
Правила Джексона для перехода от модели Чена к реляционной модели. Реляционная модель данных. 12 правил Кодда
| Вид материала | Документы |
- Реляционные решения: от открытия реляционной модели данных до проблематики фундаментальных, 61.83kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Манипулирование реляционными, 276.31kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Целостная часть реляционной, 213.79kb.
- Возможности реляционной модели данных по отображению сложных структур данных, 155.27kb.
- 1. Реляционная модель данных, 67.76kb.
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
- Самостоятельная работа 87 130 Всего часов на дисциплину, 58.84kb.
- Тема 41. Предпосылки модели экономики с экзогенными ценами (кейнсианская модель равновесия, 96.08kb.
- Разработка реляционной структуры данных, 255.43kb.
- Лекция 1) гис как специализированная информационная система. Структура информационных, 78.1kb.
Базы данных [24-26]
- Проектирование базы данных с помощью нормализации.
- Операция «соединение» и ее свойства.
- Разложение без потерь. Теорема. Примеры.
- Полностью соединимые отношения. Примеры.
- Операторы описания данных в SQL.
- Операторы манипулирования данными в SQL.
- Управление транзакциями.
- Технологии «клиент-сервер».
- Оператор Select.
- Индексация. Достоинства и недостатки. Примеры.
- В-дерево. Добавление и удаление элементов.
- Методы прямого доступа.
- Архитектуры БД.
- Управление правами доступа в SQL.
- Модель Чена.
- Примеры бинарных связей.
- Правила Джексона для перехода от модели Чена к реляционной модели.
- Реляционная модель данных. 12 правил Кодда.
- Ограничения целостности в реляционной модели данных и их поддержка в SQL.
- Восстановление данных в БД.
1. Проектирование базы данных с помощью нормализации.
Проектирование реляционной базы данных.
Проектирование состоит в разложении таблиц на элементарные таблицы, так чтобы не возникали аномалии технологических операций. Таблицы, отвечающие условиям отсутствия аномалий технологических операций, называются нормальными формами (Н.Ф.).
1Н.Ф.
2Н.Ф.
3Н.Ф. Н.Ф.Б.К.
4Н.Ф.
5Н.Ф.
Таблица находится в первой нормальной форме (1Н.Ф.), если все ее атрибуты атомарные.
Таблица находится во второй нормальной форме (2Н.Ф.), если она находится в 1Н.Ф. и все не ключевые атрибуты функционально полно зависят от ключа.
Таблица находится в третьей нормальной форме (3Н.Ф.), если она находится во 2Н.Ф. и устранены транзитивные зависимости внутри таблицы.
Т
 аблица находится в нормальной форме Бойса-Кодда (Н.Ф.Б.К.), если она находится во второй нормальной форме и каждая детерминанта функциональной зависимости является возможным ключом (
аблица находится в нормальной форме Бойса-Кодда (Н.Ф.Б.К.), если она находится во второй нормальной форме и каждая детерминанта функциональной зависимости является возможным ключом (
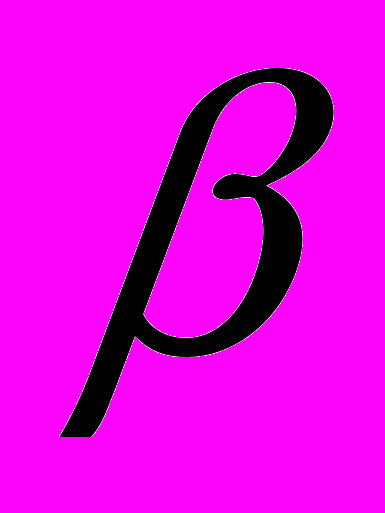 , где является детерминантом).
, где является детерминантом). Таблица находится а четвертой нормальной форме (4Н.Ф.), если она находится в третьей нормальной форме и в ней поддерживаются все возможные многозначные функциональные зависимости.
Таблица находится в пятой нормальной форме (5Н.Ф.), если она разложима без потерь.
Проектирование реляционной базы данных начинается с универсального отношения. Универсальное отношение – это одна таблица, которая содержит все атрибуты, используемые в нашей системе. Например, универсальное отношение для базы Поставщик- Деталь-Поставка имеет вид:
| фамилия | статус | Город пос- тавщика | Название детали | вес | цвет | Город детали | количество |
| Иванов | 70 | Пермь | гайка | 12 | красный | Пермь | 100 |
| | | | болт | 13 | синий | Кунгур | 200 |
| ... | | | | | | | |
| ... | | | | | | | |
Проектирование сводится к постепенному переводу универсального отношения к пятой нормальной форме.
Данная таблица не находится в первой нормальной форме, если сдублировать данные, то перейдем к первой нормальной форме, но тогда сохранятся аномалии технологических операций вставки, удаления, изменения.
Чтобы прейти ко второй нормальной форме нужно разбить данную таблицу на таблицы, так чтобы это было разложение без потерь. Для этого разобьем таблицу на две, первая будет содержать поля - фамилия поставщика (ключ), статус, город поставщика, вторая таблица будет содержать поля – фамилия поставщика, название детали, вес, цвет, город детали, количество, причем фамилия +название детали=ключ.
После данного разбиения первая таблица будет находится не только во второй нормальной форме, но и в третьей. А во второй таблице сохранятся аномалии технологических операций, т.е. вторую таблицу необходимо еще разбить на две: таблица 2.1 с полями - название детали, вес, цвет, город детали; таблица 2.2 с полями - фамилия поставщика, название детали, количество(эти две таблицы находятся в 3Н.Ф.).
Метод нормализации.
Метод начинается с универсального отношения и основан на постепенном переходе к пятой нормальной форме.
Пример:
| Фамилия автора | произведение |
| Пушкин | Евгений Онегин, Капитанская дочка, ... |
| Лермонтов | Герой нашего времени, Кавказский пленник, ... |
В этой таблице атрибут Произведение является повторяющейся группой, таблица не является нормализованной. Для перехода к первой нормальной форме дублируем:
-
автор
произведение
Пушкин
Евгений Онегин
Пушкин
Капитанская дочка
Пушкин
...
Лермонтов
Герой нашего времени
Лермонтов
Кавказский пленник
Лермонтов
...
Таблица находится в первой нормальной форме, является реляционной таблицей.
Пример:
r( поставщик, статус, город поставщика, деталь, количество) – это универсальное отношение. Установим функциональные зависимости:
поставщик +деталь = первичный ключ;
П
 +Д С (от поставщика и детали зависит статус);
+Д С (от поставщика и детали зависит статус);П
+Д Г (город);П
+Д К (количество);Г
С;П
С;П
Г.Получаем ситуацию, когда некоторые атрибуты полностью зависят от комбинации П+Д, а некоторые атрибуты зависят только от П, т.е. присутствует неполная функциональная зависимость, а также присутствуют аномалии добавления, удаления, изменения. Разобьем таблицу на 2, так чтобы сохранились функциональные зависимости:
Т1(Поставщик, Статус, Город), Т2(Поставщик, Деталь, количество). Данные 2 находятся во второй нормальной форме. Установим функциональные зависимости для Т1:
П
С; П
Г;Г
С.
 П С это транзитивная зависимость.
П С это транзитивная зависимость.
Г
В
таблице Т1 сохраняются аномалии технологических операций: при удалении поставщика теряется зависимость Город Статус, не можем добавить нового поставщика пока не знаем статуса города. Следовательно необходимо таблицу Т1 разбить еще на 2: Т11(П,Г) и Т12(Г,С).Таблицы Т11, Т12, Т2 представляют нашу базу в третьей нормальной форме.
Пример:
Т(№служащего, фамилия, №проекта, название работы).
Предположим, что в таблице нет однофамильцев, тогда ключом является либо №служащего+№проекта, либо фамилия+№проекта,
тогда №служащего фамилия. Приведем таблицу в Н.Ф.Б.К., для этого разложим таблицу на две: Т1(№служащего, фамилия), Т2(№служащего, №проекта, Название работы). Пример:
Т(№детали,№проекта,№поставщика).
№
проекта+№детали №поставщика;№
поставщика №проекта. Следовательно нужно разбить еще на 2: Т1(№детали, №поставщика) и Т2(№поставщика,№проекта).
Чтобы перевести таблицу в 4Н.Ф. нужно многозначную Ф.З. выделить в отдельную таблицу, в 5Н.Ф. все таблицы должны соединяться без потерь.
2. Операция «соединение» и ее свойства.
Операция соединения (основная).
О
 бозначение: Join или
бозначение: Join или  .
. Существует внутренняя операция соединения и внешняя, при этом внешняя делится на правую и левую.
- Внутренняя
а) естественное соединение – осуществляется по равенству значений в одноименных столбцах. Одноименные столбцы имеют одно и тоже имя и определены на одних и тех же доменах. Для соединения используются две таблицы, в результате получаем третью таблицу, кортежи которой получаются комбинацией тех кортежей из исходных таблиц, которые имеют одинаковые значения в одноименных столбцах. Операция соединения коммутативна относительно операндов, т.е. от перестановки мест результат не изменяется.
r
(A,B,C) s(A,B,D) = q(A,B,C,D)- 11a 112a
- 11b 112b
123 42c 113a
- 113b
- 421c
операция соединения для таблиц с одинаковыми схемами равносильна операции пересечения:
r
(A,B) s(A,B) = q(A,B)11 11 11
12 42 42
14
42
Операция соединения для таблиц с разными схемами равносильна декартовому произведению:
r
(A,B) s(C,D) = q(A,B,C,D)11 cd 11cd
12 c1d 11c1d
14 12cd
42 12c1d
14cd
14c1d
42cd
42c1d
б) Тета-соединение (
 ).
). Это соединение не обязательно по равенству, операция соединения происходит по любой операции сравнения(
 =(эквивалентное соединение),<>, <,>).
=(эквивалентное соединение),<>, <,>).Тета-соединение осуществляется не обязательно по одноименным столбцам, а по разным тоже, но столбцы должны быть определены на одних и тех же доменах.
r
(A,B,C) s(D,E) = q (A,B,C,D,E)B=D
a1c 1e a1c1e
a12c 1e1 a1c1e1
a11c2 2e a2c2e
a13c 2e1 a12c2e1
a11c21e
a11c21e1
r
(A,B,C) s(D,E) = q (A,B,C,D,E)B>D
a1c 1e a12c1e
a12c 1e1 a12c1e1
a11c2 2e a13c1e1
a13c 2e1 a13c1e
a13c2e
a13c2e
- внешнее соединение. Рассмотрим на примере естественного соединения. тогда внешнее соединение выполняется по тем же правилам, что и естественное, но в ответ выписываются строки из левой таблицы, если соединение левое (из правой таблицы, если соединение правое).
Пример:
r
(A,B,C) s(A,D) = q(A,B,C,D)left
1ac 1d 1acd
2a1c 2d 1acd1
1ac1 1d1 2a1cd
3ac 1ac1d
4a1c 1ac1d1
3ac null
4a1c null
Свойства
С помощью операции соединения можно выполнить операцию селекции, при этом операция селекции равносильна квантору существования.
Е
сли дано r(R), и необходимо выполнить операцию селекции 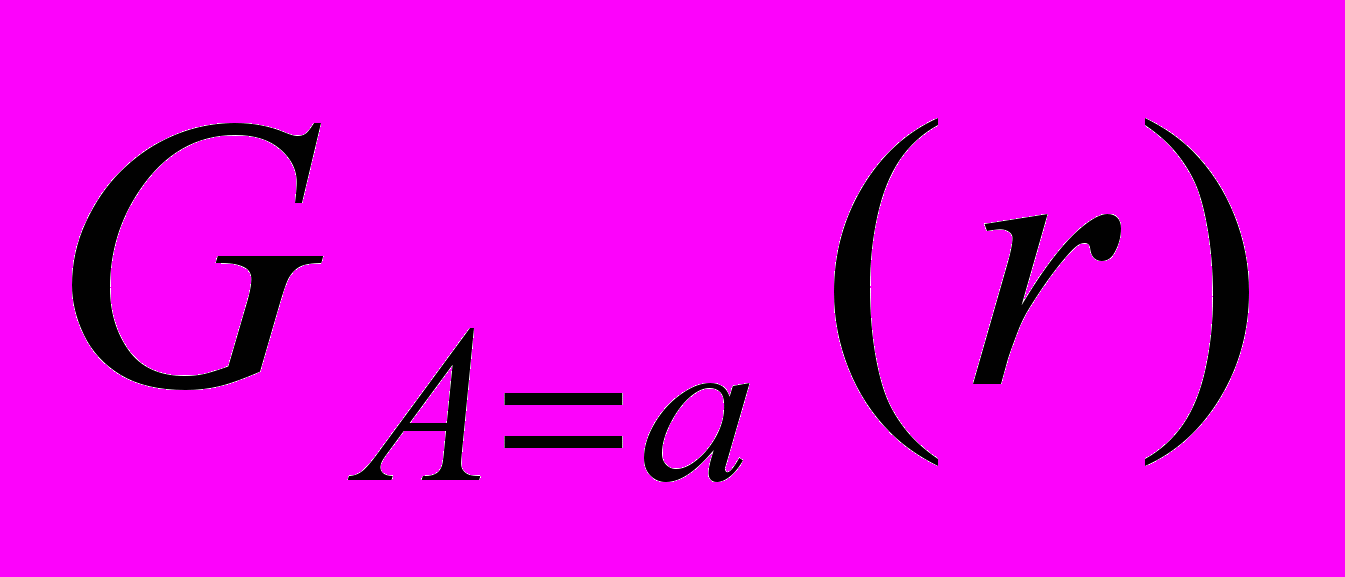 , то ее можно выполнить с помощью операции соединения r s(A)
, то ее можно выполнить с помощью операции соединения r s(A)a
Пример
Запрос: существует ли поставщик из Березников со статусом 80?
 (Поставщик s(город, статус))
(Поставщик s(город, статус))Березники, 80
Операция соединения коммутативна:
r
s = s rОперация соединения ассоциативна:
r
1 (r2 r3)=(r1 r2) r3Операция соединения дистрибутивна относительно операций пересечения, объединения и разности:
(
r1 r2) s = (r1s) (r2s);
r2) s = (r1s) (r2s);(
r1 r2) s = (r1s) (r2s);
r2) s = (r1s) (r2s);(
r1\r2) s = (r1\s) (r2\s)/Свойство идемпотентности:
q
q=q;q
r = q (q r )Свойство полусоединения:
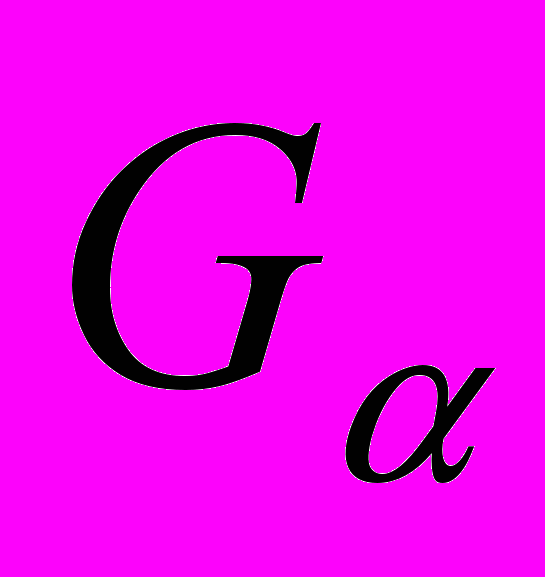 (r s) = (r) s
(r s) = (r) s3. Разложение без потерь. Теорема. Примеры.
Условие разложения без потерь.
q(R,S) r=
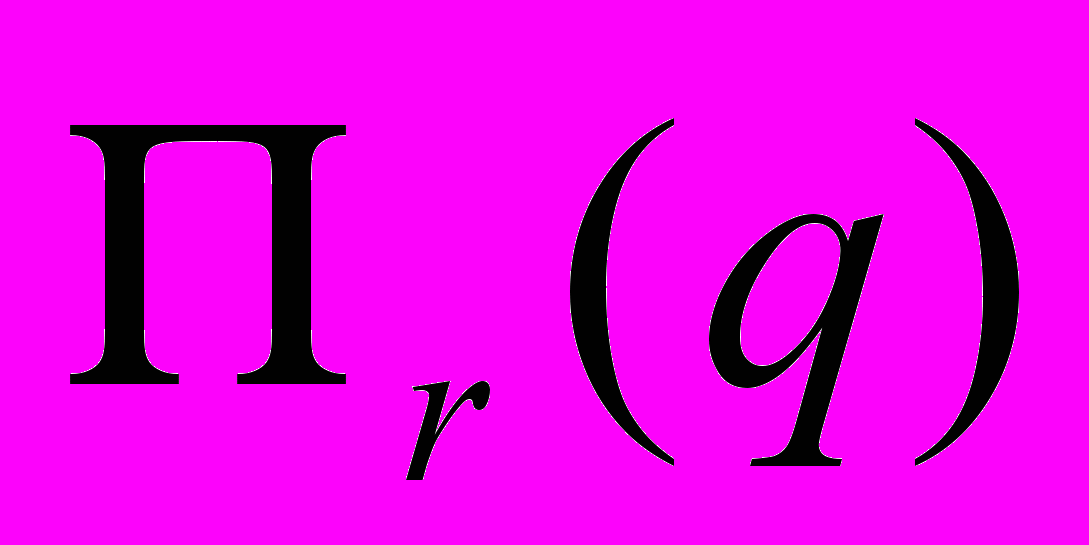 s=
s=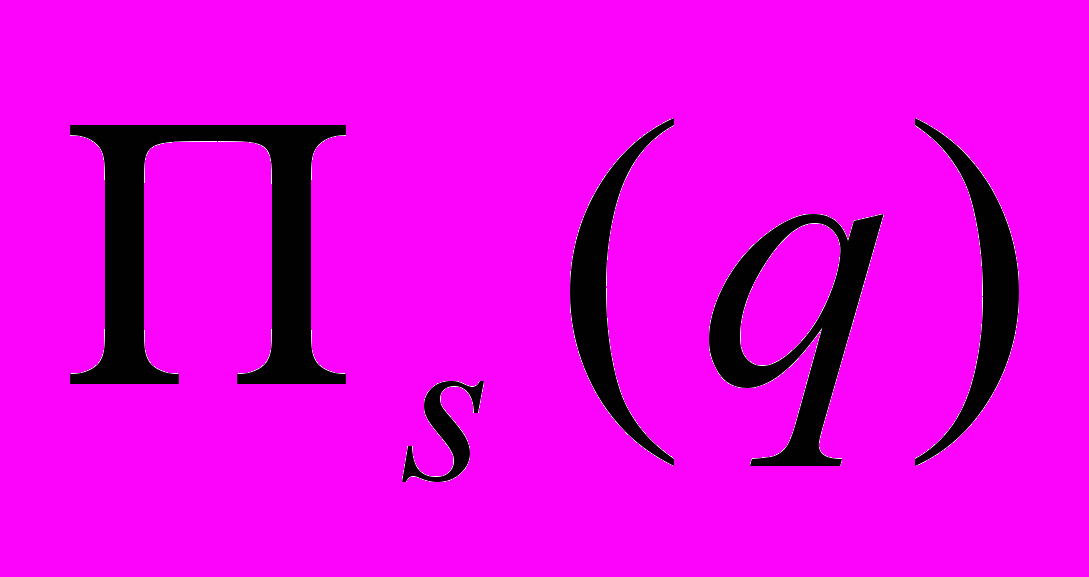 r s= =q’
r s= =q’q’
 q(R,S) т.е. q’ есть надмножество q
q(R,S) т.е. q’ есть надмножество qЕсли q’=q, то это разложение без потерь.
Пример:
R(X,Y,Z) r1(X,Y) r2(X,Z) r1 r2 = (X,Y,Z)123 12 13 123
323 32 33 127
117 11 17 122
132 13 12 323
417 41 47 113
117
112
133
137
132
417
то есть это разложение с потерями.
Рассмотрим другое измерение:
r3(X,Y) r4(Y,Z) r3 r4 = (X,Y,Z)12 23 123
32 17 323
11 32 117
13 132
- 417
это разложение без потерь.
4. Полностью соединимые отношения. Примеры.
Условие полного соединения.
Д
ано r(R) и s(S), тогда q(RS)=r s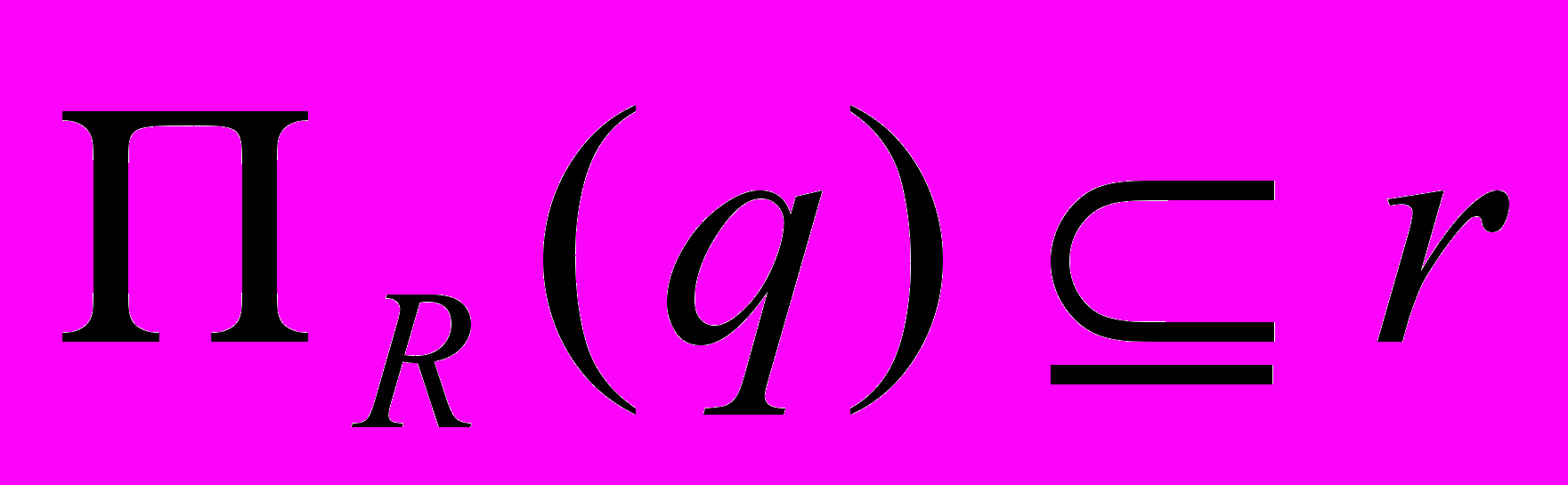 , если выполняется равенство, то r полностью соединимо.
, если выполняется равенство, то r полностью соединимо.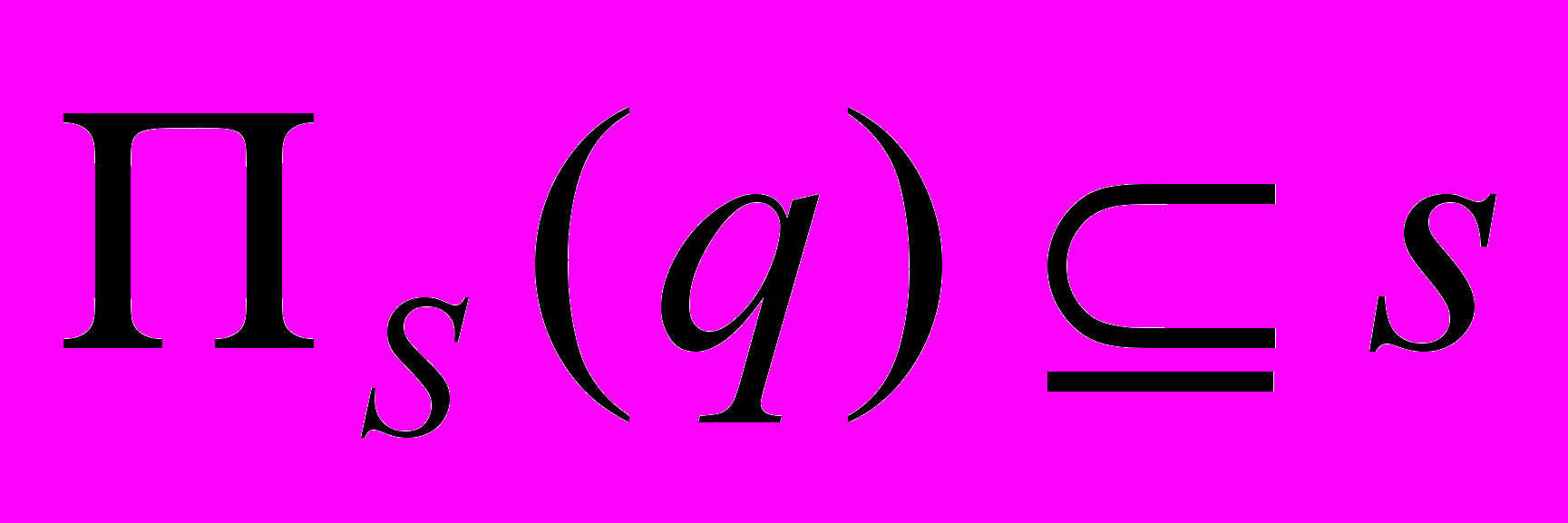 , если выполняется равенство, то s полностью соединимо.
, если выполняется равенство, то s полностью соединимо.Пример:
r(A,B) s(A,B) q(A,B,C)
ab1 b1c ab1c
ab2
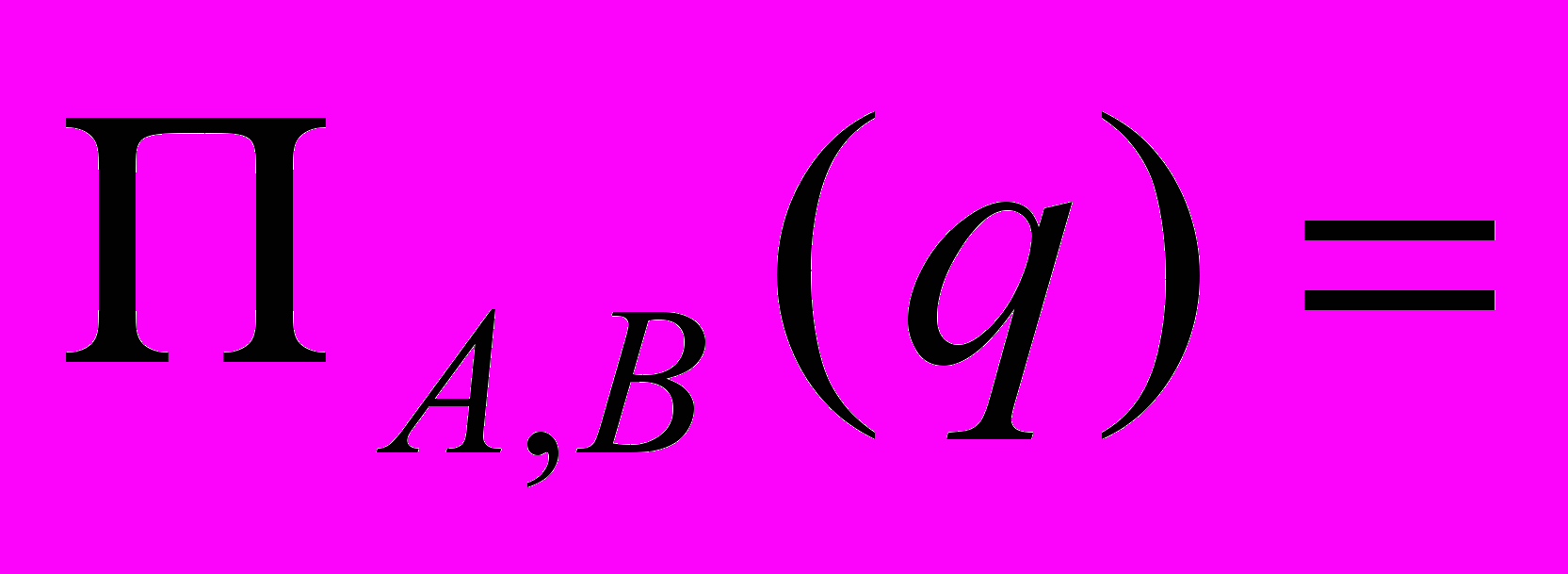 A,B
A,Bab – неполное соединение
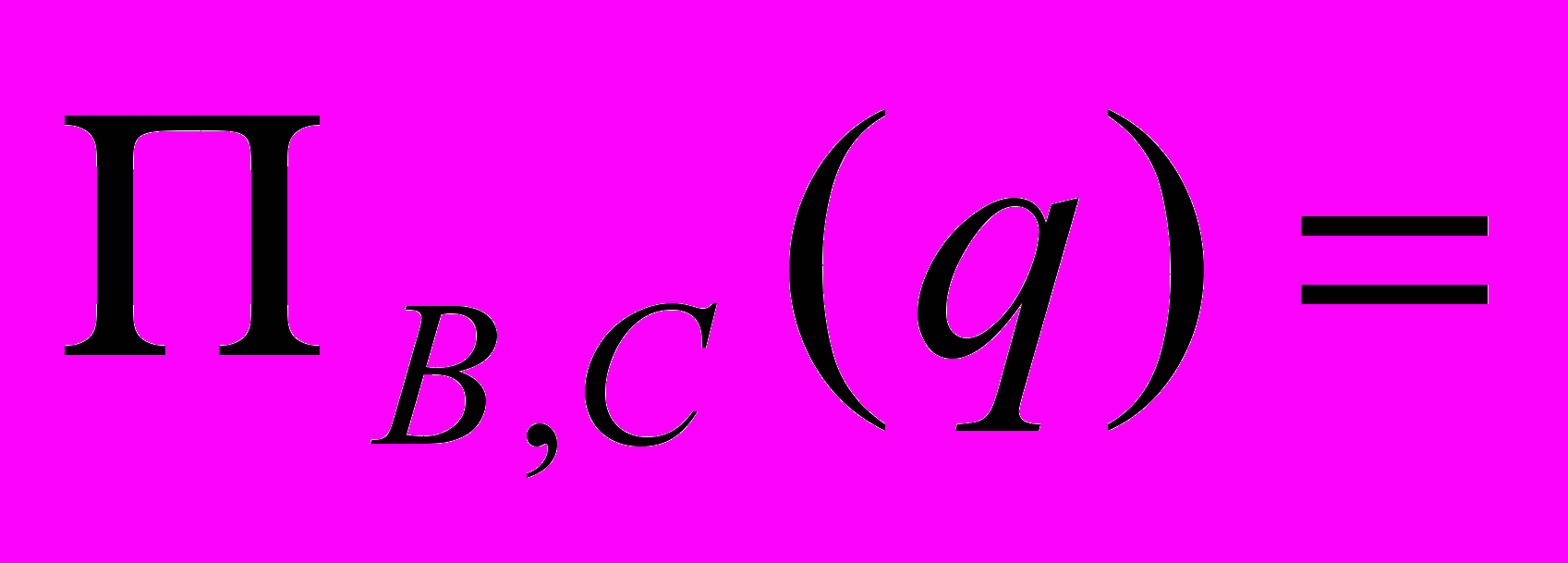 B,C
B,Cb1c - полное соединение.
Для того чтобы было полное соединение необходимо, чтобы в соединяемых столбцах были все значения R и S.
5. Операторы описания данных в SQL.
Типы данных в SQL.
- Integer – целое,занимает 4 байта;
- Smallint - короткое целое, занимает 2 байта;
- Serial- 4 байта, последовательность целых, испорльзуется в качестве ключа, генерируется автоматически, может быть последовательная генерация или случайная.
- Float – число с плавающей точкой, занимает 8 байт;
- Smallfloat – короткое число с плавающей точкой, занимает 4 байта;
- decimal(P[,n]) – упакованное число, Р – общее количество цифр в числе, n- обозначает сколько чисел после запятой, C положительное число, D – отрицательное;
- money(P,n) – для представления денежных едениц;
- date – для хранения дат;
- datetime a to b – временный интервал от а до b, значения а и b могут быть следующие:
year
day
month
hour
minute
second
fraction(1,2,3),
например, datetime year to hour 2000-04-10-13
- char – строки постоянной длины;
- char(n) – строки постоянной длины до n;
- varchar – строки до 255;
- varchar(n) – строки до n;
- text – произвольные тексты до 2ГБ;
- byte произвольная последовательность байтов до 2ГБ;
- null – пустое значение, причем 2 пустых значения не равны между собой.
Атрибуты, используемые для описания таблиц.
- Атрибуты, описывающие характеристики столбца:
Primary key - данное поле является первичным ключом;
References имя_таблицы (имя_поля) – данный столбец является внешним ключом, он взят из таблицы и поля, указанного в атрибуте;
Not null – в этом столбце не должно быть пустых значений;
Default значение – указывает значение, которое принимается по умолчанию.
Unique - все значения в этом поле должны быть уникальными, по умолчанию поле Primary key должно быть Not null и Unique;
Check (Условие) – задает условие, которое должно быть истинным при заполнении информации в этом поле.
- Атрибуты на уровне таблицы.
Check (Условие) – это значение должно быть истинным, чтобы компьютер признал все изменения правильными;
Unique (список полей) – все значения в комбинации полей должны быть уникальными;
Primary key (список полей) – указывается на уровне таблицы, если первичный ключ состоит из нескольких полей;
References имя_поля1 from имя_таблицы1 (поле1) – в нашей таблице имя_поля1 берется из таблицы1, поля1.
6. Операторы манипулирования данными в SQL.
- Добавление информации в таблицу.
Insert into имя_таблицы (список полей) values (список выражений)
- добавление одной записи,
- Чтобы добавить несколько значений из другой таблицы можно использовать следующий оператор –
Insert into имя_таблицы [(список добавляемых полей)]
или использовать полузапрос
select список полей
from список таблиц
where условие
- из таблиц будут выбраны поля, удовлетворяющие некоторому условию, и добавлены в новую таблицу.
- Оператор обновления.
Update имя_таблицы set поле=значение [where условие] (все что записано в квадратных скобках это не обязательно, может быть, а может и не быть).
- Удаление записи из таблицы.
Delete from имя_таблицы [where условие]
Если where условие опущено, то удаляются все записи.
- Оператор поиска данных в таблицах
 distinct
distinctSelect all список_полей from список_таблиц
[where условие] [group by список_полей] [having условие]
[order by поля[asc,desc]] [union [all] подзапрос]
distinct – режим, исключающий повторяющиеся записи в ответе.
All – режим, при котором в ответ включаются все записи. По умолчанию принято all, его можно не указывать.
Если одновременно присутствует where и having, то сначала будет выполняться where.
Если присутствует where, having, group by, то сначала выполнится where, потом group by, а потом having.
- Select список_полей - указывает имена полей, которые должны содержаться в ответе;
- from список_таблиц – указывает имена таблиц, которые участвуют в запросе;
- where условие – задает условие отбора записей в ответ;
- group by список_полей – задает условие группировки записей, группировка – это операция разбиения на группы, каждая из которых содержит одинаковые значения в отмеченных столбцах;
- having условие задает условие отбора групп, если нет group by, то это условие применяется ко всей таблице;
- order by поля[asc,desc] – задает тип сортировки записей в ответе, asc – это сортировка по возрастанию, desc – по убыванию, по умолчанию ставится asc;
- union [all] подзапрос позволяет объединить главный Select с результатом подзапроса, подзапросом называется вложенный оператор Select.
8. Технологии «клиент-сервер».
Сервер – это компьютер, управляющий некоторыми ресурсами и предоставляющий их для коллективного использования. Сервера бывают почтовые, баз данных, вычислительные.
Клиент – это программа или компьютер, обращающийся к услугам сервера
Существуют разные технологии клиент-сервер.
Любая программа может быть представлена из нескольких частей:
- Ввод/вывод (интерфейсная часть);
- Вычисление на основе каких-либо бизнес правил;
- Обращение к данным;
- Управляющая часть, создает единый алгоритм.
В зависимости от того, как поделить эти части между сервером и клиентом, получаются различные технологии.