
Машинный перевод с естественного языка на естественный язык
| Вид материала | Документы |
- Лекция 4 системы автоматизированного перевода и машинный перевод, 128.31kb.
- Дисциплина: Инженерия знаний Доклад Машинный перевод, 263.57kb.
- Так как текст записанной на Паскале программы не понятен компьютеру, то требуется перевести, 11.15kb.
- В. И. Сердобольский статистически-информационный подход к семантике естественных языков, 139.01kb.
- Тема урока: Устройства ввода информации, 91.29kb.
- Метод Рутисхаузера Первыми транслирующими программа, 566.93kb.
- Машинный перевод, 218.63kb.
- Естественный звуковой язык людей является самой полной и совершенной из всех систем, 342.18kb.
- Англицизмы в современном русском языке, 123.98kb.
- Когнитивная модель языка и илпт в обучении студентов иностранному языку (русскому языку, 65.26kb.
Машинный перевод с естественного языка на естественный язык
Машинный перевод (МП) – процесс перевода с одного естественного языка на другой, в котором привлекается ЭВМ.
Классификация
Системы машинного перевода принято классифицировать:
По принципу работы: прямой перевод (системы первого поколения) – лобовое решение проблемы перевода и обеспеспечивающие результаты, близкие к пословному переводу. Операция перевода требует минимума преобразований: исходный текст постепенно превращается в текст на выходном языке путем замены всех его элементов, найденных в словаре, на переводные эквиваленты. Никакая переводная модель не требуется, кроме переводных (в основном лексических) соответствий. Учитывается лишь локальный контекст, он же позволяет учитывать некоторые более сложные единицы – обороты. Поэтому такой перевод называют пословным, или пословно-оборотным.
Непрямой перевод (системы второго поколения), в свою очередь, делится на системы с трансфером и языком-посредником. В системах второго поколения переводные соотвествия устанавливаются не «прямым» способом, а толко после того, как для каждого предложения выявлена в результате анализа его синтаксическая и/или семантическая структура. Анализ и синтез независимы. Анализ ведется в категориях входного языка, а синтез – в категориях выходного языка; связь того и другого этапов обеспечивается введением особого этапа межьязыковых операций (собственно перевода, трансфера).
Перевод через семантический язык-посредник, универсальный для разных пар естественных языков, не был обеспечен единой общепризнанное лингвистической теорией.
Системы машинного перевода (СМП), основанные на знаниях. В качестве отдельного компонента включаются экстралингвистические знания (знания о предметной области, ПО), который может иметь те же формы представления, что и собственно лингвистическая информация, т.е. записываться в словарях и грамматиках. К этому классы принадлежать те СМП, которые используют при анализе концептуальную сеть знаний.
По количеству привлекаемых языковых пар СМП делятся на двуязычные (реализующие функции перевода только для данной языковой пары) и многоязычные.
По технике лингвистического анализа: бинарные (анализ входного языка ведется в категориях выходного) и универсальные (устройство анализа не зависит от выходного языка).
По тематической ориентации различают системы монотематические, настроенные на одну ПО, и политематические.
По доле участия человека в процессе перевода: полностью автоматический перевод, человекомашинный перевод. Полностью автоматический перевод происходит без участия человека, что не исключает возможности ни некоторой предварительной обработки текста, ни постредактирования. Системы человекомашинного перевода выполняют перевод в интерактивном режиме, обычно на малых (мини- и микро-ЭВМ).Выделяют две группы таких систем: машинный перевод с участием человека и человеческий перевод с участием машины. В системах первой группы перевод выполняет СМП, обращаясь к человеку за решением сложных случаев (снятие неоднозначности, выбор одного варианта из нескольких). В системах второй группы за выполнением перевода отвечает человек, который работает за дисплеем в интерактивном режиме и может обращаться к ЭВМ, например, для поиска слов в машинных словарях.
Лингвистическое обеспечение СМП
В классических СМП, осуществляющий непрямой перевод по отдельным предложениям (пофразный перевод), каждое предложение проходит последовательность преобразодваний, состоящую из трех частей (этапов): анализ -> трансфер(межьязыковые операции)->синтез.
Цель этапа анализа – построить структурное описание (промежуточное представление) входного предложения. Задача этапа трансфера (собственно перевода) – преобразовать структуру входного предолжения во внутреннюю структуру выходного предложения. К этому этапу относится и замена входных лексем их эквивалентами выходного языка (лексические межьязыковые преобразования). Цель этапа синтеза – на основе полученной на этапе анализаструктуры построить правильное предложение выходного языка.
Анализ и следующие за ним процессы строятся с учетом теории лингвистических уровней:
Досинтаксический анализ (в него входит морфологический анализ) – анализ оборотов, неопознанных элементов текста и др.
Синтаксический анализ строит синтаксическое представление предолжения, в его пределах может выделяться ряд подуровней, обеспечивающих анализ разных типов синтаксических единиц.
Семантический анализ, или логико-семантический, строит аргументно-предикатную структуру высказываний или другой вид семантического представления предложения или текста.
Концептуальный анализ – анализ в терминах концептуальных структур, отражабщих семантику ПО. Этот уровень используется в СМП, ориентированных на очень ограниченные ПО.
Синтез теоретически проходит те же уровни, что и анализ, только в обратном направлении.
Лингвистическое обеспечение стандартной современной СМП включает словари, грамматики и формализованные промежуточные представления единиц анализа на разных этапах преобразований.
Словари. Словари анализа, как правило, одноязычные. Они должны содержать всю информацию, необходимую для включения данной лексической единицы (ЛЕ) в структурное представление. Часто разделяют словари основ (с морфолого-синтаксической информацией: часть речи, теп, словоизменение, подкласс, характеризующе синтаксическое поведение ЛЕ), и словари словозначений, содержащих семантическую и концептуальную информацию: семантический класс ЛЕ, семантические падежи (валентности), условия их реализации во фразе и т.д.
Во многих системах разделены словари общеупотрибительной и терминологической лексики. Такое разделение дает возможность при переходе к текстам другой ПО ограничиваться лишь сменой терминологических словарей. Словари сложных ЛЕ (оборотов, конструкций) образуют обычно отдельный массив, словарная информация в них указывает на способ «собирания» такой ЛЕ при анализе. Часть словарной информации может задаваться в процедурной форме, например, многозначным словам могут сопоставляться алгоритмы разрешения соответствующего типа неоднозначности. Новые виды организации словарной инофрмации (по данным на 1990г.) для целей МП предлагают так называемые «лексические базы знаний». Наличие разнородной информации о слове (называемой лексическим универсумом слова) прилижает такой словарь к энциклопедии.
Грамматики и алгоритмы. Грамматика и словарь задают лингвистическую модель, образую основную часть лингвистических данных. Алгоритмы их обработки, т.е. соотнесения с текстовыми единицами, относят к математическо-алгебраическому обеспечению системы. Разделение грамматик и алгоритмнов важно в практическом смысле тем, что позволяет менять правила грамматики, не меняя алгоритмнов (и, соответственно, программ), работающих с грамматиками. Но далеко не всегда такое разделение возможно. Так, для систем с процедурным знанием грамматики и тем более с процедурным представлением словарной инофрмации такое разделение неуместно.
Наиболее четко разделение грамматик и алгоритмов наблюдается в системах, работающих с контекстно-свободными (КС) грамматиками, где модель языка – грамматика с конечным числом состояний, а алгоритм должен обеспечить для произвольно взятого предложения дерево его вывода по правилам грамматики, и если таких выводов несколько, то перечислить их. Такой алгоритм называют анализатором. Анализаторы строятся для классов грамматик, хотя учет специфических особенностей грамматики может повысить эффективность анализатора.
Грамматики синтаксического уровня – наиболее разработанная часть с точки зрения лингвистики. Вот основные типы грамматик и реализующих их алгоритмов:
Цепочечная грамматика фиксирует порядок следования элементов, т.е. линейные структуры предложения, задавая их в терминах грамматических классов слов (артикль+существительное+предлог...) или в терминах функциональных элементов (подлежащее+сказуемое). Примером реализации такой языковой модели является предсказуемостный синтаксический анализ: идентифицируемая грамматическая категория слова предсказывает (с определенной долей вероятности) появление грамматической категории следующего за ним слова. Стратегия анализа – «слева направо»: перебор слов, проверка предсказаний, их изменение и добавление новых предсказаний регулируются механизмом «магазинной памяти» (LIFO). Формально, это реализация на ЭВМ грамматик с конечным числом состояний.
Грамматика составляющих. (ГС). Фиксирует лексическую информацию о группе грамматических элементов, например именная группа (состоит из существительного, артикля, прилагательного и других модификаторов), предложная группа (состоит из предлога и именной группы) и т.д. до уровня предложения. Грамматика строится как набор правил подстановки, или исчисление продукций вида A -> B...C. ГС представляют собой грамматики порождающего типа и могут использоваться как при анализе, так и при синтезе: предолжения языка порождаются многократным применением таких правил.
Грамматика зависимостей (ГЗ) задает иерархию отношений элементов предложения (главное слово определяет форму зависимых). Анализ в ГЗ основан на идентификации хозяев и их зависимых (слуг). Главным в предложении является глагол в личной форме, так как он определяет число и характер зависимых существительных. Стратегия анализа в ГЗ – сверху вниз: сначала идентифицируются хозяева, затем слуги, или снизу вверх: хозяева определяются процессом подстановки.
Для КСГ существует широкий выбор методик построения анализаторов. Однако чистые КСГ недостаточны для описания естественного языка. Было предложено дополнить КСГ набором трансформационных правил, работающих с деревьями составляющих. Другая возможность – использование контекстно-зависимых правил. Существует много способов учета контекстных условий. Все они являются расширениями КС-правил. В общем виде это значит, что правила продукций переписываются так: A[a] -> B[b] ... C[c], где малыми буквами обозначены условия, тесты, инструкции и т.д., расширяющие исходные жесткие правила и дающие грамматике гибкость и эффективность. Так, в грамматиках расширенных сетей переходов – РСП, предусмотрены тесты и условия к дугам, а также инструкции, которые надо выполнить в случае, если анализ пошел по данной дуге. В разных модификациях дугам может приписываться вес, тогда анализатор может выбирать путь с наибольшим весом. Условия могут разбиваться на две части: контекстно-свободные и контекстно-зависимые.
Новым и сразу завоевавшим популярность методом грамматического описания является лексико-функциональная грамматика (ЛФГ). Проверочные условия в ней отделены от праил подстановки и “решаются” как автономные уравнения.
Унификационные грамматики (УГ) представляют собой обобщение модели анализа: они способны воплощать грамматики различных видов. УГ содержит четыре компонента: пакет унификаций, интерпретатор для правил и лексических описаний, программы обработки направленных графов, анализатор с помощью граф-схемы. УГ объединяют грамматические правила со словарными описаниями, синтаксические валентности с семантическими.
Семантический уровень гораздо меньше обеспечен теорией и практическими разработками. Традиционной задачей семантики считается снятие неоднозначности синтаксического анализа – структурной и лексической. Для этого используется аппарат селективных ограничений, который привязан к рамкам предположений, т.е. вписывается в синтаксическую модель. Логико-семантический анализ представляет структуру предложения в терминах логических отношений (предикаты, аргументы, атрибуты), уменьшая расстояние между поверхностными структурами разных языков. Впоследствии эти системы перешли к трансферной стратегии.
Грамматика семантического уровня в чистом виде (вне связи с синтаксисом) представлена в семантическом анализаторе Й. Уилкса. Его модель семантической предпочтительности включает такие инструменты семантического анализа, как тезаурусная информаци, правила вывода “по здравому смыслу”, понятие псевдотекста, декомпозицию лексем на семантические примитивы, что позволяет доказывать семантическую связность даже в трудном лингвистическом материале (метафорические словоупотребления).
Другая несинтаксическая грамматика – модель концептуальных зависимостей в системе, основанной на знаниях в ограниченной ПО. Понятийные сети, концептуальные сети, фреймы, схемы ПО используются как грамматика концептуального уровня.
Типы промежуточный представлений. В качестве отдельного компонента лингвистического обеспечения выделяют временные знания об обрабатываемом фрагменте текста (в отличие от постоянных, долговременных знаний, содержащихся в словарях и грамматиках). В основном это сведения о внутренней структуре такого фрагмента (синтаксической, семантической, анафорической и т.п.) – его формализованное представление, выражаемое в терминах составляющих, зависимостей, семантических сетей, фреймов и т.д. При анализе структурное представление используется для контроля за правильностью разбора предложения, а также является основой для перевода (входом в этап перевода и затем синтеза).
Можно выделить пяьт типов промежуточных структур:
- Собственно синтаксическое представление в разных вариантах: в терминах дерева ГС или ГЗ.
- СинСемП – представление на синтаксической основе, но в терминах глубинных семантических отношений (переход к структуре выходного предложения требует только смены лексики).
- СемП – представления на семантической основе, безразличное к членению текста на предложения.
- Концептуальная структура в терминах ПО.
- Язык-посредник (ЯП), или интерлингва.
Между этими представлениями существует отношение не альтернативы, а развития: каждое следующее «глубже» предшествующих. Первые две структуры имеют лингвистическую основу, третья и четвертая – понятийную, пятая базируется на единицах, не принадлежащих ни входному, ни выходному языку.
Лингвистическое обеспечение этапов трансфера и синтеза. Синтез в стандартных СМП трехчастного типа устроен проще, чем анализ, если он обеспечивается соответствующим входом, т.е. если после работы трансфера построено одно правильное дерево фразы. Используется та же лингвистическая модель, что и в анализе, в виде порождающей грамматики, программа синтеза работает как детерминированный преобразователь; необходимые для построения выходной словоформы грамматические категори определяются свойствами подчиняющего узла в дереве предложения. Одноязычные словари синтеза содержат всю информацию, которая позволяет синтезировать требуемую словоформу; в случае, если таковая не может быть построена, предлагаются замены.
Одна из задач синтеза – линеаризация узлов дерева, определяющий нужный порядок слов в синтезируемом предложении. Стандартным решением задачи о порядке слова является передача на этап синтеза информации о взаимном расположении слов (или групп, конструкций) в исходном предложении с учетом тех регулярных изменений, которые производяся на этапе трансфера.
Правильность дерева, построенного на этапе трансфера, или выбор одного из нескольких вариантов, если они остались, проверяется теми же методами, что и на этапе анализа. Таким образом, решение всех содержательных вопросов, которые могут повлиять на построение хорошено выходного предложения, остаются в компетенции этапов анализа и трансфера (межьязыковых операций).
Компонент трансфера задается двумя частями:
- Словарь трансфера, или переводной (межьязыковый словарь), - это двуязычный словарь лексических замен. Как правило он однонаправлен: ЛЕ (словозначение) входного языка -> ЛЕ выходного языка, поскольку для каждого слова с нерасчлененным значениями существует несколько переводов в зависимости от контекста. Возможны и обратимые переводные словари.
- Словарь структурных соответствий, или грамматика трансфера.
Работа алгоритма преобразования состоит в сравнении структур (pattern matching), вычислении нужных значений и замене структур входного предложения структурой выходного.Эти части связаны, так что собственно перевод состоит иногда в замене целых поддеревьев (слова с его структурным контекстом) их лексическими и структурными эквивалентами.
Синтаксический анализ (Text Parsing) (А.Михаилян
"Некоторые методы автоматического анализа естественного языка, используемые в промышленных продуктах")
Цель синтаксического анализа — автоматическое построение функционального дерева фразы, т.е. нахождение взаимозависимостей между разноуровневыми элементами предложения. Считается, что имея успешно построенное функциональное дерево фразы, можно выделить из предложения смысловые элементы: логический субъект, логический предикат, прямые и косвенные дополнения и различные виды обстоятельств. Существует большое количество различных количество подходов к синтаксическому анализу текстов. Ниже перечислены несколько известных методов построения функционального дерева фразы.
Ergo Linguistic Technologies Parser
Синтаксический анализатор (parser), разработанный Дереком Бикертоном и Филипом Браликом из Университета Гонолулу использует схему аннотации, принятую в Penn Treebank. Данная схема широко известна и имеет очень наглядное представление.
ERGO не предоставляет информацию об алгоритмах, использующихся в продуктах компании, но предлагает всем желающим - участвовать в конкурсе на лучший синтасксический анализатор, устроенном самой ERGO. На рис.2 представлен пример разбора текста синтаксическим анализатором ERGO. Подчиненные элементы сдвинуты вправо и заключены в скобки.
(S (NP-SBJ there)
(VP is
(NP-PRD a dog
(PP-LOC on
(NP the porch)))))
Обозначения
S - предложение
NP - именная группа
NP-SBJ - именная группа - субъект
VP - verb phrase
NP-PRD - именная группа - объект
PP_LOC - предложно-именная группа, локатив
Рис 2. Пример анализа текста синтаксическим анализатором ERGO.
Functional Dependency Grammar
Создан исследователями из Хельсинского Университета, позднее основавшими две фирмы: Lingsoft и Conexor. Один из наиболее удачных синтаксических анализаторов. Ранняя версия под названием ENGCG (English Constraint Grammar) была использована для аннотации самого большого в мире корпуса — Bank of English, принадлежащего издательству Collins/Harper Publishers. Отличительной особенностью данного синтаксического анализатора является то, что в случаях, когда невозможно снять многозначность, синтаксический анализатор либо выдает несколько вариантов анализа, либо не достраивает дерево для данной части предложения. В основе FDG лежит теория зависимостей, впервые предложенная Л.Теньером [Tesniere, 1959], позднее описанная Герингером [Heringer, 1993] и реализованная в рамках контекстно-зависимой грамматики [Tapanainen and Jarvinen, 1997]. На рис. 3 и 4 показан пример разбора фразы синтаксическим анализатором FDG.
1 Lots+of lots+of det:>2 @DN> DET
2 people people subj:>3\ @SUBJ N
3 act act main:>0 @+FMAINV V
4 well well man:>3 @ADVL ADV
5 but but cc:>3 @CC CC
6 very very @AD-A> ADV
7 few few det:>8 @DN> DET
8 people people subj:>9 @SUBJ N
9 talk talk cc:>3 @+FMAINV V
10 well well man:>9 @ADVL ADV
$.
Обозначения
Идентификаторы дерева фразы:
det: - определитель
subj: - субъект
main: - основной элемент
man: - обстоятельство образа действи
сс: - сочинительный союз
Функциональные идентификаторы:
@DN> - определитель
@SUBJ - субъект
@+FMAINV - личный предикатор
@ADVL - обстоятельство
@CC - сочинительный союз
@AD-A> - интенсификатор
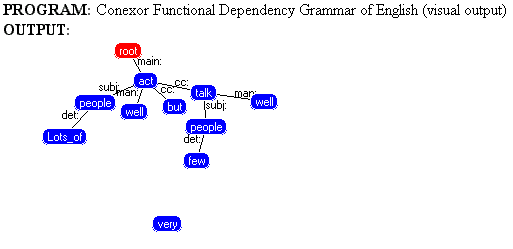
Рис 4. Пример анализа текста синтаксическим анализатором FDG;
визуальное представление.
Link Parser
Один из наиболее оригинальных подходов к синтаксическому анализу текста — Link Parser, разработанный в Carnegie-Melon University. Этот синтаксический анализатор — единственный, чьи исходные коды были опубликованы он-лайн. Тогда как большинство систем синтаксического анализа используют структуры уровня именных и глагольных групп, при построении дерева фразы, Link Grammar, лежащая в основе Link Parser'а, использует информацию о типах связей, которые каждое слово может иметь со словами, находящимися справа или слева и несколько общих грамматических правил. На рис.5 показано предложение, анализированное с помощью Link Parser.
+-----------------Xp-----------------+
| +--------Sp--------+ |
+--Wd--+-Mp-+--Jp-+ +--MVa-+ |
| | | | | | |
///// lots.n of people.p talk.v well.e .
Обозначения
Xp - связь между началом и концом предложени
Sp - связь между существительным и глаголом
Wd - связь между началом предложения и предложением
Mp - связь между именной группой и модифицирующей ее предложно-именной группой
Jp - связь между предлогом и относящейся к нему именной группой
MVa - связь между глаголом (прилагательным) и модификатором
Рис 5. Пример анализа текста с помощью Link Parser
В последнее время над задачами синтаксического анализа предложения работает множество исследовательских групп, и на настоящий момент можно считать, что в рамках синтаксического анализа предложения успешно решена и уже нашла применение в производстве задача автоматического выделения именных групп. Что же касается полного синтаксического разбора предложения, данная проблема разрабатывается все еще скорее в стенах университетских экспериментальных лабораторий, чем в лабораториях промышленных предприятий.
Проблемы машинного перевода
Конечно, проблемы, перечисленные ниже, не являются единственной причиной сложности систем МП. Другие проблемы связаны с большим числом правил и записей в словарях в реальных системах, с существованием конструкций, грамматика которых плохо понимаема, и непонятно, каким образом их можно представить или какие правила дложны быть использованы для их описания.
Неоднозначность
Когда слово имеет более одного значения, тоговорят, что оно лексически неоднозначно. Когда фраза или предложение может иметь более одной структуры, то говорят, что оно структурно неоднозначно. Неоднозначность – это капризный феномен естественного языка. Сложно найти слово, которое хотя бы не двузначно (англ.), а неоднозначные предложения (вне контекста) – это скорее всего правило, чем исключение. Проблема даже не в том, что некоторые альтернативы представляют собой неверные интерпретации, а в том, что неопределенность умножается. Предложение с двумя двузначными словами, неоднозначно четырежды, а с тремя такими словами – 8-значны. Грамматические правила резко уменьшают неоднозначность анализа. Тем не менее, знания о синтаксисе не позволяют нам определить значения всех неоднозначных слов. Это потому, что слово может иметь разное значение даже в пределах одной части речи. Например, слово button, которое может быть и существительным, и глаголом. Как существительное, оно может означать «пуговица» и «кнопка». Чтобы заставить машину использовать правильную интерпретацию, необходимо дать ей информацию о значении.
Фактически, вооружение компьютера знанием о синтаксисе, и скрытие от него информации о значении – это опасная вещь. Это от того, что применение грамматики к предложению может породить несколько различных вариантов анализа, и дело может кончиться комбинаторным взрывом. Синтаксическая неоднозначность может вылиться в неоднозначность смысла, и чтобы этого не произошло, необходимо применать знания о семантике.
Можно показать на примере, как грамматические правила, примененные по-разному, могут породить разную синтаксическую структуру предложения. Один из случаев – когда слово принадлежит более одной категории в грамматике. Например, слово cleaning – одновременно и прилагательное, и глагол. Это позволит нам присвоить два разных анализа следующему предложению:
Cleaning fluids can be dangerous
Один из вариантов исходит из того, что слово cleaning – это прилагательное, а другой – глагол. Выбор между этими альтернативами синтаксического анализа требует знания о семантике.
Лексические и структурные несовпадения
Разные языки по-разному классифицируют мир, по-разному выбирают концепции, выраженные одним словом, и концепции, которые никак не лексикализованы. Некоторые проблемы возникают из-за того, что разные языки используют разные структуры для одинаковых целей или одинаковые структуры для разных целей. В любом случае результатом является усложнение процесса перевода. В английском языке разные глаголы означают действие/событие «надеть» и децствие/состояние «носить». В японском такого различия нет, но есть различия по тому, что надевается (носится). В некоторых случаях переводчик встречается с такими культурными категориями (напр. «дача»), которые отсутствуют в целевом языке. Переводчик-человек в этом случае может предоставить дополнительные описания, неологизмы.
Лексические дыры – когда в одном языке приходится выражать фразой то, что в другом называется одним словом.
Многословные единицы: идиомы
Грубо говоря, идиомы – это выражения, значения которых не могут быть полностью поняты из значений составляющих их частей. Проблема с идиомами заключается в том, что не всегда их можно перевести, руководствуясь обычными правилами. Лексические дыры и идеомы – это чаще всего одно и то же. Разница в том, что с лексической дырой мы сталкиваемся, когда пытаемся перевести одно слово исходного языка фразой целевого языка, а с идеомой – когда фраза переводится одним словом. Существует два подхода к трактовке идиом. Первый – попытаться представить их одной лексической единицей, особенным типом слова, которое содержит в себе пробелы. Как стало потом ясно, это вцелом не работоспособное решение. Более последовательная идея – это не обособлять лексический поиск как единственный процесс, который выполняется только раз, перед синтаксическим и семантическам анализом, а позволить правилам анализа замещать фрагмены структуры информацией из лексикона на разных стадиях обработки.