
Обработка и передача изображений
| Вид материала | Документы |
- Обработка и передача изображений, 213.76kb.
- Анализ, обработка и передача динамических изображений в моделях виртуальной реальности, 80.25kb.
- Обработка и передача изображений, 243.48kb.
- Обработка и передача изображений, 149.44kb.
- Обработка и передача изображений, 357.76kb.
- Обработка и передача изображений, 241.81kb.
- 1. Информационные технологии. Структура информационного процесса. Сбор, обработка,, 1016.5kb.
- Обработка и передача изображений, 203.92kb.
- Белорусский государственный университет применение информационных технологий при анализе, 187.23kb.
- Обработка и передача измерительной информации, 201.84kb.
Обработка и передача изображений
Обработка и передача изображений
ПРОСТРАНСТВЕННО-ВРЕМЕННАЯ СЕГМЕНТАЦИЯ ВИДЕОПОСЛЕДОВАТЕЛЬНОСТЕЙ НА ОСНОВЕ 3D СТРУКТУРНОГО ТЕНЗОРА
Фаворская М.Н.
ГОУ ВПО «Сибирский государственный аэрокосмический университет имени академика М.Ф. Решетнева»
Сегментация видеопоследовательностей является важным и необходимым этапом во многих областях применения цифрового видео таких, как виртуальная реальность, анализ мультимедийных данных, компьютерное зрение, искусственный интеллект. Под сегментацией, как правило, понимается преобразование набора кадров из видеопоследовательности в совокупность признаков, описывающих компактные области (регионы) изображений с целью их последующей интерпретации. Такое преобразование, с одной стороны, приводит к потере исходной пиксельной информации, с другой стороны, формирует основу для логического восприятия и анализа предполагаемых объектов на изображении. В таком контексте правильность распознавания однозначно зависит от качества проведенной сегментации. Приведем основные цели сегментации:– разделение изображения на составляющие его области; – определение степени детализации сегментации; – достижение заданной точности сегментации; – нахождение инвариантных признаков регионов для последующего распознавания объектов.
Для сегментации видео объектов используются обобщенные методы, сочетающие яркостную или цветовую информацию (пространственная сегментация) и информацию о движении (временная сегментация), которые можно разделить на три категории: методы нахождения регионов, методы определения границ и методы, основанные на вероятностных моделях [2–4]. Первая группа методов основана на операциях кластеризации (расщепления и выращивания регионов в пространстве признаков) на основе векторов движения и некоторых пространственных признаков таких, как цветность, текстура, взаимное расположение. Недостатками такого подхода являются проблемы появления, перекрытия и исчезновения регионов из кадра, а также низкая точность определения границ регионов. Методы определения границ обычно используют угловые детекторы или активные контуры в сочетании с информацией о полях движения видео объектов. Такие методы основаны на принципах когнитивной психологии, однако они имеют низкую помехоустойчивость, а активные контуры дополнительно – сильную зависимость от выбора начального параметров. Вероятностные методы для нахождения движущихся объектов используют байесовский подход, алгоритм «максимизации-ожидания», минимизации расстояний в метрических пространствах. Указанные подходы обладают высокой вычислительной сложностью, причем, некоторые методы требуют предварительного задания количества объектов-регионов в качестве входного параметра.
Методы оценки движения обычно основываются на двух подходах: анализе оптического потока (optical flow) и соответствии блоков (block matching). В обоих случаях информация о движении определяется по интенсивностям пикселей между соседними кадрами видеопоследовательности в предположении, что смещение изображений объектов между двумя кадрами будет незначительным. Однако метод сегментации по движению с применением оптического потока является более предпочтительным, поскольку более точно определяет границы видео объектов. Метод же соответствия блоков, хотя и является более быстродействующим, предполагает разбиение изображения на относительно большие участки (1616 пикселей), в данном случае точное определение границ является проблематичным.
Приведем варианты съемок сцены одной видеокамерой по мере усложнения [1]:
1. Съемка неподвижной видеокамерой статической сцены. Признаки движения отсутствуют.
2. Съемка неподвижной видеокамерой сцены со слабо изменяющимся фоном и подвижными объектами. У видео объектов могут присутствовать признаки движения, важны глобальные векторы перемещений, значения скоростей и ускорений. При этом возникают проблемы появления и исчезновения изображений объектов, наложения и расщепления изображений объектов.
3. Съемка перемещающейся видеокамерой сцен с многочисленными ракурсами при отсутствии объектов интереса. Присутствуют признаки движения у всех регионов фона. Имеется единый глобальный вектор движения, но скорости различны, поскольку регионы «движутся» с разной скоростью в перспективной модели. Возникает проблема появления и исчезновения изображений регионов фона, т.е. фон является динамическим.
4. Съемка перемещающейся видеокамерой сцен с многочисленными ракурсами с подвижными видео объектами. Имеются признаки движения у всех регионов. Регионы фона имеют глобальный вектор движения и «движутся» с разной скоростью в перспективной модели. У видео объектов могут присутствовать признаки движения, важны глобальные векторы перемещений объектов, их скорости и ускорения. Возникают проблемы появления и исчезновения регионов фона, появления и исчезновения регионов видео объектов, возможны наложения и расщепления видео объектов.
Рассмотрим более подробно второй случай. Модель имеют три уровня обобщения – низкий уровень LL (Low Level), средний уровень ML (Middle Level) и высокий уровень HL (High Level). Видеосъемка движущихся объектов приводит к появлению двух этапов – этапа адаптации для текущего ракурса съемки и этапа сопровождения объектов интереса. Съемка неподвижной камерой сцены со слабо изменяющимся фоном (относительно последовательности кадров) с подвижными объектами находит большое практическое применение в системах наблюдения (сопровождение транспортных средств, людей), охранных системах и т.п. Адаптационная модель M2A (Adaptation Model) имеет вид:
M2A = {f :f(x,y)LFo,b(BRLL, FRLL, SPLL),
f :LFo,b(BRLL, FRLL, SPLL)MFo(BRML, GMML, TPML, MVML)} ,
а модель сопровождения M2T (Tracking Model) можно представить как
M2T = {f :f(x,y)LFo(BRLL, FRLL, SPLL),
f :LFo(BRLL, FRLL, SPLL)MFo(BRML, GMML, TPML, MVML),
f :MFo(BRML, GMML, TPML, MVML)HFo(SMHL, MVHL)} ,
где f – покадровое (frame) отображение, переводящее изображение f(x,y) в набор низкоуровневых локальных яркостных BRLL, фрактальных FRLL и спектральных SPLL признаков объектов и фона LFo,b() или объекта LFo(); f – покадровое отображение, переводящее низкоуровневые признаки LFo,b() или LFo() в набор среднеуровневых глобальных яркостных BRML, геометрических GMML, топологических TPML и локальных признаков движения MVML объектов MFo(); f – покадровое отображение, переводящее набор среднеуровневых признаков объектов MFo() в набор высокоуровневых семантических SMHL и глобальных признаков движения MVML объектов сцены HFo(). На этапе адаптации происходит разделение регионов на неподвижные сегменты, которые можно отнести к фону, и подвижные сегменты, претендующие на роль объектов интереса. На этапе сопровождения основное внимание уделяется движущимся объектам. Возможна ситуация, когда неподвижный регион начинает движение и превращается в объект интереса, и наоборот, когда движущийся регион прекращает движение. Интересно отметить, что имеет значение пространственная ориентация направления движения объекта относительно камеры. Так, в случае «наезда» объекта на камеру, трудно оценить параметры движения.
Несмотря на то, что в приведенной модели присутствует большое количество разнообразных признаков, их можно разделить на две значимых группы: признаки, описывающие пространственное состояние объекта, для определения которых достаточно одного кадра, и признаки движения, представляющие временное состояние объекта, определяемые обычно по нескольким соседним кадрам видеопоследовательности. В целом, можно отметить двойственность пространственной и временной сегментаций. Она заключается в том, что пространственная сегментация показывает лучшие результаты для однородных регионов в условиях отсутствия градиентов и более четких границ, и, наоборот, временная сегментация имеет большее значение для текстурных регионов, где градиенты велики, а границы размыты. Также следует отметить, что информация о движении является определяющим фактором для пространственного объединения регионов в видео объект на семантическом уровне. Наиболее конструктивным алгоритмом сегментации является такой алгоритм, который использует пространственную информацию для определения полей движения и наоборот, а также учитывает особенности идентификации движущихся объектов человеком, а именно форму объектов и характер их движения.
Алгоритмическая реализация адаптационной модели включает следующие этапы:
1. Пространственная сегментация сцены. Здесь допустимо применение любых известных методов сегментации таких, как пороговые методы (обнаружение разрывов яркости, обработка с глобальным или адаптивным порогом, мультиспектральная пороговая обработка, сегментация по морфологическим водоразделам, сегментация с использованием маркеров), стохастические методы (параметрические методы восстановления вероятностей, метод минимизации эмпирического риска, метод принятия решений при неполных данных), методы на основе построения и разрезания графов.
2. Нахождение движущихся регионов. Пусть видеопоследовательность I(x) представляет собой набор данных, где x=[x y t]T, x и y – пространственные координаты, t – время. 3D структурный тензор J позволяет эффективно определять локальную ориентацию пространственно-временного движения видео объектов и определяется следующим образом:
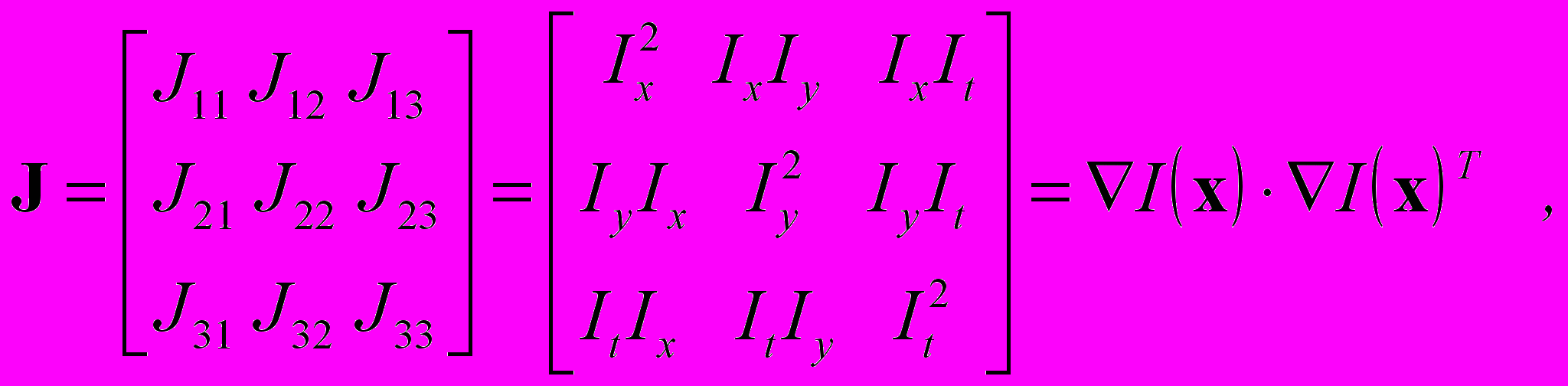 где – пространственно-временной градиент, вычисляемый по частным производным
где – пространственно-временной градиент, вычисляемый по частным производным 
Собственные векторы ek (k=1,2,3) симметричной ковариационной матрицы J размером 33 можно определить по локальным смещениям интенсивностей изображений соседних кадров и использовать для оценки локальных ориентаций движущихся сегментов. Причем, в силу особенностей видео наблюдения собственные значения k векторов ek указывают на локальные отклонения яркости по трем направлениям, и могут быть отсортированы в следующем порядке 1230. Выражение I(x)I(x)T можно рассматривать как корреляционную матрицу, составленную из векторов градиентов в пространственно-временном объеме. В соответствии с методом главных компонент собственные векторы корреляционной матрицы сортируются в порядке убывания. Первый собственный вектор, соответствующий наибольшему собственному значению, указывает направление наибольшего изменения данных. Отношение каждого собственного значения к сумме трех собственных значений характеризует концентрацию энергии по соответствующему направлению. Таким образом, собственные значения локального 3D структурного тензора можно использовать для обнаружения локальных изменений в последовательности кадров. Наименьшее собственное значение можно использовать для определения различий в кадрах, оно является более устойчивым к шуму и низко контрастным объектам фона по сравнению с простейшим методом яркостной разницы кадров. На основе собственных значений 1(x,y,t), 2(x,y,t), 3(x,y,t) можно построить карты 1(I), 2(I), 3(I) локального 3D структурного тензора. При этом карта собственных значений 1(I) фиксирует как движущиеся объекты, так и некоторые изолированные текстурные регионы фона. Карта собственных значений 2(I) является менее информативной для сегментации, а карта собственных значений 3(I) генерирует небольшие разрывы внутри масок видео объектов. Поэтому при обнаружении движения следует основное внимание уделять первому собственному вектору корреляционной матрицы 1(I).
3. Временная сегментация с учетом пространственных ограничений. Полученные маски движения могут иметь разрывы и неточные границы видео объектов. Для устранения этих артефактов можно повторно использовать один из методов разрезания графов с последующим сравнением регионов, полученных от временной Amv и пространственной Asp сегментации и вычислением критерия формирования регионов (Amv/Asp)>Psg , где Psg – некоторое пороговое значение. Если вычисленный критерий превышает пороговое значение, то пространственный регион считается принадлежащим движущемуся объекту, в противном случае он помечается как фон.
4. Пространственное объединение с учетом временных ограничений. Существуют два подхода к объединению регионов. Непараметрический подход приводит к некоторому размытию границ регионов. При параметрическом подходе критерием объединения регионов служит минимальное расстояние в некотором метрическом пространстве. Обычно при анализе сцен принимается аффинная модель движения объектов, описываемая шестью параметрами [1]. Предлагается вычислять расстояние между аффинной моделью движения vi и 3D структурным тензором Ji (для каждого пикселя i): d(vi,Ji)=viTJivi с использованием нормализованного расстояния

На этапе сопровождения найденных движущихся объектов алгоритм упрощается, поскольку пространственная сегментация требует меньших временных затрат из-за относительной стационарности фона.
Литература
- Фаворская М.Н. Методы и модели поиска целевых информативных признаков в видеопоследовательностях // В материалах IX международной научно-технической конференции «Кибернетика и высокие технологии XXI века», т.1, Воронеж, 2008. – с. 171–182.
- Bresson X., Vandergheynst P., Thiran J.-P. A Variational Model for Object Segmentation Using Boundary Information and Shape Prior Driven by the Mumford-Shah Functional // International Journal of Computer Vision, vol. 68, no. 2, 2006. – pp. 145–162.
- Cavallaro A., Salvador E., Ebrahimi T. Shadow-aware object-based video processing // IEE Vision, Image and Signal Processing, Vol. 152, Issue 4, 2005. – pp. 14–22.
- Thirde D., Jones G., Flack J.. Spatio-Temporal Semantic Object Segmentation using Probabilistic Sub-Object Regions // In British Machine Vision Conference, Norwich, UK, 2003. – рр. 163–172.
SPATIO-TEMPORAL SEGMENTATION OF IMAGE SEQUENCES BASED ON 3D STRUCTURE TENSOR
Favorskaya M.
Siberian State Airspace University after academician M.F. Reshetnev (SibSAU)
Segmentation of image sequences is the important and necessary stage in many digital video applications such as virtual reality, multimedia, computer vision, and machine intelligence. Generalized methods for video objects segmentation combine image (or spatial) and motion (or temporal) segmentations together to enhance the accuracy of video objects extraction. Typical video objects segmentation methodologies can be grouped into three categories: region-based, boundary-based, and probabilistic model-based approaches. Region-based methods use the clustering operation or regional splitting and growing. Boundary-based techniques often considerate edge detectors, level sets, or active contours. Probabilistic model-based methods exploit Bayesian approach, expectation maximization, or minimum description length.
Let’s consider the situation when camera motion is absent, background of scene does not change, and video objects can move, appear, disappear from scene, and overlap other objects. Assembly includes brightness, fractal, spectral features in low level, geometrical, topological, motional features in middle level, and semantic features in high level. They may be divided into two significant groups: spatial features received from one frame, and temporal features received from neighbor’s frames. Temporal estimation is well-posed at the locations where spatial segmentation fails, and vice versa. Spatial segmentation methods can more easily identify region boundaries where temporal segmentation methods have a difficulty. Motion information is a helpful indicator to merge over-segmented spatial segments into semantic objects.
The algorithm realization of video adaptation stage includes following phases:
1. Spatial segmentation of scene by variable well-known methods such as threshold, multispectral, probabilistic, or graph-based methods. For example, an efficient graph-based image segmentation approach is implemented in the target frame to generate homogeneous spatial subregions with small intensity variations.
2. Moving regions definition based on 3D structure tensor. Expression I(x)I(x)T where x=[x y t], x and y are the spatial components, and t is the temporal component, I(x) is image sequence, and =(Ix/t Iy/t It/t) denotes the spatio-temporal gradients, – can be viewed as a correlation matrix constituted by the gradient vectors of the space-time image volume. From the perspective of principal component analysis, if the eigenvectors of the correlation matrix computed from the input data are sorted in the descending order, the first eigenvector which corresponds to the largest eigenvalue indicates the direction that incurs the largest variance of the data. The smallest eigenvalue is the indicator of the frame difference, which is more robust to noise and low object-background contrast.
3. Spatial-constrained motion segmentation. The motion masks have small holes in the body of video objects and inaccurate boundaries. Graph-based image segmentation results are used in order to benefit from the advantages of spatial segmentation.
4. Motion-constrained spatial merging. There are two classes of region merging approaches: nonparametric techniques (lead to boundary melting) and parametric models (use the distance in feature space). The parameters of the affine motion model estimated from each spatial segment are used to compute the distance between two adjacent segments based on expression with the 3D structure tensor. Two segments will be merged together if the motion model distance between them is short enough, that is, sharing the similar motions.
During video object surveillance the algorithm is simplified because spatial segmentation of background is less changed.
Применение метода главных компонент при распознавании лиц
Пахирка А.И.
Сибирский государственный аэрокосмический университет имени академика М.Ф. Решетнева
Для представления и распознавания лиц людей применяется ряд методов (линейный дискриминантный анализ, метод опорных векторов, искусственные нейронные сети и т.д.). Одним из наиболее эффективных методов является метод главных компонент (Principal Components Analysis, PCA), который позволяет уменьшить размерность данных за счет минимизации потерь информации. Главная идея метода главных компонент (МГК) состоит в представлении изображений лиц людей в виде набора главных компонент изображений, называемых «собственные лица». Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных [1].
Любое изображение может рассматриваться как вектор из пикселей, каждое значение которого представлено значением пикселя в полутоновой градации. Например, изображение 88 пикселей может рассматриваться как вектор длиной в 64 пикселя. Такое векторное представление описывает входное пространство изображения. Для представления и распознавания лиц можно использовать подпространство, созданное собственными векторами ковариационной матрицы исследуемых изображений. Собственные векторы, соответствующие ненулевым собственным значениям ковариационной матрицы, формируют ортогональный базис, который отображает изображения в N–мерное пространство [2,3]. Каждое изображение сохраняется в векторе размера N:
 , (1), где xi – эталонные изображения, X – матрица эталонных изображений. Изображения центрируются вычитанием из каждого вектора усредненного изображения.
, (1), где xi – эталонные изображения, X – матрица эталонных изображений. Изображения центрируются вычитанием из каждого вектора усредненного изображения.  (2). Эти векторы объединяются, образуя матрицу данных NP (где P – количество изображений,
(2). Эти векторы объединяются, образуя матрицу данных NP (где P – количество изображений, 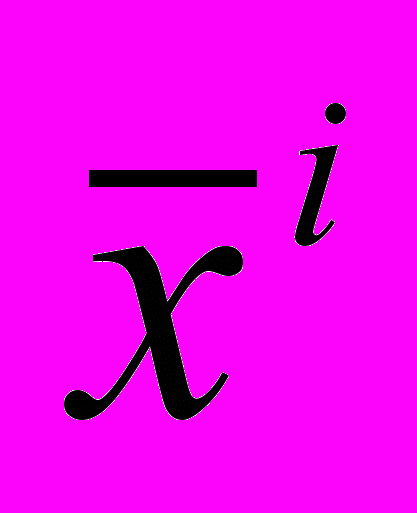 – центрированное изображение) следующим образом:
– центрированное изображение) следующим образом:  (3). Матрица данных
(3). Матрица данных  умножается на транспонированную матрицу данных для расчета ковариационной матрицы
умножается на транспонированную матрицу данных для расчета ковариационной матрицы 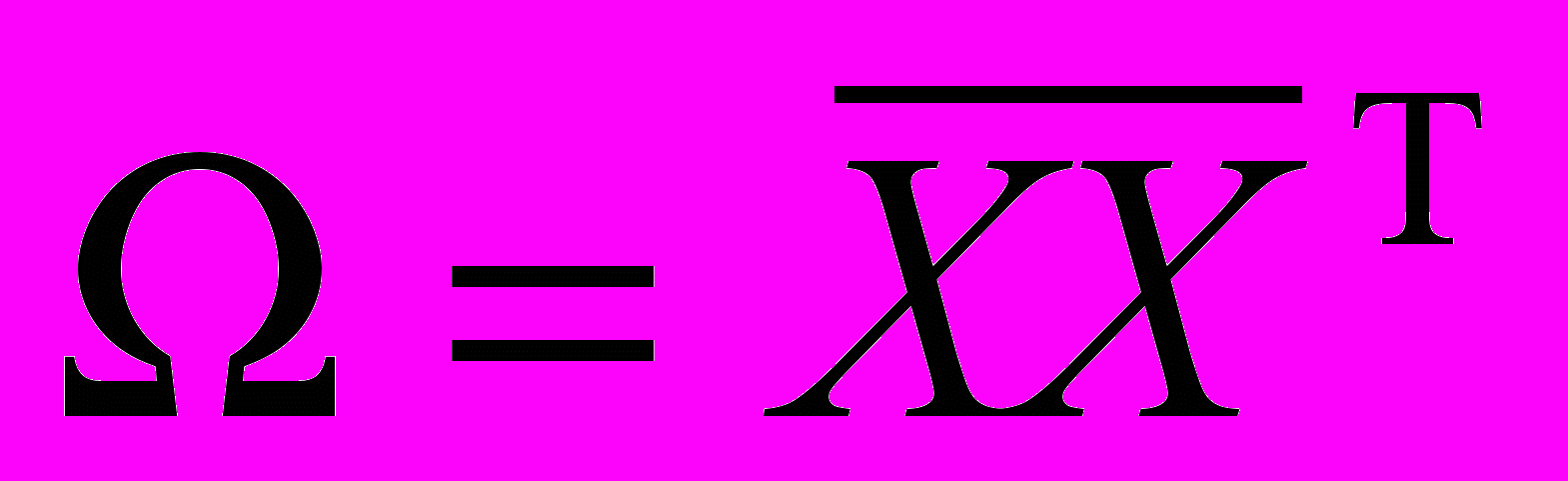 (4).
(4).Эта ковариационная матрица имеет до P собственных векторов, связанных с ненулевыми собственными значениями, при этом PN . Собственные векторы сортируются от большего значения к меньшему значению в соответствии с их собственными значениями. Собственный вектор с наибольшим собственным значением представляет самую большую дисперсию в изображениях.
Распознавание изображений с использованием проецирования на собственное пространство осуществляется в три этапа [2]:
- Создается собственное пространство из эталонных изображений (этап обучения)
- Эталонные изображения проецируются в собственное пространство (этап обучения)
- Спроецированное входное изображение сравнивается с проецированным тестовым изображением (этап распознавания).
Рассмотрим первый этап – создание собственного пространства, состоящего из следующих шагов:
– центрирование данных: каждое изображение центрируется, вычитанием усредненного изображения из каждого эталонного изображения. Усредненное изображение – это вектор-столбец, в который входят средние значения пикселей из всех пикселей эталонных изображений (выражение 2);
– создание матрицы данных: Как только входные изображения центрированы, они комбинируются в матрицу данных NP (выражение 3);
– создание ковариационной матрицы: матрица данных умножается на ее транспонированное представление (выражение 4);
– вычисление собственных векторов и собственных значений: собственные векторы и их собственные значения вычисляются из ковариационной матрицы
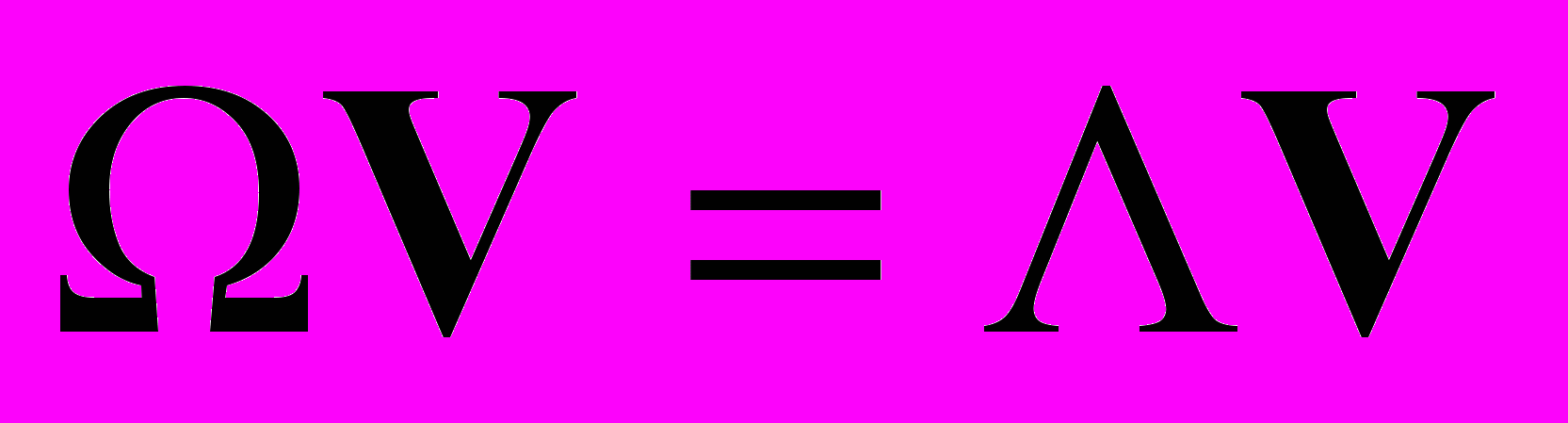 , где V набор собственных векторов связанных с собственными значениями .
, где V набор собственных векторов связанных с собственными значениями .– упорядочивание собственных векторов: упорядочиваются собственные векторы viV в соответствии с их собственными значениями i
 от большего значения к меньшему значению. Сохраняются собственные векторы с ненулевыми собственными значениями. Эта матрица собственных векторов является собственным пространством V, где каждый столбец – собственный вектор
от большего значения к меньшему значению. Сохраняются собственные векторы с ненулевыми собственными значениями. Эта матрица собственных векторов является собственным пространством V, где каждый столбец – собственный вектор 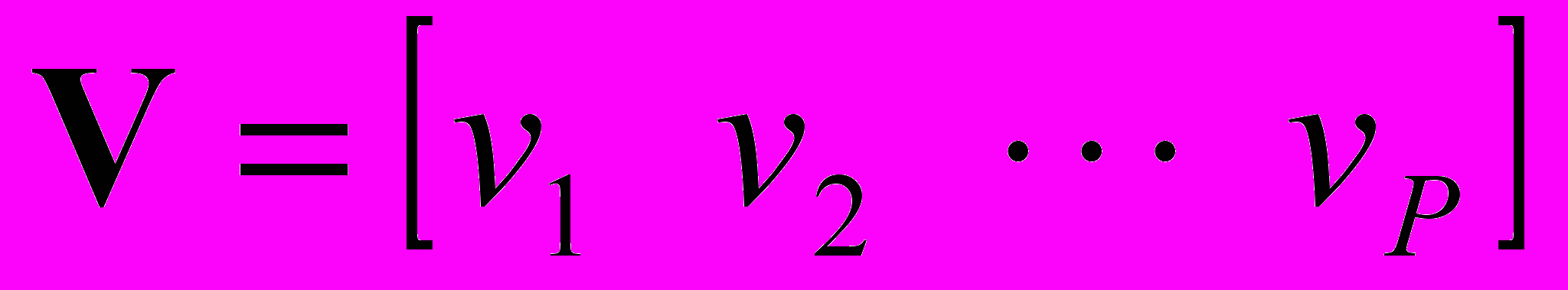
На втором этапе происходит проецирование эталонных изображений в собственное пространство. Каждое центрированное входное изображение
проецируется в собственное пространство.  .
.В рамках третьего этапа происходит распознавание входного изображения. Каждое входное изображение центрируется вычитанием усредненного изображения и затем проецируется в собственное пространство V.
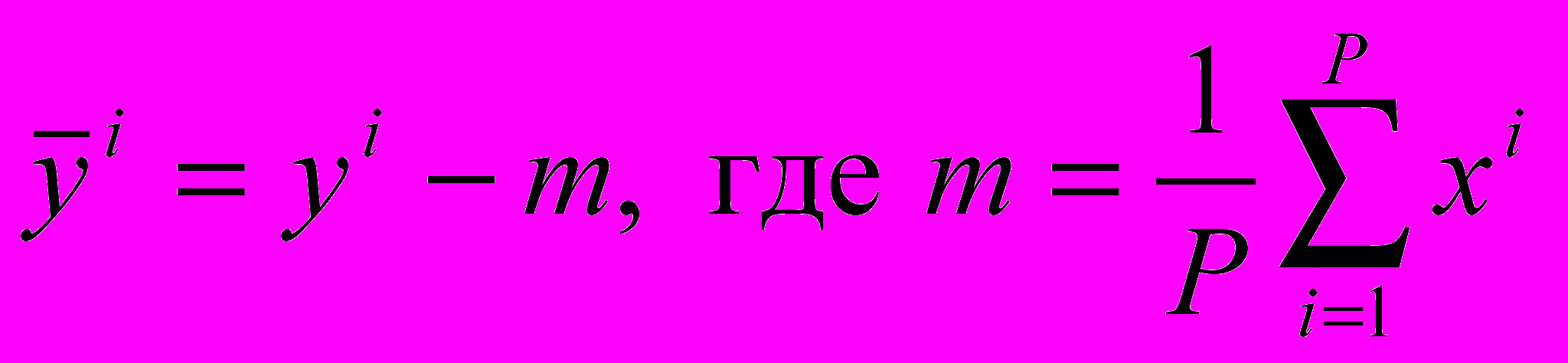 и
и 
Спроецированное входное изображение сравнивается со всеми спроецированными эталонными изображениями. Изображения могут сравниваться с использованием любой из простых метрик, например евклидовой. Применение метода главных компонент показано на рис 1.
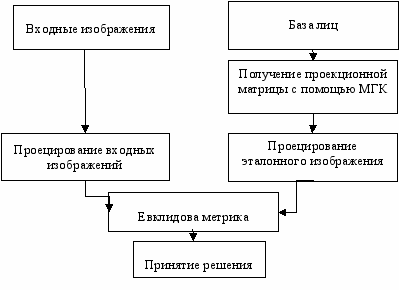
Рис 1. Применение МГК при распознавании лиц.
Входное изображение представляет собой предварительно обработанное изображение лица. Далее входное изображение проецируется с помощью проекционной матрицы, получаемой с применением метода главных компонент к эталонным изображениям. В свою очередь эталонные изображения, представленные в базе лиц, так же проецируются в собственное пространство для последующего сравнение с проецированным входным изображением.
В настоящее время введется разработка системы захвата изображений лиц из видеоизображения, с последующей обработкой и приведением изображений к некоторому «усредненному» виду, снижением влияния освещения, корректировкой положения лица, выбором из видеоданных относительно лучшего изображения лица.
Литература
- Jain K., Flynn P., Ross A., Handbook of Biometrics, Springer, 2008 – 564 p.
- Yambor W., Analysis of PCA-based and Fisher discriminant-based image recognition algorithms, Technical Report CS-00-103, 2000. – 70 p.
- Zhao W., Chellappa R., Face Processing, Advanced Modeling and Methods, 2006 – 755 p.