
Системантика
| Вид материала | Монография |
2. Представление знаний
Дальнейшее развитие структур данных связано с исследованиями в области искусственного интеллекта, которые привели к появлению специальных структур данных: классификационных систем, фреймов, семантических сетей, продукции, сценариев, названных знаниями. В семантическом плане обработка информации получает новую окраску, связанную не с процессом, а с представлением и обработкой знаний.
Знания включают в себя информацию о системах понятий проблемной области и формальных моделей, соответствии этих систем понятий, текущем состоянии проблемной области и методах решения задач.
Для представления знаний используется модельный подход. Все разнообразие моделей представления знаний можно разбить на два типа: логические и эвристические. В основу логических моделей представления знаний положено понятие формальной системы, в которой существующие отношения между единицами знаний выражаются с помощью только синтаксических правил. Эвристические модели имеют разнообразный набор средств, передающих специфические особенности предметной области.
Классификационные системы с давних пор применяются для структурирования и обобщения знаний. В таких системах, с одной стороны, все сущности разбиваются по определенным признакам на некоторое число классов, с другой – группируются вместе. При классифицировании пользователю дается набор объектов, которые можно описать некоторым множеством признаков. Любой объект может принадлежать одному или нескольким классам из фиксированного множества.
В задачах классифицирования наблюдатель должен применить установленные ранее правила принадлежности объектов тому или иному классу. При распознавании правила классификации вырабатываются на основе исследования множества объектов с известной принадлежностью различным классам. Эти объекты в совокупности называются обучающим множеством или выборкой.
В задачах формирования образа объекты предъявляются наблюдателю без указания их принадлежности к классам. Наблюдатель должен самостоятельно построить соответствующее определение классов.
Задача классификации эквивалентна задаче выяснения, является ли некоторая цепочка символов предложением в формальном языке.
Некоторые классификационные системы широко применяются для представления знаний. Вся совокупность употребляемых при классификации слов называется лексикой. Для обеспечения лексической однозначности должны быть учтены отношения синонимии, омонимии и полисемии, свойственные словам естественного языка (см. рис. 61). Например, синонимы – сумка и саквояж; размытые множества и расплывчатые множества; омонимы – мосты: зубные, электрические, телевизионные, речные; полисемия – отражение звука, света, электромагнитных волн, нападения.

Рис. 61. Отношение между словами
Между словами естественного языка существует два вида отношений:
- парадигматические (базисные), обусловленные наличием логических связей между предметами и явлениями, обозначаемыми этими словами. Такие отношения носят неязыковый характер и не зависят от ситуации, для описания которой используются слова. Например: стол-стул (мебель) – отношение координации; стол-мебель – родовидовое отношение; переплет-книга – отношение часть-целое; лампа-свет – отношение причина-следствие; лопата-экскаватор – отношение функционального сходства. Парадигматические отношения – это отношения между предметами реальной действительности;
- синтагматические (синтагма – элементарная единица для текстуальных отношений, ситуационных), которые устанавливаются непосредственно при соединении слов в словосочетания и классы.
Классом называется совокупность множества предметов, любому из которых присущи признаки, отражаемые в содержании соответствующего понятия. Слово или словосочетание, выражающее это понятие, служит именем данного класса.
Классификация – система распределения предметов или отношений на основании наиболее существенных признаков, присущих этим предметам или отношениям и отличающих их от других предметов или отношений. Классы могут быть простыми и сложными.
Простым называется такой класс, члены которого характеризуются только одним общим признаком, выраженным или обозначенным именем этого класса. Такое имя обычно выражается одним словом или одним устойчивым словосочетанием (например: самолеты, пассажиры, реактивные двигатели). Простой класс, как правило, нельзя расчленить на более простые без потери возможности однозначно восстановить исходный класс путем логического умножения полученных более узких классов.
Сложным называется такой класс, члены которого имеют не один общий признак, а сочетание признаков. Именами сложных классов являются различные словосочетания и целые фразы (например: реактивный пассажирский самолет, вычислительные машины на интегральных схемах).
Сложные классы всегда можно расчленить на простые без потери возможности их однозначного восстановления путем логического умножения полученных простых классов.
Иерархическая система классификации – это такая система, в которой между классификационными группировками установлено отношение подчинений, как правило, родовидовое (рис. 62).
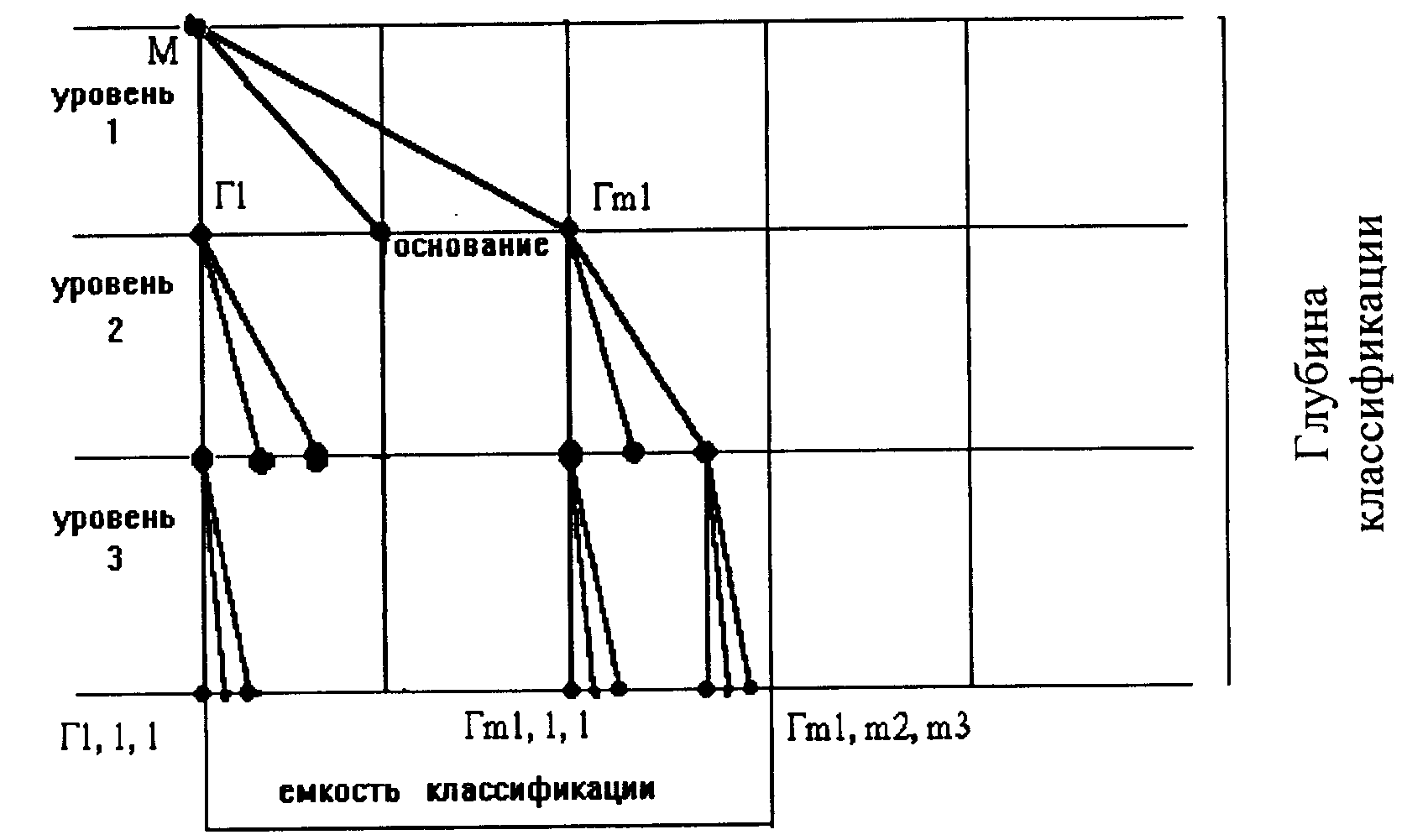
Рис. 62. Иерархическая классификация
Классификационное множество объектов делится по некоторому выбранному признаку (основание деления) на крупные группировки.
Затем любая группировка в соответствии с выбранным основанием деления разбивается на ряд последующих группировок, которые, в свою очередь, распадаются на более мелкие, постепенно конкретизируя объект классификации.
По разным основаниям одну группировку классифицировать нельзя.
При разработке иерархической системы классификации следует соблюдать следующие наиболее важные формально-логические правила:
любая классифицируемая группировка должна делиться только по одному основанию: получаемые в результате деления группировки должны исключать друг друга, т. е. не повторяться;
сумма подмножеств деления должна составить делимое множество.
Основными преимуществами иерархической системы являются большая информационная емкость и простота поиска группировки.
Недостатки заключаются в малой гибкости структуры и невозможности агрегировать объекты по любому сочетанию признаков.
Фасетной системой классификации называется последовательность расположения объектов, которая задается фасетной формулой для конкретной предметной области. Преимущество – гибкость системы, возможность классифицировать по нескольким признакам. Недостаток – нерациональное использование емкости, сложность поиска (рис. 63).
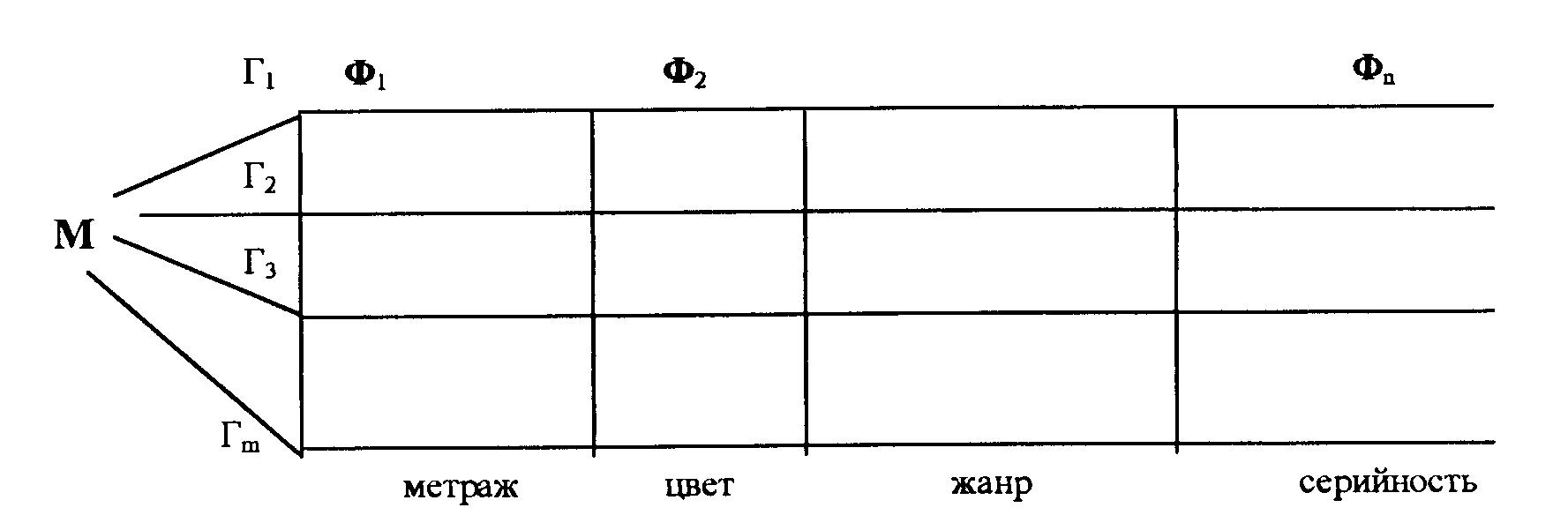
Рис. 63. Фасетная классификация
Алфавитно-предметной классификацией называется система классов, расположенных в алфавитном порядке их имен.
Тезаурус. В основе построения тезауруса лежит положение, по которому центральная тема любого текста может быть обозначена именами простых классов. В качестве имен выступают слова и словосочетания естественного языка, которые называются ключевыми. Среди ключевых слов могут быть синонимы, омонимы, а также возможны различные написания ключевых слов. В этих условиях обработка текста становится затруднительной. Для преодоления этого применяют лексикографический контроль. Он заключается в приведении используемых ключевых слов к единой морфологической форме и к единому написанию, в учете синонимии и многозначности ключевых слов.
Из одинаковых или близких по смыслу ключевых слов строится некоторый класс, из которого наиболее представительное стилистически нейтральное ключевое слово назначается именем такого класса и называется дескриптором. Нормативный словарь, в котором в едином алфавитном ряду приведены все ключевые слова и дескрипторы по выделенной предметной области, называется дескрипторным словарем. Дополнение дескрипторного словаря сведениями о предметно-тематических связях объектов и их характеристик превращает его в тезаурус.
Таким образом, тезаурус – это нормативный словарь, в котором приведены в алфавитном порядке все дескрипторы и синонимичные им ключевые слова, а также отражены важнейшие парадигматические отношения между дескрипторами. Элементарной структурной единицей тезауруса является словарная статья дескриптора, которая строится по алфавитно-структурному принципу:
Di
где Di – заглавный дескриптор; Mi1 – упорядоченное по алфавиту множество условных синонимов, образующих вместе с заглавным дескриптором класс условной эквивалентности; Mi2 – упорядоченное по алфавиту множество дескрипторов, любой из которых связан с Di отношением «род – вид»; Mi3 – упорядоченное по алфавиту множество дескрипторов, любой из которых связан с заглавным дескриптором отношением «вид – род»; Mi4 – упорядоченное по алфавиту множество дескрипторов, любой из которых связан с Di одним из следующих парадигматических отношений:
 целое – часть;
целое – часть;часть – целое;
Ассоциативные связи причина – следствие;
следствие – причина;
функциональное – сходство.
Пример словарной статьи, построенной по указанной схеме, имеет вид:

Трудящиеся (Di) – заглавный дескриптор
Синонимы: народные массы
народ
Видовые связи: интеллигенция
рабочий класс
служащие
крестьянство
Ассоциативные связи: производительные силы
рабочее время
Любое из перечисленных множеств может быть одноэлементным или пустым.
Информационно-поисковые тезаурусы по методам их создания и применения делятся на синхронные и несинхронные. Синхронные методы совмещают построение тезауруса, начиная с пустого состояния или нуль тезауруса с процессом эксплуатации системы. Несинхронные методы предусматривают предварительное, априорное построение тезауруса до начала эксплуатации системы.
Но независимо от указанных методов для построения тезауруса необходимо провести отбор ключевых слов, построить словарь дескрипторов, построить словарные статьи.
При синхронных методах указанные процедуры выполняются в динамическом режиме, одновременно с формированием фонда автоматизированной системы, что ведет к увеличению эксплуатационных расходов. Тезаурус выступает логико-семантической моделью предметной области в нечетких условиях.
Семантические сети предназначены для семантического моделирования реальной действительности с возможностью представления как экстенсиональной, так и интенсиональной информации. Семантическую сеть можно рассмотреть как маркированный ориентированный граф с помеченными узлами и дугами. Узлам соответствуют некоторые объекты, а дугам – семантические отношения между этими объектами. Например:
фермеры собрали урожай в хранилище
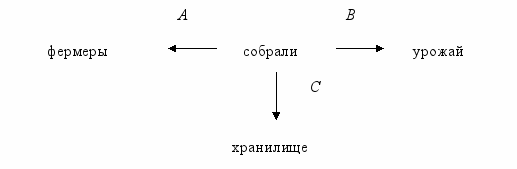
Собрали – предикативный узел. Буквами А, В и С условно помечены семантические отношения между объектом в предикатном узле и объектами в концептуальных узлах.
Метки, приписываемые узлам, выделяют множество рассматриваемых объектов и выступают в качестве их имен, в роли которых могут быть слова естественного языка. Метки, приписываемые к дугам, соответствуют элементам множества отношений, заданных на графе.
Базовым понятием в семантических сетях является понятие сущность, под которой понимаются объекты, отношения, множества, ситуации, события, моменты времени и т. п. Не существует ничего, что не являлось бы сущностью. При определении функций и отношений, необходимых для представления естественно-языковой информации, все сущности рассматриваются в качестве элементов некоторого универсального множества, которое может быть разбито на несколько типов (рис. 64).
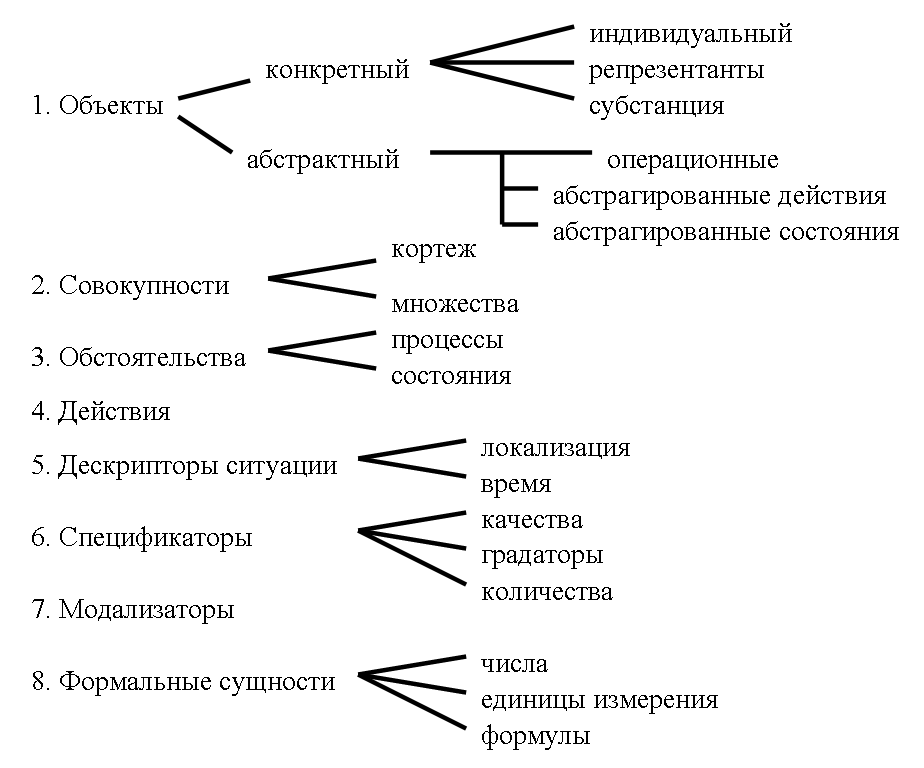
Рис. 64. Типы некоторого универсального множества сущностей
Все многообразие этих сущностей связывается семантическими отношениями, которые условно могут делиться на четыре класса:
- лингвистический;
- логический;
- теоретико-множественный;
- квантификационный.
Лингвистические отношения включают глубиннопадежные отношения и выступают в виде падежей Ч. Филлмора:
А – агент совершаемого события;
Т – предмет, над которым совершается событие;
S – начальное состояние объекта до совершения события;
G – конечное состояние объекта после совершения события;
I – инструмент, с помощью которого субъект совершает событие;
W – путь или способ, которым совершается событие.
Эти глубинно-падежные отношения указывают характеристики и действующих лиц.
К логическим отношениям относятся операции исчисления высказываний. Теоретико-множественные отношения включают отношения подмножества, супер-множества, отношения части и целого, элемент множества. Эти отношения служат для построения иерархии подчинения. Квантификационные отношения содержат логические, нелогические кванторы (много, несколько) и числовые характеристики объекта.
В зависимости от конкретного характера задания к знаниям, представляемым в форме семантической сети, приходится обращаться для извлечения или ввода информации. Для этого необходимо уметь сравнивать графы. Существует несколько методов сравнения структур:
«узел за узлом»;
«часть за частью»;
топологические.
При сравнении «узел за узлом» узлы двух рассмотренных структур сравниваются по одному до тех пор, пока не будет установлено полное совпадение или несовпадение. В последнем случае возвращаемся к тому месту, где было совпадение, и повторяем сравнение с другими элементами (режим возврата). При сравнении «часть за частью» общую структуру разбивают на части, применяя эталоны основных подструктур. Сравнение структур осуществляется по частям (поиск по образцу).
Топологический метод предполагает параллельное сравнение полных структур путем установления определенных простых свойств узлов.
Недостатком семантических сетей является слабое отражение динамики. Этот недостаток устраняют фреймы.
Фрейм является системно-структурным описанием проблемной среды (события, явления), содержащее на основании ее семантических признаков пустые ролевые позиции (слоты), которые после заполнения конкретными данными превращают фрейм в носитель конкретного знания о действительности.
Фрейм можно представить в виде сети, состоящей из вершин и узлов. Верхние уровни фрейма четко определены и представляют собой сущности, всегда истинные по отношению к предполагаемой ситуации. Нижние уровни заканчиваются терминалами (слотами), которые заполняются конкретными знаниями.
С любым слотом связываются описание условий, которые должны быть соблюдены для означивания слота. В простых случаях эти условия сводятся к семантическим категориям, удовлетворяющим значению слота. В сложных случаях они могут отражать отношения между значениями, выбираемые для нескольких слотов.
Семантически близкие друг другу фреймы связываются в систему, содержащую описание зависимостей от некоторых общих множеств слотов.
Одни и те же терминалы могут входить в состав фреймов системы. При переходе из одного состояния в другое перевычисляются только изменившиеся или появившиеся параметры.
Сильной стороной фрейм-представления является включение в него ожиданий и других видов предположений.
Слотам заранее приписываются некоторые стандартные значения – «задания отсутствия». Это позволяет анализировать ситуации, в которых отсутствуют сведения о конкретных деталях. «Задание отсутствия» служит средством для аргументации любой ситуации без использования кванторов. Системы фреймов в свою очередь организуются в информационно-поисковую сеть, позволяющую выбрать для данной ситуации более подходящий фрейм.
В качестве примера рассмотрим систему фреймов для представления куба. Структура фрейма куба имеет вид, показанный на рис. 65.
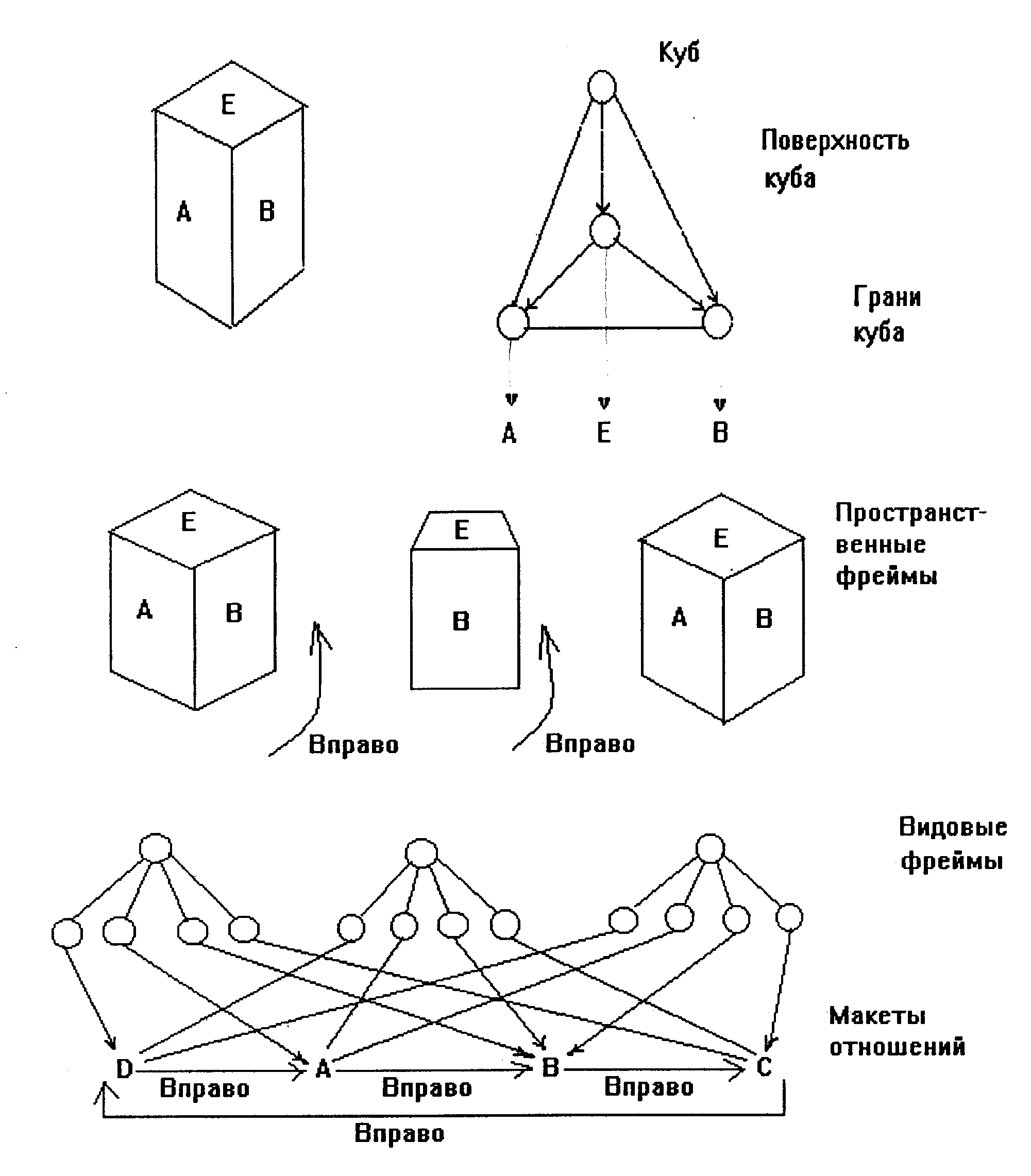
Рис. 65. Структуры фрейма
Фреймы удачно решают проблему представления знаний при известной позиции наблюдателя (известной цели). Но сам фрейм мало помогает, чтобы независимо от позиции наблюдателя определить, что именно данный фрейм необходимо вызвать.
Фрейм-представление отличается эффективным способом упаковки информации в крупные иерархически упорядоченные структуры и позволяют вести поиск в интерактивном режиме.
Продукция. Реляционные системы, семантические сети и фреймы эквивалентны по своим выразительным возможностям и являются универсальными средствами описания моделей мира. Но их практическое применение связано со значительными сложностями разработки и ведения соответствующих систем представления знаний.
Теоретически любое знание может быть представлено в виде таблиц, семантической сети или сети фреймов. Практически с увеличением сложности предметной области трудности реализации возрастают. Этим объясняются непрекращающиеся поиски более удобных в реализации методов представления знаний.
В последние годы приобретают популярность продукционные системы представления знаний, основанные на математическом аппарате канонических систем. Канонические системы были предложены Э.Л. Постом.
Каноническая система определяется следующим образом. Предположим, что задан алфавит символов и список переменных. Конечная цепочка символов и переменных называется термом.
П
 римеры термов:
римеры термов:1 ЦИФРА
 термы
термыХ ЦИФРА
Из термов строятся продукции, являющейся математическим аналогом понятий, правил, концепций.
П
- (термы) посылки
- (термы) заключение
родукция – это выражение вида.
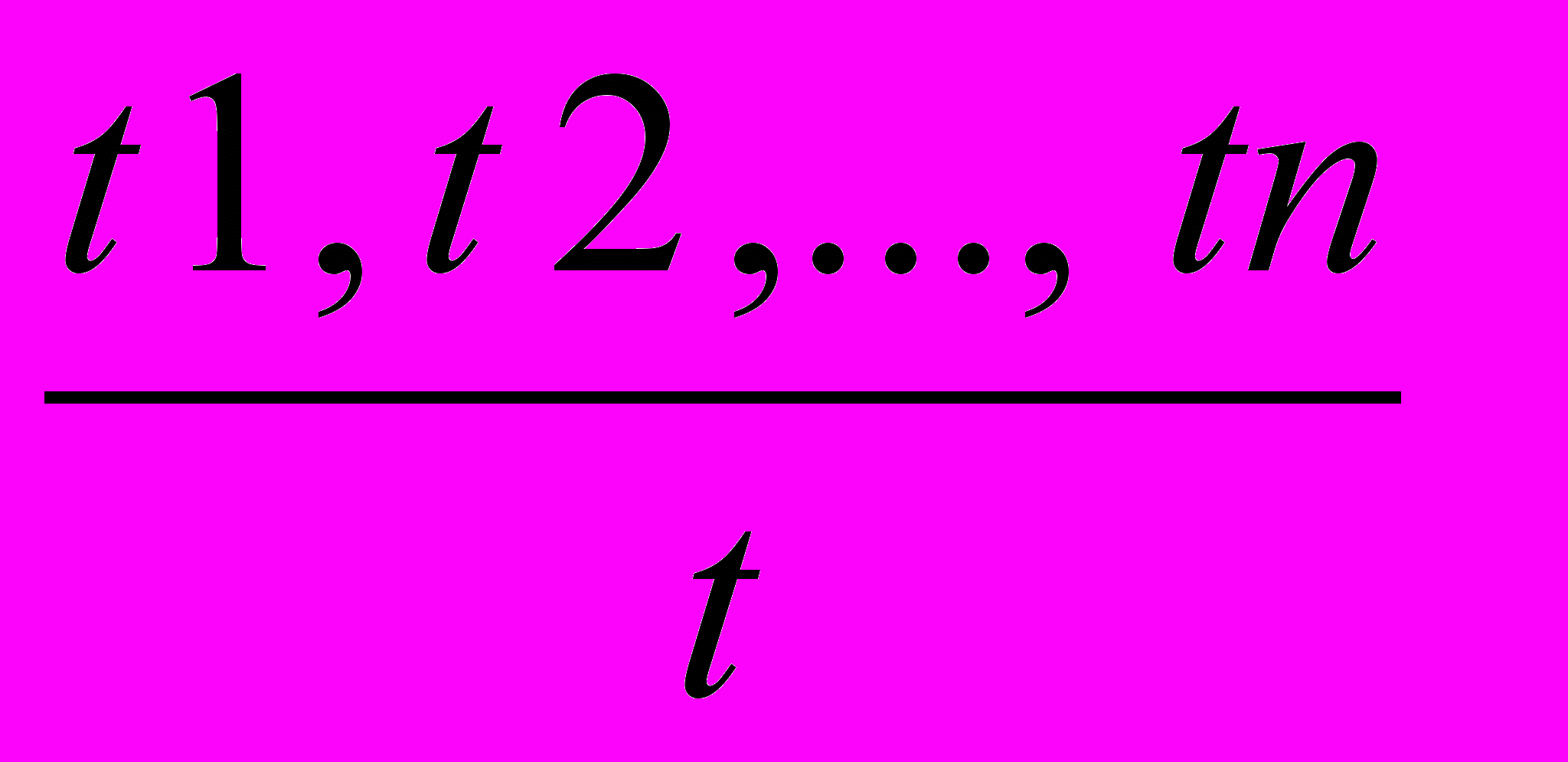
Продукция без посылок называется аксиомой.
Каноническая система определяется конечным набором продукции. Применение продукции получается подстановкой слов в заданном алфавте вместо ее переменных. Вместо одинаковых переменных подставляются одинаковые слова.
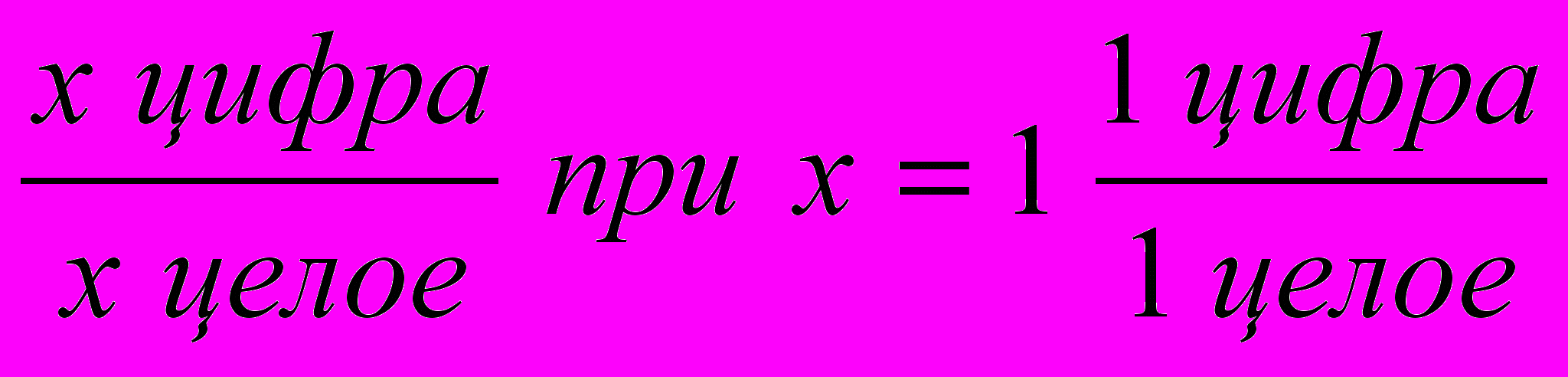
Если доказуема посылка, то доказуемо и заключение.
Каноническую систему, определяющую понятие рационального числа, можно представить следующим образом:
алфавит – прописные русские буквы и знак «/»;
переменные – x, y.
 Продукция
Продукция0
 цифра 1) x цифра
цифра 1) x цифра1 цифра аксиомы x целое
… 2) x целое y цифра9 цифра xy целое
3) x целое y целоеx/y рационально
при х = 2, у = 15
1
 ) 2 цифра 2) при x= 1 1 целое 5 цифра
) 2 цифра 2) при x= 1 1 целое 5 цифра2
 целое y=5 15 целое
целое y=5 15 целое3) 2 целое 15 целое
2
 /15 рационально
/15 рационально1. В канонических системах продукции допускают обобщения.
x буква
П
 усть продукция P =
усть продукция P = x буква ? DA .
Можно сделать обобщение: если х имеет наименование у, то справедлива запись:
xy
q
 =
= xy ? DA .
Пусть имеется p x1, x2, …
q s1, s2, ...
Если вместо переменных х продукции q можно подставить терм S так, что p=q/x1=s1, x2=s2, то продукция p называется частным случаем продукции q, а q– обобщением P. В предыдущем примере p=q/y=БУКВА.
2. Способность продукционных систем описывать действия по правилам и исключениям.
Напиши х печать х № 1.
Напиши запятую печать , № 2.
Поступает запрос: напиши запятую. Из аксиомы № 1 получаем:
Напиши запятую печать ЗАПЯТАЯ.
Из аксиомы № 2 имеем:
Напиши запятую печать ,
Введем дополнительную продукцию
х ≠ запятая
н
 апиши х печать х
апиши х печать хНекоторая продукция
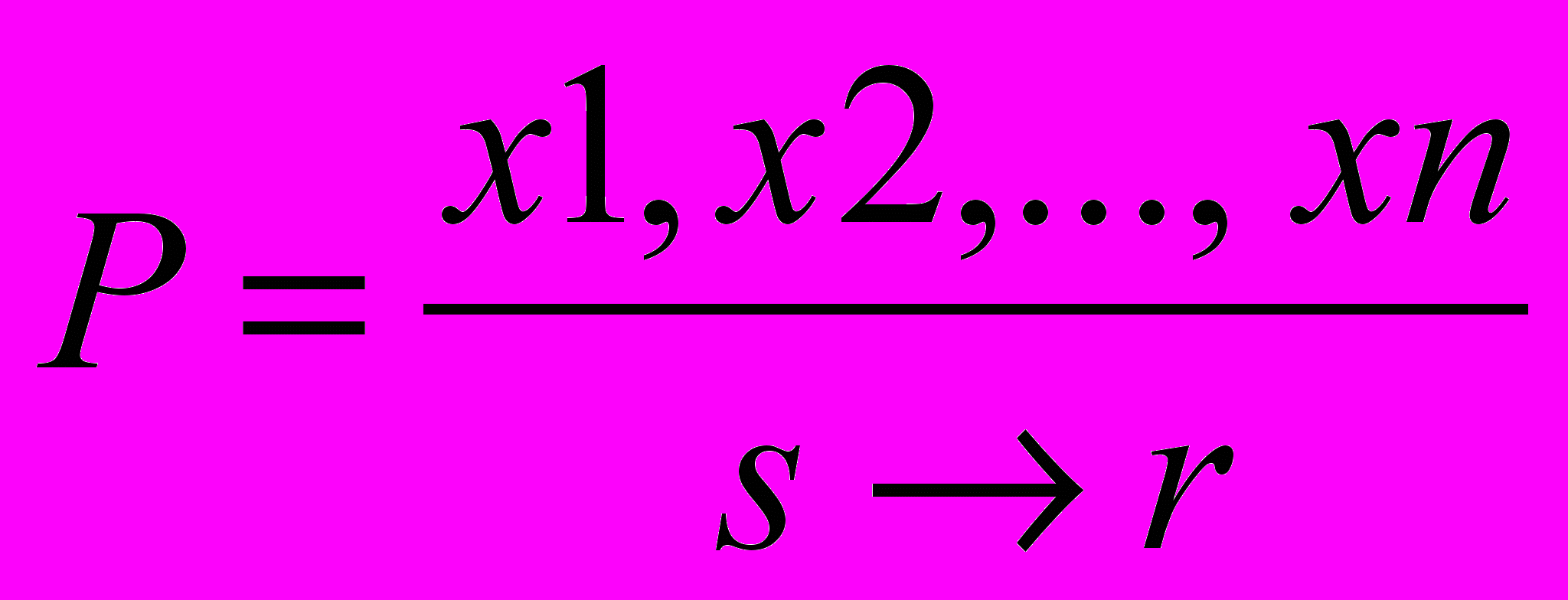
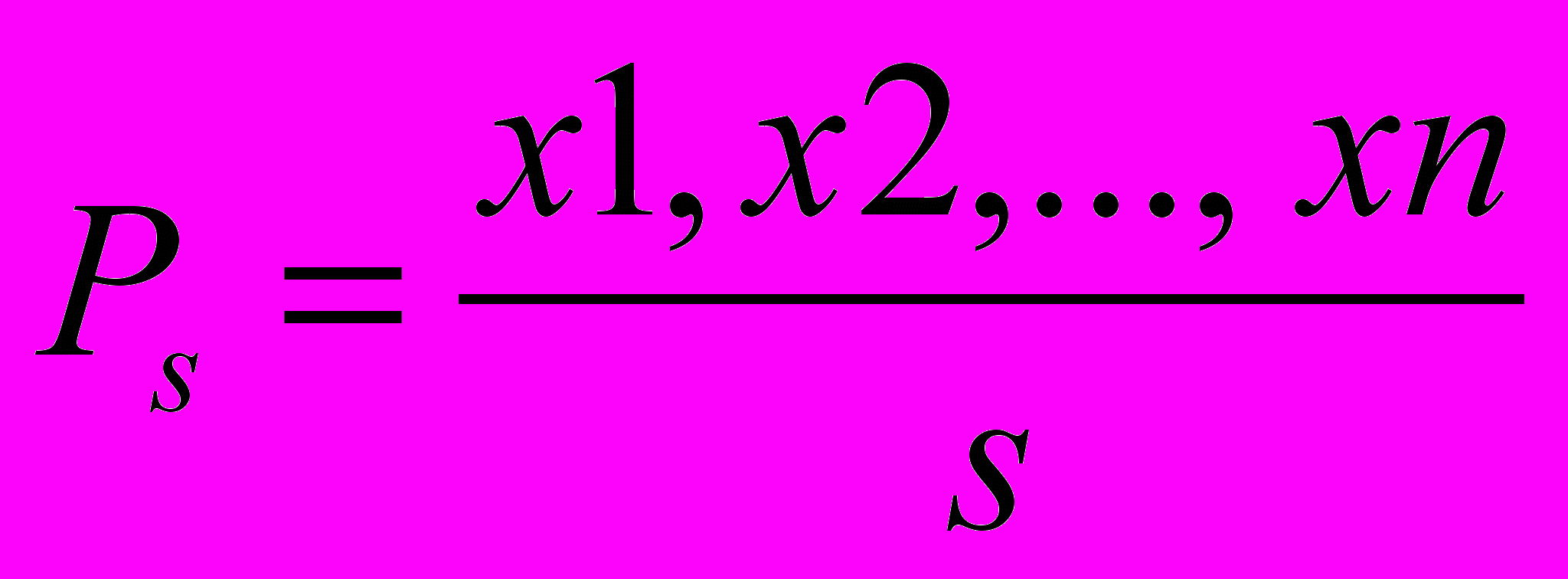 .
.Ps– область определения Р. При этих условиях:
Напиши АВС печать АВС
Напиши запятую печать ,
Эти возможности моделируют процессы мышления и действий человека. Таким образом, возможность действия по правилам и исключениям – это проблема преодоления коллизии. Если уместно исключение, то система всегда будет действовать по исключению (рис. 66).
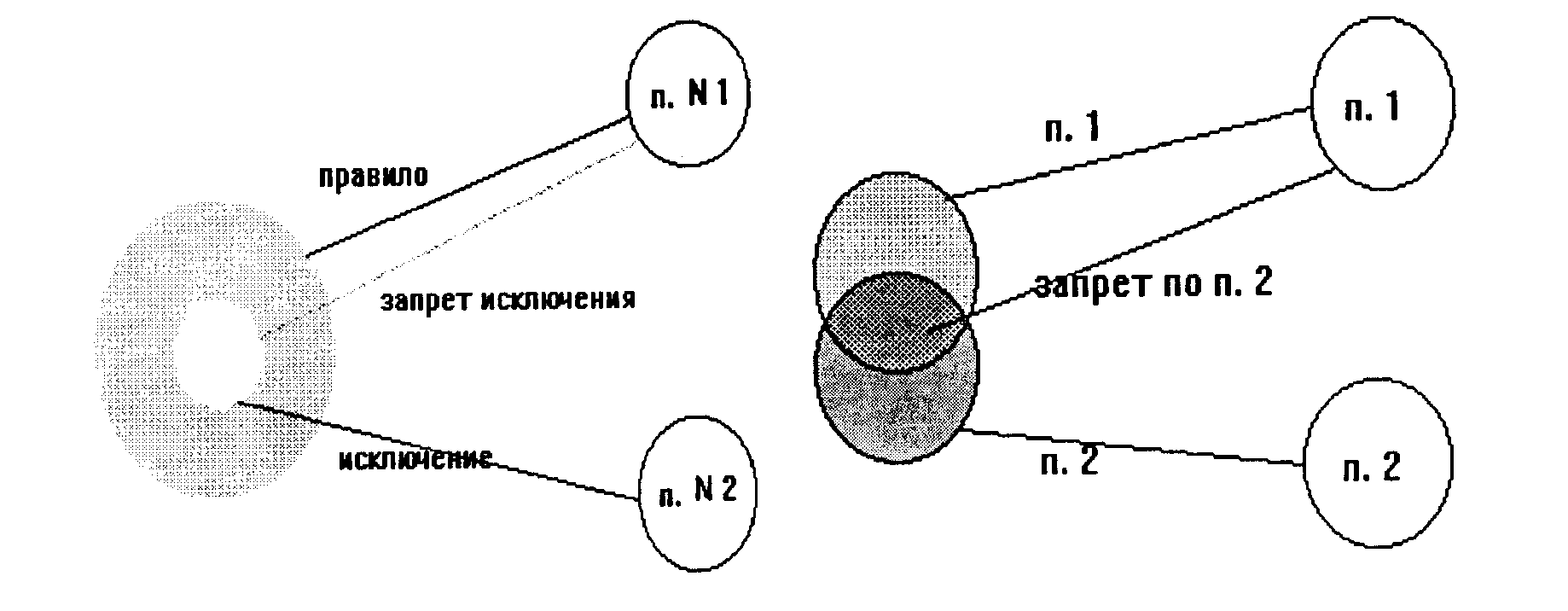
Рис. 66. Схема действий по правилу и исключению
Такие системы называются концептуальными и разработаны В.Е. Кузнецовым. Возможность обобщения значительно упрощает отображение сложной предметной области и дает возможность пользователю самому модифицировать систему, настраивая ее на свои текущие информационные потребности без помощи профессиональных разработчиков1.
По своей выразительной силе продукционные системы равнозначны системам, использующим языки исчисления предикатов, но в отличие от них могут однообразно представлять все знания.
Структурные единицы типа «если» (условие), «то» (действие) обеспечивают как представление, так и манипулирование знаниями. К таковым относятся языки: ЛИСТ, Рефал, Пролог, ПСИ. Эти языки обработки символьной информации составляют основу ЭВМ пятого поколения.
Расширенные семантические сети обеспечивают представление сложных выводов знаний, когда объекты, связанные отношениями, образуют совокупности; когда имеются кванторы; когда отношения, в свою очередь, связываются отношениями. Такие сети являются развитием, направленным на повышение изобразительных возможностей при сохранении свойства однородности представления различных видов знаний, представленных в формах естественного языка, в том числе типа логических конструкций со словами-кванторами, с нечеткими категориями, различного рода неопределенностями.
Для представления продукционных правил используются расширенные семантические сети специального вида, в которых учитывается зависимость ПРИЧИНА – СЛЕДСТВИЕ и задается отношение ЧАСТЬ – ЦЕЛОЕ.
Расширенная семантическая сеть определяется как множество элементарных фрагментов вида2 D0(D1, D2, …, Dk/Dk+1), где D0, D1, D2, …, Dk/Dk+1 ∈ Dk > 0, составленных из вершин D. Такой фрагмент представляет k-местное отношение.
Вершина D0 ставится в соответствие имени отношения, вершины D1, D2, …, Dk – объектам, участвующим в отношении, а вершина Dk+1 – всей совокупности упомянутых объектов с учетом их отношений.
Анализ развития моделей представления знаний показывает, что существует тенденция к однообразному представлению в их структурах разнородных данных. Очень вероятно, что комплексное представление знаний в компьютере будет развиваться в направлении, близком к аппарату расширенных семантических сетей.
Глава IX
ХРАНЕНИЕ ЗНАНИЙ И ПОИСК ИНФОРМАЦИИ