
В. А. Резніченко Відповідальний виконавець
| Вид материала | Документы |
- Ю. Громадський керівник розробки; М. Бєлов відповідальний виконавець, 3516.22kb.
- Районна цільова програма «Створення районного історико краєзнавчого музею «Жовківщина», 192.54kb.
- Секція: Економіка Назва наукового напряму в паспорті: Організація-виконавець, 55.56kb.
- Надійності та безпеки в будівництві, 692.13kb.
- Державні будівельні норми україни, 1940.86kb.
- Державні будівельні норми україни захист від пожежі пожежна безпека об’єктів будівництва, 5769.37kb.
- Державні будівельні норми україни захист від пожежі пожежна безпека об’єктів будівництва, 5746.45kb.
- Єпіфанов, ректор двнз «Українська академія банківської справи Національного банку України»,, 1134.49kb.
- Затверджено, 176.91kb.
- Виконавець, 828.48kb.
УДК 681.3.06
КП
№ держреєстрації 0103U006437
Інв. №
Нацiональна академiя наук України
Iнститут програмних систем (IПС НАНУ)
03187, м. Київ-187, пр. Глушкова, 40, тел. (044) 266 55 07, факс 266 62 63
-
ЗАТВЕРДЖУЮ
Директор Інституту програмних систем НАН України
член-кореспондент НАН України
П.І. Андон
2004.11.
Розробка та реалізація проектних рішень автоматизованого бібліотечного сервісу в інтересах установ НАНУ
(АСБС)
БІБЛІОТЕЧНИЙ СЕРВІС ПО ТЕМАТИЧНОМУ ПОШУКУ ПОВНОТЕКСТОВОЇ ІНФОРМАЦІЇ В СИСТЕМІ Е-КОНТЕНТ
Методичні матеріали та специфікації
| Науковий керівник ДТР пров. наук. співроб. кандидат фіз.-мат. наук | 2004.11. | В.А. Резніченко |
| Відповідальний виконавець пров. наук. співроб. кандидат фіз.-мат. наук | 2004.11. | В.О. Дерецький |
2004
СПИСОК ВИКОНАВЦІВ
| Гол. прогр. | | Богданова М.М. |
| Гол. прогр. | | Ремарович С.С. |
РЕФЕРАТ
Об’єкт досліджень – методичні матеріали та специфікації бібліотечних сервісів з повнотекстового тематичного пошуку інформації.
Цілями проекту є розробка методичних матеріалів та специфікації бібліотечних сервісів з повнотекстового тематичного пошуку інформації в повнотекстових базах даних на прикладі інформаційно-аналітичної системи Е-КОНТЕНТ.
Основним напрямком досліджень та розробки є доступ до цифрових документів, що представлені в повнотекстових базах даних. Розглядається суттєво новий вид бібліотечних ресурсів - повнотекстові бази даних на електронних носіях, створені чи придбані в бібліотеках.
Для забезпечення доступу до таких зібрань, та відбору інформації, яка цікавить користувача, використовуються цифрові технології, що повинні забезпечити широке коло послуг (сервісів) для пошуку та опрацювання інформації, що зберігається в текстових колекціях бібліотеки. Основними сервісами, що розроблялись в даному проекті є:
розробка моделі тематичного інтересу користувача (тематичної онтології). Створення тематичної онтології. Формування тематичної онтології за прототипом. Автоматичне формування тематичної онтології відповідно до заданногго тексту;
пошук та відбір текстів за заданою тематичною онтологією.
Ключові слова:
ЕЛЕКТРОННА БІБЛІОТЕКА, БІБЛІОТЕЧНИЙ СЕРВІС, ОНТОЛОГІЇ, МЕТОДИ АНАЛІЗУ (ОПРАЦЮВАННЯ) НЕСТРУКТУРОВАНОЇ ІНФОРМАЦІЇ, ТЕМАТИЧНИЙ ПОШУК, ОПРАЦЮВАННЯ ПРИРОДНОМОВНОЇ ІНФОРМАЦІЇ, СЕМАНТИЧНА МЕРЕЖА.
ЗМІСТ
РЕФЕРАТ 4
ПЕРЕЛІК СКОРОЧЕНЬ 6
ВСТУП 7
1 Бібліотечний сервіс тематичного пошуку та відбору повнотекстової інформації 9
9
2 МЕТОД Формування ТЕМАТИЧНОЇ МЕТАІНФОРМАЦІЇ 13
В СИСТЕМІ Е-КОНТЕНТ 13
2.1 Метод анотації теми засобами Wordnet 14
2.2 Генерація загального тезауруса теми 14
3 Система Е-КОНТЕНТ як бібліотечний сервіс пошуку повнотекстової інформації 16
3.1 Сервіс спеціфікації тем інформаційного пошуку (менеджер тем) 17
3.1.2 Специфікація пошукових об’єктів для тематичного пошуку в системі Е-КОНТЕНТ 20
3.2 Сервіс тематичного пошуку інформації 21
Висновки 25
Додаток А. Стандарти, що використовуються в бібліотечних сервісах пошуку інформації 26
Додаток Б. Визначення термінів 27
ПЕРЕЛІК ПОСИЛАНЬ 29
ПЕРЕЛІК СКОРОЧЕНЬ
HTML - Hyper Text Markup Language
ODLI3 - Object Definition Language
RDF - cхема опису ресурсів (Resource Description Framework)
RDFS - Resource Description Framework Shema
ВСТУП
Електронна бібліотека – розподілена інформаційна система, яка дозволяє обробку, зберігання, аналіз і пошук інформації в різних колекціях електронних документів. Електронна бібліотека розглядається як система, що забезпечує співтовариству користувачів доступ зрозумілим для них чином до великих репозиторіїв мультимедійної інформації і знань, організованих за відсутності яких-небудь відомостей про способи їх застосування. Організація та доступ до бібліотечних повнотекстових ресурсів здійснюється з використанням сервісів (порталів).
Під порталом маються на увазі сайт, з якого починається робота по пошуку інформації. Портал повинен поєднувати веб-сервіси, контент і посилання на інші ресурси так, щоб відповідати потребам великого числа користувачів. Відмінними рисами інформаційних порталів є:
1. Агрегація застосувань і інформаційного контента - структурованого і неструктурованого, в єдиний інформаційний простір.
2. Інтеграція даних з різних джерел і різних форматів (наприклад бази даних, документи HTML, документи Word, мультимедіа дані) відповідно до єдиної концепції і зручне надання їх користувачу. Перелік стандартів, що забезпечують інтеграцію бібліотечних ресурсів приведено в Додатку А.
3. Персоналізація припускає можливість для користувача оптимальним чином організувати свій робочий простір на порталі, яке буде йому доступно після проходження процедури авторизації, відповідно до своїх інтересів, а також забезпечити відсів інформації нерелевантної користувачу.
4. Розвинуті пошукові інструменти. Очевидно, що користувач повинен мати могутні пошукові інструменти для того, щоб знайти необхідну йому інформацію витрачаючи для цього мінімум зусиль. Причому пошук не повинен обмежуватися самим порталом, а проводиться також по всьому Internet або його частини, тематично пов'язаної з тематикою порталу.
Сервіси пошуку, використовані на інформаційному порталі можна розділити на наступні три класи:
1. Тематичні каталоги інформаційних ресурсів представлених на самому порталі. Інформаційний контент представлений на порталі структурується по розділах містять тематично близькі ресурси. Крім того в тематичні каталоги входить контекстний і атрибутний (по атрибутах характерних для даного розділу) пошук по документах даної рубрики (розділу).
2. Рубрикатори ресурсів. Каталог посилань на ресурси розбитий по тематичній спрямованості.
3. Система контекстного пошуку документів. Система тематичного пошуку, пошуку за ключовими словами і/або атрибутами (контекстом) документів.
Особливістю пошукових інструментів використованих на порталі є їх інтеграція на базі єдиного призначеного для користувача інтерфейсу. Задачею вирішуваною пошуковою системою є організація швидкодійного і якісного (високоточного) пошуку по будь-якому набору класифікаційних атрибутів и/или ключових слів (пошукових зразків).
Основне призначення пошукового бібліотечного сервісу - полегшити користувачу доступ до наукової і освітньої інформації. Передбачається використовування єдиного формату метаданих для опису ресурсів і використовування цих метаданих для формування тематичних каталогів і рубрикаторів, а також атрибутний пошук по них. Складання описів ресурсів проводиться колективом експертів-рецензентів.
Взаємодія з ресурсами електронних бібліотек визначається сервісами, які забезпечують користувачу бібліотечні послуги.
1 Бібліотечний сервіс тематичного пошуку та відбору повнотекстової інформації
Предметом даної розробки є бібліотечний сервіс тематичної селекції матеріалів з повнотекстової бази даних електронної бібліотеки.
Серед основних проблем і відповідно задач, які необхідно вирішити для створення та удосконалення такого сервісу тематичного пошуку та відбору повнотекстової інформації [1], слід зазначити наступні:
Пошук інформації. Сучасні методи пошуку за ключовими словами допускають велику кількість семантичної неоднозначності. Це пов’язано з тим, що кожне слово має кілька значень (змістів). Вони також пропускають інформацію, коли для пошуку заданого змісту використовуються різні терміни, що мають одне і те саме значення [2]. Інформаційний пошук традиційно зосереджується на відношенні між запитом користувача й інформаційною базою. В той же час, використання взаємозв'язків між відібраними частинами інформації (створення яких можна забезпечити за допомогою використання онтологій) може містити інформацію шуканого змісту. Неявні структури допомагають користувачу використовувати і керувати інформацією більш ефективно [3].
Вилучення інформації. Щоб вилучити доречну інформацію з інформаційних джерел, користувач застосовує перегляд і читання матеріалу. Це пов’язано з тим, що автоматичні агенти не мають знань „здорового глузду”, що необхідні для видобування такої інформації з текстових чи мультимедіа колекцій. Крім того, вони не в змозі семантично поєднувати інформацію, розподілену по різних джерелах.
Слабка підтримка джерел мультимедіа інформації. Існує надмірна складність в обслуговуванні та швидкості виконання запитів, коли такі джерела стають великими. Коректне ведення таких колекцій вимагає засобів автоматизованого представлення семантики.
Автоматичне ведення поколінь документів дозволило б забезпечити адаптивність веб-сайтів, що динамічно реконфігуровуються відповідно до представлень користувача чи інших аспектів. Покоління напівструктурованих інформаційних представлень вимагає доступного для машини представлення семантики цих інформаційних джерел.
Інструментальні засоби управління знаннями, що поєднують ресурси, розсіяні по репозиторіям, задача полягає в тому, щоб зв’язати їх у послідовний корпус у певному семантичному взаємозв'язку. Попередні дослідження в області інформаційної інтеграції [3] в значній мірі зосередилися на об'єднанні гетерогенних баз даних і баз знань, що представляють інформацію структурованим способом, часто за допомогою формальних мов. Навпаки, мережа складається з неструктурованого чи напівструктурованого тексту, поданого природними мовами.
Онтології забезпечать спосіб представлення інформаційних ресурсів на рівні семантики. Модель предметної області, що в існуючих архітектурах задана неявно, в онтології може бути прийнята як об'єднана структура для явного представлення семантики.
Роль онтологій. Онтології є ключовим засобом, що забезпечує технологію Семантичної Мережі. Вони вирівнюють розуміння символів людиною з „розумінням” машиною. Онтології були розвинуті в штучному інтелекті для полегшення спільного та повторного використання знань. Починаючи з початку 1990-их років, онтології стали популярною темою досліджень. Вони вивчались в кількох напрямках дослідження штучного інтелекту, включаючи розробку знань, обробку природної мови і представлення знань. Раніш використання онтологій також стало широко розповсюдженим в областях інтелектуальної інформаційної інтеграції, кооперативних інформаційних систем, інформаційного пошуку, електронної торгівлі і керування знаннями. Онтології стають популярними через те, що вони обіцяють загальнодоступний і звичайний спосіб розуміння предметної області, який може бути контентом між людьми і прикладними системами. Крім того, використання онтологій і інструментальних засобів їх підтримки надає можливість поліпшити здатність управління знаннями у великих організаціях. Це описує Семантичну Мережу через архітектуру управління знаннями і набір інноваційних інструментальних засобів для семантичної обробки інформації. Інструментальне середовище онтологій адресує три ключові проблеми:
- Одержання онтологій і з'єднання їх з великими обсягами даних. З причин великих об’ємів даних цей процес видобування інформації повинен бути автоматизований з використанням технологій обробки природної мови. Забезпечення якості цього процесу вимагає участі людини, що використовує редактори онтологій для побудови і керування онтологіями.
- Збереження і підтримка онтології. Використовуються Схеми опису ресурсів (RDF), які зберігаються в репозиторіях, що забезпечує технологію баз даних і прості форми міркування, засновані на правилах.
- Виконання запитів і семантичний перегляд з інформаційних джерел. Семантично посилені пошукові сервери, переглядаючи знання, спільно використовують підтримку машини обробки семантики.
Формально під моделлю онтології О будемо розуміти впорядковану трійку виду:
О = <Х, R, Ф>, де
Х – кінцева множина концептів предметної області, котрі представляє онтологія О;
R - кінцева множина відношень між концептами заданої предметної області;
Ф - кінцева множина функцій інтерпретації (аксіоматизація), заданих на концептах чи/або відношеннях онтології О.
Х – завжди кінцева і непуста множина. Коли R і Ф – пусті множини, тоді онтологія трансформується в словник. При R – пустій множині, а Ф – непустій маємо пасивний словник предметної області. Коли R і Ф – непусті, маємо таксономію понять предметної області. Під таксономічною структурою будемо розуміти ієрархічну систему понять, зв’язаних між собою відношенням is_a (бути елементом класу).
Узагальненням предметних онтологій є метаонтологія, що оперує загальними концептами та відношеннями, що не залежать від конкретної предметної області. Ії концептами є загальні поняття, такі як “об’єкт”, “властивість”, “значення” тощо.
При розробці загальної онтології крім проблем, притаманних проблематиці баз знань, виникають проблеми, пов’язані з автоматизованою побудовою онтології та її розмірами. Труднощі полягають в неможливості вмістити усі проблемні області та в збільшенні обсягів такої онтології до розмірів, коли її обробка стане неможливою.
Критична проблема для семантичної мережі: як забезпечити відповідність між глобальною онтологією і локальними онтологіями. Цей аспект є центральним, якщо ми хочемо використовувати глобальну онтологію для того, щоб відповісти на питання в контексті семантичної мережі. Проблема визначення відповідності між глобальною і локальною онтологіями - в основі інтеграції в мережі інтернет. Ця проблема ще глибоко не досліджена. Навіть самі виразні мови специфікації онтології не достатні для інформаційної інтеграції в семантичній мережі.
Сучасні семантичні підходи Web, щоб мати можливість використовувати розширену колекцію даних інтернету, використовують методи анотації, щоб зв'язати індивідуальні інформаційні ресурси зі зрозумілими машині метаданими. При цьому виникають дві проблеми:
- потреба в надійності даних у динамічних, що постійно змінюються, мережах;
- необхідність явно визначити відношення між абстрактними поняттями даних.
Онтології забезпечують ключовий механізм для рішення цих складних проблем.
2 МЕТОД Формування ТЕМАТИЧНОЇ МЕТАІНФОРМАЦІЇ
В СИСТЕМІ Е-КОНТЕНТ
Головна ідея методу, що використовується в системі Е-Контент полягає в використанні лексичної онтології WordNet [4] і покладена в основу процеса формування тематичної онтології: терміни, що описують ресурси або структури в інформаційних джерелах, містять придатну для використання семантику. Друга ідея стосується використання результатів процесу формування онтології як „теми” для зовнішніх користувачів і застосувань, для того щоб використовувати „тему”, кожен елемент онтології повинний мати відоме значення. База даних WordNet обрана як лексична онтологія, спрямована забезпечити таку “відомість”.
Таблиця 2.1 - WordNet словоформи і значення
| | F1 | F2 | F3 | … | Fn |
| M1 | E1,1 | E1,2 | | | |
| M2 | | E2,2 | | | |
| M3 | | | E2,3 | | |
| … | | | | … | |
| Mn | | | | | Em,n |
Лексична семантика WordNet заснована на асоціації між словоформами і поняттям чи значенням, що вони виражають. Лексична матриця М (див. таблицю 2.1) представляє асоціацію між формою кожного слова (стовпчики) та його значенням (рядки). Рядки представляють синонімічні набори (synsets), стовпчики показують словоформи (лема). У лінгвістиці лема - слово і всі відмінювані форми. Лема для go, наприклад, складається з go, goes, going, went і gone (або для української мови - йти, пішов, вийшов ...). База даних WordNet містить 146 350 лем, організованих у 111 223 синсетів (для англійської мови).
Елемент E1,1 приймає значення таке, що словоформа F1 може представляти слово, що означає M1. Якщо є два входження в тому ж самому стовпчику, що відповідає словоформі, то маємо випадок полісемії (polysemous) - тобто, словоформа представляє більше чим одне значення. Якщо є, принаймні, два входження в тому ж самому рядку, то ці дві словоформи синонімічні.
З огляду на словоформу F, її i-е значення буде позначене F#i. Наприклад, словоформа "course" має вісім значень у WordNet; перше - course#1 = “education imparted in a series of lessons or class meetings”.
2.1 Метод анотації теми засобами Wordnet
У стадії локальної анотації, проектувальник вручну вибирає відповідне WordNet значення для кожного концептуального елемента темиатичної онтології. Оскільки словоформа може мати різні значення в WordNet, стадія анотації включає два кроки: вибір словоформи і вибір значення.
У першому кроці, морфологічний процесор WordNet допомагає проектувальнику, пропонуючи відповідну словоформу для кожного елемента (клас чи атрибут) теми. Морфологічний процесор обробляє термін - конвертує його до загальної форми і перевіряє, чи існує цей термін в базі даних WordNet.
У другому кроці вибору значення, проектувальник може вибрати один, чи кілька значень (названих senses(змістами) у WordNet. Необхідно зазначити, що проектувальники можуть вибирати тільки серед існуючих WordNet значень: WordNet не дозволяє зовнішньому застосуванню розширювати форми новими значеннями.
Якщо проектувальник теми не знаходить відповідне значення в WordNet, термін вважають невідомим, і система не отримує ніяких словникових відношень.
2.2 Генерація загального тезауруса теми
Процес конструювання загального тезауруса інкрементно додає два типи відношень.
Lexicon-derived (виведені зі словника) відношення. Вони породжуються з анотацій схеми для лексичної онтології. WordNet визначає велику кількість семантичних відношень між його значеннями. Система виводить лексичні відношення між термами із семантичних відношень, визначених у WordNet. Він генерує ці відношення, використовуючи наступні конструкції WordNet:
synonymy (синонімічність - similar relation – подібні відношення) відповідає SYN відношенню в ODLI3;
hypernymy (super-name relation – видове відношення) відповідає BT відношенню;
hyponymy (sub-name relation) відповідає NT відношенню;
holonomy (whole-name relation) відповідає RT відношенню;
meronymy (part-name relation) відповідає RT відношенню в ODLI3. RT відношення виражають “generic” зв'язки між двома термами й у такий спосіб відповідають обом hyponymy і meronymy ;
correlation(кореляція) (коли два терма розділяють один hypernym) відповідає RT відношенню в ODLI3.
Невідомі терми не можуть додаватися до загального тезауруса, але некоректна анотація може представляти некоректні відношення.
Відношення, що добавляються проектувальником (Designer-supplied). Проектувальник може безпосередньо сформувати нові відношення. Ця операція є критичною, тому що нові відношення вводяться, щоб належати загальному тезаурусу. Якщо добавляються безглузді чи некоректні відношення, наступний крок може породжувати некоректну загальну тематичну онтологію.
3 Система Е-КОНТЕНТ як бібліотечний сервіс пошуку повнотекстової інформації
Система Е-КОНТЕНТ призначена для автоматизованого пошуку та аналітичної обробки повнотекстової інформації (Інтернет-джерела, електронні листи, корпоративні сховища даних тощо). Система дозволяє визначати інформаційні джерела та встановлювати тематичні фільтри для створення персональної структурованої добірки інформації, що відповідає потребам користувача. Незалежність системи від мови джерела інформації дозволяє використовувати її для моніторингу джерел з різних регіонів світу, доставляючи клієнтам відібрану інформацію, що відноситься до сфери їхнього інтересу. Збереження текстів в локальній повнотекстовій базі даних забезпечує доступ до інформації, яка в мережаному джерелі через деякий час може бути вже недоступна (поновлення сайту, вилучення зі сховища тощо).
У всесвітніх бібліотеках щодня з'являються мільйони кілобайт інформації, яка є джерелом для вирішення різноманітних задач. Але інформаційна насиченість та постійна поновлюваність цієї інформації в мережі створюють і значні труднощі при пошуку необхідної інформації. Час, що витрачається сьогодні на пошук і первинну обробку інформаційних потоків з використанням загальнодоступних пошукових механізмів, стає порівнянним з пошуком традиційними методами. Все це потребує використання нових інформаційних технологій, які підтримує система Е-КОНТЕНТ, для підвищення ефективності пошуку.
Система Е-КОНТЕНТ побудована на Web-технологіях, що дозволяє використовувати її у віддаленому режимі з будь-якого комп'ютера, підключеного до Інтернет. В автоматичному режимі через заданий проміжок часу аналізується інформаційна поновленність визначених мережаних джерел та доповнюється локальна база даних системи новою інформацією.
Використання системи Е-КОНТЕНТ дозволяє значно підвищити ефективність збору інформації з мережаних джерел, пошуку інформації у відповідності до індивідуально визначених тематичних потреб користувача та формування аналітичних матеріалів.
Перелік сервісів системи Е-КОНТЕНТ представлено на рис. 3.1.

Рисунок 3.1 - Сервіси системи Е-КОНТЕНТ
3.1 Сервіс спеціфікації тем інформаційного пошуку (менеджер тем)
Сервіс «Менеджер тем» призначено для визначення в системі множини тем, які використовуються для вирішення задач пошуку та аналізу текстової інформації. При використанні сервісу «Менеджер тем» (див. рис.3.1) користувач отримує вікно з горизонтальним меню у текстовому вигляді та піктограмами. Горизонтальне меню складається з наступних елементів: Вихід, Теми (Формування тем Перегляд файлів), Експорт/Імпорт (Експорт тем Імпорт тем), Вікна (Вертикальні Горизонтальні Пластами Каскадом Закрити всі), Допомога (Зміст Про Контент-Теми)
Сервіс «Формування тем» призначено для визначення в системі множини тем, структурованих у вигляді дерева (рис. 3.2). Для кожної теми у системі визначаються індикатори, тобто множину пошукових логічних виразів, наявність яких в тексті означає приналежність тексту до обраної теми. Елементами логічних виразів виступають слова та словосполучення (з використанням спеціальних символів ? , * та ~~), пов’язані логічними операторами AND, OR, NOT та спеціальними операторами визначення околиці одночасної наявності термінів.

Рисунок 3.2 Теми. Формування тем
В області дерева тем спливає меню: Поновити, Розкрити все, Закрити все, Добавити, Змінити, Знищити, реалізація которого повністью визначає функціональні можливості роботи з деревом та списком.
В області списку індикаторів тем (права частина вікна) при натисненні правої клавіши «миші» спливає меню: Добавити, Змінити, Знищити, Перегляд файлів.
При виборі «Добавити» користувач одержує вікно, що зображено на рис. 3.3.
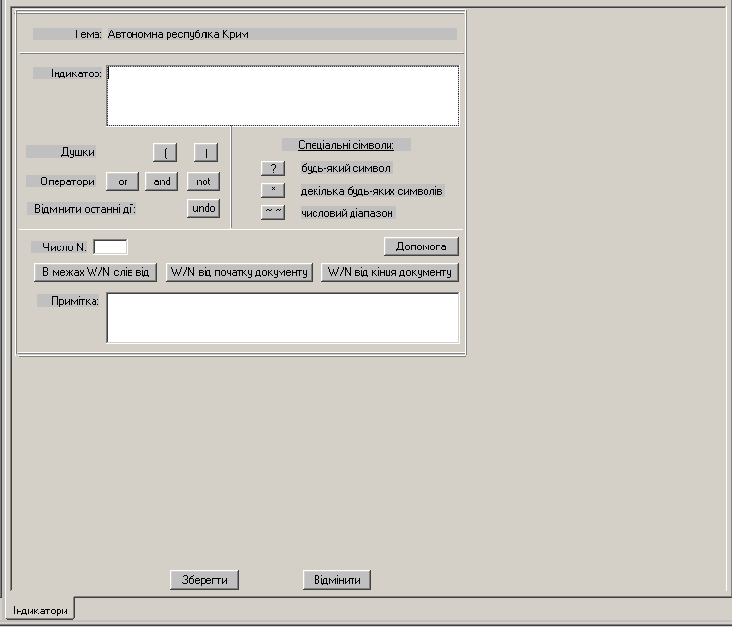
Рисунок - 3.3 Добавити індикатор
і визначає в полі вводу «Найменування індикатора» індикатор для поточної теми в дереві тем. Правила формування індикатора представлені в підрозділі 3.1.2. Використання допоміжних кнопок логічних операторів, спеціальних символів та елементів для визначення околиці пошуку терміну при формуванні індикатора дозволяє прискорити та полегшити процес формування індикатора. Клік на кнопці заносить відповідний символ в поле формування індикатора. По замовчуванню число N приймає значення 5. Число N використовується при кліку на кнопках: «В межах W/N слів від», «W/N від початку документу» та «W/N від кінця документу». Поле вводу «Примітка» використовується для збереження допоміжної довільної інформації, пов’язаної з індикатором.
В системі реалізована можливість зміни «Змінити» та знищення «Знищити» поточного індикатора.
В системі реалізована можливість перегляду файлів, що зареєстровані в системі і задовольняють умовам, сформульованим в пошуковому рядку (поточному індикатору).
3.1.2 Специфікація пошукових об’єктів для тематичного пошуку в системі Е-КОНТЕНТ
Пошуковий зразок, що використовується в системі, представляє собою логічний вираз, в якому пошукові терміни (слова та фрази) пов’язані логічними операторами:
-
AND
використовується для визначення необхідності одночасної наявності в тексті виразів, які пов’язує цей оператор
OR
використовується для визначення необхідності наявності в тексті одного з виразів, які пов’язує цей оператор
NOT
використовується для визначення необхідності відсутності в тексті виразу, який визначений за цим оператором. Якщо NOT - не перший в пошуковому рядку, то необхідно використовувати AND або OR з оператором NOT (наприклад, «Ріпка AND NOT бабка»).
Пошукові терміни можуть включати наступні спеціальні символи:
-
?
Відповідає довільному символу
*
Відповідає довільній кількості довільних символів
~~
Числовой диапазон
Крім того, слова можуть бути пов’язані спеціальними операторами визначення околиці одночасної наявності термінів. Терміни пов’язуються наступним чином:
-
<термін1> w/<термін2>
<термін1> повинен зустрітись в околиці з n слів від <термін2> (по замовчуванню n = 5)
<термін1> w/xfirstword
<термін1> повинен зустрітись в перших n словах (по замовчуванню n = 5)
<термін1> w/xlastword
<термін1> повинен зустрітись в останніх n словах (по замовчуванню n = 5)
Зазначимо, що в логічному виразі використовуються також дужки «(» та «)».
3.2 Сервіс тематичного пошуку інформації
Сервіс «Пошук інформації» призначено для пошуку потрібної користувачу інформації у відповідності до потреб задач, що вирішуються. Це основний сервіс системи, який використовує визначену в системі структуру тем та структуру колекцій проіндексованих текстових файлів. Сервіси «Менеджер тем» та «Менеджер колекцій» використовуються для створення умов найбільш ефективного та зручного пошуку текстової інформації, яка задовольняє умовам користувача.
При виборі сервісу «Пошук інформації» у вікні списку сервісів (див. рис.3.1) отримуємо вікно «Пошук інформації» (рис. 3.4).
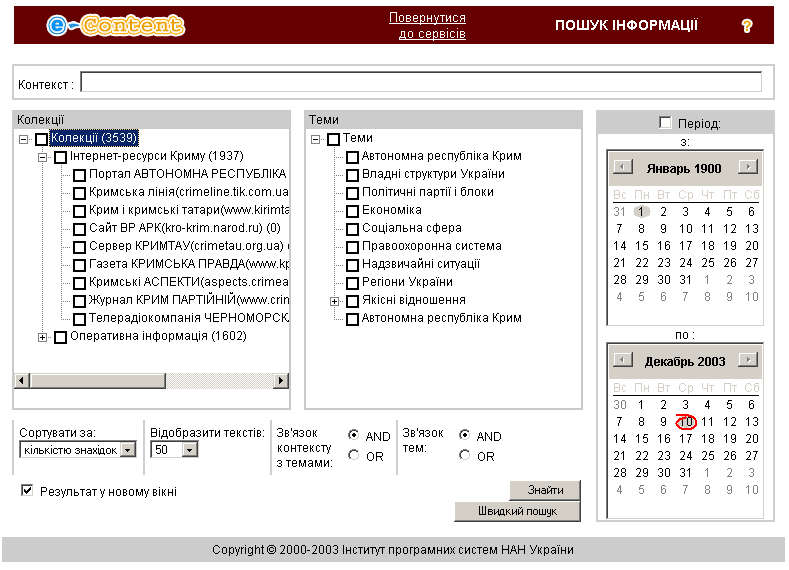
Рисунок – 3.4 Формування умов пошуку інформації
Вікно містить наступні елементи:
- вхідне поле «Контекст» (заповнення необов’язкове);
- дві зони вибору «Колекції» та «Теми»;
- календарі для визначення періоду часу, який включає системну дату створення файлу;
- радіокнопки для вибору логічних операторів для зв’язку між індикаторами тем та зв’язку між контекстом та індикаторами тем;
- поле вибору максимальної кількості текстів, що відображуються в результаті пошуку (по замовчуванню - 50);
- поле вибору способу упорядкування результуючого списку текстів (по замовчуванню - «кількість знахідок»);
- кнопки «Знайти» та «Швидкий пошук»;
У вхідному полі «Контекст» можна визначити довільний пошуковий логічний вираз у відповідності з правилами, наданими в підрозділі 3.1.2.
Для виконання пошуку обов’язково необхідно відмітити множину колекцій (хоча б одну колекцію) та множину тем (хоча б одну тему при відсутності контексту). Зауважимо, що вибір колекції чи теми певного рівня передбачає вибір всіх підпорядкованих йому елементів.
При необхідності в умовах пошуку враховувати дату створення текстового файлу, користувач «включає» елемент пошуку «Період» (проставивши відмітку) і в календарях визначає потрібні дати. Зазначимо, що при виборі колекцій в календарях встановлюється інтервал часу, якому задовольняють всі обрані користувачем колекції. Інформація про інтервал часу, який включає всі обрані колекції, надана під деревом колекцій. Користувач може в календарях звузити автоматично визначений інтервал у відповідності зі своїми потребами.
У вікні формування умов пошуку (див. рис. 3.4) по замовчуванню встановлена мітка для елементу «Результат в новому вікні». Це дозволяє одержувати результат кожного наступного пошуку в новому вікні і зберігати доступ до результатів попередніх пошуків. Якщо мітку зняти, то результат пошуку буде сформований в попередньому вікні результатів і знищить результати попереднього пошуку.
Для збереження часу на пошук та відображення текстів, у вікні формування умов пошуку (див. рис. 3.4), можна натиснути кнопку «Швидкий пошук» і поряд з темами одержати в дужках буде відображено кількість файлів з текстами відповідної теми в обраних колекціях.
Кнопка «Знайти» у вікні формування умов пошуку (див. рис. 3.4) ініціює пошук в текстах обраних колекцій у відповідності з визначеними умовами (теми, період, контекст тощо). При формуванні логічного виразу для пошуку система використовує визначені у вікні формування умов пошуку логічні оператори для поєднання контексту та індикаторів визначених тем.
При відсутності текстів, що задовольняють умовам пошуку, видається повідомлення, а в іншому разі надається вікно результатів, аналогічне зображеному на рис. 3.5.
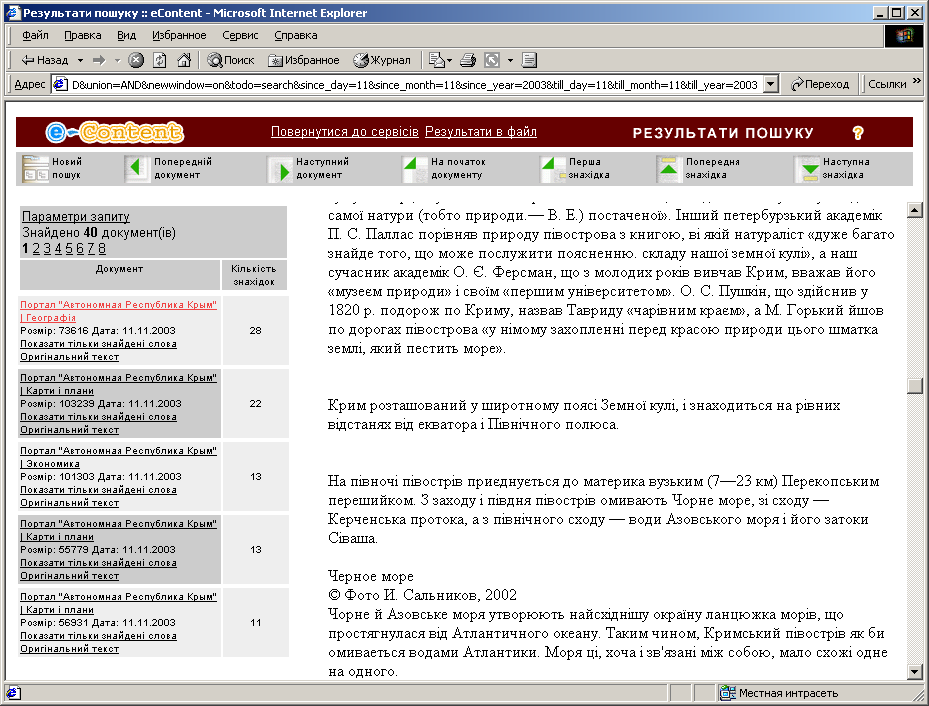
Рисунок – 3.5 Результат пошуку
В лівій частині вікна «Результати пошуку» надано інформацію про кількість знайдених документів, параметри запиту та список одержаних документів (кількість обмежена визначеним у вікні «Пошук інформації» числом). При кліку на посиланні «Параметри запиту» одержуємо параметри запиту.
Посилання, що містяться в елементах списку результатів пошуку (див. рис. 3.5), дозволяють переглянути поточний текст крім вигляду, що надає система, ще і в оригінальному вигляді та вигляді тільки пошукових слів (індикаторів визначених тем).
Система Е-КОНТЕНТ подає текст з виділеними кольором елементами пошукового запиту (контекст, індикатори тем). Кнопки на смужці в верхній частині вікна дозволяють перегортати сторінки тексту для знаходження першої знахідки попередньої знахідки, наступної знахідки або на початок документу.
Крім того, кнопки на смужці в верхній частині вікна дозволяють повернутись в вікно формування нового запиту на пошук («Новий пошук») та переміщуватись в списку документів («Попередній документ», «Наступний документ») для їх перегляду. Поточним документ стає і при кліку на його області в списку результатів.
Висновки
Методика та засоби Е-КОНТЕНТ підтримують автоматизовану побудову і розширення тематичних онтологій. Сформована онтологія може бути використана при роботі з багатьма джерелами інформації.
Додаток А. Стандарти, що використовуються в бібліотечних сервісах пошуку інформації
| Метаданные и форматы RUSMARC UNIMARC MARC 21 Dublin Core ГОСТ 7.14 ГОСТ 7.19 |
| Поиск информации Z39.50 Представлена информация о стандарте ANSI/NISO Z39.50 (ISO 23950), ориентированная на российских разработчиков и пользователей автоматизированных информационных систем. Этим стандартом определяется протокол поиска информации в распределенной неоднородной среде, использующий возможности архитектуры "клиент/сервер". Даются спецификации структур данных и правил. |
| Каталогизация ГОСТ 7.1–2003 Российские правила каталогизации |
| Тезаурусы ISO 2788 ISO 5964 ГОСТ 7.24 ГОСТ 7.25 |
| Коды ISO 3166 ISO 639-2 ГОСТ 7.67 |
| Даты, время ГОСТ 7.64 |
| МБА ISO ILL |
Додаток Б. Визначення термінів
Іменний покажчик
різновид предметного покажчика, що включає прізвища, імена, псевдоніми, прізвиська.
Індексування
процес визначення та проставлення певних позначок на документах, справах, картках з метою полегшення їх віднайдення.
Інформаційна потреба (ІП)
потреба юридичної чи фізичної особи в інформації, необхідній для вирішення наукового або практичного завдання.
Інформаційна служба
організація (підрозділ, установа) або їх сукупність, що здійснює практичну роботу з інформаційного обслуговування.
Інформаційна технологія
сукупність способів оброблення інформації в усіх видах людської діяльності з використанням сучасних засобів зв'язку, поліграфії, обчислювальної техніки та програмного забезпечення.
Інформаційний аналіз ретроспективної документної інформації
початковий етап аналітико-синтетичного оброблення документної інформації, який складається з вивчення документів та вилучення з них найсуттєвіших відомостей.
Інформаційний пошук
пошук документів, відомостей про них або фактів, відбитих у документах.
Інформаційний продукт
документована інформація, підготовлена і призначена для задоволення інформаційних потреб.
Інформаційно-пошукова мова (ІПМ)
знакова система, призначена для описування змістових аспектів документів і запитів у формі, придатній для здійснення пошуку інформації.
Інформаційно-пошукова система (ІПС)
система пошуку інформації , яка є сукупністю ІПМ, правил кодування, критерію змістової відповідності, інформаційно-пошукового масиву документів та засобів реалізації.
Інформаційно-пошуковий масив
упорядкована сукупність документів, фактів або відомостей про них, призначених для інформаційного пошуку.
Інформаційно-пошуковий тезаурус (ІПТ)
нормативний словник-довідник, призначений для перекладання з природної мови на ІПМ, що містить усі дескриптори, перелічені в алфавітному порядку разом з ключовими словами, які входять до їхніх класів, а також вказівки на ієрархічні та асоціативні відношення між дескрипторами.
Ключове слово
слово або стале словосполучення, яке має істотне смислове навантаження в тексті документа й може бути пошуковою ознакою.
Книга
одна з форм матеріальної конструкції документа у вигляді оправленого блоку скріплених у корінці аркушів паперу.
Конфіденційна інформація
документована інформація, яка знаходиться у володінні, користуванні або розпорядженні окремих юридичних чи фізичних осіб і поширюється за їх бажанням відповідно до передбачених ними умов.
ПЕРЕЛІК ПОСИЛАНЬ
- Ф.И.Андон, А.Е.Яшунин, В.А.Резниченко. Логические модели интеллектуальных информационных систем. Киев, 1999, Издательство "Наукова думка", 397 С. ;
- П.І. Андон, В.О. Дерецький. Процесори пошуку та аналізу природномовної текстової інформації в аналітичних системах // Проблемы программирования”, 2001. – N3-4. - С.144-165.
- Hearst, M.A. (1998) Information integration. IEEE Intelligent Systems, September/October: 12-24.
- Local source annotation with WordNet. The integration designer chooses a meaning for each element of a local source shema, according to the WordNet lexical ontology (www.cogsci.princeton.edu/~wn).