
М. Бен-Ари Языки программирования. Практический сравнительный анализ. Предисловие
| Вид материала | Документы |
- Рабочей программы учебной дисциплины языки программирования Уровень основной образовательной, 47.91kb.
- Существуют различные классификации языков программирования, 174.02kb.
- Лекция 3 Инструментальное по. Классификация языков программирования, 90.16kb.
- Аннотация рабочей программы учебной дисциплины языки программирования Направление подготовки, 135.09kb.
- Лекция Языки и системы программирования. Структура данных, 436.98kb.
- Государственное Образовательное Учреждение высшего профессионального образования Московский, 1556.11kb.
- Программа дисциплины Языки и технологии программирования Семестры, 20.19kb.
- Календарный план учебных занятий по дисциплине «Языки и технология программирования», 43.35kb.
- Пояснительная записка Ккурсовой работе по дисциплине "Алгоритмические языки и программирование", 121.92kb.
- Утверждены Методическим Советом иэупс, протокол №8 от 24. 04. 2008г. Языки программирования, 320.93kb.
insert_element(X, [Head Tail], [Head Tail_1]) :-
insert_element(X, Tail, Tail_1).
С процедурной точки зрения программа вполне эффективна, потому что она выполняет сортировку, непосредственно манипулируя подсписками, избегая бесцельного поиска. Как и в функциональном программировании, здесь нет никаких индексов, циклов и явных указателей, и алгоритм легко обобщается для сортировки других объектов.
Типизация и «неуспех»
В языке Prolog нет статического контроля соответствия типов. К сожалению, реакция машины вывода языка Prolog на ошибки, связанные с типом переменных, может вызывать серьезные затруднения для программиста. Предположим, что мы пишем процедуру для вычисления длины списка:
length([], 0). /* Длина пустого списка равна 0 */
length([Head | Tail], N) : - /* Длина списка равна */
length(Tail, N1), /* длине Tail */
N is N1+1. /* плюс 1*/
и случайно вызываем ее с целочисленным значением вместо списка:
?- length(5, Len).
Это не запрещено, потому что вполне возможно, что определение length содержит дополнительную нужную для отождествления формулу.
Машина вывода при вызове lenght в качестве реакции просто даст неуспех, что совсем не то, что вы ожидали. A length была вызвана внутри некоторой другой формулы р, и неуспех length приведет к.неуспеху р (чего вы также не ожидали), и так далее назад по цепочке вызовов. Результатом будут неуправляемые откаты, которые в конце концов приведут к неуспеху первоначальной цели при отсутствии какой-либо очевидной причины. Поиск таких
ошибок — очень трудный процесс трассировки вызовов шаг за шагом, пока ошибка не будет диагностирована.
По этой причине некоторые диалекты языка Prolog типизированы и требуют, чтобы вы объявили, что аргумент является или целым числом, или списком, или некоторым типом, определенным программистом. В типизированном языке Prolog вышеупомянутый вызов был бы ошибкой компиляции. В таких диалектах мы снова встречаем привычный компромисс: обнаружение ошибок во время компиляции за счет меньшей гибкости.
17.4. Более сложные понятия логического программирования
Успех языка Prolog стимулировал появление других языков логического программирования. Многие языки попытались объединить преимущества логического программирования с другими парадигмами программирования типа объектно-ориентированного и функционального программирования. Вероятно, наибольшие усилия были вложены в попытки использовать параллелизм, свойственный логическому программированию. Вспомните, что логическая программа состоит из последовательности формул:
t=>t
(t = tl || t2)(SCtl)=>(S=>t)
(t = tl || 12) (s с t2) => (s => t)
Язык Prolog вычисляет каждую цель последовательно слева направо, но цели можно вычислять и одновременно. Это называется и-параллелизмом из-за конъюнкции, которая соединяет формулы цели. Сопоставляя цели с головами формул программы, язык Prolog проверяет каждую формулу последовательно в том порядке, в котором она встречается в тексте, но можно проверять формулы и одновременно. Это называется или-параллелизмом, потому что каждая цель должна соответствовать первой или второй формуле, и т. д.
При создании параллельных логических языков возникают трудности. Проблема м-параллелизма — это проблема синхронизации: когда одна переменная появляется в двух различных целях, подобно tl в примере, фактически только одна цель может конкретизировать переменную (записывать в нее), и это должно заблокировать другие цели от чтения переменной прежде, чем будет выполнена запись. В мям-параллелизме несколько процессов выполняют параллельный поиск решения, один для каждой формулы процедуры; когда решение найдено, должны быть выполнены некоторые действия, чтобы сообщить этот факт другим процессам, и они могли бы завершить свои поиски.
Много усилий также прилагалось для интеграции функционального и логического программирования. Существует очень близкая связь между математикой функций и логикой, потому что:
y = f(xb ...,х„)
Основные различия между двумя концепциями программирования следующие:
1. Логическое программирование использует (двунаправленную) унификацию, что сильнее (однонаправленного) сопоставления с образцом, используемого в функциональном программировании.
2. Функциональные программы являются однонаправленными в том смысле, что, получив все аргументы, программа возвращает значение. В логических программах любой из аргументов цели может остаться неопределенным, и ответственность за его конкретизацию (instantiating) в соответствии с ответом лежит на унификации.
3. Логическое программирование базируется на машине вывода, которая автоматически ищет ответы.
4. Функциональное программирование оперирует с объектами более высокого уровня абстракции, поскольку функции и типы можно использовать и как данные, в то время как логическое программирование более или менее ограничено формулами на обычных типах данных.
5. Точно так же средства высокого порядка в функциональных языках программирования естественно обобщаются на модули, в то время как логические языки программирования обычно «неструктурированы».
Новая область исследования в логическом программировании — расширение отождествления от простой синтаксической унификации к включению семантической информации. Например, если цель определяет 4 < х < 8 и голова формулы определяет 6 < х < 10, то мы можем заключить, что 6 s х < 8 и что х = 6 или х = 7. Языки, которые включают семантическую информацию при отождествлении, называются ограниченными (constraint) логическими языками программирования, потому что значения ограничиваются уравнениями. Ограниченные логические языки программирования должны базироваться на эффективных алгоритмах для решения уравнений.
Продвижение в этом направлении открывает новые перспективы повышения как уровня абстракции, так и эффективности логических языков программирования.
17.5. Упражнения
1. Вычислите 3 + 4, используя логическое определение сложения.
2. Что произойдет, если программа loop вызвана с целью 1оор(-1)? Как можно исправить программу?
3. Напишите программу, которая не завершается из-за конкретного правила вычисления, принятого в языке Prolog . Напишите программу, которая не завершается из-за правила поиска.
4. По правилам языка Prolog поиск решений осуществляется сначала вглубь (depth-first search), поскольку крайняя левая формула неоднократно выбирается даже после того, как она была заменена. Также можно делать поиск сначала в ширину (breath-first search), выбирая формулы последовательно слева направо и возвращаясь к крайней левой формуле, только когда все другие уже выбраны. Как влияет это правило на успех вычисления?
5. Напишите цель на языке Prolog для следующего запроса:
Есть ли тип автомобиля, который был продан Шэрон, но не Бетти?
Если да, какой это был автомобиль?
6. Изучите встроенную формулу языка Prolog findall и покажите, как она может ответить на следующие запросы:
Сколько автомобилей продал Мартин?
Продал ли Мартин больше автомобилей, чем Шэрон?
7. Напишите программу на языке Prolog для конкатенации списков и сравните ее с программой на языке ML. Выполните программу на языке Prolog в различных «направлениях».
8. Как можно изменить процедуру языка Prolog, чтобы она улавливала несоответствия типов и выдавала сообщение об ошибке?
Какие типы логических программ извлекли бы выгоду из м-параллелиз-ма, а какие — из м/ш-параллелизма?
Глава 18
Java
Java является и языком программирования, и моделью для разработки программ для сетей. Мы начнем обсуждение с описания модели Java, чтобы показать, что модель не зависит от языка. Язык интересен сам по себе, но повышенный интерес к Java вызван больше моделью, чем свойствами языка.
18.1. Модель Java
Можно написать компилятор для языка Java точно так же, как и для любого другого процедурного объектно-ориентированного языка. Модель Java, однако, базируется на концепции интерпретатора (см. рис. 3.2, приведенный в измененной форме как рис. 18.1), подобного интерпретаторам для языка Pascal, которые мы обсуждали в разделе 3.10.

В Java стрелка от J-кода к интерпретатору J-кода представляет не просто поток данных между компонентами среды разработки программного обеспечения. Вместо этого J-код может быть упакован в так называемый аплет (applet), который может быть передан по компьютерной системе сети. Принимающий компьютер выполняет J-код, используя интерпретатор, называющийся виртуальной Java машиной (Java Virtual Machine — JVM). JVM обычно встроена внутрь браузера сети, который является программой поиска и отображения информации, получаемой по сети. Когда браузер определяет, что был получен аплет, он вызывает JVM, чтобы выполнить J-код. Кроме того, модель Java включает стандартные библиотеки для графических интерфейсов пользователя, мультимедиа и сетевой связи, которые отображаются каждой реализацией JVM на средства основной операционной системы. Это является значительным расширением концепции виртуальной машины по сравнению с простым вычислением Р-кода для языка Pascal.
Обратите внимание, что также можно написать обычную программу на Java, которая называется приложением. Приложение не подчиняется ограничениям по защите данных, рассматриваемым ниже. К сожалению, имеются несколько огорчающих различий между программированием аплета и приложения.
Проблема эффективности
Слишком хорошо, чтобы быть правдой? Конечно. Модель Java страдает от тех же самых проблем эффективности, которые присущи любой модели, основанной на интерпретации абстрактного машинного кода. Для относительно простых программ, выполняющихся на мощных персональных компьютерах и рабочих станциях, это не вызовет серьезных проблем, но производительность может установить ограничение на применимость модели Java.
Одно из решений состоит в том, чтобы включить в браузер на получающей стороне компилятор, который переводит абстрактный J-код в машинный код принимающего компьютера. Фактически, компьютер может выполнять этот перевод одновременно или почти одновременно с приемом J-кода; это называется компиляцией «налету». В худшем случае скорость работы возрастет при втором выполнении аплета, который вы загрузили.
Однако это решение — только частичное. Не очень практично встраивать сложный оптимизирующий компилятор внутрь каждого браузера для каждой комбинации компьютера и операционной системы. Тем не менее, для многих типов прикладных программ модель Java вполне подойдет для разработки переносимого программного обеспечения.
Проблема безопасности
Предположим, что вы загружаете аплет и выполняете его на своем компьютере. Откуда вы знаете, что он не собирается затереть ваш жесткий диск? Оценив существенный ущерб от компьютерных вирусов, злонамеренно внедренных во вполне хорошие в других отношениях программы, вы можете понять, как опасно загружать произвольные программы, взятые с удаленного пункта сети. Модель Java использует несколько стратегий устранения (или по крайней мере уменьшения!) возможности того, что аплет, пришедший по сети, повредит программное обеспечение и данные на принявшем его компьютере:
• Строгий контроль соответствия типов как в языке Ada. Идея состоит в том, чтобы устранить случайное или преднамеренное повреждение данных, вызванное выходом индексов за границы массива, произвольными или повисшими указателями и т. д. Мы рассмотрим этот вопрос подробно в следующих разделах.
• Проверка J-кода. Интерпретатор на принимающем компьютере проверяет, действительно ли поток байтов, полученных с удаленного компьютера, состоит из допустимых инструкций J-кода. Это гарантирует, что реально выполняется семантика безопасности модели и что не удастся «обмануть» интерпретатор и причинить вред.
• Ограничения на аплет. Аплету не разрешается выполнять некоторые операции на получающем компьютере, например запись или удаление файлов. Это наиболее проблематичный аспект модели безопасности, потому что хотелось бы писать аплеты, которые могут делать все, что может делать обычная программа.
Ясно, что успех Java зависит от того, является ли модель безопасности достаточно строгой, чтобы предотвратить злонамеренное использование JVM, в то же самое время сохраняя достаточно возможностей для создания полезных программ.
Независимость модели от языка
Проницательный читатель может заметить, что в предыдущем разделе не было ссылок на язык программирования Java! Это сделано специально, потому что модель Java является и эффективной, и полезной, даже если исходный текст аплетов написан на каком-нибудь другом языке. Например, существуют компиляторы, которые переводят Ada95 в J-Код3.
Однако язык Java был разработан вместе с JVM, и семантика языка почти полностью соответствует возможностям модели.
18.2. Язык Java
На первый взгляд синтаксис и семантика языка Java аналогичны принятым в языке C++. Однако в то время как C++ сохраняет почти полную совместимость с языком С, Java отказывается от совместимости ради устранения трудностей, связанных с проблематичными конструкциями языка С. Несмотря на внешнее сходство, языки Java и C++ весьма различны, и программу на C++ не так легко перенести на Java.
В основном языки похожи в следующих областях:
• Элементарные типы данных, выражения и управляющие операторы.
• Функции и параметры.
• Объявления класса, члены класса и достижимость.
• Наследование и динамический полиморфизм.
• Исключения.
В следующих разделах обсуждается пять областей, где проект Java существенно отличается от C++: семантика ссылки, полиморфные структуры данных, инкапсуляция, параллелизм и библиотеки. В упражнениях мы просим вас изучить другие различия между языками.
18.3. Семантика ссылки
Возможно, наихудшее свойство языка С (и C++) — неограниченное и чрезмерное использование указателей. Причем операции с указателями не только трудны для понимания, они чрезвычайно предрасположены к ошибкам, как описано в гл. 8. Ситуация в языке Ada намного лучше, потому что строгий контроль соответствия типов и уровни доступа гарантируют, что использование указателей не приведет к разрушению системы типов, однако структуры данных по-прежнему должны формироваться с помощью указателей.
Язык Java (подобно Eifiel и Smalltalk) использует семантику ссылки вместо семантики значения.
При объявлении переменной непримитивного типа память не выделяется; вместо этого выделяется неявный указатель. Чтобы реально выделить память для переменной, необходим второй шаг. Покажем теперь, как семантика ссылки работает в языке Java.
Массивы
Если вы объявляете массив в языке С, то выделяется память, которую вы запросили (см. рис. 18.2а):
| C |
inta_c[10];
в то время как в языке Java вы получаете только указатель, который может использоваться для обращений к массиву (см. рис. 18.26):
-
Java
int[ ] a Java;
Для размещения массива требуется дополнительная команда (см. рис. 18.2 в):
a Java = new int[10];
-
Java
хотя допустимо объединять объявления с запросом памяти:
-
Java
int[ ] a Java = new int[10];
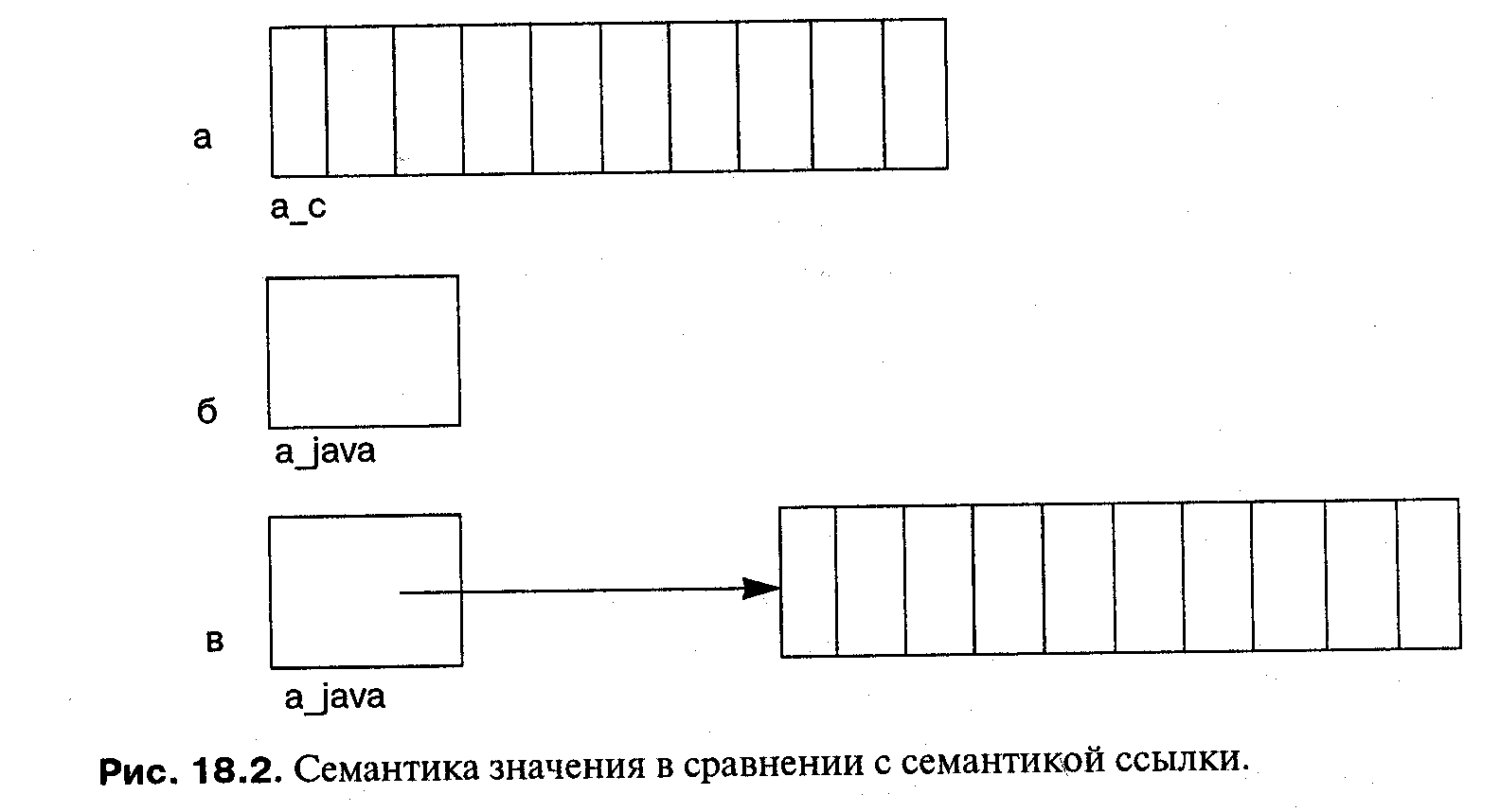
Если вы сравните рис. 18.2 с рис. 8.4, вы увидите, что массивы в Java скорее подобны структурам, определенным в языке C++ как int *a, а не как int a []. Различие заключается в том, что указатель является неявным, поэтому вы не должны заботиться об операциях с указателями или о выделении памяти. К тому же, в случае массива, переменная будет дескриптором массива (см. рис. 5.4), что дает возможность проверять границы при обращениях к массиву.
Отметим, что синтаксис Java проще читается, чем синтаксис C++: a_java is of type int [], что означает «целочисленный массив»; в языке C++ тип компонентов int и указание «масивности» [10] располагаются по разные стороны от имени переменной.
При использовании семантики ссылки разыменование указателя является неявным, поэтому после того, как массив создан, вы обращаетесь к нему как обычно:
for (i = 1; i< 10;i++)
-
Java
a_java[i] = i;
Конечно, косвенный доступ может быть значительно менее эффективен, чем прямой, если его не оптимизирует компилятор.
Отметим, что выделение памяти для объекта и присваивание его переменной могут быть выполнены в любом операторе, в результате чего появляется следующая возможность:
| Java |
…
a_Java = new int[20];
Переменная a_ Java, которая указывала на массив из десяти элементов, теперь указывает на массив из двадцати элементов, и исходный массив становится «мусором» (см. рис. 8.7). Согласно модели Java сборщик мусора должен находиться внутри JVM.
Динамические структуры данных
Как можно создавать списки и деревья без указателей?! Объявления для связанных списков в языках C++ и Ada, описанные в разделе 8.2, казалось бы, показывали, что нам нужен указательный тип для описания типа следующего поля next:
typedef struct node *Ptr;
| C |
int data;
Ptr next;
} node;
Но в Java каждый объект непримитивного типа автоматически является указателем
class Node {
| Java |
Node next;
}
Поле next — это просто указатель на узел, а не сам узел, поэтому в объявлении нет никакой цикличности. Объявление списка — это просто:
| Java |
Node head;
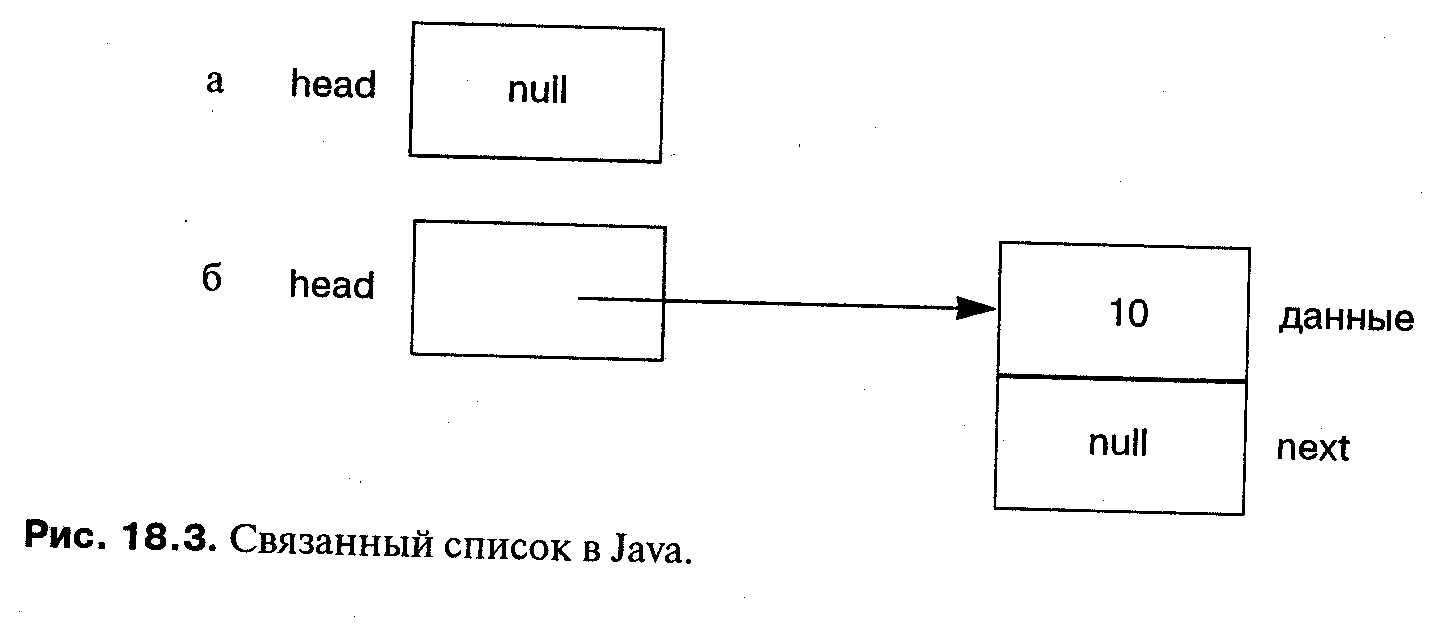
Этот оператор создает указатель переменной с нулевым значением (см. рис. 18.3,а). Подразумевая, что имеется соответствующий конструктор (см. раздел 15.3) для Node, следующий оператор создает узел в головной части списка (см. рис. 18.3,6):
| Java |
head = new Node(10, head);
Проверка равенства и присваивание
Поведение операторов присваивания и проверки равенства в языках с семантикой ссылки может оказаться неожиданным для программистов, которые работали на языке с семантикой значения. Рассмотрим объявления Java:
| Java |
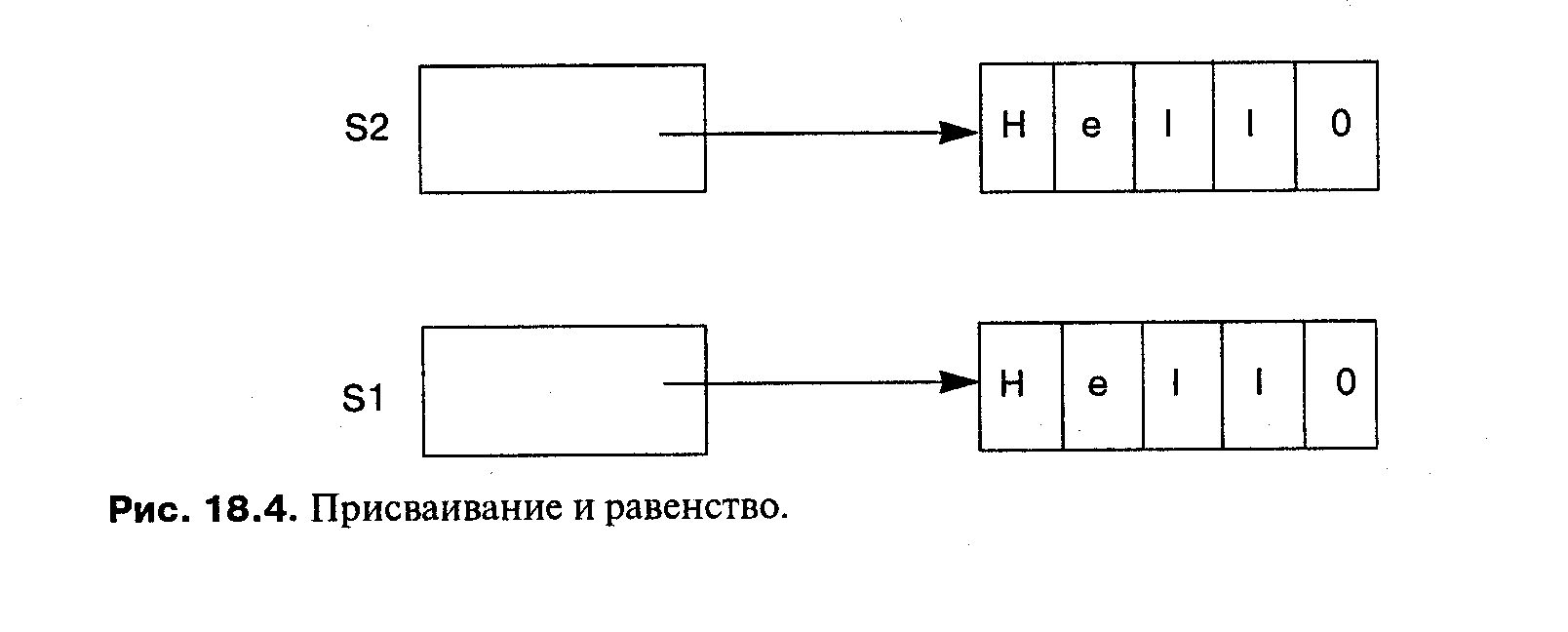
String s2 = new String("Hello");
В результате получается структура данных, показанная на рис. 18.4. Теперь предположим, что мы сравниваем строковые переменные:
| Java |
else System.out.println("Not equal");
программа напечатает Not equal (He равно)! Причина этого хорошо видна из рис. 18.4: переменные являются указателями с разными значениями, и тот факт, что они указывают на равные массивы, не имеет значения. Точно так же, если мы присваиваем одну строку другой s1 = s2, будут присвоены указатели, но никакого копирования значений при этом не будет. В этом случае, конечно, s1 == s2 будет истинно. Java делает различие между мелкими копированием и проверкой равенства и глубокими копированием и сравнением. Последние объявлены в классе Object — общем классе-прародителе — и названы clone и eguals. Предопределенный класс String, например, переопределяет эти операции, поэтому s1.equals(s2) будет истинно. Вы можете также переопределить эти операции, чтобы создать глубокие операции для своих классов.
Подведем итог использования семантики ссылки в Java:
• Можно безопасно управлять гибкими структурами данных.
• Программирование упрощается, потому что не нужны явные указатели.
• Есть определенные издержки, связанные с косвенностью доступа к структурам данных.