
Лекция (4 учебных часа – 2 ч 40 мин) Концепции распределенной обработки в сетевых ос
| Вид материала | Лекция |
- Лекция 2 Технические средства поддержки систем обработки документов. Обработка распределенной, 185.55kb.
- Лекция (4 учебных часа – 2 ч 40 мин) Сетевая безопасность, 592.19kb.
- Базовый курс Лекция Основы биржевой торговли (2 часа 15 мин), 93.69kb.
- Технические особенности сетевых сообществ и их педагогические следствия, 124.33kb.
- Темы выпускных квалификационных работ по специальности 230103 «Автоматизированные системы, 99.21kb.
- Утверждаю, 1939.25kb.
- Пояснительная записка Основной задачей курса является подготовка учащихся на уровне, 1645.04kb.
- Архитектура аппаратно-программных средств распределенной обработки информации для интернет-технологии, 185.61kb.
- Концептуальное проектирование и описание распределенной автоматизированной системы, 436.65kb.
- Программа 30 мин. (7-8 номеров) 3300 у е. Программа 40 мин. (10 номеров) 3500, 171.41kb.
Лекция 7. (4 учебных часа – 2 ч 40 мин)
Концепции распределенной обработки в сетевых ОС
7.1. Введение
Объединение компьютеров в сеть предоставляет возможность программам, работающим на отдельных компьютерах, оперативно взаимодействовать и сообща решать задачи пользователей. Связь между некоторыми программами может быть настолько тесной, что их удобно рассматривать в качестве частей одного приложения, которое называют в этом случае распределенным, или сетевым. Распределенные приложения обладают рядом потенциальных преимуществ по сравнению с локальными. Среди этих преимуществ — более высокая производительность, отказоустойчивость, масштабируемость и приближение к пользователю.
7.2. Модели сетевых служб и распределенных приложений
Значительная часть приложений, работающих в компьютерах сети, являются сетевыми, но, конечно, не все. Действительно, ничто не мешает пользователю запустить на своем компьютере полностью локальное приложение, не использующее имеющиеся сетевые коммуникационные возможности. Достаточно типичным является сетевое приложение, состоящее из двух частей. Например, одна часть приложения работает на компьютере, хранящем базу данных большого объема, а вторая — на компьютере пользователя, который хочет видеть на экране некоторые статистические характеристики данных, хранящихся в базе. Первая часть приложения выполняет поиск в базе записей, отвечающих определенным критериям, а вторая занимается статистической обработкой этих данных, представлением их в графической форме на экране, а также поддерживает диалог с пользователем, принимая от него новые запросы на вычисление тех или иных статистических характеристик. Можно представить себе случаи, когда приложение распределено и между большим числом компьютеров. Распределенным в сетях может быть не только прикладное, но и системное программное обеспечение — компоненты операционных систем. Как и в случае локальных служб, программы, которые выполняют некоторые общие и часто встречающиеся в распределенных системах функции, обычно становятся частями операционных систем и называются сетевыми службами.
Целесообразно выделить три основных параметра организации работы приложений в сети. К ним относятся:
- способ разделения приложения на части, выполняющиеся на разных компьютерах сети;
- выделение специализированных серверов в сети, на которых выполняются некоторые общие для всех приложений функции;
- способ взаимодействия между частями приложений, работающих на разных компьютерах.
7.3. Способ разделения приложений на части
Очевидно, что можно предложить различные схемы разделения приложений на части, причем для каждого конкретного приложения можно предложить свою схему. Существуют и типовые модели распределенных приложений. В следующей достаточно детальной модели предлагается разделить приложение на шесть функциональных частей:
- средства представления данных на экране, например средства графического пользовательского интерфейса;
- логика представления данных на экране описывает правила и возможные сценарии взаимодействия пользователя с приложением: выбор из системы меню, выбор элемента из списка и т. п.;
- прикладная логика — набор правил для принятия решений, вычислительные процедуры и операции;
- логика данных — операции с данными, хранящимися в некоторой базе, которые нужно выполнить для реализации прикладной логики;
- внутренние операции базы данных — действия СУБД, вызываемые в ответ на выполнение запросов логики данных, такие как поиск записи по определенным признакам;
- файловые операции — стандартные операции над файлами и файловой системой, которые обычно являются функциями операционной системы.
На основе этой модели можно построить несколько схем распределения частей приложения между компьютерами сети.
7.3.1. Двухзвенные схемы
Распределение приложения между большим числом компьютеров может повысить качество его выполнения (скорость, количество одновременно обслуживаемых пользователей и т. д.), но при этом существенно усложняется организация самого приложения, что может просто не позволить воспользоваться потенциальными преимуществами распределенной обработки. Поэтому на практике приложение обычно разделяют на две или три части и достаточно редко — на большее число частей. Наиболее распространенной является двухзвенная схема, распределяющая приложение между двумя компьютерами. Перечисленные выше типовые функциональные части приложения можно разделить между двумя компьютерами различными способами.
Рассмотрим сначала два крайних случая двухзвенной схемы, когда нагрузка в основном ложится на один узел — либо на центральный компьютер, либо на клиентскую машину.
В централизованной схеме (рис. 7.1, а) компьютер пользователя работает как терминал, выполняющий лишь функции представления данных, тогда как все остальные функции передаются центральному компьютеру. Ресурсы компьютера пользователя используются в этой схеме в незначительной степени, загруженными оказываются только графические средства подсистемы ввода-вывода ОС, отображающие на экране окна и другие графические примитивы по командам центрального компьютера, а также сетевые средства ОС, принимающие из сети команды центрального компьютера и возвращающие данные о нажатии клавиш и координатах мыши. Программа, работающая на компьютере пользователя, часто называется эмулятором терминала — графическим или текстовым, в зависимости от поддерживаемого режима. Фактически эта схема повторяет организацию многотерминальной системы на базе мэйнфрейма с тем лишь отличием, что вместо терминалов используются компьютеры, подключенные не через локальный интерфейс, а через сеть, локальную или глобальную.
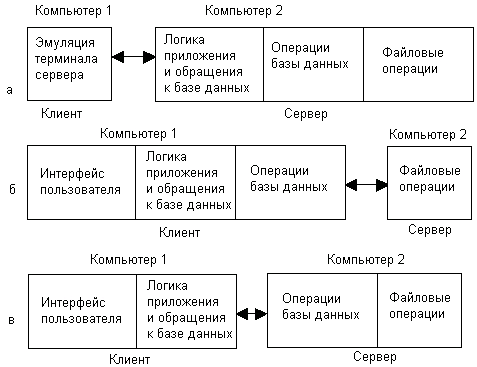
Рис. 7.1. Варианты распределений частей приложения по двухзвенной схеме
Главным и очень серьезным недостатком централизованной схемы является ее недостаточная масштабируемость и отсутствие отказоустойчивости. Производительность центрального компьютера всегда будет ограничителем количества пользователей, работающих с данным приложением, а отказ центрального компьютера приводит к прекращению работы всех пользователей. Именно из-за этих недостатков централизованные вычислительные системы, представленные мэйнфреймами, уступили место сетям, состоящим из мини-компьютеров, RISC-серверов и персональных компьютеров. Тем не менее централизованная схема иногда применяется как из-за простоты организации программы, которая почти целиком работает на одном компьютере, так и из-за наличия большого парка не распределенных приложений.
В схеме «файловый сервер» (рис. 7.1, б) на клиентской машине выполняются все части приложения, кроме файловых операций. В сети имеется достаточно мощный компьютер, имеющий дисковую подсистему большого объема, который хранит файлы, доступ к которым необходим большому числу пользователей. Этот компьютер играет роль файлового сервера, представляя собой централизованное хранилище данных, находящихся в разделяемом доступе. Распределенное приложение в этой схеме мало отличается от полностью локального приложения. Единственным отличием является обращение к удаленным файлам вместо локальных. Для того чтобы в этой схеме можно было использовать локальные приложения, в сетевые операционные системы ввели такой компонент сетевой файловой службы, как редиректор, который перехватывает обращения к удаленным файлам (с помощью специальной нотации для сетевых имен, такой, например, как //server"!/doc/file1.txt) и направляет запросы в сеть, освобождая приложение от необходимости явно задействовать сетевые системные вызовы.
Файловый сервер представляет собой компонент наиболее популярной сетевой службы — сетевой файловой системы, которая лежит в основе многих распределенных приложений и некоторых других сетевых служб. Первые сетевые ОС (NetWare компании Novell, IBM PC LAN Program, Microsoft MS-Net) обычно поддерживали две сетевые службы — файловую службу и службу печати, оставляя реализацию остальных функций разработчикам распределенных приложений.
Такая схема обладает хорошей масштабируемостью, так как дополнительные пользователи и приложения добавляют лишь незначительную нагрузку на центральный узел — файловый сервер. Однако эта архитектура имеет и свои недостатки:
- во многих случаях резко возрастает сетевая нагрузка (например, многочисленные запросы к базе данных могут приводить к загрузке всей базы данных в клиентскую машину для последующего локального поиска нужных записей), что приводит к увеличению времени реакции приложения;
- компьютер клиента должен обладать высокой вычислительной мощностью, чтобы справляться с представлением данных, логикой приложения, логикой данных и поддержкой операций базы данных.
Другие варианты двухзвенной модели более равномерно распределяют функции между клиентской и серверной частями системы. Наиболее часто используется схема, в которой на серверный компьютер возлагаются функции проведения внутренних операций базы данных и файловых операций (рис. 7.1, в). Клиентский компьютер при этом выполняет все функции, специфические для данного приложения, а сервер — функции, реализация которых не зависит от специфики приложения, из-за чего эти функции могут быть оформлены в виде сетевых служб. Поскольку функции управления базами данных нужны далеко не всем приложениям, то в отличие от файловой системы они чаще всего не реализуются в виде службы сетевой ОС, а являются независимой распределенной прикладной системой. Система управления базами данных (СУБД) является одним из наиболее часто применяемых в сетях распределенных приложений. Не все СУБД являются распределенными, но практически все мощные СУБД, позволяющие поддерживать большое число сетевых пользователей, построены в соответствии с описанной моделью клиент-сервер. Сам термин «клиент-сервер» справедлив для любой двухзвенной схемы распределения функций, но исторически он оказался наиболее тесно связанным со схемой, в которой сервер выполняет функции по управлению базами данных (и, конечно, файлами, в которых хранятся эти базы) и часто используется как синоним этой схемы.
7.3.2. Трехзвенные схемы
Трехзвенная архитектура позволяет еще лучше сбалансировать нагрузку на различные компьютеры в сети, а также способствует дальнейшей специализации серверов и средств разработки распределенных приложений. Примером трехзвенной архитектуры может служить такая организация приложения, при которой на клиентской машине выполняются средства представления и логика представления, а также поддерживается программный интерфейс для вызова частей приложения второго звена — промежуточного сервера (рис. 7.2).
Промежуточный сервер называют в этом варианте сервером приложений, так как на нем выполняются прикладная логика и логика обработки данных, представляющих собой наиболее специфические и важные части большинства приложений. Слой логики обработки данных вызывает внутренние операции базы данных, которые реализуются третьим звеном схемы — сервером баз данных.
С
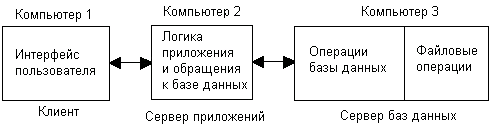
ервер баз данных, как и в двухзвенной модели, выполняет функции двух последних слоев — операции внутри базы данных и файловые операции. Примером такой схемы может служить неоднородная архитектура, включающая клиентские компьютеры под управлением Windows 95/98, сервер приложений с монитором транзакций TUXEDO в среде Solaris на компьютере компании Sun Microsystems и сервер баз данных Oracle в среде Windows 2000 на компьютере компании Compaq.
Рис. 7.2. Трехзвенная схема распределения частей приложения
Централизованная реализация логики приложения решает проблему недостаточной вычислительной мощности клиентских компьютеров для сложных приложений, а также упрощает администрирование и сопровождение. В том случае когда сервер приложений сам становится узким местом, в сети можно применить несколько серверов приложений, распределив каким-то образом запросы пользователей между ними. Упрощается и разработка крупных приложений, так как в этом случае четко разделяются платформы и инструменты для реализации интерфейса и прикладной логики, что позволяет с наибольшей эффективностью реализовывать их силами специалистов узкого профиля.
Монитор транзакций представляет собой популярный пример программного обеспечения, не входящего в состав сетевой ОС, но выполняющего функции, полезные для большого количества приложений. Такой монитор управляет транзакциями с базой данных и поддерживает целостность распределенной базы данных.
Трехзвенные схемы часто применяются для централизованной реализации в сети некоторых общих для распределенных приложений функций, отличных от файлового сервиса и управления базами данных. Программные модули, выполняющие такие функции, относят к классу middleware — то есть промежуточному слою, располагающемуся между индивидуальной для каждого приложения логикой и сервером баз данных.
В крупных сетях для связи клиентских и серверных частей приложений также используется и ряд других средств, относящихся к классу middleware, в том числе:
- средства асинхронной обработки сообщений (message-oriented middleware, MOM);
- средства удаленного вызова процедур (Remote Procedure Call, RFC);
- брокеры запроса объектов (Object Request Broker, ORB), которые находят объекты, хранящиеся на различных компьютерах, и помогают их использовать в одном приложении или документе.
Эти средства помогают улучшить качество взаимодействия клиентов с серверами за счет промышленной реализации достаточно важных и сложных функций, а также упорядочить поток запросов от множества клиентов к множеству серверов, играя роль регулировщика, распределяющего нагрузку на серверы.
Сервер приложений должен базироваться на мощной аппаратной платформе (мультипроцессорные системы, специализированные кластерные архитектуры). ОС сервера приложений должна обеспечивать высокую производительность вычислений, а значит, поддерживать многопоточную обработку, вытесняющую многозадачность, мультипроцессирование, виртуальную память и наиболее популярные прикладные среды.
7.4. Механизм передачи сообщений в распределенных системах
Единственным по-настоящему важным отличием распределенных систем от централизованных является способ взаимодействия между процессами. Принципиально межпроцессное взаимодействие может осуществляться одним из двух способов:
- с помощью совместного использования одних и тех же данных (разделяемая память);
- путем передачи друг другу данных в виде сообщений.
В централизованных системах связь между процессами, как правило, предполагает наличие разделяемой памяти. Типичный пример — задача «поставщик-потребитель». В этом случае один процесс пишет в разделяемый буфер, а другой читает из него. Даже наиболее простая форма синхронизации — семафор — требует, чтобы хотя бы одно слово (переменная самого семафора) было разделяемым. Аналогичным образом происходит взаимодействие не только между пользовательскими процессами, но и между приложением и операционной системой — процесс в пользовательском режиме запрашивает у ОС выполнения некоторой операции с помощью системного вызова, помещая в доступную ему часть оперативной памяти параметры этого системного вызова (например, имя файла, смещение от его начала и количество байт, которые необходимо прочитать). После этого модуль ядра ОС считывает эти параметры из пользовательской памяти (ядру в привилегированном режиме доступна вся память, как ее системная часть, так и пользовательская) и выполняет системный вызов. Взаимодействие и в этом случае происходит за счет непосредственно доступной обоим участникам области памяти.
В распределенных системах не существует памяти, непосредственно доступной процессам, работающим на разных компьютерах, поэтому взаимодействие процессов (как находящихся в пользовательской фазе, так и в системной, то есть выполняющих код операционной системы) может осуществляться только путем передачи сообщений через сеть. Как было показано в разделе «Сетевые службы и сетевые сервисы» главы 2 «Назначение и функции операционной системы», на основе механизма передачи сообщений работают все сетевые службы, предоставляющие пользователям сети разнообразные услуги — доступ к удаленным файлам, принтерам, почтовым ящикам и т. п. В сообщениях переносятся запросы от клиентов некоторой службы к соответствующим серверам — например, запрос на просмотр содержимого определенного каталога файловой системы, расположенной на сетевом сервере. Сервер возвращает ответ — набор имен файлов и подкаталогов, входящих в данный каталог, также помещая его в сообщение и отправляя его по сети клиенту.
Сообщение — это блок информации, отформатированный процессом-отправителем таким образом, чтобы он был понятен процессу-получателю. Сообщение состоит из заголовка, обычно фиксированной длины, и набора данных определенного типа переменной длины. В заголовке, как правило, содержатся следующие элементы.
- Адрес — набор символов, уникально определяющих отправляющий и получающий процессы. Адресное поле, таким образом, состоит из двух частей — адреса процесса-отправителя и адреса процесса-получателя. Адрес каждого процесса может, в свою очередь, иметь некоторую структуру, позволяющую найти нужный процесс в сети, состоящей из большого количества компьютеров.
- Последовательный номер, являющийся идентификатором сообщения. Используется для идентификации потерянных сообщений и дубликатов сообщений в случае отказов в сети.
- Структурированная информация, состоящая в общем случае из нескольких частей: поля типа данных, поля длины данных и поля значения данных (то есть собственно данных). Поле типа данных определяет, например, что данные являются целым числом или же представляют собой строку символов (это поле может также содержать признак нерезидентности данных, то есть указатель на данные, которые хранятся где-то вне данного сообщения). Второе поле определяет длину передаваемых в сообщении данных (обычно в байтах), то есть размер следующего поля сообщения. Сообщение может включать несколько элементов, состоящих из описанных трех полей. В тех случаях, когда сообщение всегда переносит данные одного и того же типа, поле типа может быть опущено. То же касается поля длины данных — для тех типов сообщений, которые переносят данные фиксированного формата, но такая ситуация характерна только для протоколов низкого уровня (например, ATM, имеющего фиксированный размер поля данных в 48 байт).
В любой сетевой ОС имеется подсистема передачи сообщений, называемая также транспортной подсистемой, которая обеспечивает набор средств для организации взаимодействия процессов по сети. Назначение этой системы — экранировать детали сложных сетевых протоколов от программиста. Подсистема позволяет процессам взаимодействовать посредством достаточно простых примитивов. В самом простом случае системные средства обеспечения связи могут быть сведены к двум основным коммуникационным примитивам, один send (отправить) — для посылки сообщения, другой recei ve (получить) — для получения сообщения. В дальнейшем на их базе могут быть построены более мощные средства сетевых коммуникаций, такие как распределенная файловая система или служба вызова удаленных процедур, которые, в свою очередь, также могут служить основой для работы других сетевых служб.
Транспортная подсистема сетевой ОС имеет обычно сложную структуру, отражающую структуру семиуровневой модели взаимодействия открытых систем (Open System Interconnection, OSI)1. Представление сложной задачи сетевого взаимодействия компьютеров в виде иерархии нескольких частных задач позволяет организовать это взаимодействие максимально гибким образом. В то же время каждый уровень модели OSI экранирует особенности лежащих под ним уровней от вышележащих уровней, что делает средства взаимодействия компьютеров все более универсальными по мере продвижения вверх по уровням. Таким образом, в процесс выполнения примитивов send и receive вовлекаются средства всех нижележащих коммуникационных протоколов (рис. 7.3).
Более подробно с моделью OSI и функциями ее уровней можно ознакомится в приложении. Структура сетевых средств ОС обсуждалась также в разделе «Многослойная модель, подсистемы ввода-вывода» главы 7 «Ввод-вывод и файловая система».
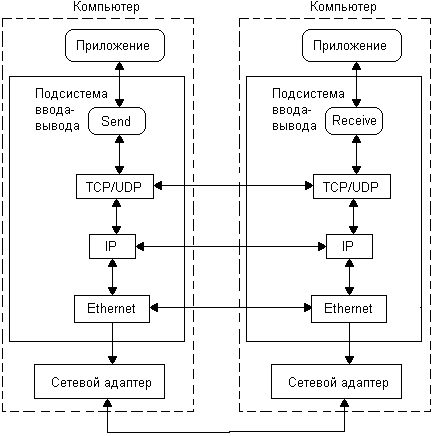
Рис. 7.3. Примитивы обмена сообщениями и транспортные средства подсистемы ввода-вывода
Несмотря на концептуальную простоту примитивов send и receive, существуют различные варианты их реализации, от правильного выбора которых зависит эффективность работы сети. В частности, эффективность зависит от способа задания адреса получателя. Не менее важны при реализации примитивов передачи сообщений ответы и на другие вопросы. В сети всегда имеется один получатель или их может быть несколько? Требуется ли гарантированная доставка сообщений? Должен ли отправитель дождаться ответа на свое сообщение, прежде чем продолжать свою работу? Как отправитель, получатель и подсистема передачи сообщений должны реагировать на отказы узла или коммуникационного канала во время взаимодействия? Что нужно делать, если приемник не готов принять сообщение, нужно ли отбрасывать сообщение или сохранять его в буфере? А если сохранять, то как быть, если буфер уже заполнен? Разрешено ли приемнику изменять порядок обработки сообщений в соответствии с их важностью? Ответы на подобные вопросы составляют семантику конкретного протокола передачи сообщений.
7.5. Синхронизация
Центральным вопросом взаимодействия процессов в сети является способ их синхронизации, который полностью определяется используемыми в операционной системе коммуникационными примитивами. В этом отношении коммуникационные примитивы делятся на блокирующие (синхронные) и неблокирующие (асинхронные), причем смысл данных терминов в целом соответствует смыслу аналогичных терминов, применяемых при описании системных вызовов (см. подраздел «Системные вызовы» раздела «Мультипрограммирование на основе прерываний» в главе 4 «Процессы и потоки») и операций ввода-вывода (см. подраздел «Поддержка синхронных и асинхронных операций ввода-вывода» раздела «Задачи ОС по управлению файлами и устройствами» в главе 7 «Ввод-вывод и файловая система»). В отличие от локальных системных вызовов (а именно такие системные вызовы были рассмотрены в главах 4 и 7) при выполнении коммуникационных примитивов завершение запрошенной операции в общем случае зависит не только от некоторой работы локальной ОС, но и от работы удаленной ОС.
Коммуникационные примитивы могут быть оформлены в операционной системе двумя способами: как внутренние процедуры ядра ОС (в этом случае ими могут использоваться только модули ОС) или как системные вызовы (доступные в этом случае процессам в пользовательском режиме).
При использовании блокирующего примитива send процесс, выдавший запрос на его выполнение, приостанавливается до момента получения по сети сообщения-подтверждения о том, что приемник получил отправленное сообщение. А вызов блокирующего примитива receive приостанавливает вызывающий процесс до момента, когда он получит сообщение. При использовании неблокирующих примитивов send и receive управление возвращается вызывающему процессу немедленно, сразу после того, как ядру передается информация о том, где в памяти находится буфер, в который нужно поместить сообщение, отправляемое в сеть или ожидаемое из сети. Преимуществом этой схемы является параллельное выполнение вызывающего процесса и процедур передачи сообщения (не обязательно работающих в контексте вызвавшего соответствующий примитив процесса).
Важным вопросом при использовании неблокирующего примитива receive является выбор способа уведомления процесса-получателя о том, что сообщение пришло и помещено в буфер. Обычно для этой цели требуется один из двух способов.
- Опрос (polling). Этот метод предусматривает наличие еще одного базового примитива test (проверить), с помощью которого процесс-получатель может анализировать состояние буфера.
- Прерывание (interrupt). Этот метод использует программное прерывание для уведомления процесса-получателя о том, что сообщение помещено в буфер. Хотя такой метод и очень эффективен (он исключает многократные проверки состояния буфера), у него имеется существенный недостаток — усложненное программирование, связанное с прерываниями пользовательского уровня, то есть прерываниями, по которым вызываются процедуры пользовательского режима (например, вызов процедур АРС в ОС Windows NT по завершении операции ввода-вывода, рассмотренный в главе 8 «Дополнительные возможности файловых систем»).
П
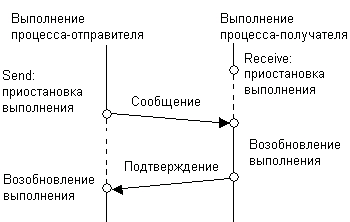
ри использовании блокирующего примитива send может возникнуть ситуация, когда процесс-отправитель блокируется навсегда. Например, если процесс получатель потерпел крах или же отправленное сообщение было утеряно из-за сетевой ошибки. Чтобы предотвратить такую ситуацию, блокирующий примитив send часто использует механизм тайм-аута. То есть определяется интервал времени, после которого операция send завершается со статусом «ошибка». Механизм тайм-аута может использоваться также блокирующим примитивом receive для предотвращения блокировки процесса-получателя на неопределенное время, когда процесс-отправитель потерпел крах или сообщение было потеряно вследствие сетевой ошибки. Если при взаимодействии двух процессов оба примитива — send и receive — являются блокирующими, говорят, что процессы взаимодействуют по сети синхронно (рис. 7.4), в противном случае взаимодействие считается асинхронным (рис. 7.5).
Рис. 7.4. Синхронное взаимодействие с помощью блокирующих примитивов send и receive
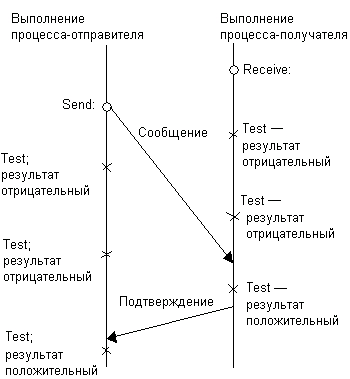
Рис. 7.5. Асинхронное взаимодействие с помощью неблокирующих примитивов send и receive
По сравнению с асинхронным взаимодействием синхронное является более простым, его легко реализовать. Оно также более надежно, так как гарантирует процессу-отправителю, возобновившему свое выполнение, что его сообщение было получено. Главный же недостаток — ограниченный параллелизм и возможность возникновения клинчей.
Обычно в ОС имеется один из двух видов примитивов, но ОС является более гибкой, если поддерживает как блокирующие, так и неблокирующие примитивы.