
Сеть Internet. Служба www
| Вид материала | Документы |
- Впредставленном курсовом проекте рассматривается глобальная сеть Internet самая крупная, 477.68kb.
- Transmission Control Protokol/Internet Protokol. Это набор правил, регламент, 143.73kb.
- Основы электронной коммерции, 2341.68kb.
- А, а также связанные с этим сервисы, частично или полностью через пакетные сети, 211.32kb.
- Мифы и реальности Internet известные и скрытые возможности сети Что такое Internet, 306.75kb.
- Сборника (www grom2005. com), 1527.25kb.
- Техническое задание на разработку структур птк наименование и область применения птк, 152.13kb.
- План: 1-Что такое Интернет (понятие) 2-Способы подключения к Интернет, 81.69kb.
- Южно Уральского Государственного Университета Машиностроительный Факультет Кафедра, 213.7kb.
- Создание собственной web-страницы в Internet, 927.61kb.
Сеть Internet. Служба WWW
Компьютер стал недорогим и высокопроизводительным рабочим инструментом. Чем дальше, тем быстрее наш мир приходит к повседневному использованию ПК и информационных сетей. Среди более чем двадцати глобальных информационных сетей Интернет называют Сетью с большой буквы. В настоящее время ПК и Интернет составляют не менее важную инфраструктуру, чем пути сообщения или электрическая сеть.
В дословном переводе на русский язык Интернет-это межсеть, то есть в узком смысле слова Интернет-это объединение сетей. Однако в последние годы у этого слова появился и более широкий смысл: Всемирная компьютерная сеть. Интернет можно рассматривать в физическом смысле как несколько миллионов компьютеров, связанных друг с другом всевозможными линиями связи, однако такой «физический» взгляд на Интернет слишком узок. Лучше рассматривать Интернет как некое информационное пространство. Интернет – это не совокупность прямых соединений между компьютерами. Так, например, если два компьютера, находящиеся на разных континентах, обмениваются данными в Интернете, это совсем не значит, что между ними действует одно прямое или виртуальное соединение. Данные, которые они посылают друг другу, разбиваются на пакеты, и даже в одном сеансе связи разные пакеты одного сообщения могут пройти разными маршрутами. Какими бы маршрутами не двигались пакеты данных, они все равно достигнут пункта назначения и будут собраны вместе в цельный документ. При этом данные, отправленные позже , могут приходить раньше, но это не помешает правильно собрать документ, поскольку каждый пакет имеет свою маркировку. Таким образом, Интернет представляет собой как бы «пространство», внутри которого осуществляется непрерывная циркуляция данных. В этом смысле его можно сравнить с теле- и радиоэфиром, хотя есть очевидная разница хотя бы в том, что в эфире никакая информация храниться не может, а в Интернете она перемещается между компьютерами, составляющими узлы сети, и какое-то время хранится на их жестких дисках.
Днем рождения Интернета в современном понимании этого слова стала дата стандартизации протокола связи TCP/IP, лежащего в основе Всемирной сети по нынешний день. Интернет работает под семейством протоколов TCP/IP, которое имеет четыре уровня (рис.1)
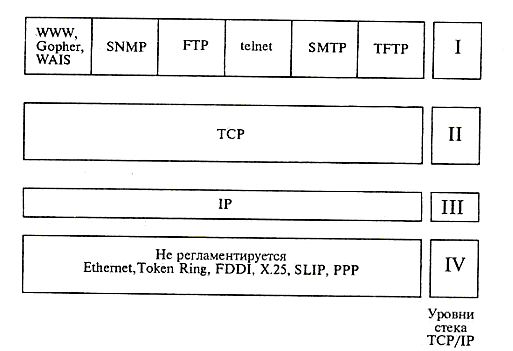
Рис.1
Самый нижний (уровень |V) соответствует уровню доступа к сети. В протоколах стека TCP/IP он не регламентируется, но поддерживает все популярные стандарты протоколов физического и канального уровня, такие, как Ethernet, Token Ring, SLIP, PPP и другие. Протоколы данного уровня обеспечивают передачу пакетов данных в сети на уровне аппаратных средств.
Следующий уровень (уровень ||| )– это уровень межсетевого взаимодействия, который обеспечивает передачу пакетов данных из одной подсети в другую. В качестве протокола в стеке используется адресный протокол IP (Internet Protocol). Его суть состоит в том, что у каждого участника Всемирной сети должен быть свой уникальный адрес (IP – адрес). Без этого нельзя говорить о точной доставке TCP – пакетов на нужное рабочее место. Этот адрес выражается очень просто - четырьмя байтами, например: 195.38.46.11. Структура IP – адреса организована так, что каждый компьютер, через который проходит какой-либо TCP – пакет, может по этим четырем числам определить, кому из ближайших соседей надо переслать пакет, чтобы он оказался «ближе» к получателю. В результате конечного числа перебросок TCP-пакет достигает адресата. Решением вопросов, что считать «ближе», а что «дальше», занимаются специальные средства – маршрутизаторы. Роль маршрутизатора в сети может выполнять как специализированный компьютер, так и специальная программа, работающая на узловом сервере сети.
Следующий уровень (уровень || ) называется основным. На этом уровне функционирует протокол управления передачей TCP (Transmission Control Protocol – управляющий протокол передачи). Согласно протоколу TCP, отправляемые данные «нарезаются» на небольшие пакеты, после чего каждый пакет маркируется таким образом, чтобы в нем были данные, необходимые для правильной сборки документа на компьютере получателя. Для понимания сути протокола TCP можно представить игру в шахматы по переписке, когда двое участников разыгрывают одновременно десяток партий. Каждый ход записывается на отдельной открытке с указанием номера партии и номера хода. В этом случае между двумя партнерами через один и тот же почтовый канал работает как бы десяток соединений (по одному на партию). Два компьютера, связанные между собой одним физическим соединением, могут точно так же поддерживать одновременно несколько TCP – соединений. Так, например, два промежуточных сетевых сервера могут одновременно по одной линии связи передавать друг другу в обе стороны множество TCP-пакетов от многочисленных клиентов.
Все перечисленные выше протоколы можно отнести к «уровню секретарей». Для конечного пользователя («начальника») наиболее необходима компетентность на самом верхнем уровне (уровень |), который называется на языке стека TCP/IP прикладным. За долгие годы использования в сетях различных стран и организаций стек TCP/IP накопил большое количество протоколов и сервисов прикладного уровня (см. рис.1).
Основные информационные ресурсы Интернет
Информационные ресурсы Интернет – это вся совокупность информационных технологий и баз данных, доступных при помощи этих технологий и существующих в режиме постоянного обновления. К их числу относятся:
- электронная почта;
- система телеконференций Usnet;
- система файловых архивов FTP;
- базы данных WWW;
- базы данных Gopher;
- базы данных WAIS;
- информационные ресурсы LICTSERV;
- справочная служба WHOIS;
- информационные ресурсы TRICKLE;
- поисковые машины Open Text Index, Alta Vista, Yahoo, Lycos и др.
Разные ресурсы имеют разные протоколы. Они называются прикладными протоколами. Их соблюдение обеспечивается и поддерживается работой специальных программ. Таким образом, чтобы воспользоваться какой-либо из служб Интернета, необходимо установить на компьютере программу, способную работать по протоколу данной службы. Такие программы называются клиентами.
Интернет- это главным образом возможность получить информацию в тот же момент, когда она нужна, т.е. в режиме on-line. Но если нет возможности работать в on-line, то для доступа к услугам большинства информационных серверов Интернет можно воспользоваться электронной почтой. Общий принцип доступа к любому информационному ресурсу через электронную почту заключается в том, что пользователь посылает сообщение почтовому роботу (специальному почтовому серверу – специальная программа автоматического обслуживания), который реализует стандартный доступ (telnet,ftp,WWW) к ресурсу и отправляет ответ пользователю по почте. (Рис2).

Рис.2
При такой схеме доступа общение между пользователем и почтовым роботом происходит в режиме работы электронной почты, а между почтовым роботом и сервером (ftp, wais или WWW) по протоколу робота этого сервера. Отметим, что многие информационные ресурсы имеют программы-роботы, которые способны общаться с почтовыми клиентами по схеме, представленной на рис.2.
Дадим краткую характеристику ресурсам Сети.
Электронная почта. Электронная почта используется для пересылки корреспонденции и, как было указано выше, по почте можно получить доступ ко многим ресурсам Интернет. Электронная почта во многом похожа на обычную почтовую службу. Корреспонденция подготавливается пользователем на своем рабочем месте либо программой подготовки почты, либо обычным текстовым редактором. Затем пользователь должен вызвать программу отправки почты(программа подготовки почты вызывает программу отправки автоматически), которая посылает сообщение на почтовый сервер отправителя. Тот в свою очередь посылает его на почтовый сервер адресата, где специальная программа занимается сортировкой почты и рассылкой ее по ящикам конечных пользователей. После запуска программы получения почты адресат устанавливает соединение со своим почтовым сервером и организует пересылку всех полученных сообщений на свое имя сообщений. Отметим, что почтовые серверы постоянно подключены к Сети, тогда как компьютеры участников переписки могут устанавливать соединение с ними по мере необходимости. Отметим также, что когда мы говорим о каком-либо сервере, не имеется в виду, что это специальный выделенный компьютер. Под сервером может пониматься программное обеспечение. Один узловой компьютер Интернета может выполнять функции нескольких серверов и обеспечивать работу различных служб.
При настройке программы работы с электронной почтой независимо от ее интерфейса необходима следующая информация от провайдера (поставщик услуг – организация или частное лицо, предоставляющие возможность подключения к своему узлу и выделяющи IP-адреса): имя сервера исходящей почты, имя сервера входящей почты, имя пользователя и пароль, а также типы протоколов, используемые при почтовом обмене.
Электронная почта основана на двух прикладных протоколах: SMTP (Simple Mail Transfer Protocol) и POP3 (Post Office Protocol, версия3). По первому происходит отправка корреспонденции с компьютера на сервер, а по второму – прием поступивших сообщений.
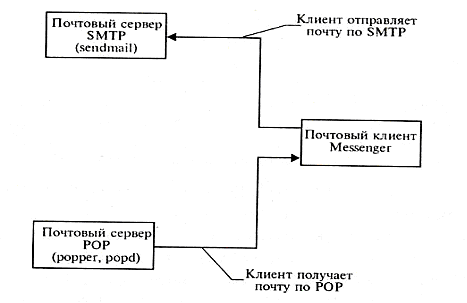
Рис.3
Основой любой почтовой службы является система адресов. В Интернет принята система адресов, которая базируется на доменном адресе машины. Например, Petrov@ensta.fr, Ivanov@inp.nsk.su. Адрес состоит из двух частей: идентификатора пользователя, который записывается перед знаком «коммерческого эй», и доменного адреса машины, который записывается после знака @.
Существует большое разнообразие клиентских почтовых программ, например, Microsoft Outlook Express (под Windows 98), Microsoft Outlook 2000 (пакет Microsoft Office 2000). Из специализированных почтовых программ хорошую популярность имеют программы The Bat и Eudora Pro.
Usenet – это служба телеконференций Интернет, которая похожа на циркулярную рассылку электронной почты, в ходе которой одно сообщение отправляется не одному корреспонденту, а большой группе (такие группы называются телеконференциями или группами новостей). Обычное сообщение электронной почты пересылается по узкой цепочке серверов от отправителя к получателю. При этом не предполагается его хранение на промежуточных серверах. Сообщения, направленные на сервер группы новостей, отправляются с него на все серверы, с которыми он связан, если на них данного сообщения еще нет. Далее процесс повторяется. Характер распространения каждого отдельного сообщения напоминает лесной пожар. На каждом из серверов поступившее сообщение хранится ограниченное время (обычно неделю). Для работы со службой телеконференций существуют специальные клиентские программы. Так, например, приложение Microsoft Outlook Express, являющееся почтовым клиентом, позволяет работать также и со службой телеконференций.
FTP – система файловых архивов – это огромное распределенное (т.е. расположенное на машинах сети, в том числе и функционирующих на разных платформах) хранилище всевозможной информации, накопленной за последние 10-15 лет в Сети. Объем программного обеспечения в архивах FTP составляет терабайты информации, и ни один пользователь или администратор сети не может просто физически обозреть эту информацию. Со стороны клиента для работы с серверами FTP может быть установлено специальное программное обеспечение, хотя в большинстве случаев броузеры WWW обладают встроенными возможностями для работы и по протоколу FTP. Протокол FTP также представляет серверу средства для идентификации обратившегося клиента. Этим часто пользуются коммерческие серверы и серверы ограниченного доступа, поставляющие информацию только зарегистрированным клиентам, - они выдают запрос на ввод имени пользователя и связанного с ним пароля. Однако существуют и десятки тысяч FTP-серверов с анонимным доступом для всех желающих. В этом случае в качестве имени пользователя надо ввести слово: anonymous, а в качестве пароля задать адрес электронной почты. В большинстве случаев программы-клиенты FTP делают это автоматически.
World Wide Web («всемирная паутина») – это последний хит Сети Интернет, темпы развития которого стремительно нарастают. WWW нередко отождествляют с Интернетом, хотя на самом деле это лишь одна из его многочисленных служб. Об этой системе поговорим позже более подробно.
Gopher – в основу ее интерфейсов положена идея иерархических каталогов. Внешне выглядит как огромная файловая система, расположенная на машинах сети. Первоначально Gopher задумывался как информационная система университета с информационными ресурсами факультетов, кафедр, общежитий ит.п. В России Gopher серверы не так распространены, как во всем мире, предпочитают WWW.
WAIS – в основу системы положен принцип поиска информации с использованием логических запросов, основанных на применении ключевых слов. Широко применяется как поисковая машина в других ресурсах Интернет, например, WWW, Gopher.
LISTSERV – служба почтовых списков сети образовательных учреждений, специально ориентирована на применение в качестве транспорта электронной почты.
WHOIS – служба содержит информацию о пользователях сети, их электронные и обычные адреса, идентификаторы и реальные имена.
TRICKLE – это доступ по почте к архивам FTP, который организован через специальный шлюз.
Поисковые машины Open Text Index, Alta Vista, Yahoo, Lycos и др. Представляют собой мощные информационно-поисковые системы, размещенные на серверах свободного доступа, специальные программы которых непрерывно в автоматическом режиме сканируют информацию Сети на основе заданных алгоритмов, проводя индексацию документов.
Служба (система) имен доменов DNS (Domain Name System). В Интернет каждой машине приписан определенный адрес, по которому к ней и осуществляется доступ в рамках одного из стандартных протоколов, причем существует одновременно как числовая адресация (так называемый IP-адрес, состоящий из набора четырех чисел, разделенных точками, например, 144.206.160.32), так и более удобная для восприятия человеком система осмысленных доменных имен. Домены отделяются точками (имя. группа. город. страна), доменов обычно не более пяти. Для стран есть единый каталог, например, su-бывший СССР, ru - Россия, fr – Франция, de-Германия, Ca – Канада и т.д. Наиболее крупные организации (используется в США) - edu - образовательные сети, com - коммерческие, gov - государственные, net – сетевые ресурсы и др. Имя домена должно иметь смысл, легко запоминаться и вводиться с клавиатуры, а также не использоваться другой организацией в Интернете. Выбранное подходящее имя регистрируется (либо из области Registration Web-страницы «InterNIC», заполняя текстовый бланк в любом текстовом редакторе, либо заполняют форму WWW, используя программу просмотра Web). Примеры: appolo.inp.nsk.su, ссылка скрыта (это имя компьютера в Сети, а не URL - адрес файла в Сети. URL – адрес файла состоит из трех частей протокол: // доменное имя компьютера / полный путь доступа к файлу на данном компьютере: http//www.abcde.com/Files/abc.zip). Доменная адресация выполняет роль сервиса. Автоматическая же работа серверов Сети организована с использованием числового адреса. Поэтому необходим перевод доменных имен в связанные с ними IP-адреса. Этим и занимается служба имен доменов DNS.
Модель «клиент-сервер» как основа построения информационных сервисов Интернет
В основу взаимодействия компонентов сервисов Сети положена модель «клиент-сервер». Как правило, в качестве клиента выступает программа, которая установлена на компьютере пользователя, а в качестве сервера – программа, установленная у провайдера. При этом возможны два варианта организации самой информационной системы, которая обеспечивает доступ к информационному ресурсу.
Большинство систем Интернет построены по принципу взаимодействия «каждый с каждым», например, система WWW, т.е. каждый пользователь может напрямую взаимодействовать с каждым сервером без посредников. Такой подход позволяет упростить всю технологическую схему построения системы, однако приводит к порождению большого трафика в Сети.
Альтернативный вариант построения системы, например Usenet, когда пользователь может взаимодействовать только со «своим» сервером и не может обратиться к произвольному серверу в Сети. Однако доступ он получает ко всей информации, которая присутствует в данной информационной системе, т.к. серверы обмениваются ею между собой.
В ряде случаев возможен выбор между первым способом реализации информационного обслуживания и вторым, например, это возможно в службе доменных имен DNS. Администратор сервера может настроить его для работы через другой сервер или непосредственно с программами-клиентами.
Выше приведенные схемы организации доступа к ресурсам показаны на рис.4.
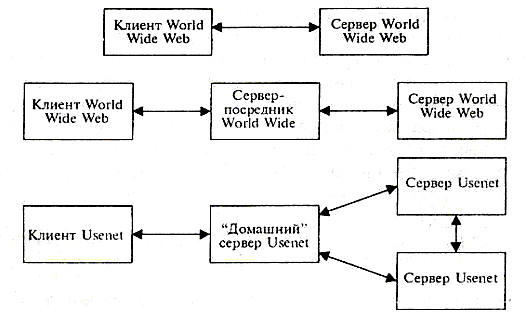
Рис.4
Схемы адресации ресурса в Интернет
В основу построения адреса ресурса в Сети заложены следующие понятия и принципы:
Расширяемость – новые адресные схемы должны легко вписываться в существующий синтаксис URI (Uniform Resource Identifier – универсальный идентификатор ресурса)(иерархическая адресация файлов). Было введено понятие адресная схема. При этом идентификатор схемы стоит перед остатком адреса, отделен от него двоеточием и двойным слэшем, также идентификатор схемы определяет порядок интерпретации остатка.
Читаемость – адрес должен быть легко читаем человеком.
Наиболее распространенные схемы адресации в Интернет:
Схема HTTP. Это основная схема для WWW. В схеме указывается идентификатор схемы, имя сервера (компьютера) Интернет, путь к файлу на этом сервере. Пример:
ссылка скрыта .
Схема FTP. Данная схема позволяет адресовать файловый архивы FTP из программ-клиентов WWW. При этом программа должна поддерживать протокол FTP. В данной схеме возможно указание не только имени схемы, адреса FTP-архива, но и имени пользователя и даже его пароля. Наиболее часто используется для доступа к публичным архивам FTP:
ссылка скрыта Здесь записана ссылка на архив «polyn.net.kiae.su» с идентификатором «anonymous» или «ftp» (анонимный доступ). Если есть необходимость указать идентификатор пользователя и его пароль, то можно это сделать перед адресом машины:
ftp://nobody:password@/polyn.net.kiae.su/users/local/pub .
Схема Gopher. Данная схема используется для ссылки на ресурсы системы Gopher. Схема состоит из идентификатора и пути, в котором указывается адрес Gopher – сервера, тип ресурса и команда Gopher: gopher://gopher.kiae.su:70:/7/kuku . В этом примере осуществляется доступ к gopher-серверу «gopher.kiae.su» через порт 70 для поиска (тип7) слова «kuku».
Схема FILE. WWW-технология используется как в сетевом, так и в локальном режимах. Для локального режима используют схему File: file:///CI/text/html/inaex.htm . В данном примере приведено обращение к локальному документу на персональном компьютере MS DOS или MS Windows.
Существует еще несколько схем.
Из приведенных выше примеров видно, что спецификация адресов URI является довольно общей и позволяет адресовать практически любой ресурс Интернет. Реальный механизм интерпретации идентификатора ресурса, опирающийся на URI, называется URL(Uniform Resource Locator – унифицированный указатель ресурса). Пользователи WWW имеют дело именно с ним.
Подключение к Интернет
Для работы в Интернете необходимо:
- физически подключить компьютер к одному из узлов Всемирной сети (через сетевой адаптер или модем);
- получить IP-адрес на постоянной или временной основе;
- установить и настроить программное обеспечение – программы-клиенты тех служб Интернета, услугами который предполагается пользоваться.
Организации, предоставляющие возможности подключения к своему узлу и выделяющие IP-адреса, называются поставщиками услуг Интернета (провайдерами). Они оказывают подобную услугу на договорной основе. Для подключения к компьютеру провайдера надо правильно настроить программу «Удаленный доступ к сети». При настройке программы необходимы данные, которые должен сообщить провайдер:
- номер телефона, по которому производится соединение;
- имя пользователя (login);
- пароль;
- IP – адрес сервера DNS.
Физическое подключение может быть выделенным или коммутируемым. Для выделенного соединения необходимо проложить новую или арендовать готовую физическую линию связи (кабельную, оптоволоконную, радиоканал, спутниковый канал и т.п.). Такое подключение используют организации и предприятия, нуждающиеся в передаче больших объемов данных. От типа линии связи зависит ее пропускная способность. В настоящее время пропускная способность мощных линий связи (оптоволоконных и спутниковых) составляет сотни мегабит в секунду (Мбит/с).
В противоположность выделенному соединению коммутируемое соединение – временное. Оно не требует специальной линии связи и может быть осуществлено, например, по телефонной линии. Коммутацию (подключение) выполняет автоматическая телефонная станция (АТС) по сигналам, выданным в момент набора телефонного номера. Для телефонных линий связи характерна низкая пропускная способность. Телефонные линии никогда не предназначались для передачи цифровых сигналов – их характеристики подходят только для передачи голоса, причем в достаточно узком диапазоне – 300-3000 Гц. Поэтому для передачи цифровой информации несущие сигналы звуковой частоты модулируют по амплитуде, фазе и частоте. Такое преобразование выполняет модем.
Технология (или служба) WWW
В течение последних лет предпринималось немало попыток разработать концепцию универсальной информационной базы данных, в которой можно было бы не только получать информацию из любой точки земного шара, но и иметь удобный способ связи информационных сегментов друг с другом.
World Wide Web – это единое информационное пространство, состоящее из сотен взаимосвязанных электронных документов, хранящихся на Web-серверах. Отдельные документы, составляющие пространство Web, называют Web-страницами. Группы тематически объединенных Web-страниц, называют Web-сайтом или просто сайтом. Один физический Web-сервер может содержать достаточно много Web-сайтов, каждому из которых, как правило, отводится отдельный каталог на жестком диске сервера.
WWW – самый популярный и самый интересный сервис Интернет в настоящее время. Самое распространенной имя для компьютера в Интернет – www. Количество серверов WWW сегодня нельзя оценить сколько-нибудь точно, но по некоторым оценкам их более 300 тысяч. Скорость роста WWW даже выше, чем у самой сети Интернет.
Проект WWW возник в начале 1989 г. в Европейской Лаборатории физики элементарных частиц. Основное назначение проекта – предоставить пользователям не профессионалам «on-line» доступ к информационным ресурсам.
Используя популярный программный интерфейс, проект WWW изменил процесс просмотра и создания информации. Идея заключалась в том, что по всему миру хаотично разбросаны тысячи информационных серверов и любую машину, подключенную к Интернет в режиме «on-line», можно преобразовать в сервер и начинить его информацией. А с любого компьютера, подключенного к Интернет, можно свободно установить сетевое соединение с таким сервером и получить от него информацию.
Позднее к проекту подключились и многие другие организации. Большой вклад в развитие WWW –технологий внес Национальный центр суперкомпьютерных приложений.
Информационный WWW-сервер использует гипертекстовую технологию. Для записи документов в гипертексте используется специальный, но очень простой язык HTML (Hypertext Markup Language – язык разметки гипертекста), который позволяет управлять шрифтами, отступами, вставлять гиперссылки, цветные иллюстрации, поддерживает вывод звука и анимации (средства мультимедиа). Для этого он использует специальные команды-теги. В стандарт языка также входит поддержка математических формул. Web-документ представляет собой обычный текстовый документ, размеченный тегами. Большинство тегов используются парами: открывающий тег и закрывающий. Закрывающий тег начинается с символа «/».
Сложные теги имеют кроме ключевого слова дополнительные атрибуты и параметры, детализирующие способ их применения. При отображении документа на экране с помощью программы броузера теги не показываются, и мы видим только Текст, составляющий документ.
Внешне гипертекст отличается от обычного текста тем, что часть слов или целые строки в нем, будучи выделены особым шрифтом или цветом, оказываются чувствительными к появлению на них указателя манипулятора «мышь». Щелчок мыши приводит к инициированию какого-либо события, чаще всего к загрузке в программу просмотра нового документа, привязанного так называемой гипертекстовой ссылкой к выделенной строке текста. В результате у пользователя появляется возможность самому выбирать порядок просмотра тех или иных страниц, двигаясь по перемежающимся между собой нитям – паутинкам ссылок. В сценарий просмотра могут входить ресурсы всего мира, доступ к которым происходит по протоколу работы с гипертекстом HTTP (Hyper Text Transfer Protocol).
Благодаря удобному интерфейсу программ-броузеров работа в Web не представляет особых трудностей даже для непрофессионалов пользователей.
Наиболее распространенными программами – клиентами (броузерами) WWW являются Netscape Navigator, Internet Explorer и Lynx.
Lynx – полноэкранный интерфейс доступа к WWW с алфавитно-цифровых устройств типа vt100. Интерфейс поддерживает все возможности языка HTML 2.0, за исключением графики.
Netscape Navigator, Internet Explorer – близкие по своим возможностям многопротокольные графические интерфейсы доступа к WWW и другим ресурсам Сети и интерпретирующие язык HTML 3.2, и поддерживающие средства работы с объектами гипермедиа.
WWW работает по принципу «клиент-сервер», точнее «клиент-серверы»: существует множество серверов, которые по запросу клиента возвращают ему гипермедийный документ со ссылками. Ссылки эти в документах WWW организованы таким образом, что каждый информационный ресурс в глобальной Сети однозначно адресуется (URL-адреса). Пользователь работает с информационным пространством Интернет как с единым целым. Причем ссылки WWW указывают не только на документы, специфичные для самой WWW, но и на прочие сервисы и информационные ресурсы Интернет. Более того, большинство программ-клиентов WWW не просто понимают эти ссылки, но и являются программами-клиентами соответствующих сервисов: ftp, gopher, Usenet, электронной почты и т.д. Таким образом, программные средства службы WWW являются универсальными для различных сервисов Интернет.
Организация информации на сайтах.
Диапазон способов организации информации на сайтах весьма широк – от сайтов, имеющих строгую линейную структуру до сайтов, у которых вообще нет четкой структуры. Обычно страницы на сайте располагаются в иерархическом или линейном порядке, а также в виде паутины.
Иерархическая организация. Сайты, которые следуют иерархической или древовидной организации, имеют единственную точку входа в сайт, остальные страницы располагаются на исходящих из нее ответвлениях. Данный подход удобен, если информация легко разбивается на категории и подкатегории. При иерархической организации сайта (рис.5) к странице самого нижнего уровня ведет один и только один путь.
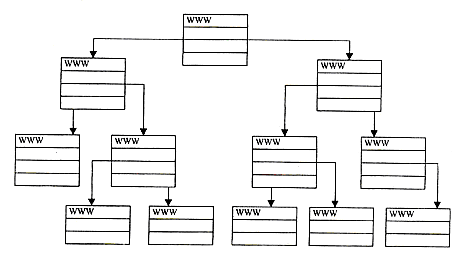
Рис.5
Такая структура может вызвать проблемы у пользователей. Например, если пользователь прошел на несколько уровней вниз по одному из путей, а потом решил попасть в другую часть дерева, то ему придется возвращаться обратно.
Линейная организация. Если необходимо, чтобы пользователи читали содержимое сайта как книгу или журнал, или чтобы они прошли по заданному пути от начала и до конца сайта, выбирается линейная структура (рис.6).
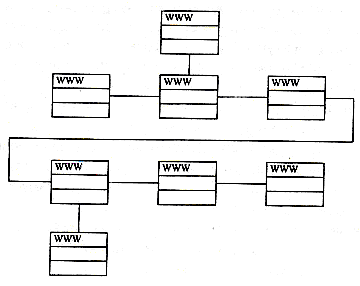
Рис.6
Какая-то страница может иметь несколько связей с примечаниями и дополнениями, но для продвижения дальше пользователь должен вернуться на нее снова. Продвижение по документу осуществляется кнопкой Next, а возврат к началу сайта – кнопкой Prev. Для большого сайта линейная организация не очень подходит. Читателям, ищущим конкретную информацию, может не понравиться необходимость пройти через множество страниц, прежде чем они попадут на нужную.
Организация в виде паутины. Эта организация наилучшим образом подходит для большинства случаев (рис.7)
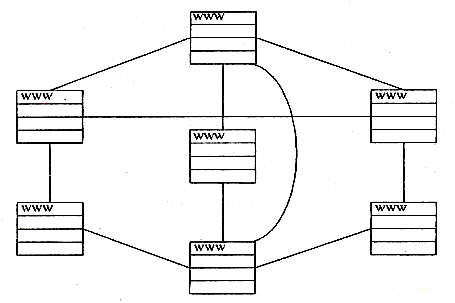
Рис.7
В этой структуре страницы связаны друг с другом общим контекстом. К одной странице может вести несколько связей, и у каждого документа есть по крайней мере два входа. Связи иногда образуют круг. Для просмотра Web эта организация сайта наиболее удобна. Быстрый проход по сайту и большая свобода перемещения. Недостаток такой структуры в том, что пользователь может что-нибудь пропустить, не пройдя по всем связям.
Стратегия поиска информации в Сети
Как разыскать в Сети необходимую информацию в условиях, когда ее поток непрерывно и до определенной степени бесконтрольно возрастает. Наиболее убедительной попыткой обуздать информационный хаос в Интернет является культивирование поисковых машин самого широкого профиля. В их функции входит автоматическое или полуавтоматическое сканирование (просмотр) узлов Сети, сопровождающееся индексированием (созданием баз данных) и классификацией их ресурсов (построением каталогов, структурированных по различным критериям) с возможностью последующего обслуживания поисковых запросов клиентов. Общий вид функциональной цепочки обобщенной поисковой машины, таким образом, следующий:
Сканирование индексирование классификация обслуживание
Сканирование. В процессе сканирования ресурсов Сети принимают участие специальные программы, в WWW их часто называют «паучками». Работа таких программ обычно происходит в автоматическом режиме и состоит в последовательном обходе узлов Сети на основе заданного алгоритма, который может отдавать предпочтения тем или иным узлам как на основе их географической или профильной принадлежности, так и частоты изменения находящихся на них ресурсов. Важной характеристикой машины является число уже отсканированных узлов и скорость работы сканирующих программ.
Индексирование предполагает формирование базы данных поисковой машины, организованной по определенным принципам. В первую очередь предметом сканирования являются текстовые документы. В результате такой операции для каждого документа формируется набор ключевых слов, по которым затем на стадии обслуживания поискового запроса пользователю выдаются адреса заинтересованных ресурсов.
Классификация ресурсов является дополнительной функцией поисковой машины, которая предполагает, например, присвоение при индексировании пометки о принадлежности данного информационного объекта к определенному типу.
Обслуживание пользователя той или иной поисковой машиной строится на разработке информационно-поискового языка, естественным образом связанного со структурой базы данных. Типичными являются два основных подхода: пользователю предоставляется возможность вести поиск интересующей его информации либо путем осмысленного на каждом шаге перемещения по дереву иерархического каталога, уже построенного системой, либо путем реализации собственного поискового запроса в рамках поддерживаемого системой поискового языка.
В процессе сканирования поисковой машине приходится получать доступ к ресурсам Сети, естественно, что такой доступ реализуется в рамках одного из протоколов прикладного уровня. В связи с этим принято различать поисковые машины по области сканирования, прежде всего это- гипертекстовые базы данных Web, ресурсы всемирного пространства GopherSpace, FTP-архивы.
В мире Интернет технологии WWW произвели революцию, следствием стали следующие факторы:
Неуклонное нарастание числа серверов в Сети, реализующих http-протокол;
Перенесение наиболее востребованных ресурсов на Web-сайты с серверов, поддерживающих другие протоколы доступа;
Разработка системы межпротокольных шлюзов WWW-Gopher, WWW-FTP, WWW-Telnet/
Существование шлюзов между протоколами прикладного уровня позволяет, например, поисковой машине WWW сканировать ресурсы FTP-архивов, темнее менее инфраструктуры межпротокольных шлюзов оказывается явно недостаточно для формирования однородного информационного пространства. В результате для исчерпывающего профессионального поиска информации в Сети следует прибегать к специальным поисковым средствам, характерным для среды того или иного протокола, а не ограничиваться наиболее развитыми сегодня средствами поисковых машин WWW, полагаясь на полноту охвата остальной части Интернет благодаря шлюзам. Профессионально подготовленный пользователь, располагающий полным арсеналом поисковых средств и пониманием логики размещения и именования различных информационных объектов Сети, в состоянии обнаружить заданный ресурс, если тот существует реально, за конечное число итераций поискового процесса.
Список документов, полученных в результате отклика на пользовательский запрос, сводящийся, например, к указанию единственного ключевого слова для поиска совпадений с ним в пространстве WWW-страниц, может содержать в себе тысячи пунктов. Даже в этой ситуации результат может иметь практическое значение, если отображаемый список представляет документы в порядке убывания их предполагаемой значимости для пользователя. Такое упорядочивание списка, или ранжирование документов по релевантности (реальной пригодности), не является тривиальным и реализуется каждой поисковой машиной в рамках своего алгоритма.
Поисковые машины WWW
На сегодня в Интернет доступно значительное число поисковых машин, среди которых такие, как Lycos, WebCrawler, Yahoo, Open Text Index, Alta Vista и др. Ссылки на адреса большинства из них присутствуют на специальной поисковой страничке компании Netscape Communication: ссылка скрыта .
Поисковая машина Alta Vista.
Это наиболее полная реализация возможностей Интернет. Некоммерческая поисковая машина свободного доступа Alta Vista (AV) ( ссылка скрыта ) поддерживается в Сети корпорацией Digital Equipment Corporation. Этой поисковой машине на сегодня принадлежит абсолютная пальма первенства по числу заиндексированных ресурсов Web Кроме того, благодаря наличию межпротокольных шлюзов машина располагает адресами ресурсов, доступных по протоколам, отличным от HTTP. Высокая скорость сканирования Паутины AV позволяет предположить, что в ближайшие годы ее индексная база данных будет покрывать подавляющее количество открытых для свободного доступа узлов WWW. Индекс поисковой машины обновляется ежедневно с помощью специальной программы Scooter, причем частота посещения отдельного узла Сети зависит от частоты изменения информации на нем. На текущий момент AV дает доступ к 30 миллионам WWW-страниц, расположенных на более чем 275 600 серверам и к 4 миллионам статей из 16 000 телеконференций Usenet.
В процессе поиска AV реализует алгоритм ранжирования, согласно которому каждому документу, содержащему совпадение по заданному термину, присваивается ранг, определяющий порядковый номер документа в списке результатов поиска. Ранг приписывается на основе частоты употребления термина в документе.
AV позволяет организовать поиск в Сети, предоставляя поисковые шаблоны простого (Simple Search (SS)) и расширенного (Advanced Search (AS)) запросов.
Русские поисковые машины.
На долю русскоязычных пользователей Интернет выпало суровое испытание - использование нескольких различных кодировок для кириллицы, среди которых koi8-r, Windows cp1251, ISO-8859-x и др.Это влечет за собой ряд неприятных моментов, в лучшем случае таких, как постоянное использование дополнительных операций перекодировки текста в рабочей области броузера, в худшем – просто невозможно получить загруженную страницу в читабельном виде. Microsoft Internet Explorer работал до последнего времени в кодировке Windows, и лишь недавно начал понимать и koi8-r.
Компания Digital Equipment Corporation, поддерживающая в сети одну из наиболее мощных поисковых машин Alta Vista, приготовила приятный сюрприз пользователям Интернет, говорящим по-русски, реализовав версию программы, которая позволяет искать информацию во всех русскоязычных кодировках. Получить к ней доступ можно либо по адресу ссылка скрыта, выбрав из предлагаемого меню страну проживания и язык, либо же непосредственно ввести URL в виде ссылка скрыта /
Другой немаловажный аспект, зачастую сводящий на нет эффективность поиска документов, набранных в кириллице, по ключевым словам состоит в том, что морфология русского языка (прежде всего многообразие падежных форм) не дает правильного числа совпадений с терминами в документе, если грамматическая форма термина в поисковом запросе и в документе отличаются. В этом смысле несомненный интерес представляет разработка поисковых систем, учитывающих морфологию русского языка, таких, как программные продукты на основе ядра Яndex компании Comp Tek International. Яndex включает модули морфологического анализа и синтеза, индексации и поиска, а также набор вспомогательных модулей, таких, как анализатор документов, языки разметки и др. Алгоритмы морфологического анализа и синтеза, основанные на базовом словаре, умеют нормализовать слова, т.е. находить их начальную форму, а также строить гипотезы для слов, не содержащихся в базовом словаре.
Поисковая система Yandex (Яndex) компании Comp Tek International реализована на базе данных сервера Издательского дома «Открытые системы» (sp.ru), причем поисковый язык является достаточно развитым.
В последнее время растет популярность достаточно мощной и быстрой поисковой машины Rambler (ссылка скрыта) , поддерживаемой в сети компанией Stack Ltd. (г. Пущино), которая предоставляет возможность поиска как в Web, так и в системе телеконференций при распознавании всех кодировок кириллицы.