
Государственное Образовательное Учреждение высшего профессионального образования Московский Авиационный Институт Государственный Технический Университет "маи" кафедра 304. конспект
| Вид материала | Конспект |
- Инновационной образовательной программы, 1090.47kb.
- Самостоятельная работа 2 часа в неделю всего часов, 28.69kb.
- Самостоятельная работа 2 часа в неделю всего часов, 45.89kb.
- Самостоятельная работа 2 часа в неделю всего часов, 73.46kb.
- Самостоятельная работа 2 часа в неделю всего часов, 46.6kb.
- Самостоятельная работа 2 часа в неделю всего часов, 41.37kb.
- Самостоятельная работа 2 часа в неделю всего часов, 41.08kb.
- Самостоятельная работа 2 часа в неделю всего часов, 64.33kb.
- Самостоятельная работа 2 часа в неделю всего часов, 29.72kb.
- Самостоятельная работа 2 часа в неделю всего часов, 33.42kb.
Модели памяти
Пакет TASM дает возможность упрощенного описания сегментной структуры программ на ЯА. Для этого введено понятие «модели памяти», которое объединяет особенности автоматического распределения памяти при ассемблировании.
Модель памяти определяет следующие параметры:
- количество сегментов, их расположение, перекрытие и т.п.;
- размерности и свойства переменных и предопределенных значений в программе (например, тип процедур NEAR или FAR).
Обычно модель памяти используется по умолчанию и определяется ассемблером в зависимости от числа сегментов, но можно задать модель памяти с помощью директивы ЯА, располагаемой в начале файла с программой, что позволяет использовать упрощенные формы описания сегментов. Общий вид директивы
.MODEL {тип}
где {тип} – может принимать следующие значения:
а) tiny – ИМ состоит из одного сегмента, т.е. регистры CS, DS и SS имеют одно и то же значение; наиболее компактная программа, занимающая 64КБ, все переходы – типа NEAR;
б) small – сегмент кода отделен от сегментов данных и стека, последние объединены в одну группу, т.е. DS и SS имеют одно и то же значение; наиболее распространенная модель памяти, все переходы – типа NEAR;
в) compact – используется один сегмент кодов и несколько сегментов данных, все переходы – типа NEAR, а обращение к данным – с указанием сегментного регистра, но сегменты данных и стека объединены в одну группу;
г) medium – несколько сегментов кодов и общий сегмент данных со стеком, доступ к процедурам – типа FAR, а обращение к данным указывает только смещение;
д) large – наиболее общий случай; несколько сегментов кодов и данных, вся адресация – с помощью сегментных регистров;
е) huge – аналогичен large, но предназначен для совмещения с программами на языках высокого уровня, разрешается работа с данными, занимающими >64КБ памяти.
Список значений параметра {тип} приведен не полностью, кроме того существуют другие параметры директивы .MODEL, но мы их здесь не рассматриваем.
При использовании данной директивы ИМ может иметь различную структуру.
Например,
. MODEL small
Stack 256
.Data
{данные}
.Code
ASSUME DS:@data, ES:@data
Main:
…
END Main
Создание файлов типа .EXE и .COM.
Для программы типа .EXE компоновщик автоматически генерирует определённый формат и при сохранении его на диске предворяет под программы специальным блоком размером ≥ 512 Б. Можно писать и выполнять программы типа .COM. Приимущество этих программ – меньший размер по сравнению с программами типа .EXE и более лёгкая адаптация к применению.
Существенные различия между программами типа .EXE и типа .COM включают в себя:
- Размер программы
Программы типа .COM используют единый сегмент для инструкций и данных, ограниченный размером 64 КБ включая префикс сегмента программы. PSP – это 256 Б(100h) блок, который загрузчик программ вставляет непосредственно перед программами при загрузке их в память диска. В .EXE есть ещё заголовок, который содержит информацию о перемещаемых адресах.
2) Сегментация
Рассмотрим сегментную структуру файлов в памяти:
| заголовок |
| PSP |
| Стек |
| Сег. данных |
| Сег. кода |

 EXE COM
EXE COM | PSP |
| Сегмент кода |
| Стек |
 DS
DSE
 S CS
S CSS
S C
S D
S SSДля программ типа .EXE необходимо явно определить сегменты данных и стека. Для программ типа .COM описание стека следует опустить.
- Инициализация
Когда загрузчик программ загружает для выполнения программу типа .COM он автоматически инициализирует CS, DS и ES адресом PSP. Поскольку PSP имеет размер 100h Б, то адресация программы начинается со смещения 100h, для чего требуется в текст программы внести директиву ORG 100h сразу за описанием сегмента. Эта директива приказывает ассемблеру установить счётчик положения в значения 100h – это адрес начала кода программы. Примеры программ, описанных в соответствии с требованиями формата .СОМ:
1) Title A05 COM
Codes Segment para ‘code’
ASSUME CS : codes, DS : codec, SS : codes, ES : codes
ORG 100h
BEGIN : JMP main
FLDD DW 215 ; определение данных
FLDE DW 125
FLDF DW ?
main proc NEAR
…………………..
mov AX, 4C00h
int 21h
main endp
codes ends
end BEGIN ; программа для MASM и для .СОМ формата файла.
2) Title A05 COM2
.model TINY
.code
ORG 100h
BEGIN : JMP main
FLDD DW 215 ; определение данных
FLDE DW 125
FLDF DW ?
main proc NEAR
…………………..
main endp
end BEGIN.
Макросы
Каждая инструкция ЯА генерирует одну команду в машинных кодах. В языках высокого уровня одной инструкции (оператору) соответствует несколько машинных команд. С этой точки зрения языки высокого уровня можно рассматривать как набор макрокоманд. Ассемблер содержит механизмы, позволяющие создавать и использовать в программах макросы, вызываемые при помощи макрокоманд. Макрокоманды позволяют вставлять в текст программы последовательности строк (которые могут быть данными или командами) и привязывать их к контексту места вставки. В общем случае можно говорить, что транслятор ассемблера состоит из двух частей – непосредственно транслятора, формирующего ОМ, и макроассемблера.
Обработка программы на ЯА с использованием макросредств неявно осуществляется в 2 фазы :
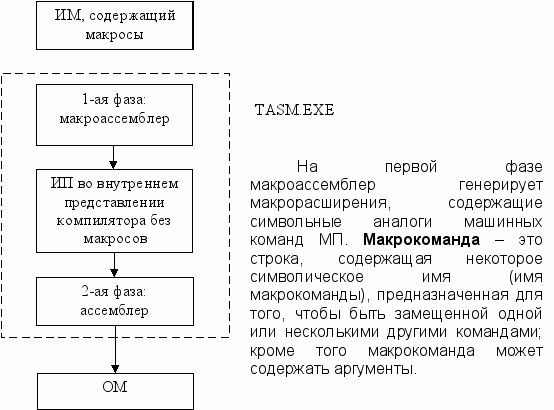
Определение макросов
Макроопределение – это описание (шаблон, описание макроса) содержимого макрокоманды. Общий вид:
{имя макроса} MACRO [{список форм. аргументов}]
{тело макроса}
ENDM
где {имя макроса} – должно быть уникальным как в программе, так и в используемых библиотеках.
Для включения макросов в программу сначала их нужно определить или скопировать из библиотеки.
Возможны варианты размещения макроопределений:
- В начале ИМ до сегментов кодов и данных, если макроопределение используется только в данной программе;
- В отдельном файле (для нескольких программ); чтобы сделать доступными эти макросы в конкретной программе, нужно в начале ИМ записать директиву
INCLUDE {имя файла с макросом}
Например,
. MASM
.MODEL small
INCLUDE show.inc
Data segment
…………………….
- В макробиблиотеке (тоже файл типа .inc). Особенность – в исходный текст программы включаются все макросы из библиотеки. Чтобы бороться с этим нужно использовать директиву PURGE {список имен макросов}
Например,
INCLUDE iomac.inc
PURGE outstr, exit.
Простые определения макросов
Используются, например, для инициализации сегментных регистров в программе:
Например,
Initz MACRO
Mov AX, @data
Mov DS,AX
ENDM
причем INITZ – имя макроса, а AX, @data и DS должны быть определены где-то в вызывающей программе. Ассемблер обнаруживает в тексте программы имя макроса – это макровызов, например
Initz
Ассемблер вставляет на место макровызова тело макроса, создавая макрорасширение.
Например, для макроса
Finish MACRO
mov AX,4C00h
Int 21h
ENDM
программа до трансляции имеет вид
Title A21MAC
INITZ MACRO
mov AX, @data
mov DS,AX
ENDM
Finish MACRO
mov AX,4C00h
Int 21h
ENDM
.MODEL small
.Stack 64
.Data
Message DB ‘Test of macro?’,13,10,’$’
.code
begin PROC far
Initz ; вызов макроса для вывода строки
mov AH,09h ;
Lea DX, message ;
Int 21h
Finish
Begin ENDP
END begin.
Использование параметров в макросах
Чтобы сделать макрос модифицируемым, необходимо ввести формальные аргументы(ФА).
Например, для вывода на экран сообщений, составим следующий макрос:
Prompt MACRO Mess
MOV AH, 09h
LEA DX, Mess
INT 21h
ENDM
При обращении к макросу используются фактические аргументы. Например,
PROMPT Message2
и где-то в программе есть декларация
Message2 DB ‘Enter the date mm/dd/yy’,’$’
Тогда при формировании макрорасширения во все команды макроса подставляется Message2 вместо Message.
Полный синтаксис формального аргумента имеет вид
{имя ФА} [: {тип}]
где {тип} может принимать значения:
- REC – требуется обязательное задание ФА при макровызове (по умолчанию);
- =<{любая строка}> – если аргумент при макровызове на задан, то в соответствующие места макрорасширения будет вставлено значение по умолчанию, указанное в < >.
Не всегда ассемблер может распознать в теле макроса ФА. Для уверенности последовательность символов, образующих ФА, предваряется символом «&». Этот прием часто используется для задания модифицируемых имен и кодов операций.
Например, определим макрос генерации в программе некоторой таблицы, причем параметры этой таблицы можно задавать с помощью аргументов.
…
def_table MACRO Type=, len
table_&type d&type len dup(0)
ENDM
…
. data
def_table b,10
def_table w,5
После трансляции получим
Table_b DB 10 dup(0)
Table_w DW 5 dup(0)
Комментарии в макросах
Т.к. по умолчанию в листинг после трансляции включаются только команды, генерирующие только объектный код ассемблера, не включающий в макрорасширение комментарии из макросов. Что бы комментарии попали в листинг существующей директивы управления листингом необходимо:
.LALL (List all) – вывести всё (помещается перед макровызовом), например:
.LALL
Promt Message1.
.XALL (по умолчанию) – подавляет комментарии в макрорасширениях. Если какой-то комментарий не должен попасть в макрорасширение при директиве .LALL, то перед ним ставят ;;
.SALL (Super all) – подавляет включение в листинг макрорасширений и позволяет уменьшить размер листинга, но не влияет на размер содержимого ОМ.
Директива управления листингом действует в программе пока в тексте программы не встретится директива LOCAL.
Некоторые программы включают в себя метки и переходы, но при многократном макровызове в одной программе может получится дублирование меток (ошибки), что бы создаваемые в макрорасширениях имена были уникальны, после директивы MACRO помещается директива LOCAL и {список имён}. Таких директив может быть несколько. В результате в каждом экземпляре макрорасширения сгенерируются уникальные имена для всех идентификаторов перечисленных в списке. Эти уникальные имена формируются автоматически и имеют вид ??ХХХХ, где ХХХХ – 16-ричное представление числа, и тогда получаем
??0000 – 1 раз
??0001 – 2 раз
??0002 – 3 раз и т.д.
Защитные режимы МП
Любой современный МП в реальном режиме работы позволяет работать с так называемыми пользовательскими регистрами. Начиная с i486 и Pentium их 16:
- 8 32-разрядных РОН(регистров общего назначения) EAX/AX/AH/AL, EBX, ECX, EDX, EBP\BP, ESi\Si, EDi\Di, ESP\SP
- 6 16-разрядных сегментных регистра CF, DF, SF, EF, SS, GS
- регистры состояния и управления EFLAGS\FLAGS, EiP\iP
Существуют ещё 16 системных регистров. Защищённый режим МП позволяет полностью использовать все возможные атрибуты для многозадачного режима. При этом сегментация памяти усложняется. Любой сегмент памяти в ЗР имеет следующие атрибуты:
- Расположение сегментов в памяти
- Размер сегмента
- Уровень привилегий, определяющий права этого сегмента относительно других
- Тип доступа (определяет назначение сегмента) и некоторые другие…
Перечисленные атрибуты показывают, что в ЗР МП поддерживает два типа защиты по привилегиям и по доступу к памяти в отличие от реального режима работы.
Ключевым объектом ЗР является специальная структура – дескриптор сегмента, которая представляет собой 8 байтовую структуру, содержащую перечисленные выше атрибуты.
Любая область ОП, которая логически может быть сегментом данных, стека или кода должна быть описана дескриптором. Все дескрипторы собираются вместе в одну из трёх дескрипторных таблиц, соответствующего назначения. Адрес размещения дескрипторных таблиц может быть любым; он хранится в специальном регистре.
Системные регистры МП:
- 4 регистра управления
- 4 регистра системных адресов
- 8 регистров отладки
1. Регистры управления предназначены для общего управления системой и доступны только для программ с уровнем привилегий 0 (Cr 0, Cr1, Cr2, Cr3).
Cr 1 – зарезервирован для спец использования и не доступен.
Cr 0 – содержит системные флаги, управляющие режимами работы МП и отражающие его состояние глобально, независимо от конкретно выполняющихся задач. Используется при страничной организации памяти.
Рассмотрим некоторые системные флаги:
- PE(Project Enable), бит 0; при PE=0 – реальный режим , в противном случае ЗР
- MP(Math Present), бит 1; при MP=1 – указывается на наличие сопроцессора
- TS(Task Switched), бит 3; переключение задач (автоматически изменяется при переключении на выполнеие другой задачи)
- AM(Alignment Mask), бит 18; маска выравнивания. При AM=1 – разрешён контроль выравнивания, в противном случае - запрет
- CD(Cash Disable), бит 30; При CD=1 – запрещена кеш-память
- PG(PaGin), бит 31; При PG=1 – разрешено страничное преобразование.
Cr 2 - используется при страничной организации памяти в ситуации, когда текущая команда обратилась по адресу, содержащемуся на странице, отсутствующей в данный момент в ОП. Тогда в МП возникает прерывание и 32 битовый адрес команды записывается в Cr 2 и обработчик определяет нужную страницу, определяет её в ОП и возобновляет нормальную работу программы.
Регистр Cr 3 используется так же при страничной организации памяти. Это регистр каталога страниц первого уровня. Он содержит 20 битовый физический базовый адрес каталога страниц текущей задачи. Этот каталог содержит 1024 32 битовых дескриптора, каждый из которых содержит адрес таблицы страниц второго уровня. В свою очередь, каждая из таблиц страниц второго уровня содержит 1024 32 битовых дескриптора, адресующих страничные кадры памяти размером по 4 КБ.
2. Регистры системных адресов (регистры управления памятью) предназначены для защиты программ и данных в мультизадачном режиме работы МП. В ЗР адресное пространство делится на:
- Глобальное (общее для всех задач)
- Локальное (отдельная для каждой задачи).
Поэтому в МП существуют следующие системные регистры:
- GDTR (Global Description Table Register) – его размер 48 бит, 32 из которых (с 16 по 47 ) базовый адрес глобальной дескрипторной таблицы CDT и 16 бит (с 0 по 15) – значение предела, т.е.размер таблицы GDT в байтах
- LDTR (Local Description Table Register) – регистр таблицы локальных дескрипторов размером в 16 бит. Содержит, так называемый, селектор дескриптора LDT, который является указателем таблицы GDT, которая описывает сегмент, содержащий LDT.
- IDTR (Interrupt Description Table Register) – регистр дескриптора прерываний, размер 48 бит. Предназначен для таблиц IDT, аналогичен GDTR.
- TR (Task Register) – регистр задачи размером 16 бит, подобно LDTR содержит селектор, т.е. указатель на дескриптор в таблице GDT, который описывает текущий сегмент состояния задачи.
TSS – этот сегмент создаётся для каждой задачи в системе, имеет жёстко регламентированную структуру и содержит контекст или текущее состояние задачи. Основное назначение сегментов TSS – сохранить текущее состояние задачи в момент переключения на другую задачу.
3. Регистры отладки предназначены для аппаратной отладки. Реально из 8 регистров МП используются 6 (все они 32 битовые):
Dr 0, Dr 1, Dr 2, Dr 3 – предназначены для задания линейных адресов четырёх контрольных точек прерывания, при этом используется механизм : любой, формируемы текущей программой, адрес сравнивается с адресами в регистрах Dr 0 , Dr 3 и при совпадении генерируется “исключения отладки №1”.
Dr 6 – регистр состояния отладки, биты этого регистра устанавливаются в соответствии с причинами прерывания.
Dr 7 – регистр управления отладкой. В нём для каждого из регистров Dr 0 …Dr 3 имеются поля, с помощью которых можно уточнить следующие условия, при которых генерируются прерывания:
- Место регистрации контрольной точки (только в текущей или любой задаче ) – это младшие 8 бит (по 2 бита на каждую контрольную точку)
- Тип доступа, по которому инициируются прерывания (только при выборе команды, при записи или чтении команды тип доступа хранится в старшей части регистра).
Большинство из системных регистров – программно-доступные.
Структуры данных ЗР.
Так как в ЗР запрос к памяти со стороны программ должен быть санкционирован, то МП аппаратно контролирует доступ к любому адресу называемому целевым. В отличие от реального режима, в сегментных регистрах вместо адреса начала сегмента, в ЗР загружается, так называемый, селектор, в котором хранится указатель на 8 байтовый блок памяти называемый дескриптором.
Схема обращения к дескриптору.
1
 5 0
5 0is i i ………..i e p p
+ 1 1 1 ……….1 0 0 0
 31 0
31 0адрес таблицы дескриптора


адрес дескриптора сегмента памяти
Дескриптор:
6

 3 Б7 Б6 48 47 Б5 Б4 31
3 Б7 Б6 48 47 Б5 Б4 31База(31..24) GD04Предел(19..16) p d d a t t t A База (23..16)
3
1 Б3 Б2 16 15 Б1 Б0 0База сегмента(15..0) Предел сегмента (15..0)
Таблица дескрипторов может быть:
- Глобальной (GDT)
- Локальной (LDT)
- Прерываний (IDT)
Адрес таблицы дескрипторов выбирается в соответствии с битом L, который при равенстве 1 LDTR, в случае равенства 0 - GDTR.
Поля дескрипторов используются следующим образом:
- Базовый адрес занимает Б2, Б3, Б4, Б7 и определяет начальный адрес сегмента в линейном адресном пространстве размером 4 ГБ.
- 20 битовое поле предела расположенное в Б0, Б1 и частично в Б6 и определяет границу сегмента.
- Б5 называется AR(Access Raights) в нём закодированы права доступа к сегменту.
- В старшей части Б6 находятся ещё 3 управляющих бита:
D – бит размера, если D=0, то данные представлены 16 битами, если 1, то данные 32 битные.
U – бит пользователя, предназначен для системы, МП его не использует.
G – бит поля гранулярности, определяет размер сегмента. При G=0 – размер в Байтах, при G=1 – размер указывается в страницах и, так как страница 4 КБ, то максимальный размер 1М * 4КБ = 4 ГБ.