
Як навчити машини перекладати
| Вид материала | Документы |
- Тема: машини та механізми, їх роль у житті людини, 380.72kb.
- «Піраміда мудрості», 190.06kb.
- Онання лабораторної роботи для студентів спеціальності „Колісні та гусеничні транспортні, 13.12kb.
- Програма вступного іспиту з фаху на спеціальність 090214 "Підйомно-транспортні, будівельні,, 94.34kb.
- Вказівки до виконання лабораторних робіт для студентів спеціальності 090215 "Машини, 994.18kb.
- Вступ, 223.17kb.
- На навчання за наступними напрямками підготовки, 88.79kb.
- Психологічне кредо, 235.01kb.
- Методичні рекомендації з фізичного виховання для студентів спеціальної медичної групи, 31.01kb.
- 3. Гігієна праці Технологічні процеси, обладнання, машини, робочий інструмент, 359.83kb.
Як навчити машини перекладати
Валерій ЛИСЕНКО
Скорочений варіант опубліковано у журналі “Друкарство” № 6 (59) листопад-грудень 2004, стор. 19-23.
Ілюстрації: художник Daniel Mroz, з сайту lem.mcs.net.pl за книгою: Stanislaw Lem. Bajki robotow. Wydawnictwo Literackie. Krakow 1978.
Сокровенна загадка людської мови лишається найпривабливішою вершиною для дослідників. Зосередимось на досягненнях і перспективах прикладного текстознавства, зокрема на актуальній темі машинного перекладу
Професор Костянтин Тищенко, творець Лінгвістичного музею при філологічному факультеті Київського національного університету імені Тараса Шевченка демонструє в українській мові древні нашарування майже 20 різних культур. Отже, вітчизняне мистецтво перекладу має надзвичайно багаті традиції. Але сучасна доба великих потрясінь спричиняє значні мовні новації. Виникли нові сфери діяльності, наприклад, юридичний переклад. Особливо швидко оновлюється науково-технічна термінологія. Наприклад, в автомобільній справі “новояз” складає до половини всіх професійних термінів, а у комп’ютерній галузі ще більше. Попит спонукає до пошуку нетрадиційних технологій підготовки довідкових видань. І саме формат комп'ютерного словника дозволяє оперативніше відгукуватись на виклики часу..
Чому варто навчати машини
Важко повірити, що колись звичайні для нас годинники були зайвою розкішшю. Так само, до середини ХХ століття авторитетні експерти вважали створення інформаційної техніки непрактичною морокою. Математики й філологи були приблизно в однаковому становищі: єдиним способом виконання об’ємних складних робіт було їх замовлення у спеціалізованих бюро, де працювали висококваліфіковані фахівці, практично вручну, користуючись довідниками, за допомогою механічних, пізніше – електромеханічних пристроїв.
З

а минулі 50 років ситуація з математикою радикально змінилась. Розв’язання величезної більшості популярних математичних задач нині втілене у зручні програмно-технічні засоби, якими може скористатись будь-який неледачий студент. Те саме сталось з безліччю інших інтернаціональних ремесел; в деякій мірі комп’ютеризовано уміння малювати й компонувати музику, діловодство і бухгалтерія. Не всім це подобається, але процес незворотний.
Мовознавство виявилась значно міцнішим горішком. До початку робіт з прикладної лінгвістики розуміння всіх мов спиралось в основному на людську ерудицію і здогадливість. Ряд фахівців і дотепер не квапиться оприлюднювати тонкощі своєї роботи, побоюючись втратити монополію на істину.
Звісно, людський стиль перекладу неможливо відтворити через створення мовних машин. Проте, з іншого боку, кожен професійний перекладач може згадати тексти, опрацьовані з різним ступенем розуміння, включаючи випадки повністю формального механічного дослівного транслювання, знявши з себе будь-яку відповідальність за зміст. Системи машинного перекладу (СМП) є такими самими інструментами, як олівці, словники чи друкарські машинки, які самі по собі також не перекладають. Та якщо паперові словники давно вичерпали можливості вдосконалення, і потребують лиш систематичного оновлення, то очевидна недосконалість сучасних лінгвістичних систем є стимулом до їх подальшого розвитку і ускладнення. Автоматизація найефективніша у тих галузях, де постійно відбувається обмін даними з усталеною, не надто різноманітною термінологією, як-от міжнародні метеорологічні, чи епідеміологічні організації. Відповідно, найбільше проблем виникає коли лексика неформалізована і швидкоплинна.
Мовознавчі установи здавна послугувались для великих лінгвістичних каталогів різними засобами оргтехніки, починаючи з найпростіших картотек. Але жодна спроба мовної автоматизації не мала шансів на практичний успіх до створення потужної інформатики. Перешкодами на шляху машинних технологій були:
- неформалізованість класичного мовознавства;
- нерозвиненість ринку лінгвістичних послуг;
- менша інтернаціональність мовознавства порівняно з іншими науками;
- порівняно великі обсяги оброблюваних даних, які потребують значних швидкодії та пам’яті;
- слабкість теорії та практики щодо взаємодії інформаційної техніки з людиною, відсутність відповідних традицій та стандартів.
З 1920-х років велися дослідження семіотики тексту, що поєднували видатних учених, серед яких математик Володимир Успенський і лінгвіст В'ячеслав Іванов. Успіхи формального підходу до мови продемонстрували можливість перетворення гуманітарної науки в логічно строгу дисципліну. Проте широкомасштабне вивчення семіотики в усьому світі розпочалось на початку 1960-х років, значною мірою завдяки роботам творця структурної лінгвістики Романа Якобсона, що емігрував з Росії у 1920 році.
Витоки
Один з перших проектів системи машинного перекладу належав провіснику інформаційного суспільства, британському винахіднику Чарльзу Беббіджу (1791-1871). Наприкінці ХІХ ст. у США були винайдені фонограф, телефон і почала розвиватись обчислювальна техніка. У 30-ті роки в Європі було створено системи телебачення і радіолокації, де засвітились перші електронно-променеві трубки. Згодом розвиток і творче поєднання всіх цих винаходів лягли у підвалини сучасних мультимедійних лінгвістичних технологій.
Близько 1918-го року в Німеччині було винайдено механічну шифрувальну машину під назвою ENIGMA (головоломка, загадка). В роки Другої Світової війни британська розвідка, викравши таку машину, в співпраці з математиками та лінгвістами, навчилась читати німецькі шифри.
Офіційно машинний переклад з російської на англійську мову було презентовано у січні 1954 року, в Джорджтаунському університеті (США). В часи Холодної війни потреба “підігрівалась” великими обсягами розвідданних, а з розвоєм всесвітньої інформаційної мережі – її моніторингом всілякими наглядовими та розвідувальними службами. Схоже, що саме на це спрямовано величезні обчислювальні потужності кращих сучасних суперкомп’ютерів.
Перші малопотужні системи машинного перекладу, по суті – автоматизовані словники, опрацьовували слово за словом, не враховуючи їх взаємозв’язків. Забезпечувалось всього лиш швидке одержання “підрядника”. Він потребував дуже серйозного послідуючого ручного редагування, і не дозволяв обійтись без звернень до тексту оригіналу. Згодом було розроблено системи другого покоління, які аналізували синтаксичну структуру, перетворювали її у відповідну структуру мови результату, і вже в цей “каркас” підставляли перекладені слова.
Ще складніші СМП формують проміжну структуру повідомлення, незалежну від конкретної мови. Їх функціонування намагались пов’язати з розумінням смислу, актуальним не лише для перекладу, а і для підслуховування чужих розмов та підглядання в чужі листи.
Наприкінці 60-х років американські розробники пережили кризу усвідомлення величезних труднощів дальшого поступу. Нова хвиля настала у 70-ті роки, коли інформаційна техніка нарешті почала “обростати” зручними для користувачів пристроями і методами взаємодії. Дисплеї зробили комп’ютери доступнішими, і СМП стали орієнтуватись не на автономну роботу, а на обслуговування автоматизованих робочих місць (АРМ) фахівців-перекладачів. З тих часів почалось широке впровадження машинних технологій у документообіг. За 15-ліття з 1978 по 1993 роки в США на дослідження в галузі МП витрачено 20 мільйонів доларів, в Європі — 70 мільйонів, в Японії — 200 мільйонів.
У дискусіях теоретиків і розробників питання було поставлено руба: чи може машина розмовляти по-людському? Тобто: чи можливо створити програму, здатну до спілкування? В 1970-ті роки було досягнуто помітних успіхів у машинній імітації діалогу: з’явились програми, що підтримували “бесіду” без наперед визначеної тематики.
У 80-і роки утворився ряд компаній, що займались розробкою і продажем СМП та природно-мовних інтерфейсів з довідковими базами даних і автоматизованими експертними системами. Японські дослідження з комп'ютерної лінгвістики концентрувались навколо загальнонаціональної програми створення комп'ютерів п'ятого покоління, оголошеної 1981-го року. У Європі роботи зі створення комп'ютерних систем перекладу стимулювалися утворенням Європейської Інформаційної Мережі (EURONET DIANA). У 1982 році Європейське економічне співтовариство оголосило про створення європейської програми EUROTRA, мета якої – розробка системи комп'ютерного перекладу для всіх європейських мов. Спочатку проект оцінювався в 12 млн доларів, але в 1987 році фахівці визначили сумарні витрати сумою понад 160 млн доларів.
Одержала поширення система SYSTRAN, розроблена на замовлення військово-повітряних сил США. Протягом 1974-1975 років вона була використана аерокосмічною асоціацією NASA для перекладу документів у міжнародному проекті стиковки космічних кораблів Аполлон-Союз. Було розгорнуто ряд військових програм створення людино-машинних інтерфейсів природною мовою. У 1983 році міністерство оборони США започаткувало “стратегічну комп'ютерну ініціативу” – десятилітню програму створення нового покоління "інтелектуальних" військових систем [6]. Особливої актуальності технології машинного перекладу набули з початком антитерористичної світової війни, коли до краю загострилась потреба розуміння багатьох мов.
Радянські розробки
Ми люди бідні, і по бідності своїй агліцьких мєлкоскопів
не маємо. Ми так, око пристрілямши…
Микола Лєсков. Лівша.
У 1950-ті роки у СРСР почалися активні роботи в галузі машинного перекладу під керівництвом академіків Олексія Ляпунова та Акселя Берга. На початку 1956 року в Інституті прикладної математики імені Мстислава Келдиша запрацювала перша вітчизняна СМП ФР-I з французької на російську мову. Математики розглядали алгоритми машинного перекладу як окремі випадки алгоритмів перекодування.
У 60-х роках ХХ століття, в добу “бурі й поступу”, радянська філологія завоювала широке міжнародне визнання в науковому світі. В ряді тогочасних видатних досліджень особливе місце займають дві теоретичні концепції світового рівня: структурно-семіотичнкий підхід, розроблюваний у рамках московсько-ленінградсько-тартуської школи В’ячеславом Івановим, Юрієм Левіним, Юрієм Лотманом та іншими «тартуанцями» і модель “ЗМІСТ – ТЕКСТ” – багаторівневий формалізований системний опис природної мови, розроблюваний Ігорем Мельчуком, Юрієм Апресяном та їх послідовниками. Обидва напрямки викликали значний резонанс у європейській та американській філології, що відбилося, зокрема, у широкому виданні та перевиданні праць наших співвітчизників всіма європейськими мовами. Інша справа – за “Залізною завісою”, у соціалістичному таборі.
В’ячеслав Іванов, нині академік РАН, один з творців структурно-семіотичного підходу, звільняється з Московського державного університету за підтримку славетного поета Бориса Пастернака. Одночасно у ВАКу “губиться” його докторська дисертація та документи про її захист; відтак науковий ступінь йому не присуджується. Публікація його робіт тривалий час заборонена. У підсумку, до початку 90-х років величезна кількість досліджень частково розсіяна у наукових журналах по всьому світі, а в значній мірі і зовсім не опублікована. Кому це на користь?
Всесвітнього визнання набула теорія моделей “ЗМІСТ – ТЕКСТ” І. Мельчука – до сих пір мало не єдина всеохоплююча теорія мови. Проте на початку 1976 року за виступ на підтримку академіка Андрія Сахарова Мельчука не переобрали на посаду ст. н. с. в Інституті мовознавства АН СРСР, хоча за звітний період він мав 10 наукових статей і монографію. За 20 років за рубежем видано більше десятка його монографій, а в Росії – жодної. Він змушений був емігрувати, і п'ятитомну фундаментальну монографію «Курс загальної морфології» видав на Заході в 90-х роках. Реалізацією його теорій займався колектив під керівництвом академіка Юрія Апресяна, що розробляв СМП ЕТАП. Ці роботи понині продовжуються в Інституті проблем передачі інформації РАН.
Іншу наукову школу очолив ленінградський професор Раймунд Піотровський, що заснував всесоюзну творчу групу “Статистика мови”. В ній об’єднали зусилля філологи та інженери всього СРСР: Ленінграду, Москви, України, Казахстану, Молдавії, Узбекістану, Азербайджану тощо. Ряду фундаментальних ідей було висловлено Р.Піотровським в основоположній статті від 1971 року, опублікованій у журналі “Проблемы структурной лингвистики”. Гаслом наукової школи Піотровського був прагматизм, аргументований це складністю розробки СМП. Лінгвіст вивчає текст, вводить його до діючої (а не до уявної) програми, аналізує результат, перенастроює алгоритм перекладу і так далі, в результаті чого система обростає всілякими “латками”.
Підготовка фахівців у галузі структурної лінгвістики почалась з 1960 р. У Київському державному університеті імені Тараса Шевченка на факультеті кібернетики, створеному 1969-го року, була спеціалізація “Прикладна лінгвістика”.
У 1976 р. в Чимкентському педінституті була розроблена СМП для англо-російського перекладу хімічних патентів. В Києві під керівництвом О. Гальченка також було розроблено подібну СМП зі словником на 100 тисяч термінів. Професор Ю. Марчук, директор Всесоюзного центру перекладів, очолив розробку проекту, що включав три мовних пари: англо-російську AMPAR, німецько-російську NERPA та франко-російську FRAP. Система була запущена в дію у 1977 році. У 80-х роках ленінградська група започаткувала проект мовної інженерії MULTIS – першу радянську СМП на платформі IBM PC. Пізніше її було розвинуто в більш досконалі системи Stylus та ПРОМТ.
Комуністична ідеологія стримувала розповсюдження інформації, тому, всупереч зусиллям талановитих науковців та винахідників, вітчизняна інформаційна техніка кульгала на обидві ноги. Роботи перетворювались на “сізіфову працю”: розтягувались на десятки років, відставали від життя, не доводились до практичних результатів.
Але життя зрештою вирвалось за ідеологічні межі. З політикою горбачовської гласності полегшилось розповсюдження інформаційної техніки та створення електронних видань. Стала масовою і повсякденною робота з електронними текстами, спочатку англійською та російською, а зрештою й українською мовами; лінгвістичні проблеми постали в аспекті ринкового платоспроможного попиту. Через два десятки років після появи кишенькових калькуляторів у продажу з’явились кишенькові машинки для перекладу, з величезними словниками на кілька десятків мов, які працюють не лише у текстовому режимі, і не лише відтворюють звучання знайдених слів, але й намагаються розпізнати голос користувача. З’явилось також щось на кшталт чарівної палички: ведеш нею по іншомовному тексту, а вона тобі його читає вголос, але вже зрозумілою мовою.
Сучасна мовна кібернетика
Всяка лінгвістична робота починається з організації довідників і пошуку. Так, використання української мови враховано на сторінках відомих пошукових порталів meta.ua/translate/defukr.asp, rambler.ru/doc/advanced.shtml та google.com/advanced_search?hl=uk. Проте вибір електронних словників на вітчизняному ринку в основному орієнтований на російську та англійську мови:
| Продукт, постачальник, Веб-сайт | Словникова база | Інтерфейс | Додаткові технічні можливості | Примітки |
VU-DictionaryВ. Купрович vu-software.spb.ru | Переклад російською з англійської, обсяг словникових баз 130 тис. лексичних одиниць. Зібрані сталі словосполучення, ідіоматичні вирази, назви мір, скорочення, а також велика кількість термінів. | Продуманий алгоритм шукає не тільки задане слово, але й всі споріднені йому форми, а список знайдених слів наводиться вже з перекладами. | Продукт обсягом близько 13 Мб можна скачати з веб-сайту. | Безкоштовний. |
Artefact DictionaryRSD Software, Inc. rsdsoft.com | Невеликі словники. Переклад з російської на англійську та з англійської на російську, німецьку, іспанську, французьку. | Модуль веб-перекладу. Вимова програмою заданих слів. Словник синонімів англійської мови та великий тлумачний Webster Dictionary. | Продукт обсягом близько 5 Мб можна скачати з веб-сайту фірми. | 30 днів безкоштовної дослідної експлуатації, реєстрація – до 10$. |
WordPointGalTech Soft wordpoint.grapho.net | Невеликі словники для 18 мов. У демо-версії можливість двостороннього перекладу з/на англійську для німецької, французької, російської, іспанської, італійської, арабської, івриту. | Для англійської мови голосове озвучування і контекстний переклад. Для деяких слів наведено типові сполучення та пояснення. | Продукт обсягом близько 40 Мб можна скачати з веб-сайту фірми. | 15 днів безкоштовної дослідної експлуатації, реєстрація – до 20$ |
MyDicBabylon Ltd. Planetsoft.ru/mydic | Тільки пара російська-англійська мови, обсяг бази 180 тис.слів. | | Обсяг 6 Мб, можна скачати з веб-сайту. | Ціна до 10$. |
Babylon ProBabylon Ltd. babylon.com | Невеликі словники для кількох десятків мов. Підтримка перекладу китайською, німецькою, французькою, івритом, іспанською, датською, італійською, шведською, російською, японською, португальською мовами – на і з англійської. | Транскрипція, пояснення, синоніми, голосове озвучування слів програмою. | Вбудований конвертер валют. | 30 днів безкоштовної дослідної експлуатації. На сайті фірми забезпечується переклад у 50-ти напрямках, включаючи українську мову. |
| LangSoft langsoft.cz | Великі професійні словники для 6 пар мов з чеською та словацькою: англійська та німецька (по 2.7 млн. слів, 700 тис. Мовних одиниць), російська (2 млн. слів, 550 тис. мовних одиниць), французька, італійська, іспанська. | Розвинений сучасний інтерфейс, включаючи голосовий. | | Вартість для одного напрямку перекладу близько 210 євро. Експлуатуються близько 27 тисяч зареєстрованих екземплярів продуктів. |
| Polyglossum «Электронные и традиционные словари» ets.ru | Найбільші словники авторитетного видавництва: англійська, німецька, французька, іспанська, фінська, шведська, латина – на і з російської мови. | Простота і швидкодія, що суттєво для експлуатації на застарілій техніці. | | Вартість найдорожчого словника близько 30$ |
| «Контекст» «Информатик» informatic.ru | Англо-російські, а також спеціальні словники російської мови: тлумачний, синонімів, антонімів, тощо. | Автоматичний морфологічний аналіз введених слів. | | Ціни версій від 10 до 60$ |
| Multilex «МедиаЛингва» multilex.ru | Найбільші і найретельніше опрацьовані словники від солідних академічних постачальників для російської (3 млн.слів), англійської (3.5 млн.слів), німецької, французької, італійської, іспанської, японської мов | Зразково опрацьовані всі мислимі можливості. Користувачу надаються різні форми слів, варіанти перекладів, наголоси, приклади й контексти застосування, омоніми. Озвучування професійними дикторами. | Мобільні версії для кишенькових комп’ютерів та телефонів Nokia і Sony Ericsson. | Окремі видання для кожної пари мов. Лінійка продуктів, починаючи з дешевої примітивної версії для початківців. Додатковий продукт “Письмовник” – підбірка шаблонів текстів англійською мовою. |
| Lingvo 9.0 Многоязычный АВВYY lingvo.ru lingvoda.ru | Словники для російської, англійської (1.4 млн.статей, 11 спец. словників, звучання 15 тис. слів), німецької, французької, італійської, іспанської мов | По кожній мові розмовник на 500 речень. Країнознавчий довідник по Великій Британії. | Мобільна версія для кишенькових комп’ютерів. | Ціна 28$ |
Спільно з Союзом перекладачів Росії фірма АВВYY веде масштабну роботу над великим універсальним словником, що не має аналогів за якістю й обсягом. Злагоджена робота має ще один важливий аспект: ревнителі чистоти нерідко ремствують на засміченість мови неблагозвучними іноземними неологізмами. Але всі ці "сиквенси", "еквалайзери", "провайдери", "піксели", "хаби" – не що інше, як наслідки перекладацьких невдач. Перекладач нерідко змушений сам винаходити еквіваленти новітніх термінів. Це вдається не завжди, і от, у результаті транслітерації, чергове слово-виродок відправляється гуляти по світу. Якщо Асоціація лексикографів Lіngvo виконає все задумане, то подібних ситуацій у майбутньому вдасться уникнути.
Я

кість машинних словників оцінюється за критеріями солідності лінгвістичної основи, повноти наукового апарату, до якого входять транскрипції, наголоси, тлумачення, наочні приклади і типові словосполучення. На них базуються контекстний переклад та автоматизована пропозиція готових фрагментів тексту. Популярність продукту визначається також структурованістю пошуку, дизайном інтерфейсу, взаємодією з іншими програмами. Важливою є Інтернет-підтримка: поповнення баз знань і обслуговування разових запитів на переклад.
У конкурентній боротьбі розробники розширюють коло охоплюваних мов (польська, китайська, іврит, латина, фінська, шведська), пропонують системи перекладу з голосу, а також намагаються перейти до “вищої ліги” лінгвістичних програм – створити на базі словників автоматичні перекладачі, як-от наступні.
- ProLing Office, куди входять українсько-російський словник УЛІС, програма перевірки правопису РУТА і СМП ПЛАЙ та деякі інші продукти, пропонують компанії ABBYY Україна (abbyy.ua) та МТ (mtsoft.kiev.ua). Обсяг словника - близько 130 тисяч слів та близько 15 тисяч словосполучень для кожного напрямку перекладу, забезпечується граматичне узгодження за правилами української та російської мов. На сторінці uaportal.com/Translator пропонується оперативний переклад.
- Pragma – від київської Trident Software (trident.com.ua): в систему включені англійська, російська, німецька та українська мови, з можливістю перекладу в будь-якому напрямі. Використовуються більше ніж 800 тис. слів в 100 тематичних словниках; загальний обсяг продукту 10 Мб.
- Перекладачка – аматорський проект багатомовної самонавчальної системи автоматизованого перекладу (pere.slovnyk.org.ua).
- PARS – від Lingvistica’98 Inc. (ling98.com) : СМП та інші лінгвістичні продукти для ряду мов. Перша версія харківської розробки PARS (узагальнений переклад для полісемантичних випадків) була запущена ще аж 1989-го року (!!!) в Грузинському медичному інформаційному центрі для перекладу анотацій з міжнародної медичної бази даних MEDLINE.
- The Microsoft Proofing Tools for Office – пакет технологій (translation.net/ukrainian.php) пропонує не надто досконалі засоби перекладу та редагування для майже 50 мов, включаючи арабську, китайську, голландську, французьку, німецьку, італійську, японську, корейську, польську, португальську, російську, іспанську, українську.
- PROMT – продукти компаній ПРОМТ (promt.ru) і американської TRADOS (trados.com), ексклюзивний дистриб’ютор якої в країнах СНД – та ж сама ПРОМТ. Нижче ми докладніше спинимось на цій технології, а поки що відзначимо: “родзинка” тут – збереження вдалих перекладів у базі знань. Ретельно відібрані фрагменти застосовуються для наступних робіт. На жаль, поки що ці досконалі рішення для української мови практично не доступні.
Перша російська комерційна СМП під назвою PROMT була представлена у 1990 році. Вже 1992-го року компанія ПРОМТ виграла конкурс NASA (і була єдиною неамериканською фірмою на цьому конкурсі). У тому ж році фірма видала ряд продуктів під назвою STYLUS для перекладу з англійської, німецької, французької, італійської та іспанської мов на російську і з російської на англійську. У 1995-1996 роках представлені перші в світі російсько-німецька та російсько-французька системи. У 1997 році випущено першу в світі систему німецько-французького перекладу, систему для підтримки кількох мовних напрямків в одній оболонці, а також спеціальний перекладач для роботи в Інтернеті WebTranSite.
Статистична лінгвістика – крок назустріч реальній мові
К
атуючись з пошуком потрібного словечка чи звороту, фахівець звертається до численних довідників. І просто старається купатись у мовному потоці. Отже, щоб підвищити якість генерованого машиною тексту, мусимо ознайомити її з усім цим людським надбанням, як роблять це з усяким початкуючим філологом. Лише наприкінці ХХ століття стали широко доступними пристрої та програми введення та оцифрування великих обсягів текстів і готові корпуси текстів, підготованих численними ентузіастами. Отже, розпочалась побудова на їх базі систем перекладу й літературного редагування за зразками. Адже надто часто про результати роботи найкращих СМП можна сказати: дещо зрозуміло, але по-людськи так не пишуть.
У 1984 році в США було започатковано розробку СМП TRADOS, заснованої на технології накопичення зразків у лінгвістичній базі даних Translation Memory (TM). Ця система стала фактичним галузевим стандартом, бо дозволяє не витрачати сил на повторний переклад аналогічних фрагментів. Нині ж розробляються повністю автоматичні методи співставлення текстів різними мовами і створення бази зразків перекладу. Характерною рисою такого підходу є ігнорування звичних для людини закономірностей, і побудова структур, зручних для машинної обробки, які виявляються лише при аналізі великих масивів даних.
Ця технологія виходить за межі логічних побудов, поринає в живі потоки реальних мов, з усім їх стилістичним багатоманіттям. Правда, при автоматизованому наповненні словників постає суто філологічна проблема сортування потоку зразків за неформальними критеріями. Як мінімум, слід розділяти суху ділову лексику, пишномовне фразерство та індивідуальні стилістики окремих художників слова. Втім, художній переклад навряд чи є основним об’єктом для СМП.
Рішення TRADOS постачаються більш ніж у 60 країн, є визнаним стандартом на ринку і забезпечують можливості професійної колективної праці над багатомовними текстами значних обсягів. Технологія TRADOS TM підтримує такі мови:
африкаанс, албанська, арабська (всі варіанти), азербайджанська (кирилична та латинська абетка), баскська, болгарська, білоруська, кампучійська, каталонська, китайська (всі варіанти), хорватська, чеська, датська, голандська (всі варіанти), англійська (всі варіанти), естонська, фарерська, фінська, французська (всі варіанти), гельська (всі варіанти), німецька (всі варіанти), грецька, іврит, угорська, ісландська, індонезійська, италійська (всі варіанти), японська, корейська (всі варіанти), латвійська-латиська, литовська, македонська, малазійська (всі варіанти), мальтійська, маорійська, норвезька (всі варіанти), перська, польська, португальська (всі варіанти), ромська, румунська, російська, сербська, словацька, словенська, Sorbian, іспанська (всі варіанти), суахілі, шведська (всі варіанти), тагальська, тайська, тсонга, турецька, українська, в’єтнамська, уельська, зулуська та ще кілька.
Реальна якість машинного перекладу
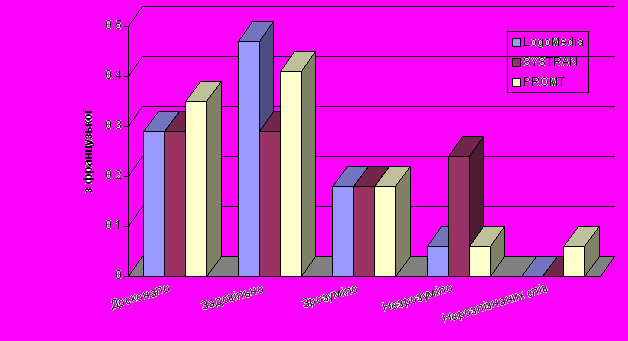
На основі даних з роботи [1] наводимо порівняльні результати дослідження трьох СМП, доступ до яких здійснювався через сайти:
- world.altavista.com - SYSTRAN systems
- logomedia.net - LogoMedia
- promt.ru - PROMT
До систем не підключали додаткові галузеві словники, а контрольні тексти не містили професійних чи жаргонних висловів та граматичних помилок.
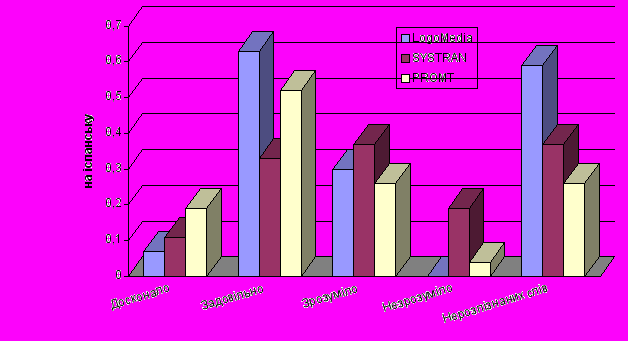
Якість перекладу унаочнюється діаграмами, що додаються. По вертикальній осі відкладено частку речень в тексті, які перекладено:
- досконало;
- задовільно;
- незадовільно, але зрозуміло;
- недостатньо зрозуміло.
Останній показник – кількість слів пересічно на одне речення, які лишились нерозпізнаними, бо були відсутні у словнику.
Результати аналізу перекладу з різних мов на англійську:
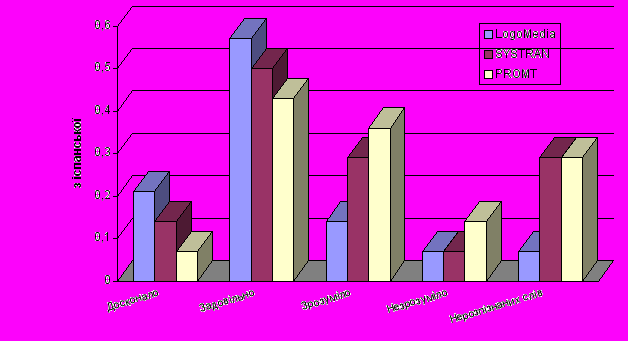
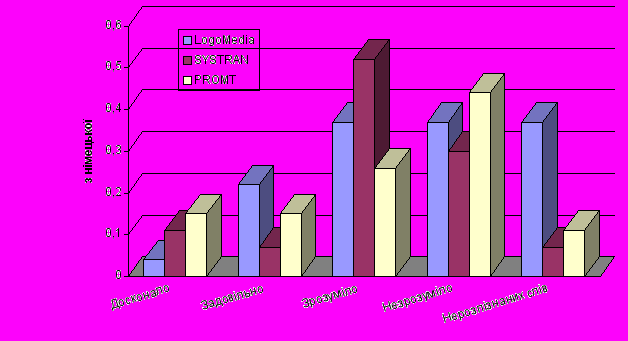
Результати порівняльного лінгвістичного аналізу перекладу з англійської на різні мови:
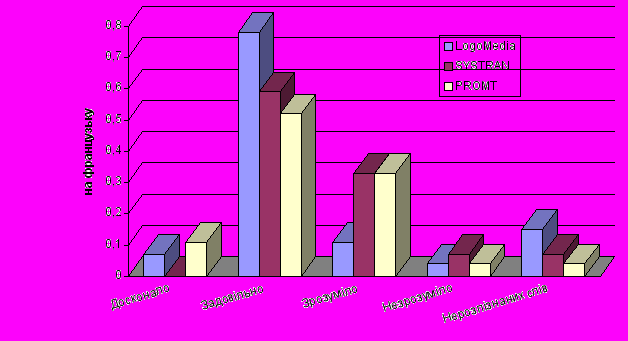
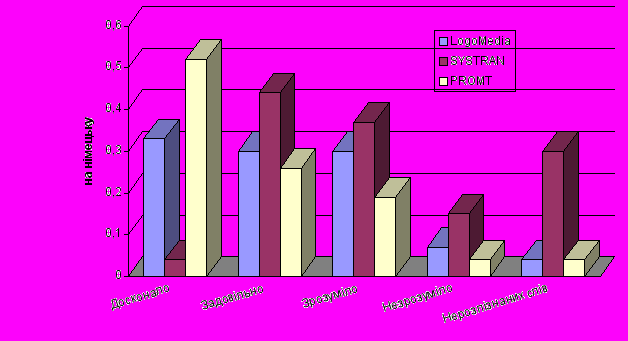
Щодо якості машинних перекладів для української мови сподіваємось навести оцінки у наступних публікаціях.
Висновки
Склались два основні напрямки розробки систем машинного перекладу. З одного боку, на новій технологічній основі розвивається традиційна словникова база, документуються мовні структури. Результати втілюються в нові електронні словники та СМП, при цьому видання класичних паперових словників значно пришвидшується й вдосконалюється.
З іншого боку, продовжується традиція Франсуа Шампольйона, який на початку ХІХ ст. розшифрував тексти ієрогліфічної давньоєгипетської писемності методом порівняльного аналізу. Подібно до того, як укладаються практичні розмовники з готовими реченнями на всі випадки життя, у системах на статистичному принципі бази знань накопичуються з потоку готових текстів.
Незважаючи на альтернативність підходів і самостійну цінність, ці напрямки мають значний потенціал до взаємодії. Адже у безмежжі мовних проблем всім вистачить місця.
Вдячно освоюючи новітні технічні засоби, мовознавці мають навзаєм зробити свій професійний внесок до розвитку національної інформатики. Поява на українському ринку автоматизованих словників та СМП для тіснішого спілкування з польською, німецькою, китайською, іспанською, французькою та іншими культурами сприятиме достойному входженню нашого суспільства у світове співтовариство.
Література
- Blekhman М. Machine translation: professional experience. 2001 // ling98.com
- Филинов Е.. История машинного перевода // transinter.ru/articles/265
- Панчук Р. Электронные словари // itc.ua/print.phtml?ID=17979
- Компания ПРОМТ // promt.ru
- Всё о языках, лингвистике, переводе // linguistic.ru/index.php?module=transservice
- Анисимов В. Компьютерная лингвистика для всех: Мифы. Алгоритмы. Язык. К.: Наукова думка, 1991. – 208 с. lib.ru/CULTURE/ANISIMOW/lingw.txt
- Издательство «Языки русской/славянской культуры» // dialog-21.ru/bookstore.asp?content=info&publ_id=25397
- Лысенко В. Мечты об автоматизированном переводе // Компьютеры + Программы № 8(23), 1995. 1000years.uazone.net/translat.php
- Филинов Е. История машинного перевода. // computer-museum.ru/histsoft/histmt.htm
- Тищенко К. Історія запозичення слів до українського словника. К., 2002. slovnyk.org.ua/txt/tyschenkok/zapoz
- Возняк Т. Тексти та переклади. Харків: Фоліо, 1998. slovnyk.org.ua/txt/vozniakt/text-i-perekl
- Факультет лінгвістики НТУУ "КПІ". Список літератури з теорії та практики перекладу.
fl.ntu-kpi.kiev.ua/Site/Departments/Bibliographyeng/translation_theory.php
- Мірам Г. та ін. Основи перекладу. Курс лекцій з теорії та практики перекладу для факультетів та інститутів міжнародних відносин. - К.: Ельга. Ніка-Центр, 2002.-237 с.
- Бюро перекладів ЛІНГО. lingo.com.ua
- Сайт “Лингвист”. linguists.narod.ru
- Сайт “Город переводчиков”. trworkshop.net
- Шмелева А. Переводчики делают электронный словарь. Газета Iностранец N10 от 25.03.2003.
inostranets.ru/cgi-bin/materials.cgi?id=12688&chapter=9

* * *
Лисенко Валерій Миколайович Valery_Lysenko@mail. ru д. т. 440-2518
- асистент кафедри видавничої справи та редагування Інституту журналістики Київського національного університету імені Тараса Шевченка,
- автор приватного Інтернет-проекту “1000-ліття української культури” 1000years.uazone.net