
Основные понятия информационного поиска информационные процессы и системы
| Вид материала | Документы |
- Полный курс лекций по Информационным системам информационные системы, 787.33kb.
- Конспект лекций для специальности «Прикладная информатика в экономике», 1468.57kb.
- Организационные основы информационных технологий в экономике, 44.75kb.
- Информационные системы (теория к экзамену) Основные понятия информационных систем, 82.21kb.
- Курсовая работа предмет: Информационные системы Тема: Языки информационного поиска, 154.92kb.
- Информация и информационные процессы, 276.11kb.
- Справочно-информационные системы в подготовке юриста, 31.18kb.
- 1 Информация. Кодирование информации, 59.79kb.
- Инициативный проект Российского семинара по оценке методов информационного поиска (ромип), 149.92kb.
- Программа по дисциплине «прикладные протоколы интернет и www» по направлениям: «Математика., 234.28kb.
1.3.2. Методы определения релевантности
Остается открытым вопрос о способах и методах определения различных видов релевантности. Относительно пертинентности ясно: ее должен оценивать потребитель информации, ибо только он может сказать, насколько тот или иной документ соответствует его информационной потребности. При этом оценка потребителя зависит от характера стоящей перед ним практической задачи, уровня его научной квалификации и других факторов.
Но кто и каким образом должен определять релевантность? На этот счет существуют различные мнения. С учетом того, что в предыдущем разделе говорилось о релевантности, можно сказать, что суждение о релевантности есть присвоение некоего значения одной из релевантностей человеком-экспертом в определенный момент времени. Эти суждения о релевантности можно классифицировать по пяти измерениям:
- «документная» сущность, на основе которой выносится суждение (поисковый образ, документ или информация);
- «запросная» сущность, которую использует эксперт для того, чтобы вынести суждение (поисковое предписание, пользовательский запрос, информационная потребность или проблема);
- компонента, относительно которой выносится суждение (тема, задача, контекст);
- момент времени, в который выносится суждение о релевантности;
5) тип эксперта (пользователь или специалист).
Релевантность - понятие субъективное: известно, что разные эксперты выносят разные суждения о релевантности27. Желательно, чтобы оценка релевантности осуществлялась по формальным правилам, обеспечивающим необходимое единообразие в этих оценках.
Имеются такие варианты выражения суждений о релевантности:
- дихотомия (да/нет);
- шкалы, в которых для суждений о релевантности существует несколько значений;
- численное значение величины релевантности. По данной проблематике имеется значительное число публикаций28.
Для современных работ по релевантности характерен переход от исследований, ориентированных на систему, т. е. выявляющих влияние на релевантность различных поисковых средств, к исследованиям, ориентированным на пользователя29.
1.4. Состав информационно-поисковой системы
Напомним, что информационно-поисковая система представляет собой совокупность средств, предназначенных для хранения, поиска и выдачи информации по запросам. Это:
- информационные массивы (документы, запросы, метаданные);
- логико-лингвистический аппарат, включающий информационно-поисковый язык (ИПЯ), правила его использования и критерий смыслового соответствия, а также некоторые другие лингвистические средства;
- вычислительные средства, обеспечивающие реализацию функций системы (программы, компьютеры);
- средства, обеспечивающие ее эксплуатацию (персонал, инструктивно-методические материалы и т. п.).
ИПС в этом составе называют конкретной (рабочей) ИПС в отличие от абстрактной ИПС, включающей только части 1 и 230. Об абстрактной ИПС можно говорить как о логико-лингвистической модели, которая и определяет в первую очередь тип системы и качество поиска. Д.Г. Лахути предлагает названия «информационно-поисковая система» (абстрактная ИПС) и «информационно-поисковая служба» (конкретная ИПС)31.
Составные части ИПС называют подсистемами. Разделение на подсистемы необходимо и полезно как в целях разработки, так и для описания технологии функционирования систем. Оно может иметь разную основу. Обычно рассматривают два типа разбиения ИПС на подсистемы: по функциональному принципу (функциональные подсистемы) и по типу средств (обеспечивающие подсистемы)32.
1.4.1. Обеспечивающие подсистемы
Различные средства, реализующие функции ИПС, получили название обеспечивающих подсистем, или «обеспечений». В обобщенном виде это четыре части, перечисленные выше и составляющие конкретную ИПС. При более дробном делении выделяют следующие подсистемы: лингвистическое обеспечение, информационное обеспечение, техническое обеспечение, программное обеспечение, технологическое обеспечение, кадровое обеспечение и др.
Информационное обеспечение - это информационные массивы (документы, запросы, метаданные), а также средства и способы их описания, построения и классификации.
Лингвистическое обеспечение — это логико-семантический аппарат, состоящий из информационно-поискового языка, правил применения (методик индексирования), критерия выдачи и других языковых средств.
Программное обеспечение—это алгоритмы и программные средства, реализующие все функции ИПС, выполняемые с помощью компьютера.
Техническое обеспечение — это технические средства (компьютеры, средства телекоммуникаций), обеспечивающие хранение, поиск и передачу информации.
Технологическое обеспечение — это набор и порядок выполнения автоматизированных и неавтоматизированных процессов и процедур обработки информации в ИПС, включая их описание, информационно-технологические схемы и инструктивно-методические материалы.
Кадровое (или штатное) обеспечение - это люди, взаимодействующие с системой и обеспечивающие ее эксплуатацию (обслуживающий персонал)34.
На начальных этапах развития ИПС говорилось об информационно-лингвистическом обеспечении, впоследствии эти два вида средств стали рассматривать отдельно, хотя граница между ними довольно подвижная. В частности, языки представления и описания информации можно отнести как к лингвистическому, так и к информационному обеспечению.
1.4.2. Функциональные подсистемы
ИПС также делят на составные части (подсистемы) по функциональному признаку, когда каждая подсистема выполняет определенную функцию в технологическом процессе: ввод документов, индексирование документов, ввод и корректировка запросов, индексирование запросов, поиск, ведение словарей, ведение статистики, обработка результатов поиска, выдача документов и др. Такие части получили название функциональных подсистем. Эти подсистемы образуют структурную (еще говорят, процессную, операционную) модель ИПС.
На рис. 1.1 показан пример функционально-операционной схемы ИПС как совокупности взаимосвязанных модулей (операций). Объединение модулей в подсистемы достаточно условно и может производиться по-разному. В частности, приведенные на рис. 1.1 модули могут быть объединены в пять функциональных блоков (подсистем) - рис. 1.2.
Перечислим эти подсистемы, на рисунке обозначенные цифрами: 1 — подсистема обработки документов; 2 - подсистема обработки запросов; 3 - подсистема поиска; 4 - словарная подсистема; 5 - подсистема обработки и выдачи результатов поиска33.
Каждый модуль в отдельности также строится как маленькая подсистема, состоящая из более мелких функциональных элементов, интегрированных в виде программ. Покажем это на примере модуля «Пред-машинная обработка документов», который может быть разбит на более мелкие составные элементы (операции), а именно:
- идентификация документов;
- форматная разметка документов;
- составление метаописания;
- индексирование документов.
Модуль «Формулирование запроса» может состоять из элементов:
- определение темы запроса (информационной потребности);
- выделение подтем;
- индексирование запроса;
- смысловое расширение;
- задание ограничений поиска;
- запись поискового предписания на языке запросов конкретной системы.
В других условиях часть этих элементов может реализовываться в других модулях (например, «Индексирование запроса» может выполняться в модуле «Поиск» и т. д.). Прежде всего важны системные взаимосвязи каждого элемента или модуля с другими с учетом глобальной цели.35
1.5. Математическая модель документальной ИПС
Рассмотрев способы декомпозиции ИПС на подсистемы, определим теперь само понятие «система». Система определяется как совокупность элементов, обладающая:
а) связями, которые позволяют посредством переходов по ним от элемента к элементу соединить два любых элемента совокупности;
б) свойством (назначением, функцией), отличным от свойств отдельных элементов совокупности36.
Информационно-поисковая система всецело отвечает такому определению.
Применяя так называемое кортежное определение, систему можно представить в виде следующей записи:
S:{{M},{X},F}, где S-система;
{M} — совокупность элементов;
{X} - совокупность связей;
F - функция (новое свойство) системы.
Это наиболее простое описание системы. Существуют формы записи, включающие более 10 членов кортежной последовательности, соответствующих различным свойствам сложных систем37.
В качестве элементов системы выступают объекты (материальные, информационные), обладающие рядом важных свойств, но внутреннее устройство которых в данном случае не рассматривается.
Связями между элементами системы называют воздействия, которые один элемент оказывает на другой. В информационных системах чаще всего эти связи заключаются в передаче данных.
Определенные группы элементов образуют части системы, называемые подсистемами. Каждая подсистема представляет собой группу элементов, имеющих сильные связи между собой и слабые - с элементами других групп (подсистем). Совокупность подсистем с указанием связей между ними называется структурой системы.
Символьно автоматизированную ИПС можно представить следующим образом:
S = {{Мт}, {Мч}, {Мя}, {Ми}, {М„}, {Мх}, {М.}, {X}, F}, где Мт — технические средства (компьютеры),
Мч - действия и решения человека,
Мя - языковые средства,
Ми - информационное обеспечение,.
Мп - программное обеспечение,
Мх - технологическое обеспечение,
ML - остальные средства системы,
X - совокупность связей между элементами системы,
F - функция системы.
Декомпозицию системы и кортежное определение можно усложнять и далее, разбивая подсистемы на отдельные средства, а глобальную цель на локальные. ИПС, как и все искусственные системы, относятся к типу Целенаправленных систем. Проектирование любой целенаправленной системы представляет собой разбиение глобальной цели, стоящей перед системой, на локальные цели, стоящие перед подсистемами (модулями) и выступающие как требования к выходным характеристикам модулей. Очевидно, что при таком подходе крайне важно согласование локальных целей и объединение частей в целенаправленную систему. Заметим, что согласование обычно является сложной, плохо формализуемой процедурой. Автоматизированные ИПС относятся к классу так называемых сложных систем, состоящих из элементов разных типов и обладающих разнородными связями между ними38.
1.6. Документы и запросы
Слово «документ» происходит от лат. documentum - «свидетельство». Понятие документа меняется с течением времени, постоянно появляются новые формы документов. Но и старые формы претерпевают изменения. В соответствии с российским государственным стандартом документ определяется как средство закрепления любым способом на специальном материале любой информации о фактах, событиях, явлениях объективной действительности и мыслительной деятельности человека.
Существуют различные классификации документов. Одним из существенных является деление документов на первичные и вторичные. К первичным относят документы, содержащие информацию, исходящую от автора. К вторичным - документы, являющиеся результатом обработки одного или нескольких первичных. Обычно такую обработку называют аналитико-синтетической. В качестве особого вида вторичного документа можно рассматривать поисковый образ документа (ПОД), являющийся результатом индексирования — записи основного содержания на специальном информационно-поисковом языке.
Документы имеют различную форму представления. В автоматизированных документальных ИПС это прежде всего текстовая информация на естественных языках в машиночитаемой форме. Существенное значение для поиска имеет внутренняя структура документов: разбиение их на поля и наличие элементов метаописания. Структура может разрабатываться специально для конкретной ИПС или же определяться конкретными стандартами. Языки структурирования и описания документов рассматриваются во 2-й главе. Также важны форматы и кодировки документов.
В ИПС обычно имеются два типа массивов - так называемые первый и второй «контуры». Под первым контуром понимаются поисковые массивы (поисковые образы документов), хранящиеся в компьютере (на внешних носителях), под вторым - массивы первичных документов, хранящихся часто вне компьютера (на бумаге или на микроносителях) или
на других компьютерах (напр., в сети Интернет). В последнее время этот термин (контур) используется все реже.
Для обеспечения эффективного и быстрого поиска большую роль играет физическая организация массивов. Особенно остро этот вопрос стоит при обработке полнотекстовых документов.
Вторая часть информационного обеспечения ИПС - это запросы. Выше, в разделе 1.3.1, уже говорилось, что запрос представляет собой информационную потребность, сформулированную на естественном языке. Результат «перевода» информационного запроса на информационно-поисковый язык называют поисковым образом запроса (ПОЗ). И выявление информационной потребности, и индексирование запросов представляют собой сложные семантические процедуры. Наряду с термином «поисковый образ запроса» используется понятие «поисковое предписание» (ПП). Под этим понимают выражение на языке запросов, который включает в себя как собственно ИПЯ, так и средства управления поиском. Синтаксис и семантика языков запросов определяются структурой и наполнением документов и общими задачами системы. Для того чтобы составить адекватное 1111, пользователь должен знать язык запросов и информационно-поисковый язык, т. е. представлять себе уровень «понимания», «интерпретации» поисковой системой содержания документов.
Третья часть информационного обеспечения - так называемая «выдача», результаты поиска. Выдача существует в двух видах: краткие описания документов и собственно документы. Знание того, каким образом система интерпретирует документы, «что система умеет искать», необходимо не только для правильного составления ПП, но и для правильной интерпретации выдаваемых системой результатов. В любом случае поиск, выполняемый ИПС по составленному ПП, является чисто формальной компьютерной обработкой данных по заданной программе. Какой бы то ни было сущностный смысл в заданный системе вопрос и полученный от нее ответ вкладывает пользователь.
1.7. Информационно-поисковый язык
Важнейшей компонентой информационно-поисковых систем является информационно-поисковый язык. Человек, чтобы отобрать из массива документов нужные, должен прочитать или просмотреть их содержимое. Для ускорения и упрощения этой процедуры появились различные формы сокращенной записи содержания документов - аннотации,
рефераты, каталоги. Но во всех этих случаях при отборе документов по их сокращенным описаниям используется естественный язык. Известно, что акт понимания в языке опирается на сигнификативное значение, которое находится в сложных отношениях с явно выраженными в тексте (в речи) языковыми знаками. Хорошо известны такие «недостатки» языковых знаков, как омонимия, синонимия, многозначность. Точное значение многих слов можно понять только в контексте. Это препятствует использованию естественного языка для фиксации и отождествления понятийной информации. Но этим «асимметрия» и «алогизм» языковых знаков не заканчивается. Неоднозначность и многозначность в языке относятся не только к лексике, но и к грамматике. Одни и те же грамматические отношения могут выражаться по-разному, и одни и те же формы могут иметь разное грамматическое значение. Кроме того, существенные с точки зрения понимания смысла отношения понятий, например, отношение «род-вид», никак явно не отражаются в лексической и грамматической системе естественного языка.
Поэтому формальные системы, предназначенные для хранения документальной информации с целью последующего поиска, потребовали создания специальных информационных языков. Вероятно, первые такие языки, отличные от естественных и получившие название классификаций, были созданы для библиотек. Внедрение в информационный поиск компьютеров способствовало дальнейшему развитию и формализации информационных языков. Информационно-поисковые языки представляют собой знаковые системы, со своим алфавитом, лексикой, грамматикой и правилами пользования. Заметим лишь, что все искусственные языки так или иначе создавались и создаются на основе естественных языков.
Основные требования к информационно-поисковым языкам следующие:
- однозначность между планом выражения и планом содержания (каждая лексическая единица соотносится с одним понятием, и наоборот - каждое понятие имеет уникальное имя, и, как следствие, каждая запись на ИПЯ имеет только один смысл);
- достаточная семантическая сила (способность фиксировать с достаточными полнотой и точностью все существенное в содержании документов и запросов);
• открытость (возможность корректировки и пополнения языка).
Подробнее об ИПЯ см. в следующей главе.
1.8. Критерий смыслового соответствия
При сопоставлении документов и запросов требуется определить релевантность документа по отношению к запросу и принять решение о выдаче или невыдаче документа на данный запрос. Правила, на основе которых формально определяется степень релевантности документа и запроса, т. е. соответствие ПОД и ПОЗ, называются критерием смыслового соответствия (КСС), или критерием выдачи (KB). Описание документа, признанного релевантным запросу (или он сам), помещается в файл результатов поиска, или, как говорят, в выдачу. Именно поэтому появился термин «критерий выдачи», возможно, даже более предпочтительный, как более соответствующий явлению формальной релевантности.
Все применяемые KB можно разбить на две большие группы: количественные и логические. Первые оперируют количественными параметрами, и на основе их для каждой пары «документ - запрос» вычисляется количественное значение (коэффициент) степени смысловой близости (подобия) документов и запросов. Это дает возможность ранжировать документы выдачи в порядке уменьшения коэффициента подобия, а также выдавать то или другое количество документов в зависимости от заданного порогового значения.
Математические модели и формулы вычисления коэффициента подобия могут быть самые разные. В первых поисковых системах KB основывался на теоретико-множественной операции пересечения множеств терминов ПОД и ПОЗ. Степень такого пересечения может определяться в процентах. В этом случае величина значения критерия выдачи R определяется по формуле
R = (M/N)xlOO% , где М - количество совпавших при поиске терминов ПОД и ПОЗ,
N - общее количество терминов в ПОЗ.
Критерий выдачи в этом случае задается как пороговое значение, выраженное в процентах, выше которого находится уровень релевантности. Крайний случай - критерий выдачи, равный 100%, т. е. требование полного совпадения ПОД и ПОЗ или включения ПОЗ в ПОД.
Простые критерии выдачи исходят из равнозначности терминов, входящих в документ и в поисковое предписание. В то же время часто разные термины, как в запросах, так и в документах, не равнозначны с точки зрения отражения в них предметного содержания. В связи с этим появилось понятие весового коэффициента, или «веса» термина. Операцию присвоения терминам весов называют «взвешиванием». Способы взвешивания могут быть разные. Самый простой из них заключается в том, что пользователь при составлении 1111 оценивает каждую лексическую единицу ПП определенным числом - весовым коэффициентом. «Взвешиваться» могут и термины документов, в ручном или автоматизированном режиме. Например, может анализироваться относительная частота встречаемости какого-либо слова. Очевидно, что слова, относительная частота которых в данном документе превосходит относительную частоту для этих слов в совокупности всех документов, являются более значимыми с точки зрения отражения основного содержания данного документа. Другой подход заключается в приписывании повышенных весов терминам, выбранным для включения в поисковый образ документа из наиболее важных зон документа (заглавие, резюме и т. п.).
В этом случае KB вычисляется как функция от значений весовых коэффициентов отдельных поисковых терминов (обычно как сумма весов). Кроме того, пользователь может задать пороговое значение коэффициента выдачи, ниже которого документы не выдаются.
Все эксперименты показывают высокую эффективность ИПС с весовым КСС. Однако на практике постепенно повсеместное распространение получили ИПС с логическим критерием выдачи, когда ПП строятся с использованием логических (булевых) операторов конъюнкции (&), дизъюнкции (V), отрицания (~). В этом случае логическое выражение запроса представляет собой набор поисковых элементов (обычно ключевых слов), объединенных логическими операторами и скобками, необходимыми для указания порядка выполнения операторов. Ключевые слова ПП играют роль булевых переменных, принимающих значение 1 («истина»), если данное слово содержится в документе, и 0 («ложь»), когда оно там отсутствует. Документ признается релевантным запросу, если логическая формула запроса в целом получает для данного документа значение «истина», и нерелевантным, если результат вычисления логической формулы дает «ложь».
Элементарные логические выражения поискового предписания при этом можно интерпретировать следующим образом:
• а&b - в тексте документа обязательно должны быть оба слова, «а» и «b»;
а\/b - в тексте документа обязательно должно быть хотя бы одно из двух слов, или «а», или «b» (хотя могут быть и оба вместе);
• а&-b-в тексте документа обязательно должно быть слово «а» и не должно быть слова «b».
Принятые в логике для обозначения конъюнкции, дизъюнкции и отрицания значки (&, V, ~) в информационном поиске обычно заменяют на операторы AND, OR и NOT, соответственно. В России чаще используются обозначения И, ИЛИ, НЕ. Однако в общем случае в каждой конкретной ИПС обозначения для булевых операторов выбираются свои, причем иногда для удобства пользователя вводится несколько значков для одного и того же оператора (например, в ИПС «Апорт» оператор конъюнкции может быть задан следующими знаками: &, пробел, AND,
и,+).
Чаще всего поисковое предписание в ИПС с логическим КСС записывается как конъюнктивная нормальная форма (конъюнкция дизъюнкций). Оператором ИЛИ (дизъюнкция) обычно связывают термины (или словосочетания), находящиеся в отношении условной синонимии. Оператором И (конъюнкция) связывают термины (или группы терминов), выражающие разные аспекты (подтемы) темы запроса. Например: простое поисковое предписание по теме «Мировые информационные сети» может быть представлено в виде следующего ПП: (мировые V всемирные V глобальные) & информационные &(сети V ресурсы) . Оператор НЕ используется в сочетании с И для отсева документов. Например: поисковое предписание по теме «Жигули на Волге» может быть записано как: Жигули & Волга & НЕ автомобиль.
Использование булевых операторов обеспечивает логику сравнения документов и запросов, понятную пользователю. Поиск (вычисление истинности для элементов 1111), как правило, проводится по инвертированным файлам, построенным на основе словника документального массива, и характеризуется высокой скоростью. Эти простота и понятность логического КСС и явились причиной его широкой распространенности.
В то же время в ИПС с чисто логическим КСС не обеспечивается ранжирование выдаваемых документов, сложно обеспечить контроль за объемом выдачи, возникают проблемы при обеспечении желаемого уровня эффективности ИПС — и поэтому безоговорочная «победа» логического критерия выдачи представляется немного загадочной и, возможно, не окончательной. Один из пионеров информационного поиска Ф. Ланкастер пишет: «Возможно, что использование булевой алгебры для построения автоматизированной поисковой системы было ошибкой... источник которой лежит в сходстве первых поисковых автоматизированных систем с системами, построенными на картах с краевой перфорацией или на принципе оптического совпадения... В этих системах не предусматривалась возможность частичного совпадения и выдачи списков документов, что же касается автоматизированных систем, то в них такого рода ограничения не имеют смысла»39.
1.9. Организация поисковых массивов
В документальных ИПС используются две принципиальные схемы организации информационных массивов: прямая и инвертированная.
Прямая схема организации массива может быть реализована следующим образом (рис. 1.3). Каждая запись массива содержит поисковый образ очередного документа, представленный характерным для него набором дескрипторов, ключевых слов, просто терминов или других поисковых признаков (kw(). Это подокументная организация массива. Весь массив может быть упорядочен по идентификаторам (инвентарным номерам) документов или по любому другому принципу. Однако, поскольку полный ответ по любому запросу может быть получен лишь при условии сплошного просмотра массива, введение какого-либо специального порядка расположения документов не дает никакого эффекта. Прямая схема организации массива целесообразна при групповой обработке запросов, так как за один просмотр массива может быть получен ответ на всю группу запросов. Она является наиболее реальной схемой для систем поиска в режиме избирательного распространения информации, поскольку там поиск производится по (сравнительно небольшому) массиву вновь поступивших документов разом для всех запросов системы.
| Идентификатор документа (ПОД) | Дескрипторы, ключевые слова или другие поисковые элементы | |||||
| D, | | kw2 | | kw4 | | |
| D2 | kw1 | kw2 | kw3 | | kws | |
| D3 | | kw2 | | kw4 | kws | |
| D4 | | | kw3 | | kws | |
| D5 | | kw2 | kw3 | kw4 | | |
| | | | | | | |
| di | | | | | | |
Рис. 1.З. Условный пример прямой схемы организации информационного
массива.
Инвертированная схема организации массива основана на принципе обеспечения доступа к документам через их идентификаторы содержания (поисковые признаки: дескрипторы, ключевые слова, термины). Такую схему получают путем обработки массива с прямой организацией и создания специальных вспомогательных инвертированных (инверсных) файлов - точек доступа. Их еще называют индексными файлами, или индексами. Каждая запись такого вспомогательного массива идентифицирована соответствующим идентификатором содержания (дескриптор, ключевое слово, просто термин, имя автора, название организации и т. п.) и содержит имена (адреса хранения) всех документов, в поисковых образах которых он содержится (рис. 1.4). Для каждого идентификатора содержания (поискового элемента данных) в инвертированном массиве вместе с адресом (номером, именем) документа может храниться (и обычно хранится) дополнительная информация, как-то: имя поля, номер предложения, в составе которых данный элемент встретился в данном документе, номер слова в предложении и т. д.
| Поисковый элемент данных | Идентификаторы документов (ПОДов) | |||||
| kwj | | D2 | | | | |
| kw2 | D, | D2 | D3 | | D5 | |
| kw3 | | D2 | | D4 | D5 | |
| kw4 | D, | | D3 | | D5 | |
| kw5 | | D2 | D3 | D4 | | |
| | | | | | | |
| kwt | | | | | | |
Рис. 1.4. Условный пример инвертированной схемы организации информационного массива.
В этом случае нахождение необходимых документов будет осуществляться не сплошным просмотром всего их массива, а просмотром только тех идентификаторов содержания, которые заданы в поисковом предписании, т. е. число сравнений при поиске примерно равно числу терминов поискового предписания. При этом время обращения к элементам упорядоченных индексов практически не зависит от местоположения элементов в массиве благодаря использованию специальных алгоритмов. Далее полученные списки номеров документов обрабатывается в соответствии с критерием смыслового соответствия. Такой способ сравнения снижает время поиска и позволяет обслуживать потребителей информации в реальном масштабе времени. При повсеместно принятой инверсной организации массивов существует большое разнообразие реализаций, во многом определяющих быстродействие системы.
Существенными недостатками инвертированной схемы являются необходимость переформирования инвертированных массивов после ввода в систему новых документов и дополнительный расход дисковой памяти под инвертированные файлы. Поскольку инвертированные файлы включают все словоупотребления всех слов массива документов (иногда за исключением слов из так называемого списка «стоп-слов» (отрицательного словаря), куда входят незначащие и служебные слова), то их размеры весьма велики. Дня средней ИПС суммарный объем инверсного файла соизмерим с объемом массива документов.
Также применяется комбинированная схема организации массива, когда для поиска по наиболее часто используемым поисковым признакам и в наиболее частых полях документа создается инвертированный указатель, в остальных случаях выполняется поиск по массиву с прямой организацией.
1.10. Оценки эффективности информационно-поисковых систем
Проблема оценки эффективности поиска является комплексной проблемой, включающей как теоретическую, так и практическую сторону40. Различные показатели для оценки информационно-поисковых систем: качественные, временные, финансовые - можно поделить на показатели функциональной эффективности и показатели экономической эффективности. С некоторой долей условности можно сказать, что первые характеризуют абстрактную ИПС, а вторые - информационно-поисковую службу. Такие показатели, как оперативность поиска, трудоемкость, стоимость обслуживания, социальная эффективность и др., очень важны, но имеют лишь косвенное отношение к логико-лингвистическому аппарату.
Показатели функциональной эффективности базируются на понятии релевантности. Проблемы определения и вычисления релевантности рассматривались нами в разделе 1.3. Одно из главных противоречий в оценке функциональной эффективности заключается в том, что большинство специалистов роль арбитра релевантности предлагают поручить потребителю информации. В реальных условиях чаще всего так
оно и происходит. Естественно, что в этом случае различие между понятиями «пертинентность» и «релевантность» фактически стирается. На потребителя неизбежно будет оказывать давление его информационная потребность, которая и определит в конечном итоге его решения. В этом случае существенный признак понятия «пертинентность» - субъективность - переносится на понятие «релевантность», в то время как по сути оно должно носить объективный характер, как и другие семантические понятия. Подчеркивая субъективный характер оценок релевантности, М. Тауб писал: «Во всяком случае ясно, что с точки зрения лица, производящего информационный поиск, «релевантность» - это психологический предикат, описывающий признание или непризнание им определенного сходства между смыслом или содержанием документа и смыслом или содержанием запроса»41.
Поэтому в тех случаях, когда речь идет об испытании конкретной ИПС или об исследовании тех или иных средств, определяющих эффективность ИПС в целом, рекомендуется прибегать к оценкам независимых экспертов.
Главные из функциональных (технических) показателей ИПС, базирующихся на релевантности - полнота и точность. Эти показатели, впервые введенные Дж. Перри и А. Кентом42, до сих пор остаются главными. Полнота и точность поиска основываются на разделении документов на релевантные и нерелевантные, а также на выданные и невыданные.
Введем следующие обозначения для документов поискового массива, представив их в виде матрицы:
Документы Релевантные Нерелевантные
Выданные а Ь
Невыданные с d
Полнотой поиска (П) (англ, recall - R) называется мера, вычисляемая как отношение количества выданных релевантных документов к общему числу релевантных документов, содержащихся в информационном массиве.
Точность поиска (Т) (англ, precision - Р) - это отношение количества выданных релевантных документов к общему числу документов в выдаче.
Полнота и точность обычно выражаются в процентах:
П = (а/(а+с)) х 100%,
Т = (а/(а+b)) х 100%.
Например, пусть информационный массив насчитывает 100 тыс. документов. Допустим, в нем имеется 100 документов, релевантных какому-либо запросу. В результате машинного поиска часть релевантных документов, как правило, теряется, а некоторые документы в выдаче оказываются нерелевантными. Допустим, в результате поиска объем выдачи (а+b) составил 125 док. При просмотре выдачи число релевантных документов (а) оказалось равным 75. Тогда показатели полноты и точности будут равняться:
П = (75/100) х 100% = 75%,
Т = (75/125) х 100% = 60%.
Показатель полноты может быть вычислен в результате специального просмотра и оценки на релевантность документов всего массива. В реальных условиях это, как правило, невозможно. Существуют различные методы приблизительной оценки данного показателя43.
Полнота и точность зависят от многих факторов, в том числе и от применяемых в системе языковых средств, а также от умения специалистов пользоваться этими средствами. Напомним о различении двух видов релевантности - смысловой и формальной. Смысловая релевантность обеспечивается возможно более точным и полным выражением на ИПЯ центральной и сопутствующих тем или предметов документов, а также смыслового содержания информационных запросов, т. е. возможно более точным и полным их выражением в поисковых образах документов и поисковых предписаниях. Следовательно, смысловая релевантность зависит от семантической силы ИПЯ, используемого в данной ИПС, от точности и достаточной глубины индексирования (ручного или автоматического), а также от модели поиска и критерия смыслового соответствия. Формальная релевантность зависит лишь от правильности работы программы по сравнению поискового образа документа с поисковым предписанием, т. е. от правильности алгоритмической и программной реализации ИПС.
Зависимость показателей полноты и точности от различных методов и средств, применяемых в ИПС, неоднократно исследовалась44. При этом, как правило, объектом исследования является способность ИПЯ выразить и отразить в поисковом предписании тематическую компоненту информационной потребности. Значение поисковых характеристик зависит также и от ряда других факторов: тип и характер задачи, решаемой пользователем, тип массива документов, режим поиска. Имеются различные способы управления этими показателями. Однако в рамках одной ИПС показатели полноты и точности находятся в отношении обратно-пропорционалыюй зависимости: чем больше полнота, тем меньше точность, и наоборот.
Как правило, в ИПС по науке и технике коэффициент полноты поиска обычно составляет 50-60%, а коэффициент точности - 40-50%. В полнотекстовых поисковых системах сети Интернет эти показатели намного ниже. Увеличение этих параметров на каждые 10% требует едва-ли не удвоения сложности лингвистических и/или программных средств. Причем если показатель точности дается пользователю, так сказать, в непосредственном восприятии, то потери релевантных документов остаются незамеченными, а вычисление показателя полноты требует выполнения специальной работы. Очевидно, что обеспечить приемлемую полноту без специальных лингвистических средств и методов практически невозможно.
1.11. Типы информационно-поисковых систем
Существует различные классификации ИПС по различным основаниям. Приведем общую схему классификации ИПС (рис. 1.5) по их внутренним характеристикам и свойствам:
по степени автоматизации информационных процессов;
- по типу данных;
- по типу языка;
по типу критерия смыслового соответствия (критерий выдачи);
- по режиму работы;
- по способу хранения первичных документов.
По степени автоматизации информационных процессов различают ручные, механизированные и автоматизированные ИПС. Ручные и механизированные ИПС отошли в область истории45. Однако нужно понимать, что даже печатный справочник, энциклопедия, научная книга с различными указателями (предметный, авторский, географический, указатель названий и т. п.), записная книжка также являются поисковыми системами со своим способом организации материала и поиска.
Как уже было сказано, по характеру выдаваемой информации —типу данных - ИПС делятся на документальные, фактографические и информационно-логические.
Классификация ИПС по типу языка будет подробно рассмотрена в главе 2.
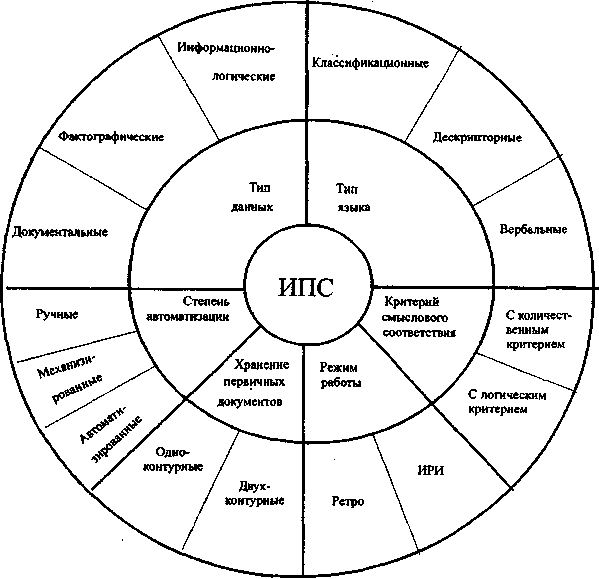
Рис. 1.5. Классификация ИПС.
По типу критерия смыслового соответствия все ИПС подразделяют на системы с логическими КСС и с количественными КСС. В ИПС первой группы применяют аппарат алгебры логики с использованием основных операций булевой алгебры И, ИЛИ, НЕ. Степень соответствия ПОД и ПОЗ определяется путем подстановки значений истинности или ложности на место терминов ПОЗ в зависимости от их нахождения/ненахождения в ПОД и последующего вычисления значения истинности всей логической формулы запроса.
В основе КСС ИПС второй группы лежат различные функции и формулы: арифметические, алгебраические, статистические, строящиеся на частоте совместной встречаемости и других частотных и вероятностных характеристиках лексики ПОД и ПОЗ. Частный, но важный случай данного типа критерия - весовой КСС, когда при индексировании документов и запросов терминам может приписываться - вручную или автоматически — так называемый «вес», определяемый смысловой значимостью данного термина в документе или запросе.
Информационная коммуникация может быть реализована путем выдачи всей релевантной информации, имеющейся в системе, или только новой, текущей, введенной в систему за какой-то последний промежуток времени. Это может быть достигнуто заданием временного ограничения в запросе, если язык системы позволяет. Но существуют специальные типы систем, различающихся по режиму работы: режим запрос—ответ и режим избирательного распространения информации (ИРИ) (англ. SDI - selective dissemination of information). Первый из них предусматривает разовые запросы, поиск по которым проводится, как правило, во всем накопленном массиве документов, который называют ретроспективным. И поэтому этот режим обычно называют ретро. Поиск в режиме ИРИ - это поиск в массиве новых поступлений документов по постоянным (действующим в течение определенного срока) запросам. Их еще называют «профилями». Похожие режимы работы ИПС в сети Интернет получили названия «фильтрация» (filtering) и «технология оповещения» (push technology).
С точки зрения взаимодействия человека и компьютера различают пакетный и диалоговый режимы поиска. Поиск в пакетном режиме выполняется автономно, без участия человека, как правило, в одном сеансе поиска сразу по всем запросам. Диалоговый поиск предполагает, что в процессе поиска фиксируются те или иные промежуточные результаты и по ходу решения задачи человек (пользователь или специально подготовленный информационный посредник) ведет с компьютером диалог - т.е. принимает некоторые решения, уточняющие запрос или стратегию поиска. Первый более характерен для ИРИ, второй - для «ретро».
По способу хранения информации системы делятся на одноконтурные и двухконтурные. В этом случае под «первым контуром» имеют в виду хранящиеся в машине поисковые образы документов. Сами документы - «второй контур» - хранятся вне машины, в привычном бумажном виде или на микроносителях (микрофильмы, микрофиши). В последнее время встречаются одноконтурные ИПС, когда и поисковый, и документальный контуры содержатся непосредственно в компьютере и поиск заканчивается выдачей полных текстов документов. В то же время глобальные ИПС сети Интернет — типичные двухконтурные системы, хотя оба контура представлены в электронном виде: вначале пользователь проводит поиск в базе данных ИПС, получает список найденных документов с ссылками на их сетевые адреса, обратившись по которым он может получить сам документ.
Возможны другие, так сказать, внешние классификации ИПС: по видам документов, по областям применения и т. п.
С пространственной точки зрения, по степени охвата документальных источников системы можно поделить на локальные, распределенные и глобальные. Причем эти признаки можно применить к описанию:
- входного потока документов;
- собственно поисковой базы;
- входного потока запросов и обслуживания.
В результате всевозможных комбинаций получаются разные виды систем. В качестве примеров можно назвать сводный электронный каталог нескольких библиотек, базу данных на CD-ROM (все локально), поиск по материалам веб-сервера («локальные» документы при удаленных пользователях), глобальные ИПС Интернета46 (распределенный, децентрализованный документальный поток, удаленные пользователи, «локализованная» поисковая база) и т. п.