
Методика тестирования алгоритмов распознавания по лицу и голосу Aea tests Round Версия 2 Содержание
| Вид материала | Документы |
- Методика проведения тестирования и оценивания результатов тестирования в рамках единой, 118kb.
- Задачи : Проверка стабильности результатов тестирования клубной конвергенции по методу, 149.26kb.
- «Понятие об алгоритме. Примеры алгоритмов. Свойства алгоритмов. Типы алгоритмов, построение, 84.9kb.
- Программа «Методика (теория и технология) лингводидактического тестирования в рамках, 23.55kb.
- Программа «Методика (теория и технология) лингводидактического тестирования в рамках, 23.5kb.
- Курс Vсеместры 9 (осенний) лекции 17 часов Экзамен 9 семестр (осенний), 69.52kb.
- Правила приема дополнены различными льготами. Теперь на курсы принимаются: без тестирования,, 131.12kb.
- Исследование методов ввода, обработки и анализа звуковых сигналов при помощи компьютера, 241.8kb.
- Применение алгоритмов адаптивной маршрутизации в протоколе igrp, 37.51kb.
- Д. С. Осипенко Понятие алгоритма. Примеры алгоритмов. Свойства алгоритмов. Способы, 96.46kb.
 Группа ДАНКОМ Почтовый адрес: РФ, 125167, г.Москва, ул. Планетная, д.11 Т  ел.: +7 495 5458292 Факс: +7 812 3363275, 3251814/1854 ел.: +7 495 5458292 Факс: +7 812 3363275, 3251814/1854Веб-сайты: www.dancom.ru Email: aeainfo@dancom.ru | Program AeA®Tests www.dancom.ru/rus/AeA/TestProtocolR1.pdf www.dancom.ru/rus/AeA/TestProtocolR1.doc |

Методика тестирования алгоритмов распознавания
по лицу и голосу AeA Tests Round 1. Версия 2
Содержание:
1. История версий 1
2. Цель тестирования 1
3. Основные понятия 1
4. Методика тестирования 4
5. Организационные этапы тестирования 5
6. Структура баз данных 6
6.1. БДИ 6
6.2. НБД изображений 7
6.3. НБД аудиозаписей 8
6.4. ТБД 8
7. Целевые пользовательские приложения 8
8. Описание API для тестирования алгоритмов версии 1.0 9
8.1. Структуры данных и функции библиотеки распознавания. 9
8.2. Схема взаимодействия ПО тестирования с библиотекой распознавания. 12
1. История версий
| Версия | Дата | Изменения |
| 1 | 28 июня 2006г. | Начальная версия AeA FaRT |
| 2 | 20 июля 2006г. | Введены определения и более подробно описана методика |
2. Цель тестирования
Определение характеристик различных алгоритмов распознавания человека по изображениям лица или речевым данным в режиме верификации при ограничениях, устанавливаемых условиями тестирования, на выборке базы данных, полученной в условиях и по сценарию работы пункта установления личности человека, и последующее сравнение результатов, продемонстрированных алгоритмами различных производителей.
По результатам тестирования даются независимые рекомендации экспертов относительно достоинств и недостатков того или иного алгоритма, а также анализируются применения в различных пользовательских приложениях.
3. Основные понятия
Персона – индивидуум (человек), изображения или аудиозаписи которого используются для распознавания.
ПИН – идентификатор персоны, номер, однозначно определяющий персону в базе данных.
Изображение (лица). Используются изображения размера 240x240 пикселей в формате Windows BMP, RGB24. Лицо занимает не менее 25% и не более 70% размера изображения по вертикали, полностью помещено в кадр1.
Аудиозапись (речи). Запись формата MS WAVE format, mono, 16 bit, 22050Hz со средним отношением сигнал/шум - +15 dB. Содержит раздельное произнесение персоной слов словаря, состоящего из 14 слов (старт, стоп, да, нет, 0, 1, …, 9) и трех ПИН: двукратного произнесения «своего» ПИН, принадлежащего данной персоне, и однократного произнесения «чужого» ПИН, принадлежащего другой зарегистрированной персоне.
Исходная сессия – последовательность изображений лица, состоящая из не менее 200 изображений персоны, снятых неподвижной камерой за промежуток времени не более 1 минуты, или аудиозапись продолжительностью около 25 секунд +- 30%. Каждая персона представлена несколькими сессиями.
Сессия – последовательность изображений лица, состоящая для данного теста из десяти изображений персоны, снятых неподвижной камерой за промежуток времени не более 1 минуты, или аудиозапись продолжительностью около 25 секунд +- 30%. Каждая персона представлена несколькими сессиями.
Параметры (дескрипторы) сессии – неизменяемые и изменяемые данные, характеризующие персону (возраст, пол, раса, степень сотрудничества) и среду регистрации изображений лица (освещенность) или аудиозаписи (шум), регистрационное оборудование и другие обстоятельства регистрации. Всего используется около 70 параметров сессии.
База исходных данных (база данных изображений или аудиозаписей, БДИ) – совокупность всех сессий всех персон.
Настроечная БД (НБД) – подмножество случайно выбранных сессий БДИ, предоставляемое участникам тестирования для настройки алгоритмов и отладки взаимодействия с программой тестирования.
Тестовая БД (ТБД) – подмножество БДИ, используемое для проведения тестирования алгоритмов участников организатором. ТБД участникам не предоставляется. Множества сессий, представленных в ТБД и НБД не пересекаются.
Шаблон – представление, содержащее информацию, достаточную для распознавания. Шаблон является представлением персоны с точки зрения алгоритма распознавания и имеет размер не более 10Кб. Шаблон строится по изображениям или аудиозаписям одной сессии.
Построение шаблона – процесс преобразования сессии в шаблон, выполняемый алгоритмами участника тестирования за время не более 1 секунды. Возможна ситуация, в которой по какой-либо причине алгоритм построения шаблона не в состоянии создать шаблон из изображений или аудиозаписи сессии. Такая ситуация называется отказом в регистрации.
Старение шаблона – естественное или вынужденное изменение биометрических характеристик персоны во времени, приводящее к снижению точности распознавания.
Вероятность отказа в регистрации – отношение количества отказов в регистрации к общему количеству сессий, поданных для регистрации.
Эталон – совокупность биометрических данных (шаблона) и идентификационных данных (ПИН, номер сессии).
База данных эталонов (БДЭ) – совокупность эталонов, построенных по НБД или ТБД. Персона может быть представлена одним или несколькими эталонами.
Сравнение шаблонов – вычисление меры сходства двух шаблонов алгоритмами участников тестирования за время не более 0,001 секунды.
Мера сходства. Представляет из себя действительное число, характеризующее сходство шаблонов и варьирующееся от 0 (совершенное несходство) до 1 (совершенное сходство).
Сравнение (двух) баз данных эталонов – попарное сравнение каждого из эталонов одной базы данных с каждым из эталонов другой.
Порог распознавания – число в диапазоне от 0 до 1. При сравнении меры сходства с порогом в режиме верификации принимается бинарное решение: «распознан», если мера сходства превосходит или равна порогу, «не распознан» в противном случае.
Ложный допуск – принятие при заданном пороге бинарного решения «распознан» при сравнении шаблонов разных персон.
Ложный недопуск – принятие при заданном пороге бинарного решения «не распознан» при сравнении шаблонов одной персоны.
Вероятность ложного допуска, False Acceptance Rate (FAR). Вычисляется при заданном пороге распознавания Т как отношение числа ложных допусков к числу сравнений разных персон, полученных при сравнении двух БД эталонов. Вероятность ложного допуска для заданных сравниваемых БДЭ представляет собой функцию порога распознавания FAR(T). По построению FAR(T) равна 1 при Т<0 или 0 при Т>1 и монотонно убывает на отрезке [0;1].
Вероятность ложного недопуска, False Rejection Rate (FRR). Вычисляется при заданном пороге распознавания Т как отношение числа ложных недопусков к числу сравнений с участием одной персоны, полученных при сравнении двух БД эталонов. Вероятность ложного недопуска для заданных сравниваемых БДЭ представляет собой функцию порога распознавания FRR(T). По построению FRR(T) равна 0 при Т<0 или 1 при Т>1 и монотонно возрастает на отрезке [0;1].
Параметрическая кривая ошибки (DET-curve) – параметрическая кривая, построенная в координатах (FRR(T);FAR(T)). Параметрическая кривая ошибки, построенная для ТБД, наряду с вероятностью отказа от регистрации рассматривается в данном тесте как основная характеристика эффективности алгоритмов распознавания в режиме верификации (Рис. 1).
Верификация (сравнение «один к одному») – операция сравнения предъявленного шаблона с эталонами из БД эталонов, построенными для одной определенной персоны (имеющими один заданный ПИН), при заданном пороге распознавания. Результат операции бинарный: «распознан» если мера сходства хотя бы одного шаблона из БДЭ с предъявленными данными превзошла или равна порогу, «не распознан» в противном случае, а также в случае, когда персона с заданным ПИН не зарегистрирована в БДЭ.
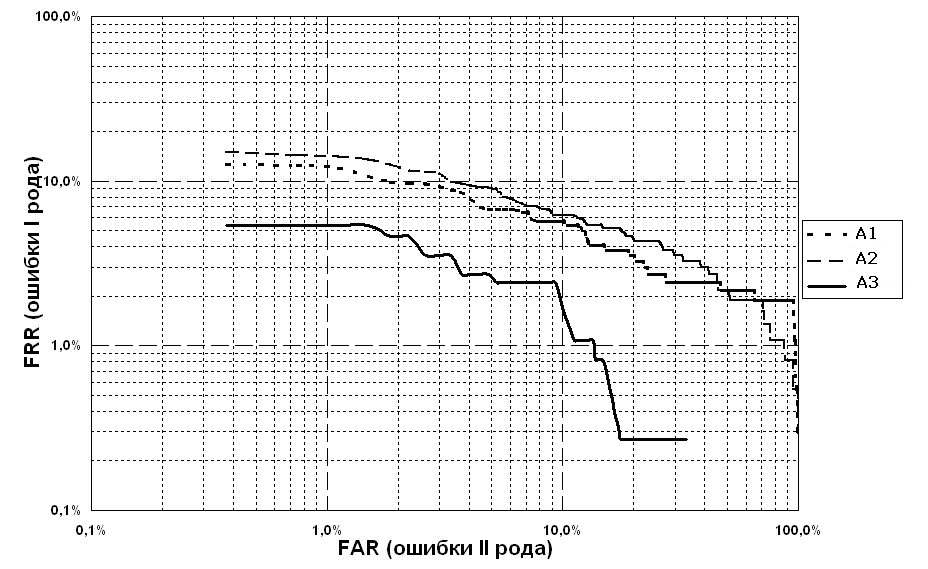
Рис. 1. Графики DET-curves параметрических кривых ошибок, построенных для различных алгоритмов распознавания в режиме верификации
4. Методика тестирования
Можно выделить шесть основных операций тестирования, производимых для алгоритмов распознавания каждого из участников:
- Построение БД эталонов из БД изображений или аудиозаписей, вычисление вероятности отказа от регистрации;
- Сравнение БДЭ с собой;
- Построение параметрической кривой ошибки на БДЭ;
- Построение параметрических кривых ошибки на подмножествах БДЭ, определяемых значимыми параметрами сессии;
- Определение временных характеристик работы алгоритмов;
- Статистическое обоснование полученных результатов.
Параметрические кривые ошибки и вероятности отказа от регистрации, полученные для алгоритмов участников, являются основным результатом тестирования и публикуются в виде сводных таблиц (графиков).
Поскольку методы проверки качества изображений или аудиозаписей и шаблонов у участников различаются, отказы от регистрации, скорее всего, произойдут на различных сессиях БДИ. В результате, из одной и той же БДИ алгоритмами разных участников будут получены БДЭ, соответствующие различным подмножествам сессий. В этом случае сравнение параметрических кривых ошибки (полученных для разных БДЭ) характеризует сравнительную эффективность не только алгоритмов распознавания, но и алгоритмов отбраковки.
Для сравнения только алгоритмов распознавания как таковых предназначен ещё один тест, в основном совпадающий с предыдущим и дополненный шагом урезания БД эталонов до подмножества сессий, содержащихся во всех ранее построенных БДЭ каждого из участников:
- Построение БД эталонов из БД изображений или аудиозаписей, вычисление вероятности отказа от регистрации для каждого из участников;
- Урезание баз данных эталонов до подмножества сессий, которое представлено в БДЭ всех участников;
- Сравнение урезанных БД эталонов с собой;
- Построение параметрических кривых ошибки на урезанной БДЭ;
- Построение параметрических кривых ошибки на подмножествах урезанной БДЭ, определяемых значимыми параметрами сессии;
- Определение временных характеристик работы алгоритмов;
- Статистическое обоснование полученных результатов.
Параметрические кривые ошибки, полученные в этом тесте также публикуются в виде сводных таблиц (графиков).
Условимся называть первый тест «независимым тестированием», второй – «тестированием на общем подмножестве».
Таким образом, исходными данными и условиями тестирования являются:
- Тестовая БД изображений или аудиозаписей, имеющаяся у организатора;
- Алгоритмы построения эталонов по сессиям ТБД и алгоритмы сравнения эталонов, предоставленные организатору участником;
- Методика тестирования, изложенная в настоящем документе и реализованная организатором в тестирующем приложении.
Результатами тестирования являются:
- Параметрические кривые ошибки и вероятности отказа от регистрации, полученные для алгоритмов участников в виде таблиц (графиков) для независимого тестирования;
- Параметрические кривые ошибки, полученные для алгоритмов участников в виде таблиц (графиков) для тестирования на общем подмножестве;
- Временные характеристики;
- Статистическое обоснование полученных результатов.
5. Организационные этапы тестирования
Тестирование алгоритмов организуется Группой ДАНКОМ.
В тестировании принимают участие разработчики алгоритмов, которые могут быть коммерческими или государственными организациями, научными учреждениями, физическими или любыми другими лицами, за исключением организатора.
Организатор публично объявляет о методике и порядке проведения тестирования. Участники подают заявку в заданные сроки и заключают с организатором договор о неразглашении информации для исключения публичного обсуждения деталей тестирования.
Допускается анонимное участие в тестировании.
В общем случае отношения организатора и участников регламентируются Положением об участниках тестов AeA.
Краткая последовательность действий:
1. Организатор предоставляет участникам настроечную БД, описание методики тестирования и тестирующее приложение в исходных кодах;
2. Участники адаптируются к условиям тестирования (настраивают алгоритмы обработки изображений или аудиозаписей, используя данные НБД, и обеспечивают совместимость с API тестирующего приложения) и предоставляют организатору алгоритм (библиотеку) в форме следующих файлов:
-динамической библиотеки для системы MS Windows (Win32 DLL);
-DEF файла с описанием экспортируемых функций.
Библиотека должна экспортировать следующие пользовательские функции: InitLibrary, CreateTemplate, CompareTemplates, UnInitLibrary. Более подробные требования приведены в п.8. Если для работы алгоритмов требуются какие-либо файлы или настройки системы помимо DLL, это необходимо указывать в сопроводительной документации;
3. Участники регистрируют свои алгоритмы у организатора;
4. Организатор выполняет тестирование согласно описанной методике;
5. Организатор обязуется не использовать алгоритмы участников нигде, за исключением настоящего тестирования;
6. Организатор анализирует и публикует результаты тестирования, сопроводив их независимыми комментариями членов Экспертного совета и участников тестирования по согласованию.
6. Структура баз данных
Биометрические данные собраны в виде совокупности исходных сессий - последовательностей не менее 200 изображений лица или аудиозаписей длительностью в среднем около 25 сек. Каждая сессия однозначно связана с ПИНом того субъекта, чьи биометрические данные записывались.
Одной из задач при создании БДИ было изучение изменчивости биометрических характеристик с течением времени (эффекта старения шаблона). Поэтому предпринимались определенные усилия к повторным регистрациям данных: допускалась регистрация не менее 4-х исходных сессий в течение одного дня (визита) с минимальным допустимым интервалом между сессиями – 1-2 недели.
Система сбора базы данных была сконструирована и отлажена таким образом, что было обеспечено постоянство фоновой и цветовой экспозиции, чувствительности микрофона и камер, определена позиция головы по отношению к камере и микрофону. Были точно установлены правила поведения оператора и регистрируемой персоны: запись данных, действий оператора и персоны производились в соответствии с установленным сценарием, который был реализован при помощи вывода на экран визуальных команд для персоны. Для каждой сессии оператор фиксировал информацию о поведении персоны и о посторонних событиях во время записи.
6.1. БДИ
База исходных данных имеет следующую структуру:
-персон – 1 673;
-визитов – 3 246;
-исходных сессий – 15 234.
Соотношения:
-2.12 визитов на персону;
-9.83 исходных сессий на персону;
-4.64 исходных сессий за визит;
-относительное число женщин - ~43%.
Приведенный ниже график (Рис. 2) иллюстрирует количество персон с различным числом визитов.
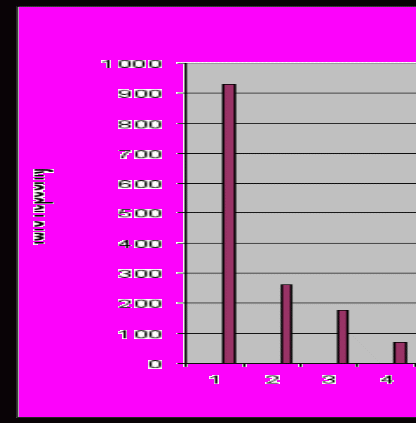
Рис. 2. Количество персон с различным числом визитов
6.2. НБД изображений
В настроечной БД представлено 100 персон, для каждой из них имеется 8 сессий, состоящих из 10 изображений персоны в различных ракурсах, снятые в течение небольшого интервала времени.
Алгоритм распознавания по каждой сессии формирует эталон персоны. Таким образом, для каждой персоны может быть создано 8 эталонов, а всего из НБД может быть создано 800 различных эталонов. В заголовок эталона включается идентификатор технологии «распознавание по изображениям лица», чтобы отличать эталоны, созданные для различных биометрических технологий.
Эталоны сравниваются по схеме «каждый с каждым». В результате получается матрица сходства, в которой блоки 8x8, расположенные на главной диагонали, характеризуют результат сравнения одной и той же персоны, а элементы вне этих блоков – сравнения разных персон. На основании этих данных вычисляются различные показатели качества распознавания, в первую очередь это FAR, FRR и параметрическая кривая.
НБД записана на ДВД-диск и имеет следующий формат.
В корневой директории имеется 100 директорий с именами от 00000 до 00099. Имя директории совпадает с ПИНом персоны.
Внутри каждой из директорий содержатся данные только одной персоны.
Файлы с изображениями внутри директорий персон имеют следующий формат имен:
{PIN}-{SESS}-{IMGNUM}.bmp,
где
{PIN} есть указанный выше идентификатор персоны, унаследованный от родительской директории;
{SESS} есть идентификатор сессии, строка от 0000 до 0007;
{IMGNUM} есть номер изображения в сессии, изменяется от 0 до 9. Пример имени файла: 00052-0006-3.bmp есть изображение персоны с ПИН 00052, из сессии 0006, третье изображение. Этот файл находится в директории 00052.
6.3. НБД аудиозаписей
Настроечная БД аудиозаписей имеет структуру и состав, схожие с НБД изображений, описанной в п. 6.2.
6.4. ТБД
Тестовая БД, на которой тестируются алгоритмы, имеет схожий формат и отличается количеством персон и сессий.
ТБД изображений содержит около 30 000 сессий.
ТБД аудиозаписей содержит около 15 000 сессий.
7. Целевые пользовательские приложения
Результаты тестирования могут быть использованы для изучения возможности внедрения биометрических алгоритмов распознавания в различные пользовательские приложения, включающие:
1. Автоматические системы установления личности. Назначение таких систем – автоматическое принятие решения о личности человека при предоставлении ему доступа к тому или иному объекту (например, пропускной пункт). Системы могут работать в режимах верификации, идентификации или связанной идентификации;
2. Автоматизированные системы установления личности. Назначение этих систем – автоматизация работы оператора, принимающего окончательное решение о личности человека. Системы могут работать в режимах верификации, идентификации ранга N>=1 или связанной идентификации;
3. Системы для установления личности из целевого списка. Такие системы предназначены для работы в режиме идентификации ранга N>=1. Они, в отличие от автоматизированных систем установления личности, предназначены для работы с интенсивным потоком биометрических данных, в котором количество человек, не занесенных в целевой список, как правило, значительно превосходит размер целевого списка;
4. Системы слежения за перемещением человека на основе детектирования лица и его элементов в режиме реального времени.
Конфигурации целевых пользовательских приложений для тестирования алгоритмов определяются Экспертным Советом.
На первом этапе тестирования (Round 1) алгоритмы распознавания тестируются и анализируются применительно только к режимам верификации.
На следующих этапах будут проводиться тестирования в режимах идентификации, связанной идентификации, целевого списка и других.
8. Описание API для тестирования алгоритмов версии 1.0
Алгоритмы распознавания предоставляются в виде динамической библиотеки для системы MS Windows (Win32 DLL). Указанная библиотека должна сопровождаться DEF файлом, в котором описаны экспортируемые функции (см. ниже).
Все необходимые функции должны экспортироваться по именам, без декорирования (т.е. со спецификатором extern “C”) . Загрузка DLL библиотеки подразумевается во время исполнения, при помощи системных вызовов LoadLibrary и GetProcAddress, где последняя функция указывает имя загружаемой функции.
8.1. Структуры данных и функции библиотеки распознавания.
Предлагается использовать следующие функции и структуры данных для экспортирования алгоритмов распознавания.
Коды возврата из функций реализуют диагностику ошибок.
#define ERR_NONE 0
#define ERR_BADPARAM 1
#define ERR_BADBUFFERSIZE 2
#define ERR_INCOMPATIBLETEMPLATES 3
#define ERR_CREATEFAILED 4
#define ERR_BADTEMPLATE 5
typedef insigned int DWORD;
типы исходных данных для распознавания включают изображения (лица) и записи голоса.
#define SOURCE_TYPE_IMAGE 1
#define SOURCE_TYPE_SOUND 2
typedef struct
{
int nImageWidht, //ширина изображения в пикселях
int nImageHeight //высота изображения в пикселях
} ImageParameters;
typedef struct
{
int nSampligRate, // частота дискретизации в Гц
int nBitsPerSample
} SoundParameters;
int InitLibrary (DWORD dwApiVersion, //in
DWORD nTemplateType, //in
const void* pInitData); //in
Функция инициализирует внутренние структуры библиотеки и алгоритмов, все остальные функции библиотеки могут вызваться только после вызова данной функции. Функция возвращает 0 (ERR_NONE) в случае успеха или код ошибки.
dwApiVersion есть номер версии API, для описываемого интерфейса равен 0x1.
nTemplateType есть тип исходных данных (изображения, звук и т.д.), в текущей версии допустимые значения есть SOURCE_TYPE_IMAGE или SOURCE_TYPE_SOUND. Для всех прочих значений функцией возвращается код ошибки ERR_BADPARAM
pInitData есть указатель на структуру, содержащую параметры исходных данных в соответствии с типом nTemplateType.
- Если значение параметра nTemplateType равно SOURCE_TYPE_IMAGE, то указатель pInitData указывает на структуру данных типа SoundParameters, где для версии API 1.0 высота и ширина изображений равна 240 и 240 пикселей . В случае прочих значений размеров изображений функция InitLibrary возвращает код ошибки ERR_BADPARAM.
- Если значение параметра nTemplateType равно SOURCE_TYPE_SOUND, то указатель pInitData указывает на структуру данных типа ImageParameters, где для версии API 1.0 частота дискретизации равна 22050 Гц, а разрядность 16 бит. В случае прочих значений размеров изображений функция InitLibrary возвращает код ошибки ERR_BADPARAM.
В случае успешного выполнения функция InitLibrary возвращает 0.
В случае ошибки функция InitLibrary возвращает ненулевое значение.
typedef struct
{
const void* images[10];
} ImagesContainer;
typedef struct
{
DWORD nBufferLen,
const void* pBuffer;
} SoundContainer;
int CreateTemplate(DWORD nTemplateType,
const void* pSource, //in
void* pTemplate, //out
int* pTemplateSize); //in&out
Функция создает эталон в памяти из исходных данных, заданных типом nTemplateType и представлением pSource (зависит от типа). Функция возвращает 0 в случае успеха или код ошибки. Размер передаваемого буфера для эталона указывается в переменной *pTemplateSize. Если этот размер недостаточен, функция возвращает код ошибки ERR_BADBUFFERSIZE и необходимый размер в *pTemplateSize.
Если входные данные таковы, что создать эталон с приемлемым качеством невозможно, функция возвращает код ошибки ERR_CREATEFAILED.
nTemplateType есть тип исходных данных (изображения, звук и т.д.), в текущей версии допустимые значения есть SOURCE_TYPE_IMAGE или SOURCE_TYPE_SOUND. Для всех прочих значений функцией возвращается код ошибки ERR_BADPARAM. Если при инициализации библиотеки распознавания было указано значение nTemplateType, отличного от указанного при вызове данной функции, то возвращается код ошибки ERR_BADPARAM.
pSource есть указатель на структуру, содержащую параметры исходных данных в соответствии с типом nTemplateType.
- Если значение параметра nTemplateType равно SOURCE_TYPE_IMAGE, то указатель pSource указывает на структуру данных типа ImagesContainer, где содержится массив из 10 указателей на соответствующие кадровые буферы, содержащие изображения, предназначенные для создания эталона. Формат пикселей кадровых буферов – RGB24. Первый байт каждого кадрового буфера соответствует левому нижнему углу изображения.
- Если значение параметра nTemplateType равно SOURCE_TYPE_SOUND, то указатель pSource указывает на структуру данных типа SoundContainer, где содержится размер звукового буфера в сэмплах, и указатель на первый элемент звукового буфера. Формат звукового буфера определяется при инициализации библиотеки.
pTemplate – параметр указывает на буфер, предназначенный для сохранения эталона, созданного из исходных данных, на которые указывает pSource.
pTemplate может принимать значение NULL, в этом случае функция должна вернуть код ошибки ERR_BADBUFFERSIZE и записать необходимый размер буфера в *pTemplateSize.
pTemplateSize – при вызове функции переменная указывает на целое число, равное выделенному размеру буфера для эталона. После возврата из функции данная переменная должна содержать фактически использованный размер буфера. Если размер буфера, оказался достаточным для сохранения эталона, данное значение можно оставить без изменения.
Если размер области памяти, указанный вызывающим приложением, недостаточен для создания эталона, функция должна вернуть код ошибки ERR_BADBUFFERSIZE и записать необходимый размер в *pTemplateSize. Эта функциональность может использоваться приложением для определения необходимого размера буфера для хранения эталона.
int CompareTemplates ( const void* pFirstTemplate, //in
const void* pSecondTemplate, //in
int* pSimilarity); //out
Функция производит сравнение эталонов, заданных первыми двумя параметрами, результат записывается по указателю, заданному третьим параметром.
Владение памятью эталонов остается за вызывающей программой. Функция возвращает 0 в случае успешного выполнения, иначе возвращается код ошибки. В случае несовместимости сравниваемых эталонов, возвращается код ошибки ERR_INCOMPATIBLETEMPLATES. Если один из эталонов содержит ошибочные данные (содержимое испорчено), функция возвращает код ошибки ERR_BADTEMPLATE.
pFirstTemplate – указатель на первый из двух эталонов для сравнения.
pSecondTemplate – указатель на второй из двух эталонов для сравнения.
pSimilarity – переменная *pSimilarity получает величину меры сходства.
*pSimilarity может принимать значения от 0 до 231-1. Истинное значение меры сходства есть частное от деления указанной величины на 231-1.
int UnInitLibrary();
Функция завершает сеанс работы с библиотекой. Библиотека освобождает внутренние ресурсы. Вызовы других функций после этого запрещены.
8.2. Схема взаимодействия ПО тестирования с библиотекой распознавания.
Сеанс работы с библиотекой состоит из вызовов InitLibrary, UnInitLibrary, между которыми производятся вызовы CreateTemplate и/или CompareTemplates.
Функционирование ПО тестирования и библиотеки распознавания происходит следующим образом и состоит из двух этапов (рассматривается на примере распознавания по изображениям лица):
- Этап создания эталонов.
- Программа тестирования проводит инициализацию, определяет списки персон и сессий для создания эталонов.
- Программа тестирования загружает и инициализирует DLL, содержащую программный код, реализующий распознавание.
- Для этого, вызывается системная функция LoadLibrary, и затем, при помощи вызова GetProcAddress по именам определяются адреса функций InitLibrary, CreateTemplate, CompareTemplates, UnInitLibrary.
- Вызывается функция InitLibrary с необходимыми входными параметрами.
- Для этого, вызывается системная функция LoadLibrary, и затем, при помощи вызова GetProcAddress по именам определяются адреса функций InitLibrary, CreateTemplate, CompareTemplates, UnInitLibrary.
- Библиотека распознавания при вызове InitLibrary производит необходимую инициализацию библиотеки, ее внутренних структур, захват необходимых ресурсов и т.п.
- Программа тестирования для каждой сессии, из которой должен быть создан эталон, производит следующие действия.
- Программа тестирования загружает в память файлы, содержащие информацию, необходимую для создания эталона, (например, загружает файлы формата BMP с изображениями), производит анализ корректности содержания файлов (например, заголовков BMP).
- Программа тестирования вызывает функцию CreateTemplate, указывая в качестве аргументов адреса областей памяти, куда загружены входные данные и нулевой размер буфера для эталона.
- Библиотека распознавания при таком вызове CreateTemplate производит оценку необходимого размера буфера для эталона, записывает его по адресу pTemplateSize и возвращает код ошибки ERR_BADBUFFERSIZE.
- Программа тестирования выделяет область памяти необходимого для эталона размера и вновь вызывает функцию CreateTemplate, указывая входные данные, адрес выделенного буфера и его размер.
- Библиотека распознавания, при таком вызове определяет, что переданный ей буфер имеет достаточный размер для создания эталона, создает эталон в указанной области памяти, и возвращает код успешного завершения. Если создание эталона завершилось неудачно, возвращается код ошибки ERR_CREATEFAILED.
- Программа тестирования сохраняет эталон в соответствующий файл на диске, для целей дальнейшего сравнения.
- Программа тестирования освобождает ресурсы, захваченные в п. X1.4.1X и X1.4.4X, и переходит к обработке следующей сессии.
- Программа тестирования загружает в память файлы, содержащие информацию, необходимую для создания эталона, (например, загружает файлы формата BMP с изображениями), производит анализ корректности содержания файлов (например, заголовков BMP).
- Программа тестирования вызывает функцию UnInitLibrary, для того, чтобы библиотека распознавания освободила внутренние ресурсы.
- Библиотека распознавания при вызове освобождает ресурсы, захваченные при вызове InitLibrary в п.X1.3X.
- Программа тестирования вызывает системную функцию FreeLibrary, выгружая DLL с библиотекой распознавания и освобождает другие ресурсы, захваченные при загрузке программы. На этом работа программы тестирования в режиме создания эталонов завершается.
- Программа тестирования проводит инициализацию, определяет списки персон и сессий для создания эталонов.
- Этап сравнения эталонов.
- Программа тестирования проводит инициализацию, определяет список пар эталонов для сравнения, подготавливает структуры данных для хранения результатов сравнения.
- Программа тестирования загружает и инициализирует DLL, содержащую программный код, реализующий распознавание.
- Для этого, вызывается системная функция LoadLibrary, и затем, при помощи вызова GetProcAddress по именам определяются адреса функций InitLibrary, CreateTemplate, CompareTemplates, UnInitLibrary.
- Вызывается функция InitLibrary с необходимыми входными параметрами.
- Для этого, вызывается системная функция LoadLibrary, и затем, при помощи вызова GetProcAddress по именам определяются адреса функций InitLibrary, CreateTemplate, CompareTemplates, UnInitLibrary.
- Библиотека распознавания при вызове InitLibrary производит необходимую инициализацию библиотеки, ее внутренних структур, захват необходимых ресурсов и т.п.
- Программа тестирования для каждой из пар эталонов, которые подлежат сравнению, производит следующие действия.
- Программа тестирования загружает в память файлы, содержащие эталоны.
- Программа тестирования вызывает функцию CompareTemplates, указывая в качестве аргументов адреса областей памяти, куда загружены эталоны
- Библиотека распознавания при вызове CompareTemplates производит сравнение эталонов и возвращает меру сходства или код ошибки, в случае неуспешного выполнения.
- Программа тестирования сохраняет результаты сравнения во внутренние структуры данных и в лог-файл сравнения.
- Программа тестирования освобождает ресурсы, захваченные в п.X2.4.1X, и переходит к сравнению следующей пары эталонов.
- Программа тестирования загружает в память файлы, содержащие эталоны.
- После завершения сравнения всех пар эталонов, программа тестирования вызывает функцию UnInitLibrary, для того, чтобы библиотека распознавания освободила внутренние ресурсы.
- Библиотека распознавания при вызове освобождает ресурсы, захваченные при вызове InitLibrary в п.X2.3X.
- Программа тестирования вызывает системную функцию FreeLibrary, чтобы выгрузить DLL с библиотекой распознавания.
- Программа тестирования производит статистическую обработку накопленных результатов сохраняет их соответствующим образом.
- Программа тестирования освобождает другие ресурсы, захваченные при запуске программы. На этом работа программы тестирования в режиме сравнения эталонов завершается.
- Программа тестирования проводит инициализацию, определяет список пар эталонов для сравнения, подготавливает структуры данных для хранения результатов сравнения.
###
1 Данные изображения характерны для широко распространенных приложений, в которых используются аналоговые видеокамеры. Изображения с более высоким разрешением будут использоваться в следующих сериях тестирования AeA и могут быть получены при помощи цифровых видеокамер, которые редко применяются из-за высокой стоимости и жестких требований к периферии, поддерживающей, например, интерфейсы FireWire (IEEE-1394) или CameraLink.
© 2006 DANCOM Group. Confidential Стр. из