
Вопрос №3 Принципы проектирования информационного обеспечения программного комплекса
| Вид материала | Документы |
СодержаниеВопрос №15 Модели баз данных Модели баз данных Сетевая модель базы данных Реляционная модель базы данных Функциональная зависимость Пятая нормальная форма |
- Е. В. Чепин московский инженерно-физический институт (государственный университет), 30.11kb.
- Рабочая программа учебной дисциплины (модуля) case-средства проектирования программного, 143.56kb.
- Технология программирования, 643.21kb.
- Базы данных, 3110.93kb.
- А. А. Дюмин московский инженерно-физический институт (государственный университет), 30.84kb.
- Учебно-методический комплекс дисциплины разработка и стандартизация программных средств, 362.73kb.
- Методика выбора программного обеспечения турфирмой Антон Россихин (само-софт), 34.31kb.
- С. Д. Романин московский инженерно-физический институт (государственный университет), 24.74kb.
- Примерная программа наименование дисциплины Проектирование и архитектура программных, 182.2kb.
- Рабочая программа учебной дисциплины "системы автоматизированного проектирования электроустановок, 119.83kb.
Вопрос №15 Модели баз данных
База данных — это централизованное хранилище данных, обеспечивающее хранение, доступ, первичную обработку и поиск информации (или - это интегральная совокупность данных с централизованным управлением). Во многих современных вычислительных машинах, как аппаратные средства, так и операционные системы сейчас предусматривают реализацию специальных функций, необходимых для работы с базами данных. Благодаря этому пользователь получает в свое распоряжение гораздо более широкие возможности манипулирования данными, чем те, которые обычно предусматривались в традиционных файловых системах.
Независимость программ от данных означает, что существующие прикладные программы можно менять, а новые прикладные программы разрабатывать, не модифицируя структуру хранения данных и стратегию доступа к данным. Распределенная база данных — это база данных, которая разнесена по различным вычислительным машинам сети. Словарь данных описывает данные, содержащиеся в базе данных.
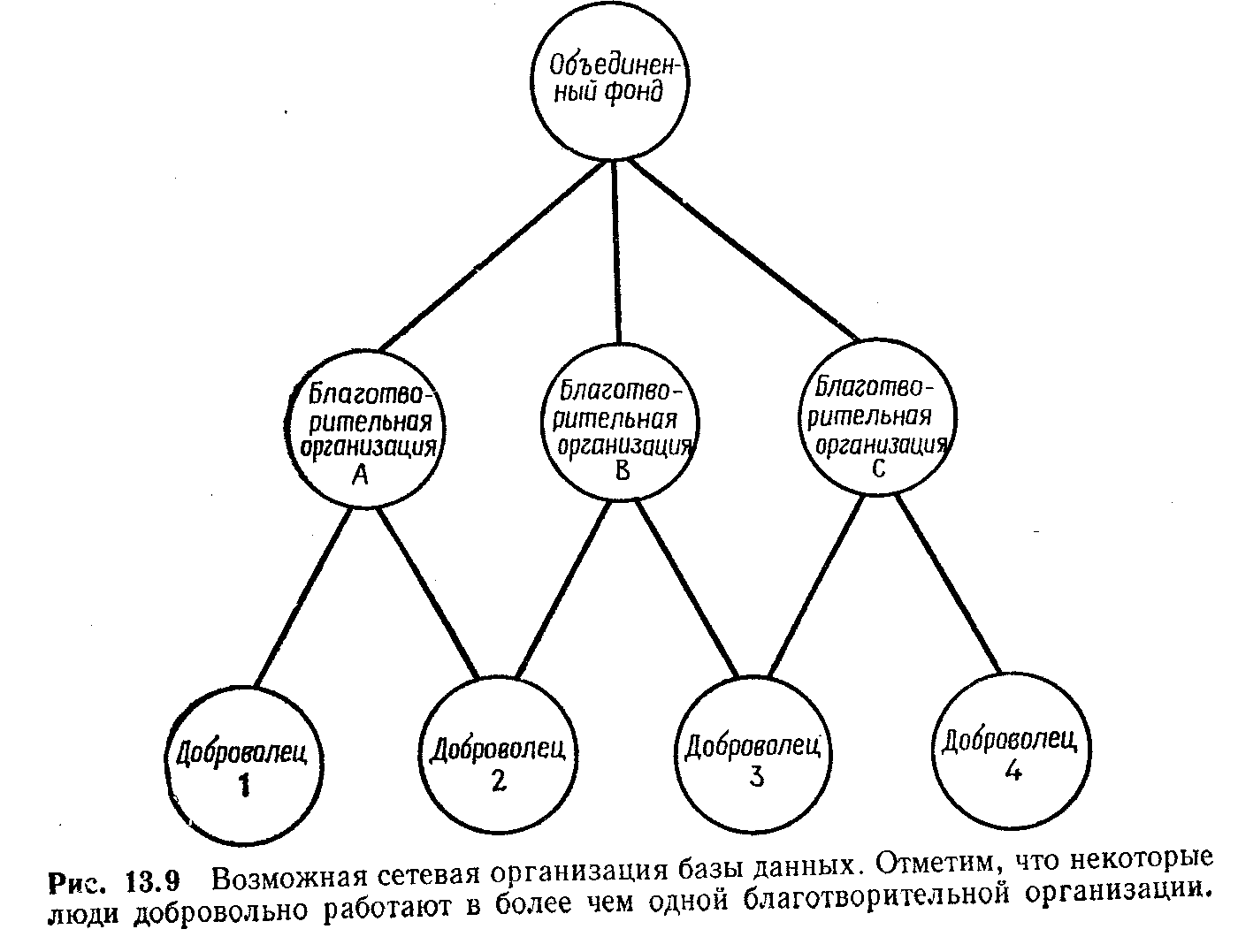
Существуют три наиболее популярные организации баз данных: иерархическая, сетевая и реляционная.
Иерархическая модель предусматривает организацию данных в соответствии с отношениями типа «отец — сын»; каждый сын может иметь только одного отца, однако каждый отец может иметь много сыновей. Иерархическая база данных удобна для ведения и поисков нужных данных, однако она ограничивает возможности пользователя с точки зрения гибкого определения сложных взаимозависимостей между данными.
Сетевая модель позволяет достаточно удобно выражать взаимозависимости общего вида. Однако получающиеся при этом структуры данных могут оказаться сложными для понимания, модификации или реконструирования в случае отказа.
Реляционная модель базы данных обладает многими преимуществами по сравнению с иерархической и сетевой моделями. Табличное представление данных удобнее для понимания и реализации. Базы данных, построенные в соответствии с другими моделями, легко можно преобразовать в реляционную структуру. Такие удобные операции, как проекция и соединение, позволяют без всяких сложностей создавать новые отношения. Защиту секретных и конфиденциальных данных от несанкционированного доступа можно обеспечивать, помещая их в отдельные отношения. Реляционная база данных характеризуется тем, что модификация данных упрощается, а наглядность и четкость структуры базы данных существенно улучшаются.
Модели баз данных
Широкое распространение получили три различные модели баз данных: (1) иерархическая, (2) сетевая и (3) реляционная.
- Иерархическая модель базы данных
Ц
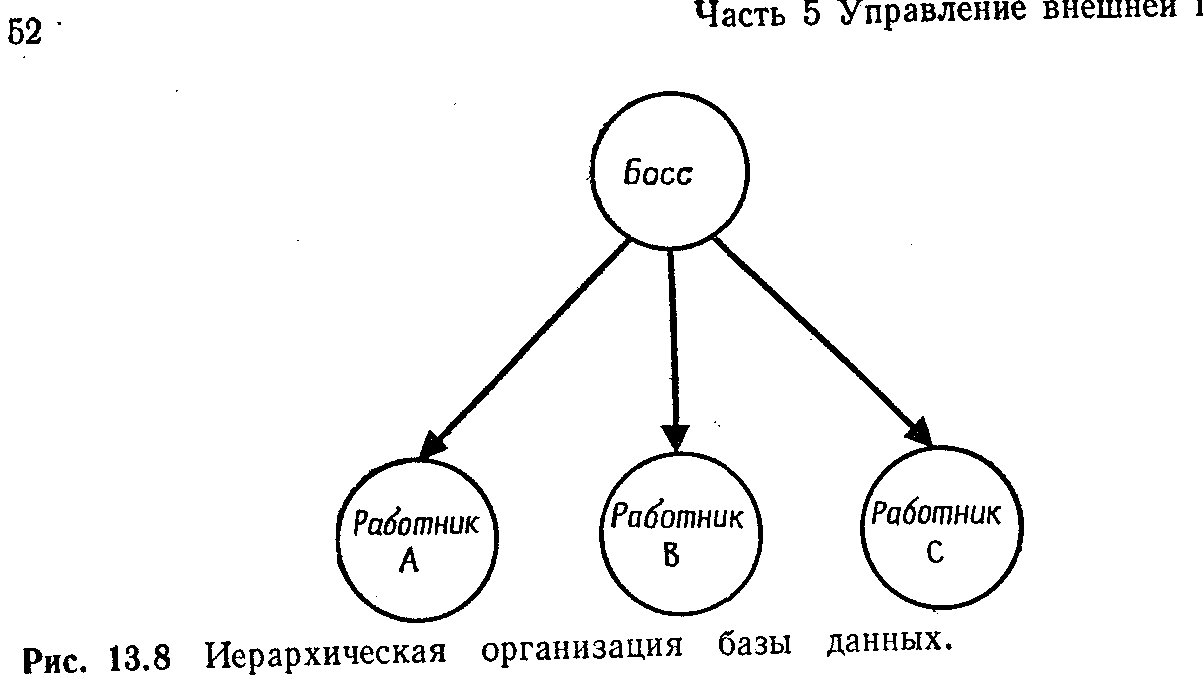
енность метода баз данных определяется преимущественно тем, что он позволяет явным образом указывать отношения между элементами данных. В иерархической модели (рис. 13.8) элементы данных связываются отношением «отец—сын»; каждый отец может иметь много сыновей, однако каждый сын может иметь только одного отца. Иерархическая организация не предусматривает выражения отношений, в которых сыновья связываются более чем с одним отцом. Такая негибкость заставляет многих разработчиков выбирать другую модель базы данных. Если, однако, отношения между данными в действительности являются иерархическими, то иерархическая модель вполне приемлема, так как ее легко реализовать, модифицировать и производить в ней поиск нужных данных.
Сетевая модель базы данных
Сетевая модель (рис. 13.9) является более гибкой, чем иерархическая Она позволяет сыновьям иметь связь с многими отцами, а также предусматривает возможность выражения достаточно произвольных взаимозависимостей. Недостаток сетевой модели заключается в том, что некоторые сетевые структуры в определенных случаях начинают походить на «крысиное гнездо», где указатели смотрят в самых различных направлениях. С подобной структурой сложно разбираться, ее трудно модифицировать или реконструировать в случае отказа. Сетевая структура полезна для стабильных условий работы, когда н
еобходимо иметь возможность выражать сложные взаимозависимости данных, чтобы обеспечить эффективное использование базы данных. В более динамичных условиях, когда следует ожидать значительного роста базы данных или когда с большой вероятностью в базу данных будут вводиться новые параметры и отношения, сетевой моделью лучше не пользоваться.
Реляционная модель базы данных
В последнее время большой интерес среди специалистов вызывает реляционная модель базы данных, которую предложил Кодд (Со70, Со72). Реляционная модель обладает многими преимуществами по сравнению с иерархической и сетевой моделями.
Э.Кодд предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение) и теории отношений. Он показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение – relation. Термин нормализация также обязан своим появлением Э. Кодду, который определил различные нормальные формы отношений.
Отношение – это двумерная таблица. Каждая строка в таблице содержит данные, относящиеся к некоторой вещи или какой-то ее части. Каждый столбец таблицы описывает какой-либо атрибут этой вещи. Иногда строки называются кортежами, а столбцы – атрибутами.
Термины отношение, кортеж и атрибут пришли из реляционной математики, которая является теоретическим источником этой модели. Программисты предпочитают употреблять аналогичные термины файл, запись и поле, а большинство пользователей находят более удобными термины таблица, строка и столбец.
Чтобы таблица была отношением, она должна удовлетворять определенным ограничениям. Во-первых, значения в ячейках таблицы должны быть одиночными – ни повторяющиеся группы, ни массивы не допускаются. Все записи в столбце должны быть одного типа. Каждый столбец имеет уникальное имя; порядок столбцов в таблице не существенен. Наконец, в отношении не может быть двух одинаковых строк, и порядок строк не имеет значения.
Рис. 13.10. Отношение СОТРУДНИК
| | Атрибут 1 | Атрибут 2 | Атрибут 3 | Атрибут 4 |
| | Имя | Возраст | Пол | ТабельныйНомер |
| Кортеж 1 | Андерсон | 21 | Ж | 010110 |
| Кортеж 2 | Деккер | 22 | М | 010100 |
| . | Гловер | 22 | М | 101000 |
| Кортеж 3 | Джексон | 21 | Ж | 201100 |
Рисунок 13.10 представляет отдельный экземпляр отношения. Обобщенный формат отношения – СОТРУДНИК (Имя, Возраст, Пол, ТабельныйНомер) – называется структурой отношения, и именно это большинство людей имеют в виду, используя термин отношение.
Но не все отношения одинаково желательны. Таблица, отвечающая минимальному определению отношения, может иметь неэффективную или неподходящую структуру. Для некоторых отношений изменение данных может привести к нежелательным последствиям, называемым аномалиями модификации. Аномалии могут быть устранены путем разбиения исходного отношения на два или более новых отношения. Любое отношение, содержащее две или более темы, следует разбить на два или более отношения, каждое из которых будет содержать одну тему. Этот процесс составляет суть нормализации.
Чтобы понять, что такое нормализация, нужно определить два важных термина: функциональная зависимость и ключ.
Функциональная зависимость – это связь между атрибутами. Предположим, что если мы знаем значение одного атрибута, то можем вычислить (или найти) значение другого атрибута. Например, если нам известен номер счета клиента, то мы можем определить состояние его счета. В таком случае можно сказать, что атрибут СостояниеСчетаКлиента функционально зависит от атрибута НомерСчетаКлиента.
Ключ – это группа из одного или более атрибутов, которая уникальным образом идентифицирует строку.
В своей работе Кодд и другие определили первую, вторую и третью нормальные формы (1НФ, 2НФ и 3НФ). Позднее была введена нормальная форма Бойса-Кодда (НФБК), а затем были определены четвертая и пятая нормальные формы. Эти нормальные формы являются вложенными. То есть отношение во второй нормальной форме является также отношением в первой нормальной форме, а отношение в 5НФ находится одновременно в 4НФ, НФБК, 3НФ, 2НФ и 1НФ.
Эти нормальные формы помогали, но у них было и серьезное ограничение. Не было теории, гарантирующей, что какая-либо из этих форм устранит все аномалии: каждая форма могла устранить только определенные их виды. Эта ситуация разрешилась в 1981г., когда Р. Фагин ввел новую нормальную форму, которую он назвал доменно-ключевой нормальной формой, или ДКНФ. В своей статье Фагин показал, что отношение в ДКНФ свободно от всех аномалий модификации, независимо от их типа. Он также показал, что любое отношение, свободное от аномалий модификации, должно находиться в ДКНФ.
Рис. 13.11. Отношение СЕКЦИИ
| НомерСтудента | Секция | Плата |
| 100 | Лыжи | 200 |
| 100 | Гольф | 65 |
| 150 | Плавание | 50 |
| 175 | Сквош | 50 |
| 175 | Плавание | 50 |
| 200 | Плавание | 50 |
| 200 | Гольф | 65 |
Нормальные формы:
- О любой таблице данных, удовлетворяющей определению отношения, говорят, что она находится в первой нормальной форме. Отношение на рис. 13.11 находится в первой нормальной форме.
- Отношение находится во второй нормальной форме, если все его неключевые атрибуты зависят от всего ключа.
Рассмотрим отношение СЕКЦИИ на рис. 13.11. Это отношение имеет аномалии модификации. Если мы удалим строку с данными о студенте с номером 175, мы потеряем тот факт, что абонент в секции сквоша стоит $50. Кроме того мы не сможем ввести информацию о секции, пока в эту секцию не запишется хотя бы один студент. Проблема с этим отношением состоит в том, что оно содержит зависимость, затрагивающую только часть ключа. Ключом является комбинация (НомерСтудента, Секция), но отношение содержит зависимость Секция>Плата. Детерминант этой зависимости (Секция) представляет собой лишь часть ключа (НомерСтудента, Секция). В этом случае мы можем сказать, что атрибут Плата частично зависит от ключа таблицы. Аномалий модификации не было бы, если бы Плата зависела от всего ключа. Чтобы устранить эти аномалии, мы должны разделить отношение на два отношения.
Рис. 13.12. Разбиение отношения СЕКЦИЯ на два отношения
| НомерСтудента | Секция | | Секция | Плата |
| 100 | Лыжи | | Лыжи | 200 |
| 100 | Гольф | | Гольф | 65 |
| 150 | Плавание | | Плавание | 50 |
| 175 | Сквош | | Сквош | 50 |
| 175 | Плавание | | | |
| 200 | Плавание | | | |
| 200 | Гольф | | | |
- Отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме и не имеет транзитивных зависимостей.
Рассмотрим отношение ПРОЖИВАНИЕ на рис. 13.13. Ключом здесь является НомерСтудента, и имеются функциональные зависимости НомерСтудента>Общежитие и Общежитие>Плата. Эти зависимости возникают потому, что каждый студент живет только в одном общежитии, и каждое общежитие взимает со всех проживающих в нем студентов одинаковую плату.
Поскольку НомерСтудента определяет атрибут Общежитие, а Общежитие определяет атрибут Плата, то косвенным образом НомерСтудента>Плата. Такая структура функциональных зависимостей называется транзитивной зависимостью, поскольку атрибут НомерСтудента определяет атрибут Плата через атрибут Общежитие.
Атрибут НомерСтудента является одиночным ключом, следовательно, отношение находится во 2НФ. Но оно имеет аномалию удаления: если мы удалим вторую строку, то потеряем не только тот факт, что студент №150 живет в Ингерсол, но и тот факт, что проживание в этом общежитии стоит $3100. И аномалию вставки: мы не можем записать тот факт, что плата за проживание в Кэрриг составляет $3500, пока туда не поселится хотя бы один студент.
Чтобы удалить аномалии, необходимо устранить транзитивную зависимость, разделив отношение ПРОЖИВАНИЕ на два отношения.
Рис. 13.13. Устранение транзитивной зависимости в отношении ПРОЖИВАНИЕ
| НомерСтудента | Общежитие | Плата |
| 100 | Рэндольф | 3200 |
| 150 | Ингерсол | 3100 |
| 200 | Рэндольф | 3200 |
| 250 | Питкин | 3100 |
| 300 | Рэндольф | 3200 |
| НомерСтудента | Общежитие | | Общежитие | Плата |
| 100 | Рэндольф | | Рэндольф | 3200 |
| 150 | Ингерсол | | Ингерсол | 3100 |
| 200 | Рэндольф | | Питкин | 3100 |
| 250 | Питкин | | | |
| 300 | Рэндольф | | | |
- Отношение находится в НФБК, если каждый детерминант является ключом-кандидатом.
Рассмотрим отношение КОНСУЛЬТАНТ на рис. 13.14. Пусть требования к этому отношению таковы:
- студент может иметь одну или несколько специальностей,
- консультантами по одному и тому же предмету могут быть несколько преподавателей,
- каждый преподаватель может быть консультантом только по одной специальности.
Поскольку студенты могут специализироваться в нескольких областях, атрибут НомерСтудента не определяет атрибут Специальность. Более того, так как студент может иметь несколько консультантов, НомерСтудента не определяет и атрибут Преподаватель. Таким образом, НомерСтудента сам по себе не может быть ключом.
Комбинация (НомерСтудента, Специальность) определяет атрибут Преподаватель, а комбинация (НомерСтудента, Преподаватель) определяет атрибут Специальность. Следовательно, любая из этих комбинаций может быть ключом. Два или более атрибута или группы атрибутов, которые могут быть ключом, называются ключами-кандидатами. Тот из ключей-кандидатов, который выбирается в качестве ключа, называется первичным ключом.
Кроме ключей-кандидатов, есть еще одна функциональная зависимость: атрибут Преподаватель определяет атрибут Специальность (любой из преподавателей является консультантом только по одному предмету; следовательно, зная имя преподавателя, мы можем определить специальность). Таким образом, Преподаватель является детерминантом.
Несмотря на то, что отношение находится в 3НФ, оно имеет аномалии. Если мы удалим строку с информацией о студенте с номером 300, мы потеряем тот факт, что Перлс является консультантом по психологии. А записать в базу тот факт, что Кейнс является консультантом по экономике, мы не сможем, пока не появится хотя бы один студент, специализирующийся на экономике. Отношение КОНСУЛЬТАНТ можно разбить на два отношения, не имеющие аномалий.
Рис. 13.14. Получение нормальной формы Бойса-Кодда для отношения КОНСУЛЬТАНТ
| НомерСтудента | Специальность | Преподаватель |
| 100 | Математика | Коши |
| 150 | Психология | Юнг |
| 200 | Математика | Риман |
| 250 | Математика | Коши |
| 300 | Психология | Перлс |
| 300 | Математика | Риман |
| НомерСтудента | Преподаватель | | Преподаватель | Специальность |
| 100 | Коши | | Коши | Математика |
| 150 | Юнг | | Юнг | Психология |
| 200 | Риман | | Риман | Математика |
| 250 | Коши | | Перлс | Психология |
| 300 | Перлс | | | |
| 300 | Риман | | | |
- Отношение находится в четвертой нормальной форме, если оно находится в НФБК и не имеет многозначных зависимостей.
Рассмотрим отношение СТУДЕНТ на рис. 13.15. Предположим, что студенты могут иметь несколько специальностей и заниматься в нескольких различных секциях. В таком случае единственным ключом является комбинация (НомерСтудента, Специальность, Секция).
Одному и тому же значению атрибута НомерСтудента может соответствовать много значений атрибута Специальность. Помимо того, одному и тому же значению атрибута НомерСтудента может соответствовать много значений атрибута Секция.
Такая зависимость атрибутов называется многозначной зависимостью. Многозначные зависимости приводят к аномалиям модификации. Для начала надо обратить внимание на избыточность данных. Во вторых, допустим, что студентка с номером 100 решила записаться в секцию лыж, и поэтому мы добавляем в таблицу строку [100,Музыка,Лыжи]. В данный момент из отношения можно сделать вывод, что студентка 100 занимается лыжами только как музыкант, но не как бухгалтер. Чтобы данные имели согласованный характер, мы должны добавить столько строк, сколько имеется специальностей, и в каждой из них указать секцию лыж. Таким образом, мы должны добавить строку [100,Бухгалтерский учет,Лыжи], как показано на рис. 13.16. Это аномалия обновления: требуется слишком много модификаций, чтобы внести одно простое изменение.
Чтобы устранить эти аномалии, мы должны избавиться от многозначной зависимости. Мы сделаем это, создав два отношения, в каждом из которых будут храниться данные только по одному многозначному атрибуту, как показано на рис. 13.17.
Рис. 13.15. Отношение с многозначными зависимостями
| НомерСтудента | Специальность | Секция |
| 100 | Музыка | Плавание |
| 100 | Бухгалтерский учет | Плавание |
| 100 | Музыка | Теннис |
| 100 | Бухгалтерский учет | Теннис |
| 150 | Математика | Бег |
Рис. 13.16. Отношение СТУДЕНТ с аномалиями вставки
| НомерСтудента | Специальность | Секция |
| 100 | Музыка | Лыжи |
| 100 | Бухгалтерский учет | Лыжи |
| 100 | Музыка | Плавание |
| 100 | Бухгалтерский учет | Плавание |
| 100 | Музыка | Теннис |
| 100 | Бухгалтерский учет | Теннис |
| 150 | Математика | Бег |
Рис. 13.16. Устранение многозначной зависимости
| НомерСтудента | Специальность | | НомерСтудента | Секция |
| 100 | Музыка | | 100 | Лыжи |
| 100 | Бухгалтерский учет | | 100 | Плавание |
| 150 | Математика | | 100 | Теннис |
| | | | 150 | Бег |
| | | | | |
| | | | | |
- Пятая нормальная форма связана с зависимостями, которые имеют несколько неопределенный характер. Речь идет об отношениях, которые можно разделить на несколько более мелких отношений, но затем невозможно восстановить. Условия, при которых возникает эта ситуация, не имеют ясной, интуитивной интерпретации.
- Отношение находится в доменно-ключевой нормальной форме, если каждое ограничение, накладываемое на это отношение, является логическим следствием определения доменов и ключей.
Фагин определяет ограничение как любое правило, регулирующее возможные статические значения атрибутов и достаточно точное для того, чтобы можно было установить, выполняется оно или нет. Правила редактирования, ограничения взаимоотношений и структуры отношений, функциональные зависимости и многозначные зависимости являются примерами таких отношений. Отсюда исключаются ограничения, относящиеся к изменениям значений данных, или ограничения, зависящие от времени. Например, правило «Зарплата продавца за текущий период не может быть меньше, чем за предыдущий период» не подпадает под определение ограничения, которое дал Фагин.
Домен – это описание допустимых значений атрибута.
По сравнению с иерархической и сетевой моделями реляционная модель базы данных обладает многими преимуществами:
- Табличное представление данных, применяемое в реляционной модели, делает ее простой для понимания пользователями и для реализации в физической системе базы данных.
- Практически любой другой тип структуры базы данных относительно легко превратить в реляционную схему. Таким образом, эту схему можно рассматривать как один из видов универсального представления данных.
- Операции проекции и соединения (в числе других) легко реализовать, и они позволяют легко создавать новые отношения, необходимые для конкретных приложений.
- Управление доступом к секретным и конфиденциальным данным реализуется без всяких сложностей. Такие данные просто помещаются в отдельные отношения, а доступ к этим отношениям контролируется при помощи тех или иных средств проверки полномочий или защиты от несанкционированного доступа.
- Реляционные структуры гораздо проще модифицировать, чем иерархические или сетевые. Для условий, где гибкость является обязательным требованием, это может стать решающим фактором.
- Реляционная структура делает базу данных гораздо более наглядной и удобной для поисков. Гораздо проще разбираться в табличных данных, чем «раскручивать», быть может, произвольно сложенные связи элементов данных в механизме с указателями.
- Предложенная теория нормализации явилась толчком для создания языков манипулирования данными реляционного типа. Среди них наиболее распространены SQL (структурированный язык запросов) и QBE (запросы по образцу).