
Тестирование (Т)
| Вид материала | Тесты |
- Реферат «Тестирование на уроках русского языка», 341.77kb.
- Лекция №10. Юзабилити-тестирование, 89.95kb.
- Тестирование учащихся в общеобразовательных учреждениях, 120.35kb.
- Й курс Разработка и тестирование компьютерной программы для сортировки методом выбора, 67.8kb.
- И. Н. учитель русского языка и литературы Миронова Е. Ю. учитель русского языка и литературы, 62.7kb.
- Холл-тесты (holl-test) тестирование отдельных характеристик товаров в точках продаж,, 52.73kb.
- «Тестирование в сфере образования: проблемы и перспективы развития», 17.88kb.
- Магистерская программа «Финансовая и информационная безопасность в кредитно-финансовой, 39.5kb.
- Контрольное тестирование по теме, 104.7kb.
- Аттестационное тестирование в сфере профессионального образования, 58.97kb.
Тестирование (Т)
Т явл-ся одним из этапов ЖЦ ПИ, направленным на повышение каче-ственных харак-к. При создании ПИ около 40% общего времени и более 40% стоимости расходуется на Т.
Проги, кок объекты Т, имеют особенности, которые отличают процесс их Т-я от общепринятого(при Т-и техн-х изделий). Особенности: отсут-ствие эталона, которому д. соотв-ть Т-ая прога; высокая сложность прог и принципиальная невозможность исчерпывающего Т-ия; практич-ая невозм-ть созд-ия единой методики Т-ия в силу большого разнообра-зия ПИ по их сложности, функц-му назнач-ю, области исп-я и т.д.
Т-ие ПИ – это процесс многократного выполнения проги с целью обнаруж-я ош-к (мнение, что Т-е – это демонстрация отсут-ия ош-к - неправильна). Прога Т-ся для повышения уровня надежн-ти, т.е. выявить max-е число ош-к.
Цель Т-ия - выявление как можно большего числа ош-к. Из опред-я Т-ия вытекает ряд принципов: 1) Процесс Т-ия более эффективен, если проводится не автором проги. Тестовый прогон, в рез-те к-го не выявлено ош-к , явл-ся неэффективным. 2) Описание предпологаемых значений результ-ов Т-ия–необх-ая часть тестового набора данных(ТНД).
ТНД д. вкл-ть: описание вх-х д-х и точного и корректного рез-та, соотв-го набору вх-х д-х. 3) Н. досконально изучить рез-ты примен-ия каждого теста. 4) Тесты для неправильных и не предусм-ых вх-х д-х должны разрабатываться также тщательно, как для правельных, педусмотренных.
Соглатно принципу при обработке д-х, выходящих за обл-ть допустимых значений, в проге д.б. предусмотрена диагностика в виде сообщений. Если этого нет и прога аварийно выходит, то такая прога считается не-работоспособной и требует доработки. Такие ош-ки легко обнаружить.
5) Необх-мо проверять не только. делает ли прога то, для чего она предназначена, но и не делает ли она то, чего не должна делать.
6) Вероятность наличия необнаруженных ош-к в части проги пропорцио-нальна числу ош-к, уже обнаруженной в этой части если в какой-либо части проги обнаружено больше ош-к, чем в другой, то ее н. тестировать более тщательно.
Методы Т-ия прог
Т-ие явл-ся частью «отладки прог». Отладка – это процесс, позволяю-щий получить прогу, функционирующую с требуемыми характ-ками в заданной области изменения вх-х д-х. Отладка вкл-ет: действия, напра-вленные на выявление ош-к(Т-ие); диагностику и локализацию ош-к (опред-ие характера и местонахождения ош-к); внесение исправлений в прогу с целью устранения ош-к.
Последовательно применяемые методы Т-ия: статический, детерминированный, стохастический и в реальном масштабе времени.
Статическое Т-ие – наиболее формализованное, базируется на пра-вилах структурного построения прог и обработки д-х. Проверка степени выполнения этих правил проводится без изменения объективного кода программы путем формального анализа текста проги на языке програм-мирования. Операторы и операнды текста проги анализируются в симво-личном виде, поэтому этот метод иногда называют символическим Т-ем.
Детерминированное Т-ие – наиболее трудоемкое и детализованное, требует многократного выполнения проги с использованием определе-нных, специальным образом подобранных тестовых наборов д-х. Конт-ролируется каждая комбинация исходных д-х и соответ-ие результаты, а также каждое утверждение в спецификации тестируемой проге. Это Т-ие в силу трудоемкости возможно применять для отдельных модулей в про-цессе сборки проги или для небольших и несложных программных комплексов.
Стохастическое Т-ие – этот метод применяется для комплексного Т-ия т.к. при тестировании ПИ невозможно перебрать все комбинации ис-ходных д-х и проконтролировать результаты функц-ия на каждой из них. Т-е предпологает использование в качестве исходных д-х множества случайных величин с соответ-ми распределениями, а для сравнения по-лученных рез-ов используется также распределение случайных величин. Применяется в основном для обнаружения ош-к, а для диагностики и ло-кализации ош-к приходится переходить к детерминированному Т-ию с использование м конкретных значений исходныш д-х из области измене-ния ранее использовавшихся случайных величин. Это Т-ие наилучшим образом подвергается автоматизации при использовании датчиков случайных значений.
Т-ие в реальном масштабе времени – предназначено для Т-ия ПИ для работы в системах реального времени. Проверяются результаты об-работки д-х с учетом времени их поступления, длительности и приорите-тности обработки, динамики использования памяти и взоимодействия с др-ми прогами. При обнаружении отклонения результатов от ожидаемых для локализации ош-к приходится фиксировать время и переходить к детерминир-му Т-ю.
Каждый из этих методов не исключает последовательное использова-ние другого. Требование к повышению качества ПИ предпологает необ-ходимость проверки различными методами Т-ия в зависимости от слож-ности и области применения. Это достаточно эффективно (вероятность того, что при исправлении ош-к не вносятся новые, намного выше).
Основные методы ручного Т-ия: инспекция исходного текста и сквозные просмотры.
Инспекция исходного текста – набор правил и приемов обнаружения ош-к при изучении текста проги группой спец-ов. В группу входят обычно 4 человека: председатель(не автор), автор проги, проектировщик и спец-т по Т-ию. В функции председателя входят: подготовка материалов для заседания, составление графика проведения инспекций, ведение заседания и регистрация всех наденных ош-к. Общая процедура инспекции заключается в том, что председатель заранее раздает листинг проги и проектную спецификацию остальным члена группы для ознако-мления. Заседание начинается с доклада автора о логике проги, о методах и приемах, использованных при ее написании. Далее прога анализируется по списку вопросов для выявления общих ош-к програм-мирования. Председатель д. нести ответственность за результативность дискусии, а участники д. сосредоточить свое внимание на поиске ош-к, а не на их корректировке. По окончании заседания автору передается спи-сок ош-к. Заседание длятся 90-120 мин., скорость просмотра 150 опера-торов в час. Результаты инспекции позволяют программисту увидеть сделанные им ош-ки и способствуют его обучению, а также позволяют оценить стиль программирования.
Сквозные просмотры – рад поцедур и способов обнаружения ош-к, осуществляемых группой спец-ов. Процедура подготовки и проведения заседания отличается тем, что на подготовительном этапе спец-т по Т-ию готовит небольшое число тестов, во время заседания каждый тест мысленно выполняется, и состояние проги отслеживается на бумаге.
Эти мнетоды рекомендуется использовать не только для Т-ия новых прог, но и для модифицируемых.
Методы проектирования текстовых наборов д-х
Чтобы разработать эффективный текстовый набор, необходимо знать ряд методов его построения и придерживаться определенных правил и рекомендаций.
В соотв-ии с методом детерминированного Т-ия при структурном Т-ии ориентируются на построения тестовых наборов по принципу «белого ящика», а при функциональном Т-ии по принципу «черного ящика».
«Белый ящик» - руководствуются критериями: покрытие операторов, узлов ветвления, условий и комбинаторное покрытие условий.
Покрытие операторов предпологает выбор такого тестового набора данных , который вызывает выполнение каждого оператора в проге хотябы один раз. Этот критерий очень слабый, является необходимым, но и недостаточным условием Т-ия.
Покрытие узлов ветвления(покрытие решений) предпологает разработку такого количества тестов, чтобы в каждом узле ветвления был обеспечен переход по веткам «истина» и «ложь» хотябы один раз.
Покрытие условий обычно удовлетворяет критерию покрытия операторов, однако нельзя забывать о некоторых исключениях из этого правила (Пр. 1)Если прога имеет несколько точек входа, то данный оператор выполняется только в том случае, если выполнение проги начинается с соответствующей точки входа. 2)Операторы внутри ON-единиц; выполнение каждого направления перехода необязательно будет вызывать выполнение ON-единиц).
Покрытие условий. Если узел ветвления содержит более одного условия, тогда нужно разработать число тестов, достаточное для того, чтобы выполненные результаты каждого условия в решении выполнялись по крайней мере один раз.
Комбинаторное покрытие условий требует создание такого числа тестов, чтобы всевозможные комбинации результатов условия в каждом решении и все точки входа и ON-единицы выполнялись по крайней мере один раз.
«Черный ящик» программа рассматривается как «черный ящик»(не известны текст программы и ее логика), а исходной инф-ией для тестовых наборов служат спецификации. К стратегии «черного ящика» относятся методы: эквивалентного разбиения, анализ граничных значений, функциональных диаграмм.
Метод эквивалентного разбиения. Построение тестов осуществляется в 2 этапа: 1) выделение классов эквивалентности(КЭ); 2) построение тестов. КЭ – множество входных значений, каждое из которых имеет одинаковую вероятность обнаружения конкретного типа ош-к. КЭ выделяются путем анализа входного условия и разбиением его на две или более групп. Для любого условия существуют правильный и неправильный, т.е. ошибочные вх-е значения, КЭ.
При выделении КЭцелесообразно придерживаться правил:
- Если входное условие описывает область значений, то определяется один правильный КЭ и два неправильных класса.
- Если входное условие описывает конечное число конкретных значений и есть основания пологать, что каждое значение прога трактует особо, то определяются правильный КЭ для каждого значения и один неправильный КЭ.
- Если входное условие описывает ситуация «должно быть», то определяются один правильный КЭ и один неправильный. На основе КЭ нужно стремиться к минимальному числу тестовых наборов, т.е. каждый тест должен покрывать по возможгости большее число правильных КЭ. Для каждого неправильного КЭ строится хотябы один тестовый набор.
Анализ граничных значений предпологает исследование ситуаций, возникающих на границах и вблизи границ эквивалентвых разбиений (Пр. если правильная область значений есть –1,0 до +1,0, то нужно предусмотреть тесты –1,0; 1,0; -1,001 и 1,001).
Метод функциональных диаграмм заключается в преобразовании входной спецификации проги в функциональную диаграмму(диаг-ма причанно-следственных связей) с помощью простейших булевских отношений, построения таблици решений(методом обратной трассировки), которая явл-ся основой для написания эффект-х тестовых наборов д-х.
- В спецификации проги выделяются причины и следствия. Причины – это отдельное входное условие или клас эквив-ти вх-х условий. Следствие – выходное условие или результат преобразования системы. Каждой причине и следствию приписывается уникальный номер.
- Анализируется симантическое содержание спецификаций, которое преобразуется в булевский граф, связывающий причины и следствия. Каждая вершина графа может находиться в состоянии «истина»(1) или «лож»(2).
Базовые символы для записи булевского графа:
- Диаграмма снабжается примечаниями, задающими ограничения и описывающими комбинации причин и(или) следствий, которые являются невозможными из-за синтакс-их или внешних ограничений.
Используются следующие обозначения
- По полученной функциональной диаграмме строится таблица
решений. Для этого поочередно для каждого следствия, значение которого условно устанавливается в 1, прослеживается обратный путь(по диаграмме) ко всем причинам, связанным с этим следствием и фиксируется их состояние. Каждый столбец таблицы решений соответствует тесту.
- Столбцы решений преобразуются в тесты.
Пр.: методом функцион-х диаграмм составить тестовый набор для проги, которая осуществляет контроль записей файла, содержащего инф-ию о студентах института заочной формы обучения (первые две позиции каждой записи могут принимать значения «3М» или «3С») и осуществляет формирование 2-х файлов по факультетам соответственно ОФЭИ и статистика (FM,FC). В случае ош-ки в первой позиции выдается сообщение «ош-ка в первой позиции записи», ош-ка во 2 позиции – «ош-ка во2 позиции записи».
- Выделяем причины и следствия и присваиваем им номера.
Причины: 1 – буква «3» в 1-й позиции; 2- буква «М» в 2-й позиции; 3- буква «С» в 2-й позиции;
Следствия: 20 –формирование файла FM; 21 –формирование файла FC;
22 –сообщение «ош-ки в 1-й позиции»; 23 –сообщение «ош-ки в 2-й позиции»;
- Строится функцион-я диагрвмма, связывающая эти причины и
следствия:
Для наглядности графа
при построении исполь-
зуются промежуточные
вершины 10, 11, 12
- Полученный граф снабжается ограничениями: действительно,
причины 2 и 3 могут выполняться одновременно.
- Строим таблицу решений по графу . Для этого фиксируем в
состоянии “1” поочередно все следствия. Пр.: следствие 22 будет в состоянии “1”, только в том случае, если причина 1, с которой она связана, находится в состоянии “0”. Следствие 20 будет в состоянии “1”, если промежуточная вершина 10 будет в состоянии “1”. Она, в свою очередь, будет находиться в состоянии “1”, только в том случае, когда причина 1 в состоянии “1” и причина 2 в состоянии “1” одновременно, так как связаны логическим И. Таблица решений:
| Причина | 1 2 3 | 0 -- -- | 1 1 -- | 1 -- 1 | -- 0 0 |
| Следствия | 22 20 21 23 | 1 -- -- -- | -- 1 -- -- | -- -- 1 -- | -- -- -- 1 |
Фиксируем в состоянии “1” следствие 21. Она “тождеством” связана с промежуточной вершиной 11, значит, и 11 находится в состоянии ”1”. Это возможно в единственном случае, когда причины 1 и 3 находятся в состоянии “1”. Вершина, не влияющая на состояние данного следствия (в конкретном случае 2), отличается в табл. решений черточкой.
Если следствие 23 находится в состоянии “1”, то промежуточная вершина 12 должна быть в состоянии “0”, т.к. они связаны отношением НЕ. Это возможно в случае, когда обе причина 2 и 3 находятся в состоянии “0”, т.е. во 2-й позиции стоит буква “М”, а не “С”.
- Переходим от таблицы решений к тестовым наборам. Каждый
столбец решений соответст вует одному тесту. Причем “1” озночает выполнение соответствующей причины, а “0” – невыполнение. Прочерк указывает, что эта причина не влияет на значение следствия.
Тестовые наборы: 1. АМ …; 2. 3М …; 3. 3С …; 4. 3А …;
Каждый из рассмотренных методов обеспечивает создание определенного набора тестов, но ни один мз них сам по себе не может дать исчерпывающий набор тестов. Поэтому при разработке тестовых наборов следует придерживаться стратегии различного сочетания всех рассмотренных методов.
Сборка прог при Т-ии
Разработка больших, многомодульных программных комплек-сов требует использавания спец-х способов сборки их при Т-ии.
Прежде чем приступить к Т-ию прогр-го комплекся в целом, нежно, чтобы составляющие его части были тщательно отТ-ны. Это необходимое условие получения надежных програм-х комп-лексов возможно обеспечить на уровне Т-ия отдельных модулей, так как только на этом уровне возможно временное Т-ие нескольких модулей, облегчается задача отладки (т.е. поиска и исправления ош-к) и т.д.
Сборка модулей в прогр-й комплекс может осуществляться 2-мя методами: монолитным и пошаговым. Пошаговая сборка может быть восходящей(снизу-вверх) и нисходящей(сверху-вниз)
Монолитный метод сборки предпологает выполнение автономного Т-ия каждого модуля, а затем их одновременную сборку и Т-ие в комтлексе.
Пошаговое Т-ие предпологает последовательное подключение к набору уже оттестир-х модулей очередного тестир-ого модуля.
Пр.: рассмотрим прогу из 9 модулей.
Монолитное Т-ие:
все 9 модулей Т-ся независимо
др. от др., последовательно или
параллельно. Затем они соби-
раются в одну прогу. Для
автономного Т-ия любого
модуля нужен модуль-драйвер(отлаживающий модуль) и один или несколько модулей-заглушек(иммитаторы). Для рассматриваемого примера модули-драйверы нужны для всех модулей кроме М1, а содули-заглушки нужны для всех, краме М5, М6, М7, М8, М9.
Таким образом, при монолитной сборке для автономного Т-ия составляющих прогр-ый комплекс модулей дополнительно необходимо разработать 8 модулей-драуверов и 9 модулей-заглушек.
Драйвер – это модуль, обеспечивающий вызов и передачу Т-мому модулю необходимых входных д-х и обработку результатов. Заглушка – это модуль, иммитирующий функции модулей, вызываемых тестируемым.
Пошаговая сборка: предпологает, что модули тестируются не автономно, а подключаются поочередно для выполнения теста, к набору уже ранее оттестированных модулей. При таком подходе возможны 2 варианта: сверху-вниз и снизу-вверх.
Сверху-вних: для модуля М1 нужно разработать 3 заглушки. Далее модключается реальный модуль М2, для которого н. предварительно разработать 2 заглушки, и тестируется М1-М2. Затем заглушки М5 заменяется реальным модулем М5 и тестируется М1-М2-М5. Процесс продолжается до тех пор, пока не будет собран весь комплекс.
 Есть возможность некоторого распароллеливания работ и автономного Т-ия цепочек: М1 М2 М5, М1 М4М8,
Есть возможность некоторого распароллеливания работ и автономного Т-ия цепочек: М1 М2 М5, М1 М4М8,М1М3М7. М6 М9
Ясно, что при пошаговой сборке сверху-вниз нужно разработать 9 заглушек, но не нужны драйверы.
Снизу-вверх: тестируются модули низшего уровня М5, М6, М7, М8, М9. Для каждого из них нужен драйвер. Далее параллельно можно проводить Т-ие М5-М2, М6-М2, М7-М3, М8-М4, М9-М4. Затем подключить М1 и провести комплексное тТ-ие всей роги. Таким образом, при восходящем Т-ии н. будет разработать максимум 8 драйверов, но не нужны заглушки.
Сравнивая монолитную и пошаговую сборки прог можно отметить ряд достоинсв и недостатков каждого из них.
Монолитная сборка требует больших затрат, т.к. предпологает дополнительно разработку драйверов и заглушек, а при пошаговой сборке разрабатываются либо загл-ки, либо драйвера.
При пошаговом Т-ии раньше обнаруживаются ош-ки в интерфейсах между модулями, поскольку раньше начинается сборка проги. При монолитном методе модули «не видят др.др.» до последней фазы.
Отладка прог при пошаговом Т-ии легче, т.к. большинство ош-к интерфейса трудно локализовать при монолитном Т-ии. Однако, безусловным преимуществом монолитного метода сборки явл-ся большая возможность распараллеливания работ.
Выбор способа сборки прог зависит от конкретных условий разработки и особенностей тестируемого прогр-го комплекса.
Критерии завершенности Т-ия
При проведении Т-ия встает вопрос о том, когда завершить Т-ие, когда разрабатываемое ПС достигло того уровня надежности, которое может удовлетворить будующих пользователей.
На практике придерживаются 2-х критериев: когда время, отведенное по графику, истекло; когда все тесты выполняются без выявления ош-к.
Оба этих критерия недостаточно точны и логичны, т.к. первому можно удовлетворить, ничего не делая, а второй зависит от количества тестового набора д-х.
Иногда используют критерий, основанный в значительной степени на здравом смысле и инф-ии о количестве ош-к, полученных в процессе Т-ия. Для этого строят график зависимости кол-ва ош-к и времени их появления. По форме полученной кривой можно определить, стоит продолжать Т-ие или нет.
Кол.ош-к
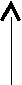
продолжить Т-ие
завершить Т-ие
 время
времяИз графиков видно, что если с увеличением времени тестирования число ошибок растет, то естественно, что тестирование необходимо продол-жать. Если в процессе тестирования в определенный момент наступило снижение числа выявленных ошибок, постепенно стремится к нулю или достигло нуля, то понятно, что процесс тестирования можно завершить.
Более прогрессивным может считаться подход, при котором для определения критерия завершенности тестирования используются количественные показатели надежности, расчитываемые по моделям надежности.
Сопровождение программного изделия на стадии экспл-ции
В соответствии с жизненным циклом ПИ после этапов опытного и промышленного внедрения начинается их эксплуатация. В процессе экспл-ции для поддержания ПИ в актуальном состоянии и увеличения срока эусплуатации, а также организации серийного производства и реализации необходимо осуществлять ряд мероприятий по сопровождению.
Сопрвождение ПИ – процесс модификации существующей прграммы ВМ, обусловленный необходимостью устранения выявленных в ней ошибок и(или) изменения ее функциональных возможностей.
В процессе сопровождения ПИ без изменения основной научной идеи дорабатываются, доотлаживаются, тиражируются и поставляются организациям-пользователям. Деятельность по сопровож-дению ПИ может осуществляться как организацией-разработчиком ПИ, так и специальными организациями-фондодержателями через систему фонда алгоритмов и программ АО Центрпрограммсистем г.Тверь. В последнем случае разработанное ПИ сдается фондодержателю, который осуществляет тиражирование, распространение и централизованное сопровождение.
Распространение ПИ, состоящих на сопровождении в ФАП центрпрограммсистем осуществляется продажей их организациям-пользователям, а также предоставлением промышленных услуг по под-держанию ПИ в актуальном состоянии.
Весь комплект работ по поддержке ПИ в актуальном состоянии в условиях постоянно меняющейся среды функционирования, а также по обеспечению работоспособности иногда называют сопровождением в узком смысле этого понятия.
Программист, занятый сопровождением, не занимается разработками новых программ и, как правило, не является автором конкретной сопровождаемой программы. Но это должен быть специалист высокой квалификации, хорошо знакомый с деталями программы, способный ее модифицировать, расширять функциональные возможности, ликвидиро-вать ошибки, которые могут возникнуть при эксплуатации.
Период сопровождения ПИ, т.е. активного его применения конкрет-ным польз-ем, обычно достигает 5-7 лет. Затраты на сопровождение за этот период могут намного превышать затраты на разработку этого ПИ.
Проблемы снижения затрат на сопровождение ПИ очень актуальны и могут рассматриваться по следующим направлениям:
- повышение производительности труда специалистов в процессе разра-ботки качественного ПИ, т.е. совершенствование систем программиро-вания, развитие и использование языков высокого уровня, структурного програм-ия и т.д.
- разработка типовых ПИ, т.е. таких, которые могут исп-ся многократно большим числом польз-ей с определенной привязкой к конкретным условиям
- разработка ПИ с высокими требованиями к качеству документации, надежности и легкости освоения и внесения изменений.
ФАП Центрпрограммсистем обеспечивает проведение следующих видов работ:
- планирование и координация разработок ПИ
- исправление ош-к, обнаруженных в процессе эксплуатации ПИ в течении определенного времени
- модификация ПИ в процессе экспл-ии
- разработка средств диагностики
- разработка средств обучения
- организация рекламы ПИ, имеющихся в ФАП
- тиражирование ПИ, документации к нему, поставка потребителям и оказание услуг по внедрению в экспл-ию
- обучение спец-ов-потребителей работе с переданным ПИ
Т.о., сопровождение в широком смысле этого понятия включает все перечисленные виды работ, основная цель которых снижение трудоемкости, сокращение сроков разработки и увеличение сроков экспл-ии ПИ, повышение эффект-ти их функц-ия.
Основные показатель качественного ПИ
Сущ-ет неск-ко подходов к опред-нию показателей кач-ва ПИ.
На первом этапе определение показателей кач-ва составляются вопросники, которые позволяют определить степень важности, возможность количественного выражения и др-е св-ва показателей для хар-ки завершенности ПИ. Это одна из немногих хар-к, которая имеет наибольшую исправляющую способность при отладке проги. Она позволяет выявить 37 типов ош-к из 224.
Следующий шаг в оценке данного показателя кач-ва – разработка алгоритма для оценки каждого из вопросов; оценки могут располагаться в интервале от 0 до1.
Результаты оценки могут быть выданы в виде таблицы, в которой представлены перечень элементов(модулей) в ПИ с оценкой О, распределения элементов по интервалам оценок. Кроме того, производится окончательный расчет среднего значения оценки качества модуля по данному показателю по общеизвестной формуле:
где S – средняя оценка качества;
О – оценка элемента;
v – вес элемента, устанавливаемый в пределах 0 – 1;
М – число модулей в ПИ.
Следует подчеркнуть, что основное назначение показателей качества ПИ разработчиков – это определение направления работ по устранению дефектов и совершенствованию работы ПИ. Аналогична оценка остальных показателей качества ПИ, обладающего рапссмотренными хар-ми.
Перечень показателей, по которым оценивается качество ПИ, в основном совпадает с рассотренным ранее. Поэтому выделим только те показатели, расчет которых производится по методике, ранее не рассмотренной.
Показатель эффективности ПИ отражает рациональное использование ресурсов ЭВМ. Это могут быть: ОП, внешняя память, пропускная способность каналов и т.п.
Коэффициент использования ОП ПИ, которая имеет оверлейную структуру, опред-ся по формуле:
где Кin – объем памяти, используемый
на i-том этапе решения задачи
в n-ой реализации;
Tin – длительность этого этапа;
К – емкость ОП;
Т – общее время работы ПИ; m – общее число этапов.
Этот коэфф. можно рассчитать для нескольких программных реализаций и выбрать ту, для которой он наибольший.
Возможно определение коэф-тф использования ОП по формуле:
где Pm – коэф. согласования хар-к ЭВМ,
на которой решается эталонная
и исследуемая программа;
Р2 – коэф. согласования памяти
эталонной программой;
Kp – коэф. использования памяти данной программой.
Чем ближе Кs к 1, тем выше эффек-ть ПИ в части использования ОП.
Коэф-ты эталонных программ могут быть определены статистически при функионировании программ, реализующих подобные задачи.
Общая оценка уровня качества ПИ производится с помощью дифференциального метода. Он основан на сравнении хар-к исследуе-мого ПИ и базового. Вычисляются значения относительных показателей по формуле:
где Рi – значение i-того показателя
качества, оцениваемого ПИ;
Pis – значение соответствующего базового показателя.
Уровень качества оцениваемого ПИ должен быть >=1.
Кроме дифферен-го метода оценки качества сущ-т комплексный метод оценки уровня качества ПИ. Наиболее простой вариант этого метода – расчет средневзвешенных показателей качества.
Средневзвешенный арифметический показатель расчитывается:
где Рi – значение i-того показателя
качества, оцениваемого ПИ;
mi(Q) – весовой коэф. значимости
i-го показателя, входящего в обобщенный показатель;
n – число используемых показателе качества оцениваемого ПИ.
Средневзвешенный геометрический показатель качества расчит-ся:
где mi(V) – весовой коэф. показателя
качества, входящего в обобщенный
показатель V.
Весовые коэф-ты обычно устанавливаются экспертным путем.
Надежность ПИ (Н-ть)
Одной из важнейших хар-к качества ПИ является надежность. Н-ть - это свойство ПИ сохранить работоспособность в течение определенного периода времени, в определенных условиях эксплуатации с учетом последствий для пользователя каждого отказа.
Работоспособным наз-ся такое состояние ПИ, при к-ром оно способно выполнять заданные функции с параметрами, установленными требованиями технического задания (ТЗ). С переходом ПИ в неработоспособное состояние связано событие отказа.
Причины отказа ПИ и технических систем различны. Если для технических систем причиной отказа может быть физический износ узлов и деталей, то ПИ физическому износу не подвержены. Моральный износ, характерный для ПИ, не может быть причиной наступления неработоспособности.
Причиной отказа ПИ является невозможность его полной проверки в процессе Т-ния и испытаний. При эксплуатации ПИ в реальных условиях может возникнуть такая комбинация вход-х д-х, к-рая вызывает отказ. Т.об., работоспособность ПИ зависит от вх-й информации, и чем меньше эта зависимость, тем выше уровень Н-ти.
Для оценки Н-ти используются 3 группы показателей: качественные, порядковые и количественные.
Основные количественные показатели Н-ти ПИ:
1. Вероятность безотказной работы Р(tз) - это вероятность того, что в пределах заданной наработки отказ системы не возникает. Наработка - продолжительность, или объем работы:
P(t3)=P(tt3), где t - случайное время работы ПИ до отказа;
tз - заданная наработка.
2. Вероятность отказа - вероятность того, что в пределах заданной наработки отказ системы возникнет. Это показатель обратный предыдущему: Q(t3)=l-P(t3) .
3. Интенсивность отказов системы (t) - это условная плотность вероятности возникновения отказа ПИ в определенный момент времени при условии, что до этого времени отказ не возник: (t)=f(t)/P(t), где f(t) - плотность вероятности отказа в момент времени t.
Существует следующая связь между (t) и P(t):
В частном случае при =const P(t) = ехр(-t) .
Если в процессе тестирования фиксируется число отказов за определенный временной интервал, то (t) - число отказов в единицу времени.
4. Средняя наработка до отказа Тi - математическое ожидание времени работы ПИ до очередного отказа;
где t - время работы ПИ от (k-l) до k-го
отказа. Иначе среднюю наработку на отказ Ti можно представить:
где ti - время работы ПИ между отказами; n - количество отказов.
5. Среднее время восстановления Тв - математическое ожидание времени восстановления Твi - времени, затраченного на обнаружение и локализацию отказа – tо.л.i , времени устранения Tу.оi, времени пропускной проверки работоспособности – tп.п.i:
tвi=tо.л.i+tу.о.i+tп.п.i, где tвi - время восстановления после i-ro отказа.
где n - количество отказов.
Для этого показателя термин «время» означает время, затраченное специалистом по тестированию на перечисленные виды работ.
6. Коэффициент готовности Кг - вероятность того, что ПИ ожидается в работоспособном состоянии в произвольный момент времени его использования по назначению: Кг=Ti/(Тi+Тв)
Причиной отказа ПИ являются ош-ки, к-рые могут быть вызваны: внутренним свойством ПИ, реакцией ПИ на изменение внешней среды функционирования. Это значит, что даже при самом тщательном Т-нии, если предположить, что удалось избавиться от всех внутренних ошибок, никогда нельзя с полной уверенностью утверждать, что в процессе эксплуатации ПИ отказ не возникнет.
Естественно, необходимо стремиться повысить уровень Н-ти ПИ, но достижение 100%-ной Н-ти лежит за пределами возможного.
Причиной ош-к в ПИ явл-ся нарушение правильности перевода информации (из одного представления в другое). Создание ПИ рассматривается как совокупность процессов перевода информации из одной формы представления в другую с фиксацией множества промежуточных решений, с участием специалистов различного профиля и квалификации. Кроме того, необходимо учитывать возможность взаимного перекрытия процессов и наличие циклов обратной связи. Например, ошибки, сделанные в процессе проектирования, могут быть обнаружены при программировании. Тогда возникает необходимость возврата к предыдущему этапу и устранению ошибки.
Разнообразие и сложность видов деятельности в процессе создания ПИ приводят к появлению множества различных типов ош-к, к-рые нуждаются в систематизации.
Классификация программных ош-к по категориям основана на эмпирических д-х, полученных при разработке различных ПИ.
Под категорией ош-к понимается видовое описание ошибок конкретных типов. В полной классификации выделено более 160 категорий, объединенных в 20 классов. При сборке и анализе данных об ошибках программы следует придерживаться следующих правил:
1. Создать список ош-к.
2. Опред-ть перечень категорий, имеющих причинный характер.
3. Обеспечить получение необходимой информации о происхождении каждой ош-ки.
Для реализации этого пункта целесообразно воспользоваться классификацией, к-рая построена по принципу «сверху - вниз» с необходимым описанием контекста, в к-ром обнаружена ошибка.
На первом уровне классификационной схемы выделены 5 признаков ош-ки:
1. Где произошла ош-ка.
2. На что похожа ош-ка.
3. Как была сделана ош-ка.
4. Когда произошла ош-ка.
5. Почему произошла ош-ка.
Каждый признак представлен в виде набора категорий, разделов и подразделов. Проблема создания надежных ПИ имеет две стороны:
- разработка средств и методов, применение к-рых в процессе создания ПИ позволит обеспечить ему высокие показатели Н-ти;
- развитие самой теории Н-ти: создание стройной системы показателей Н-ти; планирование уровня Н-ти на начальных этапах разработки ПИ; возможность оценить показатели Н-ти по результатам испытаний прог; контроль уровня Н-ти в процессе эксплуатации ПИ и т.д.
ПИ создается коллективами разработчиков на протяжении определенного времени, после чего они могут поставляться пользователям для эксплуатации по назначению.
Это означает переход от кустарных методов создания прог к их промышленному производству, т.е. к становлению новой отрасли материального производства - производству ПС.
С целью управления Н-тью ПС возникает необходимость определения количественных показателей Н-ти на различных этапах его разработки.
Чем обосновывается эта необходимость:
1. Н-ть ПС, оставаясь ценным качеством, достигается в действительности за счет 2 основных моментов: 1) за счет другой характеристики ПС, например объема прог, времени их выполнения, объема внешней и ОП, и т.д.; 2) за счет характеристик процесса создания ПС, таких, как стоимость разработки, материальные ресурсы, выделенные на создание ПС, график выполнения работ и т.д. Желательно, чтобы при выборе характеристик ПС и организации процесса его разработки можно было принимать компромиссные решения.
2. Количественные показатели Н-ти могут использоваться для оценки достигнутого уровня технологии программирования, для выбора метода проектирования будущего программного средства. Применение на практике любой новой идеи по технологии программирования связано с дополнительными затратами. Количественный показатель Н-ти позволяет установить критерии, по к-рым можно оценивать новые методы и вырабатывать рекомендации по их применению.
3. На этапе тестовых испытаний ПС показатели Н-ти могут служить критериями завершенности тестирования, т.к. выявлена высокая степень корреляции показателей Н-ти (например, средней наработки на отказ) с количеством проверок. Это позволяет связать Н-ть с плановыми сроками выполнения программного проекта.
4. При эксплуатации ПС часто возникает необходимость проведения работ по сопровождению. Известно, что внесение изменений, модификация ПС ухудшают Н-ть, поэтому по количественному показателю Н-ти можно судить об эффективности и целесообразности.