
Краснопрошин Виктор Владимирович, доцент Кожич Павел Павлович Минск 2009 г. Оглавление Глава Введение. 4 Глава Анализ проблемы и постановка задачи. 5 1 задача
| Вид материала | Задача |
- Краснопрошин Виктор Владимирович ст преподаватель Кожич Павел Павлович Минск 2008, 166.87kb.
- Кожич Павел Павлович, доцент Запрудский Сергей Николаевич Минск 2010 г. Оглавление, 202.51kb.
- Степанец Владимир Яковлевич доцент Кожич Павел Павлович Минск 2008 г. Оглавление Оглавление, 228.35kb.
- Забрейко Петр Петрович доцент Кожич Павел Павлович Минск 2007 г. Оглавление Оглавление, 254.67kb.
- Кожич Павел Павлович Минск 2010 г Оглавление Оглавление 2 Применение информационных, 302.47kb.
- Кожич Павел Павлович, профессор Воробьев Василий Петрович Минск 2010 г. Оглавление, 247.09kb.
- Сидорская Ирина Владимировна старший преподаватель Кожич Павел Павлович Минск 2010, 900.44kb.
- Коледа Виктор Антонович, ст преподаватель Пол Кожич Минск 2010 г. Оглавление Оглавление, 340.48kb.
- А. А. Самопознание и Субъективная психология. Содержание введение Раздел I постановка, 5204.65kb.
- Русская доктрина андрей Кобяков Виталий Аверьянов Владимир Кучеренко (Максим Калашников), 11986.64kb.
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Выпускная работа по
«Основам информационных технологий»
Магистранта
факультета прикладной математики и
информатики
кафедры МО АСУ
Тарасюка Александра Евгеньевича
Руководители:
заведующий кафедрой МО АСУ
доктор технических наук
Краснопрошин Виктор Владимирович,
доцент Кожич Павел Павлович
Минск – 2009 г.
Оглавление
Глава 1. Введение. 4
Глава 2. Анализ проблемы и постановка задачи. 5
2.1 Задача распознавания лиц. 5
2.1.1 Общая формулировка задачи. 5
2.1.2 Классификация задач распознавания лиц. 5
2.2 Основные подходы к решению проблемы. 6
2.2.1 Анализ существующих подходов. 6
2.2.2 Предобработка изображения. 6
2.2.2 Существующие методы сравнения изображений. 7
2.3. Технологические основы нейросетевых методов. 11
2.3.1 Основные понятия. 11
2.3.2 Архитектура многослойных нейронных сетей. 12
2.3.3 Свёрточные нейронные сети. 14
2.4. Постановка задачи. 15
Глава 3. Разработка алгоритма для решения задачи. 15
3.1. Описание базового алгоритма. 15
3.2. Анализ результатов работы. 17
3.2.1 Описание проведённых экспериментов. 17
3.2.2. Анализ ошибок базового алгоритма. 19
3.3. Модификации базового алгоритма. 20
3.3.1 Нормализация входных значений. 20
3.3.2 Введение обратных связей. 22
3.3.3 Выводы. 22
Глава 4. Описание программной системы. 23
4.1 Общая архитектура и состав системы. 23
4.2 Программная реализация базового алгоритма. 23
4.3 Средства настройки. 24
Глава 5. Эксперименты. 26
5.1 Результаты. 26
5.2 Выводы. 27
Глава 6. Заключение. 28
Предметный указатель к реферату 29
Интернет ресурсы в предметной области исследования. 30
Действующий личный сайт в WWW. 31
Граф научных интересов. 32
Презентация магистерской диссертации. 35
Тестовые вопросы по Основам информационных технологий 36
Список литературы 37
Приложение 38
Глава 1. Введение.
В настоящее время биометрические системы идентификации человека приобретают всё большее распространение. Их главные преимущества перед традиционными способами идентификации следующие: они основываются на уникальных биологических признаках, а, следовательно, их чрезвычайно сложно подделать. Также, очевидно удобство их использования – они не требуют от человека обладания какими-либо специальными карточками, ключами и т.д.
Существует несколько способов идентификации по биометрическим признакам. На данный момент лидерами являются идентификация по отпечаткам пальцев и сетчатке глаза. Другие виды идентификации (по лицу или голосу) менее развиты. Они не столь надёжны по своей природе (проще для фальсификации), а поэтому их использование возможно лишь в некоторых областях.
Тем не менее, идентификация по лицу имеет ряд неоспоримых преимуществ. Главные из них – это относительная дешевизна и мобильность оборудования (в большинстве случаев требуется лишь персональный компьютер и фото (видео) камера), быстрота идентификация, её массовость и отсутствие необходимости каких-либо действия со стороны идентифицируемого.
В большинство современных методов выделение ключевых методов, определение их важности и нахождение взаимосвязей между ними производится автоматически или полуавтоматически при помощи анализа обучающей выборке.
Главные трудности, которые необходимо преодолеть при идентификации человека по лицу – это обеспечения независимости работы системы от таких факторов, как освещённость, ракурс, а также возрастные изменения. Многие методы включают в себя большой и затратный этап предобработки. Однако без понимания некой общей семантики изображения сложно сделать это правильно.
Именно поэтому перспективным выглядит направление нейросетевых методов. Принцип работы таких методов основан на принципе работы человеческого мозга. Они с помощью обучения позволяют находить взаимосвязи между отдельными признаками изображения и выполнять распознавание с достаточной точностью.
В данной работе описывается подход к проблеме создания системы распознавания лиц на основе свёрточной нейронной сети с вейвлетной предобработкой изображения.
Глава 2. Анализ проблемы и постановка задачи.
2.1 Задача распознавания лиц.
2.1.1 Общая формулировка задачи.
В общем случае практическая задача распознавания образов формулируется следующим образом. Имеется множество неких объектов и множество классов объектов. Для некоторого конечного подмножества (называемым обучающей выборкой) известна принадлежность объектов к классам. Требуется построить алгоритм, который находил бы принадлежность к классам для всех объектов множества.
Существует различные вариации этой задачи. Например, классы могут быть не заданы изначально (обязанность их выделения лежит на алгоритме).
2.1.2 Классификация задач распознавания лиц.
Частным случаем задачи распознавания образов является задача распознавания лиц. В задачах распознавания лиц в качестве объектов выступают изображения человеческого лица. В качестве классов могут быть различные сущности. Существует 3 наиболее востребованных группы задач: поиск в больших базах данных, идентификация и контроль доступа для небольшой группы и контроль фотографий в документах.
В двух первых группах в качестве классов выступают люди (также, как правило, имеется класс незнакомых). Различия заключаются в основных требованиях к ответу. Если в первой группе ответом может служить список людей (при этом не требуется большой точности, главное, чтобы искомый человек был в этом списке), то во второй группе на первое место выходит требование к точности. При этом смягчаются требования к производительности (в следствии меньшего количества классов) и скорости обучения системы. В третьей группе имеется только 2 класса – класс соответствия изображения лица изображению на документах и противоположный ему класс.
Методы, применяемые для решения этих задач, серьёзно отличаются. Мы будем рассматривать лишь вторую группу. В рассматриваемой задаче имеется небольшая группа людей (10 – 100 человек), которых система должна распознавать по изображению их лица. Для каждого человека имеется его изображения в различных вариациях. Требуется по единичному изображению лица соотнести его с каким-либо человеком.
Время обучение не является критичным, важно лишь время распознавания. Желательно, чтобы система имела возможность дообучаться на вновь поступающих изображениях. Также требуется высокая достоверность распознавания, возможно, даже за счёт увеличения отказов от распознавания.
2.2 Основные подходы к решению проблемы.
2.2.1 Анализ существующих подходов.
Большинство существующих методов обладает следующей схемой:
- Предобработка изображения.
- Сравнение изображений посредством некой метрики. Как правило, сравнение производится после нахождения значений ключевых признаков для изображения.
- Отнесение изображения к определенному классу на основе результатов сравнения.
2.2.2 Предобработка изображения.
Предобработка служит 2 главным целям:
- увеличить скорость работы системы при помощи отбрасывания несущественной информации.
- обеспечить устойчивость метода к изменению освещения, расположения лица на изображении и т.д. путём приведения изображения к некому каноническому виду.
Главным способом устранения избыточности изображения является уменьшение его размеров. Это может выполняться разными методами.
Наиболее простой (и наименее точный) – это масштабирование путём локального усреднения значений пикселей. На примере базы ORL ясно, что после масштабирование изображений до размера 23 на 28 человек всё равно с лёгкостью способен распознать его. Следовательно, информации, содержащейся там, вполне достаточно и для автоматического распознавания. Данное утверждение неверно для более обширных баз, где требуется больше информации для распознавания.
Более точные методы уменьшения размеров изображения – это частотные преобразования. Некоторую функцию можно представить в виде суммы синусоид различного периода, умноженных на некоторые коэффициенты. Набор синусоидальных функций представляют собой ортонормальный базис, и поэтому коэффициенты несут максимально независимую информацию. Частотные преобразования позволяют вычислить эти коэффициенты. Таким образом, каждый коэффициент характеризует всю функцию целиком, а не в окрестности одной точки в отличие, например, от коэффициентов полиномов при разложении в ряды Тейлора.
Коэффициенты, соответствующие низким частотам, характеризуют общую форму изображения, высоким частотам – резкие грани и различные мелкие детали. Причём по небольшой части низкочастотных коэффициентов (10-50% от всего числа коэффициентов) можно с высокой степенью точности реконструировать исходное изображение (на глаз практически неотличимо).
Задачи реконструкции и распознавания связаны между собой, потому что многие современные форматы хранят изображения в сжатом виде, и в большинстве из них используются частотные преобразования (JPEG, MPEG). [5]
Развитием данной идеи являются вейвлетные преборазования. В отличии от преобразований Фурье, они являются частотно-локальными, и позволяют оценить не только вклад какой-либо составляющей, но и её пространственно-временную локализацию. Вейвлетное сжатие позволяет более точно реконструировать изображение по сравнению с преобразованием Фурье или косинусным преобразованием.
Для обеспечения устойчивости к различным факторам используются более сложные методы предобработки (выравнивание яркости, поиск лица и его ориентации на изображении). Однако, несмотря на их развитие, они всё равно порождают ошибки, в том числе такие, которые не могут быть исправлены самим алгоритмом распознавания. Также при использовании сложных методов предобработки всегда существует риск в результате преобразований потерять информацию, важную для распознавания.
2.2.2 Существующие методы сравнения изображений.
Суть большинства методов распознавания заключается в выделении неких признаков для рассматриваемых объектов и сравнении их посредством некой метрики.
При этом существует 4 основных подхода:
- Разделение рассматриваемого пространства признаков на области.
- Выделение ключевых областей на изображении и их сравнение.
- Анализ характера искажения изображения.
- Анализ характера искажения изображения и всего изображения.
Методы, основанные на разделении пространства признаков.
К первой группе относятся, например, наиболее ранние способы распознавания лиц – геометрические. В них в качестве признаков используются расстояния между ключевыми точками на лице, а также углы, образующиеся между линиями, соединяющие эти точки. Ключевые точки ищутся с помощью предобработки в автоматическом или полуавтоматическом режиме. К достоинствам данных методов можно отнести скорость работы, простоту алгоритма. Однако, недостатки также очевидны – это большая доля эмпиричности (работа зависит от выбора ключевых точек и величин, используемых в качестве признаков), неустойчивость данных алгоритмов к большинству видов искажений (поворот, наклон головы).
Сходными свойствами также обладают метод линейного дискриминанта, а также простейшие нейронные сети [1]. Возможны их вариации с использованием частотных преобразований (косинусное преобразование, вейвлеты, Габоровские преобразования). ). В этом случае признаками служат коэффициенты этих преобразований. Несмотря на то, что самые совершенные методы могут лучшим способом разбить исходное пространство на области, этого недостаточно, поскольку для реальных объектов требуется огромное количество разделяющих областей (и обучающих примеров), чтобы учесть всевозможные способы изменения изображений объектов. Таким образом, на обучающей выборке методы дают 100% результат и разбивают пространство признаков на области, то есть решают задачу в её формальной постановке, но задача в её искомой постановке оказывается решённой неверно. Это связано с тем, что даже незначительное, с человеческой точки зрения, изменение изображения (например, ракурс, освещение или наличие бороды), может дать положение в пространстве признаков, очень далеко лежащее от исходного. И система в этом случае может среагировать не на одинакового человека, а, например, на одинаковый ракурс, посчитав изображение другого человека в том же ракурсе наиболее похожим на неизвестное. Таким образов, данные методы имеют определённый порог точности, который сложно или невозможно преодолеть модификациями алгоритма.
Методы, основанные на выделении ключевых областей.
Работа следующей группы методов основана на выделении ключевых участков изображения и их последующем сравнении посредством некой метрики, после чего изображение относится к одному из классов. Для сравнения могут быть использованы методы предыдущей группы. Как и в любых комбинированных методах, главным недостатком является «накопление» ошибок на различных степенях решения задачи. Поэтому в данной группе методов чрезвычайно важную роль играет предобработка изображений (выравнивание яркости, коррекция местоположения лица, масштабирование), после применения которой важная для распознавания информация не должна быть потеряна или искажена.
Методы, основанные на анализе характера искажений изображения.
Весьма распространен метод эластичных графов [4][7], относящийся к третьей основной группе методов. При помощи фильтров Габора на изображении ищутся ключевые точки и вычисляются наборы коэффициентов для этих точек - джетов. Так как человек при распознавании, очевидно, выделяет отдельные участки лица и их взаимное расположение, идея выглядит перспективной.
Джеты характеризуют локальные области изображений и служат для двух целей. Во-первых, для нахождения точек соответствия в заданной области на двух различных изображениях и анализа искажения. Во-вторых – для сравнения двух соответствующих областей различных изображений.

Рис.2.1 Пример отмеченных вручную графов для обучающей выборки.
Для поиска точек на новом изображении оценивается её приблизительное расположение. Затем в окрестности этой точки ищется точка с джетом, наиболее близким к джетам этого участка, уже находящимися в базе.[4]
Вышеописанный метод учитывает только суммарную взвешенную меру геометрических искажений, никак не пытаясь построить модель или учесть характер этих изменений. Другими словами, это перспективный метод извлечения и поиска характеристик на изображении, но этому методу не хватает механизма классификации.


Рис.2.2 Пример 2 ошибок, первая вызвана плохой предобработкой,
вторая – самим алгоритмом распознавания.
Нами были проведены тесты упрощённой реализации данного метода (при этом полученные коэффициенты подавались на вход простейшего 2-х слойного персептрона для более точной классификации). Результаты можно назвать неоднозначными (Рис.2,3). С одной стороны, полученная точность достаточно велика, однако она достигается только при ручной разметке обучающего набора, что требует больших затрат. Также сложно выявлять причины ошибок для улучшения качества работы. Поэтому нами было решено отказаться от развития этого метода.

Рис.2.3 Пример успешной коррекции местоположения
зрачков и успешного распознавания.
Методы, основанные на анализе характера искажений изображения и всего изображения.
Для обеспечения устойчивости к различным факторам используются более сложные методы предобработки. Как следствие, несмотря на их развитие, они всё равно порождают ошибки, в том числе такие, которые не могут быть исправлены самим алгоритмом распознавания. В итоге ошибки аккумулируются, что ведёт к понижению точности. Всё это подталкивает к использованию методов, работающих с изначальным изображением (возможно, после незначительных преобразований, не затрагивающих структуру изображения (масштабирование, выравнивание яркости)), анализирующих как искажение изображения, так и выделенные признаки.
Наиболее исследованными и эффективными методами данного типа являются свёрточные нейронные сети и скрытые Марковские модели. Анализируя различные работы в данной области, можно сделать вывод, что по эффективности и сложности эти методы эквивалентны. Нами были выбраны нейронные сети, так как в этой области уже был получен большой объём предварительных результатов.
2.3. Технологические основы нейросетевых методов.
2.3.1 Основные понятия.
Основными понятиями для нейросетевых методов являются нейрон, нейронный слой, нейронная сеть (НС).
Большинство нейронных сетей состоят из формальных нейронов [2], имеющих следующий (или похожий) вид, рис.1:
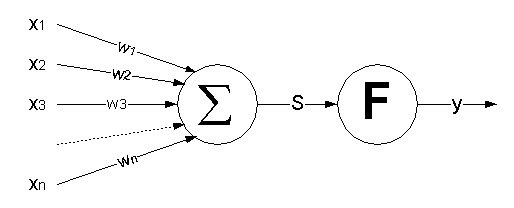
Рис.2.4 Формальный нейрон
где x1..xn – значения, поступающие на входы (синапсы) нейрона, w1..wn – веса синапсов, S – взвешенная сумма входных сигналов:
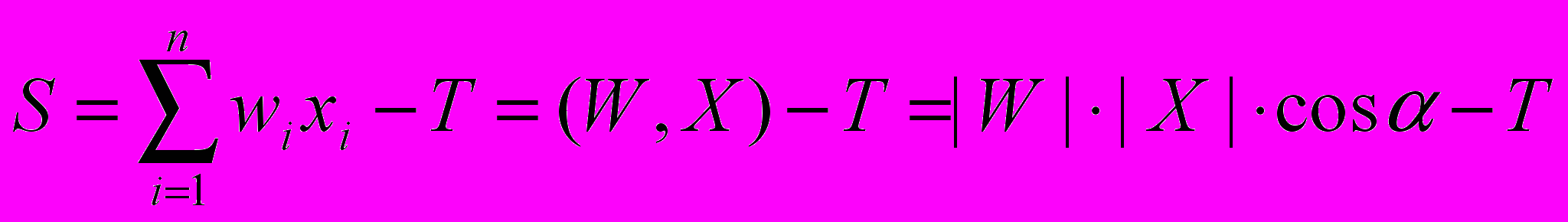
T – порог нейрона, во многих моделях обходятся без него, F – функция активации нейрона, преобразующая взвешенную сумму в выходной сигнал
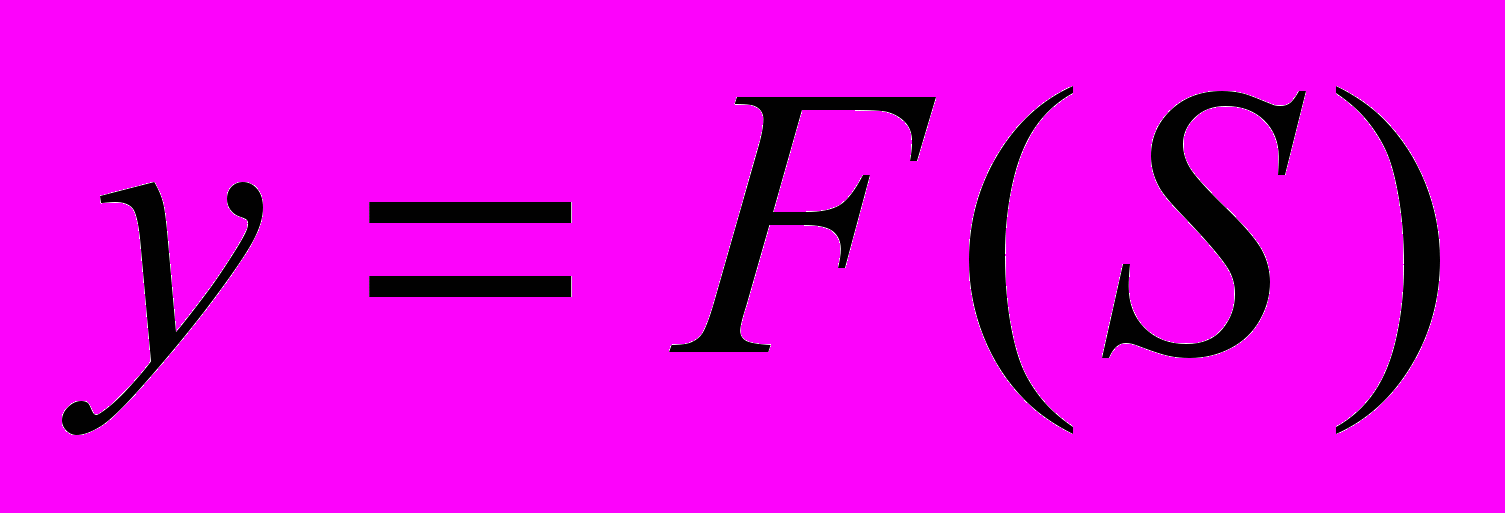 . Как правило, в качестве такой функции выступает сигмоидная функция или гиперболический тангенс.
. Как правило, в качестве такой функции выступает сигмоидная функция или гиперболический тангенс.В нейронных сетях нейроны располагаются слоями и бывают полносвязными, когда каждый нейрон связан со всеми остальными, и слоистыми, когда нейроны последующего слоя связаны только со всеми нейронами предыдущего слоя. В сложных нейронных сетях возможны также случаи, когда нейрон связан лишь с участком предыдущего слоя.
Формальный нейрон отдалённо напоминает свой биологический прототип. Искусственные нейронные сети способны выполнять любые логические операции и вообще любые преобразования, реализуемые дискретными устройствами с конечной памятью.
2.3.2 Архитектура многослойных нейронных сетей.
Архитектура многослойных нейронных сетей (другое название – многослойный персептрон) представляет собой несколько последовательно соединённых слоёв нейронов, где нейрон связан со всеми нейронами предыдущего слоя. В процессе анализа нами были проведены тесты 2-х слойного персептрона, принимающего на вход всё изображение. На выходном слое кол-во нейронов совпадает с количеством классов. Главные достоинства – это относительная простота алгоритма, полная автоматизация, удовлетворительная точность.
Для обучения сети в большинстве подходов применяется алгоритм коррекции весов, называемый обратным распространением ошибки [2]. Для последнего слоя вычисляется ошибка (разница между выходными yki и эталонными ti значениями), и распространяется обратно по сети сквозь веса скрытых нейронов. Величина коррекции ошибки (для гиперболического тангенса):
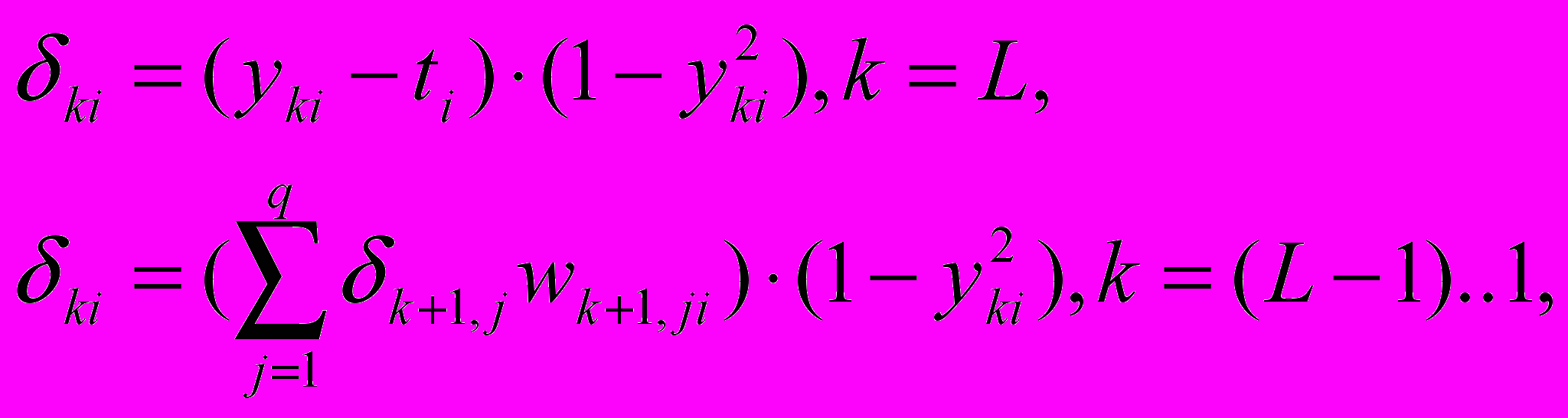
,где k уменьшается от L до 1, q – число нейронов в слое k+1, для РНС эталоном является входное изображение:
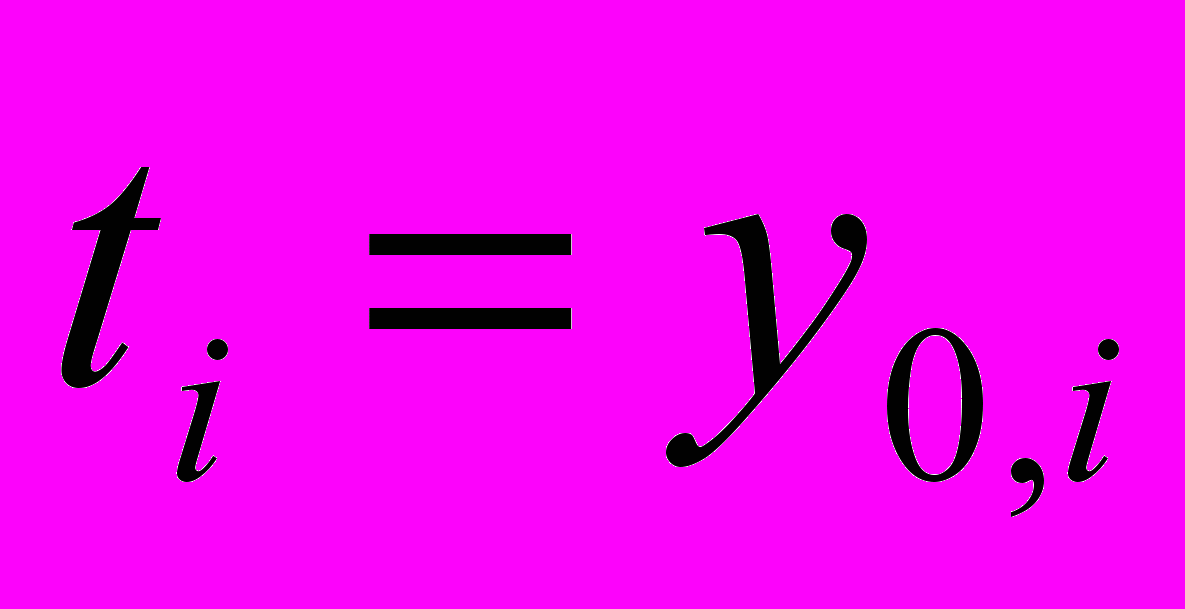 .
.Затем корректируются веса:
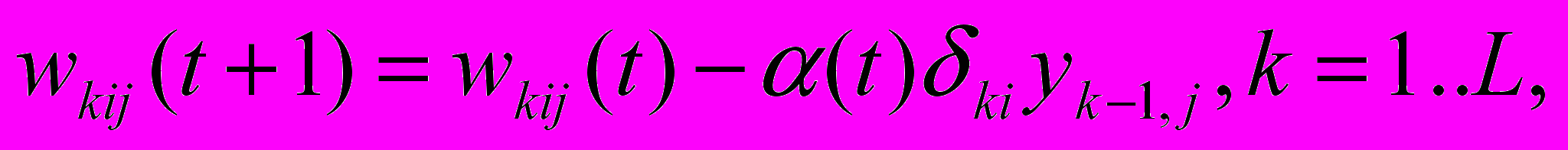
где
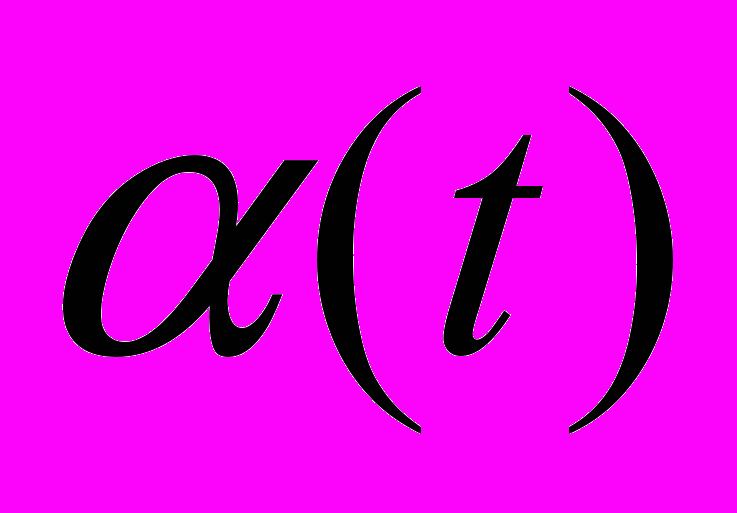 – скорость (шаг) обучения, t – номер обучающего цикла. Для классического обратного распространения скорость фиксирована. Существуют так же эвристические подходы, в которых скорость изменяется от большой вначале до маленькой в конце обучения [1].
– скорость (шаг) обучения, t – номер обучающего цикла. Для классического обратного распространения скорость фиксирована. Существуют так же эвристические подходы, в которых скорость изменяется от большой вначале до маленькой в конце обучения [1].Многослойный персептрон, используемый для распознавания лиц, как правило, содержит в последнем слое столько нейронов, сколько существует классов и настраивается на получения на выходе этих нейронов значения 1(или 0,9) для верного класса и -1(-0,9 соответственно) для неверного. Результаты, показываемые данным алгоритмом, можно назвать удовлетворительными, сеть достаточно быстро обучается и производит распознавание с удовлетворительной точностью.

Рис.2.5 Пример удачного распознавания.
Однако имеются и существенные недостатки. В первую очередь это неустойчивость к повороту головы и местоположению лица на изображении. Главной причиной этих ошибок является то, что простой персептрон слабо учитывает двумерный характер расположения пикселей изображения (изображение рассматривается как вектор). Немаловажным недостатком является и «скрытость» работы алгоритма, что приводит к сложности анализа тестов для улучшения эффективности.
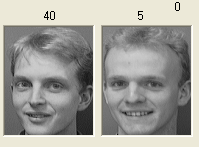
Рис.2.6. Пример неудачного распознавания.
2.3.3 Свёрточные нейронные сети.
Анализирую работу многослойной нейронной сети, можно заметить, что для обучающей выборки значения выходов второго нейронного слоя после обучения становятся очень близки к эталонным. Таким образорм, можно говорить, что многослойный персептрон справляется с задачей разбиения пространства признаков на области. Однако, несмотря на это, точность распознвания для тестовой выборки остаётся неидеальной. Следовательно, можно сделать вывод, что проблема лежит не в области сравнения изображений на основе признаков, а в алгоритме для выделения этих признаков.
Главные архитектурные отличия когнитрона заключаются в том, что каждый нейрон связан только с небольшой локальной областью предыдущего слоя, и такие области перекрываются друг с другом. Слоёв в когнитроне обычно больше чем в сетях других типов. Таким образом достигается иерархическая организация, когда на высших слоях когнитрон реагирует на более абстрактные образы, меньше реагирует на их смещение и искажение.
Обучается когнитрон конкурентным обучением (без учителя).
Неокогнитрон [2] является дальнейшим развитием идеи когнитрона и более точно отражает строение зрительной системы, позволяет распознавать образы независимо от их преобразований: смещения, вращения, изменения масштаба и искажения. Неокогнитрон может как самообучаться, так и обучаться с учителем. Неокогнитрон получает на входе двумерные образы, аналогичные изображениям на сетчатой оболочке глаза, и обрабатывает их в последующих слоях аналогично тому, как это было обнаружено в зрительной коре человека.
Упрощённым вариантом этих методом являются свёрточные нейронные сети (Convolutional Neural Network), которая по своей структуре обеспечивает частичную устойчивость распознавания к изменению освещённости, масштаба, ракурса.
Алгоритм, использованный в качестве базового в данной работе, был создан на основе работы [3]. Свёрточная НС состоит из многих слоёв 2 базовых видов - свёрточного и подвыборочного – которые чередуются.
В каждом слое имеется набор из нескольких плоскостей, причём нейроны одной плоскости имеют одинаковые веса, ведущие ко всем локальным участкам предыдущего слоя (как в зрительной коре человека), изображение предыдущего слоя как бы сканируется небольшим окном и пропускается сквозь набор весов, а результат отображается на соответствующий нейрон текущего слоя. Таким образом, набор плоскостей представляет собой «карты черт» (feature maps) и каждая плоскость находит «свои» участки изображения в любом месте предыдущего слоя.
Подвыборочные слои уменьшают масштаб изображения при помощи локального усреднения значений. Благодаря этому образуется иерархическая организация, т.е последующие слои извлекают из изображения более общие характеристики.
Тестовая реализация данного алгоритма показала достаточно высокую точность распознавания. Алгоритм устойчиво работает в случае небольших изменений ракурса и положения и практически не нуждается в предобработке.
Дополнительным преимуществом данного метода является то, что значения, получаемые на промежуточных слоях, можно интерпретировать в виде реальных объектов, то есть наблюдается некоторое “понимание” нейронной сетью изображения, а следовательно возможен подробный анализ полученных результатов с целью улучшения алгоритма.
2.4. Постановка задачи.
Таким образом, нам необходимо разработать алгоритм, решающий следующую задачу.
Дано множество портретных изображений для группы людей. При этом для каждого человека кол-во изображений достаточное (не менее 5). Необходимо разработать алгоритм на основе свёрточной нейронной сети, относящий новое изображение к одному из классов (либо к классу неизвестных), инвариантный к изменению освещения, изменениям ракурса, помехам, и имеющий хорошую точность.
На основе этого алгоритма необходимо создать систему для идентификации человека по изображению его лица. Система, построенная на основе алгоритма, должна обладать хорошей скоростью распознавания, приемлемой скоростью обучения, возможностью дообучения на новой выборке.
В качестве основной базы данных для проведения экпериментов и тестирования была выбрана база ORL. Она содержит 400 изображений 40 человек (по 10 изображений каждого). Изображения содержат небольшие изменения ракурса, масштаба и освещения. База FERET также была использована в тестировании при изучении более сложных условий для распознавания.