
Информатика и программирование Информация и информатика. Информация
| Вид материала | Изложение |
- Конспекты лекций по курсу «Информатика» Для студентов Аграрного факультета рудн, 699.31kb.
- Вопросы к зачету по курсу лекций "Информатика" для студентов Iкурса кафедры аэту iсеместр., 18.81kb.
- 1 семестр Информатика, ее предмет и задачи. Основные понятия информатики. Информация, 2127.85kb.
- Программа дисциплины по кафедре Прикладная математика т информатика алгоритмические, 564.02kb.
- Задания для контрольной работы по курсу «Математика и информатика», 50.38kb.
- Лекции по информатике Лекция Введение в информатику Термин "информатика" (франц informatique), 626.63kb.
- Лекция Введение в информатику > Что такое инфоpматика? Термин "информатика" (франц, 179.14kb.
- Лекция Введение в информатику > Что такое инфоpматика? Термин "информатика" (франц, 3049.6kb.
- Рабочая программа по дисциплине "алгоритмизация и программирование" для специальности, 136.39kb.
- Рабочая учебная программа по дисциплине «Программирование на языке высокого уровня», 119.59kb.
Информатика и программирование
Информация и информатика.
Информация
Information – сведение, разъяснение, изложение. В обиходе под информацией понимают любые данные либо сведения, интересующие кого-либо.
Информировать – сообщать что-либо ранее неизвестное.
Сигналы и данные.
Все виды энергообмена сопровождаются появлением сигнала. Сигналы регистрируются физическими телами.
Процесс регистрации сигналов – процесс изменения физических тел.
Данные – зарегистрированный сигнал. Данные несут информацию, но они не адекватны понятию информации. Для того чтобы данные несли информацию, необходим метод обработки данных.


 А
АИ
 зменение времени (насколько не известно, необходима обработка информации).
зменение времени (насколько не известно, необходима обработка информации).В
Информация – продукт взаимодействия данных и адекватных им методов. Важно следующее обстоятельство: информация носит динамический характер, потому, что возникает в момент обработки данных методами. Требуется адекватность методов, ведь одни и те же данные в момент потребления могут доставлять разную информацию. Диалектический характер данных и методов: данные по своей природе являются объективными, методы же субъективны.



С
 ИГНАЛ ДАННЫЕ ИНФОРМАЦИЯ
ИГНАЛ ДАННЫЕ ИНФОРМАЦИЯРегистрация Адекватный
метод
обработки
Свойства информации
1. Объективность и субъективность информации.
Более объективной принято считать ту информация, в которую методы вносят меньший субъективный элемент. В ходе информационного процесса степень объективности информации понижается. Полнота информации определяется достаточностью данных. Чем полнее данные, тем шире диапазон методов, вносящий минимум погрешностей в ходе информационного процесса.
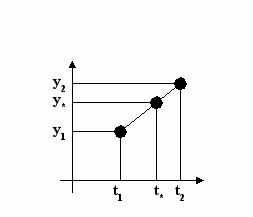
Метод интерполяции
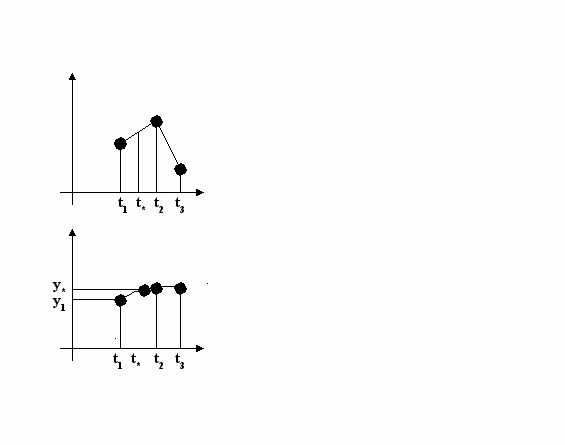
Y=Y(t)
y-y1 / y2- y1 = t-t1 / t2- t1
y = at2 + bt + c
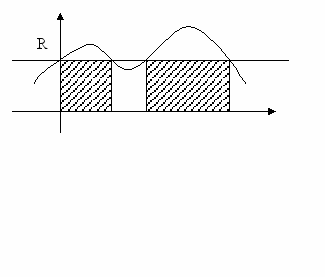
2. Достоверность информации определяется уровнем «информационного шума».
При увеличении шума достоверность информации снижается.
3. Адекватность информации – соответствие объективному состоянию дел. Неадекватность информации может быть основана на неполных либо недостоверных данных.
4. Доступность информации – мера возможности получить ту или иную информацию.
РегистрацияС
 ИГНАЛ ДАННЫЕ ИНФОРМАЦИЯ
ИГНАЛ ДАННЫЕ ИНФОРМАЦИЯДостоверность Адекватный
информации метод
обработки
5. Актуальность информации – степень соответствия информации текущему моменту времени.
Рассмотрим второй подход:
Данные и информации одно – и тоже.
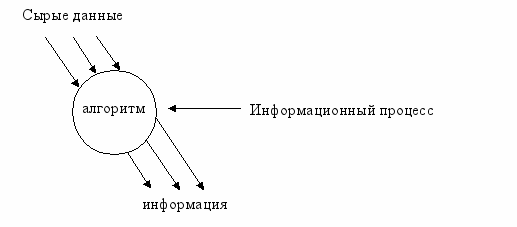
Операции с данными и информацией.
1. сбор данных
2. формализация данных (приведение данных к одной форме)
3. фильтрация данных (отсеивание лишних данных)
4. защита данных
5. архивация данных
6. сортировка данных
7. транспортировка данных
8. преобразование данных
Линейная структура (список). Структура имеет последовательный доступ.
Достоинство: простота обращения. Недостаток: время поиска данных
Иерархичная структура (дерево).
Достоинство: простота поиска. Недостаток: длина пути.
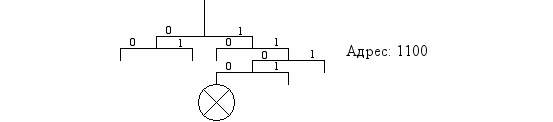
Табличная структура. Структура содержит и элементы списка, и иерархичные элементы.
Методы и модели оценки количества информации.
1 – объёмный
2 – энтропийный
3 – алгоритмический
1. Объёмный
Вычислительная техника: количество информации сообщения – количество символов сообщения. Метод чувствителен к способу представления сообщения. Одно и то же сообщение может быть описано разными способами. Возникает проблема выбора алфавитов и описания.
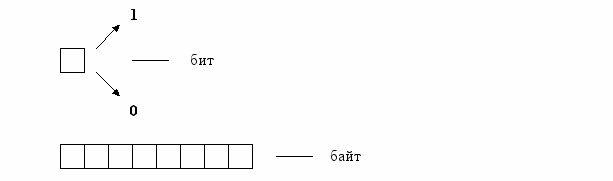
28 = 256
Информатика = 11 байт
2. Энтропийный
Подход принят в теории информации и кодирования. Получатель информации имеет определённое представление о возможности наступления некоторых событий. Эти представления выражаются с помощью вероятности, с которой наступит то или иное событие.
I = Hapr – Haps
A priori (из предшествующего, до опыта)
A posteriori (из последующего, после опыта)
Если, Haps = 0 – при получении информации полностью сняли неопределённость
I = Hapr
H – мера неопределённости системы. H должно удовлетворять естественным свойствам системы. Чем больше источников информации, тем больше неопределённости.
Если бы мы рассматривали два независимых источника информации, то естественно было бы предположить, что их энтропии следовало бы сложить.
Для измерения информации следует подобрать такую функцию, чтобы выполнялись свойства:
1 – F(n) – монотонная, возрастающая.
2 – F(nm) = F(n) + F(m)
3 – F(n=1) = 0
H = log2m
Можно использовать натуральное состояние: H = lnm
m – количество возможных состояний источника.
Величина m – число равновероятных возможных выборов.
Допустим, что имеется колода из 32 карт. Каково количество информационных сообщений, что наугад взятая карта из колоды – туз пик?
Pi = 1/m = 1/32
H = log232 = 5
Число 5 показывает количество вопросов с двоичным ответом («да» либо «нет»), отвечая на которые можно угадать заданную карту.
Загаданная карта – 10.
Вопросы:
1 – Номер больше либо равен 16? Ответ: «нет» - 0
2 - Номер больше либо равен 8? Ответ: «да» - 1
3 - Номер больше либо равен 12? Ответ: «нет» - 0
4 - Номер больше либо равен 10? Ответ: «да» - 1
5. Номер равен 10? Ответ: «да» - 1
Какой вид имеет формула, если источник информации выдаёт неравновероятные сигналы? Рассмотрим источник, неопределённость которого задаётся ансамблем состояний.
A = ( a1 a2 … am )
( p1 p2 … pm )
( 0 1 )
A = ( 1 1 )
( 1 2 )
p1 + p2 = ½ +½ = 1
pj = 1
( 1 2 3 )
A = ( 1 1 1 )
( 2 4 4 )
hi = log21/pi – Формула Шеннона
pi – вероятность выбора i сообщения, символа, буквы или состояния источника.
hi = -log2pi
H = pi hi = - pi log2pi
Покажем, что если вероятности p1 = p2 = pm = 1/m, то формула Шеннона даёт нам формулу:
H = 1/m log21/m = -1/m log2m-1 = m/m log2m = log2m
Согласно экспериментальным данным вероятность появления в русской раскладке:
Символа пробел -0,75 %
Буквы «о» - 0,09%
Буквы «а» - 0,062%
и.т.д.
Таким образом, слово «информатика» можно записать как:
Pi;H = 0,01log20,01 - 0,053log20,053 - … - 0,062log20,062
Можно определить избыток источника сообщений: D = (Hmax(A) – H(A)) / Hmax(A)
Избыточность русского алфавита:
D(A) = 0,13
Избыточность латинского алфавита:
D(A) = 0,15
Уровни изучения свойств сообщения
Существует 3 уровня:
1 – Синтаксический (рассмотрение внутренних свойств сообщения, т.е. отношение межу символами, знаками, изучение структуры знаковой системы) На этом уровне используется энтропийный подход. Возникают проблемы теоретической информации. Цель: совершенствование средств передачи данных, разработка алгоритмов кодирования, увеличение скорости передачи.
2 – Семантический (анализируются отношение между знаками сообщений, отношения сообщений и источников информации). Для измерения смыслового содержания на семантическом уровне применяется тезаурусная мера. При полном отсутствии знаний о предмете, количество полученной информации будет равно нолю. С ростом знаний сообщение дает больше информации. Но если имеешь максимум знаний об объекте, то информации о нём ты получить не сможешь.
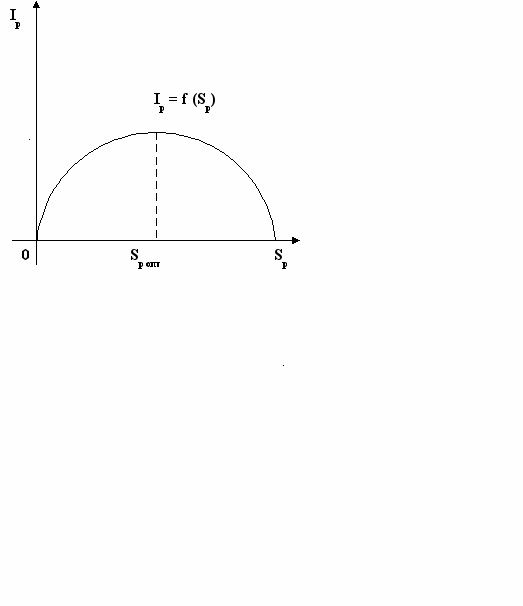
Тезаурус – совокупность сведений, которыми располагает пользователь или система. S – тезаурус системы, Sp – тезаурус пользователя.
- Sp = 0 – пользователь не воспримет информацию.
- Sp = – пользователь всё знает и поступившая информация ему не нужна.
- Sp = Sp опт – смысл содержания сообщения совпадает с тезаурусом пользователя, информация понятна и приносит пользу.
C = I / V (объём информации сообщения)
3 – Прагматический (рассматривается отношение между сообщением и получателем). Потребительское содержание сообщения – величина относительная и зависит от того, в какой информационной системе работаешь. За меру ценности информации принимается количество информации, необходимое для достижения заданных целей.
P0 – количество информации в точке 0
P1 - количество информации в точке 1
I = log2 P1 - log2 P2 = P1 log2 P1/P0
Информация измеряется в битах.
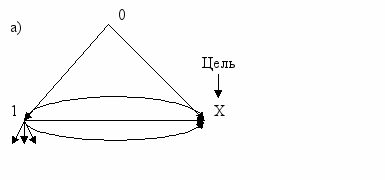
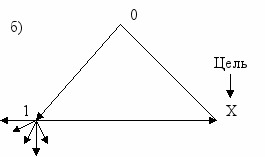
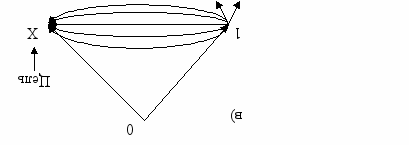
 - Благоприятный исход
- Благоприятный исхода) P1 = 3/6 = ½; P0 = ½; I = log2 1 = 0
б) P1 = 1/6; P0 = ½; I = log2 1/3 = -log32 – отрицательная ценность информации
в) P1 = 2/3; P0 = ½; I = log2 4/3 ≈0,42
Алгоритмический подход
Количество информации в сообщении определяется сложностью алгоритма или программы, которая может воспроизвести данное сообщение. Чем сложнее программа, тем больше информации в данном сообщении. Сообщение, состоящее из одних «0» может воспроизвести более простая программа, чем та программа, которая способна воспроизвести сообщение из «01». Ни какая последовательность не может быть воспроизведена простой программой.
Теория алгоритмов – раздел математики, изучающий общие свойства алгоритмов. Под алгоритмом понимается процедура, которая позволяет, путём выполнения элементарных шагов, получить однозначный результат, не зависимо от того, кто выполняет эти шаги. В любой алгоритмической модели должен быть конкретный набор элементов, шагов и способов выбора перехода от шага к шагу. Необходима также простота использования.
Классы алгоритмических моделей:
1 – Арифметизация алгоритмов
2 – Алгоритмы или модели, использующие виртуальные вычислительные машины
3 – Нормальные алгоритмы. Модель Маркова
I. Арифметизация алгоритмов
Предполагается, что любые данные можно закодировать числами и, следовательно, всякое преобразование над данными можно производить как преобразование над числами. Элементарные шаги – арифметические операции. Определение последовательности шагов выполняется двумя способами:
1. Суперпозиция двух функций:
а) U = f(x)
б) y = (U)
y = F(x) = (f(x)) = (f)(x)
2. Рекурсивный подход
n! = n(n-1) (n-2) …21
(n+1)! = n!(n+1)
f(n+1) = f(n) (n+1)
II. Алгоритмы или модели, использующие виртуальные вычислительные машины. Машина Тьюринга.
Для того, чтобы алгоритм понимался однозначно, каждый шаг должен быть элементарно выполнимым, для того, чтобы его могла выполнить машина. Машина состоит из некоторой ленты (лента бесконечная и в ту, и в другую сторону), управляющего устройства и считывающей головки.
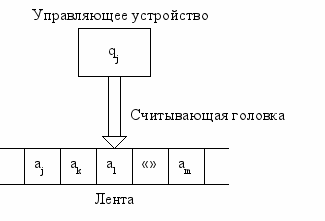
Вводится алфавит машины:
A = {a, …am}
Q = {q1, …qk)
Головка всегда располагается на какой-либо ячейке ленты. Она может как читать, так и писать символы. Элементарные шаги машины: qjak qia1dp. Новый записываемый символ – a1. Определение перемещения – dp (). Устройство управления хранит и выполняет команды.
III. Модель Маркова. Нормальные алгоритмы.
Задаётся алфавит, некоторое конечное множество допустимых установок и порядок их применения. В качестве алфавита используется русский алфавит.
Пример:
- ЯУ
- ЛУ
- СВ
- ВБ
- РТ
- ТР!
- ОХ
- НА
Правила:
1 – Проверить возможность подстановки в порядке их возрастания. Левая часть подстановки, если обнаруживается в исходном слове, подлежит замене.
2 – Если в принятой подстановке есть «!», то преобразование прекращается, если нет, то текущее состояние становится исходным и весь процесс начинается заново.
3 – Если ни одна из подстановок не применима, то процесс подстановки завершён.
«СЛОН» «СУОН» «МУОН» «МУХН» «МУХА»
Алгоритмы Маркова эквивалентны машине Тьюринга. Появление точного понятия алгоритма позволило сформулировать алгоритмически неразрешимые проблемы. С точки зрения, задача считается алгоритмически неразрешимой, если для неё не существует машины Тьюринга или нельзя применить алгоритмы Маркова. Неразрешимой проблемой также является распознавание эквивалентности алгоритмов. Нет алгоритма, который бы давал ответ на вопрос: «Эквивалентны или нет две других программы или алгоритма?».
Кибернетика.
Кибернетика – наука об управлении. Под информацией понимают ту часть знаний, которая используется для ориентирования активного действия управления (в целях сохранения, усовершенствования и развития системы). Существует два вида управления:
1 – Программное (на весь промежуток управления)
2 – Позиционное управление (решение на принятие управления в зависимости от состояния, которое задаёт система)
Информация:
1 - отрицание энтропии
2 – мера сложности структуры
3 – отражённое разнообразие
Содержание процесса отражения информации – вероятность выбора.
Предметы и задачи информатики.
Информатика – техническая наука, систематизирующая приёмы создания, хранения, обработки и передачи данных средствами вычислительной техники, а также принципы функционирования этих средств и методы управления ими. Предмет информатики составляют следующие понятия:
1 – аппаратное обеспечение средств вычислительной техники
2 – программное обеспечение средств вычислительной техники
3 – средства взаимодействия аппаратного и программного обеспечений
4 – средства взаимодействий человека с аппаратным и программным обеспечениями.
Перечисленные понятия называются интерфейсами. Основная задача информатики – систематизация приёмов и методов работы с аппаратными и программными средствами.
Практические направления:
1 – архитектура вычислительной системы (приёмы и методы построения систем)
2 – интерфейс вычислительных систем
3 – программирование (приёмы, методы и средства разработки компьютерных программ)
4 – преобразование данных
5 – приёмы автоматизации (автоматизация – функционирование программно-аппаратных средств без участия человека)
6 – защита информации
7 – стандартизация информации (обеспечение совместимости между аппаратными и программными средствам, а также форматами представления данных).
Определения и принципы
Организация информационных процессов в вычислительных устройствах.
Одним из подходов для определения ЭВМ могут являться принципы функционирования (минимальный набор устройств, которые должны входить в состав любой ЭВМ), можно также представить некоторую информационную модель ЭВМ.
Принципы фон Неймана (1945 год). EDVAC – первая ЭВМ, разработанная со своей программой.
Принципы фон Неймана:
1 – Основными блоками фон Неймановской машины являются:
а – блок управления
б – арифметико-логическое устройство
в – память
г – устройство ввода-вывода
2 – Информация кодируется в двоичной форме и разделяется на единицы, называемые словами.
3 – Алгоритм представляется в форме последовательности управляющих слов, которые определяют смысл операции (слова – команды).
4 – Программы и данные хранятся в одной и той же памяти. Разнотипные слова различаются по способу кодирования.
5 – Устройство управления и арифметико-логическое устройство объединены в центральный процессор. Он определяет действие, подлежащее выполнению, путём считывания команд из оперативной памяти. Обратная информация, предписанная алгоритму, сводится к последовательному выполнению команд в порядке, однозначно определяемом командой.
Два способа организации архитектуры: шинная и канальная организации.
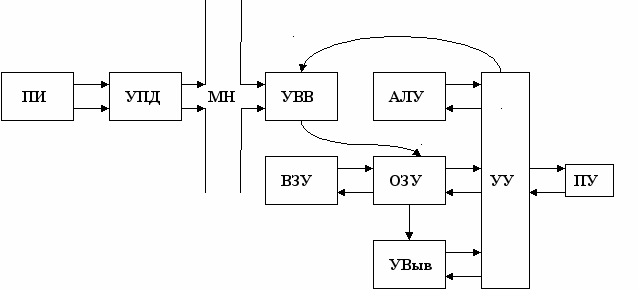
ПИ – первичная информация
УПД – устройство подготовки данных
МН – машинный носитель
УВВ – устройство ввода информации
ВЗУ – внешнее запоминающее устройство
АЛУ – арифметико-логическое устройство
ОЗУ – оперативное запоминающее устройство
УВыв – устройство вывода
УУ – устройство управления
ПУ – пульт управления
Архитектура ЭВМ – абстрактное определение машины в терминах основных функциональных модулей языка и структур данных. Архитектура ЭВМ не определяет реализацию структур данных. Конфигурация ЭВМ – компоновка состояния систем с чётким определением характера взаимосвязей и количества характеристик функциональных элементов.
Под командой мы понимаем совокупность сведений, необходимых для выполнения определённых действий при выполнении программ.
Команда состоит из двух частей:
1 – Код операции (содержит указания на ту операцию, которую необходимо выполнить)
2 – Состоит из нескольких адресных полей, содержащих указания на коды полей, где хранятся операнды для выполнения команд.
Характеристики центрального процессора:
1 – Архитектура выполнения процессора
2 – Кэш-память процессора (внутренняя)
3 – Система команд
4 – Тактовая частота (количество операций в секунду)
5 – Напряжение, на котором работает процессор
Чем более высокая технология, тем на меньшем напряжении работает процессор.
Основная память состоит из регистров. Разновидности регистров:
1 – Random Access Memory (RAM) – память произвольного доступа. Измеряется в байтах, мегабайтах и гигабайтах.
1 килобайт = 1 байт210 = 1024 байта
1 мегабайт = 1 килобайт 210 = 1 байт220
1 гигабайт = 1 мегабайт210 = 1 килобайт 220 = 1 байт230
1 терабайт = 1 байт240
2 – КЭШ. Измеряется в килобайтах.
3 – ROM (Read Only Memory) – постоянная память.
4 – CMOS – полупостоянная память (напитывается от аккумулятора). В этой памяти хранятся параметры, настраивающие BIOS.
Внешние запоминающие устройства:
| Устройство вывода памяти | Время доставки |
| Регистры | (2-20)10-9 |
| Оперативная память | (2-20)10-6 |
| Внутренняя память | 10-100 |
Устройства ввода информации:
1 – Клавиатура
2 – Мышь
3 – Сканер
И.т.д.
Устройства вывода информации:
1 – Видео подсистема:
а – графический процессор (количество цветов, поддерживаемых системой, характеризуется глубиной цвета)
б – Монитор
2 – Принтер
3 – Периферийные устройства
4 – Устройства внешней памяти
Коммуникационные устройства
Связь межу устройствами происходит с помощью шин.
Системная шина состоит из шины данных, шины адресов и шины управления. По одному каналу шины можно передать либо «0», либо «1», из-за этого, как правило, шина состоит из множества каналов. Шина из 20 каналов может реализовать 220 сигналов.
Функционирование ЭВМ с шинной структурой:
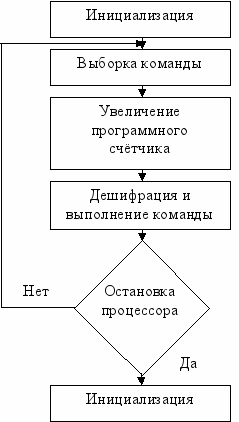
После включения ЭВМ или операции сброса в регистре центрального процессора записываются некоторые начальные данные. Задача первичного загрузчика – запуск операционной системы. Программному счётчику присваивается адрес программы, которая запускается. Центральный процессор производит считывание. В качестве адреса используется содержимое программного счётчика. Содержимое считанной ячейки памяти интерпретируется процессором как команда и помещается в регистр команд.
По полю кода операции из первого слова команды устройство управления определяет длину команды и команда считывается полностью процессором
Вычисленная длина команды добавляется к исходному содержимому программного счётчика. Если команда полностью прочитана, то программный счётчик будет хранить адрес следующей команды.
По адресным полям команды устройство управления определяет, имеет ли команда операнды в памяти. Если да, то на основе адресных полей вычисляются адреса операндов в памяти и производится операция чтения.
Устройство управления и арифметико-логическое устройство выполняют операцию, указанную в поле хода. В регистре флага запоминаются признаки результата: равенство либо неравенство нулю, знак результата, наличие переполнения. Если необходимо, устройство управления выполняет операцию записи для того, чтобы поместить результат в памяти.
Остановка процессора.
Если последняя команда процессора не была «остановить процессор», то описанная последовательность повторяется с нулевого шага.
Программное обеспечение.
Программное обеспечение – совокупность программ, выполняемых вычислительной системой и необходимых для её эксплуатации и использования документов.
Виды программного обеспечения:
1 – Технология проектирования программ (структурная, объектно-ориентированная, нисходящая и т.д.)
2 – Методы тестирования программ
3 – Анализ качества работы программ
4 – Документирование программ
5 – Разработка и использование программных средств, облегчающих процесс создания программ.
Программный продукт – комплекс программ для решения определённой задачи массового спроса.
Проводится определённая классификация программных продуктов:
1 – Для аппаратной части
2 – Для технической разработки программ
3 – Для функциональных возможностей.
Системное программное обеспечение необходимо для обеспечения работы систем ЭВМ и ЭВУ.
Есть два класса программного обеспечения:
1 – Базовое программное обеспечение: BIOS, операционная система, операционная оболочка.
2 – Сервисное программное обеспечение: программы диагностики работоспособности компьютера, антивирусы, программы обслуживания дисков, программы архивирования данных.
Функции операционной системы:
1 – Осуществление диалога с пользователем
2 – Выводы управления данными
3 – Планирование и организация процесса обработки программ
4 – Распределение ресурсов
5 – Запуск программ на выполнение
6 – Операции обслуживания системы
7 – Передача информации между различными внутренними элементами компьютера
8 – Программная поддержка работы периферийных устройств
Операционные системы компьютеров делятся на однопользовательские и многопользовательские, на однозадачные и многозадачные, на сетевые и несетевые.
Прикладное программное обеспечение и языки программирования.
Машины, ориентированные языки – языки, ориентированные на конкретные архитектурные машины, воспринимаемые аппаратной частью компьютера.
Языки низкого уровня: процедурно-ориентированные языки, проблемно-ориентированные языки, интегрированные системы программирования.
Любая программа, создаваемая языком высокого уровня должна переводиться в машинные коды. Трансляторы, которые отвечают за это, делятся на два типа:
1 – Компилятор (переводит полностью всю программу в машинные коды)
2 – Интерпретатор (Переводит программу в машинные коды по блокам)
Современная система программ содержит компилятор и интерпретатор, интегрированную среду обработки, средства создания и редактирования программ, библиотеки, диалоговую среду, многооконный режим, графические библиотеки, утилиты, ассемблер и справочную систему.
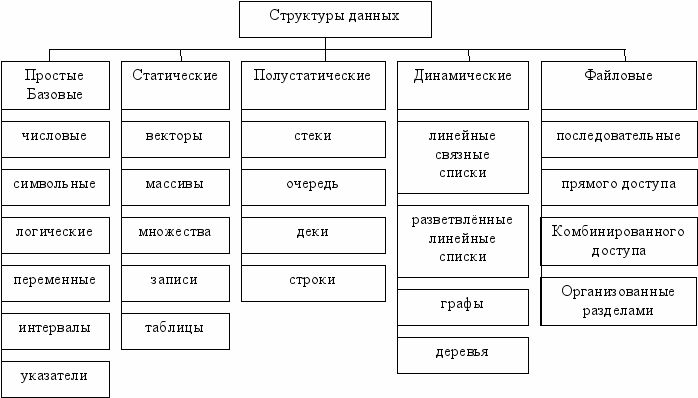
Типы и структуры данных
Классификация по принципу изменчивости.
Изменчивость – возможность изменять связи и элементы структуры. Есть статические, полустатические и динамические структуры данных.
Вектор – одноразмерный массив данных (структура элементов одного и того же типа). Количество элементов фиксировано.
Массив – последовательность элементов базового типа.
Множество – структура, представляет собой набор неповторяющихся элементов.
Записи – конечное упорядоченное множество полей, характеризующееся различными типами данных.
Таблица – последовательность записей, имеющих одну и ту же организацию.
Списки – упорядоченные множества, состоящие из переменного числа элементов. Но ко всем элементам списка применяются операции включения и исключения.
Очередь – структура, в которую включают элементы с одной стороны, а исключают с другой.
Дек – линейная структура, в которой операции включения и исключения могут добавляться и исключаться как одного конца, так и с другого.
Каждый элемент списка состоит из двух полей. В одном поле располагается указатель, а во втором – элемент данных. Классификация линейной структуры зависит от выполнения некоторых условий.
Алфавит языка
Алфавит языка – совокупность допустимых в языке символов
ASC II – американский стандартный код обмена информации. Элементы можно разделить на 4 части:
1 – Идентификаторы
2 – Разделители
3 – Специальные символы
4 – Неиспользуемые модули
1 – Символы, используемые в идентификаторах.
Идентификатор – имя любого объекта языка. Он состоит из латинских букв «a…z» и чисел от 1 до 9. Цифры нельзя использовать в начале идентификатора. Иногда прописные и строчные значения не отличаются. Могут присутствовать ограничения на длину идентификатора.
2 – Разделители используются для отделения друг от друга идентификаторов, чисел и слотов.
3 – Специальные символы – знаки пунктуации.
К служебным символам относятся служебные слова (зарезервированные слова, которые не определяются пользователем и не могут быть использованы как имена собственные).
4 – Неиспользуемые символы – коды американского стандарта, которые используются только в комментариях и символьных строках, но не в конструкции языка.
Структура программы
Program … {заголовок программы}
Uses … {подключенные модули}
Label … {метки}
Const … {описание константы}
Type … {описание типов}
Var … {описание переменных}
Procedure … {раздел описания процедур}
Function … {раздел описания функции}
Begin … {операторы}
Тип данных характеризует внутреннее представление данных. Для определения типа используется слово type, затем для каждого типа идёт конструкция. К простым типам данных относят целые типы, логический тип, символьный тип и вещественный тип.
Все эти типы являются порядковыми. Это означает, что каждому значению порядкового типа функция Ord ставит число (порядковый номер данного значения в множестве допустимых значений). Любой порядковый тип является упорядоченным.
Shorting -27 … 27-1 -128 … 127 – 1 байт
Integral -215 … 215-1
Lonint -231 … 231-1
Операции умножения, деления, сложения и вычитания.
Определяются операции целочисленного деления.
a div b
a = kb + r a div b = k
10 div 3 = 3
a mod b = r
10 mod 3 = 1
Древовидные структуры – структуры, состоящие из набора вершин и рёбер и ссылки на низкие вершины.
Графы – совокупность двух и более вершин и рёбер.
Плебсы – это деревья со сложными связями.
Abs – абсолютное значение (x)
Sin(x)
Cos(x)
Exp(x)
En(x)
Sqr(x)
Sqrt(x)
Вещественные типы.
N = m × E ± p
M – Мантисса числа (модуль целой части мантиссы изменяется в диапазоне от 1 до 9.
P – Целочисленный порядок.
E – Основание системы исчисления (стандартно 10)
Real – занимает 6 байт. Диапазон от 2,9Е-10-29 до 1,7Е-1038 (11-12 цифр)
Single – занимает 4 байта. От 1,5Е-45 до 3,4Е+38 (7-8 значений, цифр)
Double – занимает 8 байт. От 5,0Е-324 до 1,7Е+308. (15-16 значений, цифр)
Extendent – занимает 10 байт. От 3,4Е-4932 до 1,1Е+4932 (19-20 точных значений)
Comp – занимает 8 байт. От 9,2Е-18 до 9,2Е+18 Все цифры точны.
Все естественные операции применимы. Неточности в хранении вещественных чисел может привести к тому, что число при вычитании получит понижение значимости. Использовать сравнение вещественных чисел не рекомендуется.
Program sravnenie
Var
x: single
y: double
z: extended
begin
x:=1/3; y:=1/3; z:=abs
(x-y)
Write ln (‘z=’z)
End
Z = 9.93410748106882E-109
A=b, если abs (a-b) < eps
Eps = min (abs (a), abs (b))*10-m, где m – необходимое число совпадающих разрядов.
Логический тип
Boolean
True, false
Ord (false) = 0 Ord (true) = 1
not
and false true
false false false
true false true
or false true
false false true
true true true
or false true
false false true
true true false
1) ’a’, ‘b’, ‘*’
2) #97, #130, #42
Полный набор символов ASCII
Один символ – один байт.
Ограниченные виды
Ранее обсуждаемые типы являются стандартными. На основе таких типов можно определить новые типы. Самый простой способ образования новых типов – перечисление или ограничение уже существующих типов по диапазону.
Index: 1…10
C: “a” … “z”
Перечисляемые типы
Позволяют абстрагироваться от физической природы значения. Новый тип создаётся путём перечисления всех возможных его значений. Каждое значение определяется только именем.
Color = (red, yellow, green)
Power = (on, off)
Допускается образование ограниченных типов из перечисляемых по обычным правилам.
Описание переменных констант. Любая переменная должна быть определена. Её описание должно текстуально предшествовать её первому появлению в программе. Далее идёт последовательность переменных, которые можно заменить запятыми.
Идентификатор: тип;
Идентификатор 2: тип 2;
A, b, c: integer;
M: 0 … 5;
S: char;
Semaphore: (opened; closed)
Есть некоторые ограничения на объём используемых переменных. Это ограничение вводится за счёт введения блочных типов, либо за счёт механизма динамичной памяти.
Переменная может принимать значения только того типа, к которому она относится. Есть объекты, которые похожи на переменные, но которые не будут меняться при выполнении программы. Их называют константы
Const
Идентификатор 1 = значение 1;
Идентификатор 2 = значение 2;
Const:
One = 1;
High limit = 1000;
Low limit = - high limit;
Max real = 1.7E38;
Separator = ‘*******’;
Любой идентификатор постоянной может входить в связное с ним выражение.
D: = (high limit – low limit) / 2 + 1
Недопустимо менять значение постоянной в программе. При определённых константах можно использовать константное выражение.
Const:
Min = 0;
Max = 100;
Center = (max – min) div 2;
T = ‘TURBO’
P = ‘PASCAL’
TP = T + P
Регулярные типы (массивы)
Массив – последовательность записей одинаковой структуры. Каждый элемент массива может быть получен по его номеру.
Имя типа = array [диапазон параметров] of тип;
В качестве элементов массива используются любые типы языка, кроме файловых. Нельзя использовать базовый тип longint. 3 способа описания одного и того же массива:
Type {1} M1 = array [0 … 5] of integer
M2 = array [char] of M1
M3 = array [-2 … 2] of M2
Type {2} M3 = array [-2 … 2] of array [char] of array [0 … 5] of integer
Type {3} M3 = array [-2 … 2, char, 0 … 5] of integer
Var A, B: M3;
5×256×6×2 байта
Begin:
Read (A [-1, ‘a’, 3]);
Read (A [1][‘x’][]);
A [1][‘c’, 1]: =1;
End
Глубина логичности при определении массива не ограничена. Pascal и Delphi допускают одно действие над массивами – присвоение массива.
Vect 1: = Vect 2
Линейный алгоритм
Операторы в программе выполняются один за другим в том порядке, в котором они перечисляются в программе. Пустой оператор не выполняет никаких действий. Может быть выполнен обмен значений. Пусть есть x и y. Записать значение x в y и наоборот.
x
y
z
2

1 3
Begin
z: = x;
e: = z;
x: = y;
End;
Оператор присваивания
Имя переменной: = выражение;
X: = y; {x, y – real}
Z: = A + B; {A; B – integer, Z – real}
X: = (y + z) / (z + 2) – 0.5;
Color: = red;
Done: = (I > 100) or (A [I] = 0);
(I < = 100) and (A [I] < > 0)
Myset: [1, 7 … 10, 100];
Простейшие операции ввода/вывода. 2 типа операторов:
1 - Операции ввода/вывода информации
Read (переменная, список переменной через запятую);
Read in (переменная, список переменных)
Write (переменная, список переменных)
Write in (переменная, список переменных)
2 – Форматированные выводы. Дополнительно в списке вывода после каждой переменной можно указывать количество позиций, отводимых под число и количество цифр в дробной части числа.
X – real;
Write (X);
N
 = 1.5 0 … 0 E+ 0000
= 1.5 0 … 0 E+ 000013
Y1: 0,0707
Разветвляющиеся алгоритмы
Выполнение операторов происходит не в том порядке, в котором они записаны. Это осуществляется за счёт оператора перехода.
Goto <метка>;
Передаётся управление на нужный оператор программы, перед которым располагается вторая метка >: оператор. В разделе описания меток по возможности избегать этого оператора в колонтитуле else <оператор>;. Для целого числа необходимо вывести соответствующий ему символ.
Program ascil –symbol;
Var
I: word;
Begin
Write (‘Vvedite celoe chislo’:);
Read in (1);
If (I > 31) and (I < 256) then write in (‘Sootv symbol -; chr (I))
Задача: a, b, c; решить: ax2 + bx + c = 0

H


a, b, c

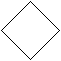
 a = 0
a = 0 
 D = b2 – 4ac b = 0
D = b2 – 4ac b = 0



 D < 0 x = -c/b c = 0
D < 0 x = -c/b c = 0

 x – любое
x – любое x1 = -b + D Решений нет Решений нет число
x1 = -b + D Решений нет Решений нет число

 2a x
2a x
x2 = -b - D
 x1, x2
x1, x22a
If a = 0 then;
If d = 0 then;
Id c = 0 then;
Writeln(‘x – lyboe’);
Else writeln(‘Resheni net’);
Else writeln(‘x=’,-c/b);
Else begin
D:=b×b-4ac;
If D<0 then writeln(‘Destvitelnih znacheni net’);
Else begin
X1:=(-b+sqrt(D))/2a;
X2:=(-b-sqrt(D))/2a;
Writeln(‘x1=’,x1);
Writeln(‘x2=’,x2);
End;
End.
Оператор выбора.




Cn1 Cn2 Cn3 … Cnn

Case <ключ выбора> of
Cn1: <оператор 1>;
Cn2: <оператор 2>;
……………............
Cnn:<оператор n>;
[else <оператор>;]
[] – означает необязательность действия
End.
Операторы 1, 2, n – возможно составные операторы, из которых выполняется тот, с константой которого происходит первое совпадение ключа.
Вводится целое число, нужно выяснить: чётное оно или нет, отрицательное или нет, больше 10 или нет, от 10 до ста или нет или больше 100.
Program chislo;
Var
I:integer;
Begin
Writeln(‘Vvedite chislo’);
Readln(I);
Case I of
0,2,4,6,8: writeln(‘Chotnaia cifra’);
1,3,5,7,9:writeln(‘Nechotnaia cifra’);
10 … 100:writeln(‘Chislo ot 10 do 100’);
Else writeln(‘chislo libo otrichatelnoe, libo bolshe 100’);
End;
Read on;
End.
Может быть организовано 3 вида операторов для последовательности действий.
Цикл с параметром
For <оператор>:=
На первом шаге параметр принимает начальное значение nz и вычисляет конечное значение kz.
После выполнения тела цикла <параметр>≠
Nz
Nz>kz
For<параметр>:=
Downto
Program fib
var a, b, c : word; i, n: byte
begin:
write (‘Vvedite № chisla’);
readln (n);
a:=1; {a=F(0), а соответственно F(i-2)}
b:=1; {b=F(1), а соответственно F(i-1)}
for i:=2 to n do;
c:=a+b; {в соответствии F(i)}
a:=b;
b:=c; {в качестве a и b берётся следующая пара чисел}
end
Если заранее неизвестно число изменения цикла, то исполняются циклы с условием:
1 – Циклы с предисловием
2 – Циклы типа write. Цикл write может не выполняться ни одного раза.
Процедура continue.
Досрочно завершает очередной шаг цикла и передаёт управление на начало цикла. Для того, чтобы избавиться от зацикливания программы, необходимо обеспечить изменение на каждом шаге цикла значения хотя бы одной переменной. Необходима проверка по каждому условию завершения цикла.
Алгоритмы сортировки
Методы сортировки
сортировка в линейных структурах сортировка в нелинейных структурах



в
 ставка выбором обмен турнирная сортировка
ставка выбором обмен турнирная сортировка



п
ростая простой метод пирамидальная сортировкавыбор Шелла
б
инарная метод ХаараСортировка выбора.
Массив из нескольких элементов. Находится максимальный элемент массива и меняется с последним элементом. Последний элемент имеет номер n. На следующем шаге выбирается максимальный элемент от 1 до n-1 и ставится на n-1.
A [N] N=5 0(N2)
| 35 | 20 | 5 | 1 | 4 | порядок N2 |
| 4 | 20 | 5 | 1 | 35 | (max = 35; N=5) |
| 4 | 1 | 5 | 20 | 35 | (max = 20; N=4) |
| 4 | 1 | 5 | 20 | 35 | (max = 5; N=3) |
| 1 | 4 | 5 | 20 | 35 | (max = 4; N=3) |
program sort-vybor;
var a: array [1…100] of integer
n, i, m, k, x: integer;
begin
write (‘kolichestvo elementov massiva’);
read (N);
far i:=1 to N do read (a[i]);
far k:=N downto 210; {k – количество элементов для поиска}
begin
m:=1; {m – место максимального элемента}
for i:=2 to k do;
if a[i] > a[m] then m=i; {меняет местами элементы с номером k и m}
x:=a[m];
a[m]:=a[x];
a[k]:=x;
end.
program sort-obmen
var a: array[1…100] of integer
n, i, k, x: integer
begin
write (‘Vvedite element x’);
for i:=1 to n do;
begin
write (‘Vvedite element a[‘,i,’]=’];
readln (a[i]);
end;
for k:=n-1 downto 1 do; {k – количество сравниваемых элементов}
for i:=1 to k do;
if a[i] > a[i+1] then; {меняет местами следующие элементы}
begin
x:=a[i];
a[i]:=a[i+1];
a[i+1]:=x;
end;
writeln (‘Yporiadochennij massiv’);
for i:=1 to n do write (a[i], ‘ ‘);
readln;
end.
В программировании используется принцип модульности. Один компонент можно использовать несколько раз. От этого программа становится более штабельной.
Программы функций. Описание подпрограммы функций располагается в отделе описания.
function – имя функции (список параметров, тип результатов)
Параметры перечисляются через запятую (тип параметров)
Описание показательных меток, типов переменных и констант
label, const, type, var.
begin
Обязательно должен присутствовать хотя бы один оператор, который содержит имя функции.
Можно указать директивы компьютера.
В процедуре функции возникает описание встроенной функции.
Решение неравенства:
bn ≤ a< bn+1
отношение n, при условии a≥1, b>1
Решение реализации процесса:
function largest_power (a, b, longint): word
var
n: word;
x: longint;
begin
x:= b;
n:= 0;
while x<=a do;
x:= x*b;
inc (n); {n:= n+1}
end;
begin
writeln (‘sn<=1000<3(n+1’);
writeln(‘n=’ largest_power (1000, 3));
readln;
end;
Вывод таблицы значений функции на экран
program
var x: real; k: word;
function f (x: real): real;
begin
f:=x/(1.0+x)
end;
begin
x:= 0.0;
writeln(‘Таблица значений функции f(x)=x/(1+x)’);
writeln;
writeln(‘x’:10; ‘f(x)’:20);
writeln;
for k:=0 to 50 do
begin
writeln (x:10:4, F(x):20:10);
x:= x+0,1;
if k mod 10=9 then
readln;
end;
writeln;
write (‘Нажмите Enter’);
readln;
end.
Имена объектов, описанные в первом блоке должны быть уникальны в пределах этого блока. Если в некотором блоке описан объект, содержащийся в объёме блока, то это последнее имя станет недоступным в данном блоке.
Имя, описанное в блоке, экранирует одноимённый объект из объемлющего блока. Если в блоке «а» описана переменная «х», а в блоке «с» описаны «х» и «у», тогда переменная «х» доступна в «а» и недоступна «а» и «б», а у недоступна в «б» и «с».
Переменная «у» из блока «с» имеет локальный контекст. Локальные объекты блока вместе с видимыми в нём объектами объемлющего блока образуют локальный контекст имён данного блока.
Совокупность объектов описанных во внешнем блоке называется глобальным контекстом программы.
Механизм параметров.
Параметры – идентификаторы, которые служат для обмена значениями между программными модулями. Параметры, указанные в заголовке считаются локальными в данной подпрограмме. Параметры, указанные в заголовке процедуры называются формальными. Переменные имена, которые подставляются в операторы вызова процедуры, при фактическом вызове процедуры называются фактическими параметрами. Параметры:
1 – Параметры значений
2 – Параметры переменных
3 – Не типизированные
Параметры значений (входные данные)
Procedure primer (a, b integer) – формальные
В программе primer (c, d;) – фактические параметры
Действие внутри процедуры с формальным параметром никак не отражается на значениях переменной вне процедуры.
Пример использует передачу параметров по значению.
Параметры переменных (выходная информация) обозначаются в списке параметров переменных, в которые должен быть занесён ответ.
Перед параметрами переменных ставится Var.
Не типизированные параметры и параметры const.
Const запрещено менять внутри процедуры. Использование бестиповых параметров требует приведения к какому либо типу.
Тип (переменная)
Идентификатор типа Переменная, имеющая некоторый другой тип
Предварительное описание программы. Под внешним описанием программы понимается, когда программа разрабатывается в другой системе. В этом случае объектный код подключаемой программы … .obj
Рекурсия и побочный эффект.
В теле подпрограммы доступны все объекты внешнего блока, в том числе имя самой подпрограммы. Процессы и функции, использующие вызов самих себя называются рекурсивными.
Если в некоторой функции изменяются конструкции, изменяющие значения переменных в объемлющих блоках, то может возникнуть ситуация, при которой значения выражения, использующего вызов функции, зависит от порядка следования операндов. Такая ситуация называется «побочный эффект».
Program Side Effect;
Var
a, z: integer;
function change (x: integer): integer;
begin {изменяет значение нелокальной переменной}
z: = z-x;
change: = sqr(x);
end;
begin
z:=10; a:=change (z); writeln (a, z);
z:=10; a=change (10)*change (z); writeln (a, z);
z:=10; a:=change (z)*change (10); writeln (a, z)
end.
Операция над строками
Var
a, s: string
Строковая переменная похожа на массив
Var
st: string [4];
st: ‘abc’;
st: ‘abcde’ (такое присваивание будет ошибочным)
Максимальная длина строки ≤ 255 символам.
string [8]
В памяти резерв = 81 байт. Длина строки байтов равна значению кода символов.
st:=’abcdefgh’
st [0] = chr(8)
st [1] = ‘a’
st [8] = ‘h’
ord (st [0])
Существующий набор процедур:
1 – конкатенация.
Пример:
ss1:=’ABC’;
ss2:=’def’;
concat(str1, str2)
Результат: ‘ABCdef’
c:string;
c:=concat (ss1, ss2)
2 – length(str);
3 – Удаление части строки, которая имеет определённую длину и позицию.
delete (str, nach pos, dl fragm).