
План Необходимость перехода к распределенным бд. Преимущества распределенных бд
| Вид материала | Документы |
- Л. Р. Сыраева Научный руководитель М. С. Крашенинникова, доцент Московский инженерно-физический, 22.43kb.
- Утверждаю, 111.69kb.
- 2 Регулирование рынка труда посредством профсоюзов III, 27.02kb.
- План. Необходимость развивающего обучения. Задачи математического развития ребёнка, 115.56kb.
- Методическое обеспечение перехода на предоставление государственных услуг и исполнение, 250.28kb.
- Методическое обеспечение перехода на предоставление государственных услуг и исполнение, 235.49kb.
- Лабораторная работа №7 Технологии разработки распределенных информационных систем, 168.59kb.
- Лекция Архитектура распределенных приложений J2EE, 532.44kb.
- Чики аппаратуры и программного обеспечения при создании первых крупных территориально-распределенных, 178.72kb.
- План реферата Фармацевтический рынок в России в условиях перехода к рыночной экономике., 187.83kb.
VII. ЦЕНТРАЛИЗОВАННЫЕ И РАСПРЕДЕЛЕННЫЕ БАЗЫ ДАННЫХ
План
Необходимость перехода к распределенным БД.
Преимущества распределенных БД.
Решения по созданию распределенных БД.
Пример распределенных БД.
Заключение.
Необходимость перехода к распределенным БД
В централизованных БД пользователи тратят очень много времени на поиск информации (недели и даже месяцы) и доступ к ней. В связи с растущей сложностью и разнообразием данных, представляющих интерес для различных отраслей экономики страны, обеспечение пользователей информацией из одного центра неизбежно становится сложнее.
Уровень технического развития отдельных центров данных потенциально позволяет обеспечить достаточно высокую оперативность обслуживания пользователей. Но при этом требуется много усилий на поддержание актуальности БД.
В нашей стране еще в восьмидесятые годы были созданы оперативные системы централизованного доведения информации до пользователей, например, СИГМА–ОКА (ВНИИГМИ–МЦД), DIALOG (ВИНИТИ) и др. Эти системы, как правило, были уникальными, удовлетворяли нужды отдельных (высокопоставленных) пользователей. Средства этих систем позволяли обеспечить доступ по выделенным каналам связи через центр коммутации сообщений с выдачей результатов поиска на экран видеотерминала и печатающее устройство. К сожалению, из-за высокой стоимости эксплуатации таких систем, недостаточной надежности каналов связи, сбоев ЭВМ, работающих в этих центрах, от них пришлось отказаться.
По мере роста производительности процессоров и неизбежного усложнения программного обеспечения самостоятельная эксплуатация персонального компьютера становится все сложнее и дороже. Некоторые компании (например, Oracle) объявили о намерении развивать новое направление сбыта своей продукции с помощью аренды программных средств через Интернет. Эта технология позволяет использовать сложное программное обеспечение не на серверах локальной сети компании и не на рабочих станциях пользователей, а в центрах данных, т.е. в области распространения и эксплуатации программного обеспечения остается выгодной централизация обслуживания. Такая же тенденция намечается в области эксплуатации крупных серверов БД.
Таким образом, на каждом этапе развития вычислительной техники и методов обработки должен соблюдаться компромисс между уровнем централизации и децентрализации данных и программного обеспечения.
Создание распределенных БД основано не на пустом месте. На первом этапе развития централизованной обработки данных в шестидесятых – начале семидесятых годов были заложены основы сбора данных на технических носителях, создания фондов данных, на втором этапе середина семидесятых – начало восьмидесятых годов – разработка программных средств для научных исследований, на третьем – с середины восьмидесятых годов – создание баз и банков данных. Эти этапы отражают преемственность в развитии системы переработки информации. Решение задач на каждом из них осуществлялось в соответствии с реальным уровнем развития современных методов автоматизированной обработки данных, программного и технического обеспечения и создало предпосылки для перехода к очередному этапу – созданию распределенных БД и удаленной обработки. Централизованный сбор данных позволил сократить трудозатраты на сбор, поиск и систематизацию данных, уменьшить сроки обработки больших массивов данных, увеличить полноту обрабатываемых данных, в т.ч. за счет международного и межведомственного обмена обеспечить одноразовое занесение данных на носитель. Последнее позволило в восьмидесятых годах обеспечить многие учреждения копиями основных массивов данных на магнитных лентах, без чего переход к следующему этапу был бы невозможен, т.к. не был бы накоплен опыт обработки данных в региональных организациях.
Анализ материалов, характеризующих деятельность организаций России, позволяет выделить следующие недостатки и проблемы централизованного создания и обработки БД:
- не обеспечивается полное и своевременное поступление и занесение данных на технические носители и в то же время есть дублирование занесения данных в различных организациях (не решен вопрос о рациональном распределении потоков данных при их сборе);
- замкнутость фондов данных в пределах одной отрасли привела к различиям в структуре отраслевых и региональных БД, неодинаковой степени автоматизации сбора и обработки данных, различиям в информационно–технологических процессах при решении одинаковых задач;
- отсутствие централизованной справочной службы для нескольких родственных отраслей и неодинаковая структура справочно – поискового аппарата;
- сведения о данных разобщены по нескольким справочным базам данных;
- отсутствует возможность аналитической обработки данных, низка оперативность и своевременность доведения справочной и исходной информации до пользователя;
- большинство центров данных не являются составными частями технически согласованной информационной сети, что существенно снижает эффективность их деятельности;
- из-за недостаточной координации работ центры разрабатывают программные средства сбора и обработки с дублированием, без учета взаимного обмена данными;
- сложилась ситуация, когда при наличии большого числа данных, они не могут быть использованы с достаточной полнотой и в приемлемые сроки при проведении НИР или принятии решений;
- при проектировании мало используется типовых проектных решений, различный состав классификаторов, кодификаторов, словарей и методов их ведения, отсутствуют методические материалы по проектированию конкретных приложений, имеется слабая заинтересованность ведомств в необходимости проектирования общей системы, нет методического и проектного руководства со стороны государственных органов;
- плохо используется пользователями получаемая информация из-за несовершенства форм представления информации, отсутствия системы критериев, регламентирующих использование данных, слабо автоматизируются методы принятия решений.
Повышение эффективности обеспечения пользователей информацией может быть достигнуто за счет интеграции учреждений в систему распределенных БД.
Преимущества распределенных БД
Распределенные БД имеют следующие основные преимущества по сравнению с централизованной БД: обеспечивается большая надежность работы, хранения копий или частей БД, данные становятся ближе к точкам их использования, что ускоряет обращение к данным и сокращает затраты на их передачу. Кроме того, преимуществами распределенных БД являются неявность адресации и тиражирования, независимость от конфигурации, использование неоднородных СУБД, тиражирование данных, расчленение БД, фрагментация данных.
Неявность адресации позволяет пользователю обращаться к данным, не зная и не интересуясь, в каком центре они расположены.
Неявность тиражирования связана с тем, что если существуют копии данных, то при извлечении данных необходимо извлекать одну копию данных, а при внесении изменений в данные необходимо обновлять все копии. Выбор одной копии при извлечении данных и обеспечение обновления всех копий должна автоматически выполнять система, позволяя пользователю сосредоточиться на информационных запросах.
Независимость от конфигурации позволяет:
- организации добавлять или заменять оборудование, не изменяя существующих компонентов программного обеспечения распределенных БД;
- расширить систему в случае, если существующее оборудование перестает удовлетворять пользователя.
Использование неоднородных СУБД на разных компьютерах требует создания общего пользовательского интерфейса, за которым находятся разные модели данных.
Тиражирование данных означает поддержку нескольких одинаковых копий реляционных таблиц. Тиражирование применяется с целью повышения доступности данных и надежности их хранения. Кроме того, несколько пользователей могут параллельно обращаться к одним и тем же данным. Например, это могут быть копии статистических данных для отдельных регионов, во-вторых, метаданные. Издержками этого подхода является необходимость дополнительного объема памяти и поддержания согласованности данных разных копий. Для этого нужно поддерживать централизованную базу, а копии выделять для локального использования. Потери данных на одном центре могут восстанавливаться при помощи централизованной БД. Недостатком такого подхода является слишком долгое время загрузки центральной БД. Поэтому загрузка новых данных, касающихся локальной БД, в региональном и главном центрах происходит одновременно. Можно применить тиражирование данных по времени отсечения. Например, в региональном центре данные хранятся только за последний год.
Управление распределенной БД – выработка способов функционирования в ситуации, когда БД из соображений эффективности тиражируется на нескольких узлах. Здесь нужно поддерживать идентичность копий. В ситуациях, когда связь нарушается, в копиях могут появиться различия. После восстановления связи должен включаться механизм согласования, который формирует некоторую копию, отражающую все сделанные изменения. В связи с растущей зависимостью производственных процессов от БД, для многих приложений необходимым требованием становится стопроцентная доступность – семь дней в неделю, 24 ч. в сутки. Репликация должна обеспечивать идентичность копий данных и корректное функционирование системы в условиях отказа отдельных компонентов.
Расчленение БД применяется для разных типов данных в одной предметной области. Здесь улучшается защита данных, особенно если разделенные сегменты нуждаются в разных видах защиты. При этом варианте реализации один пользовательский запрос может требовать обращения к нескольким базам данных, реализованным на разных подходах. Хотя сложности реализации скрыты от пользователя, действительные операции, например, соединения таблиц, являются несколько запутанными.
Фрагментация данных связана с тем, каким образом реляционные таблицы могут быть разделены и распределены между центрами. Это продолжение стратегии расчленения данных, которая обычно означает распределение по центрам таблиц целиком. При фрагментации таблица делится на несколько частей (подмножеств). Объединение этих подмножеств составит исходную таблицу. Фрагментация может быть горизонтальной (данные для разных районов в разные фрагменты) и вертикальной (разные атрибуты в разные фрагменты). Для случая одного типа данных лучше применить горизонтальную фрагментацию. Здесь имеется проблема пересечения данных, т.е. одни и те же данные могут дублироваться на границах регионов.
При проектировании распределенных БД используются следующие принципы:
- отражение сложившейся организационной структуры системы;
- централизация сбора и обработки метаданных и глобальных данных, долговременного хранения данных в ведомственных центрах и децентрализация сбора, занесения текущих данных на технических носителях и обеспечения пользователей;
- единство справочной службы сведений о данных во всей системе, с централизацией основных сведений в главном центре данных;
- построение БД на основе типовых проектных решений;
- единое методическое руководство деятельностью учреждений, занимающихся информационным обеспечением пользователей за счет широкого применения стандартизации и унификации;
- применение единой классификации данных;
- всемерное использование возможностей международного сотрудничества в области обмена данными, теории и практики обслуживания пользователей;
- единство технологических процессов сбора, обработки и распространения данных;
- Надежность функционирования – обеспечение сохранности, защиты, безопасности информации;
- функциональная целостность – обеспечение функционирования распределенных БД как единого комплекса, позволяющего решать одну сложную задачу и множество справочных запросов;
- конструктивная однородность и мобильность (учет новых требований) – сравнительно небольшой набор номенклатуры применяемых технических средств, что создает основу для наращивания мощности распределенных БД;
- функциональная модульность – создание типовых функциональных модулей (для статистической обработки, доступа к данным и др.);
- способность воспринимать новую информацию и технологические процессы ее переработки без крупной перестройки структуры и изменения функций действующих звеньев.
В организационном плане создание распределенных БД представляет длительный процесс последовательного ввода в действие отдельных ее составных частей. Как по функциям, так и по центрам, очередность включения в систему новых центров данных зависит от реальных условий, сложившихся в региональных учреждениях (наличия опыта работы в области автоматизации и квалифицированных кадров, технической оснащенности, объема и важности запросов).
Для создания такого режима работы необходим правильный выбор протоколов, используемых в телекоммуникационных сетях, выработка стратегии распределения информации в сети, создание справочной службы и соответствующей инфраструктуры сети.
Решения по созданию распределенных БД
Целью создания распределенных БД является наиболее полное и эффективное обеспечение данными для принятия решений при наименьших затратах труда и материально – технических ресурсов. Для этого необходимо:
- обеспечить своевременное и полное поступление качественных данных;
- создать распределенные базы данных и метаданных;
- разработать средства доступа к данным.
Важнейшими вопросами построения распределенных БД являются методы тиражирования БД между центрами, реализация связей между ними, разработка типовых проектных решений, создание основных блоков со стандартными методами поиска, кодификаторами, форматами хранения данных.
В последние годы появились новые требования к сбору и пополнению БД, оптимальному распределению данных по регионам с целью уменьшения времени отклика, издержек на передачу данных, затрат на хранение, увеличение скорости поиска данных, улучшения работы с метаданными, разработки эффективного выполнения операций по обращению к распределенным данным. Трудно перейти к этапу автоматизации на основе распределенных данных одновременно всем. Элементы централизованной обработки будут существовать еще какое-то время. Только после того как распределенные БД заработают как единый механизм и не в экспериментальном, а в промышленном режиме, произойдет отмирание отдельных функций централизованной обработки данных. Но пока это приводит к дублированию работ по занесению некоторых данных на носителях, различными структурами хранения данных и др. Если устранение различий в структурах данных и используемых СУБД достигается очень большой ценой – полной реконструкцией существующих БД, то лучше разрабатывать программы – конверторы.
Распределенные БД создаются на основе существующих средств регистрации, связи, вычислительной техники и программно–информационных средств. С помощью распределенных БД создается единый технологический процесс сбора, первичной обработки, хранения, статистической обработки, обмена, доведения и использования информации.
Распределенные БД проектируются для выполнения задач двух типов – научных, связанных с накоплением максимально полных БД; производственных, которые сводятся к информационному обеспечению поддержки решений на объектах экономики.
В распределенных БД централизованно хранятся метаданные верхнего уровня (сведения о БД, предоставляемых в общее пользование и по специальному режиму). Исходные данные распределяются среди центров данных, удаленных географически на многие тысячи километров, но связанных коммуникационными линиями. Каждый центр имеет свою собственную базу данных, кроме того, он может обращаться к данным, хранящимся в других центрах.
Распределенная БД является многоуровневой по обеспечению пользователей и централизованной по хранению метаданных. Каждый пользователь обращается в распределенную БД на своем уровне обслуживания, а получает информацию с любого уровня в зависимости от его статуса.
Позволяя каждому центру поддерживать свою собственную БД, получаем быстрый и эффективный доступ к наиболее часто используемым данным. Распределенная БД повышает надежность системы. Если компьютер одного центра выходит из строя, то остальная сеть продолжает работать. Это достигается за счет дублирования данных в разных центрах.
Решающим фактором, определяющим организационную структуру распределенных БД, особенно на начальном этапе создания системы, является отражение в ней сложившейся структуры сбора, обработки и обеспечения пользователей информацией. Центр данных эксплуатирует распределенные БД, взаимодействуя с различными системами в зависимости от уровня управления экономикой (на локальном, региональном, национальном или международном уровнях).
Пример распределенной системы
Для функционирования распределенной БД в области морской деятельности создается Единая система информации об обстановке в Мировом океане (ЕСИМО), рис.15.
В
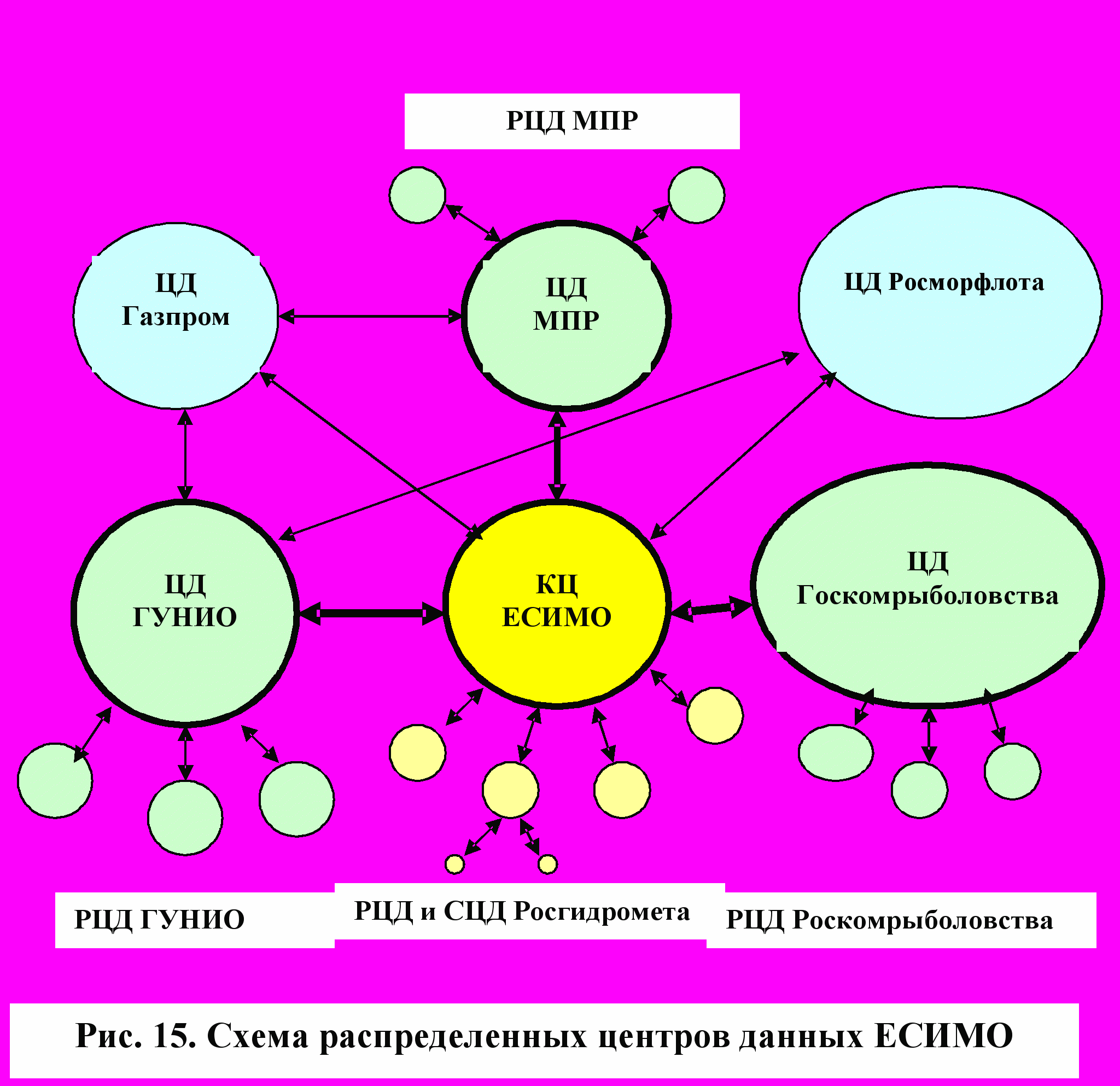
организационном плане можно выделить локальные, региональные (РЦ), тематические и ведомственные центры данных (ЦД). Иерархическое построение определяется не только аналогией с традиционными структурами учреждений Росгидромета, Министерства природных ресурсов, Госкомрыболовства, Главного управления навигации и океанографии, Государственной службы морского флота и других, но и требованиями контроля процессов сбора, обработки и распространения информации. На отраслевом и региональном уровнях осуществляется международный обмен данными. Для распределенных БД, как составной части международных систем, предусмотрено взаимодействие с международными организациями.
Каждому центру позволено администрировать данными, которые пользуются наибольшим спросом. За счет этого распределенные БД способны точнее соответствовать административной структуре организации и лучше соответствовать потребностям пользователей.
Распределенные БД являются примером многостороннего взаимодействия. Так отраслевые центры активно взаимодействуют друг с другом, региональными центрами, исполняющими роль поставщиков информации, и пользователями. Преобладают здесь вертикальные связи, т.к. на региональном уровне взаимодействие между организациями пока очень слабое. Приведенные организационно–функциональные формы взаимодействия не исчерпывают всего многообразия этих видов взаимодействия. Как правило, каждый центр участвует в различных информационных связях. Внешние связи определяют взаимодействие с информационными системами, не входящими в состав центров данных, эксплуатирующих распределенную БД.
Для реализации всей совокупности функций распределенных БД выделены соответствующие региональные учреждения. Это можно сделать путем предоставления таких полномочий одной из мореведческих организаций региона. Это учреждение должно выполнять руководящие функции в отношении всех других мореведческих организаций, занимающихся сбором, обработкой и распространением информации о морской среде, являясь в то же время равноправным звеном в сети региональных центров и постоянным партнером координационного центра (КЦ) и информационных систем других отраслей регионального уровня. Важным моментом является то, что в каждом регионе должен быть выделенный ответственный региональный центр, который может представлять один из региональных центров, т.е. в РЦ тиражируются определенные типы данных.
Характерной особенностью распределенных БД является то, что в ней всю исходную информацию собирают и хранят отраслевые центры, а Межотраслевой координационный центр хранит метаданные (сведения об информационных ресурсах), здесь производится фрагментация данных.
Необходимость сочетания отраслевой, региональной и межотраслевой информации обуславливает наличие вертикального и горизонтального взаимодействий. Вертикальные связи отражают соподчиненность центров в рамках отрасли, горизонтальные – необходимость координации функционирования центров на одном уровне (отраслевом или региональном).
В настоящее время практически все распределенные БД построены на разных СУБД, имеют отличающиеся структуры данных. Интеграция информационных ресурсов производится только на уровне метаданных и отдельных типов данных, выделенных в общее пользование.
В результате распределенные БД обеспечивают не только быстрый доступ к информации, но и позволяют готовить более эффективные и обоснованные управленческие решения.
5. Заключение
Показаны преимущества и недостатки централизованных БД, архитектуры распределенных БД. Представлены проектные решения и рассмотрен пример создания такой БД в области исследования морской природной среды. Децентрализация сбора, обработки данных и создание распределенных БД позволит улучшить обслуживание пользователей, ускорить доступ к данным.
Литература
Проектирование БД и хранилищ данных // ссылка скрыта
Вопросы для самопроверки
- Назовите преимущества централизованных и распределенных БД.
- Сравните понятия расчлененная и тиражируемая БД. Когда одна из них предпочтительнее, чем другая?
- Опишите, чем отличаются распределенные от централизованных БД?