
Isbn 5-7262-0634 нейроинформатика 2006
| Вид материала | Документы |
- Isbn 5-7262-0634 нейроинформатика 2006, 188.49kb.
- Isbn 5-7262-0634 нейроинформатика 2006, 96.9kb.
- Isbn 5-7262-0634 нейроинформатика 2006, 95.41kb.
- Isbn 5-7262-0634 нейроинформатика 2006, 112.72kb.
- Isbn 5-7262-0634 нейроинформатика 2006, 104.27kb.
- Isbn 5-7262-0634 нейроинформатика 2006, 75.04kb.
- Isbn 5-7262-0634 нейроинформатика 2006, 103.98kb.
- Isbn 5-7262-0634 нейроинформатика 2006, 93.81kb.
- Isbn 978-5-7262-1377 нейроинформатика 2011, 107.92kb.
- Isbn 978-5-7262-1226 нейроинформатика 2010, 142.85kb.
ISBN 5-7262-0634-7. НЕЙРОИНФОРМАТИКА – 2006. Часть 3
П.Ю. ПОЛЯКОВ1, А.А. ФРОЛОВ2, Д. ГУСЕК3
1Институт оптико-нейронных технологий РАН, Москва
2Институт высшей нервной деятельности и нейрофизиологии РАН, Москва
3Институт информатики АН ЧР, Прага
pavel@8ka.mipt.ru, aafrolov@mail.ru, dusan@cs.cas.cz
БИНАРНАЯ ФАКТОРИЗАЦИЯ С ПОМОЩЬЮ СЕТИ
ХОПФИЛДА И ЕЕ ПРИЛОЖЕНИЕ К АВТОМАТИЧЕСКОЙ
КЛАССИФИКАЦИИ ТЕКСТОВ
Аннотация
Предложен метод бинарной факторизации на основе сети Хопфилда. Метод применен для автоматической классификации статей конференций по нейроинформатике 2004 и 2005 гг. Показана высокая эффективность метода.
Введение
Факторный анализ является одним из наиболее мощных статистических методов. Он позволяет выявить и преодолеть информационную избыточность многомерных сигналов, проявляющуюся в скоррелированности их компонент. С помощью факторного анализа исходное сигнальное пространство преобразуется в пространство факторов гораздо меньшей размерности. Метод главных компонент – классический пример линейного факторного анализа. Методы нелинейного факторного анализа разработаны значительно слабее. Особенно это касается бинарной факторизации, когда предполагается, что компоненты исходных сигналов
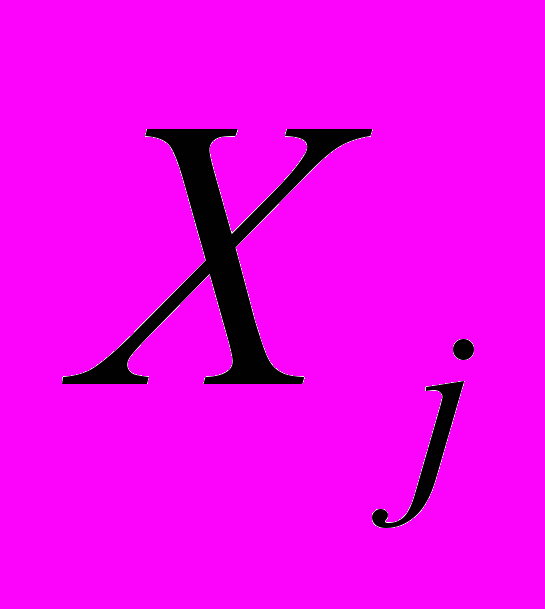 , факторные нагрузки
, факторные нагрузки 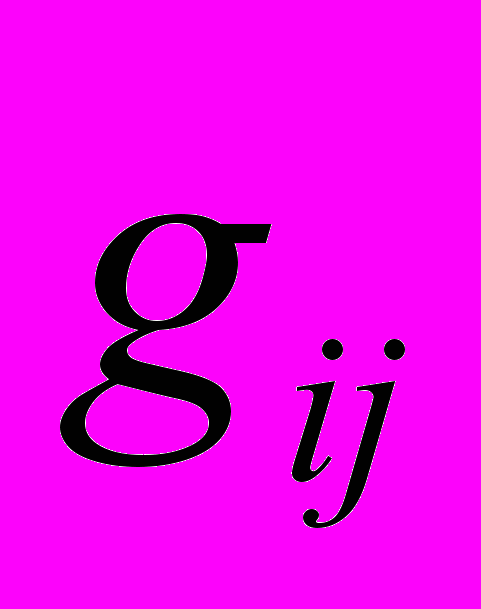 и вклады факторов
и вклады факторов 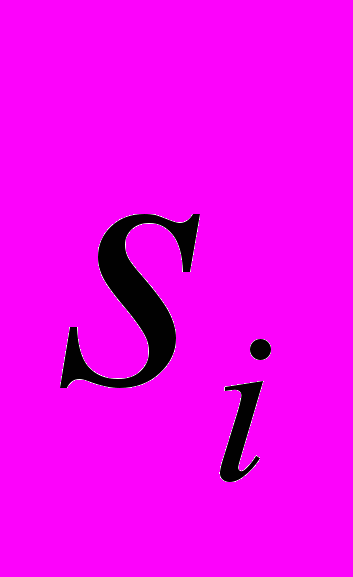 в исходные сигналы являются бинарными числами, т.е. исходные сигналы представляются в виде булевской суммы
в исходные сигналы являются бинарными числами, т.е. исходные сигналы представляются в виде булевской суммы 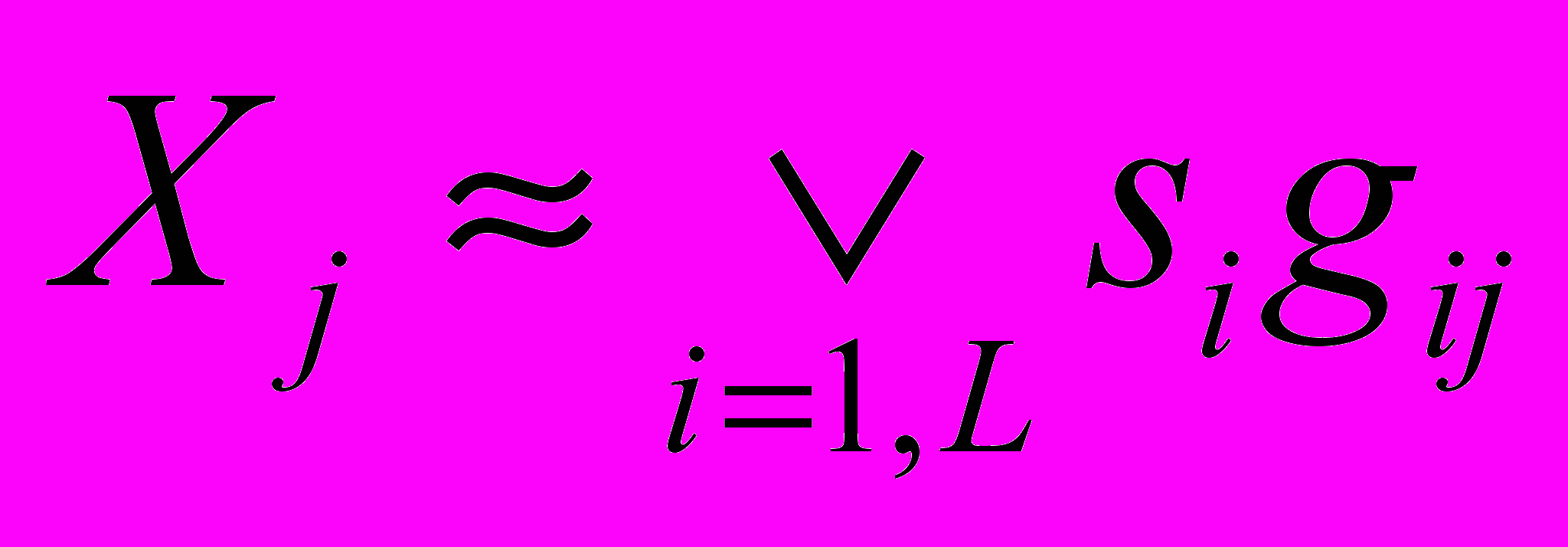 , где L – общее число факторов.
, где L – общее число факторов.Бинарная форма представления данных типична для социальных наук, маркетинга, зоологии, генетики, медицины и многих других областей. В настоящей работе мы иллюстрируем разработанный нами метод бинарной факторизации [1] на примере текстовых документов, а именно статей, представленных на конференции по «Нейроинформатике» в 2004 и 2005 годах. Мы исходим из гипотезы, что каждое направление исследований («тема») характеризуется специфическим набором используемых «ключевых» слов. Тогда согласованное появление этих слов в некоторой статье должно соответствовать ее теме. В этом случае размерность исходного пространства сигналов равна размеру используемого словаря, а каждая статья представляется бинарным вектором из нулей и единиц в зависимости от наличия или отсутствия в ней данного слова. Тема является фактором, факторные нагрузки принимают значения 0 или 1 в зависимости от того, является ли данное слово ключевым для данной темы, а наличие или отсутствие темы в данной статье задается двоичным числом вклада соответствующего фактора. Мы будем называть для краткости «фактором» набор ключевых слов для данной темы, т.е. бинарный вектор ее факторных нагрузок и говорить, что статья включает фактор, если она содержит соответствующий набор ключевых слов.
Исследованный набор документов составлял 189 статей. После отсеивания редко встречаемых и стоп-слов размер словаря составил 834 слова. Как иллюстрацию эффективности метода мы представляем результат автоматического разбиения статей по секциям, т.е. альтернативную программу, которая сравнивается с программами предшествующих конференций.
Описание метода
Разработанный нами метод [1] основан на специфической способности сети Хопфилда – формировать аттракторы нейродинамики группами сильно связанных между собой нейронов. При формировании матрицы связей по правилу Хебба усиливаются связи между теми нейронами, которые одновременно активируются паттернами обучающей выборки. Если паттерны являются бинарными суперпозициями нескольких факторов, появляющихся в различных сочетаниях, то связи между нейронами одного фактора будут сильнее, чем между нейронами разных факторов, так как нейроны одного фактора активируются вместе всегда, а нейроны разных факторов активируются одновременно только эпизодически. Поэтому нейроны факторов формируют сильно связанные группы, которые могут быть выявлены как аттракторы нейродинамики с помощью тестирования активности из множества случайных состояний.
В методе используется полносвязная сеть Хопфилда из N нейронов, которые могут находиться в состояниях 0 и 1. В режиме обучения матрица связей формируется по корреляционному правилу Хебба:
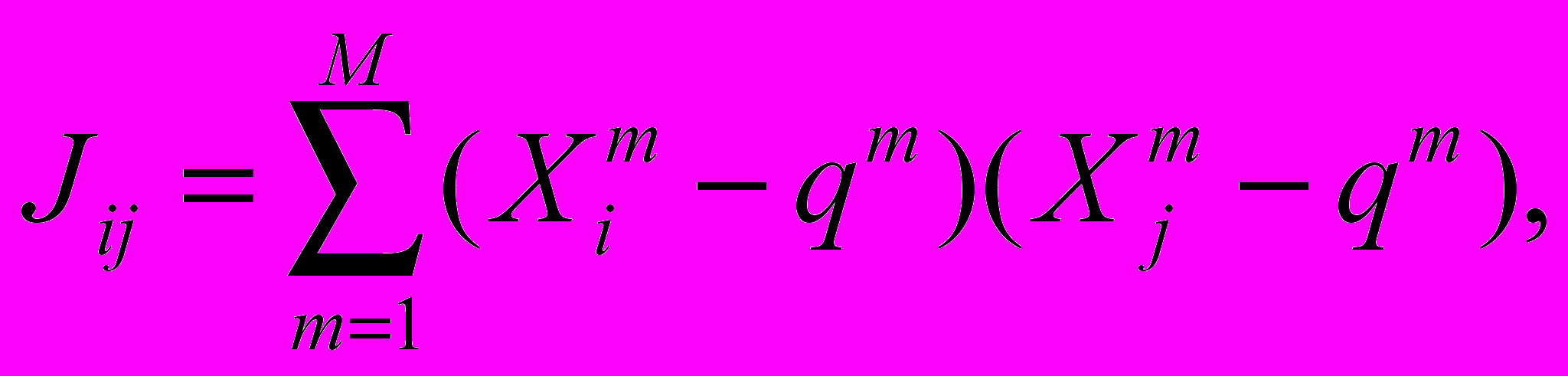 | 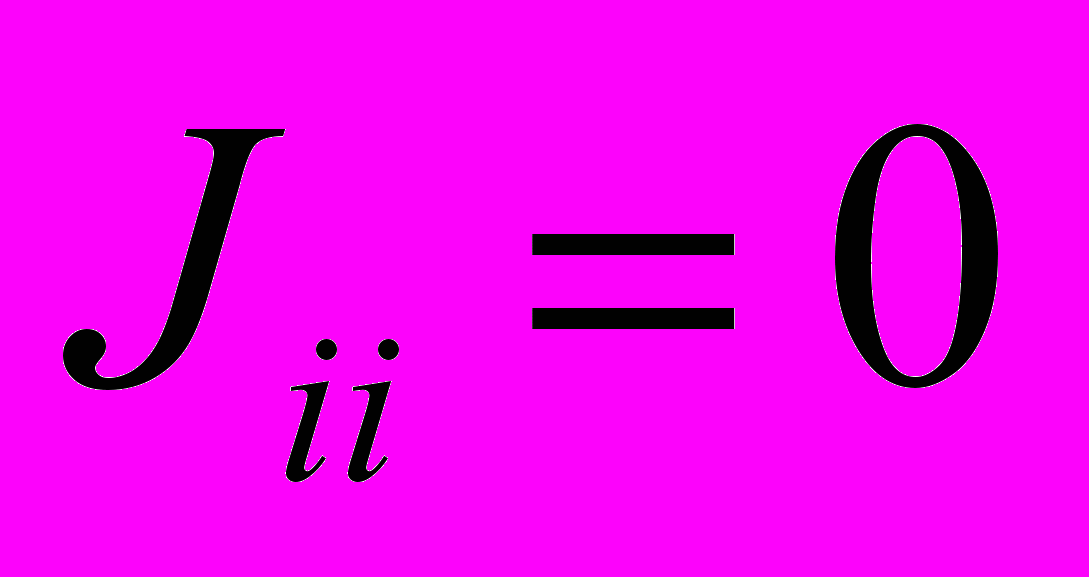 , , | (1) |
где смещение
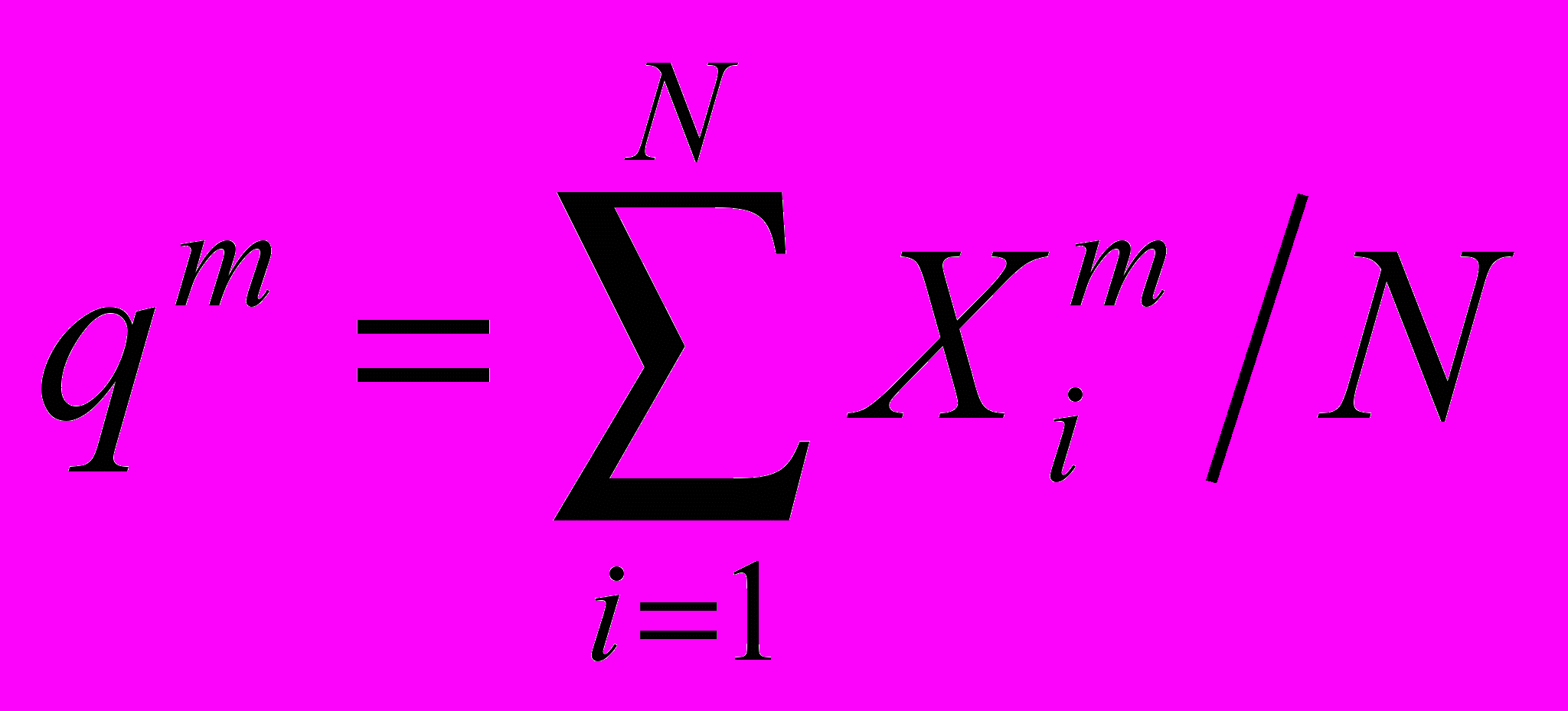 - суммарная активность m-го паттерна обучающей выборки, а M – общее число паттернов выборки.
- суммарная активность m-го паттерна обучающей выборки, а M – общее число паттернов выборки.Поиск факторов осуществляется с помощью двухходовой процедуры. Траектория нейронной активности запускается из случайного начального состояния сети, в котором активны kin нейронов. Проход нижнего уровня осуществляется при фиксированном числе активных нейронов kin на каждом шаге итерации. На шаге итерации t+1 состояние сети задается уравнением
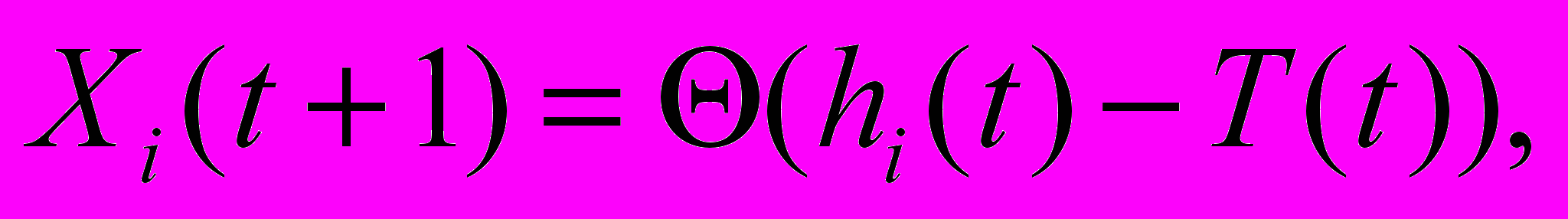 | 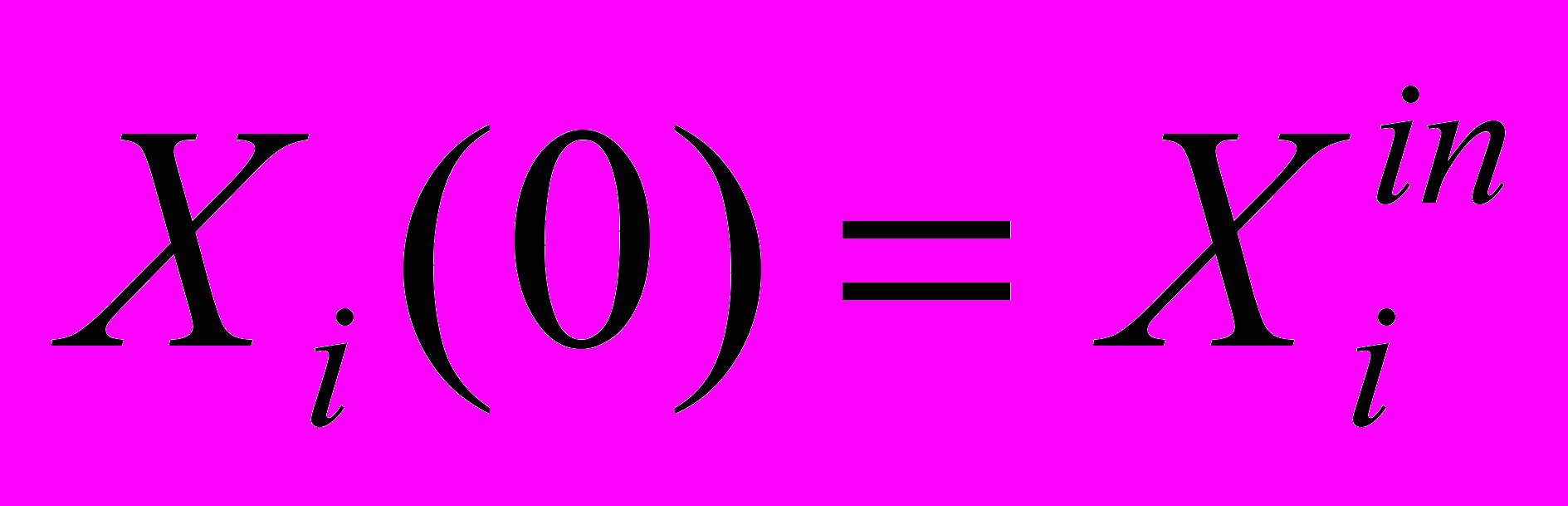 , , | |
где
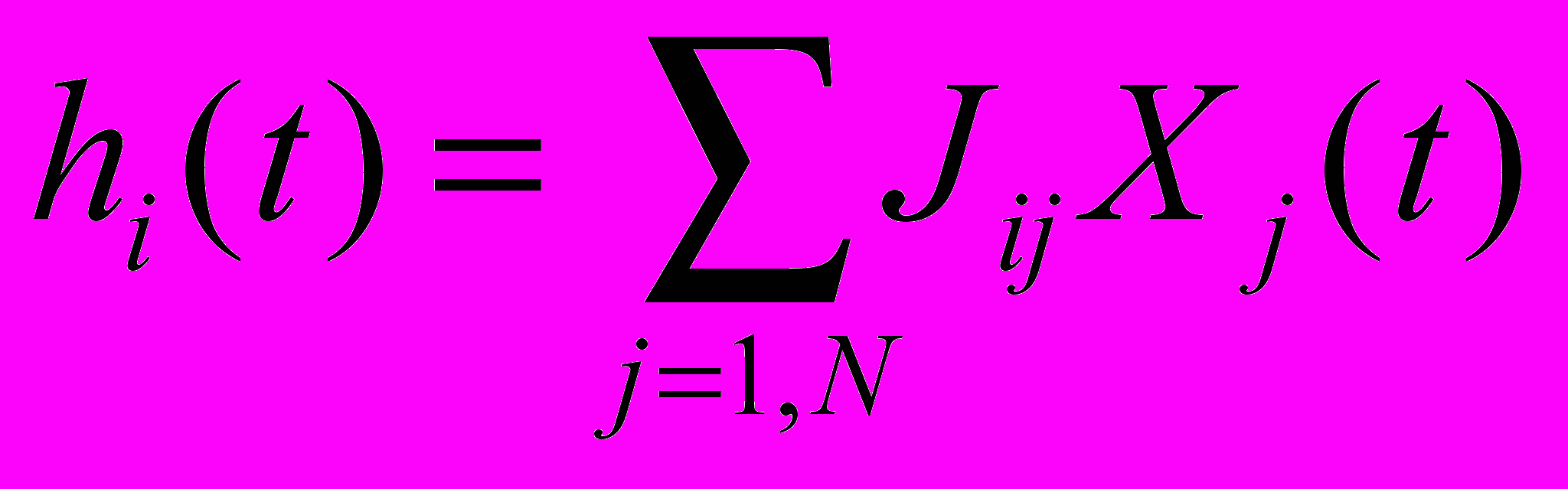 | | |
есть синаптическое возбуждение i-го нейрона,
 – пороговая функция, а T(t) – порог активации, который обеспечивает активацию kin победителей. При фиксированном уровне активности сети ее состояние сходится к точечному аттрактору или циклу длины два [2]. После достижения аттрактора проход нижнего уровня заканчивается. Переход ко второму уровню осуществляется добавлением нейрона с максимальным уровнем возбуждения после нейронов аттрактора, и повторением процедуры нижнего уровня с фиксированным числом активных нейронов kin + 1. Процедура верхнего уровня продолжается, пока число активных нейронов не достигнет заданного финального уровня k fin.
– пороговая функция, а T(t) – порог активации, который обеспечивает активацию kin победителей. При фиксированном уровне активности сети ее состояние сходится к точечному аттрактору или циклу длины два [2]. После достижения аттрактора проход нижнего уровня заканчивается. Переход ко второму уровню осуществляется добавлением нейрона с максимальным уровнем возбуждения после нейронов аттрактора, и повторением процедуры нижнего уровня с фиксированным числом активных нейронов kin + 1. Процедура верхнего уровня продолжается, пока число активных нейронов не достигнет заданного финального уровня k fin. Траекторию активности сети будем характеризовать функцией Ляпунова в конечных точках внутренних проходов, т.е. в аттракторах c числом активных нейронов k. Функция Ляпунова задается уравнением
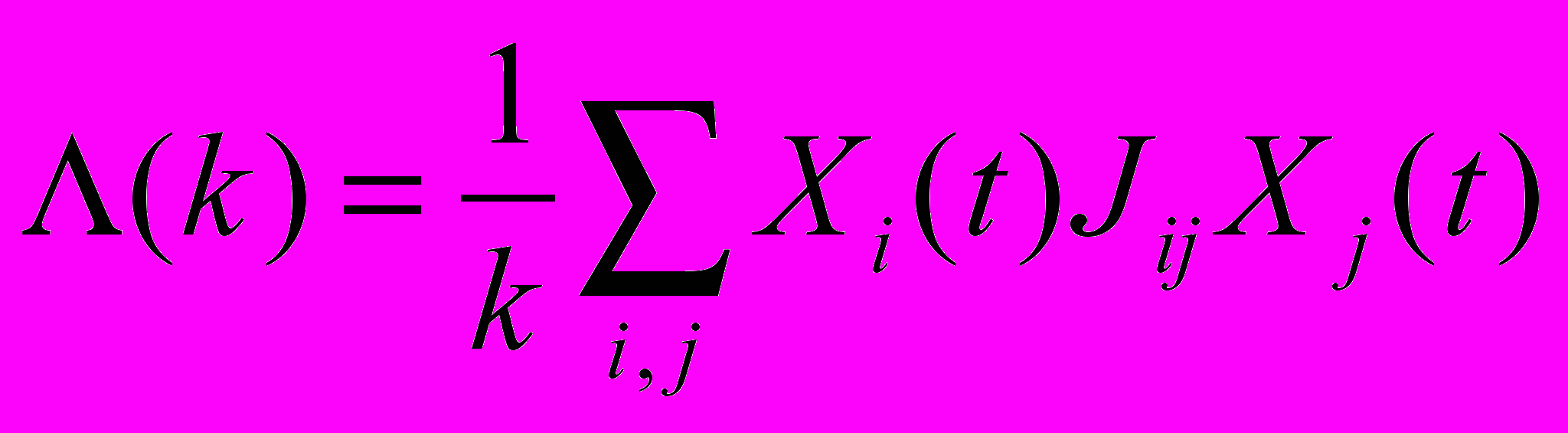 . . | | |
Известно, что при фиксированном k функция Ляпунова монотонно возрастает, достигая максимума в аттракторе [2].
Как показано в [3], факторами являются состояния аттракторов на траекториях нейронной активности, полученных в описанной процедуре. Если траектория содержит фактор, мы будем называть ее правильной. Хорошо известным свойством сети Хопфилда является то, что она имеет множество случайных (ложных) аттракторов. Траектории, содержащие такие аттракторы, будем называть ложными. Для идентификации факторов требуется отделить правильные траектории от ложных.
Ложные аттракторы бывают двух видов: глобальные и локальные. Два глобальных ложных аттрактора образуются двумя группами нейронов: наиболее часто и наиболее редко активными в обучающей выборке. Мы подавляли эти два аттрактора вычитанием из матрицы связей, полученной по уравнению (1) матрицы
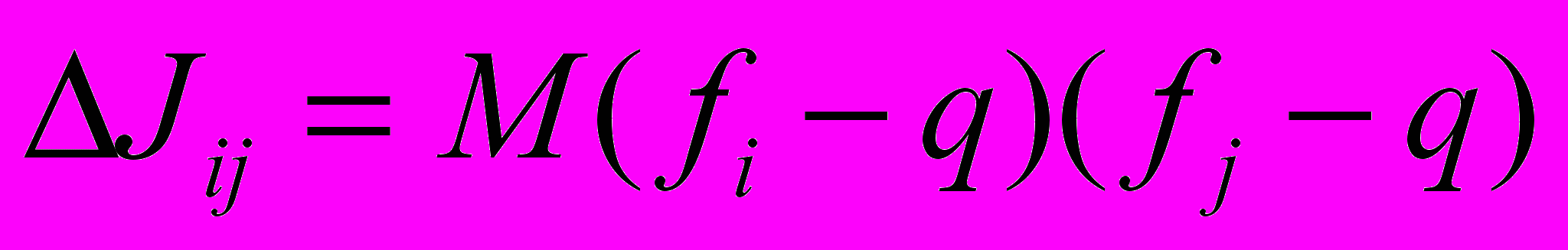 , , | | |
где fi – частота активации i-го нейрона, а q – средняя частота активации всех нейронов в обучающей выборке. Это приводит к полному исключению глобальных ложных аттракторов из динамики сети [3]. Правильные и локальные ложные аттракторы разделялись по гистограмме близостей между паттернами обучающей выборки и аттракторов. Если аттрактор соответствует фактору, то гистограмма содержит две моды. Одна – для паттернов обучающей выборки, которые содержат фактор (большая близость), другая – для паттернов, не содержащих фактор (малая близость). Если аттрактор ложный, то гистограмма содержит только вторую моду. Гистограммы использовали как для идентификации ложных и правильных аттракторов по наличию двух мод, так и для определения паттернов обучающей выборки, содержащих и не содержащих фактор, по тому, в какую из двух мод попадает его близость с фактором.
Другая проблема поиска факторов по траекториям, исходящим из случайных начальных состояний, связана с тем, что правильные аттракторы имеют довольно большие различия значений функции Ляпунова, которые обусловлены двумя причинами: частотой появления факторов в обучающей выборке и степенью синхронности появления нейронов фактора. Фактор содержат нейроны, активирующиеся с большей (ядро) и меньшей (бахрома) вероятностью. Если ядро большое, а бахрома малая, то связи между нейронами аттрактора сильные, и он имеет большое значение функции Ляпунова. Если наоборот бахрома большая, то функция Ляпунова мала даже при частом появлении фактора.
Аттракторы с большим значением функции Ляпунова доминируют и притягивают к себе почти все траектории. Для подавления доминирующих аттракторов, которые уже были идентифицированы как факторы, и ускорения поиска новых использовалась стандартная процедура разобучения: из матрицы связей вычитается матрица
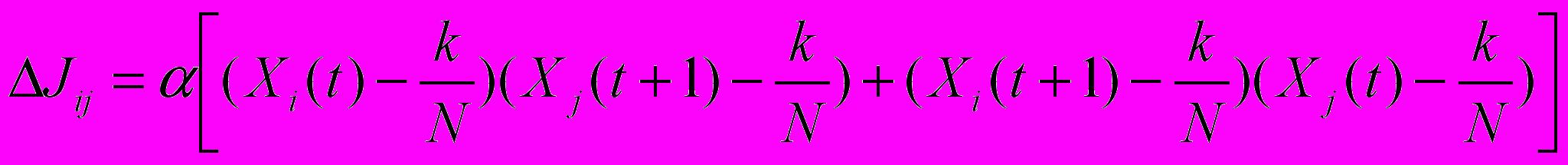 , , | | |
где – скорость разобучения, а Xi(t) – активность i-го нейрона в аттракторе. Формула для разобучения содержит два члена, так как она учитывает наличие циклических аттракторов.
Результаты
На рис. 1 приведены значения функции Ляпунова для траекторий, полученных непосредственно после процедуры подавления глобальных ложных аттракторов. Видны точки перехода от аттракторов с малой функцией Ляпунова к двум доминирующим аттракторам. Видно также, что при малой активности сети доминирует один аттрактор, а при увеличении активности значения функции Ляпунова сближаются. Наиболее связанные слова, образующие первый аттрактор, приведены в табл. 1. Они позволяют идентифицировать соответствующий фактор, как тему «нейробиология». Этот фактор, хотя и реже появлялся в обучающей выборке (в 30 статьях из 189, см. табл. 2) имеет малую бахрому и поэтому большую функцию Ляпунова.
Таблица 1
Условные наименования 5 факторов из 11 и их первые наиболее связанные
слова. В первом столбце указано общее число слов в каждом факторе
| 50 | Нейробиология: ПОТЕНЦИАЛ СИНАПС ИМПУЛЬС МЕМБРАНА АКТИВНОСТЬ КЛЕТКА ФИЗИОЛОГИЯ НЕРВ МОЗГ ВОЗБУЖДЕНИЕ РЕЦЕПТОР СТИМУЛ СИНАПС ТОРМОЗ СИГНАЛ РЕАКЦИЯ СПАЙК ДЕЙСТВИЕ МЕХАНИЗМ ВОСПРИЯТИЕ |
| 133 | Общие вопросы биологии: ДЕЙСТВИЕ ОКРУЖЕНИЕ КОНЦЕПЦИЯ СРЕДА ВЗАИМОДЕЙСТВИЕ ОРГАНИЗМ ЕСТЕСТВЕННОСТЬ СЛОЖНОСТЬ БИОЛОГИЯ КЛЕТКА МОЗГ ОТРАЖЕНИЕ СМЫСЛ РАЗВИТИЕ ОБЪЕКТ АБСТРАКЦИЯ УРОВЕНЬ ЭВОЛЮЦИЯ ЖИЗНЬ РОЛЬ ПОВЕДЕНИЕ ПАМЯТЬ ИНФОРМАЦИЯ ПОНИМАНИЕ |
| 63 | Искусственные сети: ИТЕРАЦИЯ ОШИБКА ВЕС ВЫХОД ВХОД НЕЙРОН СКРЫТЫЙ СЛОЙ ОБУЧЕНИЕ РАСПРОСТРАНЕНИЕ СЕТЬ МНОГОСЛОЙНОСТЬ ПЕРСЕПТРОН ОПТИМИЗАЦИЯ КОЭФФИЦИЕНТ ВЕКТОР АППРОКСИМАЦИЯ УЧИТЕЛЬ ГРАДИЕНТ СХОДИМОСТЬ МОДИФИКАЦИЯ АКТИВАЦИЯ АЛГОРИТМ |
| 44 | Изображение: ПИКСЕЛ ЗРИТЕЛЬ ФИЛЬТРАЦИЯ РЕЖИМ УРОВЕНЬ ЯРКОСТЬ ПОРОГ ИЗОБРАЖЕНИЕ ДИНАМИКА АКТИВНОСТЬ ФРАГМЕНТ ПРОСТРАНСТВО ЧАСТОТА ВЫДЕЛЕНИЕ ОБЪЕКТ РАСПОЗНАНИЕ ОРИЕНТАЦИЯ БЛОК УГОЛ ПРЕДЕЛ ПЛОЩАДЬ ПРИЗНАК ЦЕНТР ФОН ИСКАЖЕНИЕ ОБНАРУЖЕНИЕ |
| 57 | Математика: МИНИМУМ УРАВНЕНИЕ РАСПРЕДЕЛЕНИЕ НОЛЬ ЗНАК ОБЛАСТЬ СРЕДНИЙ СИММЕТРИЯ ФОРМА НЕЗАВИСИМОСТЬ СХОДИМОСТЬ ФУНКЦИОНАЛ ЛОКАЛЬНОСТЬ НЕРАВЕНСТВО ПЛОСКОСТЬ РАВЕНСТВО ФИЗИКА УСЛОВИЕ ВЗЯТИЕ МАТРИЦА НОРМА РАВНЫЙ БЛИЗОСТЬ ПРИБЛИЖЕНИЕ КВАДРАТ |
На рис. 2 показана гистограмма близостей первого фактора со статьями. Близости считались по мере Дайса (Dice). Гистограмма имеет две четкие моды для статей, содержащих и не содержащих указанный фактор. Полагалось, что статьи с близостью, превышающей 0.3 – порог разделения мод, содержат фактор «нейробиология».
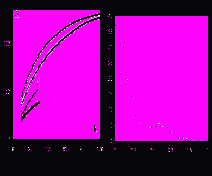 | |
| Рис. 1. Функция Ляпунова в аттракторах тестирующих траекторий в зависимости от числа активных нейронов | Рис. 2. Гистограмма близостей между первым фактором и всеми статьями |
В результате процедуры разобучения и построения аналогичных гистограмм были идентифицированы еще 10 факторов и статьи их содержащие. Наиболее связанные слова, образующие 5 из 11 полученных приведены в табл. 1. Мы приводим также условные наименования тем, которые отражают эти факторы.
В результате проведенной факторизации каждая статья представляется бинарным вектором вкладов 11 факторов в эту статью. Некоторые статьи имеют вклад только одного фактора, другие – нескольких. Например, статья «Исследования ориентационной чувствительности зрительной системы человека» содержит факторы «нейробиология» и «изображение», а статья «Инверсный метод нейросетевых аппроксимаций для решения задач оптимизации и управления» – «искусственные сети», «математика» и «применение».
Таблица 2
Пересечение автоматически полученных кластеров с секциями программ
конференций, составленных Программным комитетом
| | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 1 | 10 | 0 | 12 | 3 | 0 | 3 | 6 | 2 | 6 | 1 |
| 2 | 1 | 23 | 0 | 1 | 0 | 1 | 0 | 1 | 3 | 2 |
| 3 | 3 | 0 | 3 | 1 | 0 | 0 | 0 | 0 | 3 | 0 |
| 4 | 3 | 1 | 2 | 7 | 2 | 0 | 0 | 0 | 16 | 3 |
| 5 | 3 | 0 | 1 | 1 | 3 | 0 | 0 | 0 | 1 | 1 |
| 6 | 1 | 1 | 2 | 0 | 0 | 8 | 0 | 0 | 2 | 0 |
| 7 | 8 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 5 | 0 | 2 | 1 | 0 | 0 | 0 | 0 | 4 | 2 |
| 9 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 10 | 4 | 1 | 5 | 1 | 0 | 0 | 0 | 0 | 3 | 5 |
В первом столбце таблицы указаны номера кластеров, которым присвоены следующие названия:
- Искусственные нейронные сети и их применение.
- Нейробиология.
- Генетические алгоритмы и адаптивные нейронные сети.
- Нейронные сети и искусственный интеллект - общие вопросы.
- Естественные и искусственные языки.
- Анализ изображений.
- Импульсные нейронные сети.
- Нейроматематика.
- Ассоциативная память.
- Неидентифицированные.
В первой строке указаны номера секций со следующими названиями:
- Теория нейронных сетей.
- Нейробиология
- Применение нейронных сетей.
- Модели адаптивного поведения.
- Нейронные сети и когнитивные системы.
- Нейронные сети в задачах обработки изображений
- Нейронные сети в экономических приложениях
- Медицинские приложения нейроинформатики
- Стендовые доклады
- Неидентифицированные
Полученные бинарные представления всех статей были объединены в кластеры с помощью программы иерархической кластеризации системы SPSS. Результаты кластеризации для разбиения на 9 кластеров приведены в табл. 2. Число кластеров разбиения было выбрано близким к числу секций в программах конференций, чтобы сделать разумным сравнение автоматической и экспертной кластеризации. Для облегчения сравнения мы каждому кластеру дали название, отражающее, как нам представляется, содержание его статей. По строкам таблицы указано, какое число статей каждой секции вошло в соответствующие кластеры. Видно, что наибольшее пересечение автоматической и экспертной кластеризации произошло по секции «Нейробиологи». Все статьи, которые вошли в этот кластер, но не вошли в секцию, являются спорными по классификации и вполне могли бы быть включены в секцию «Нейробиология». Например, статья А.Н. Покровского «Нейроинформатика и нейрофизиология», которая составителями программы была включена в секцию «Теория нейронных сетей». Нам удалось найти только 9 статей из 189, содержание которых противоречит названиям, которые мы дали автоматически полученным кластерам.
Обсуждение
Проблема автоматической классификации документов и их поиска становится все более актуальной особенно в связи с внедрением Интернета. Стандартные методы классификации, основанные на объединении текстов в классы непосредственно по близости входящих слов, обеспечивают только 20-35 % совпадений с классификацией экспертов. Лучшие результаты дают нейросетевые подходы, основанные на самоорганизующихся картах Кохонена и теории адаптивного резонанса (ТАР). В частности, методы, основанные на ТАР, обеспечивают до 50 % совпадений [4]. Трудно сравнивать автоматическую и экспертную классификации, так как число кластеров, полученных автоматически, обычно больше числа классов, используемых экспертами. Несколько кластеров могут входить в один класс, демонстрируя более тонкую специализацию классов. Бывает и противоположный результат, когда один кластер объединяет несколько экспертных классов, демонстрируя обобщение классов. Могут встретиться и более сложные соотношения между кластерами и классами, когда они пересекаются, а не объединяются вложениями. Например, полученная нами автоматическая классификация текстов представляется вполне разумной, хотя и не совпадает с экспертной. Если судить о точности классификации по числу статей, которые нам удалось отобрать как ошибочно классифицированные, то точность нашей классификации составляет (189-9)/189 = 95 %. Это намного превосходит оценки, приведенные в других статьях, хотя этот результат может быть объяснен и разными способами получения оценки. В целом нам представляется, что точность нашего метода должна быть не хуже, чем у методов ТАР, которые также основаны на выделении групп одновременно появляющихся слов, т.е. тех же факторов.
Работа выполнялась при финансовой поддержке грантом РФФИ 02-01-00457, грантом AVOZ10300504 и Information society grant No1ET00300419.
Список литературы
1. Frolov A.A, Sirota A.M, Husek D, Muraviev I.P, Polyakov P.Y: Binary factorization in Hopfield-like neural networks: Single-Step approximation and computer simulations. Neural Networks World, 14, 2004, p. 139-152.
2. Frolov A.A, Husek D, Muraviev I.P: Informational efficiency of sparsely encoded Hopfield-like autoassociative memory. Optical Memory & Neural Networks 12, 3.
3. Frolov A.A, Husek D, Polyakov P.Y, Rezankova H, Snasel V: Binary factorization of textual data by Hopfield-like neural network. In Computational Statistics (Ed: Antoch J) – Heidelberg, Physica Verlag 2004, p. 1035-1041.
4. Massey L: On the quality of ART1 text clustering. Neural Networks, 16 (2003), p. 771-778.
УДК 004.032.26(06) Нейронные сети