
1. понятие архитектуры вычислительной системы
| Вид материала | Документы |
- Реферат по курсу «Микропроцессорные системы» на тему «Распределенные вычислительные, 377.31kb.
- Тема отчётность, 87.45kb.
- 1. Этапы развития вычислительной техники и программного обеспечения, 1182.63kb.
- Лекция Понятие архитектуры вс и ЭВМ, 87.83kb.
- Комплекс программ, предназначенный для обеспечения определенного уровня эффективности, 735.51kb.
- Лекция 5 (4 часа). Раздел Архитектура предприятия, 242.66kb.
- Лекции концептуальные основы ос» Тема лекции концептуальные основы ос», 188.78kb.
- Программа по специальным дисциплинам: по дисциплине «Деньги, кредит, банки»: Тема., 288.06kb.
- Программа по специальным дисциплинам: по дисциплине «Деньги, кредит, банки»: Тема., 289.08kb.
- Программа дисциплины по кафедре Вычислительной техники микропроцессорные системы, 464.96kb.
1. ПОНЯТИЕ АРХИТЕКТУРЫ ВЫЧИСЛИТЕЛЬНОЙ
СИСТЕМЫ
Появление серийно выпускаемых сверхбольших надежных и дешевых интегральных схем, массовое производство микропроцессоров, возобновившийся интерес к разработке языков программирования и программного обеспечения порождают возможность при проектировании компьютеров качественно продвинуться вперед за счет улучшения программно аппаратного интерфейса, т. е. семантической связи между возможностями аппаратных средств современных ЭВМ и их программного обеспечения. Организация вычислительной системы (ВС) на этом уровне лежит в основе понятия "архитектура". Для неспециалистов в области программного обеспечения термин "архитектура" ассоциируется, как правило, со строительными объектами. И здесь, как увидим далее, есть много общего.
Действительно, архитектура компьютера, характеризующая его логическую организацию, может быть представлена как множество взаимосвязанных компонент, включающих, на первый взгляд, элементы различной природы: программное обеспечение (software), аппаратное обеспечение (hardware), алгоритмическое обеспечение (brainware), специальное фирменное обеспечение (firmware) – и поддерживающих его слаженное функционирование в форме единого архитектурного ансамбля, позволяющего вести эффективную обработку различных объектов.
С другой стороны, архитектура может быть задана как абстрактное многоуровневое представление физической системы с точки зрения программиста, с закреплением функций за каждым уровнем и установлением интерфейса между различными уровнями.
Знание особенностей разнообразных архитектурных решений дает возможность пользователям компьютеров эффективно распоряжаться всеми предоставляемыми ресурсами, осуществляя их направленный выбор и тем самым повышая эффективность обработки данных.
1.1. Архитектура как набор взаимодействующих компонент
Ранее область применения вычислительных систем определялась ее быстродействием. Однако существует достаточно большое количество ВС, обладающих равным быстродействием, но имеющих совершенно разные способы представления данных, методы организации памяти, режимы работы, системы команд, набор ВнУ и т. д. Таким образом, ВС имеет, кроме быстродействия, ряд других характеристик, необычайно важных в той или иной области применения. Это стало особенно заметно при переходе к ВС четвертого и пятого поколений. Совокупность таких характеристик и легла в основу понятия архитектуры ВС.
Архитектура ВС определяет основные функциональные возможности системы, сферу применения (научно техническая, экономическая, управление и т. д.), режим работы (пакетный, мультипрограммный, разделения времени, диалоговый и т. д.), характеризует параметры ВС (быстродействие, набор и объем памяти, набор периферийных устройств и т. д.), особенности структуры (одно , многопроцессорная) и т. д. Составные части понятия "архитектура" можно определить следующей схемой (рис. 1.1).
Р

ис. 1.1. Функциональные возможности ВС
Вычислительные и логические возможности ВС. Они обусловливаются системой команд (СК), характеризующей гибкость программирования, форматами данных и скоростью выполнения операций, определяющих класс задач, наиболее эффективно решаемых на ВС. Система команд ВС, базирующихся на архитектуре фон Неймана, сегодня мало чем отличается от СК ЭВМ 50 х годов. Большинство достижений в этой области остались незамеченными проектировщиками и соответственно не нашли адекватного воплощения в архитектуре современных компьютеров.
Анализ показывает, что в различных программах чаще всего встречаются достаточно простые команды: команды пересылки и команды процессора с использованием регистров и простых режимов адресации. Не нашли широкого применения и нетрадиционные способы кодирования данных, несмотря на значительные возможности их в плане разработки быстродействующих алгоритмов арифметических операций. Среди них знакоразрядные системы, системы в коде вычетов и др.
Рассмотрим структуру системы команд в зависимости от класса решаемых задач (рис. 1.2).
К командам управления мы относим команды ввода-вывода данных и команды управления состоянием процессора, памяти и каналов.
Как видно из рис. 1.2, для решения задач любого класса необходимы
Р
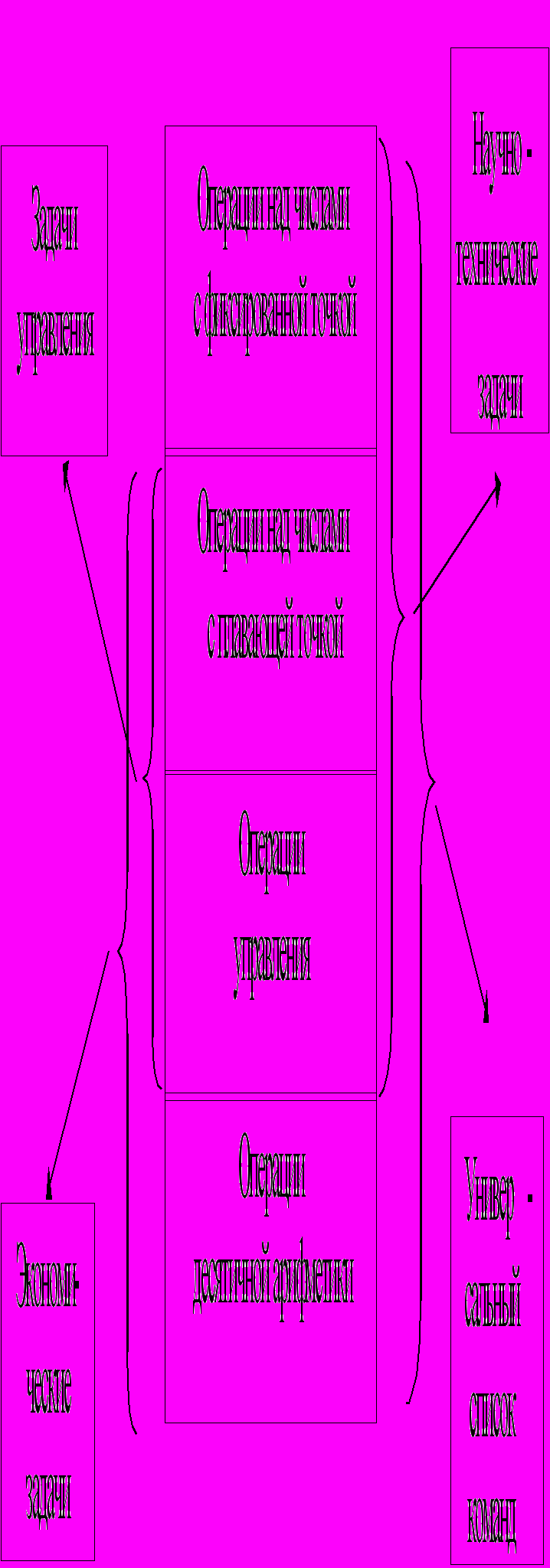
ис. 1.2. Классификация СК по назначению
команды типов 2 и 3. Следовательно, эти типы команд должны присутствовать в любом компьютере.
Большое влияние на точность выполнения операций оказывают форматы данных. Современные компьютеры имеют развитую систему форматов. Например, компьютеры фирм ЕС ЭВМ и IВМ имеют форматы в 2, 4, 8 и 16 байт.
Алгоритмы выполнения операций достаточно полно отражают производительность только однопроцессорных ВС.
Аппаратные средства. Простейшая ВС включает модули пяти типов: центральный процессор, основная память, каналы, контроллеры и внешние устройства.
Процессор (УУ + АЛУ + память) управляет работой системы и обеспечивает вычисления непосредственно по программе. Выполнение машинных команд, команд ввода-вывода (I/О), обращение к памяти, управление состоянием устройств инициализируются или выполняются с помощью процессора.
Основная память предназначена для хранения команд и данных и обеспечивает адресный доступ к ним от процессора. Современная память работает со скоростью, близкой к скорости работы процессора.
Каналы – спецустройства, управляющие обменом данных с внешними устройствами. Каналы инициируют свою работу с помощью процессора и затем переходят в автономный режим работы. Это, по сути, спецпроцессор ввода – вывода, обеспечивающий работу внешних устройств, контроль информации и т. д.
Контроллеры ввода-вывода служат для подсоединения внешних устройств (ВнУ) к каналам и обеспечивают обмен управляющей информацией с внешними устройствами, присвоение приоритетов и выдачу информации о состоянии ВнУ для канала, т. е. это устройства управления ВнУ.
ВнУ служат для ввода-вывода информации с различных носителей.
П

амять может быть организована как многоуровневая с различным объемом и временем доступа к ней – сверхоперативная (СОЗУ), оперативная (ОП), внешняя (ВнП) (рис. 1.3), так и одноуровневая, виртуальная. Почти всегда виртуальная память есть переупорядоченное подмножество реальной памяти.
Рис. 1.3. Типы памяти (V – объем, S – быстродействие)
Уровни иерархии памяти взаимосвязаны между собой: все данные одного уровня могут быть найдены на более низком уровне.
Успешное или неуспешное обращение к уровню памяти называют соответственно попаданием (hit) или промахом (miss), а соответствующее время – временем обращения (hit time или miss penalty).
Существенное влияние на производительность ВС оказывают каналы ввода-вывода. Мультиплексный канал обеспечивает работу группы медленных устройств, блок-мультиплексный – группы быстрых устройств, селекторный – монополизирует информационную магистраль только одним быстродействующим устройством.
Для повышения пропускной способности каналов используют некоторые дополнительные меры, например буферизацию ВнУ путем введения памяти в состав самого устройства или контроллера.
Аппаратные средства защиты памяти служат для управления доступом к различным областям памяти в соответствии с имеющимися у пользователя полномочиями.
Программное обеспечение. Оно является составной частью архитектуры компьютера и существенно влияет на весь вычислительный процесс, в частности позволяет эффективно эксплуатировать аппаратные средства системы.
Операционная система (ОС) управляет ресурсами, разрешает конфликтные ситуации, оптимизирует функционирование системы в целом.
Широкий спектр языков программирования позволяет описывать практически любые задачи, а разнообразие компиляторов – их эффективно реализовывать.
Роль прикладного программного обеспечения (ПО) необычайно велика для решения тематических задач.
1.2. Архитектура как интерфейс
между уровнями физической системы
П
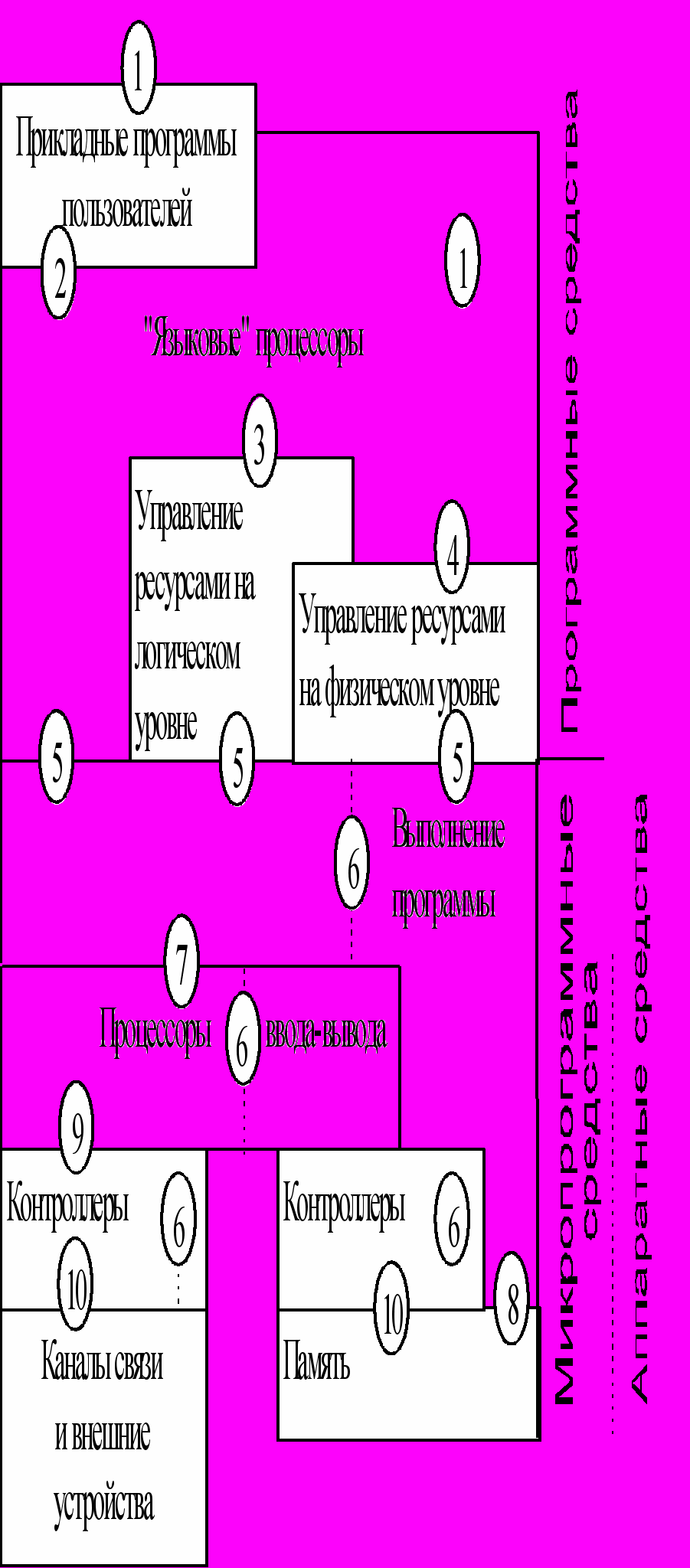
рименительно к ВС термин "архитектура" может быть определен как распределение функций, выполняемых системой, по различным уровням и установление интерфейса между этими уровнями. На рис. 1.4 представлен набор уровней абстракции как специфического свойства архитектуры ВС. Остановимся лишь на ключевых уровнях.
Рис. 1.4. Многоуровневая организация архитектуры
вычислительной системы
Архитектура первого уровня определяет, какие функции по обработке данных решаются системой, а какие передаются внешнему миру: пользователю, оператору ЭВМ, администратору баз данных и т. д. Система взаимодействует с внешним миром через два набора интерфейсов: языки (язык программирования, язык оператора терминала, язык управления заданиями, язык общения с базой данных, язык оператора ЭВМ) и системные программы (программы редактирования, связи, оптимизации, восстановления и обновления информации, интерпретации, управления и т. д., т. е. программы, созданные разработчиком системы). Оба интерфейса должны быть созданы при разработке архитектуры системы.
Уровни, определяемые интерфейсами внутри программного обеспечения, могут быть представлены как архитектура программного обеспечения. К примеру, если прикладные задачи реализованы на языках программирования, которые не входят в набор языков, предоставляемых системой пользователю, то здесь речь может идти об архитектуре уровня, позволяющего определить указанные языки.
Уровень 5 является одним из центральных уровней архитектуры и проводит разграничение между системным программным и аппаратным (т. е. схемным и микропрограммным) обеспечением. Он позволяет представить физическую структуру системы независимо от способа реализации.
Остальные уровни отражают интерфейсы и распределяют функции между отдельными частями физической системы.
Таким образом, можно сказать, что архитектура компьютера – это абстрактное представление физической системы с точки зрения программиста.
Процесс разработки архитектуры ЭВМ включает все этапы разработки типовых проектов:
- анализ требований, предъявляемых к системе;
- составление спецификаций;
- изучение известных решений;
- разработку функциональной схемы;
- разработку структурной схемы;
- отладку проекта;
- оценку проекта.
При анализе требований, например, мы учитываем спектр необходимых языков программирования, способ взаимодействия с окружающей средой, требования к операционной системе, некоторые технико экономические факторы: количество таких систем (ибо это существенно влияет на соотношение между аппаратным и программным обеспечением), совместимость разрабатываемой системы (по языкам программирования, операционным системам, форматам данных, техническим устройствам) с существующими аналогичными вычислительными системами и т. д.
При анализе требований и составлении перечня спецификаций параметров системы необходимо разработать критерии (с их весовыми коэффициентами), определяющие стоимость, надежность, защиту от несанкционированного доступа, совместимость и т. д. и описать функции системы в соответствии с этими критериями. В спецификациях учитывается и существующий или достижимый технологический уровень для производства системы. Естественно, что возникающие противоречивые требования должны быть разрешены в соответствии с приоритетами или на другой основе.
На этапе разработки функциональной схемы необходимо в первую очередь решить вопрос о разграничении функций между аппаратурой и программным обеспечением, а также между другими уровнями архитектуры. Здесь же решаются вопросы о необходимости работы с плавающей или фиксированной точкой, о приоритетных прерываниях, о стековой организации памяти и т. д.
При структурной организации все вопросы детализируются и углубляются. В частности, здесь решаются проблемы типов и форматов команд, способов представления данных, способов адресации, семантики языка.
При завершении проекта идет его отладка, согласование взаимодействия отдельных уровней и оптимизация, например, по количеству битов, пересылаемых между процессором и памятью при выполнении данной программы, отысканию эффективного метода кодирования команд и числовой информации и т. д.
И наконец – оценка проекта. Простая оценка быстродействия (которое иногда понимается как производительность) мало что определяет. Здесь необходимо учитывать время, затраченное на разработку программы. Используя известные статистические данные о том, что преобладающее количество разработанных программ выполняется только один раз, простота программирования при оценке архитектуры может оказаться важнее скорости выполнения команд.
Однако скорость выполнения операций – важный параметр. Быстродействие, естественно, зависит как от технологической элементной базы, влияющей на скорость обработки данных, так и от архитектуры машины, которая определяет объем выполняемых работ. Часто архитектуры сравниваются по критерию эффективности обработки информации. Для этого, как правило, анализируют следующие параметры:
S – размер программы, определяемый длиной команд, размером косвенных адресов, объемом рабочих областей для временного размещения
данных;
Np – количество битов, передаваемых между процессором и памятью машины (пересылка между регистрами) за время выполнения программы, характеризующее интерфейс, т. е. "полосу пропускания" между процессором и памятью, что в значительной степени определяет предел эффективности выполнения программ. Ясно, что параметр должен учитывать и локальность ссылок, т. е. близость расположения в памяти используемых данных;
NR – количество битов, передаваемых между внутренними регистрами процессора за время выполнения программы. Здесь учитываются те пересылки, которые не охватывает параметр Np. Значение NR в значительной части определяется набором функций, воплощенных в АЛУ и в схемной реализации процессора.
Иногда архитектуры сравнивают лишь по параметрам S и Np, исключая параметр NR, игнорируя тем самым внутренней организацией процессора.
1.3. Семантический разрыв между архитектурными решениями ЭВМ и его программным окружением
Все характерные особенности архитектуры большинства сегодняшних компьютеров появились уже к 1960 г. Среди них индексные регистры, регистры общего назначения, данные в форме с плавающей точкой, косвенная адресация, программные прерывания, асинхронный ввод-вывод, виртуальная память, мультипроцессорная обработка.
В основном сегодняшние компьютеры отличаются от прежних лишь стоимостью, надежностью, быстродействием и элементной базой. Концептуальные возможности не претерпели существенных изменений.
При анализе особенностей архитектурных решений возникают следующие вопросы:
- оптимальны ли на все времена архитектурные решения, предложенные в 50–60 х годах?
- достаточные ли изменения претерпела технологическая база (аппаратная и теоретико концептуальная), чтобы считать оправданными изменения архитектуры компьютеров?
Рассмотрим архитектурные решения, базирующиеся на концепции фон Неймана, и в первую очередь различия принципов, которые лежат в основе современных языков программирования (ЯП) высокого уровня, и принципов, определяющих архитектуру ЭВМ.
Этот феномен известен как семантический разрыв. Как правило, современные компьютеры имеют нежелательно большой семантический разрыв между объектами и операциями, описываемыми в ЯП, и объектами манипулирования и соответствующими операциями, реализуемыми архитектурой ВС. Обобщая, можно говорить о семантическом разрыве между архитектурой машины и средой использования.
Все это порождает ряд проблем: высокая стоимость разработки ПО, его ненадежность, большой объем программ, сложность компиляторов и ОС, наличие отступлений от правил построения ЯП.
Для уяснения семантического разрыва можно проанализировать взаимосвязи между каким нибудь ЯП (например, ПАСКАЛЬ, С++, DELPHI, PL/1) и архитектурой ЭВМ, скажем с архитектурными решениями наиболее распространенных у нас компьютеров фирмы IВМ, и оценить "расстояние" между принципами, положенными в основу ЯП, и соответствующими принципами, положенными в основу архитектуры ЭВМ.
Попробуем сравнить несколько основополагающих принципов языка PL/1, широко используемых в ВС, с идеологией mainframe и определить адекватность их принципам, заложенным в IВМ 370.
Массивы. Это наиболее часто используемый тип организации данных. PL/1 позволяет использовать многомерные массивы, обращение к отдельным элементам массива посредством индексов, операции над целыми массивами, обращение к отдельным подмассивам внутри массива, защиту от выхода за пределы соответствующего массива. В языке АДА, например, имеется возможность соединения массивов.
Исследование архитектуры IВМ 370 показывает, что в ней нет средств, адекватных описываемым принципам работы с массивами, за исключением разве что примитивного подобия одного из принципов языка – использование индексных регистров. Следовательно, реализация принципа организации данных в виде массива возлагается на компилятор, в распоряжении которого имеется лишь набор команд IВМ 370, весьма далекий по своим возможностям от задач, возникающих при работе с массивами.
Структуры. Это второй из часто используемых типов организации данных в виде наборов разнородных элементов данных (в некоторых ЯП называемых записями). И здесь в системе IВМ 370 отсутствуют средства, адекватные структурам и операциям над ними.
Строки. В PL/1 используются строковые данные (или просто строка). Допустимые операции: слияние, выделение заданной части (подстроки), поиск строки по заданной подстроке, определение длины текущей строки, проверка присутствия одной строки в другой строке. Подобные возможности в системе команд IВМ 370 не предусмотрены. Более того, задача манипулирования строками битов (возможность, предоставляемая PL/1) осложняется еще и тем, что в IВМ 370 допускается адресация к группам из 8 бит, т. е. к байтам. И опять-таки все это надо реализовывать через компилятор, что существенно усложняет его работу.
Процедуры. При вызове процедуры требуется сохранить состояние текущей процедуры, динамически назначить память для локальных переменных вызванной процедуры, передать параметры и инициализировать выполнение вызванной процедуры. Что есть в архитектуре IВМ 370? Только команда BALR (переход с возвратом). Но вклад этой команды в реализацию операций вызова процедуры настолько мал, что ее отсутствие осталось бы незамеченным. Компилятор мог бы заменить ее двумя командами: LA (загрузка адреса) и BR (переход безусловный).
Ясно, что эти трудности по несоответствию принципов ЯП и архитектуры должны реализовываться за счет сложного компилятора.
Важно также сравнить имеющийся семантический разрыв с частотой использования соответствующих операций, предоставляемых ЯП. Из литературы известно, что 45 % всех арифметических операторов имеют дело с массивом или элементом массива, 16 % всех выполняемых операторов языка высокого уровня – это обращение к подпрограммам процедурам, подпрограммам функциям и операторы возврата. Компилятор с ФОРТРАНА, например, тратит до 15 % своего времени на установление связей между подпрограммами. Другие исследования говорят, что 19 % всех операторов программы составляют операторы CALL, RETURN, PROCEDURE.
Подобным образом можно проанализировать семантический разрыв между ЭВМ и операционной системой. В частности, понятие процесса как принципа обработки в системах параллельного действия никак не отражается в архитектуре компьютера, а все вопросы, связанные с синхронизацией процессов, решаемые через семафоры, критические секции, мониторы и передачи сообщений, не нашли своего воплощения в интерфейсе ЭВМ.
Значительный разрыв существует между архитектурой ЭВМ и принципами построения программного обеспечения. Известно, например, что около 50 % всех ресурсов тратится на тестирование и отладку программ, однако архитектура ЭВМ дает ничтожные средства для этого, хотя для надежности аппаратных средств создаются весьма существенные разработки.
Семантический разрыв между архитектурой и организацией памяти программисту заметить труднее. Однако такой вопрос, как разный тип адресации в зависимости от того, где хранятся данные, проанализировать достаточно просто. Действительно, для оперативной памяти осуществляется линейное смещение, добавляемое к адресу, хранимому в спецрегистре, а для данных на магнитном диске используются номер диска, цилиндра, дорожки и линейное смещение в пределах записи. То же имеем и при выполнении операции. Так, операция умножения может быть выполнена непосредственно, если оба операнда находятся в ОП, если же они на НМД, то необходимо предварительно скопировать их в оперативную память. И так как эти принципы не заложены в архитектуре, то имеющийся разрыв программистам приходится обходить при создании ЯП за счет моделирования организации памяти. Виртуальная память создает лишь иллюзию решения проблемы.
Изложенные и другие проблемы семантического разрыва, не разрешенные в архитектуре ЭВМ, ухудшают надежность программного обеспечения, увеличивают непроизводительные затраты и перекладывают их разрешение на компилятор, а последний, как правило, на плечи прикладного программиста из за отсутствия удачных и оптимальных решений во время компиляции. Это, например, происходит, если идет обращение к переменной, значение которой не определено, или к элементу массива, один из индексов которого выходит за соответствующие пределы.
Семантический разрыв требует для своего разрешения через компилятор значительных затрат машинного времени и памяти.
Так, компилятор языка PL/1 фирмы IВМ генерирует 17 машинных команд для реализации оператора
C(I,J) = A(I,J) + B(I,J),
где А, В и С – массивы двоичных элементов одинакового размера в форме с фиксированной точкой.
Если подсоединяется средство контроля данной операции, то компилятор генерирует уже 75 машинных команд, а время выполнения оператора вырастает в 3 раза. Такой же контроль может быть выполнен компьютером без затрат дополнительной памяти и времени, если реализовать на более быстродействующей машине аппаратный контроль.
Здесь впору сказать об экономии памяти для хранения сгенерированных компилятором команд (объектного кода), а также обсудить объем пересылок между памятью и процессором. И хотя бытует мнение, что проблема "памяти" скоро исчезнет, проблема эта существует. Во-первых, из-за ее дороговизны (стоимость основной памяти микропроцессорной системы значительно превосходит стоимость процессора), а во-вторых, потребность в памяти растет пропорционально снижению ее стоимости.
Все изложенное делает очевидным семантический разрыв между архитектурой компьютера и принципами, определяющими построение компиляторов. Чтобы эффективно ликвидировать существующий семантический разрыв, необходимо делать компилятор очень сложным.
Естественно, существующий разрыв можно уменьшить или устранить вообще за счет усложнения архитектуры ЭВМ. Ясно, что если ЭВМ имеет не один, а несколько компиляторов и каждый из них содержит такие средства, как вызов процедур, описание массивов и т. д. (а это почти всегда так), то выгодно ликвидировать этот разрыв один раз за счет соответствующей модификации архитектуры машины, даже если других преимуществ и не будет.
Семантический разрыв порождает и некорректное использование языка программирования. Так, если в PL/1 мы объявляем переменную B как DCL B DECIMAL FIXED (2), т. е. двухразрядной десятичной с фиксированной точкой, а при использовании оператора присваивания напишем В = 200, то естественно ждать сообщение об ошибке. Но его нет. И при выводе на печать значения B мы получим 200. Все дело в том, что система IBM 370 может представлять десятичные числа, имеющие только нечетное количество цифр. Чтобы при полном устранении семантического разрыва не прийти к генерированию неэффективных объектных кодов, компилятор преобразует двухразрядные десятичные переменные в трехразрядные операнды машины. Если бы мы изменили соответствующие правила языка PL/1, то язык стал бы машинно-зависимым, с ориентацией на IBM 370.
Тот же вариант некорректности может возникнуть при работе с десятичными и двоичными числами, использование которых допускает язык PL/1. Программисты иногда применяют двоичные числа вместо десятичных, ибо первые занимают меньше памяти, не требуют преобразования данных, а операции над ними выполняются быстрее, чем над десятичными. Следовательно, архитектура используемого компьютера приводит к некорректному применению языка программирования.
Подобные некорректности можно найти и в других ЯП. Например в языке ФОРТРАН условный оператор IF имеет три точки перехода: = 0, > 0, < 0. Но это не широкие возможности языка, а зависимость его от архитектуры IBM 704, где встроенная операция сравнения в зависимости от результата своего выполнения передает управление одной из трех последующих команд.
В языке АДА для повышения надежности программирования тоже введен ряд компромиссов и ограничений при использовании современных ЭВМ, чтобы ошибки, появляющиеся, например, из за применения в арифметических операциях несовместимых операндов или обращения за допустимое адресное пространство, было возможно выявить на стадии компиляции.
Как следствие семантического разрыва – низкая производительность при проектировании программ. Создатель прикладного ПО тратит больше времени на управление памятью и пересылку данных, чем на собственную их обработку. Последние исследования показывают, что каждый 20 й оператор в PL/1 программах – это ввод и вывод информации.
Совершенствование архитектуры компьютера по устранению семантического разрыва также ограничено принципами построения, например, архитектуры процессора. Так, в случае реализации параллелизма при организации процессора используются только два варианта обработки: мультипроцессорный и поточный. Причем мультипроцессорная обработка решает проблему лишь частично из за сложности выделения независимых фрагментов программы, которые можно выполнять параллельно (задача декомпозиции), трудностей синхронизации взаимодействующих процессов и перекрытия областей памяти.
1.4. Анализ архитектурных принципов фон Неймана
Архитектурные принципы фон Нейманом формулировались примени-тельно к созданию автоматического устройства для решения дифферен-циальных уравнений.
Основные характеристики архитектуры фон Неймановского типа следующие:
- последовательно адресуемая единственная память линейного типа для хранения программ и данных;
- команды и данные различаются через идентификатор неявным способом лишь при выполнении операций. Принимаемые по умолчанию соглашения типа: операнды операции умножения – это данные, а объект, на который указывает команда перехода – это команда, позволяют обращаться с командой как с данными, например, для ее модификации;
- назначение данных определяется лишь логикой программы, так как в памяти машины набор бит может представлять собой как десятичное число с фиксированной точкой, так и строку символов.
Указанные свойства были исключительно важными для своего времени. Однако появление языков высокого уровня (ЯВУ), новых методов решения, логических способов ускорения операций, более совершенной элементной базы требует наряду с имеющимися возможностями архитектуры и принципиально новых. Среди них требования ЯВУ имеют следующие особенности:
- память состоит из набора дискретных именуемых переменных. Вовсе не требуется, например, чтобы память для значений переменных одной программы располагалась рядом с памятью для значений переменных другой программы. Таким образом, принцип единственной последовательной памяти имеет мало общего с организацией памяти в ЯВУ;
- ЯВУ наряду с линейными данными оперируют и с многомерными: массивами, структурами, списками;
- в ЯВУ четко разграничены операции и данные;
- данные определяют и операции над ними.
Например, смысл операции A + C определяется описанием A и С. Cемантика операции "+" совершенно различна, например, для целых чисел и символьных переменных.
Архитектура фон Неймана плохо ориентирована на выполнение программ на ЯВУ. Действительно,
- объем кодов, генерируемых компилятором, из за несоответствия требуемой ЯВУ и предлагаемой архитектурой организации памяти значительно превосходит необходимый объем для решения запрограммированной задачи;
- примитивность выполняемых операций в объектном коде требует сложной работы компилятора.
К сожалению, ЯВУ имитируют в своей структуре архитектуру фон Неймановского типа: переменные – пассивное ЗУ; оператор присваивания – арифметическое устройство (АУ); последовательное выполнение операторов управления (IF, GOTO) – устройство управления (УУ).
Много сложностей из за работы компьютера в двоичной системе. Как отразится на экране дисплея вводимое десятичное вещественное число? Не будет ли потерь в младшем разряде?
Язык АДА, особенно беспокоящийся о точности вычислений, также не ушел от аппроксимации десятичных вещественных чисел двоичными.
Общая взаимосвязь между ЯВУ и ЭВМ в зависимости от уровня языка машины может быть представлена следующей схемой (рис. 1.5).
Введение программно адресуемых регистров (так называемых регистров общего назначения) существенно увеличивает количество используемых команд LOAD (загрузка в регистр) и STORE (запись в память), т. е. команд перемещения данных из регистров в память и обратно. Исследования на компьютере PDP для различных ЯВУ показывают, что 42 % всех выполняемых команд затрачивается на перемещение данных между памятью и регистрами. Имеются исследования, утверждающие, что использование кэш-памяти позволяет достичь увеличения быстродействия за счет использования регистров общего назначения.
В настоящее время имеются конкретные проекты архитектур машин, ориентированные на ЯВУ: ПАСКАЛЬ, PL, ЛИСП, КОБОЛ.
Однако больший интерес представляют архитектуры, ориентированные не на конкретный язык, а на общие семантические возможности некоторой группы языков. Так, архитектура машины SWARD ориентирована на языки PL/1, АДА, ФОРТРАН, КОБОЛ и некоторые другие, создавая тем самым благоприятную среду для программиста.
Компьютеры фирмы Burroughs, начиная с модели B 1700, за счет вызова различных микропрограмм динамически настраиваются на язык написания выполняемой программы.
Р

ис. 1.5. Соотношение программ на ЯВУ и машинном языке:
1 – это традиционный подход. После компилирования программа переводится на машинный язык, а затем интерпретируется машиной; 2 – компиляция идет на машинный язык более высокого уровня, сокращая тем самым семантический разрыв между ЯВУ и машиной; 3 – здесь ЯВУ можно рассматривать как язык ассемблера, т. е. имеется взаимно однозначное соответствие между типами операторов и знаков операций ЯВУ с командами машинного языка. Здесь идет ассемблирование, а не компилирование, во время которого удаляются комментарии и пробелы в исходной программе, преобразуются разделители, ключевые слова и знаки операций в машинные коды, имена – в адреса полей памяти. Таким образом, многих привычных функций компилятора здесь нет. Остальная привязка программы к ЭВМ происходит перед выполнением программы; 4 – здесь машинный
язык является ЯВУ и идет процесс интерпретации программы на компьютере
Отметим, что разработчику архитектуры ЭВМ не следует строго ориентироваться на языки программирования, компиляторы, операционные сис-
темы и другие программы, чтобы не потерять главное в архитектуре – ориентацию на современные требования задач и окружение пользователя.
Необходимо искать разумный компромисс в распределении функций системы между аппаратной и программной реализацией с учетом стоимости, возможности модификации, работы на микроуровне и т. д. Необходимо помнить, что компьютер создается для эффективного выполнения программ.
1.5. Некоторые способы совершенствования архитектуры
Архитектура компьютеров чаще всего совершенствуется за счет введения дополнительных средств. Рассмотрим некоторые из них.
1.5.1. Хранение информации в виде самоопределяемых данных
Обычно информацию о типе хранимых в памяти данных мы узнаем из команд программы. Однако мы можем в ячейке памяти, где хранятся данные, указать и тип данных (целое, десятичное, символьное и т. д.), дополнив данные некоторым набором битов – тегом. Этот принцип организации памяти получил название теговой памяти. Наряду с типом данных в теге можно хранить и другие характеристики, например длину операнда, информацию об определении текущего значения переменной, использующего данную ячейку памяти, и т. д.
Что дает тег? Известно, что в IBM 370 имеется 15 различных команд ADD, формат одной из них требует двух 4 битовых полей для указания длины обоих операндов. Использование тегов позволило бы ограничиться одной командой, а тип подлежащих сложению операндов и их длину компьютер определял бы путем анализа содержимого тегов соответствующих операндов.
Расширив тег еще одним битом, мы могли бы использовать его в случае обращения к этой ячейке для незапрограммированного прерывания при возникновении определенной ситуации и переходе к процедуре ее обработки.
Бывают два типа тегов: статические, содержимое которых определяется перед выполнением программы и по ходу вычислений не изменяется, и динамическое – с наполнением его содержания во время вычислений и периодическим обновлением.
В
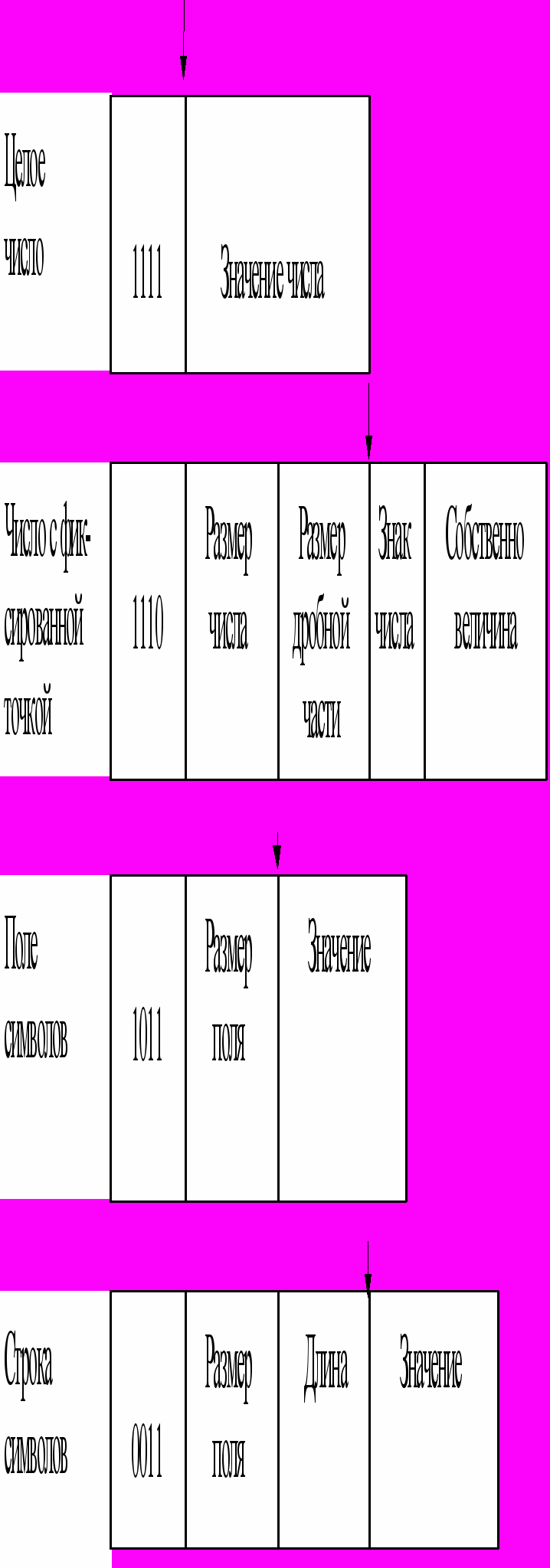
от пример типов структур элементов теговой памяти, ориентированный на языки программирования (рис. 1.6). Здесь стрелка "" разделяет тег и данные.
Рис. 1.6. Типы ячеек при теговой организации
Первые четыре бита определяют тип хранимой величины: целое, число с фиксированной точкой и т. д., затем идет количество цифр, длина и т. д.
Использование тегов позволяет найти некоторые ошибки. Например, может обнаружиться, что одним из операндов команды сложения является строка символов или число с плавающей точкой записывается в качестве адреса, или значение одного из операндов неизвестно и т. д. То есть идет защита типа данных.
Может возникнуть ситуация, когда складываем числа с фиксированной точкой, но позиции точки в числах разные, т. е. необходимо предварительно выравнять эти позиции. Данные могут отличаться длиной или формой представления. Таким образом, возможно автоматическое преобразование данных.
Теги позволяют повысить скорость обработки команд. Это происходит, во-первых, из-за того, что обычно для преобразования данных надо генерировать компилятором отдельные наборы команд, а во вторых, отпадает необходимость в извлечении из памяти и декодировании команд преобразования данных. Теги позволяют упростить алгоритмы некоторых операций. Так, для сравнения двух величин необходимо произвести их выравнивание (усечение до меньшей или дополнение до длинной), на что компилятор PL/1, например, генерирует код из 49 команд, а при теговой архитектуре потребуется одна машинная команда.
Структуры команд делаются более регулярными, за счет чего уменьшается разнообразие команд. Однако мы должны задаться вопросом, всегда ли уменьшение количества команд способно эквивалентно отразить исходное разнообразие операций. Всегда ли эквивалентна, например, операция арифметического сдвига и операция деления на 2?
Компилятор становится более простым и быстрым. Это следует из предыдущих рассуждений. Здесь не надо генерировать различный код в зависимости от типа данных, ибо набор команд инвариантен к типу обрабатываемых данных.
Теги позволяют сделать отладку более совершенной. В частности, дамп памяти становится более информативным.
Осуществляется независимость разрабатываемых программных средств от данных благодаря наличию команд, инвариантных к типу данных.
А что будет с объемом памяти для хранения программ и данных? Оказывается, хотя все данные требуют дополнительные поля, но за счет многократного и из многих команд обращения за данными, благодаря устранению избыточности информации в кодах операций команд в машинах с теговой организацией памяти потребуется меньший объем для хранения программ и данных, чем в ЭВМ с традиционной архитектурой. Проведенные эксперименты с программами на языке КОБОЛ показали, что если число обращений к операнду больше 3,5, то теговая организация уже выгодна и по объему памяти. Среднее же число обращений к одному операнду в некоторых наборах экономических программ имеет коэффициент обращения > 10,4.
Эти рассуждения еще раз подтверждают мысль, что оптимальное решение при проектировании архитектуры машины можно принимать лишь при глубоком анализе ЯП и программ.
Экономия памяти происходит из-за ненадобности повторного генерирования кодов для функций контроля и преобразования данных. Экономии можно достичь и за счет того, что один тег можно заводить для всего массива данных и для всех элементов строки символов, так как последние содержат, как правило, одинаковые атрибуты.
Наряду с тегами, во многих машинах используются и дескрипторы. Это дополнительная информация, выполняющая роль косвенного адреса ячейки памяти с данными. В этих компьютерах команды содержат ссылки на дескрипторы, которые, в свою очередь, содержат ссылки на области памяти, хранящие значения операндов команд.
Основное отличие тегов и дескрипторов состоит в следующем: дескрипторы создают дополнительный уровень адресации, что требует увеличения затрат на формирование адреса, т. е. дескрипторы – это часть команды (программы), а теги – это часть данных.
Пример использования дескрипторов (рис. 1.7).
| 101 | P | I | R | W | Длина | Адрес | |
Рис. 1.7. Дескрипторы
Здесь первые три бита содержат тег. Если значение его 101, то данное слово дескриптор. Бит P указывает, находятся данные в основной памяти или во вспомогательной; I указывает, одиночный ли элемент описывает данный дескриптор или весь массив; R идентифицирует непрерывную или разрывную область памяти; W означает, что разрешено только чтение данных.
1.5.2. Области санкционированного доступа
Средства доступа используются для защиты данных, например, области ОС от ревизии пользователя. Как правило, имеющиеся средства защиты не охраняют процесс от самого себя или одну программную секцию от другой, или программы пользователя от программного обеспечения.
Для защиты памяти выделяются домены – области санкционированного доступа как локальное адресное пространство, определяющее адреса, которые могут формироваться или использоваться некоторым набором команд. Имеется в виду, что область памяти защищается и от случайного обращения, и от преднамеренного ввиду секретности хранимой информации.
Появилась мысль придать каждой программной секции (это обычно отдельно компилируемая программная единица) домен – отдельное адресное пространство, доступное только ее (секции) локальным переменным. Передача фактических параметров подпрограмм (секции), занимающей некоторый домен, можно рассматривать как временное его расширение и решение проблемы передачи данных. Как только доступ к данным (обмен) закончился, расширение "домен-секция" исчезает. Для большей защиты домена данных программной секции может быть предоставлена только конкретная точка входа (или несколько), а не доступ к любому слову (рис. 1.8).
Р

ис. 1.8. Временное расширение домена
Использование доменов имеет ряд достоинств:
- улучшается отладка программ. Сфера действия любой ошибки ограничивается размерами домена, в котором она произошла, что увеличивает вероятность ее обнаружения;
- повышается надежность защиты программ. Информация, принадлежащая одной секции, защищается от воздействия других секций. Например, если модуль A вызывает модуль B для выполнения некоторых функций, то последний, будучи присоединенным к A, может анализировать все данные модуля A, хотя они должны быть защищены от подобных действий. Если же модуль A разделен на домены, возможности адресации модуля B ограничены только фактическими параметрами, которые передаются ему во время вызова. То же характерно и для вызываемого модуля B.
Чтобы исключить доступ ко всем данным исходной программы, ее сегментируют.
Для решения аппарата доменов, естественно, необходимы изменения и в архитектуре ЭВМ, например включение механизма, не разрешающего при выборе одного значения из домена доступ к другим его данным. Необходим механизм защиты от несанкционированных точек входа в модуль.
1.5.3. Одноуровневая память
Программист по-разному адресует память в зависимости от того, данные расположены в оперативной или внешней памяти. На программиста возлагается обязанность по явному заданию перемещения данных (операции ввода-вывода). В связи с ограниченным объемом оперативной памяти необходимо прибегать к другим принципам организации памяти, например к файловым структурам. Все это повышает стоимость программирования.
Данные в программу поступают обычно через передачу фактических параметров или через ввод-вывод (имеющий, например, файловую структуру). Эта разная организация данных может быть неприемлемой для одного и того же модуля. Кстати, организация файлов на накопителях на магнитных лентах (НМЛ) отличается от организации их на НМД.
Решение указанных проблем требует унификации всего разнообразия ЗУ, чтобы программист имел одинаковую адресацию вне зависимости от организации ЗУ. Теперь файлы станут элементами одноуровневой памяти, функции перемещения данных между различными уровнями ЗУ возлагаются на ЭВМ. Это в чем то напоминает виртуальную память. Однако одноуровневая память в отличие от виртуальной распространяется на все запоминающее пространство системы, а не только на вопросы, связанные с недостатком оперативной памяти. Кроме того, обслуживающий набор виртуальной памяти – это модель, исчезающая при завершении работы.
Достоинства одноуровневой памяти:
- сравнительно низкая стоимость программного обеспечения;
- независимость адресации от принципа организации памяти.
Трудности, возникающие при этом:
- создание встроенного в архитектуру ЭВМ механизма иерархии ЗУ;
- восстановление памяти;
- переносимость объектов на другие системы с традиционной орга-низацией архитектуры.
1.6. Концепция виртуальной памяти
Каждая часть среды компьютера имеет собственное обозначение: ячейка – адрес, периферийное устройство – номер и т. д. В простейших компьютерах собственные обозначения указываются непосредственно в программе. В более сложных компьютерах программа отделена от среды "аппаратом преобразования собственных обозначений". Рассмотрим один элемент среды – память. Аппарат преобразования адреса (АПА) не находится под прямым управлением программы и связь с ним осуществляется только через процедуры, работающие в управляющем режиме.
Если программисту безразлично существование АПА, то он работает с набором ячеек и периферийных устройств, образующих "виртуальную (математическую, мнимую) среду". Почти всегда виртуальная среда есть переупорядоченное подмножество реальной среды. Каждому виртуальному элементу соответствует реальный элемент, но обратное не всегда верно.
Рассмотрим один из элементов виртуальной среды – виртуальную память (ВП).
1.6.1. Задачи, решаемые виртуальной памятью
Виртуальный адрес – адрес, по которому ссылаются на ячейку виртуальной памяти. Область виртуальных адресов – это множество всех виртуальных адресов.
Использование виртуальной адресации обусловливается следующими обстоятельствами.
1. Однородность области адресов. Представим себе реальный компьютер без виртуальной памяти. Пусть на нем выполняется параллельно несколько процессов. У каждого процесса будет отдельная локальная среда и каким то образом распределяемые элементы общей среды. Программисту требуется заранее знать, к каким конкретно частям общей среды его процедура может обращаться. Это затруднительно для пользователей ЭВМ, составляющих свои собственные программы. Отвести наперед фиксированную область среды для каждого процесса невозможно, ибо положение каждой конкретной программы определяется положением всех других программ.
При виртуальной адресации каждый процесс может выполняться в памяти начиная с фиксированной (обычно нулевой) ячейки, имеющей необходимые размеры области ЗУ. Автору безразлично, в каком участке памяти выполняется его программа, так как каждое обращение к виртуальной памяти во время выполнения посредством АПА преобразуется в реальное обращение.
Замечание. АПА работает не во время ассемблирования, а непосредственно во время выполнения обращения.
2. Защита памяти. Общеизвестно, что основная цель защиты памяти состоит в том, чтобы не дать возможности некорректному процессу испортить часть среды, относящуюся к другому процессу. Особенно это важно при защите сред управляющих процедур. Виртуальная адресация здесь используется следующим образом: при каждой ссылке процессом на память проверяется, принадлежит ли она к области виртуальных адресов, отведенных для данного процесса.
3. Изменение структуры памяти. При проектировании больших программ структура памяти машины с малой ОП явно усложняет проектируемую программу. Применение виртуальной адресации позволяет преобразовать память на разных ступенях иерархии в "одноуровневую память" с одинаковым доступом ко всем элементам и отобразить ее на реальную память.
Для удовлетворения пунктов 1–3 требуется аппарат "страничной" организации памяти, для пунктов 1, 2 достаточно иметь регистры "настройки": регистры "базы" и "границы".
1.6.2. Страничная организация памяти
Отображение виртуальной памяти в реальную обычно осуществляется с помощью страничной организации памяти.
Виртуальную память в системе со страничной организацией памяти делят на ряд "блоков" фиксированной длины, равной 2k, где k – целое натуральное число. Так как первая ячейка блока N + 1 примыкает к последней ячейке блока N, то программисту факт разбиения ВП на блоки учитывать не требуется.
Оперативная память компьютера делится на "страницы", а вспомогательная – на "сегменты" такого же размера.
Виртуальную память пользователя можно разделить на три типа:
- "активные" блоки, которые содержат программу и данные, используемые в текущий момент;
- "пассивные" блоки, содержащие программу и данные, которые будут использоваться при выполнении программы;
- "мнимые" блоки, к которым не обращаются на протяжении выполнения программы.
Соотношения между первым и вторым типами блоков ВП в процессе выполнения программы изменяются. Третий тип блоков возможен лишь при наличии очень большой области ВП.
Аппарат виртуальной адресации должен отображать виртуальную среду на реальную, причем так, чтобы "активные" блоки находились в оперативной памяти, "пассивные" – по возможности в оперативной или вспомогательной, а мнимые – нигде.
Наиболее удачной из первых ЭВМ со страничной организацией памяти (СОП) является ATLAS (Ferranti). ВП в ней содержит около 2000 блоков по 512 слов. Оперативная память содержит от 32 до 96 страниц тоже по 512 слов. Если ATLAS выполняет процесс, который запрашивает блок из ВП, то некоторым блокам отводятся страницы из оперативной памяти, остальные блоки помещаются на накопитель на магнитном барабане. Фиксированных соотношений между номерами страниц, блоков и сегментов не существует. Динамическое соотношение между сегментами отражено в соответствующей таблице операционной системы.
П

реобразование виртуального адреса в реальный происходит с помощью регистров адресов страниц (РАС). Структура виртуального адреса
 . Каждой странице ОП соответствует свой РАС, формат которого дан на рис. 1.9. Аппарат виртуальной адресации отображает
. Каждой странице ОП соответствует свой РАС, формат которого дан на рис. 1.9. Аппарат виртуальной адресации отображает Рис. 1.9. Структура регистра адреса страницы
виртуальный адрес в реальный следующим образом: виртуальный адрес сравнивается одновременно с содержимым всех РАС. Единственным сравнимым с ним РАС будет тот, который содержит тот же номер блока и "1" в разряде активности. РАС определяет номер страницы, с которой он связан. Для получения реального адреса памяти к номеру страницы данного РАС присоединяется номер строки из виртуального адреса (ВА). В последовательной интерпретации процесс отображения ВА в реальный можно представить следующей схемой (рис. 1.10).
Р
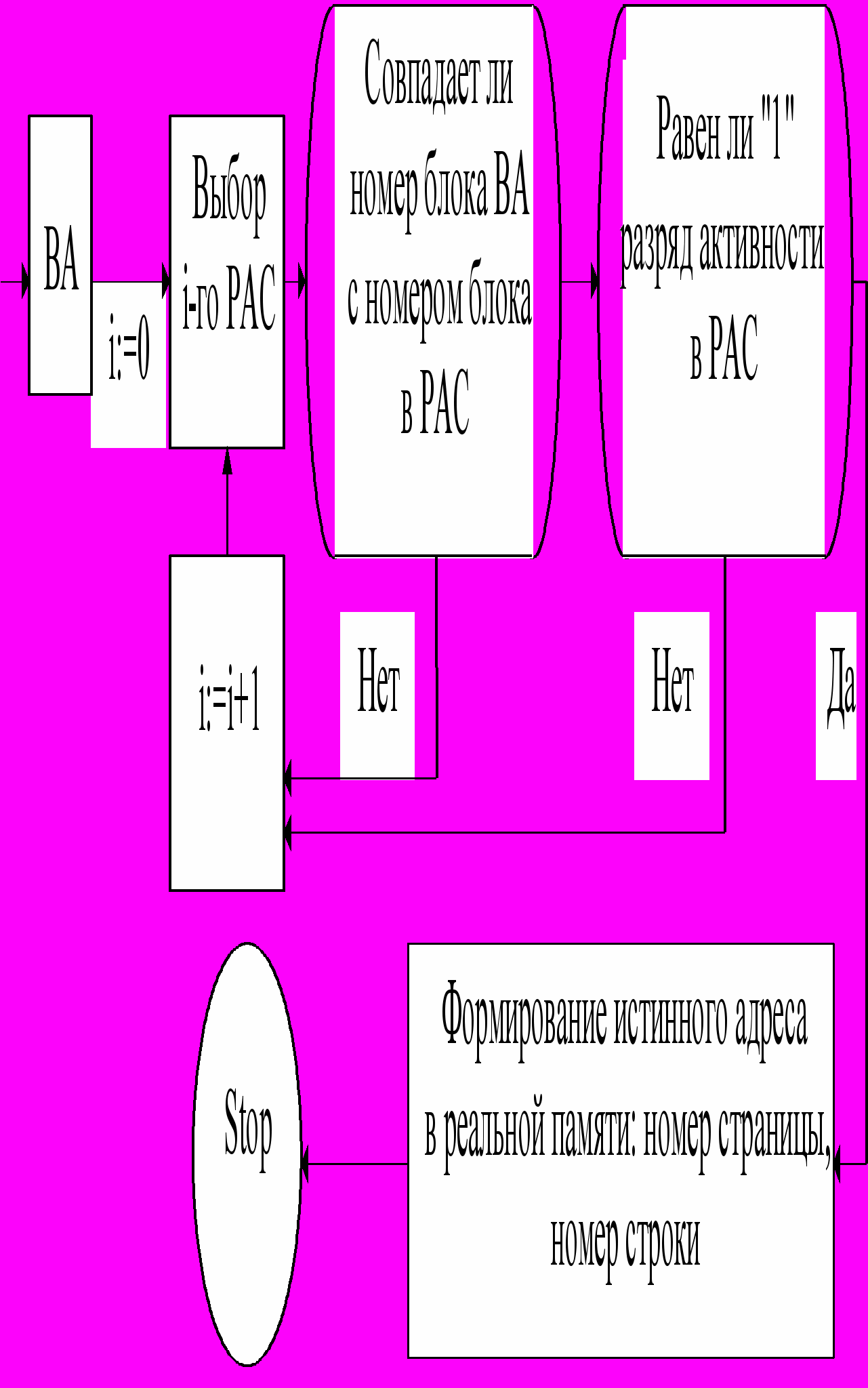
азряд записи в РАС служит для экономии времени перезаписи "страницы" в ВнП. Когда блок переносится из ВнП в оперативную память в разряд записи пишут "0". Если какая то строка данной страницы ОП изменяется в процессе обращения к ней, то в пишут "1". И пока в разряде записи "0" эта страница является точной копией соответствующего блока в ВнП.
Рис. 1.10. Схема отображения ВА в реальный адрес
В разряд использования "1" посылается при очередном обращении к данной странице. Через равные промежутки времени содержимое регистра использования сканируется и записывается в определенную ячейку памяти, тем самым создавая статистику использования данной страницы. Подобная статистика полезна при замещении страниц в ОП.
Для создания РАС требуется очень дорогая ассоциативная память, поэтому в mainframe компьютерах число РАС меньше количества страниц ОП. В них каждому блоку ВП отводится в ОП одна последовательная ячейка памяти, указывающая, где хранится данный блок (ОП, ВнП или нигде). Имеется небольшое количество ассоциативных регистров для РАС (обычно 8 или 16).
Полный процесс отображения ВП в реальную выполняется за три этапа.
1. Если происходит обращение к блоку ВП, который должен отображаться на страницу ОП, РАС для которой является одним из 8 (16) ассоциативных регистров, то процесс отображения выполняется согласно схеме, приведенной на рис. 1.11.
2. Если обращение происходит к блоку ВП, для которого условия п. 1 не выполняются, то номер виртуального блока служит указателем для обращения к таблице блоков (ТБ) в оперативной памяти. Если из ТБ видно, что искомый блок находится в оперативной памяти, то номер страницы также может быть выбран из ТБ.
Если же нужный блок находится во вспомогательной памяти или отсутствует вообще, то происходит прерывание, и тогда переходим к управляющей процедуре (см. п. 3).
3. Обработка прерывания.
Для эффективной работы системы необходимо, чтобы ассоциативные регистры содержали РАС для наиболее часто используемых страниц.
О
сновная цель методов оптимизации распределения реальной памяти состоит в минимизации числа обменов между оперативной и вспомогательной памятью. Отсюда следует, что необходимо корректно выбирать стратегию замещения страниц.
Рис. 1.11. Схема процесса отображения ВА в РА в ЭВМ ATLAS
Основные стратегии замещения страниц, наиболее часто используемые на практике: циклическое изгнание, случайная выборка, наименьшее число обращений с момента последнего прерывания. Результаты экспериментов показали, что ни в одном случае разница в числе обменов, требуемых конкретной задачей при использовании указанных стратегий, не превышала 10 %.
Перенеся концепцию виртуальной памяти на другие компоненты компьютера, мы придем к концепции виртуального компьютера.
1.7. Особенности функционирования управляющей ЭВМ
Для автоматизации управления сложным производственным или технологическим процессом в контур управления включают компьютер, т. е. управляющую вычислительную машину (УВМ). Наиболее часто в качестве управляющей ЭВМ используют цифровую ЭВМ благодаря следующим ее качествам:
- наличию больших и высоконадежных ЗУ различного типа;
- возможности решения на них сложных вычислительных и логичес-
ких задач;
- гибкости (за счет программы);
- надежности и быстродействию.
В общем случае система автоматического управления с УВМ определяет собой замкнутый контур (рис. 1.12).
Здесь
x1, x1, …, xn – измеряемые параметры:
нерегулируемые (характеристики исходного продукта);
выходные параметры, характеристики качества продукции;
выходные параметры, по которым непосредственно или путем расчета определяется эффективность производственных процессов (производительность, экономичность), или ограничения, наложенные на условия его протекания;
y1, y2, …, yn – регулируемые параметры, которые могут изменяться исполнительными механизмами (ИМ) – регуляторами и оператором;
f1, f2, …, fn – нерегулируемые и неизмеряемые параметры (например, химический состав сырья).
На вход УВМ от датчика Д (термопар, расходомеров) идет измерительная информация о текущем значении параметров x1, x2, …, xn. Согласно алгоритму управления, УВМ определяет величину управляющих воздействий U1, U2, …, Un, которые необходимо приложить к ИМ для изменения регулируемых параметров y1, y1, …, yn с тем, чтобы управляющий процесс протекал оптимально. Измерительные датчики вырабатывают непрерывный сигнал (напряжение, ток, угол поворота), а ЦВМ работает в дискретной форме, поэтому 2 раза идет преобразование из непрерывной формы в дискретную (Н/Д) и наоборот (Д/Н).
Р

ис. 1.12. Принцип действия УВМ
Для уменьшения оборудования преобразователи Н/Д и Д/Н выполнены многоканальными. Посредством коммутатора преобразователь поочередно подключается к каждому датчику и осуществляется преобразование Н/Д. Поступившее управляющее воздействие U сохраняется в цепи до выработки следующего управляющего воздействия в УВМ.
Теперь наибольшее распространение получил синхронный принцип связи УВМ с объектом, при котором процесс управления разбивается на циклы равной продолжительности тактирующими импульсами электронных часов.
Цикл начинается с приходом тактирующего импульса на устройство прерывания. В начале каждого цикла проводятся последовательный опрос и преобразование в цифровую форму сигналов датчиков.
После выработки управляющих воздействий Ui и преобразования их в непрерывную форму УВМ останавливается до прихода нового тактирующего импульса или выполняет какую-нибудь вспомогательную работу.
Для установления более тесной связи объекта с УВМ используют асинхронный принцип связи с объектом. Вместо тактирующих импульсов в УВМ поступают импульсы от датчиков прерывания (ДП), непосредственно связанных с объектом (например, конечных выключателей аварийного состояния). Каждый импульс прерывания эквивалентен требованию о прекращении производимых вычислений и переходе к выполнению подпрограммы, соответствующей данному каналу прерывания. УВМ реагирует на импульсы прерывания с учетом приоритета одних сигналов прерывания над другими.
В некоторых системах применяют комбинированный способ – синхронизацию "плюс" датчики аварийного состояния, переводящие УВМ на режим
аварийной работы. В замкнутом контуре (см. рис. 1.12) УВМ прямо воздействует на ИМ, непосредственно управляя производственным процессом. Это режим прямого цифрового управления.
Однако для сложных систем, а также для комплексов агрегатов, связанных между собой технологическим процессом, система управления строится так, что отдельные параметры процесса регулируются соответствующими автоматическими регуляторами, а УВМ обрабатывает измерительную информацию, рассчитывает и устанавливает оптимальные настройки регуляторов. Это повышает надежность системы, так как ее работоспособность сохраняется и при отказах УВМ. При такой схеме УВМ может быть более простой, так как снижается требование к ее быстродействию.
УВМ в разомкнутой цепи используется:
- в системах автоматического программного управления;
- в системах, где УВМ выполняет функции советчика.
В первом случае уменьшается объем первоначально вводимой информации в УВМ для расчета оптимальных настроек регуляторов. Детальный расчет программы управления с заданной точностью производится самим вычислительным устройством, которое в соответствии с этой программой вырабатывает необходимые управляющие воздействия.
В режиме советчика УВМ обрабатывает измерительную информацию с объекта и рассчитывает управляющие воздействия для оптимизации процесса. Эта информация служит рекомендацией оператору, управляющему процессом.
Упражнения
1. Чем различаются понятия "архитектура" и "структура" компьютера?
2. На конкретном примере продемонстрируйте семантический разрыв между современными языками программирования и архитектурными решениями компьютера.
3. Какие пути усовершенствования архитектуры фон Неймана Вам
известны?
4. Разработайте и реализуйте механизм преобразования виртуального адреса в реальный.
5. Разработайте и реализуйте алгоритм управления простейшим технологическим процессом для компьютера, работающего в "замкнутом" цикле.
6. Разработайте алгоритмы взаимодействия основных компонент компьютера с VLIW архитектурой.