
4. Применение систем управления базами данных (субд) в современных системах обработки информации > 1
| Вид материала | Документы |
- И. А. Защита информации в субд. Лекция, 137.23kb.
- Тенденции в мире систем управления базами данных, 225.58kb.
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Проектный практикум, 61.84kb.
- Лекция 2 Базы данных, 241.25kb.
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
- Рабочая программа По дисциплине «Базы данных» По специальности 230102. 65 Автоматизированные, 204.1kb.
- Понятия о базах данных и системах управления ими. Классификация баз данных. Основные, 222.31kb.
- Система управления базами данных это комплекс программных и языковых средств, необходимых, 150.5kb.
- Базовая учебная программа дисциплины «системы управления базами данных» для студентов, 80.99kb.
| | Тема 4. Применение систем управления базами данных (СУБД) в современных системах обработки информации |
| 1. | Введение. |
| 2. | Первый учебный вопрос: Основы построения баз данных. Реляционная база данных |
| 3. | Второй учебный вопрос: Порядок проектирования реляционной базы данных |
| 5. | Заключение. |
ВВЕДЕНИЕ
Сегодня необходимым условием эффективного функционирования управленческой структуры любого уровня является наличие действующей информационной системы, на которую возложены функции автоматизированного сбора, обработки и манипулирования данными и которая включает в себя технические средства обработки данных, программное обеспечение и обслуживающий персонал.
Во многих источниках понятие «информационная система» раскрывается по разному (Слайд 1). Одно из них – это взаимосвязанная совокупность средств, методов и персонала, используемых для сбора, хранения, обработки, поиска и выдачи информации в интересах достижения поставленной цели. Можно предложить и такой вариант. Информационная система – организационно упорядоченная совокупность документов (массивов документов) и информационных технологий, в том числе с использованием средств вычислительной техники и связи, реализующих информационные процессы.
Понятие «информационная система» неразрывно связано с понятиями «информационная технология» и «информационный процесс». Под информационными технологиями (Слайд 2) понимается совокупность методов, производственных процессов и программно – технических средств, объединенных в технологическую цепочку, обеспечивающую сбор, обработку, хранение, распространение и отображение информации с целью снижения трудоемкости процессов использования информационного ресурса, а также повышения их надежности и оперативности. Информационные процессы – это процессы сбора, обработки, накопления, хранения, поиска и распространения информации.
Таким образом, для того, чтобы реализовать информационный процесс, современная информационная система (Слайд 3) включает в свой состав вычислительную систему, одну или несколько баз данных (БД), систему управления базами данных (СУБД) и набор прикладных программ (ПП). Основными функциями ИС являются:
• хранение данных и их защита;
• изменение (обновление, добавление и удаление) хранимых данных;
• поиск и отбор данных по запросам пользователей;
• обработка данных и вывод результатов.
1. Основы построения баз данных.
Реляционная база данных. (Слайд 4)
Современные авторы часто употребляют термины «банк данных» и «база данных» как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных Государственного комитета по науке и технике (ГКНТ), изданных в 1982 г., эти понятия различаются. Там приводятся следующие определения банка данных, базы данных и СУБД:
Банк данных (БнД) – это система специальным образом организованных данных – баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных (БД) – именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
В качестве примеров простейших БД можно назвать телефонный справочник, расписание движения поездов, сведения о сотрудниках учреждения, список цен на товары, алфавитный или предметный каталоги книг в библиотеке, словарь иностранных слов, результаты сдачи сессии слушателями, каталог учебных видеозаписей и т.п.
Главное достоинство БД (Слайд 5) – это возможность быстрого поиска и отбора информации, а также простая генерация (создание) отчета по заданной форме. Например, по номерам зачеток легко определить фамилии курсантов или по фамилии автора составить список его трудов.
Пользователей баз данных можно разделить на три категории: конечные пользователи (те, кто вводят, извлекают и используют данные), программисты и системные аналитики (те, кто пишут прикладные программы разработки данных, определяют логическую структуру БД) и администраторы.
Администратор базы данных – это лицо, отвечающее за выработку требований к базе данных во время ее проектирования, реализацию БД в процесce создания, эффективное использование и сопровождение БД в процессе эксплуатации.
Администратор взаимодействует с конечными пользователями и программистами в процессе проектирования БД, контролирует ее работоспособность, отвечает за реорганизацию и своевременное обновление информации, удаление устаревших данных и за восстановление разрушенных данных, за обеспечение безопасности и целостности данных.
Программисты и системные аналитики, создавая БД, стремятся упорядочить информацию по различным признакам (атрибутам), для того чтобы можно было извлекать из БД информацию с произвольным сочетанием признаков.
В современной технологии использования баз данных предполагается, что создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляется с помощью специального программного обеспечения – систем управления базами данных.
Система управления базами данных (Слайд 6) представляет собой пакет прикладных программ и совокупность языковых средств, предназначенных для создания, сопровождения и использования баз данных.
СУБД позволяют вводить, отбирать и редактировать данные. СУБД предоставляют средства для извлечения данных по определенному критерию (требованию, правилу). СУБД дают возможность конечным пользователям осуществлять непосредственное управление данными, а программистам и системным аналитикам быстро разрабатывать более совершенные программные средства их обработки (приложения). Связь программ и данных при использовании СУБД показана на рис.1 (Слайд 7)
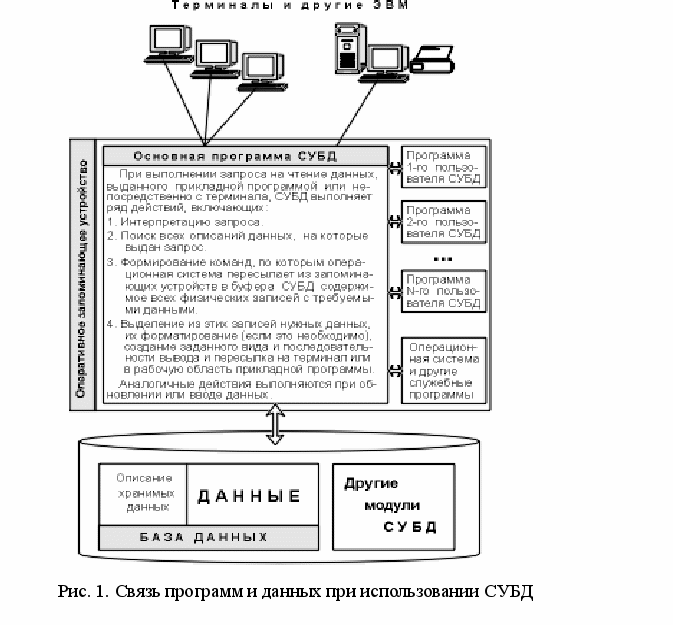
Основная особенность СУБД – это наличие процедур для ввода и хранения не только самих данных, но и описаний их структуры в соответствии с некоторой моделью, поддерживаемой СУБД. К числу важнейших относятся следующие модели структур данных:
• иерархическая;
• сетевая;
• реляционная.
В иерархической модели (Слайд 8) данные представляются в виде древовидной (иерархической) структуры. Простота организации, наличие заранее заданных связей между сущностями (различными объектами), сходство с физическими моделями данных позволяет добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. Но, если данные со сложными логическими связями или не имеют древовидной структуры, то возникает масса сложностей при построении модели, а физическая реализация сложна и громоздка.
Сетевая модель означает представление данных в виде произвольного графа. Это достаточно сложные структуры, состоящие из «наборов» поименованных двухуровневых деревьев. «Наборы» соединяются с помощью «записей-связок», образуя цепочки и т.д. При разработке сетевых моделей было выдумано множество «маленьких хитростей», позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п. Данной модели присущи высокая сложность и жесткость схемы базы данных.
Реляционную модель данных (Слайд 9) рассмотрим более подробно. Свое название она получила от английского термина relation – отношение. Ее предложил в 70-е годы сотрудник фирмы IBM Эдгар Кодд. При соблюдении определенных условий отношение представляется в виде двумерной таблицы, привычной для человека. Большинство современных СУБД для персональных ЭВМ являются реляционными.
Достоинствами реляционной модели данных являются ее простота, удобство реализации на ЭВМ, наличие теоретического обоснования и возможность формирования гибкой схемы БД, допускающей настройку при формировании запросов.
Реляционная модель данных используется в основном в БД среднего размера. При увеличении числа таблиц в базе данных заметно падает скорость работы с ней. Определенные проблемы использования РМД возникают при создании систем со сложными структурами данных.
При выполнении основных из этих функций СУБД должна использовать различные описания данных. А как создавать эти описания?
Естественно, что проект базы данных надо начинать с анализа предметной области и выявления требований к ней отдельных пользователей (сотрудников организации, для которых создается база данных). Подробнее этот процесс будет рассмотрен ниже, а здесь отметим, что проектирование обычно поручается человеку (группе лиц) – администратору базы данных (АБД).
Объединяя частные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут потребоваться в будущих приложениях, АБД сначала создает обобщенное неформальное описание создаваемой базы данных. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных, называют инфологической моделью данных (рис. 2) – Слайд.

Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов этой средой может быть память человека, а не ЭВМ. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Остальные модели, показанные на рисунке, являются компьютеро-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, создаваемое администратором базы данных по инфологической модели данных, называют даталогической моделью данных.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. АБД может при необходимости переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся «прозрачными» для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений.
Как уже указывалось, разработка любой базы данных начинается с инфологического моделирования, т.е. путем естественного для человека способом сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить по аналогии с естественным языком (последний не может быть использован в чистом виде из-за сложности компьютерной обработки текстов и неоднозначности любого естественного языка), но с введением некоторых конструктивных элементов. Основные из этих элементов показаны на рис.3 – Слайд.

Рассмотрим их.
Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, ЦВЕТ может быть определен для многих сущностей: СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности АВТОМОБИЛЬ являются ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута ЦВЕТ имеет много экземпляров или значений: Красный, Синий, Банановый, Белая ночь и т.д., однако каждому экземпляру сущности присваивается только одно значение атрибута.
Отношение (таблица) – это множество несовпадающих элементов (значений атрибутов сущности), представленное в виде двумерной таблицы. Наименьшая единица данных в отношении – это отдельное атомарное (неразложимое) для реляционной модели значение данных. Так, в одной предметной области фамилия, имя и отчество могут рассматриваться как единое значение, а в другой – как три различных значения.
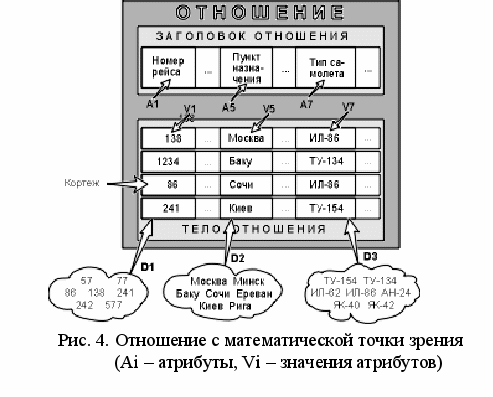
Доменом (поле, столбец) называется множество атомарных значений одного и того же типа. На рис. 4 (Слайд) домен пунктов отправления (назначения) – множество названий населенных пунктов, а домен номеров рейса – множество целых положительных чисел. Смысл доменов состоит в том, что имеется возможность сравнения или выполнения каких либо арифметических (логических) действий над значениями атрибутов одного или нескольких доменов одинакового типа. Например, для организации транзитного рейса можно дать запрос «Выдать рейсы, в которых время вылета из Москвы в Сочи больше времени прибытия из Архангельска в Москву»). Если же значения двух атрибутов берутся из доменов различных типов, то их сравнение, вероятно, лишено смысла: стоит ли сравнивать номер рейса со стоимостью билета?
Отношение состоит из заголовка и тела.
Заголовок состоит из такого фиксированного множества атрибутов A1, A2, ..., An, что существует взаимно однозначное соответствие между этими атрибутами Ai и определяющими их доменами Di (i=1,2,...,n).
Тело состоит из меняющегося во времени множества кортежей (запись, строка), где каждый кортеж состоит в свою очередь из множества пар атрибут-значение (Ai:Vi), (i=1,2,...,n), по одной такой паре для каждого атрибута Ai в заголовке. Для любой заданной пары атрибут-значение (Ai:Vi) Vi является значением из единственного домена Di, который связан с атрибутом Ai.
Степень отношения – это число его атрибутов. Отношение степени один называют унарным, степени два – бинарным, степени три – тернарным, ..., а степени n – n-арным.
Кардинальное число или мощность отношения – это число его кортежей. Кардинальное число отношения изменяется во времени в отличие от его степени.
Поскольку отношение – это множество, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно-заданный момент времени. Для поиска необходимого кортежа используется ключ.
На отношение налагаются определенные условия и ограничения, выполнение которых позволяет таблицу считать отношением:
1. Каждая таблица состоит из однотипных строк и имеет уникальное имя.
2. Строки имеют фиксированное число полей (столбцов) и значений (множественные поля и повторяющиеся группы недопустимы). Иначе говоря, в каждой позиции таблицы на пересечении строки и столбца всегда имеется в точности одно значение или ничего.
3. Строки таблицы обязательно отличаются друг от друга хотя бы единственным значением, что позволяет однозначно идентифицировать любую строку такой таблицы.
4. Столбцам таблицы однозначно присваиваются имена, и в каждом из них размещаются однородные значения данных (даты, фамилии, целые числа или денежные суммы).
5. Полное информационное содержание базы данных представляется в виде явных значений данных (абсолютных, а не относительных значений, т.е. нет отсылки за явным значением к другой таблице) и такой метод представления является единственным. Не существует каких-либо специальных «связей» или указателей, соединяющих одну таблицу с другой.
6. При выполнении операций с таблицей ее строки и столбцы можно обрабатывать в любом порядке безотносительно к их информационному содержанию. Этому способствует наличие имен таблиц и их столбцов, а также возможность выделения любой их строки или любого набора строк с указанными признаками (например, рейсов с пунктом назначения «Москва» и временем прибытия до 12 часов).
Ключ (возможный ключ)- (Слайд) – это минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся. Не существует двух кортежей (записей, строк), которые бы имели одно и то же значение на всех атрибутах, т.е. ключом отношения называется набор атрибутов отношения, однозначно определяющий кортеж. Или еще проще: ключ – это набор столбцов таблицы, значения которых уникально определяют строку.
Каждая сущность обладает хотя бы одним возможным ключом. Один из них принимается за первичный ключ. При выборе первичного ключа следует отдавать предпочтение несоставным ключам или ключам, составленным из минимального числа атрибутов. Так, для сущности Расписание самолетов ключом является атрибут Номер_рейса или набор: Пункт_отправления, Время_вылета и Пункт_назначения (при условии, что из пункта в пункт вылетает в каждый момент времени один самолет).
Нецелесообразно также использовать ключи с длинными текстовыми значениями (предпочтительнее использовать целочисленные атрибуты). Так, для идентификации слушателя можно использовать либо уникальный номер зачетной книжки, либо набор из фамилии, имени, отчества, номера группы и может быть дополнительных атрибутов, так как не исключено появление в группе двух курсантов с одинаковыми фамилиями, именами и отчествами.
Не допускается, чтобы первичный ключ сущности (любой атрибут, участвующий в первичном ключе) принимал неопределенное значение. Иначе возникнет противоречивая ситуация: появится не обладающий индивидуальностью, и, следовательно не существующий экземпляр сущности. По тем же причинам необходимо обеспечить уникальность первичного ключа.
Для установления связи между отношениями используется понятие внешний ключ.
При появлении трудности определения ключа может вводится суррогатный ключ. К примеру, к суррогатным ключам относятся табельные номера сотрудников, регистрационные номера автомобилей, серийные номера изделий и т.д.
Связь – ассоциирование (объединение) двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Следует отметить, что связывание таблиц базы данных осуществляется только через процедуру определения ключа (Слайд).
Между двумя сущностям, например, А и В возможны четыре вида связей.
Первый тип – связь ОДИН-К-ОДНОМУ (1:1): в каждый момент времени каждому представителю (экземпляру) сущности А соответствует 1 или 0 представителей сущности В. Для другого варианта связи – Офицер Иванов имеет одно воинское звание, например, капитан (Слайд – Рис.5)

.
Второй тип – связь ОДИН-КО-МНОГИМ (1:М): одному представителю сущности А соответствуют 0, 1 или несколько представителей сущности В. Для другого варианта связи – Офицер может состоять в различных званиях: лейтенант, старший лейтенант, капитан и т.д. (Слайд – Рис.6)

Так как между двумя сущностями возможны связи в обоих направлениях, то существует еще два типа связи МНОГИЕ-К-ОДНОМУ (М:1) и МНОГИЕ-КО-МНОГИМ (М:N). Характер связей между сущностями не ограничивается перечисленными. Существуют и более сложные связи.
Завершая рассмотрение основных элементов реляционной модели данных мы должны обратить внимание на сложность структуры отношения. Она заключается в том, что некоторые таблицы могут состоять из ограниченного состава атрибутов (полей) и неограниченного количества кортежей (записей). Поэтому для любой СУБД всегда остается актуальным обеспечение целостности данных.
Целостность (от англ. integrity – нетронутость, неприкосновенность, сохранность, целостность) – понимается как правильность данных в любой момент времени. Но эта цель может быть достигнута лишь в определенных пределах: СУБД не может контролировать правильность каждого отдельного значения, вводимого в базу данных (хотя каждое значение можно проверить на правдоподобность). Например, нельзя обнаружить, что вводимое значение 5 (представляющее номер дня недели) в действительности должно быть равно 3. С другой стороны, значение 9 явно будет ошибочным и СУБД должна его отвергнуть. Однако для этого ей следует сообщить, что номера дней недели должны принадлежать набору (1,2,3,4,5,6,7).
Поддержание целостности базы данных может рассматриваться как защита данных от неверных изменений или разрушений (не путать с незаконными изменениями и разрушениями, являющимися проблемой безопасности). Современные СУБД имеют ряд средств для обеспечения поддержания целостности (так же, как и средств обеспечения поддержания безопасности). Кроме этого разработчики баз данных при их создании должны придерживаться некоторых правил целостности, общих для любых реляционных баз данных (Слайд):
- не допускается, чтобы какой-либо атрибут, участвующий в первичном ключе, принимал неопределенное значение (должен быть задан явно, без относительной ссылки на другой атрибут);
- значение внешнего ключа должно либо быть равным значению первичного ключа связываемого отношения, либо быть полностью неопределенным, т.е. каждое значение атрибута, участвующего во внешнем ключе должно быть неопределенным;
- для любой конкретной базы данных существует ряд дополнительных специфических правил, которые относятся к ней одной и определяются разработчиком. Чаще всего контролируется: уникальность тех или иных атрибутов, диапазон значений (экзаменационная оценка от 2 до 5) и т.д.
Мы рассмотрели основные положения устройства баз данных, которые присущи всем моделям структур. Теперь остановимся на особенностях архитектуры одного из представителя СУБД – Access.
Что такое Microsoft Access? Это система управления реляционными базами данных, предназначенная для работы на автономном ПК или в ЛВС под управлением ОС Windows.
Средствами Access можно производить следующие операции (Слайд).
1. Проектирование базовых объектов информационной системы – двумерных таблиц с разными типами данных.
2. Установление связей между таблицами, с поддержкой целостности данных, обновления и удаления данных.
3. Ввод, хранение, просмотр, сортировка, модификация и выборка данных из таблиц с использованием различных средств контроля информации, индексирования таблиц и аппарата логической алгебры (для фильтрации данных).
4. Создание, модификация и использование производных объектов (форм, запросов и отчетов), с помощью которых в свою очередь выполняются следующие операции:
- оптимизация пользовательского ввода и просмотра данных (формы);
- соединение данных из различных таблиц; проведение групповых операций (т.е. операций над группами записей, объединенных каким-то признаком), с расчетами и формированием вычисляемых полей; отбор данных с применением аппарата логической алгебры (запросы);
- составление печатных отчетов по данным, которые содержатся в таблицах и запросах БД.
Объектом обработки Microsoft Access является файл базы данных, имеющий произвольное имя и расширение .MDB. В этот файл входят основные объекты Microsoft Access (Слайд): таблицы, формы, запросы и отчеты. Кроме того, квалифицированные пользователи могут работать еще с двумя объектами: макросами и модулями. Макрос – это набор специальных макрокоманд (например, ОткрытьФорму, ПечататьОтчет и т.п.), а модуль – это программа, написанная на языке VBA.
Таблица является базовым объектом Microsoft Access: мы проектируем таблицу каждый раз при создании новых баз данных. О порядке проектирования будет сказано ниже. Все остальные объекты являются производными и создаются только на базе ранее подготовленных таблиц.
Каждый объект Access имеет имя, Длина имени любого объекта – не более 64 произвольных символа.
С каждым объектом работа производится в отдельном окне, причем предусмотрено два режима работы:
1. оперативный режим, когда решаются в окне задачи информационной системы, т.е. просмотр, изменение, выбор информации;
2. режим конструктора, – когда создается или изменяется макет, структура объекта (например, структуру таблицы).
Кроме этого, в файл базы данных входит еще один документ, имеющий собственное окно: Схема данных. В этом окне мы создаем, просматриваем, изменяем и разрываем связи между таблицами. Эти связи помогают контролировать данные, создавать запросы и отчеты.
Структура таблицы и типы данных. Все составляющие базы данных (таблицы, отчеты, запросы и формы) хранятся в едином дисковом файле, а ее основным структурным компонентом является таблица, в которой хранятся вводимые данные. Таблица состоит из столбцов, называемых полями, и строк, называемых записями. Каждая запись таблицы содержит всю необходимую информацию об отдельном элементе сущности, т.е. объекта базы данных.
В Access используется три способа создания таблицы: путем ввода данных, с помощью Мастера создания таблиц и с помощью Конструктора таблиц. Для каждого из этих способов существует специальный ярлык новых объектов в списке таблиц. Первый из этих способов используется тогда, когда имеются затруднения в определении структуры таблицы. В данном режиме пользователь заполняет пустую таблицу со стандартными названиями столбцов: Поле1, Поле2 и т.д. С помощью Мастера создания таблиц за несколько шагов можно создать макет базы данных, приблизительно соответствующий нашему замыслу. Данный режим рекомендуется использовать при создании форм и отчетов.
В режиме Конструктора (Слайд) таблицы создаются путем задания имен полей, их типов и свойств. Здесь необходимо прежде всего определить названия полей, из которых она должна состоять, типы полей и их размеры. Каждому полю таблицы присваивается уникальное имя, которое не может содержать более 64 символов. Каждому полю присваивается один из типов данных (Слайд – Рис.7):
- текстовый – текст или числа, не требующие расчетов (до 255 знаков);
- числовой – числовые данные различных форматов, используемые для проведения расчетов четов;
- дата/время – хранение информации о дате и времени;
- денежный – денежные значения и числовые данные, используемые в расчетах;
- поле МЕМО – хранение комментариев (до 65 535 символов);
- счетчик – специальное числовое поле, в котором автоматически присваивается уникальный порядковый номер каждой записи (значения поля обновлять нельзя);
- логический – может иметь только одно из двух возможных значений (True/False);
- поле объекта OLE – объект, связанный или внедренный в таблицу Access.
Рис.7 Структура типов данных
В тоже время, для каждого типа данных следует установить соответствующие значения свойств. Перечень свойств меняется, в зависимости от типа данных. В лекции невозможно описать все свойства и их допустимые значения. Большинство значений принимается системой по умолчанию, многие свойства можно изучить самостоятельно. Некоторые значения можно выбрать из раскрывающегося списка.
Поэтому, без особых комментариев приведу лишь принципиально важные рекомендации, которым целесообразно следовать при выборе значения свойства.
Для текстового и числового поля надо указать размер поля, причем для текста – это допустимая длина значения (например, 20 или 40 символов), а для числа – формат представления в машине (байт, целое (два байта), длинное целое и т.д.).
Для поля «Дата/время» обязательно надо указать формат, чтобы система знала, как обрабатывать вводимые данные. Например, если выбрать «Краткий формат даты», система будет ожидать от вас ввода именно даты (в русской версии – ДД.ММ.ГГГГ), а если выбрать «Краткий формат времени», в этом поле придется набирать ЧЧ:ММ (часы и минуты).
В качестве значения свойства «Условие на значение» надо указать правила верификации, т.е. логическое выражение, которое должно принимать значение TRUE («Истина») при вводе данных в это поле. Например, если для поля ОЦЕНКА таблицы Успеваемость записать [ОЦЕНКА]>=1 And [ОЦЕНКА]<=5 (или еще проще: >=1 And <=5), система признает ошибочным ввод в это поле любого значения, кроме 1-5.
В следующем свойстве можно записать произвольное сообщение об ошибке, которое будет выдано системой, например: «Значение оценки недопустимо».
В свойстве «Обязательное поле» можно указать «Да» (пустые значения не допускаются) или «Нет» (пустые значения допускаются.
И последняя рекомендация. Если в первичный ключ таблицы входит одно поле, в свойстве «Индексированное поле» для него надо выбрать: «Да, совпадения не допускаются», а затем щелкнуть в панели инструментов на кнопке «Определить ключ». Тем самым будет определен первичный ключ таблицы и в дальнейшем будет запрещен ввод записей с повторяющимся значением первичного ключа.
2. Порядок проектирования реляционной базы данных
Проектирование информационных систем, включающих в себя базы данных, осуществляется на физическом и логическом уровнях. Проектирование на физическом уровне зависит от используемой СУБД, сегодня автоматизировано и скрыто от пользователя. В ряде случаев пользователю предоставляется возможность настройки отдельных параметров системы.
Логическое проектирование в основном определяется спецификой задач предметной области и заключается в определении числа, структуры и связи таблиц, формировании запросов к БД, определении типов отчетных документов, разработке алгоритмов обработки информации, создании форм для ввода и редактирования данных в базе и решении ряда аналогичных задач.
При проектировании структур данных для автоматизированных систем можно следовать одним из двух основных подходов.
1. Формирование информации об объектах в одной таблице (в одном отношении) с последующей декомпозиции ее на несколько взаимосвязанных таблиц на основе процедуры нормализации отношений. Это классический и исторически первый подход.
2. Формулирование информации о системе и требований к обработке данных, получение с помощью CASE-средств (CASE-средство – автоматизированная разработка программного обеспечения – среда разработки программного обеспечения, ориентированная на автоматизацию всех стадий разработки программы, начиная с планирования и моделирования и кончая кодированием и документированием. Среда CASE состоит из программ и др. инструментальных средств разработки, позволяющих администраторам, системным аналитикам, программистам и проч. автоматизировать процесс составления и внедрения программ и процедур в компьютерные системы делового, инженерного и научного характера) готовой схемы БД или даже готовой прикладной информационной системы. Это современный подход и здесь не обойтись без современного программного обеспечения.
С технической точки зрения процесс непосредственной разработки информационной системы обычно включает следующие этапы:
создание БД (формирование и связывание таблиц, ввод данных);
создание меню приложения;
создание запросов;
создание экранных форм, отчетов;
генерация приложения как исполняемой программы.
Приведенный перечень является примерным и определяется требованиями к создаваемой ИС. Этот процесс, как правило, носит итерационный характер. Более подробно мы остановимся на первом подходе.
Как указывалось ранее, реляционная модель данных представляется в виде двумерных таблиц, с помощью которых осуществляется описание всех реальных объектов через соответствующие атрибуты. Начальное представление данных конкретного объекта в форме таблицы называется формирование исходного отношения.
Дальнейшее изложение материала о порядке проектирования базы данных построим на примере создания базы данных о преподавателях военного учебного заведения.
Предположим, что для учебной части факультета создается БзД о преподавателях. На первом этапе проектирования БзД в результате общения с заказчиком («заведующим учебной частью) должны быть определены содержащиеся в базе сведения о том, как она должна использоваться и какую информацию заказчик хочет получать в процессе ее эксплуатации. В результате устанавливаются атрибуты, которые должны содержаться в отношениях БзД, и связи между ними. Перечислим возможные имена атрибутов исходного отношения и их краткие характеристики (Слайд – Рис.8):
ФИО – фамилия и инициалы сотрудника (Возможность совпадения фамилии и инициалов исключена).
Должн – должность, занимаемая преподавателем.
Оклад – оклад преподавателя.
Стаж – преподавательский стаж
И т.д.
Здесь необходимо отметить, что хранение данных в реляционных базах данных преследует две цели: понизить избыточность данных и повысить их достоверность. Для этого необходимо иметь возможность накладывать некоторые ограничения как на сами хранимые данные, так и на взаимосвязи и взаимозависимости между ними, т.к. в противном случае вместо базы данных мы получим просто свалку, лишенную всякой структуры. Одним из средств формализации информации является зависимость между данными – функциональная зависимость (ФЗ), или F-зависимость. Из указанного выше примера можно сделать ряд выводов:
- {Должн и Стаж} функционально зависят от {ФИО}.
- {Надбавка за выслугу} функционально зависит от {стаж}.
- {Группа} функционально зависит от {ФИО, Предм, ВидЗан}.
- {Оклад} функционально зависят от {Должность}.
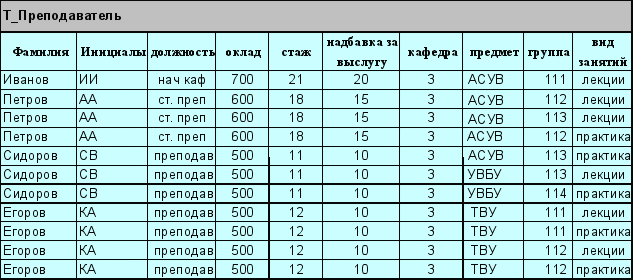
Рис.8 Пример исходного отношения ПРЕПОДАВАТЕЛЬ
Итак, если значения кортежа на некотором множестве атрибутов единственным образом определяют значения на другом множестве атрибутов, говорят, что имеет место функциональная зависимость или, короче, F-зависимость.
Приведенная функциональная зависимость может зачастую содержать избыточность данных, которая является причиной аномалий редактирования БзД. Аномалии в первую очередь заключаются в потери достоверности и проявлении противоречивости хранимых данных. Различают избыточность явную и неявную (Слайд).
Явная избыточность в исходном отношении состоит в том, что строки с данными о преподавателях, проводящих занятия в нескольких группах, повторяются.
Неявная избыточность в исходном отношении проявляется в одинаковых окладах у всех преподавателей, в одинаковых добавках к окладу за одинаковый стаж.
Решение рассмотренной проблемы, т.е. исключение избыточного дублирования, может быть найдено в декомпозиции исходного отношения на два и более отношений. На Слайде 24 (рис. 9) показаны некоторые особенности избавления от избыточности данных методом декомпозиции.
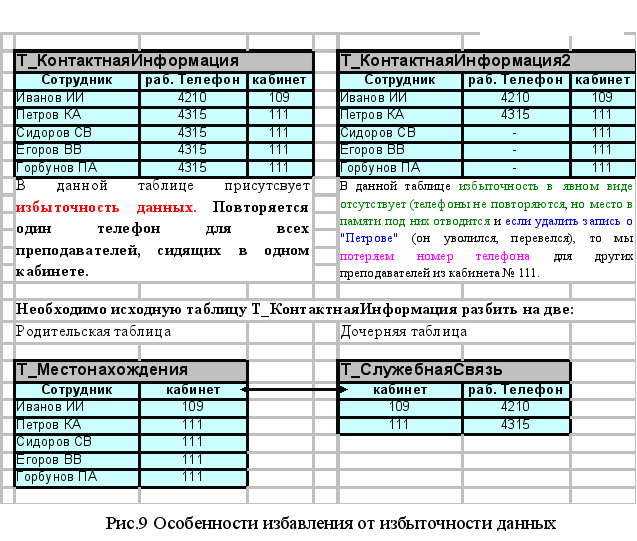
Используя указанные методы избавления избыточности данных в исходной таблице предыдущего примера получим 3 таблицы: одна Родительская – Т_Преподаватель и две дочерние: Т_ОкладыПоДолжностям и Т_НадбавкиЗаВыслугу (Слайд). Важным здесь является то, чтобы каждому экземпляру сущности (базы данных), представленному в отношении (в таблице), соответствует только один его кортеж (запись), т.е. этим обеспечивается целостность сущностей. Связывание этих таблиц осуществляются через ключевые поля дочерних таблиц: должность и стаж. При этом, для каждого значения внешнего ключа родительской таблицы должна найтись строка в дочерней таблице с таким же значением первичного ключа, этим будет обеспечена целостность ссылок.
Средством исключения указанных проблем в отношениях, кроме рассмотренного выше метода декомпозиции, является процесс нормализации отношений. Он, как правило, сопутствует процессу разработки исходного отношения.
Под нормализацией отношения подразумевается процесс приведения отношения к одной из так называемых нормальных форм (НФ). Однако перед рассмотрением НФ следует сказать несколько слов, зачем нужна нормализация (Слайд).
База данных – это не просто хранилище фактов. При проектировании баз данных упор в первую очередь делается на достоверность и непротиворечивость хранимых данных, причем эти свойства не должны утрачиваться в процессе работы с данными, т.е. после многочисленных изменений, удалений и дополнений данных по отношению к первоначальному состоянию БзД. Это возможно сделать путем устранения избыточности и дублирования информации. Поэтому, главная цель нормализации базы данных – это устранение (или, по крайней мере, серьезное сокращение) избыточности и дублирования данных. Как следствие этого, в дальнейшем значительно сокращается вероятность появления противоречивых данных, облегчается администрирование базы и обновление информации в ней, сокращается объем дискового пространства.
В идеале при нормализации надо добиться, чтобы любое значение хранилось в базе в одном экземпляре, причем значение это не должно быть получено расчетным путем из других данных, хранящихся в базе.
Для поддержания БзД в устойчивом состоянии используется ряд механизмов, которые получили обобщенное название средств поддержки целостности. Эти механизмы применяются как статически (на этапе проектирования БзД), так и динамически (в процессе работы с БзД). Приведение структуры БзД в соответствие этим ограничениям – это и есть нормализация.
В целом суть этих ограничений весьма проста: каждый факт, хранимый в БзД, должен храниться один-единственный раз, поскольку дублирование может привести (и на практике непременно приводит, как только проект приобретает реальную сложность) к несогласованности между копиями одной и той же информации. Следует избегать любых неоднозначностей, а также избыточности хранимой информации. С этими требованиями трудно не согласиться и выглядят они вполне разумно.
В процессе нормализации постоянно встречается ситуация, когда отношение приходится разложить на несколько других отношений. Поэтому более корректно было бы говорить о нормализации не отдельных отношений, а всей их совокупности, т.е. БзД в целом.
Нормализация может не представлять такую уж проблему, если БзД проектируется сразу по определенным канонам. Другими словами, можно сначала сделать БзД как попало, а потом нормализовать ее, или же с самого начала строить ее по правилам, чтобы в дальнейшем не пришлось переделывать.
И так, приступаем к процессу нормализации нашего исходного отношения ПРЕПОДАВАТЕЛЬ (Слайд), или скажем по-другому, к проектированию БзД методом нормальных форм.
На первом этапе мы должны выявить зависимости между атрибутами исходного отношения Обратим внимание, что, после того, как выделены все функциональные зависимости, следует проверить их согласованность с данными исходного отношения, в нашем примере, (Слайд – рис.10).
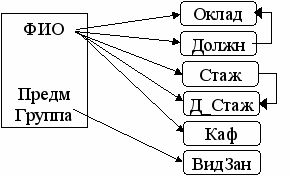
Рис.10. Пример выделения функциональной зависимости
Второй и следующие этапы представляют собой непосредственно процесс нормализации. Он заключается в последовательном преобразовании исходного отношения к НФ, при этом каждая следующая НФ обязательно включает в себя предыдущую (что, собственно, и позволяет разбить процесс на этапы и производить его однократно, не возвращаясь к предыдущим этапам). Или по другому, каждая следующая нормальная форма, сохраняя свойства предшествующих нормальных форм, ограничивает определенный тип функциональных зависимостей и устраняет соответствующие аномалии при выполнении операций над отношениями БзД.
Всего в реляционной теории насчитывается 6 НФ. Рассмотрим некоторые из них.
• Первая нормальная форма (1НФ). Отношение находится в 1 НФ, (Слайд) если все его атрибуты являются простыми (имеют единственное значение). Другими словами, каждый атрибут отношения должен хранить одно-единственное значение и не являться ни списком, ни множеством значений.
Исходное отношение строится таким образом, чтобы оно было в 1 НФ.
Следует заметить, что однозначно определить понятие атомарности зачастую оказывается довольно затруднительно, если заранее неизвестны семантика атрибута и его роль в обработке хранимых данных. Атрибут, который является атомарным в одном приложении, может оказаться составным в другом.
Простейший пример: в БД отдела кадров учебного заведения в таблице, хранящей личные сведения о преподавателях, имеется атрибут «домашний-адрес», в котором адрес хранится в формате: город, улица, дом, квартира. В данном случае адрес хранится в виде единой текстовой строки, поскольку маловероятно, чтобы потребовалось выбрать сотрудников, скажем, по номеру квартиры. Таким образом, в контексте БД отдела кадров адрес является атомарным понятием, и его деление на составные части не имеет смысла, т.к. только внесет в БД излишнюю громоздкость. Однако тот же адрес для приложения, предназначенного для организации оповещения военнослужащих, атомарным не является, поскольку желательно сгруппировать (карточки оповещения) конверты в отдельные стопки по улицам, так как каждую улицу обслуживает свой посыльный. Кроме того, с целью оптимизации перемещений посыльного в пределах улицы, каждую стопку желательно отсортировать по номерам домов, чтобы сделать возможным оповещение за один проход по улице без возврата.
Приведение отношения к 1НФ – довольно простая операция. Мы должны просмотреть схему отношения и разделить составные атрибуты на различные строки/столбцы. Возможно, эту операцию придется повторить несколько раз до тех пор, пока каждый из атрибутов не станет атомарным.
К примеру, в БзД ПРЕПОДАВАТЕЛЬ (Слайд) значения атрибута ФИО не являются атомарными, поскольку в них содержатся значения и фамилии, и имени, и отчества. Приведенный атрибут ФИО может быть атомарным, если в последующем не потребуется выполнять действия по сортировке или выбору отдельного значения этого атрибута. Но поскольку мы предполагаем выполнять данные действия, то необходимо разделить поле ФИО на три: ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО. Рядом показан другой пример приведения отношения в нормальную форму.
Таким образом, первая нормальная форма:
- запрещает повторяющиеся столбцы (содержащие одинаковую по смыслу информацию)
- запрещает множественные столбцы (содержащие значения типа списка и т.п.)
- требует определить первичный ключ для таблицы, то есть тот столбец или комбинацию столбцов, которые однозначно определяют каждую строку
• Вторая нормальная форма (2НФ). Отношение находится во 2НФ (Слакйд 29).
Повторяющиеся значения, которых немало в предыдущей таблице, являются потенциальным источником проблем.
Во-первых, при вводе их значений легко ошибиться. Например, достаточно изменить всего одну цифру в графе «Группа», и формально это будет уже совершенно другая группа курсантов, не имеющая ничего общего с первой. Найти подобные опечатки в объемной таблице – задача не из простых.
Во-вторых, может измениться название предмета, хоть это происходит и не так часто (тем не менее пренебрегать такой возможностью не стоит). Тогда придется опять же шерстить всю таблицу и изменять соответствующие значения.
В-третьих, нельзя пренебрегать и эффективностью хранения информации. В исходной таблице (Rисх) строки с данными о преподавателях повторяются. В данном примере это мелочи, но на практике встречаются базы пообъемнее. Как нетрудно прикинуть, лишнее поле размером всего-навсего в 10 байт раздует объем файла на порядок и более. Помимо того, что эти гигабайты нужно хранить на диске, при операциях с базой их приходится прокачивать из дисковой памяти в оперативную, а порой и в локальную сеть.
Таким образом, борьба с избыточностью данных выгодна со всех сторон – как со стороны повышения удобства пользования данными и поддержания их в целостном виде, так и со стороны эффективности обработки и хранения данных аппаратными средствами. Именно на устранение этой избыточности и направлена дальнейшая нормализация отношений.
Схема отношения R находится во 2НФ относительно множества функциональных зависимостей F, если она находится в 1НФ и каждый неключевой атрибут полностью зависит от каждого ключа для R. Другими словами, отношение находится во 2НФ, если оно находится в 1НФ, и при этом все неключевые атрибуты зависят только от ключа целиком, а не от какой-то его части (элемента составного ключа).
Следует обратить внимание на факт, который далеко не всегда явно отражен в литературе по базам данных. Поскольку в данном случае речь идет о частичной зависимости атрибутов от ключа, то все вышесказанное относится исключительно к отношениям с составным ключом. Отношение с простым, или атомарным, ключом (состоящим из единственного атрибута), приведенное к 1НФ, находится во 2НФ по определению и в данном этапе нормализации не нуждается
Для исходного отношение Rисх (база данных преподавателей) 2-я нормальная форма получается путем разбиения на отношение R1 и отношение R2 (Слайд – Рис. 11):
В общем случае, вторая нормальная форма требует, чтобы неключевые столбцы таблиц зависили от первичного ключа в целом, но не от его части. Если таблица находится в первой нормальной форме и первичный ключ у нее состоит из одного столбца, то она автоматически находится и во второй нормальной форме.
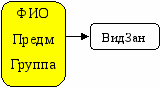 R1 R1 | | | |
| ФИО | Предм | Группа | ВидЗан |
| Иванов_АА | АСУВ | 111 | Лекц |
| Петров_ВВ | АСУВ | 111 | ПЗ |
| Петров_ВВ | АСУВ | 112 | Лекция |
| Петров_ВВ | АСУВ | 112 | ПЗ |
| Сидоров_СВ | УВБУ | 113 | Лекция |
| Сидоров_СВ | УВБУ | 113 | ПЗ |
| Сидоров_СВ | УВБУ | 114 | П 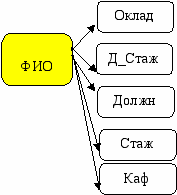 З З |
| R2 | | | | | |
| ФИО | Должн | Оклад | Стаж | Д_Стаж | Каф |
| Иванов АА | Нач_каф | 700 | >20 | 20 | 3 |
| Петров ВВ | Ст_преп | 600 | >15 | 15 | 3 |
| Петров ВВ | Ст_преп | 600 | >15 | 15 | 3 |
| Петров ВВ | Преп | 500 | >10 | 10 | 3 |
Рис.11 Отношение в виде таблиц R1 и R2 – 2-я нормальная форма
• Третья нормальная форма (ЗНФ). Схема отношения R находится в 3НФ относительно множества функциональных зависимостей F, если она находится во 2НФ и ни один из неключевых атрибутов не является зависимым от других атрибутов отношения R, т.е. чтобы привести отношение к 3НФ, необходимо устранить функциональные зависимости между неключевыми атрибутами отношения.
Таким образом, чтобы таблица находилась в третьей нормальной форме, необходимо, чтобы неключевые столбцы в ней не зависели от других неключевых столбцов, а зависели только от первичного ключа.
Для выполнения этого условия обратим внимание на полученные Отношения R1 и R2. Таблица R1 имеет всего один неключевой атрибут и потому она удовлетворяет требованиям 3НФ. В Таблице R2 имеются зависимые атрибуты: Оклад зависит от Должн, а Д_Стаж – от Стаж. Поэтому отношение R2 разбиваем на дочерние таблицы: R3, R4 и R5 (Слайд – Рис. 12):
В результате проектирования получаем БзД, состоящую из таблиц: R1, R2, R3, R4, R5. В полученной БзД отсутствует избыточное дублирование данных.
| R3 | | | | | R4 | | | R5 | |
| ФИО | Должн | Стаж | Каф | | Должн | Оклад | | Стаж | Д_Стаж |
| Иванов_АА | Нач_каф | >20 | 3 | | Нач_каф | 700 | | >5 | 10 |
| Петров_ВВ | Ст_преп | >15 | 3 | | ст_преп | 600 | | >10 | 15 |
| Петров_ВВ | Ст_преп | >15 | 3 | | преп | 500 | | >15 | 20 |
| Петров_ВВ | преп | >10 | 3 | | | | | | |
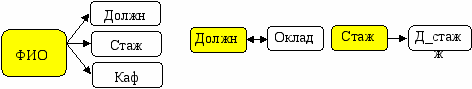
Рис. 12. 3-я нормальная форма отношения в виде таблиц R1, R2, R3, R4 и R5.
Таким образом, процесс нормализации отношений методом нормальных форм предполагает последовательное удаление из исходного отношения соответствующих зависимостей атрибутов от ключа. После завершения проектирования, БзД создается с помощью СУБД.
С организационной точки зрения работы по созданию информационной системы в масштабе штаба или другой воинской организации производятся поэтапно, в следующей очередности (Слайд):
- предпроектное обследование;
- составление технического задания (ТЗ) на информационную систему или экспертиза ТЗ;
- составление технического проекта (ТП) системы или экспертиза ТП;
- прототипирование;
- создание рабочих проектов; разработка и внедрение информационных систем.
Рассмотрим содержание основных этапов создания ИС.
Предпроектное обследование
Предпроектное обследование включает сбор, систематизацию и анализ информации о структуре учреждения (войсковой части) и организации его деятельности. С помощью специализированных программных средств (CASE-систем) или определенной методики анализа и моделирования строится модель деятельности учреждения. Эта модель должна дать достаточно четкое представление о происходящих внутренних и внешних процессах. Работая с этой моделью, системные аналитики смогут выявить «узкие места» в работе воинской организации, непроизводительные и дублирующиеся операции и т.п.. Исходя из этого, определяются основные цели и задачи реорганизации, ее стратегия, а также информационные потребности. После того, как построена и изучена модель «AS IS», т.е. «как есть» строится модель «ТО BE» «как должно быть».
Техническое задание
Это набор документов и спецификаций, определяющих требования к информационной системе и ее функционированию. Для того, чтобы достаточно четко поставить задачу разработчикам, которые будут собственно создавать информационную систему, необходимо указать, какая информация вводится в систему, в какой форме, как она должна храниться, какие выходные документы должна система генерировать. В техническом задании определяются также требования к секретности, уровню защиты информации и многие другие условия, которым система должна удовлетворять. В составлении технического задания обязательно должны принимать участие профессионалы-разработчики, которые, во-первых, глубоко разбираются во всех технических аспектах и видят всевозможные «подводные камни» и, во-вторых, владеют специальной терминологией и специальным понятийным аппаратом, что крайне важно, поскольку читать техническое задание будут именно разработчики.
Технический проект
Технический проект (техническое предложение) – это набор документов и спецификаций1, описывающих конструкцию, архитектуру, устройство, состав как системы в целом, так и ее отдельных модулей. Основой для технического проекта служит техническое задание, о котором говорилось выше. Не имея технического проекта, невозможно приступить к разработке системы.
Прототипирование
Под прототипом обычно понимают набор программ, моделирующих (изображающих, эмулирующих) работу готовой системы. Можно сказать, что прототип – это как бы «ожившее» техническое задание. Цель прототипирования – более ясно представить себе будущую систему, предугадать ее недостатки на этапе проектирования, внести необходимые коррективы в техническое задание и технический проект, если он уже готов. Прототип системы удобно демонстрировать сотрудникам учреждения, чтобы они могли понять, насколько удобно им будет пользоваться системой, какие функции следует добавить или исключить.
Создание рабочих проектов
Рабочий проект – это уже не прототип, но еще и не готовая система. Рабочие проекты помогают смоделировать работу системы, нащупать ее «узкие места» и исключить их на ранних этапах создания системы. Иными словами, рабочий проект по отношению к техническому проекту – это примерно то же, что прототип по отношению к техническому заданию.
Разработка и внедрение информационных систем
Проведя заказчика через все необходимые предварительные этапы создания информационной системы (ТЗ, ТП, прототипы, рабочие проекты), компания – разработчик информационной системы воплощает получившийся проект в жизнь. При этом заказчику обычно предоставляется полный набор услуг – от закупки и установки техники и прокладки сетевых кабелей до написания и отладки необходимых программных модулей и внедрения системы.
Экспертиза
Можно поручить проектной организации, провести всестороннюю экспертизу технических заданий, технических проектов, прототипов или готовых систем созданных другими фирмами. Подробно изучив предоставленные материалы, специалисты сделают заключение о соответствии или несоответствии предлагаемой системы задачам, стоящим перед учреждением или штабом, целесообразности и ресурсоемкости разработки и т.п. По результатам проведенного предпроектного обследования эксперты могут рекомендовать наиболее подходящую аппаратную и программную платформу, архитектуру, средства разработки или просто готовое решение.
Эффективность функционирования информационной системы во многом зависит от ее архитектуры. В настоящее время перспективной является архитектура клиент-сервер. В достаточно распространенном варианте она предполагает наличие компьютерной сети и распределенной базы данных, включающей БзД корпоративную (БзДК) и БзД персональные (БзДП). БзДК размещается на компьютере-сервере, БзДП размещаются на компьютерах сотрудников подразделений, являющихся клиентами корпоративной БзД. Сервером определенного ресурса в компьютерной сети называется компьютер (программа), управляющий этим ресурсом, клиентом – компьютер (программа), использующая этот ресурс. В качестве ресурса компьютерной сети могут выступать, к примеру, базы данных, файловые системы, службы печати, почтовые службы. Тип сервера определяется видом ресурса, которым он управляет. Например, если управляемым ресурсом является база данных, то соответствующий сервер называется сервером базы данных.
Достоинством организации информационной системы по архитектуре клиент-сервер является удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей корпоративной информации с индивидуальной работой над персональной информацией. Структура распределенной БзД, построенной по архитектуре клиент-сервер, показана на рис.13.
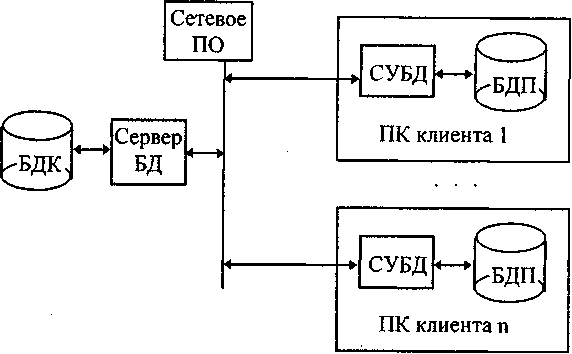 Рис. 13. Структура распределенной БД
Рис. 13. Структура распределенной БД
Корпоративная БзД создается, поддерживается и функционирует под управлением сервера БзД, например, Microsoft SQL Server пли Oracle Server.
Для создания и управления функционированием персональных БзД и приложений, работающих с ними, используются СУБД такие, например, как Access и Visual FoxPro фирмы Microsoft, Paradox фирмы Borland.
В зависимости от размеров организации и особенностей решаемых задач информационная система может иметь одну из следующих конфигураций:
• компьютер-сервер, содержащий корпоративную и персональные базы;
• компьютер-сервер и персональные компьютеры с БзДП;
• несколько компьютеров-серверов и персональных компьютеров с БзДП.
Использование архитектуры клиент-сервер дает возможность постепенного наращивания информационной системы предприятия, во-первых, по мере развития предприятия; во-вторых, по мере развития самой информационной системы.
Разделение общей БзД на корпоративную БзД и персональные БзД позволяет уменьшить сложность проектирования БзД по сравнению с централизованным вариантом, а значит, снизить вероятность ошибок при проектировании и стоимость проектирования.
Важнейшим достоинством применения БзД в информационных системах является обеспечение независимости данных от прикладных программ. Это позволяет не обременять пользователей проблемами представления данных на физическом уровне: размещения данных в памяти, методов доступа к ним и т. д.
Такая независимость достигается поддерживаемым СУБД многоуровневым представлением данных в БзД на логическом (пользовательском) и физическом уровнях. Иными словами, благодаря СУБД и наличию логического уровня представления данных обеспечивается отделение концептуальной модели БД от ее физического представления в памяти ЭВМ.
Выбор системы управления базами данных
СУБД, как правило, разделяют по используемой модели данных (как и базы данных) на следующие типы: иерархические, сетевые, реляционные и объектно-ориентированные.
Сведения о моделях данных, применяемых в некоторых СУБД, в качестве примера приведены на Слайд (в таблице 1):
Таблица 1
| Название СУБД | Тип БД |
| MS Access | Реляционная |
| Clipper | Реляционная |
| Dbase | Реляционная |
| FoxBase+ | Сетевая |
| FoxPro | Сетевая |
| IMS/VS | Иерархическая |
| Oracle | Реляционная |
| Paradox | Реляционная |
По характеру использования СУБД делят на персональные (СУБДП) и многополъзователъские (СУБДМ).
К персональным СУБД относятся Visual FoxPro, Paradox, Clipper, dBase, Access и др.; к многопользовательским СУБД относятся, например, СУБД Oracle и Informix. Многопользователъские СУБД включают в себя сервер БзД и клиентскую часть, работают в однородной вычислительной среде – допускаются разные типы ЭВМ и различные операционные системы. Поэтому на базе СУБДМ можно создать информационную систему, функционирующую по технологии клиент-сервер. Универсальность многопользовательских СУБД отражается соответственно на высокой цене и компьютерных ресурсах, требуемых для их поддержки.
СУБДП представляет собой совокупность языковых и программных средств, предназначенных для создания, ведения и использования БД.
Персональные СУБД обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними, и при необходимости создания приложений, работающих с сервером БД.
Заключение
Управление войсками в современных условиях является очень сложной задачей, не только из – за больших объемов обрабатываемых данных, но и из-за оперативности получения справочной или расчетной информации, влияющей в первую очередь на успех проведения операции и количество потерь в живой силе и технике.
Сегодня необходимым условием эффективного функционирования управленческой структуры любого уровня является наличие действующей информационной системы, на которую возложены функции автоматизированного сбора, обработки и манипулирования данными и которая включает в себя технические средства обработки данных, программное обеспечение и обслуживающий персонал.
Основные из перечисленных функций могут выполняться системами управления базами данных.
1 Применительно к вычислительным аппаратным средствам спецификация дает информацию о компонентах, возможностях и особых характеристиках. В отношении программного обеспечения, особенно для разрабатываемых программ, спецификации описывают условия эксплуатации, предлагаемые характеристики и ограничения новой программы. При обработке информации: спецификации описывают записи данных, программы и процедуры, использованные в отдельной задаче.