
О проектировании данных для клиент-серверных приложений С++Builder
| Вид материала | Документы |
- Мирончик Игорь Янович ClipperIgor@gmail com (496)573-34-22 курс лекций, 28.92kb.
- Исследование быстрого роста данных для лучшего понимания прошлого и тенденций будущего, 25.36kb.
- Учебная программа курса Краткий обзор sql server Краткий обзор программирования в sql, 16.78kb.
- «Базы данных» Общая трудоемкость изучения дисциплины составляет, 138.01kb.
- Методические указания к выполнению курсовой работы «Разработка приложений, предназначенных, 348.71kb.
- Методические рекомендации по использованию sql-ориентированных заданий, выполняемых, 151.55kb.
- Современным предприятиям приходится обрабатывать высокие объемы данных, причем количество, 13.97kb.
- Лекция: Этапы проектирования ис с применением uml: Основные типы uml-диаграмм, используемые, 209.83kb.
- Рабочая учебная программа по дисциплине «Базы данных» Направление №230100 «Информатика, 115.03kb.
- Е серверов приложений является следующим шагом за клиент-серверной технологией и позволяет, 126.48kb.
О проектировании данных для клиент-серверных приложений С++Builder
Известно, что информационные системы, основанные на архитектуре клиент/сервер, могут обладать существенными преимуществами по сравнению с информационными системами, основанными на сетевых версиях настольных СУБД, такими, как высокая производительность, низкий сетевой трафик, встроенные средства обеспечения безопасности и целостности данных, возможность хранения бизнес-правил в базе данных и использования их при создании клиентских приложений. Однако использование всех этих преимуществ может быть эффективным, во-первых, при корректном проектировании данных, и, во-вторых, при соблюдении правил оптимизации как серверной, так и клиентской частей информационной системы.
Проблема проектирования данных носит общий характер и не имеет прямого отношения к выбору средства разработки. Использование современных средств проектирования баз данных, и, в частности, CASE-технологии, существенно облегчает решение этой проблемы, но отнюдь не устраняет ее. Причина этого заключается в том, что ннформационные системы создаются программистами, являющимися чаще всего экспертами в программировании, а вовсе не в той предметной области, для которой создается информационная система, и взаимодействие программиста с заказчиком нередко осложнено чисто терминологическим взаимным непониманием.
^ Создание информационной системы обычно начинается с определения того, для чего она предназначена, из каких автоматизированных рабочих мест она состоит, какие документы или иные информационные объекты являются результатом ее работы. Как правило, все эти сведения содержатся в техническом задании. После этого можно приступить к проектированию данных.
Проектирование данных в значительной степени является тем процессом, где обе категории исполнителей, и эксперты в предметной области, и программисты, должны прийти к соглашению относительно того, какие объекты регистрируются в информационной системе и как они связаны с другими регистрируемыми объектами, а также относительно реализации хранения сведений о них. Соответственно говорят о логическом проектировании как об описании характеристик наборов объектов, сведения о которых будут накапливаться и использоваться в информационной системе, и о физическом проектировании, представляющем собой описание таблиц, индексов, а также триггеров, хранимых процедур, представлений (Views), если таковые поддерживаются данной СУБД.
^
Терминология, используемая при проектировании баз данных
Когда говорят о логическом проектировании, употребляют такие термины, как сущность, связь и атрибут.
Сущность - это множество однотипных объектов, называемых экземплярами, при этом каждый экземпляр индивидуален и отличается от всех остальных экземпляров. Типичными примерами сущностей могут быть сущности "Врач", "Пациент", "Специальность", а примерами экземпляров - "Иванов", "Петров", "терапевт". Как правило, сущности именуются в единственном числе. Сущности рекомендуется снабжать текстовым описанием (хотя бы для того, чтобы через несколько месяцев не забыть, что имелось в виду).
Атрибут - это характеристика сущности. Атрибут выражает одно законченное и определенное свойство сущности (например, дату рождения пациента). При проектировании данных рекомендуется создавать атомарные атрибуты (например, выделение страны и города в отдельные атрибуты при описании адреса в дальнейшем позволит анализировать экземпляры сущности "Пациент" по признаку принадлежности к той или иной стране или тому или иному городу).
Связь - это логическое отношение между сущностями, выражающее некоторое ограничение или бизнес-правило. Связь обычно именуется глаголом.
Связи обладают свойством, называемым кардинальностью. Например: "Заказчик может иметь 0,1 или много заказов" (связь типа "0,1 или много"), "заказ содержит 1 или много товаров" (связь типа "1 или много"), "у автомобиля ровно 4 колеса" (связь типа "ровно n"), "билет резервируется для 0 или 1 пассажира (связь типа "0 или 1"). Наиболее типичным является первый случай, называемый иногда связью "один ко многим".
^ При логическом проектировании нередко также создаются связи "многие ко многим". Типичный пример такой связи - связь врач-пациент, когда любой пациент может лечиться у любого врача. В случае такой связи в общем случае невозможно определить, какой экземпляр одной сущности соответствует выбранному экземпляру другой сущности, что делает неосуществимой физическую (на уровне индексов и триггеров) реализацию такой связи между соответствующими таблицами. Поэтому перед переходом к физической модели все связи "многие ко многим" должны быть переопределены (некоторые CASE-средства, если таковые используются при проектировании данных, делают это автоматически). Обычно для этой цели вводится промежуточная сущность, обладающая ассоциативными атрибутами. В нашем примере объектом, представляющим собой экземпляр подобной сущности, может являться посещение пациентом врача (то есть реальное событие), либо регистрирующий его документ - статистический талон), а ассоциативными атрибутами, отличающими по существу один ее экземпляр от другого, могут быть дата посещения, цель посещения и иные содержащиеся в статистическом талоне сведения.
Говоря о связях, нельзя не остановиться на понятии ключей и ключевых атрибутов. Первичным ключом называется атрибут или группа атрибутов, однозначно идентифицирующих каждый экземпляр сущности. Нередко возможны несколько вариантов выбора первичного ключа. Например, в небольшой организации первичными ключами сущности "сотрудник" могут быть как табельный номер, так и комбинация фамилии, имени и отчества (при уверенности, что в организации нет полных тезок), либо номер и серия паспорта (если паспорта есть у всех сотрудников) . В таких случаях при выборе первичного ключа предпочтение отдается наиболее простым ключам (в данном примере - табельному номеру). Другие кандидаты на роль первичного ключа называются альтернативными ключами.
Отметим, что обязательным требованием, предъявляемым к первичному ключу, является его уникальность - два экземпляра сущности не должны иметь одинаковых значений первичного ключа. Другим важным требованием является компактность - сложный первичный ключ не должен содержать ни одного атрибута, удаление которого не приводило бы к утрате уникальности. Помимо этого, первичный ключ не должен содержать пустых значений. При выборе первичного ключа рекомендуется выбирать атрибут, значение которого не меняется в течение всего времени существования экземпляра (в этом случае табельный номер предпочтительнее фамилии, так как ее можно сменить, вступив в брак).
При создании связей между сущностями (например, "один ко многим") в дочернюю сущность передаются атрибуты, составляющие первичный ключ в родительской сущности. Эти атрибуты образуют в дочерней сущности внешний ключ.
^
Нормализация данных
Одним из основополагающих принципов проектирования данных является принцип нормализации, позволяющей существенно сократить объем хранимой информации и устраняющей аномалии в организации хранения данных. Степень нормализации данных может быть различной.
Говорят, что модель данных соответствует первой нормальной форме, если в таблицах отсутствуют группы повторяющихся значений. Это соответствие достигается путем выделения атрибутов с повторяющимися значениями в отдельные сущности, созданием или выбором для них новых первичных ключей и установлением связей "один ко многим" от новых сущностей к старым. При этом первичные ключи новых сущностей станут внешними ключами для старой сущности.
Говорят, что модель данных соответствует второй нормальной форме, если в сущностях, содержащих составной первичный ключ, неключевые атрибуты зависят от всего первичного ключа. Если же в какой-либо сущности имеется зависимость каких-либо неключевых атрибутов от части ключа, следует выделить их в отдельную сущность, сделав первичным ключом новой сущности ту часть первичного ключа, от которой зависят данные атрибуты, и установить связь "один ко многим" от новой сущности к старой.
Говорят, что модель данных соответствует третьей нормальной форме, если в сущностях отсутствует взаимозависимость между неключевыми атрибутами. Это соответствие достигается путем выделения в отдельную сущность атрибутов с одной и той же зависимостью от неключевого атрибута, использования атрибутов, определяющих эту зависимость, в качестве первичного ключа новой сущности и установки связи "один ко многим" от новой сущности к старой сущности.
Результатом нормализации является модель данных, которую легко поддерживать, не содержащая неопределенностей в данных и повторений данных.
Отметим , что проектирование данных гораздо удобнее производить, используя современные средства проектирования баз данных, и, в частности, CASE-средства, так как с их помощью можно автоматизировать рутинную работу по созданию собственно объектов базы данных на основе созданных логической модели и физической моделей дан
^
Пример проектирования простейшей информационной системы
Рассмотрим в качестве примера проектирование и создание информационной системы для ввода данных о посещаемости хозрасчетной поликлиники пациентами, выполняемое обычно ординаторами факультета управления здравоохранением московской медицинской Академии им. И.М.Сеченова на занятиях, посвященных проектированию информационных систем. Сразу же отметим, что данный пример носит исключительно учебный характер и ни в коем случае не претендует на роль образцовой информационной системы для данной предметной области - в реальной информационной системе подобного назначения число таблиц и набор полей таблиц должно быть существенно большим, да и автоматизированные рабочие места обычно выглядят несколько по-другому.
Целью данной информационной системы является хранение данных о посещениях пациентами поликлиники с целью дальнейшей статистической обработки, или, иными словами, регистрация статистических талонов, содержащих набор сведений, сходный с представленным на рис.1

^ Рис.1. Примерное содержание статистического талона
Итак, центральной сущностью будущей модели данных является посещение врача пациентом. И врач, и пациент участвуют в посещении. В исходной сущности помимо атрибутов, идентифицирующих врача и пациента (которые, следовательно, могут повторяться) присутствуют атрибуты, характеризующие конкретный экземпляр данной сущности - дата посещения, цель посещения, статус (первичное или повторное это посещение), диагноз. При проектировании данных желательно создать также уникальный первичный ключ (номер талона). Это более удобно, чем использование комбинации первичных ключей сущностей "Врач" и "Пациент", так как визитов одного и того же пациента к одному и тому же врачу может быть несколько(рис.2).
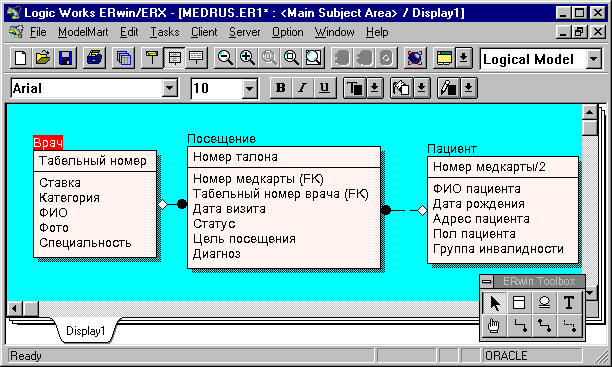
^ Рис.2. Первый вариант модели данных - выделяем сущности "Врач" и "Пациент"
Учитывая возможную повторяемость значений атрибутов, характеризующих диагноз, цель посещения, статус, создадим соответствующие дополнительные сущности, выполняющие роль справочников (вспомним о том, что модель данных должна удовлетворять первой нормальной форме).
Далее рассмотрим сущность "Врач". Очевидно, в поликлинике может быть несколько врачей, имеющих одну и ту же специальность, поэтому имеет смысл выделить понятие "специальность" в отдельную сущность и связать ее посредством внешнего ключа с сущностью "Врач". В результате получим модель данных, похожую на изображенную на рис.3.

Рис.3. Модель данных после нормализации.
Возникает вопрос: а как быть с остальными атрибутами этой сущности? Ведь очевидно, что атрибуты "Ставка" и "Категория" тоже повторяются. Однако атрибут "Категория" - это обычно целое число, и поэтому нет смысла выносить его в отдельный справочник. Что касается атрибута "Ставка", характеризующего продолжительность рабочего времени, то это обычно дробное число (например, 1.25). В принципе можно было бы вынести его в отдельный справочник, но из соображений разумной достаточности в данном примере мы этого делать не будем (нормализуя модель, можно дойти до такого состояния, когда выполнение запросов к таблицам окажется весьма длительным из-за их большого числа).
Теперь рассмотрим сущность "Пациент". Исходя из требования атомарности атрибутов, следует обдумать, является ли таковым адрес пациента. Отметим, что ответ на этот вопрос неоднозначен. Если, например, речь идет о районной поликлинике с делением на участки, очевидно, что следует как минимум выделить в отдельные атрибут номер квартиры и остальную часть адреса (улица, дом, номер корпуса), так как эта остальная часть адреса указывает на принадлежность к определенному участку, а также, возможно, создать сущности "Участок" и "Часть участка" (со сведениями об улице, доме и номере корпуса), связав их между собой и с сущностью "Пациент". С другой стороны, если речь идет о хозрасчетной или ведомственной поликлинике, где адрес может потребоваться главным образом для отправки по почте счетов за услуги, то вполне возможно, что в этом случае адрес может считаться атомарным атрибутом (если, конечно, в дальнейшем не потребуется какая-либо специфическая статистическая обработка данных, связанная с анализом распределения посещений по районам проживания пациентов). Кроме того, если речь идет о районной поликлинике, возможна повторяемость не только частей адресов, но и самих адресов (в случае, если поликлиника обслуживает нескольких жителей одной квартиры). В любом случае, проектируя данные, следует ставить подобные вопросы перед заказчиками и будущими пользователями информационной системы еще на этапе проектирования данных, так как исправления в модели данных гораздо более удобно делать до разработки автоматизированных рабочих мест, нежели исправлять вместе с моделью готовую базу данных и приложения.
Итак, мы создали логическую модель данных. До этого момента можно было думать о предметной области, не вдаваясь в подробности физической реализации разрабатываемой модели. Теперь же следует подумать о физическом проектировании данных, а именно о выборе СУБД, создании таблиц, соответствующих созданным сущностям, типах полей для хранения атрибутов, а также о создании других объектов базы данных, предназначенных для облегчения поиска в таблицах, контроля ссылочной целостности данных, обработки данных, таких, как индексы, триггеры, хранимые процедуры.
Как уже отмечалось в данном цикле статей, использование серверной СУБД значительно облегчает разработку информационных систем по сравнению с использованием плоских таблиц типа dBase или Paradox, так как в последнем случае реализация правил ссылочной целостности, а также механизмов авторизации пользователя и методов ограничения доступа к данным может быть реализована только в приложении (фактически разработчик вынужден "изобретать велосипед при наличии самолетов", создавая в своих приложениях код, уже реализованный в серверах баз данных). Поэтому для реализации данной информационной системы воспользуемся какой-либо серверной СУБД (например, Oracle Workgroup Server 7.2 for Windows NT).Для создания физической модели выберем соответствующую платформу в используемом CASE-средстве и опишем характеристики таблиц, соответствующих описанным в логической модели сущностям, и содержащихся в них полей, соответствующих их атрибутам (рис.4)
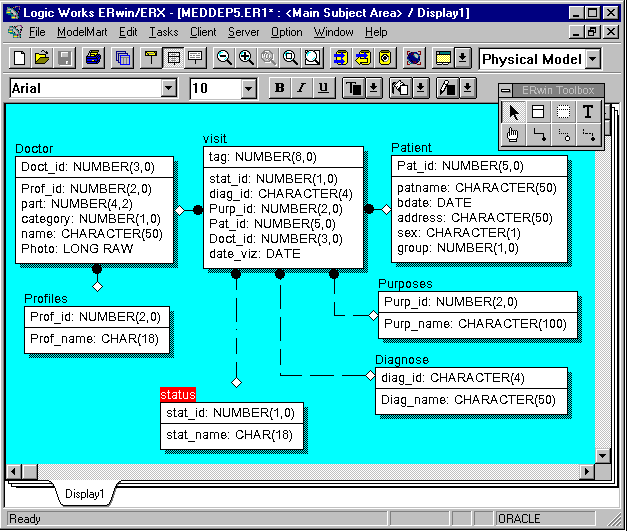
^ Рис.4. Физическая модель данных
Далее опишем свойства связей между таблицами, в частности, реакцию сервера на попытки нарушения ссылочной целостности желании можно также отредактировать тексты сообщений триггеров сервера, передаваемых со стороны клиентского приложения (рис.5): При клиентскому приложению.
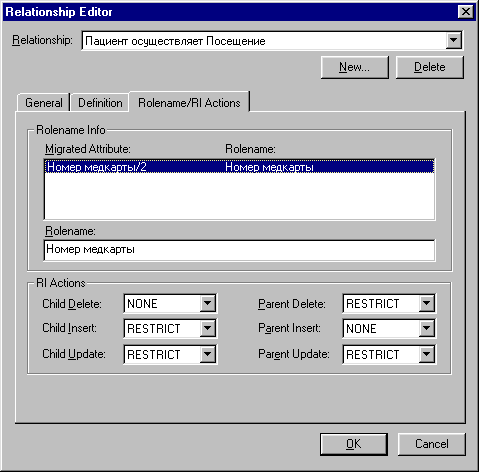
^ Рис.5. Описание реакции сервера на попытки нарушения ссылочной целостности данных
После этого можно создать на сервере схему базы данных, либо сгенерировать DDL-сценарий создания базы данных, представляющий собой набор предложений на процедурном расширении языка SQL данной серверной СУБД) с целью его последующего выполнения. В результате выполнения DDL-сценария на сервере должны быть созданы пустые таблицы, а также иные объекты базы данных, которые можно просмотреть с помощью утилиты Database Explorer (рис.6)
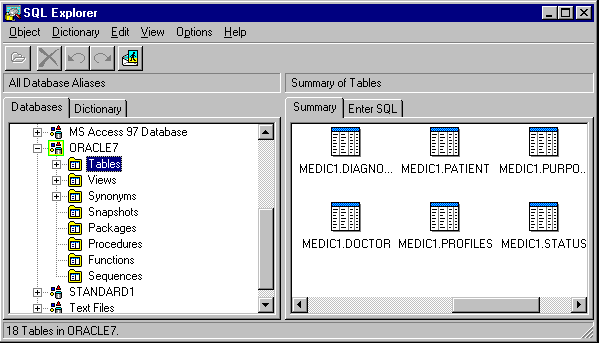
^ Рис.6. Созданные на сервере объекты базы данных
Итак, база данных создана. Теперь, наконец, можно заняться созданием автоматизированных рабочих мест.
^ Создание автоматизированных рабочих мест
Сколько и каких автоматизированных рабочих мест должно быть создано, обычно решается на этапе проектирования данных. В данном простейшем случае очевидно, что работа по вводу данных в информационную систему подразделяется на три основных дочерних работы: ввод сведений о врачах поликлиники (это обычно делается в отделе кадров, и соответственно следует создать АРМ инспектора отдела кадров), ввод сведений о пациентах (рабочее место медрегистратора), ввод сведений о статистических талонах (рабочее место медстатистика). Помимо этого, кто-то должен осуществлять заполнение справочников "Цель посещения" и "Статус" (можно добавить эти функции в АРМ медстатистика, так как объем этих таблиц невелик). Что касается списка диагнозов, он может быть либо введен в базу данных кем-либо из персонала поликлиники, либо импортирован администратором базы данных из какого-либо другого формата, так как этот список основан на реально существующем и неоднократно опубликованном документе.
В общем случае эти рабочие места могут представлять собой отдельные приложения, обращающиеся к определенным таблицам в базе данных, а различные пользователи информационной системы должны иметь соответствующие их служебным обязанностям права доступа к таблицам. Например, представляется разумным запретить медрегистратору и медстатистику вносить изменения в таблицы со списком врачей, а кадровику вносить изменения в списки пациентов. Если исходить из того, что медстатистиков, медрегистраторов и кадровиков может быть несколько, имеет смысл создать в базе данных соответствующие роли (если, конечно, создание ролей поддерживается выбранным сервером), и назначить каждому пользователю соответствующую роль.
Руководствуясь этими соображениями, создадим три роли в базе данных с соответствующими правами доступа к таблицам и три автоматизированных рабочих места для инспектора отдела кадров, медрегистратора и медстатистика, возложив на последнего также обязанность корректировать список диагнозов.
Первые два АРМ-а создать относительно несложно (одно из них предназначено для ввода данных в одну таблицу, другое - в две таблицы, связанные соотношением "один ко многим"). Для этой цели можно воспользоваться утилитой Database Form Wizard и затем внести небольшие изменения в сгенерированные формы и код, в частности, для обеспечения возможности не использовать мышь при массовом вводе данных, а также для установки фокуса ввода в первое поле формы при создании новой записи (в обработчике события OnNewRecord соответствующего компонента TTable). Кроме того, следует исключить возможность ввода пользователем значения поля PROF_ID в список врачей - в этом случае значение этого поля генерируется автоматически в соответствии со значением в выбранной строке списка специальностей, что исключает попытки создания некорректной записи уже на уровне клиентского приложения (рис. 7,8)
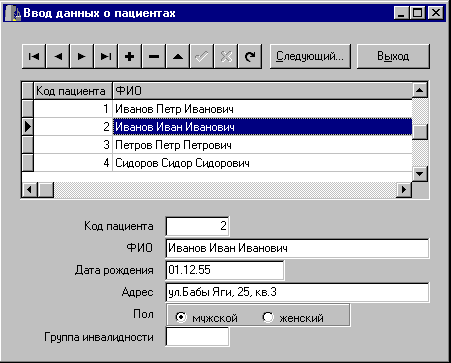
Рис. 7. Автоматизированное рабочее место медрегистратора
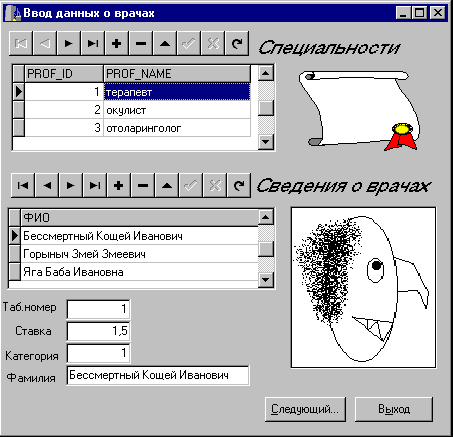
Рис. 8. Автоматизированное рабочее место инспектора отдела кадров.
Автоматизированное рабочее место медстатистика в нашей версии информационной системы используется не только для ввода данных в таблицу статистических талонов, но и для ввода данных в три словарных таблицы - список диагнозов, целей и статусов посещения. Поэтому выполним его в виде многостраничного блокнота. Для ввода словарных таблиц используем компоненты DBGrid (рис.9), а на интерфейсе ввода данных в таблицу статистических талонов остановимся отдельно.
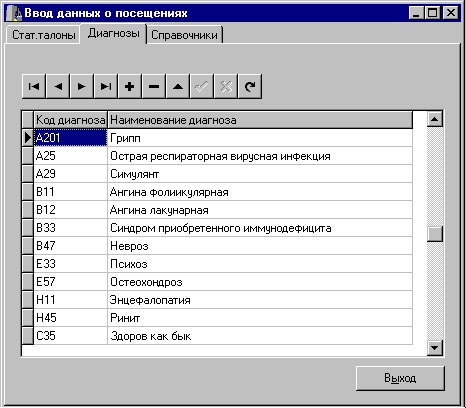

Рис.9. Автоматизированное рабочее место медстатистика - ввод справочных таблиц
Используя серверную СУБД и сгенерировав базу данных с учетом правил ссылочной целостности в соответствии со схемой данных, представленной на рис.4, мы, конечно, можем быть уверены, что ввести в базу данных некорректные значения полей DOCT_ID, DIAG_ID, STAT_ID, PURP_ID, PAT_ID сервер пользователю не даст. Однако это вовсе не означает, что можно поместить на форму набор компонентов TDBEdit для ввода данных в эти поля. Такая реализация интерфейса приведет к совершенно неприемлемым условиям труда пользователя, вводящего данные - он должен помнить наизусть все табельные номера, номера карт и коды во вспомогательных таблицах и в случае ошибок сталкиваться с сообщениями, сгенерированными триггерами сервера. Более разумно использовать выбор нужного значения из списка, поэтому для ввода данных в эти поля поместим на форму компоненты TDBLookupCombBox и выберем в качестве значения ListSource источники данных, связанные с соответствующими словарными таблицами, в качестве значения КеуField - имена их первичных ключей, а в качестве ListField - имена полей, в которых хранятся соответствующие названия статусов, диагнозов, имена врачей и др. Теперь пользователь может выбирать значения полей DOCT_ID, DIAG_ID, STAT_ID, PURP_ID, PAT_ID из выпадающих списков, в которых содержатся не коды, а символьные строки (рис 10). Таким образом, мы избавились от необходимости непосредственного ввода пользователем значений внешних ключей, заменив его выбором из соответствующих списков.

^ Рис.10. Автоматизированное рабочее место медстатистика - ввод статистических талонов.
Такая реализация автоматизированного рабочего места, разумеется, не является идеальной. Если список статусов и целей посещения обычно действительно невелик, и выпадающий список здесь вполне уместен, то список пациентов, скорее всего, будет составлять не меньше сотни строк. Поэтому вполне уместно либо иметь этот список в отсортированном по алфавиту виде (например, создав соответствующий индекс в базе данных, либо используя в качестве источника данных компонент TQuery с соответствующим предложением Order by). В этом случае при наборе начала фамилии пациента указатель в списке автоматически установится на ближайшую подходящую позицию. Примерно так же можно поступить и со списком диагнозов. Возможен также ввод каких-либо признаков (например, специальности врача или типа заболевания) и дальнейший выбор диагноза или фамилии врача из отфильтрованного списка, причем такая фильтрация записей может быть реализована как с помощью параметризованного запроса, выполняемого на сервере, так и с помощью локального фильтра в клиентском приложении. Какую из реализаций выбрать, зависит от размера справочной таблицы - локальные фильтры могут быть более производительны, чем параметризованный запрос, если таблица целиком кэшируется на рабочей станции, то есть ее объем сравним с емкостью буферов для кэширования данных.
Отметим также, что в списке пациентов могут быть полные тезки. В этом случае следует создать в списке пациентов вычисляемое поле (например, включающее фамилию, имя , отчество и дату рождения пациента) и использовать его для поиска.
^ О генерации уникальных первичных ключей
Еще одним серьезным недостатком подобной информационной системы является необходимость ввода пользователем значений первичных ключей, что в данном примере особенно критично для списка пациентов и списка посещений. В этом случае весьма высока возможность ошибки, связанной с вводом значения, уже имеющегося в базе данных. Причиной может быть как ошибка самого оператора, так и попытка одновременного ввода одного и того же значения с разных рабочих станций сети.
Проблема подобного рода может быть решена с помощью генерации уникальных первичных ключей как в клиентском приложении, так и на сервере. В приложении генерация первичного ключа осуществляется, например, путем создания длинной случайной символьной строки с помощью какого-либо генератора, использующего в качестве параметров время с точностью до долей секунды и какие-либо уникальные характеристики рабочей станции так, чтобы вероятность повторов была чрезвычайно мала. Этот способ обычно используется с теми СУБД, которые сами не поддерживают возможность генерации таких ключей (например, dBase). Он неудобен, так как при наличии нескольких различных приложений, использующих одну и ту же базу данных, требуется в каждом из них повторить код, отвечающий за генерацию первичных ключей.
Более предпочтительным способом является использование возможностей генерации первичных ключей, содержащихся в самой СУБД. Эту возможность поддерживает большинство серверных СУБД, а также некоторые настольные СУБД (например, Paradox, позволяющий создавать в таблицах автоинкрементные поля).
В качестве примера рассмотрим, как можно использовать возможности генерации первичных ключей, предоставляемые Oracle, для автоматического заполнения поля TAG таблицы VISIT. С этой целью воспользуемся генератором последовательностей Oracle, создающим последовательности уникальных целых чисел, используемых клиентскими приложениями в качестве значений первичных ключей. Создадим такую последовательность с помощью следующего набора операторов (исполнить их можно с помощью SQL Plus или с помощью утилиты Database Explorer):
create sequence seqtag
start with 200
increment by 1
nominvalue
nomaxvalue
nocycle
nocache
На главной форме приложения заменим компонент TDBEdit, в который ранее вводилось значение поля TAG, компонентом TDBText, чтобы исключить возможность ввода этого значения пользователем. В модуль данных нашего клиентского приложения поместим компонент TUpdateSQL, выберем его имя в качестве значения свойства UpdateObject компонента TTable, с помощью которого вводятся данные в таблицу VISIT, сгенерируем операторы SQL для вставки, удаления и модификации записи и изменим оператор SQL для вставки следующим образом:
Insert into VISIT
^ (TAG, STAT_ID, DIAG_ID, PURP_ID, PAT_ID, DOCT_ID, DATE_VIZ)
values
(seqtag.NEXTVAL, :STAT_ID, :DIAG_ID, :PURP_ID, :PAT_ID, :DOCT_ID, :DATE_VIZ)
Далее изменим свойство CachedUpdates этого компонента TTable на true и обеспечим возможность сохранять в базе данных изменения, накопленные в кэше, переопределив реакцию на нажатие кнопок компонента TDBNavigator либо введя для этой цели либо дополнительные интерфейсные элементы (например, кнопку):
void __fastcall TMAINFORM::Button1Click(TObject *Sender)
{
DataModule2->Table1->ApplyUpdates();
DataModule2->Table1->CommitUpdates();
}
Метод ApplyUpdates() нужен для сохранения изменений в базе данных, а метод CommitUpdates() - для очистки кэша.
Скомпилировав и выполнив приложение, можно убедиться в том, что первичные ключи в базе данных генерируются автоматически (например, с помощью Database Explorer). Окончательный вид приложения представлен на рис.11.
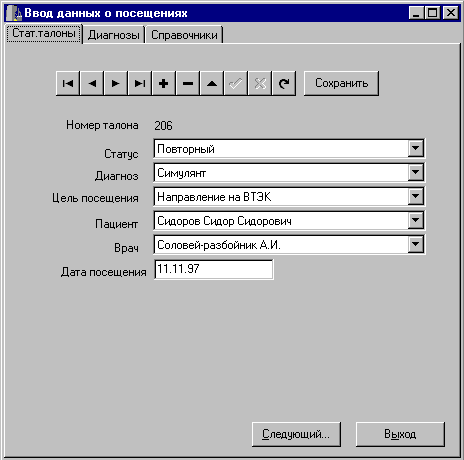
Рис. 11. Окончательный вид главной формы АРМ медстатистика.
Этот способ создания первичных ключей в любом случае намного более удобен, чем использование ручного ввода их значений. Однако и этот способ является не самым эффективным, так как операторы SQL для вставки записи содержатся в клиентском приложении.
Другой способ генерации ключей с использованием последовательности реализуется путем создания триггера, выполняющегося перед вставкой записи в таблицу, примерно следующего вида:
^ CREATE TRIGGER MEDIC1.VI_INS BEFORE INSERT
ON MEDIC1.VISIT
FOR EACH ROW
BEGIN
UPDATE VISIT SET TAG=seqtag.nextval where TAG=10;
END;
Триггер можно создать, например, с помощью утилиты SQL Plus, и с помощью SQL Explorer можно просматривать его текст (рис.12):
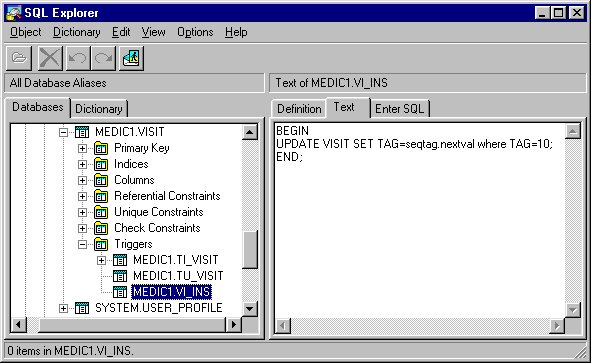
^ Рис.12. Просмотр текста созданного триггера с помощью SQL Explorer.
В этом случае компонент TUpdateSQL уже не требуется, но при этом нужно добавить в приложение код, присваивающий значение полю TAG, так как в противном случае клиентское приложение не допустит отправки запроса на сервер:
void __fastcall TDataModule2::Table1BeforeInsert(TDataSet *DataSet)
{
Table1TAG->Value=10;
}
Concluzii
Итак, в результате мы имеем базу данных, содержащую семь таблиц и ряд других объектов (индексов, триггеров, последовательностей) для реализации правил ссылоччной целостности, а также три автоматизированных рабочих места. Отметим, что, несмотря на наличие некоторых недостатков (все-таки это лишь учебный пример), такая реализация информационной системы является гораздо более эффективной, чем реализация в виде приложения, использующего одну-единственную таблицу, запись которой идентична содержанию статистического талона (типа изображенной на рис.1).
Другими словами, при использовании основополагающих принципов проектирования данных в созданных информационных системах исключается повторяемость данных и, соответственно, уменьшается возможность ошибок, а также многократно экономится время, затрачиваемое на ввод данных. Помимо этого, более просто осуществляется разделение информационной системы на автоматизированные рабочие места в соответствии с должностными функциями пользователей. Все это наглядно подтверждает необходимость начинать любую, даже самую простую, информационную систему с создания логической и физической моделей данных, и лишь потом приступать к созданию собственно клиентских приложений.