
Основные понятия информационного поиска информационные процессы и системы
| Вид материала | Документы |
- Полный курс лекций по Информационным системам информационные системы, 787.33kb.
- Конспект лекций для специальности «Прикладная информатика в экономике», 1468.57kb.
- Организационные основы информационных технологий в экономике, 44.75kb.
- Информационные системы (теория к экзамену) Основные понятия информационных систем, 82.21kb.
- Курсовая работа предмет: Информационные системы Тема: Языки информационного поиска, 154.92kb.
- Информация и информационные процессы, 276.11kb.
- Справочно-информационные системы в подготовке юриста, 31.18kb.
- 1 Информация. Кодирование информации, 59.79kb.
- Инициативный проект Российского семинара по оценке методов информационного поиска (ромип), 149.92kb.
- Программа по дисциплине «прикладные протоколы интернет и www» по направлениям: «Математика., 234.28kb.
P111,J - современный английский язык
(запятая разделяет фокусы в фасетах Р («Языки») - «английский язык» - и Р2 («Стадии языка») - «современный»),
3:1 — произношение слов
(двоеточие разделяет фокусы в фасетах РЗ («Элементы языка») -«слова» - и Е («Проблемы») - «фонология»),
k - словарь.
Составление индексов в «Классификации двоеточием» достаточно сложное дело. Первая часть классификации вообще посвящена теории и методике фасетной классификации.
Фасетные классификации сближаются, фактически, с одной стороны, с дескрипторными языками с развитым тезаурусом, с другой - с языками объектно-признакового типа, используемыми в фактографических системах. В связи с большой трудоемкостью разработки фасетных классификаций они могут быть созданы для документального поиска только для узких предметных областей. Методика индексирования с применением фасетных классификаций также сложна. Поэтому на практике в автоматизированных документальных ИПС эти классификации широкого применения не нашли.
Основные недостатки всех классификаций в целом как информационно-поисковых языков заключаются в следующем:
- невозможность обеспечить свободное многоаспектное индексирование;
- невозможность порождать новые, сколь угодно узкие классы понятий методом координации;
- недостаточная глубина деления классов и рубрик;
- постоянное отставание словаря и классификационной схемы отреальной действительности.
2.2.2. Посткоординируемые ИПЯ
Дескрипторные ИПЯ
В основу построения посткоординируемых языков положен принцип координации - соотнесения двух понятий и порождение ими нового непосредственно в процессе поиска. Принцип координатного индексирования был разработан в 1950-х годах в процессе создания механизированных ИПС. Однако сам принцип описания содержания документов
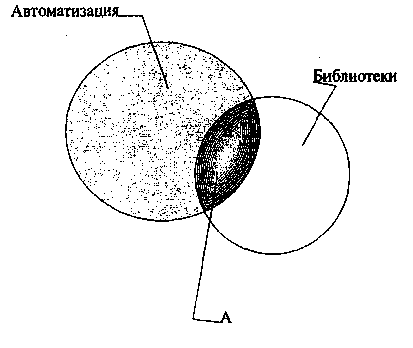
через перечисление ключевых слов существует издавна. Координация, или логическое умножение понятий, в результате которой из простых лексических единиц строятся более сложные, выражающие более узкие понятия, осуществляется как бы дважды: потенциально (при индексировании документа) и реально - в процессе поиска: при сопоставлении поискового образа документа с терминами запроса (поискового предписания). Например, пересечением понятий БИБЛИОТЕКИ и АВТОМАТИЗАЦИЯ, заданных в поисковом предписании, порождается новое более узкое понятие АВТОМАТИЗАЦИЯ БИБЛИОТЕК. Логическое умножение понятий хорошо иллюстрируется на кругах Эйлера (они же -диаграммы Венна).
вгоматизация библиотек
Рис. 2.2. Логическое умножение понятий.
Отдельная проблема - действительно ли образованное таким образом сочетание терминов является именем понятия и всегда ли? Известно и достаточно подробно изучено явление ложной координации понятий. Документ, в котором встретились слова БИБЛИОТЕКА и АВТОМАТИЗАЦИЯ, на самом деле может быть посвящен, например, роли БИБЛИОТЕК в АВТОМАТИЗАЦИИ научных исследований. То есть тема, определяемая понятием «автоматизация библиотек», в данном документе не обсуждается.
Другой пример: пусть имеется запрос со словосочетанием КАТАЛИЗАТОРЫ БРОМИСТОГО МАРГАНЦА. И пусть имеется документ, содержащий фрагмент текста «Производство фталевой кислоты окислением ксилола БРОМИСТЫМ МАРГАНЦЕМ в присутствии КАТАЛИЗАТОРОВ». Как и в первом примере, пересечение понятий КАТАЛИЗАТОР и МАРГАНЕЦ для данного документа дает ложную координацию понятий.
Одной из первых ИПС с посткоординируемым ИПЯ была система УНИТЕРМ (UNITERM), разработанная в США М. Таубом31. В ней в качестве индексов, описывающих содержание документов и запросов, использовались ключевые слова, выбранные из текста (англ. Uniterm - одиночный термин). Все такие слова имели одинаковый иерархический ранг. Словарный состав унитермных языков не разрабатывался предварительно, а формировался непосредственно в процессе индексирования.
В то же время очевидно, что в естественном языке одна и та же тема в разных документах может описываться разными способами (например, «устройство для запоминания информации» и «запоминающее устройство»). Встает проблема выбора информативных слов и проблема их нормализации. Нормализация заключается в приведении всех ключевых слов к «нормальному» виду (единое написание, единая морфологическая форма) и в устранении лексической и синтаксической синонимии, полисемии, омонимии. Эта нормализация получила название лексического (или лексикографического) контроля. Контроль осуществляется при помощи специального нормативно-справочного словаря, в котором перечисляются все ключевые слова и словосочетания, встречающиеся в документах. Синонимичные слова и словосочетания объединяются в один класс, омонимы, наоборот, разносятся по разным классам, и каждому классу присваивается уникальное имя. Такие имена назвали дескрипторами (англ, describe — описывать), а их алфавитный перечень — дескрипторным словарем. Языки, в основе которых лежит дескрипторный словарь, получили название дескрипторных ИПЯ.
Вербальные ИПЯ
Использование дескрипторных языков предполагает процедуру индексирования — перевода содержания документов с естественного языка на дескрипторный. Индексирование может быть ручным или автоматизированным. В обоих случаях имеются свои проблемы: в первом случае это большие затраты человеческого труда и субъективность индексирования, во втором - нерешенность вопросов компьютерного моделирования интеллектуальных семантических процессов, к каковым, безусловно, относится индексирование. В целях упрощения процедур автоматического индексирования вместо дескрипторных языков часто используются языки, в которых нет лексического контроля. Такие ИПЯ называют бестезоурусными или вербальными. Часто даже говорят, что в качестве ИПЯ в этом случае используется ЕЯ. На самом деле имеется в виду, что для координатного индексирования в таких ИПС используются слова и словосочетания ЕЯ, содержащиеся в документах и запросах. Фактически, мы имеем дело с дескрипторными ИПЯ без фиксированного словаря и без фиксированной парадигматики. А.И. Черный считает, что в этом случае используются два варианта ИПЯ: один - с нулевой нормализацией ключевых слов и словосочетаний естественного языка (для координатного индексирования документов), другой - с большой степенью логической обработки (для избыточного индексирования запросов)*2.
ИПС может рассматриваться как совокупность механизмов смыслоразличения (описание содержания документов и запросов) и смыслоотождествления (сравнение ПОД и ПОЗ). Отказ от индексирования документов и лексического контроля затрудняет выполнение функции смыслоотождествления и, как следствие, ведет к снижению полноты. Поэтому требуется включение компенсационных механизмов в каком-либо другом месте системы. В бестезаурусных ИПС эта проблема решается на стадии составления поисковых предписаний (ПП) путем избыточного индексирования. Там каждому термину из ПП приписываются синонимичные или близкие ему по смыслу термины, в том числе термины, находящиеся с исходными в родовидовых и других парадигматических отношениях, т. е. происходит как бы «развертывание» словарной статьи дескрипторного словаря или тезауруса. Отличие от индексирования в традиционном смысле заключается в том, что исходные ЛЕ запроса и документа здесь никак не «портятся» и что методика индексирования запроса при таком подходе в большей степени и более гибко способна учесть конкретную информационную потребность. В ИПС бестезаурусного типа тезаурус не исключается, но он начинает использоваться, как и тезаурус в лингвистике, в качестве средства для моделирования информационной потребности и смыслового варьирования запросов.
Семантические и синтагматические языки jfc Представление содержания документов является главной функцией Документальных ИПЯ. В дескрипторных ИПЯ семантическая задача описания содержания документов и запросов решается, по сути дела, приблизительно. Гораздо ближе к этой проблеме подошли создатели семантических и синтагматических языков, среди которых наиболее известны семантический код Перри-Кента33, язык RX-кодов34 и язык СИНТОЛ35. Их разработчики основную задачу видели в обеспечении однозначного перевода с естественного языка на ИПЯ с учетом семантических и синтаксических факторов. Характерная особенность этих языков -наличие средств, явно описывающих семантическую и семантико-синтаксическую структуру понятий и выражений (семантические множители, термы, реляторы, предикаты, сущности и т. п.).
Приведем пример лексических единиц языка RX-кодов для понятий «луг» и «лес». В языке RX-кодов для образования слов и словосочетаний применяются два типа единиц: термины (X), обозначающие предметы и понятия, и релятемы (R), обозначающие свойства и бинарные отношения.
Луг - это участок, покрытый травянистой растительностью и расположенный в пойме реки.
Лес - это участок, покрытый деревьями.
На языке RX-кодов эти два понятия будут выражены так.
X1=R1X2R2X3R3X4
X5=R1X2R2X6
Здесь
XI - понятие «луг».
Х2 — участок,
ХЗ — травянистая растительность,
Х4 - пойма реки,
Х5 — понятие «лес».
Х6 - древесная растительность,
R1 - быть видом,
R2 - быть покрытым,
R3 - быть расположенным.
Более подробно об этих языках см., например, в книгах А.И. Черного и В. А. Московича36.
Развитие семантических языков в целом прошло сложный путь «самоопределения», и в настоящее время языки этого типа используются в основном в системах искусственного интеллекта. Практика показала, что сложные семантические языки и трудно реализуемые синтаксические и семантические методы анализа текстов не дают существенного выигрыша с точки зрения достигаемых результатов документального поиска (а чаще просто дают худшие результаты). Постепенно стала осознаваться необходимость построения информационно-поисковых языков в соответствии с типами задач, для решения которых они предназначаются, и современным уровнем компьютерной лингвистики. «Нужно иметь в виду, что всякое усложнение информационного языка, не сопровождающееся соответствующим усложнением остальных компонент, не может дать позитивного результата и, скорее всего, даже ухудшит работу ИПС»37. Авторы указанной статьи, проведя и описав серию экспериментов по оценке смыслоразличительной роли синтаксической связи в ситуации документального поиска, делают вывод, что синтаксический анализ сам по себе не дает улучшения качества документального поиска. «Полученные нами результаты показывают, что возможности использования в информационном поиске чисто синтаксических моделей не следует переоценивать. Только в рамках хорошо разработанной семантической модели языка в качестве одной из ее составляющих синтаксический анализ может дать должный поисковый эффект. К сожалению, для полной практической реализации такого подхода сегодня еще нет достаточных теоретических предпосылок»38.
Именно поэтому большинство реально работающих документальных ИПС строится на основе вербальных ИПЯ с простой грамматикой.
Основной целью содержательного анализа в информационно-поисковых системах является выдача релевантных документов, а не представление их содержания, в отличие от систем искусственного интеллекта, где требуется способность делать выводы из полученной информации, т. е. где имеет место такой компонент значения, как истинностная оценка. Существует мнение, что документальные информационно-поисковые системы не являются промежуточными продуктами на пути создания интеллектуальных систем тина «вопрос-ответ», а выполняют особую информационно-поисковую функцию там, где нет необходимости в использовании идей семантики39.
Представляет интерес описание информационных языков разных типов в уже упоминавшейся книге В.А. Московича, которое дается по одной и той же схеме: общие сведения, способ кодирования, аппарат парадигматики, аппарат синтагматики, правила интерпретации, дополнительные сведения.
2.2.3. Составные части информационно-поисковых языков
Любой письменный язык состоит, по крайней мере, из трех компонент: алфавит, словарь и грамматика. Это применимо и к ИПЯ. Система графических знаков, используемая для записи лексических единиц (ЛЕ) различных ИПЯ - алфавит - может включать в себя алфавитно-цифровые символы, знаки пунктуации и специальные символы. Иногда в понятие алфавит включается микросинтаксис - способы построения лексем из знаков алфавита. Совокупность всех ЛЕ ИПЯ называется словарем. Система отношений между ЛЕ ИПЯ и правил построения выражений на ИПЯ называется грамматикой. Перечисленные части ИПЯ можно выделить в языках различных типов. Мы их рассмотрим на примере дескрипторных и вербальных ИПЯ.
Словарь
Словарь является основной частью всех информационно-поисковых языков. В качестве лексических единиц в дескрипторных ИПЯ выступают дескрипторы - имена понятий или классов понятий, которые явно перечисляются в дескрипторном словаре. В обычном понимании - это слова (или словосочетания), выбранные в качестве представителей классов условной эквивалентности — групп синонимичных слов и словосочетаний. Как правило, это существительные или номинативные выражения. Связь номинации с понятиями давно осознана в языкознании40. То же понимание утвердилось и в информатике: «Номинативная группа как наиболее общая речевая форма представления понятия в тексте рассматривается ... как фундаментальное для методов автоматической обработки текстов явление»41. «Объектный характер назывных слов роднит их с понятиями. Лексические значения, как и понятия, это своего рода умственные «концентраторы», сгустки человеческих знаний об определенных фрагментах и сторонах окружающей нас действительности»42.
Дескрипторный словарь представляет собой нормативный словарь, в котором в алфавитном порядке приведены все важнейшие ключевые слова данной предметной области с соответствующими пометами. Если в качестве имен понятий выбираются слова естественного языка, то существуют специальные способы для устранения полисемии и омонимии слов. Например, в системах с ручным (интеллектуальным) индексированием для этого используются специальные пометы: нос (орган обоняния) - нос (передняя часть судна, самолета); линь (рыба) -линь (мор. канат). Можно просто перенумеровать омонимы, оговорив в словаре их значения: нос! - нос2; линь! - линь2.
Дескрипторный словарь используется как инструмент лексического контроля при индексировании документов и запросов. Термин «лексический контроль» (ЛК) имеет синоним «словарный контроль», так как для семантического нормирования ЛЕ ИПЯ используется словарь индексирования, или Дескрипторный словарь, в котором в явном виде перечислены все важнейшие ключевые слова и дескрипторы, объединенные в классы условной эквивалентности. Лексический контроль - это совокупность мер, принимаемых при координатном индексировании с целью сокращения до минимума отрицательных последствий неоднозначного и неединообразного употребления слов ЕЯ.
Суть лексического контроля, осуществляемого с помощью словаря индексирования, в основном сводится к контролю43 синонимии и разрешению омонимии.
Кратко коснемся каждой из составляющих ЛК.
- Контроль синонимии является главной функцией ЛК в ИПС. Он заключается в том, что все синонимы текста в ПОД и ПОЗ представляются одной и той же лексической единицей — дескриптором. В число синонимов включаются:
- полные синонимы (радар - радиолокатор, ЭВМ - компьютер);
- фонетические (графические) варианты слов (секстан — секстант,center - centre, labor - labour, Chekhov - Tchekhov);
- аббревиатуры (ИПС - информационно-поисковая система);
- слова, близкие по смыслу (отсечка — отсечение, магнитный диск -магнитная память, ОРЗ - простуда);
- слова, совпадающие по смыслу в одном из значений (компьютер - машина, статья — работа, перепись — перезапись).
- Иногда к синонимам относят и антонимы («квазисинонимы») (жесткость - мягкость, фокусировка — дефокусировка).
- Иногда в один класс условной эквивалентности сводятся не только грамматические формы одной лексемы, но и разноосновные и относящиеся даже к разным частям речи лексемы, объединяемые общим лексическим значением, например: трелевка - трелевочный, сверло - сверление. Л.В. Сахарный назвал такие единицы «гиперлексемами»44.
- ЛК призван также обеспечить различение омонимов (омографов) и многозначных слов. Это достигается присвоением им различных цифровых кодов (в первых дескрипторных ИПЯ, лексика которых записывалась с помощью цифрового алфавита) или системой помет, например:
конденсаторы (для пара) - конденсаторы (электрические), литье (предмет) - литье (процесс), меркурий (металл) - Меркурий (планета).
В ряде исследований, однако, показано, что неразличение омонимов не ведет к заметному информационному шуму45. Это объясняется тем, что совпадение (ложное) одного термина запроса с омонимичным ему термином в документе не влияет сколь-либо значительно на коэффициент релевантности при количественном критерии смыслового соответствия и недостаточно, как правило, для присвоения логическому выражению запроса значения «истина», так как другие термины из конъюнктивной формулы запроса скорее всего в данном документе будут, отсутствовать.
Между лексическими единицами ИПЯ могут быть установлены различные отношения. Обычно их включают в грамматику. Однако те из них, которые не зависят от контекста и фиксируются в словаре, могут рассматриваться как семантические характеристики лексических единиц и относиться к словарю. Такие отношения называют базовыми, или парадигматическими, или аналитическими. Дескрипторный словарь (нормативный словарь индексирования) с зафиксированными в нем парадигматическими отношениями (подробнее см. следующий раздел - «Грамматика ИПЯ») называется информационно-поисковым тезаурусом (ИПТ), или просто тезаурусом. Целью создания ИПТ является повышение показателей качества поиска информации46.
«Информационно-поисковый тезаурус - контролируемый словарь лексических единиц дескрипторного языка, основанный на лексике естественного языка, отображающий семантические отношения между лексическими единицами и предназначенный для организации поиска информации путем индексирования документов и/или запросов»47.
В лексическом составе ИПТ выделяют дескрипторы и аскрипторы48. Дескриптор - это лексическая единица ИПТ, предназначенная для использования в поисковых образах документов и/или запросов. Аскриптор (недескриптор) - лексическая единица ИПТ, которая в поисковых образах документов (запросов) подлежит замене на дескриптор при поиске или обработке информации.
Форма представления тезауруса определяется требованиями удобства пользования. Она должна обеспечивать нахождение нужной по смыслу ЛЕ и всех ЛЕ, с ней связанных.
Чаще всего ИПТ имеет две части.
1) Словарная часть (собственно тезаурус), представляющая собой алфавитный список дескрипторов вместе с их словарными статьями (гнездами)49.
Словарная статья обычно содержит:
заглавный дескриптор (прописными буквами);
ключевые слова или словосочетания, входящие в гнездо данного дескриптора (условные синонимы) (строчными буквами);
«вышестоящие» дескрипторы (находящиеся с данным в отношении «род—вид», «часть-целое»);
«нижестоящие» дескрипторы (находящиеся с заглавным дескриптором в отношении «вид-род», «целое-часть»);
ассоциативные (ассоциированные) дескрипторы (связанные с данным другими разнообразными отношениями, как-то: причина-следствие, сырье-продукт, процесс-объект, процесс-субъект, свойство-носитель свойства, функциональное сходство)50.
Указанные подмножества обычно приводятся с пометами, чаще всего:
«с» - синонимы,
«в» - выше,
«н» - ниже,
«а» - ассоциация51.
Также встречаются и другие пометы и знаки:
«см.» - смотри (отсылка к соответствующему заглавному дескриптору);
«исп к»—использует комбинацию (в случаях замены ключевого слова сочетанием двух или более дескрипторов);
«исп а» — использует альтернативу (в случае многозначного ключевого слова, заменяемого одним из двух или более дескрипторов);
«ср» - сравни (для многозначных слов внутри дескрипторного гнезда, которые могут заменяться не только данным дескриптором);
() — в скобках уточняется лексическое значение дескриптора (для омонимов) или ограничение области использования.
2) Указатели различных видов, облегчающие пользование тезаурусом (алфавитный указатель всех ключевых слов, пермутационный указатель для элементов словосочетаний, частотный указатель и др.).
Пример дескрипторной статьи из Тезауруса по информатике52:
ДОКУМЕНТАЛЬНЫЕ ИПС
с документальные информационно-поисковые системы
ср документально-фактографические ИПС
в ИПС
н БИБЛИОГРАФИЧЕСКИЕ ИПС ДОКУМЕНТАЛЬНЫЕ АИПС
а ДОКУМЕНТАЛЬНАЯ ИНФОРМАЦИЯ ДОКУМЕНТАЛЬНЫЙ ПОИСК
Принципы построения тезауруса широко описаны в литературе и могут быть сведены к следующим:
- ни одно редко встречающееся понятие не надо включать в тезаурус;
- служебные (незначащие) слова в тезаурус не включаются;
- термины слишком общего значения с высокой частотой встречаемости должны быть исключены из словаря;
- у неоднозначных терминов должны быть закодированы только те их значения, в которых они встречаются в фонде обрабатываемых документов.
Помимо лексико-семантической нормализации, в ИПС всех типов необходима морфологическая нормализация лексических единиц текста (ИПЯ) — приведение всех словоформ одной и той же лексической единицы к некоторому стандартному, каноническому виду. В системах с ручным индексированием эта задача решается индексатором на уровне составления ПОД и ПОЗ. В остальных случаях разрабатываются автоматизированные методы учета словоизменения (см. об этом в разделах 2.3.2 и 2.4.3).
Грамматика
Грамматика ИПЯ представляет собой совокупность отношений между лексическими единицами языка и правил их выражения. Грамматические отношения в дескрипторных и вербальных языках бывают двух видов: синтагматические (текстуальные, контекстные) и парадигматические (базовые). Синтагматические отношения - это отношения между лексическими единицами, возникающие в определенной ситуации, в определенном контексте (т. е. в тексте — в данном документе или запросе). Для фиксации синтагматических отношений, отражающих связи между ЛЕ (т. е., фактически, между понятиями) в тексте, вводятся специальные грамматические средства. Набор и способы записи этих средств различны в разных ИПС и зависят от назначения системы и других факторов.
В системах 1960—1970-х гг. наибольшее распространение получили указатели роли и связи53. Указатели роли определяют, какое категориальное значение имеет в тексте (и соответственно, в ПОД) тот или иной дескриптор, и играют в ИПЯ роль квазиграмматических категорий. В качестве примеров таких категорий можно назвать «процесс», «свойства», «материал», «оборудование», «среда». Фактически, с указателями роли в дескрипторные ИПЯ вводятся элементы фасетного анализа. Обозначаются указатели роли посредством соответствующих буквенно-цифровых кодов, приписываемых дескрипторам в ПОД и ПОЗ. Естественно, эти грамматические категории соответствующим образом должны учитываться в критериях смыслового соответствия и программах поиска.
Указатели связи определяют, какие из дескрипторов в тексте (в документе или запросе) связаны между собой (логически или синтаксически). Обозначаются они также особыми символами, приписываемыми дескрипторам в ПОД и ПОЗ.
Приведем пример указателей роли из языка ИПС Американского общества инженеров-химиков54:
A. То, что вводится (загружается) в химическую реакцию или подвергается переработке.
B. Продукт, побочный продукт, продукт, сопутствующий реакции или процессу производства.
C. Брак, отход, загрязнение.
D. Особый агент, катализатор.
E. Растворитель, среда, окружение.
F. Независимая переменная, действие которой изучается.
G. Независимая переменная, изучаемая с точки зрения воздействий на нее.
Н. Активное понятие, предмет изучения.
I. Пассивное понятие.
J. Приборы, материалы или методы, используемые для производства операций.
Их использование при индексировании можно показать на следующем реферате:
«Осушение жидкостей распылением без применения атонизирующего газа. Латентная теплота подается прямым излучением от горячей стены к распылителю...».
Тогда поисковый образ этого документа можно представить следующим образом55:
жидкость-А, распыление-J, сушка-Н, атомизация-J, газ-j, латентная теплота-J, излучение-J, стена-1.
Использование указателей роли и связи увеличивает смыслоразли-чительную силу ИПЯ и позволяет улучшить поисковые характеристики ИПС, в частности, точность. Так, вышеприведенный реферат не будет выдан на запрос со словами «... методом сушки», так как в поисковом образе запроса этому дескриптору будет приписан указатель «J» (сушка - J), отличный от указателя роли для дескриптора «сушка» в ПОД. Но при этом неизбежно усложняются методика индексирования и критерий соответствия (т. е. усложняется процесс смыслоотождествления), что может привести к снижению других характеристик, а именно, полноты. Индексирование документов с применением указателей роли и связи требует также дополнительных трудозатрат и влечет за собой возможность ошибок. Все это привело к тому, что на практике в современных ИПС указатели роли и связи, как правило, перестали использоваться.
Парадигматические отношения относятся к словарному составу языка и, в отличие от естественных языков, в словаре (тезаурусе) отображаются в явном виде. Парадигматические отношения обусловлены наличием логических связей между понятиями как элементами, отражающими объекты и явления реального мира. Они отражают смысловые связи между ЛЕ ИПЯ, зависящие не от контекста, а от отношений между объектами в реальном мире. К их числу относятся иерархическое отношение (род-вид), а также многочисленные отношения, получившие название ассоциативных (часть—целое, предмет-свойство, процесс—результат и др.). Справедливости ради следует сказать, что эти отношения (например, причина-следствие) не всегда независимы от контекста. Смысловые (логические) связи между понятиями в явном виде фиксируются в информационно-поисковых тезаурусах (ИПТ). Можно сказать, что ИПТ - это семантическая модель плана содержания соответствующей области знания.
Собственно говоря, грамматике в узком смысле принадлежат только синтагматические отношения. Поэтому иногда вместо грамматики говорят о синтаксисе ИПЯ. Языки, в которых есть средства для выражения синтагматических отношений, называют «ИПЯ с грамматикой», а те, в которых таких средств нет - «ИПЯ без грамматики» (или «ИПЯ с мешочной грамматикой», когда расстановка дескрипторов или ключевых слов не зависит от значения или положения соответствующих им понятий в индексируемом тексте).
В ряде случаев отсутствие указателей связи компенсируется другими способами. Наибольшее распространение получили средства фиксации линейной структуры текста и принадлежности ЛЕ к соответствующим структурным составляющим документа, таким как предложение, абзац, раздел, глава и т. п. Подобные средства, позволяющие использовать порядок следования лексических единиц, структуру и деление текста на части, получили название «контекстной», «линейной», «позиционной» или «позиционно-скобочной» грамматики. К ним относятся специальные контекстные (позиционные) операторы, или квалификаторы, ограничивающие область действия обычных булевых операторов И, ИЛИ, НЕ (см. 2.4 «Языки запросов»).
Существуют языки (семантические и синтагматические) и с более сложной грамматикой, например, с представлением в ПОД и ПОЗ синтаксических зависимостей между ЛЕ ИПЯ. Способы их фиксации могут базироваться на грамматике зависимостей или иметь собственные грамматические средства типа глубинного синтаксиса. КСС в этом случае должен учитывать отношения синтаксического подчинения,
Все системы (языки) с точки зрения своего состава можно поделить на 4 типа (А, Б, В, Г).
Таблица. 2.1 Типы систем по составу ИПЯ
| Наличие фиксированного ____ словаря Наличие грамматики ' -_____ | Нет | Есть |
| Нет | А | Б |
| Есть | В | Г |
Системы типа УНИТЕРМ не имели ни фиксированного словаря, ни грамматики (тип А). Первые дескрипторные языки имели только словарь (тип Б). Классические ИПЯ (дескрипторные, семантические, синтагматические) относятся к классу Г. Постепенно среди документальных систем «победил» тип ИПС с вербальными ИПЯ (без фиксированного словаря) с линейной грамматикой (тип В).
Разделение языковых средств ИПС на словарные и грамматические довольно условно, как в ЕЯ, так и в ИПЯ. Например, какое-либо понятие в языке может обозначаться словосочетанием. В ИПС без фиксированного словаря элементы такого словосочетания будут связаны синтагматической связью. В ИПС с фиксированным словарем это словосочетание может быть задано непосредственно в словаре в дескрипторной статье, т. е. то, что в первом случае представлено как грамматическая связь, во втором случае будет выражено лексически. Указатели роли, эти своего рода информационно-поисковые «члены предложения», могут выступать как грамматические средства, а могут фиксироваться в ИПС как элементы лексики56.
2.3. Индексирование
2.3.1. Содержательные аспекты индексирования
Индексирование — одно из основных понятий информационного поиска. Традиционный документальный поиск основан на использовании поисковых образов документов и запросов. Поисковым образом документа служит составленный по определенным правилам текст, в котором выражена центральная тема или предмет этого документа (запроса) и (частично) сопутствующие ей темы или предметы. Так же создается поисковый образ запроса. Процесс выбора и присвоения документам и запросам или их частям индексов - лексических единиц ИПЯ - называют: индексированием. Цель процесса индексирования в информационной системе - приписать каждому документу и запросу некоторое множество «индексов» - идентификаторов, отражающих содержание документа. Идентификаторы называют индексами, рубриками, индексационными терминами, ключевыми словами, дескрипторами, полями и т. д., в зависимости от типа используемого ИПЯ. Эти «индексы» отражают содержание документа и управляют поиском, приводя к тем документам, термины которых оказываются наиболее сходными с терминами запроса.
В соответствии со стандартами под индексированием документов понимаются «процессы описания их смыслового содержания средствами ИПЯ с целью обеспечения высоких показателей их поиска. Итоговая продукция этих процессов содержится в поисковых образах документов (ПОД), каждый из которых представляет собой совокупность характеристик конкретного документа, выраженных в знаках или терминах ИПЯ»57.
Процесс индексирования, т. е. выбор дескрипторов для включения в ПОД и ПОЗ, определяется специальными инструкциями, называемыми методикой индексирования. Эффективность поиска во многом определяется качеством индексирования, которое зависит как от качества словаря, от методики индексирования, так и от знаний и опыта индексатора. В оценке качества индексирования, как и при поиске, используют показатели полноты (глубины) и точности (детальности) индексирования. Полнота определяется, в первую очередь, количеством дескрипторов, включенных в ПОД (ПОЗ), точность — так сказать, их «качеством», т. е. смысловой близостью выбранных дескрипторов к основному содержанию документа (запроса). Эти характеристики, так же, как полнота и точность поиска, находятся в отношении обратной зависимости. Для обеспечения полноты индексирования и поиска применяется избыточное индексирование документов или запросов. Под избыточным индексированием понимается дополнение ПОД и ПОЗ дескрипторами, связанными по смыслу с основными.
Процесс индексирования разделяют на несколько более мелких операций, основных и вспомогательных, выполняемых последовательно или одновременно. Число таких операций у разных исследователей и в разных системах может существенно различаться. Так, А.И. Черный и Ю.И. Шемакин58 указывают на две операции - работу по выделению ключевых слов и нормализацию лексики по тезаурусу. Ф.С. Воройский приводит пять основных операций59. Есть методики, где процесс индексирования разбивается на несколько десятков операций, большая часть которых является второстепенными и вспомогательными. Большинство отечественных описаний процесса анализа и индексирования информации базируются на методических указаниях и материалах ВИНИТИ60, в соответствии с которыми процесс индексирования включает в себя шесть основных операций:
- анализ содержания документа и выбор из текста номинативных лексических единиц, существенных с точки зрения его содержания;
- формирование перечня ключевых слов (морфологически нормализованных ЛЕ), используемых в процессе свободного координатного индексирования;
- нормализацию ключевых слов по форме и содержанию при помощи словарей ИПЯ, используемых при контролируемом индексировании;
- избыточное индексирование — введение в ПОД дополнительных ЛЕ, связанных по смыслу с исходными КС и выбираемых из словаря ИПЯ;
- введение в ПОД грамматических средств (типа указателей роли и связи);
- заполнение рабочего листа предмашинного формуляра ПОД и/или его ввод в компьютер.
Иногда в числе операций, имеющих отношение к индексированию, рассматривают или просто упоминают библиографическое описание произведений печати. Это правомерно в той мере, в какой элементы данных библиографических записей используются при проведении поиска информации.
В отечественной информатике широко применяется схема анализа и индексирования информации, представленная в монографии Ю.И. Шемакина61. Эта модель индексирования, с теми или иными модификациями и дополнениями, определяющимися спецификой логико-понятийного аппарата предметных областей знания, нашла применение в большом числе ИПС. Процесс индексирования, по Ю.И. Шемакину, должен идти в определенной последовательности и по единой логической схеме, чем обеспечивается унификация описания документов и постоянство (единообразие) индексирования. В схеме анализа информации выделяются следующие обобщенные элементы (смысловые аспекты)62:
предмет или тема высказывания;
сторона, с которой исследуется предмет или его свойства, признаки, закономерности;
область применения или использования предмета;
конкретный метод исследования;
методика проведения исследования и специальное оборудование, используемое для изучения предмета или его свойств;
условия, при которых проведены исследования предмета.
В цитируемой работе приводится пример индексирования информации с использованием описанной схемы анализа документов63.
Понятие «предмет индексирования» у данного автора (и у многих других) интерпретируется весьма широко и без каких-либо содержательных ограничений. «Применительно к документам по научно-технической тематике в качестве предмета исследования (разработки) могут выступать общие и частные понятия, а также любые материальные объекты: изделия, устройства, образцы техники и имущества, виды и системы вооружения»64. Важнейшее понятие предмета текста относится к области понимания и, как многие явления семантики, не имеет точного определения, хотя и является интуитивно понятным. Отсюда различные и весьма широкие толкования этого термина. В англоязычной литературе по информационному поиску вместо термина предмет (subject) иногда используется термин «aboutness»65. И этот термин хорошо отражает сущность документального поиска.
Неоднозначность понятия «предмет» относится как к информатике, так и к библиотечному делу, где оно входит в число базовых понятий66. В работе западной исследовательницы М. Бэйтс говорится: «Практически невозможно определить, что значит "предмет документа" или что следует искать в документе, чтобы идентифицировать его "предмет"... Мы, специалисты по каталогу, обычно видим, что этому, самому важному в практике предметизатора навыку обучают в таких маловразумительных выражениях как: "ищите основную тему документа"»67. Приведем еще один вариант определения из отечественной литературы: «Предмет произведения печати, это понятие в узкоспециальном смысле, означает тему, которой в основном, непосредственно посвящено произведение»68.
В зарубежных работах по библиотековедению и информатике для определения сущности понятия «предмет документа» часто используется теория Т. ван Дейка69. По ван Дейку восприятие текста - это акт когнитивной редукции (компрессии). Этот акт состоит в опускании информации, менее значимой для читающего, которое продолжается до тех пор, пока важная информация не будет приведена в такое состояние, что ее можно сохранить в памяти. Результатом этого процесса и будет тема, предмет, содержание документа. Во многих отечественных источниках, в частности, в работах Л.В. Сахарного, В.П. Леонова, Д.И. Блюменау™, также показано, что понятие «предмет документа» связано с процессом свертывания и развертывания информации.
Предметное индексирование должно отражать особенности пользователей фонда документов и их требований к информации71. Также в поисковые образы, наряду с содержательными, могут входить и формальные характеристики документов (автор, дата создания, регион, тип данных и т. п.)
В методиках индексирования и в исследованиях делались попытки структурировать ПОД и тем самым выделить составные части понятия «предмет индексирования». Так, Ю.И. Шемакин, развивая выделенные им аспекты индексационной схемы, пишет: «Первые три смысловых аспекта поискового образа отражают информацию, касающуюся предмета исследования, остальные характеризуют сам процесс исследования»72. Таким образом, получается, что, с одной стороны, предмет индексирования информации - это ключевое слово или понятие, выражающее в обрабатываемом документе предмет исследования, а с другой стороны, сложный предикат, сочетающий, по крайней мере, три смысловые компоненты: предмет - сторона его рассмотрения - область применения. Последняя интерпретация хорошо согласуется с некоторыми положениями лингвистики текста, например, с характеристикой темы дискурса (связного текста) у Т. ван Дейка73 - тема есть пропозиция, а не просто отдельный концепт, из чего вытекают некоторые общие положения моделей анализа содержания документов.
Стороны рассмотрения предметов представлены, как правило, лексикой с процессуальным значением, как, например, «производство», «эксплуатация», «применение», «автоматизация» и т. п. или терминами с обобщенным значением типа «технические требования», «стоимость».
В качестве области применения предмета выступают любые другие предметы или целые предметные области, отрасли хозяйства, военные операции и другие процессы и операции, рассматриваемые как применения предметов исследования и разработки.
Индексирование запросов имеет свою специфику и обычно рассматривается как составная часть общего процесса составления и отладки поисковых предписаний (см. раздел 2.4 «Языки запросов»)74.
В современных системах ручное интеллектуальное индексирование документов, как правило, уже не применяется, и поэтому многие проблемы индексирования документов ключевыми словами в документальных ИПС, равно как и проблемы создания и применения тезаурусов, в настоящее время как бы ушли на периферию исследований. Однако это не отменяет их значимости с точки зрения поиска в целом как интеллектуальной семантической задачи.
Часто индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов, в которых он встречается. Такая процедура является только частным случаем, а точнее, техническим аспектом создания поискового аппарата ИПС.
2.3.2. Автоматическое индексирование
Практически с самого начала развития информационного поиска предпринимались попытки автоматизации процедур индексирования. Начало исследованиям по автоматизации индексирования положили работы Г. Луна75 и П. Баксендейла76, а в нашей стране - Д.Г. Лахути77. В этой области накоплен большой теоретический и экспериментальный материал. Однако в реальности эти исследования оказались (возможно, на какое-то время) невостребованными. Это связано как со сложностью практической реализации задачи полноценного автоматического индексирования (АИ), так и с общими тенденциями развития документального поиска, а именно - с переходом от дескрипторных языков к вербальным, с поиском по полному тексту с применением средств линейной грамматики и т. д.
Существовали и существуют и практически работающие системы (СКОБКИ, АИДОС, CAS, MEDLINE и др.). Но, как правило, автоматизировались лишь некоторые стороны предметного индексирования, а именно, не связанные с процессом понимания содержания документов.
При АИ используются словарные, морфологические, семантические, прагматические, статистические, межфразовще методы анализа текста. Существующие средства АИ могут быть сгруппированы следующим образом:
- алгоритмы морфологического анализа и соответствующие словари для разделения слов на основы и аффиксы;
- алгоритмы морфологического синтеза и соответствующие словари для порождения канонической формы слова;
- дескрипторный словарь (словарь синонимов), используемый для замены значащих слов именами понятий, каждое из которых представляет класс основ слов, близких по смыслу;
- иерархическая структура понятий (информационно-поисковый тезаурус), позволяющая для данного определенного входа (лексемы) словаря найти более широкие понятия, идя вверх по иерархии, или более узкие, спускаясь вниз;
- методы статистических ассоциаций, применяемые для расчета коэффициентов подобия между словами, основами слов или понятиями, для «вычисления» статистических словосочетаний и базирующиеся на принципе совместной встречаемости этих элементов в предложениях документа;
- методы синтаксического анализа для «вычисления» синтаксических словосочетаний, которые позволяют распознать и использовать в качестве характеристик содержания документа словосочетания, состоящие из нескольких слов или понятий, связанных между собой определенными синтаксическими связями;
- методы распознавания словосочетаний на основе предварительно созданного словаря словосочетаний.
Не касаясь конкретных разработок, кратко остановимся на методах лингвистического анализа, так или иначе присутствующих во всех системах с автоматическим анализом документов. Программы лингвистического анализа всегда начинаются с морфологического анализа, решающего несколько частных задач. Прежде всего, это определение части речи, так как во многих системах в ПОД включаются лишь существительные и номинативные группы. Эта задача может быть решена упрощенными методами, которые базируются на списках конечных буквосочетаний, характерных для тех или других частей речи (длина буквосочетаний при этом колеблется от одной до пяти букв)78.
Основная цель морфологического анализа — определение грамматических характеристик словоформ. В настоящее время морфологический анализ основывается, как правило, на словарных методах79. При этом используются различные типы словарей и лексико-грамматических списков: словари основ (корней), словоформ, флексий, суффиксов, списки неизменяемых слов, чередований и т. п. В зависимости от вида основной словарной статьи различают словари словоформ и словари основ. Во втором случае объем словаря значительно меньше, зато увеличивается и усложняется таблица грамматических признаков, сопровождающая каждую основу, включаются дополнительные словари флексий, аффиксов и др. В словаре словоформ словарная статья обычно состоит из самой словоформы, длины словоизменительной основы, возможно, длины словообразовательной основы, признака лексической категории слова и набора грамматических признаков. Слова, принадлежащие нескольким лексическим категориям, могут иметь несколько словарных статей. Если слово имеет несколько толкований, в его словарной статье может использоваться несколько наборов грамматических признаков. При словоизменительном анализе производится отсечение окончаний (квазиокончаний), их сравнение со списком окончаний и проверка их принадлежности к флективному классу выделенной основы. Для повышения точности морфологического анализа в ряде систем проводится еще и словообразовательный анализ80. В результате анализа по словарю каждое входное слово получает набор лексических и семантических категорий, а также ряд грамматических характеристик, определяемых функциями слов в контексте и используемых на последующих этапах, в частности, на этапе синтаксического анализа.
Синтаксический анализ в информационно-поисковых системах используется очень ограниченно, как правило, для выделения номинативных синтагм.
Наряду с приписыванием словам документа грамматических характеристик, на этом этапе также может решаться задача морфологической нормализации, т. е. приведения словоформы (всех словоформ одной и той же лексемы) к стандартному (словарному) виду. Это позволяет уменьшить объем инвертированного файла и упростить процедуру сравнения слов при поиске (словоформы поисковых предписаний нормализуются по тем же алгоритмам). При порождении стандартной формы ЛЕ требуется производить учет чередования гласных и согласных в основе. Введение в словарь индексов словообразовательных классов позволяет нормализовать даже те слова, которые отсутствуют в словарях81.
Автоматическое индексирование в дескрипторных ИПС, основывающееся на дескрипторных словарях и тезаурусах, называют приписным (или индексированием по тезаурусу). Индексирование, при котором лексический контроль отсутствует и в ПОД включаются ключевые слова непосредственно из документов, называется дериватным (или свободным). Сравнительная оценка различных режимов индексирования с применением тезауруса дается в книге Ю.И. Шемакина82. Сегодня большинство работающих ИПС относится к классу вербальных систем бестезаурусного типа, применительно к которым можно говорить о дериватном индексировании либо вообще лишь о подобии индексирования (когда, например, из поисковых файлов исключаются незначащие слова, а все остальные термины документа участвуют в поиске).
В обзоре Ф. Ланкастера83 на основе сравнительных экспериментов делается вывод, что дериватные методы, в том случае когда индексационные термины выбираются из текстов документов, оказались более успешными, чем автоматическое индексирование методом приписывания, когда индексы выбираются из классификационной схемы или тезауруса.
В последнее время проблема АИ в основном решается в рамках создания систем искусственного интеллекта. В информационно-поисковых системах задачи, решаемые подсистемой АИ, решаются в других блоках и другими средствами. Однако проблемы поиска в сети Интернет делают задачу АИ, как для вербальных систем, так и для классификационных, весьма актуальной.
2.4. Языки запросов
2.4.1. Понятие и состав языка запросов
Информационный запрос -это словесное выражение определенной информационной потребности. Запросы анализируются по своему предметному содержанию и описываются в терминах, отобранных из словаря конкретного ИПЯ. Как известно, процедура собственно поиска состоит из поочередного сопоставления поискового образа запроса с поисковыми образами документов и вычисления (по установленным правилам) их соответствия (степени соответствия). Если такое соответствие имеется, то документ, соответствующий данному поисковому предписанию, считается релевантным (т. е. отвечающим (предположительно!) на Данный информационный запрос) и подлежит выдаче.
Обычно считают, что индексирование и поиск являются зеркальными отражениями друг друга. При индексировании содержание документов каким-то образом описывается или представляется. Со стороны поиска пользователь формулирует информационную потребность в виде пользовательского запроса или поискового предписания. Затем эти два представления документа и запроса сопоставляются в блоке поиска. На самом деле отношение симметрии между индексированием и поиском является кажущимся, поверхностным. Опыт пользователя кардинально отличается от опыта индексатора, так как. пользователю предстоит описать что-то ему еще не известное, т. е. некий «пробел» в его знаниях. Это приводит к неточности в описании информационной потребности или к описанию более широкой тематической области. При этом, естественно, словарь пользователя и словарь индексатора не совпадают. Это противоречие является одной из центральных проблем информационного поиска.
Далее: индексатор обычно не знает или не задумывается над критерием смыслового соответствия, в то время как для пользователя это знание обязательно и критерий тем или другим способом входит в понятие «язык запросов».
Языки запросов, служащие для построения ПП, объединяют собственно ИПЯ и критерий смыслового соответствия, а также могут содержать в себе требования к интерфейсу выдачи. Обобщенная структурная модель языка запросов включает следующие элементы:
- собственно поисковые элементы (термины, выражающие информационную потребность, и т. п.);
- средства морфологической нормализации текстовых элементовзапроса;
- поисковые (булевы) операторы;
- средства линейной грамматики (операторы расстояния, позиционные операторы);
- дополнительные условия поиска:
- поиск в определенных полях (частях) документа;
- ограничение области поиска по языку, региону, дате создания документа;
- Средства управления критерием смыслового соответствия;
- требование на сортировку (ранжирование) выдаваемых результатов поиска;
- требования к форме представления результатов поиска:
- вид выдаваемых результатов;
— количество выдаваемых документов.