
Курс, 4 семестр, 51 час Лекции Саратов 2007 Часть Системное программное обеспечение 3
| Вид материала | Лекции |
Содержание2.3.Простые типы данных ассемблера |
- Методика рейтингового контроля знаний студентов по дисциплине «Системное программное, 42.76kb.
- Методические указания по выполнению курсовых работ по дисциплине «Системное программное, 710.3kb.
- М. В. Ломоносова Факультет вычислительной математики и кибернетики Н. В. Вдовикина,, 2124.49kb.
- Рабочая учебная программа по дисциплине «Системное программное обеспечение» Направление, 78.8kb.
- Вопросы к экзамену по дисциплине «Системное программное обеспечение» 4 курс (1 семестр), 17.38kb.
- Методические указания и контрольные задания по дисциплине системное программное обеспечение, 196.97kb.
- Курс. 2 семестр. Специальность «Программное обеспечение вт и ас» Понятие системы,, 19.28kb.
- Семестр Осенний Весенний лекции 36 час. 18 час. Лабораторные з анятия 36 час. 36 час., 487.51kb.
- Управление экономикой и создание экономических информационных систем Изучив данную, 148.93kb.
- Курс 2 Семестры 3,4 Всего аудиторных часов 136, в том числе: 3 семестр 58 час; 4 семестр, 252.62kb.
2.3.Простые типы данных ассемблера
Любая программа предназначена для обработки некоторой информации, поэтому вопрос о том, как описать данные с использованием средств языка, обычно встает одним из первых. TASM предоставляет очень широкий набор средств описания и обработки данных, который вполне сравним с аналогичными средствами некоторых языков высокого уровня.
Начнем обсуждение с правил описания простых типов данных, которые являются базовыми для описания более сложных типов. Для описания простых типов данных в программе используются специальные директивы резервирования и инициализации данных, которые по сути являются указаниями транслятору на выделение определенного объема памяти. Если проводить аналогию с языками высокого уровня, то директивы резервирования и инициализации данных являются определениями переменных. Машинного эквивалента этим директивам нет, просто транслятор, обрабатывая каждую такую директиву, выделяет необходимое количество байт памяти и при необходимости инициализирует эту область некоторым значением. Директивы резервирования и инициализации данных простых типов имеют формат, показанный на рис. 5.17.
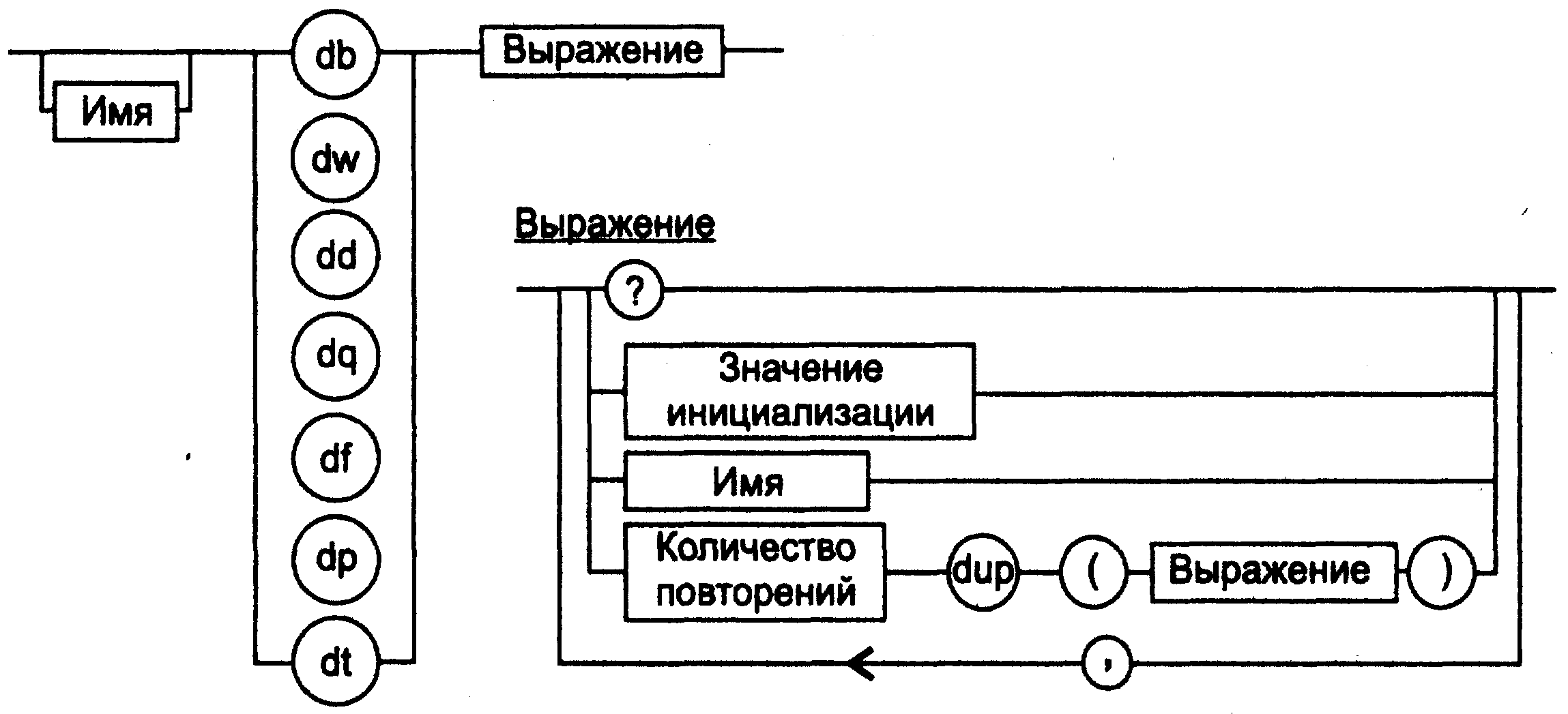
Рис. 5.17. Директивы описания данных простых типов
На рис. 5.17 использованы следующие обозначения.
- ? показывает, что содержимое поля не определено, то есть при задании директивы с таким значением выражения содержимое выделенного участка физической памяти изменяться не будет. Фактически создается неинициализированная переменная;
- значение инициализации — значение элемента данных, которое будет занесено в память после загрузки программы. Фактически создается инициализированная переменная, в качестве которой могут выступать константы, строки символов, константные и адресные выражения в зависимости от типа данных. Подробная информация приведена в Справочнике;
- выражение — итеративная конструкция с синтаксисом, описанным на рис. 5.17. Эта конструкция позволяет повторить последовательное занесение в физическую память выражения в скобках п раз.
- имя — некоторое символическое имя метки или ячейки памяти в сегменте данных, используемое в программе.
На рис. 5.17 представлены следующие поддерживаемые TASM директивы резервирования и инициализации данных:
- db — резервирование памяти для данных размером 1 байт;
- dw — резервирование памяти для данных размером 2 байта;
- dd — резервирование памяти для данных размером 4 байта;
- df — резервирование памяти для данных размером 6 байтов;
- dp — резервирование памяти для данных размером 6 байтов;
- dq — резервирование памяти для данных размером 8 байтов;
- dt — резервирование памяти для данных размером 10 байтов.
Очень важно уяснить себе порядок размещения данных в памяти. Он напрямую связан с логикой работы микропроцессора с данными. Микропроцессоры Intel требуют следования данных в памяти по принципу: младший байт по младшему адресу.
Для иллюстрации данного принципа рассмотрим листинг 5.2, в котором определим сегмент данных. В этом сегменте данных приведено несколько директив описания простых типов данных. Используя последовательность шагов, описанную на уроке 3, получим загрузочный модуль.
Листинг 5.2. Пример использования директив резервирования и инициализации данных
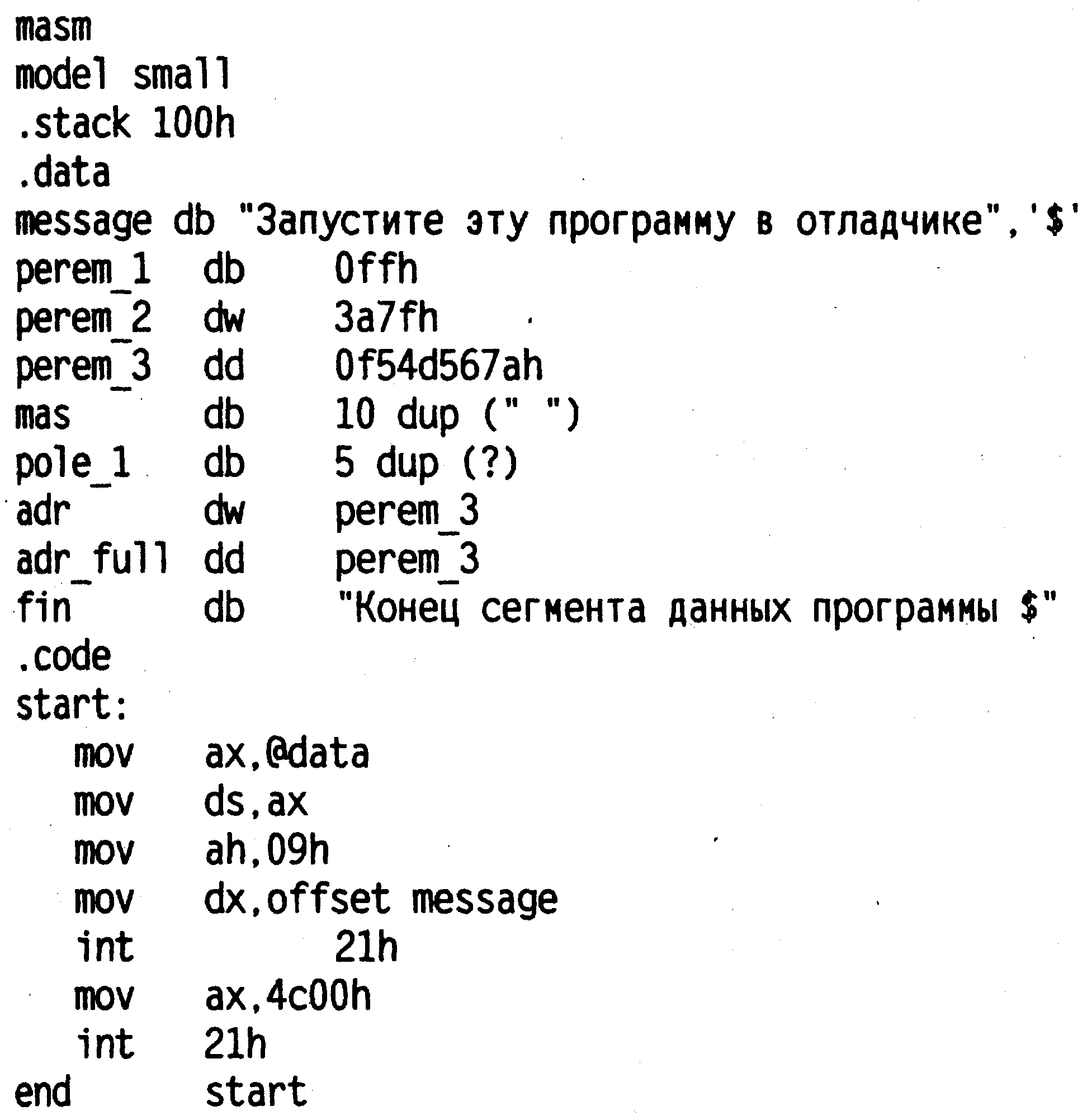
Теперь наша цель — посмотреть, как выглядит сегмент данных программы листинга 5.2 в памяти компьютера. Это даст нам возможность обсудить практическую реализацию обозначенного нами принципа размещения данных. Для этого запустим отладчик td.exe, входящий в комплект поставки TASM. Опишем этот процесс по шагам.
Введем код из листинга 5.2 в файл с названием prg_5_2.asm. Как мы договорились раньше, все манипуляции с файлом будем производить в директории work, где уже содержатся все необходимые для компиляции, компоновки и отладки файлы пакета TASM.
Запустим процесс трансляции файла следующей командой:
tasm.exe /zi prg_5_2.asm ...
После устранения синтаксических ошибок запустим процесс компоновки объектного файла:
tlink.exe /v prg_5_2.obj
Теперь можно производить отладку:
td prg_5_2.exe
Если все было сделано правильно, то в отладчике откроется окно Module с исходным текстом программы. Для того чтобы с помощью отладчика просмотреть область памяти, содержащую наш сегмент данных, необходимо открыть окно Dump. Это делается с помощью команды главного меню View > Dump.
Но одного открытия окна недостаточно; нужно еще настроить его на адрес начала сегмента данных. Этот адрес должен содержаться в сегментном регистре ds, но, как сказано выше, перед началом выполнения программы адрес в ds не соответствует началу сегмента данных. Нужно перед первым обращением к любому символическому имени произвести загрузку действительного физического адреса сегмента данных. Обычно это действие не откладывают в долгий ящик и производят первыми двумя командами в сегменте кода. Действительный физический адрес сегмента данных извлекают как значение предопределенной переменной @data. В нашей программе эти действия выполняют команды:
mov ax, @data
mov ds, ax
Для того чтобы посмотреть содержимое нашего сегмента данных, нужно остановить выполнение программы после этих двух команд. Это можно сделать, если перевести отладчик в пошаговый режим с помощью клавиш F7 или F8. Нажмите два раза F8. Теперь можно открыть окно Dump.
В окне Dump вызовите контекстное меню, щелкнув правой кнопкой мыши. В появившемся контекстном меню выберите команду Goto. Появится диалоговое окно, в котором нужно ввести начальный адрес памяти, начиная с которого будет выводиться информация в окне Dump. Синтаксис задания этого адреса должен соответствовать синтаксису задания адресного операнда в программе на ассемблере (см. начало этого урока). Мы бы хотели увидеть содержимое памяти для нашего сегмента данных, начиная с его начала, поэтому введем ds:0000. Для удобства, если сегмент достаточно велик, это окно можно распахнуть на весь экран. Для этого нужно щелкнуть на символе «» в правом верхнем углу окна Dump. Вид экрана показан на рис. 5.18.
Обсудим рис. 5.18. На нем вы видите данные вашего сегмента в двух представлениях: шестнадцатеричном и символьном. Видно, что со смещением 0000 расположены символы, входящие в строку message. Она занимает 34 байта. После нее следует байт, имеющий в сегменте данных символическое имя perem_l, содержимое этого байта 0ffh. Теперь обратите внимание на то, как размещены в памяти байты, входящие в слово, обозначенное символическим именем регеm_2. Сначала следует байт со значением 7fh, а затем со значением 3ah. Как видите, в памяти действительно сначала расположен младший байт значения, а затем старший. Теперь посмотрите и самостоятельно проанализируйте размещение байтов для поля, обозначенного символическим именем perem_3. Оставшуюся часть сегмента данных вы можете также проанализировать самостоятельно. Остановимся лишь на двух специфических особенностях использования директив резервирования и инициализации памяти. Речь идет о случае использования в поле операндов директив dw и dd символического имени из поля имя этой или другой директивы резервирования и инициализации памяти. В нашем примере сегмента данных это директивы с именами adr и adr_full. Когда транслятор встречает директивы описания памяти с подобными операндами, то он формирует в памяти значения адресов тех переменных, чьи имена были указаны в качестве операндов. В зависимости от директивы, применяемой для получения такого адреса, формируется либо полный адрес (директива dd) в виде двух байтов сегментного адреса и двух байтов смещения, либо только смещение (директива dw). Найдите в дампе на рис. 5.18 поля, соответствующие именам adr и adr_full и проанализируйте их содержимое.
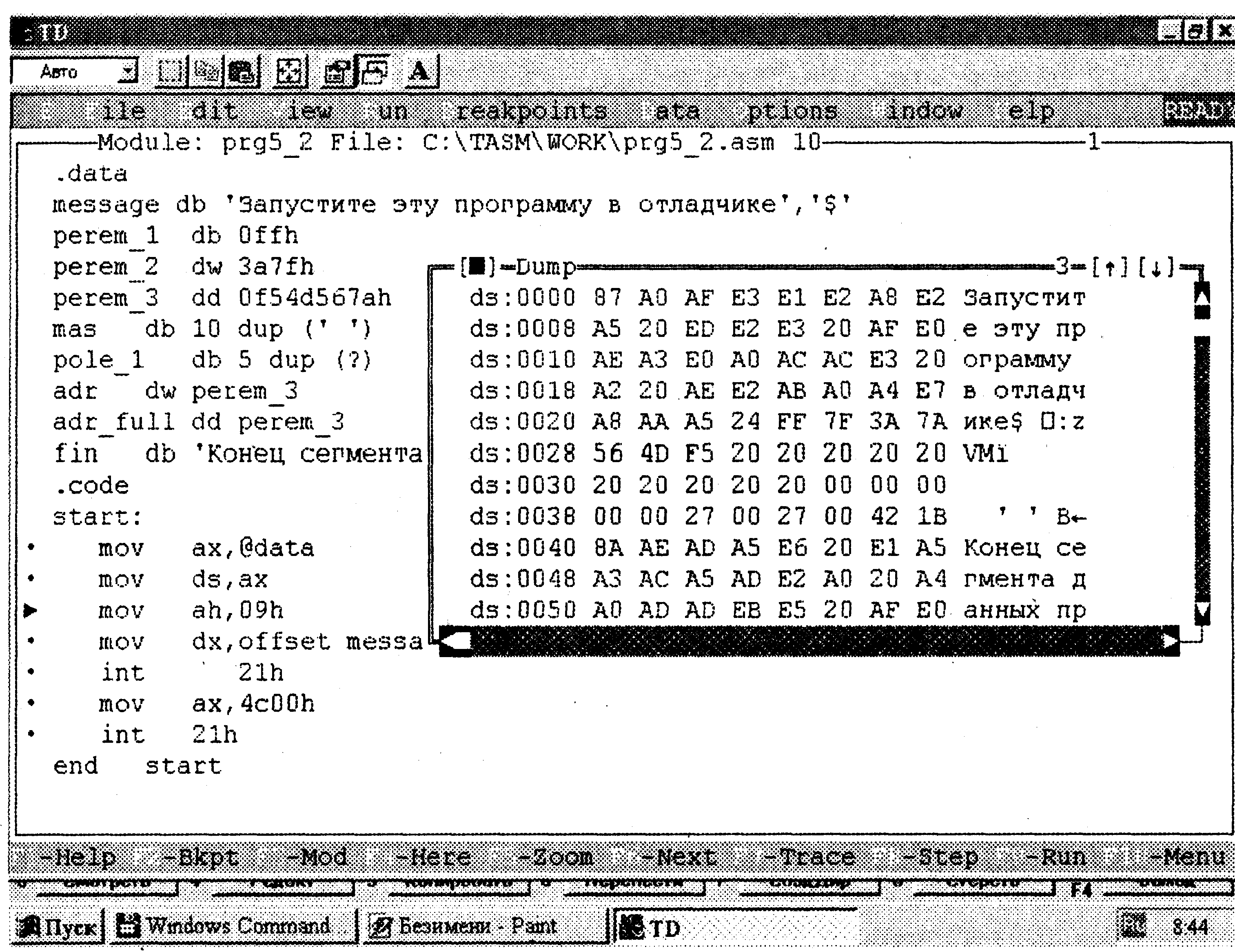
Рис. 5.18. Окно дампа памяти
Любой переменной, объявленной с помощью директив описания простых типов данных, ассемблер присваивает три атрибута:
- Сегмент (seg) — адрес начала сегмента, содержащего переменную.
- Смещение (offset) в байтах от начала сегмента с переменной.
- Тип (type) определяет количество памяти, выделяемой переменной в соответствии с директивой объявления переменной.
Получить и использовать значение этих атрибутов в программе можно с помощью рассмотренных нами выше операторов ассемблера seg, offset и type.
В заключение рекомендую вам обратить внимание на то, что в Справочнике приведены диапазоны значений для тех простых типов данных, директивы описания которых мы обсудили на данном уроке. Посмотрите эту информацию и используйте ее при необходимости явного задания значений для данных различных типов.