
Конспект лекций по дисциплине " Операционные системы"
| Вид материала | Конспект |
- Конспект лекций по дисциплине «Операционные системы и среды», 618.94kb.
- Методические указания для выполнения Курсовой работы по дисциплине «Операционные системы», 72.86kb.
- Программа по дисциплине «Технологии программирования и операционные системы», 42.87kb.
- Ые системы", "Операционные системы, среды и оболочки" и "Операционные системы и системное, 1294.27kb.
- Конспект лекций по дисциплине «Маркетинг», 487.79kb.
- Конспект лекций по дисциплине «Информационные системы в экономике», 1286.5kb.
- Рабочая программа По дисциплине «Операционные системы» По специальности 230102., 376.29kb.
- В. Ф. Панин Конспект лекций по учебной дисциплине "Теоретические основы защиты окружающей, 1559.17kb.
- Рабочая программа по учебной дисциплине Операционные системы, среды и оболочки наименование, 623.3kb.
- Тема лекции «Многозадачные многопользовательские операционные системы. Операционные, 154.91kb.
Сегментно-страничное распределение
Данный метод – попытка объединить достоинства обоих методов.
Здесь, как и при сегментной организации памяти, виртуальное адресное пространство процесса разделено на сегменты. Это позволяет определять разные права доступа к разным данным. Перемещение данных между памятью и диском осуществляется не сегментами, а страницами. Для этого каждый сегмент и физическая память делятся на страницы равного размера, что позволяет минимизировать фрагментацию.
В большинстве современных реализаций сегментно-страничной организации
диапазонов адресов при сегментной организации все виртуальные сегменты образуют одно непрерывное линейное виртуальное адресное пространство.
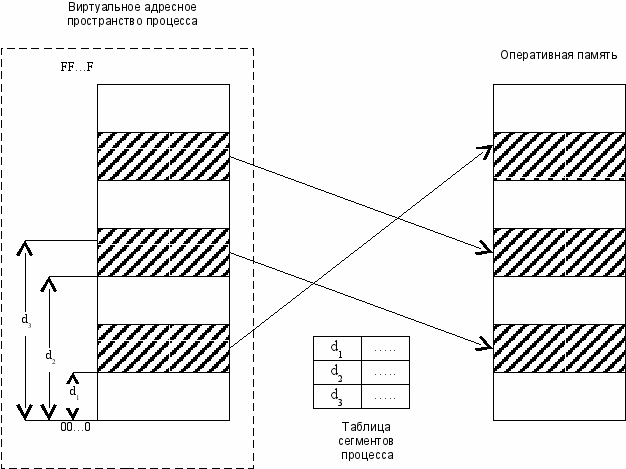
Координаты байта при этом можно задать двумя способами. Во-первых, линейным виртуальным адресом, который равен сдвигу данного байта относительно границы общего линейного виртуального пространства, во вторых, парой чисел, одно из которых является номером сегмента, а другое – смещением относительно сегмента.
При этом в отличие от сегментной модели для однозначного задания виртуального адреса вторым способом необходимо указать также начальный виртуальный адрес сегмента с данным номером.
Чаще всего используется второй способ, так как он позволяет непосредственно определить принадлежность адреса некоторому сегменту и проверить права доступа процесса к нему.
Для каждого процесса ОС создает отдельную таблицу сегментов, в которой содержатся дескрипторы (описатели ) всех сегментов процесса. Описание сегмента включает назначенные ему права доступа и другие характеристики, подобные тем, которые содержатся в дескрипторах сегментов при сегментной организации памяти.
Однако есть отличия. В поле базового адреса указывается не начальный физический адрес сегмента, а начальный линейный виртуальный адрес сегмента в пространстве виртуальных адресов. Его наличие позволяет однозначно преобразовать адрес, заданный парой (g, s) в линейный виртуальный адрес байта, который затем преобразуется в физический адрес страничным механизмом.
Деление общего линейного виртуального адресного пространства процесса и физической памяти на страницы осуществляется так же, как это делается при страничной организации памяти.
Базовые адреса таблицы сегментов и таблицы страниц процесса являются частью его контекста. При активизации процесса эти адреса загружаются в специальные регистры процессов и используются механизмы преобразования адресов.
Преобразование виртуального адреса в физический происходит в два этапа.
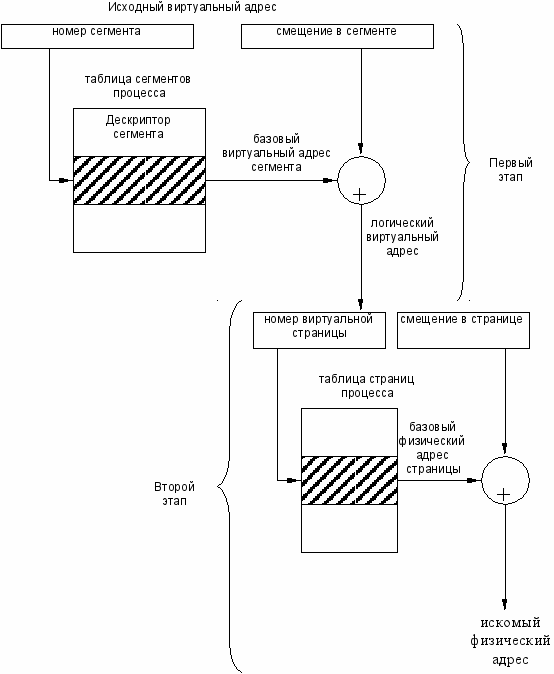
1. На первом этапе работает механизм сегментации. Исходный виртуальный адрес пары (g, s) преобразуется в линейный виртуальный адрес. Для этого на основании базового адреса сегментов и номера сегмента вычисляется поле дескриптора и выполняется проверка возможности выполнения заданной операции.
Если доступ к сегменту разрешен, то вычисляется линейный виртуальный адрес путем сложения базового адреса сегмента, извлеченного из дескриптора, и смещения, заданного в исходном виртуальном адресе.
2. Второй этап использует страничный механизм. Линейный виртуальный адрес преобразуется в физический. В результате преобразования линейный виртуальный адрес представляется в том виде, в котором он используется при страничной организации памяти (пара: номер страницы, смещение в странице). Далее как уже изучали ранее.
Старшие разряды линейного виртуального адреса, содержащие номер виртуальной страницы, заменяются номером физической операции, взятым из таблицы страниц, а младшие разряды виртуального адреса, содержащие смещение, остаются без изменения.
Как следует из рассмотрения, механизм сегментации и страничный действуют достаточно независимо друг от друга.
Поэтому не трудно представить себе реализацию памяти, когда механизм сегментации выполняется, как было показано, а страничный механизм реализуется по двухуровневой схеме: виртуальное адресное пространство делится сначала на разделы, а уж потом на страницы.
В таком случае преобразование виртуального адреса в физический происходит в несколько этапов.
Сначала механизм сегментации обычным образом, используя таблицу сегментов, вычисляет линейный виртуальный адрес. Затем из этого адреса вычисляется номер раздела, номер страницы и смещение. По номеру раздела из таблицы разделов определяется адрес таблицы страниц, а затем по номеру виртуальной страницы из таблицы страниц определяется номер физической страницы, к которой приписывается смещение.
Именно этот подход реализован в процессорах i386, i486 и Pentium.
Рассмотрим еще одну схему управления памятью, основанную на сегментно-страничном подходе.
Отличие этого подхода состоит в том, что виртуальные страницы нумеруются не в пределах всего адресного пространства процесса, а пределах сегмента.
Виртуальный адрес в этом случае выражается тройкой (номер сегмента, номер страницы, смещение в странице).
Загрузки процесса выполняются постранично. Для каждого процесса создается своя таблица сегментов, а для каждого сегмента - своя таблица страниц.
Адрес таблицы сегментов загружается в специальный регистр процессора, когда .
Таблицы страниц полностью аналогичны таблице страниц в предыдущем случае.
В таблице сегментов имеются существенные отличия. Она состоит из дескрипторов сегментов, которые вместо информации о расположении сегментов в виртуальном адресном пространстве содержит описание расположения таблиц страниц в физической памяти.
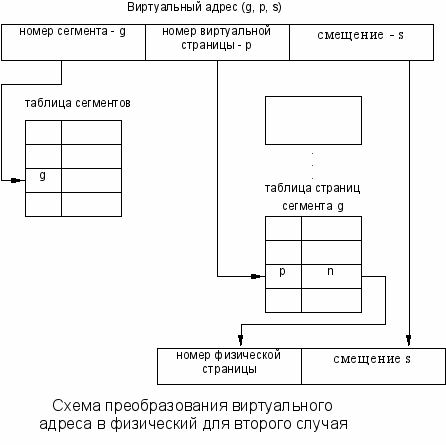
1. По номеру сегмента, заданному в виртуальном адресе, из таблицы сегментов извлекается физический адрес соответствующей таблицы страниц.
2. По номеру виртуальной страницы, заданному в виртуальном адресе, из таблицы страниц извлекается дескриптор, в котором указан номер физической страницы.
3. К номеру физической страницы пристыковуется младшая часть виртуального адреса - смещение.
Разделяемые сегменты памяти
Примером применения разделяемой области память может быть использование ее в качестве буфера при межпроцессном обмене данными. Один процесс пишет в разделяемую область, другой – читает.
Для организации разделяемого сегмента при наличии системы виртуальной памяти достаточно поместить его в виртуальное адресное пространство каждого процесса, которому нужен доступ к данному сегменту, а затем настроить параметры отображения этих виртуальных сегментов так, чтобы они соответствовали одной и той же области оперативной памяти.
Детали такой настройки зависят от памяти.
«Попадание» виртуальных сегментов на общую часть оперативной памяти достигается либо за счет согласованной настройки ОС многочисленных дескрипторов для процессов, либо помещением единственного разделительного виртуального сегмента в общую часть виртуального адресного пространства процессов, которую обычно используют для модулей ОС. В этом случае настройка дескриптора сегмента и дескрипторов страниц выполняется один раз, а все процессы пользуются такой постройкой и совместно используют часть оперативной памяти.
При работе с разделяемыми сегментами памяти необходимо соблюдать общие правила использования разделяемых ресурсов – семафоры, мониторы и т.п.
Для отличия разделяемых сегментов памяти от индивидуальных. Дескриптор сегмента должен содержать поле, имеющий два значения shared(разделяемый) или private(индивидуальный).
Разделяемые сегменты выгружаются на диск системой виртуальной памяти по тем же алгоритмам и с помощью тех же механизмов что и индивидуальные.
Кэширование данных
Память ЭВМ – это иерархия ЗУ, отличающихся средним временем доступа к данным, объемом и стоимостью хранения 1 бита информации.
Фундамент этой пирамиды – память на жестких дисках, но время доступа к диску исчисляется миллисекундами.
Оперативная память – время доступа 10-20 наносекунд (от нескольких мегабайт до нескольких гигабайт)
Сверхоперативная память (десятки сотни килобайт) – 8нсек.
Внутренние регистры процессора – несколько десятков байт со временем доступа 2-3 наносекунд.
Кэш память или просто кэш способ совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который за счет динамического копирования в быстрые ЗУ наиболее часто используемой информации из «медленного» ЗУ позволяет, с одной стороны, уменьшить среднее время доступа к данным, с другой - сэкономить более дорогую быстродействующую память.
Особенностью кэширования является то, что система не требует никакой внешней информации об интенсивности использования данных, ни пользователи, ни программы не принимают никакого участия в перемещении данных из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными средствами.
Кэшем часто называют не только способ организации двух типов запоминающих устройств, но и одно из устройств – «быстрое ЗУ». Оно дороже и сравнительно небольшого объема в противовес «медленному» ЗУ – оперативной памяти.
Если кэширование используют для уменьшения среднего времени доступа к оперативной памяти, то в качестве КЭШа используют более дорогую и быстродействующую статическую память.
Если кэширование используется системой ввода-вывода для ускорения доступа к данным, хранящимся на диске, роль кэш-памяти играют буфера, реализованные в оперативной памяти.
Виртуальную память тоже можно рассматривать как частный случай кэширования.
Принцип действия кэш-памяти
Содержимое кэш-памяти представляет собой совокупность записей обо всех загруженных в нее элементах данных из основной памяти. Каждая запись включает:
- элементы данных;
- адрес, который этот элемент имеет в основной памяти;
- дополнительную информацию, которая используется для реализации алгоритма включает признак модификации и признак действительности данных.
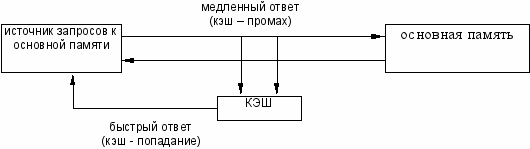
При каждом обращении к основной памяти по физическому адресу просматривается содержимое кэш-памяти с целью определения, не находятся ли там нужные данные.
Кэш-память не является адресуемой, поэтому поиск нужных данных осуществляется по содержимому - по взятому из запроса значению поля адреса в оперативной памяти.
Далее возможны два варианта развития:
- данные обнаружены в кэш-памяти, т.е. произведено кэш-попадание (cache-hit), они считываются и передаются источнику запроса;
- нужные данные отсутствуют, т.е. произошел кэш-перенос (cache-miss), они считываются из основной памяти, передаются источнику запроса и одновременно копируются в кэш-память.
Эффективность кэширования зависит от вероятности попадания в кэш.
Если обозначить вероятность кэш-попадания через p, а время доступа к основной памяти через t1, время доступа через t2, то по формуле полной вероятности среднее время доступа будет равно:
t=t2p+t1(1-p)
Если p=1, время доступа равно t2.
Вероятность обнаружения данных в кэше зависит от различных факторов, таких как:
- объем кэша;
- объем кэшируемой памяти;
- алгоритм замещения данных в кэше;
- особенностей выполняемой программы и т.п.
На практике процент попаданий оказывается весьма высоким – порядка 90%. Такой процент объясняется наличием у данных объективных свойств таких как пространственной и временной локальности.
Пространственная локальность. Если произошло обращение по некоторому адресу, то с высокой вероятностью в ближайшее время произойдет обращение по соседним адресам.
Временная локальность. Если произошло обращение по некоторому адресу, то следующее обращение по тому же адресу с большой вероятностью произойдет в ближайшее время.
Поскольку при выполнении программы очень высока вероятность, что команды выбираются из памяти одна за другой из соседних ячеек, имеет смысл загружать в кэш целый фрагмент программы. Аналогично и с массивами данных.
В процессе работы содержимое кэш-памяти постоянно обновляется. Вытеснение данных означает либо просто объявление свободной некоторой области кэш-памяти (сброс бита действительности) менялись либо в дополнение к этому копирование данных в основную память, если они модифицировались.
Наличие в компьютере двух копий данных – в основной памяти и в кэше – порождает проблему согласования данных.
Существует два подхода к решению этой проблемы:
- сквозная запись (write through). При запросе к основной памяти (в том числе при записи) просматривается кэш. Если данные по запрашиваемому адресу отсутствуют, запись выполняется только в основную память. Если данные находятся в кэше, запись делается и в кэш ив память.
- обратная запись (write back). Выполняется просмотр кэша, если данных там нет, то запись делается в основную память. В противном случае запись делается только в кэш. При этом устанавливается признак модификации. При вытеснении данных из кэша эти данные будут переписаны в основную память.
Способы отображения основной памяти на кэш.
Алгоритмы поиска и замещения данных в кэше зависят от того, как основная память отображается на кэш.
Используются две схемы отображения:
- случайное отображение;
- детерминированное отображение.
При случайном отображении элемент оперативной памяти может быть размещен в произвольном месте кэш памяти. Он помещается туда вместе со своим адресом в оперативной памяти. Поиск информации осуществляется по этому адресу. Процедуры простого перебора адресов при больших временных затрат.
Поэтому используется так называемый ассоциативный поиск, при котором сравнение выполняется не последовательно с каждой записью в кэше, а параллельно со всеми его записями. Признак, по которому выполняется сравнение, называется тэгом (tag). В данном случае тэгом является адрес данных в оперативной памяти.
Электронная реализация такого поиска значительно удорожает кэш-память. Поэтому этот метод используется для обеспечения высокого процента попадания при небольшом объеме кэш-памяти.
В кэшах на основе случайного отображения вытеснение старых данных происходит только в том случае, когда вся кэш-память заполнена и нет свободного места. Выбор данных на выгрузку основывается на тех же принципах, что и при замещении страниц (давно нет обращений, меньше всего обращений и т.д.).
При детерминированном способе отображения любой элемент основной памяти отображается в одно и то же место кэш-памяти. В этом случае кэш-память разделена на строки, каждая из которых предназначена для хранения одной записи об одном элементе данных и имеет свой номер.
Между номерами строк кэш-памяти и адресами оперативной памяти устанавливается соответствие «один ко многим»: одному номеру строки соответствует несколько (довольно много) адресов оперативной памяти.
В качестве отображающей функции может использоваться простое выделение нескольких разрядов из адреса оперативной памяти, которые интерпретируются как номер строки кэш-памяти. Такое отображение называется прямым. Например, кэш рассчитан на 1024 записи (1024 строки). Тогда любой адрес оперативной памяти может быть отображен на адрес кэш-памяти простым отделением 10 двоичных разрядов.
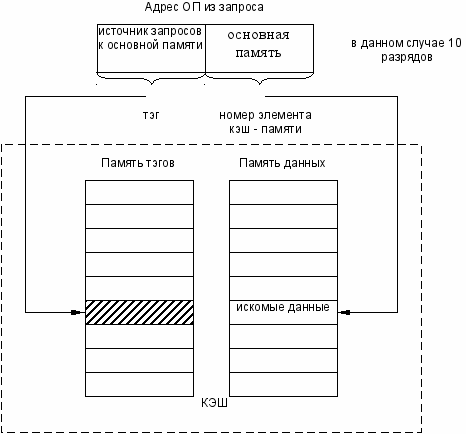
При поиске данных в кэше используется быстрый прямой доступ к записи по номеру строки, полученному из адреса оперативной памяти из запроса. Кроме того, выполняется дополнительная проверка на совпадение тега с соответствующей частью адреса из запроса.
При совпадении тега с соответствующей частью адреса из запроса констатируется кэш попадание. Если нет констатируется кэш-промах и данные считываются из OI и копируются в кэш.
Во многих современных процессорах кэш-память стоится на основе сочетания этих двух подходов, что позволяет найти компромисс между сравнительно
При смешанном подходе произвольный адрес оперативной памяти отображается не на один адрес кэш-памяти (как это характерно для прямого отображения), и не на любой адрес кэш-памяти (как это делается при случайном отображении), а на некоторую группу адресов). Все группы пронумерованы. Поиск в кэше осуществляется вначале по номеру группы, полученному из адреса ОП из запроса, а затем в пределах группы путем ассоциативного просмотра всех записей группы на предмет совпадения старших частей адресов ОП
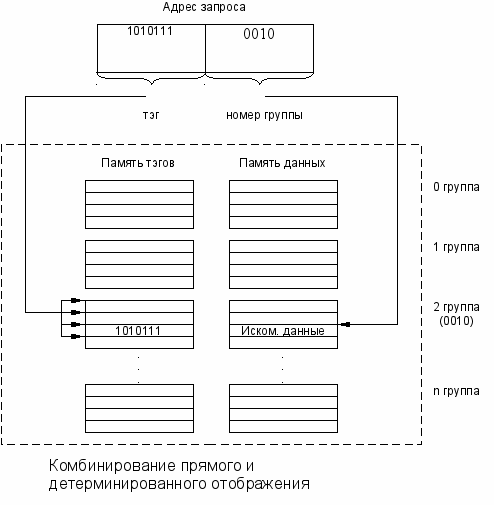
При промахе данные копируются по любому свободному адресу из однозначно заданной группы.
Если свободных адресов в группе нет, то выполняется вытеснение данных. Поскольку кандидатов на выгрузку несколько – все записи из данной группы – алгоритм замещения может учесть интенсивность обращения к данным и тем самым повысить вероятность попаданий в будущем.
Как мы видели, кэш просматривается только с целью согласования содержимого кэша и основной памяти. Если происходит промах, то запросы на запись не вызывают никаких изменений кэша.
В некоторых реализациях кэш-памяти при отсутствии данных в кэше они копируются туда из основной памяти независимо от того, выполняется запрос на чтение или запись.
В соответствии с описанной логикой работы кэш памяти при возникновении запроса сначала просматривается кэш, а затем, если произошел промах, выполняется обращение к основной памяти.
Однако, часто реализуется и другая схема работы кэша: поиск в кэше и основной памяти начинается одновременно, затем в результате просмотра кэша, операция в основной памяти либо продолжается, либо прерывается.
В ряде вычислительных систем используется двухуровневое кэширование.
Кэш первого уровня имеет меньший объем и более высокое быстродействие, чем кэш второго уровня. Кэш второго уровня играет роль основной памяти по отношению к кэшу первого уровня.
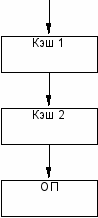
Сначала делается попытка обнаружить данные в кэше 1-го уровня. Если произошел промах, поиск продолжается в кэше второго уровня. Если нужные данные отсутствуют и здесь, тогда происходит считывание данных из основной памяти.
При считывании данных из ОП происходит их копирование в кэш второго уровня, а если данные считываются из кэша второго уровня, то они копируются в кэш первого уровня.
Кэши разных уровней могут согласовывать данные разными способами. Например, в процессоре Pentium кэш первого уровня использует кэш первого уровня - обратную запись.
Заметим, что мы рассматривали системы, в которых на каждом уровне имеется только один кэш. Однако существует целый ряд систем – распределенных систем обработки информации, в которых на каждом уровне имеется несколько кэшей.
Ввод – вывод и файловая система
Основными компонентами подсистемы ввода – вывода являются драйверы, управляющие внешними устройствами, и файловые системы.
К подсистеме ввода – вывода можно также отнести и диспетчер прерываний; правда это весьма условно, так как он обслуживает не только модули подсистемы ввода – вывода но также планировщик или диспетчер потоков.
Файловую систему целесообразно рассматривать совместно с другими компонентами ввода – вывода по двум причинам:
- файловая система активно использует ввод – вывод;
- модель файла может быть в основе большинства механизмов доступа к устройствам ввода – вывода.
Задачи ОС по управлению файлами и устройствами
Подсистема ввода-вывода мультипрограммной ОС решает следующие основные задачи:
- организация параллельной работы устройств ввода – вывода и процессора;
- согласование скоростей обмена и кэширование данных;
- разделение устройств и данных между процессами;
- обеспечение удобного логического интерфейса между устройствами и остальной частью системы;
- поддержка широкого спектра драйверов с возможностью простого включения в систему нового драйвера;
- динамическая загрузка и выгрузка драйверов;
- поддержка нескольких файловых систем;
- поддержка синхронных и асинхронных операций ввода – вывода.
Организация параллельной работы устройств ввода – вывода и процессора.
Каждое устройство ввода – вывода – снабжено блоком управления – контроллером. Контроллер взаимодействует с драйвером – системным программным модулем, управляющим данным устройством.
Контроллер периодически принимает от драйвера выводимую на устройство информацию и команды управления, которые определяют, что делать с этой
Устройство ввода – вывода работает под управлением контроллера в интервалах между выдачей команд независимо от ОС.
От подсистем ввода – вывода требуется спланировать в реальном масштабе времени запуск и приостановку драйверов, обеспечив приемлемое время реакции каждого драйвера на независимые события контролера.
Для этого все драйверы распределяются по нескольким приоритетным уровням в соответствии с требованиями по времени реакции и временными затратами процессорного времени.
Для реализации этого процесса обычно используется диспетчер прерываний ОС.
Согласование скоростей обмена и кэширования данных
При обмене данными возникает задача согласования скоростей. Оно достигается за счет буферизации данных в ОП и синхронизации доступа процессов к буферу.
Но буферизация только на основе ОП в подсистеме ввода – вывода оказывается недостаточной – разница между скоростью обмена с ОП и скоростью работы внешнего устройства оказывается слишком большой. С другой стороны, при больших объемах ввода – вывода ОП просто может не хватить.
Для таких случаев в качестве буфера используется (spool - шпулька). Типичный пример – вывод на принтер. Печать документа в несколько десятков мегабайт – не редкость.
Другое решение проблемы – большая буферная память в контроллерах внешних устройств. Пример – контроллеры графических дисплеев. Их ОП соизмерима с ОП процессора.
Распределение устройств и данных между процессами
Устройства ввода – вывода могут предоставляться процессам, как в монопольном, так и в разделяемом режимах.
ОС должна обеспечивать контроль доступа теми же способами, что и при доступе процессов к другим ресурсам ВС.
ОС может контролировать доступ не только к устройству в целом, но и к отдельным порциям данных. Например, при выводе на графический дисплей – информация по отдельным окнам экрана.
Потому для организации совместного доступа к частям устройства или частям данных непременным условием является задание режима совместного использования устройствам или данных в целом.
ОС предоставляет устройства, отслеживая процедуры захвата и освобождения использования устройств, оптимизируя последовательность операций ввода – вывода для различных процессов в целях повышения общей производительности, если это возможно.
Например, при обмене данными нескольких процессов с дисками можно упорядочить последовательность операций так
Обеспечение удобного логического интерфейса между устройствами и остальной частью системы
Все современные ОС поддерживают в качестве основы такого интерфейса файловую модель периферийных устройств. При таком подходе любое устройство выглядит как набор байт, с которыми можно работать с помощью унифицированных системных вызовов (например, read, write), задавая имя файла – устройства и смещение от начала последовательности байт.
Привлекательность такой модели состоит в ее простоте и унифицированности для устройств различного типа.
Иногда для специальных применений этот интерфейс используется как базовый и требует дополнительной доработки. Например, при программировании операций сетевого обмена или вводе на дисплей графической информации.
Поддержка широкого спектра драйверов и простота включения нового драйвера в систему
Наличие разнообразных драйверов для всех типов внешних устройств является важной характеристикой ОС. Например, такая прекрасная во многих отношениях ОС как ОС/2 была вытеснена ОС Windows благодаря богатству драйверов.
Поэтому открытость интерфейса драйверов, т.е. доступность его описания для независимых разработчиков ПО – необходимое
Драйвер взаимодействует, с одной стороны с модулями ядра ОП (подсистемой ввода – вывода, системными вызовами, управления процессами и памятью), с другой стороны, с контролерами внешних устройств.
Поэтому существует 2 типа интерфейсов:
- драйвер – ядро;
- драйвер – устройство.
Интерфейс драйвер – ядро должен быть стандартизирован в любом случае.
Интерфейс драйвер – устройство имеет смысл стандартизировать тогда, когда подсистема ввода – вывода не разрешает драйверу непосредственно взаимодейсвовать с аппаратурой.
Экранирование драйвера от аппаратуры является весьма полезной функцией, так как драйвер становится независимым от аппаратной платформы.
Для поддержки процесса разработки драйверов к ОС обычно выпускается пакет ДДК (Diver Development Kit), представляющий собой инструментарий – библиотеки, компиляторы и отладчики.
Динамическая загрузка и выгрузка драйверов
Включение драйвера в состав модулей работающей ОС представляет собой самостоятельную проблему.
Так как набор потенциально поддерживаемых данной ОС периферийных устройств всегда шире конкретной системе, то очень ценным свойством ОС является возможность динамически загружать в ОП требуемый драйвер (без останова ОС) и выгружать его после того, как потребность в поддержке устройства миновала. Это может существенно экономить системную область памяти.
Альтернативой динамической загрузке драйверов при изменениях текущей конфигурации внешних устройств является повторная компиляция кода ядра с требуемым набором драйверов, что создает между всеми компонентами ядра статические связи вместо динамических. Изменения в процессе работы ОС невозможны.
Поддержка нескольких файловых систем
Диски – особый род периферийных устройств, так как на них хранится большая часть пользовательских и системных данных. Эти данные организуются в файловые сисемы, свойства которых во многом определяют свойства ОС (отказоустойчивость, быстродействие, макс. объем хранимых данных). Хорошая файловая система обычно «кочует» из одной ОС в другую.
Так файловая система FAT первоначально была разработана для MS-DOS, затем перекочевала в OS/2 и MS Windows (3.1).
Важно, чтобы архитектура подсистемы ввода- вывода позволяла бы достаточно просто включать в ее состав новые типы файловых систем без необходимости переписывания кода.
Для этого в ОС предусматривается специальный слой ПО, который отвечает за решение данной задачи. Например, слой VFS (Virtual File System) в версиях UNIX.
Поддержка синхронных и асинхронных операций ввода – вывода
Операции ввода – вывода могут выполняться в синхронном и асинхронном режимах.
Синхронный режим означает, что процесс, запросивший операцию, приостанавливает свою работу до тех пор, пока операция ввода – вывода не завершится.
При асинхронном режиме процесс выполняется в мультипрограммном режиме одновременно с операцией ввода – вывода.
Подсистема ввода – вывода предоставляет своим клиентам (пользовательским процессам и ядру ОС) возможность выполнять как синхронные, так и асинхронные операции ввода – вывода в зависимости от потребностей вызывающей стороны.
Системные вызовы ввода – вывода чаще оформляются как синхронные процедуры в связи с тем, что такие операции длятся долго и пользовательскому процессу или потоку все равно придется ждать результатов, чтобы продолжить работу.
Внутренние вызовы из модулей ядра ОС выполняются как асинхронные процедуры, так как ядру нужна свобода в выборе дальнейшего поведения после запроса операции ввода – вывода.
Многослойная модель подсистемы ввода – вывода
При большом разнообразии устройств ввода – вывода, обладающих весьма отличающимися позволяет соблюсти баланс между двумя противоречивыми требованиями:
- необходимостью учета всех особенностей каждого устройства;
- единое логическое представление и унифицированный интерфейс для устройств всех типов.
Нижние слои подсистемы ввода – вывода должны включать индивидуальные драйвера конкретных физических устройств, а верхние слои должны обобщать процедуры управления этими устройствами, предоставляя по возможности общий интерфейс.
Менеджер ввода – вывода
Модули подсистемы ввода – вывода, которые организуют согласованную работу всех компонентов подсистемы и взаимодействие с пользовательскими процессами и другими подсистемами ОС образуют как бы оболочку подсистемы.
Эта оболочка называется менеджером ввода – вывода.
Верхний слой менеджера поддерживает пользовательский интерфейс ввода – вывода, т.е. принимает запросы на ввод – вывод и переадресует их драйверам, а также возвращают процессам результаты операций ввода – вывода.
Нижний слой взаимодействует с контроллерами внешних устройств, экранирую драйверы от особенностей аппар ввода – вывода, системы прерываний и т.п. Этот слой принимает от драйверов запросы на обмен данными с регистрами контроллеров в некоторой обобщенной форме с пользованием независимых от шины ввода – вывода адресации и формата, преобразуя эти запросы в формат, понятный аппаратной платформе.
Еще одной функцией менеджера ввода – вывода является организация взаимодействия модулей ввода –вывода с модулями других подсистем ОС, таких как подсистемы управления процессами, виртуальной памятью и др.
Наличие стандартного виртуального межмодульного интерфейса повышает устойчивость и улучшает расширяемость подсистемы ввода – вывода, хотя и замедляет ее работу.
Многоуровневые драйверы.
Традиционные особенности и функции, выполняемые драйвером состоят в следующем:
- входит в состав ядра ОС, работая в привилегированном режиме;
- непосредственно управляет внешним устройством, взаимодействуя с его контроллером с помощью команд ввода – вывода компьютера;
- обрабатывает прерывания от контроллера;
- предоставляет программисту удобный логический интерфейс, экранируя от ненужных деталей и подробностей;
- взаимодействует с другими модулями
Традиционные драйверы н делились на слои. С развитием ОС наряду с традиционными появились высокоуровневые драйверы, которые располагаются над традиционными драйверами. При этом традиционные драйверы стали называть аппаратными. С помощью высокоуровневого драйвера повышается гибкость и расширяемость функций по управлению устройством – вместо жесткого набора функций, которые сосредоточены в низкоуровневом драйвере, администратор ОС может выбрать требуемый набор функций, установив нужный высокоуровневый драйвер.
Если различным приложениям необходимо работать с различными логическими модулями одного и того же физического устройства, то для этого достаточно установить в системе несколько драйверов на одном уровне, работающих над одним аппаратным драйвером.
Количество уровней драйверов обычно не ограничивается. На практике используется от 2 до 5 уровней.
Высокоуровневые драйверы оформляются по тем же правилам и придерживаются тех де внутренних интерфейсов, что и аппаратные драйверы за исключением того, что они не вызываются по прерываниям, так как взаимодействуют
Как общие принципы построения многоуровневых драйверов могут быть реализованы применительно к конкретным устройствам можно рассмотреть на примере управления дисками.
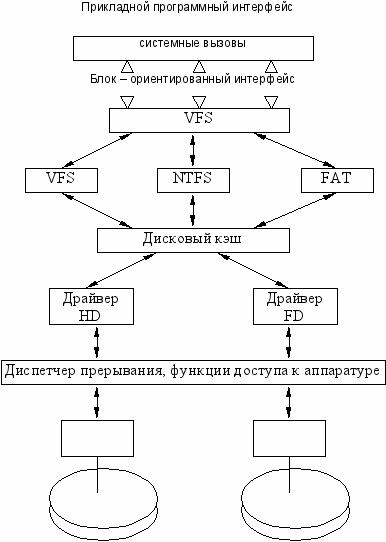
Аппаратные драйверы поддерживают для верхних уровней представление диска как последовательного набора блоков одинакового размера, преобразуя вместе с контроллером номер блока в более сложный адрес из номера цилиндра, головки и сектора. Понятие «файла» и файловой системы аппаратные драйверы не поддерживают
Эти абстракции создаются на более высоком уровне . Они могут поддерживать несколько файловых систем одновременно. Для этого в ОС устанавливается несколько высокоуровневых драйверов (UFS, NTFS, FAT). Они работают с общими аппаратными драйверами, но по-своему организуют файловую систему пользователям и прикладными процессам.
Для унификации представления различных файловых систем может использоваться общий драйвер верхнего уровня VFS(Virtual File System). Такой драйвер используется, например в системах UNIX.
В унификацию драйверов большой вклад внесла ОС UNIX. В ней все драйверы разделены на 2 больших класса; блок – ориентированные и байт – ориентированные.
Например, драйвера графических и сетевых устройств относятся к байт – ориентированным, а драйверы, управляющие устройствами прямого доступа, которые хранят информацию в блоках фиксированного размера, - к блок – ориентированным (диск).
Адресуемость блоков приводят к тому, что для устройств прямого доступа имеется возможность кэширования данных в оперативной памяти. Это влияет на общую организацию ввода – вывода таких устройств.
Специальные файлы
Специальные файлы, называемые иногда наборами данных, которые хранятся на дисках. Они используются для унифицированного представления устройств ввода – вывода.
Со специальным файлом можно работать так же, как и с обычным – открывать, читать или записывать байты, а после завершения операции закрывать.
Для этого используется те же системные вызовы, что и для работы с обычными файлами; open, create, read, write, close.
Традиционно специальные файлы помещаются в каталог /dev, хотя ничто не мешает создать их любом каталоге файловой системы. При появлении нового устройства и, соответственно, нового драйвера администратор системы может создать новую зарись (например, с помощью команды mknod).
Логическая организация файловой системы
Логическая модель файловой системы материализуется в виде дерева каталогов, выводимого на экран, например, с помощью Norton Commander или Windows Explorer, в символьных составных именах файлов и командах работы с файлами.
Цели и задачи файловой системы
Файл – это именованная область внешней памяти в которую можно записывать и из которой можно считывать данные. Обычно файлы хранятся на энергонезависимой памяти – диске. Однако есть и исключения. Например, может быть создан
Основные цели использования файла:
- долговременное и надежное хранение информации;
- совместное использование информации.
Файл может быть создан одним пользователем, а использоваться другим. При этом могут быть определены права доступа к информации.
Файловая система – часть ОС, которая включает;
- совокупность всех файлов на диске;
- наборы структур данных для управления файлами. Каталоги файлов. дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске;
- комплекс системных программных средств, реализующих операции над файлами; создание, уничтожение, запись, чтение именования и поиск файлов.
Файловая система позволяет обходиться набором простых операций над некоторым абстрактным объектом, наз. файлом.
Файловая система экранирует все сложности физической организации долговременного хранения данных и предоставляет набор удобных в использовании команд для манипулирования файлами.
Задачи, которые решает ФС, зависят от способа организации вычислительного процесса в целом. Самый простой тип ФС – однопользовательская, однопрограммная. К их числу принадлежит MS-DOS.
следующие:
- именование файлов;
- программный интерфейс для приложений;
- отображение логической модели файловой системы на физическую организацию хранилища данных;
- обеспечение устойчивости файловой системы к сбоям питания, ошибка аппаратных и программных средств.
Задачи ФС усложняются в однопользовательских мультипрограммных ОС. Примером такой ОС является OS/2. Здесь добавляется новая задача совместного доступа к файлу из нескольких процессов.
В этом случае файл – разделяемый ресурс со всеми вытекающими отсюда проблемами.
В многопользовательских системах добавляется еще одна задача; защита файлов от несанкционированного доступа.
Типы файлов
Обычные файлы – содержат информацию произвольного характера. Большинство современных ОС (UNIX, Windows, OS/2) никак не ограничивают и не контролируют содержимое и структуру файла.
Все ОС должны распознавать хотя бы один тип файлов – их собственные исполняемые файлы.
Каталоги – особый тип файлов. Они содержат системную справочную информацию о наборе файлов, сгруппированных пользователями по какому – либо неформальному признаку (например, один документ и т.п.).
Во многих ОС в каталог могут входить
для поиска.
Специальные файлы - это фиктивные файлы, ассоциированные с устройствами ввода – вывода. Они используются с целью унификации механизма доступа к файлам и внешним устройствам. Специальные файлы позволяют пользователю выполнять операции ввода – вывода посредством обычных команд записи в файл или чтения из файла. Эти команды обрабатываются сначала программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются ОС в команды управления соответствующим устройством.
Иерархическая структура файловой системы
Большинство файловых систем имеет иерархическую структуру, в которой уровни создаются за счет того, что каталог более низкого уровня может входить в каталог более высокого уровня.
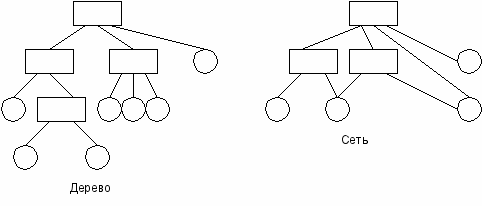
Граф описывающий иерархию каталогов может быть деревом или сетью. если файлу разрешено входить только в один каталог, файлы образуют дерево. Сеть – файл может входить сразу в несколько каталогов.
Например, в MS – DOC и Windows каталоги образуют древовидную структуру, а в UNIX – сетевую.
В древовидной структуре каждый файл является листом. каталог самого верхнего уровня называется корневым каталогом или корнем.
Имена файлов
В файловых системах используется три типа имен файлов: простые, составные и относительные.
Простое (короткое, символьное) имя идентифицирует файл в пределах одного каталога. Эти имена присваивают пользователи с учетом ограничений ОС. Мак в файловой системе FAT длина имени ограничивается схемой 8.3 (8 символов имя, 3-расшинение), а в файловых системах NTFS и FAT32, входящих в состав ОС Windows NT, имя файла может содержать до 255 символов.
В иерархических файловых системах разным файлам разрешено иметь одинаковые простые символьные имена при условии, что они принадлежат разным каталогам.
Для однозначной идентификации в таких системах используется так наз. полное имя.
Полное имя представляет собой цепочку через которые проходит путь от корня до данного файла.
В древовидной файловой системе между файлом и его полным именем имеется взаимно однозначное соответствие один файл – одно полное имя.
В случае сетевой структуры имеет место соответствие: один файл – много полных имен.
Файл может быть также идентифицирован относительным именем. Оно образуется через понятие текущий каталог. ОС фиксирует имя текущего каталога и использует его как «добавку» к полному имени, используя относительное имя. Например. текущий каталог USER относительное имя main.exe. Полное имя USER/main.exe.
Монтирование
Вычислительная система может иметь несколько дисковых устройств. Более того, одни физическое устройство может иметь несколько логических дисков.
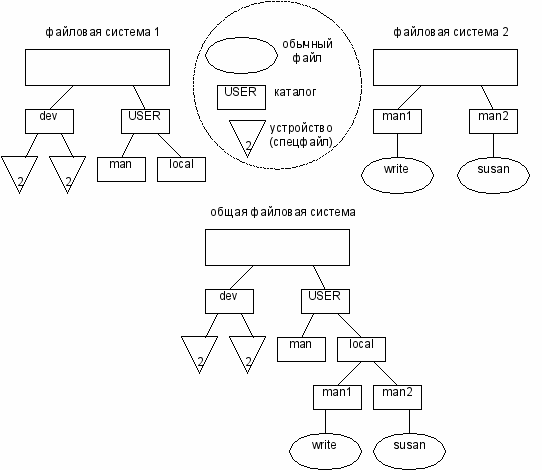
Возникает проблема хранения файлов в системе, которая имеет несколько устройств внешней памяти.
Первое решение. На каждом из устройств размещается автономная файловая система. Т.е. имеется два независимых дерева каталогов. Здесь в полное имя файла входит идентификатор соответствующего логического
Второе решение. Файловые системы объединяются в единую файловую систему, которая описывается единым деревом каталогов.
Такая операция наз. монтированием.
При этом ОС выделяет одно дисковое устройство, называемое системным. Пусть имеется де файловые системы, расположенные на разных логически дисках, причем одни из них является системным.
Файловая система. расположенная на системном диске, назначается корневой. для связи иерархий файлов в корневой файловой системе выбирается некоторый существующий каталог. После выполнения монтирования выбранный каталог становится корневым каталогом второй файловой системы. Через этот каталог монтируемая файловая система подсоединяется как поддерево к общему дереву.
Атрибуты файлов
Атрибуты –информация, которая описывает свойства файла. Примеры возможных атрибутов:
- тип файла (обычный файл, каталог, спецфайл);
- владелец файла;
- создатель файла;
- пароль для доступа к файлу;
- информация о разрешенных операциях доступа к файлу;
- времена создания, последнего доступа и последнего изменения;
- текущий размер файла;
- максимальный размер файла;
- признак «только для чтения»;
- признак «скрытый файл»;
- признак «системный файл»;
- признак «архивный файл»;
- признак «двоичный/символьный»;
- признак «временный» (удалить по завершении процесса);
- признак блокирования;
- признак записи в файл;
- указатель на ключевое поле в записи;
- длина ключа.
Конкретный перечень атрибутов определяется спецификой файловой системы.
сделано в MS-DOS
| 8 | 3 | 1 | 4 | ||||
| Имя файла | Расширение | R | A | H | S | Резервные | |
| Резервные | Время | Дата | Номер первого набора | Размер | |||
Другим вариантом является размещение атрибутов в специальных таблицах, когда в каталогах содержатся только ссылки на эти таблицы. В такой файловой системе (ОС UNIX) структура каталога очень простая
| 2 | 14 |
| № индексного дескриптора | Имя файла |
Индексный дескриптор файла – таблица, в которой сосредоточены значения атрибутов файла. Такая система более гибкая. Файл может быть включен сразу в несколько каталогов.
Логическая организация файла
Признаками, отделяющими один структурный элемент от другого, могут служить определенные кодовые последовательности или просто известные программе значения смещений этих структурных элементов относительно начала файла. Поддержание структуры данных может быть либо целиком возможно на приложение, либо в той или иной степени эту работу может на себя брать файловая система.
В первом случае файл представляется ФС неструктурированной последовательностью данных. Приложение формулирует запросы к файловой системе на ввод – вывод, используя общие для всех приложений системные средства, например, указывая смещения от начала файла и количество байт, которые необходимо прочесть или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью (потоком) байт, широко используется в большинстве современных ОС (MS-DOS, Windows NT/2000). Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями: разные приложения могут по-своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл. Эта модель применялась ранее (в OS/360). Поддержание структуры файла обеспечивается файловой системой. Она видит файл как упорядоченную последовательность логических записей.
Приложение может обращаться к ФС с запросами на ввод – вывод на уровне записей. Например, считав запись 25 из файла FILE.DOC ФС обладает информацией о структуре файла достаточной для того, чтобы выделить любую запись. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением.
Развитием этого
поддерживают сложные структуры данных и взаимосвязи между ними.
Логическая запись – наименьший элемент данных которым оперирует программист при обмене с внешним устройством.
ФС может обеспечивать два способа доступа к логическим записям:
- последовательный доступ;
- прямой доступ (позиционируется файл на конкретную запись)
Физическая организация файловой системы
Представление о файловой системе как об иерархически организованном множестве информационных объектов имеет мало общего с фактическим порядком хранения файлов на диске.
Файл может быть разбросан «кусочками» по всему диску. Логически объединенные файлы из одного каталога совсем не обязательно соседствуют на диске.
Принципы размещения файлов, каталогов и системной информации на реальном устройстве описываются физической организацией файловой системы.
Основным носителем является жесткий диск, который состоит из пакета пластин.
На каждой стороне пластины размещены тонкие концентрические кольца - дорожки (tracks), на которых хранятся данные, Количество дорожек зависит от типа диска. Нумерация дорожек начинается с 0 от внешнего края в центру. Когда диск вращается, головка считывает данные с магнитной дорожки или записывает их на дорожку.
дискретными шагами. Каждый шаг сдвигается на 1 дорожку. В некоторых дисках вместо одной головки имеется по головке на каждую дорожку.
Совокупность дорожек одного радиуса на всех поверхностях всех пластин называется цилиндром (cylinder). Каждая дорожка разбивается на фрагменты, называемые секторами (sectors) или блоками (blocks).
Все дорожки имеют равное число секторов, в которых можно максимально записать одно и то же число байт.
Сектор имеет фиксированный для конкретной системы размер, выражающийся степенью двойки. Чаще всего – 512 байт. Поскольку дорожки разного радиуса имеют одинаковое число секторов, плотность записи на дорожках различна – больше к центру.
Сектор – наименьшая адресуемая единица обмена данными с оперативной памятью.
Для того, чтобы контроллер мог найти на диске нужный сектор, необходимо задать ему все составляющие адреса сектора; номер цилиндра, номер поверхности и номер сектора.
Так как прикладной программе нужен не сектор, а некоторое количество байт, не обязательно кратное размеру сектора, типичный запрос включает чтение нескольких секторов, которые содержат требуемую информацию и одного или двух секторов с избыточными данными.
ОС при работе с диском использует собственную единицу дискового пространства, которое называют кластером. При создании файла на диске место ему выделяется кластерами. Например, размер кластера может быть равен 1024 байт.
Дорожки и сектора создаются в результате выполнения процедуры физического (или низкоуровневого)
Форматирование предшествует использованию диска.
Для определения границ блоков на диск записывается идентификационная информация.
Низкоуровневый формат диска не зависит от типа ОС, которая этот диск использует.
Разметку диска под конкретный тип файловой системы выполняют процедуры высокоуровневого или логического форматирования. При этом определяется размер кластера и записывается информация, необходимая для работы файловой системы, в том числе информация о доступном и неиспользуемом пространстве, о границах областей, отведенных под файлы и каталоги о поврежденных областях. Кроме того, на диск записывается загрузчик ОС – программа (обычно небольшая), которая начинает процесс инициализации ОС после включения питания.
Прежде, чем форматировать диск под определенную файловую систему он может быть разбит на разделы.