ф. Хорошевского. – М.: Радио и связь, 1990.
11. Корнеев В.В. и др. Базы данных. Интеллектуальная обработка информации. – М.: Нолидж, 2000.
12. Логический подход к искусственному интеллекту: от классической логики к логическому программированию: Пер. с фр. / А. Тейз, П. Грибомон, Ж. Луи и др. – М.: Мир, 1990.
13. Нильсон Н.Дж. Искусственный интеллект. Метод поиска решений. – М.: Мир, 1973.
14. Осипов Г.С. Приобретение знаний интеллектуальными системами. – М.: Наука, 1997.
15. Половинкин А.И. Основы инженерного творчества. – М.: Машиностроение, 1988.
16. Хант Э. Искусственный интеллект: Пер. с англ. / Под ред. В.Л. Стефанюка. – М.: Мир, 1978.
17. Экспертные системы. Принципы работы и примеры: Пер. с англ. / Под ред. Р. Форсайта. – М.: Радио и связь, 1987.
18. Элти Дж., Кумбс М. Экспертные системы: концепции и примеры: Пер. с англ. – М.: Финансы и статистика, 1987.
СОДЕРЖАНИЕ:
1. НАЗНАЧЕНИЕ УКАЗАНИЙ 3
2. ЛАБОРАТОРНАЯ РАБОТА №1 «Экспертные оболочки» 3
3. ЛАБОРАТОРНАЯ РАБОТА №2 «Логическое программирование» 10
4. ЛАБОРАТОРНАЯ РАБОТА №3 «Разработка экспертной оболочки» 19
5. ЛАБОРАТОРНАЯ РАБОТА №4 «Нечеткая логика» 23
6. ЛАБОРАТОРНАЯ РАБОТА №5 «Алгоритмы нейронных сетей» 26
7. СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ 30
8. ДОПОЛНИТЕЛЬНАЯ ЛИТЕРАТУРА 30