
Управления реляционными базами данных и анализа данных
| Вид материала | Руководство |
СодержаниеМощный и гибкий анализ данных на веб-основе Выявление закономерностей и анализ статистики посещений веб-узлов Связанные кубы данных и доступ к ним по протоколу HTTP |
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
- Проектирование базы данных, 642.58kb.
- «Прикладная информатика (по областям)», 1362.72kb.
- Тема Базы данных. Системы управления базами даннях (12 часов), 116.1kb.
- Реляционная модель данных в системах управления базами данных, 200.05kb.
- Системы управления базами данных, 313.7kb.
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- 1. 2 Системы управления базами данных. Основные функции, 630.95kb.
- Развитие объектно-ориентированных систем управления базами данных, 122.52kb.
- Любая программа для обработки данных должна выполнять три основных функции: ввод новых, 298.05kb.
Мощный и гибкий анализ данных на веб-основе
SQL Server 2000 предоставляет несколько важных средств в службах анализа данных, позволяющих компаниям делать дополнительные выводы на основе своих данных с помощью быстрого и универсального анализа. В сервере SQL Server 2000 применяется новая интегрированная технология выявления закономерностей, которая является базовым компонентом для реализации на основе сервера SQL Server законченного комплексного решения для анализа данных. Связанные кубы данных и доступ к ним по протоколу HTTP распространяют возможности анализа за пределы компании и ее корпоративной сети, открывая новые рынки для многомерных данных и новые способы поиска этих данных в Интернете. Помимо этих очевидно важных средств, службы анализа данных также включают в себя такие возможности, как DISTINCT COUNT, которые упрощают работу аналитика. Особенно удобный для анализа пользовательского трафика на веб-узлах метод DISTINCT COUNT традиционно считается профессиональным средством анализа данных из-за относительной сложности его реализации. Службы анализа данных в сервере SQL Server 2000 предоставляют всем пользователям возможность применять метод DISTINCT COUNT в качестве нового измерительного средства и позволяют аналитикам отвечать на такие важные вопросы, как: «Сколько различных пользователей посетило сегодня мой веб-узел?» Это лишь один небольшой пример того, как группа разработки SQL Server расширила возможности и гибкость служб анализа данных в сервере SQL Server 2000.
Выявление закономерностей и анализ статистики посещений
веб-узлов
Интегрированное выявление закономерностей является новым средством сервера SQL Server 2000, которое в составе служб анализа данных включено в выпуски Enterprise Edition, Standard Edition, Personal Edition, Developer Edition и Enterprise Evaluation Edition. Технология выявления закономерностей помогает пользователям анализировать данные в реляционных базах данных и многомерных кубах OLAP для обнаружения закономерностей и структур, которые могут быть полезны для прогнозирования. Компоненты для выявления закономерностей в сервере SQL Server 2000 тесно интегрированы с источниками реляционных данных и данных OLAP. Фактически результаты выявления закономерностей могут использоваться при создании дополнительных измерений куба для последующего анализа данных OLAP. Их можно использовать в реляционных базах данных с помощью простого выполнения запросов SQL. Средства выявления закономерностей, включенные в службы анализа данных сервера SQL Server 2000, вошли в открытую и расширяемую реализацию новой спецификации OLE DB для выявления закономерностей.
Сервер SQL Server 2000 включает в себя два класса алгоритмов выявления закономерностей, разработанные группой Microsoft Research: Microsoft Decision Trees (деревья решений) и Microsoft Clustering (кластеризация). Алгоритм Microsoft Decision Trees в действительности состоит из четырех различных алгоритмов и основан на понятии классификации. Алгоритм строит дерево, прогнозирующее значения столбцов на основании других столбцов обучающего набора (т.е. таблицы фактов). Решение о размещении каждого узла в дереве принимается алгоритмом, а наиболее значимые и определяющие различие атрибуты отображаются ближе к корню дерева решений. Реализация алгоритма Microsoft Decision Trees может использоваться для определения тех посетителей веб-узла, кто вероятнее всего щелкнет конкретный рекламный заголовок или купит конкретный продукт на коммерческом веб-узле. Алгоритм Microsoft Clustering использует метод ближайшего соседа для группировки записей в кластеры, проявляющие некоторые подобные, предсказуемые характеристики. Часто эти характеристики могут быть скрыты или неясны. Например, алгоритм Microsoft Clustering может использоваться для оценки зависимости потребительского спроса от возраста. Разумеется, интегрированное выявление закономерностей в сервере SQL Server 2000 поддерживает алгоритмы, разработанные сторонними производителями.
Поддержка выявления закономерностей пронизывает службы анализа данных и другие компоненты сервера SQL Server 2000. Для упрощения разработки, создания, изучения и использования моделей выявления закономерностей предусмотрены новые мастеры, редакторы и другие элементы пользовательского интерфейса. Результаты выявления закономерностей могут быть включены в кубы OLAP, а для упрощения программного управления моделями выявления закономерностей, связанными с этими кубами, в сервере SQL Server 2000 был расширен синтаксис MDX.
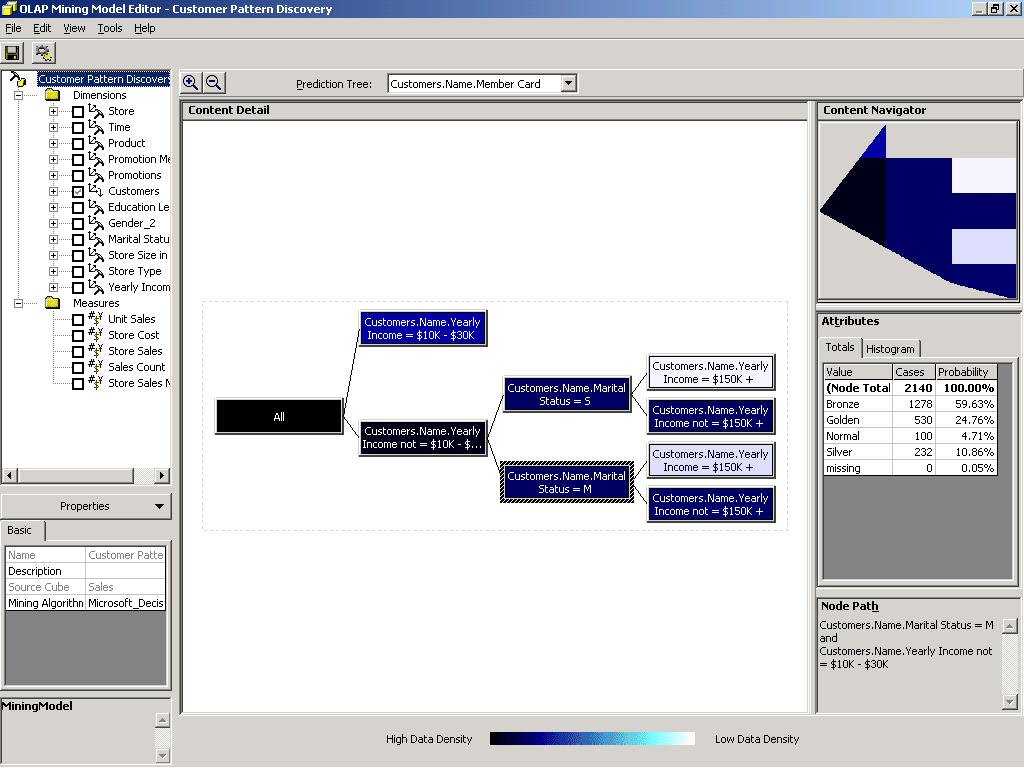
Рис. 3. Редактор Data Mining Model Editor отображает результаты анализа закономерностей (здесь применяется алгоритм дерева решений, разработанный корпорацией Майкрософт)
Интегрированная технология выявления закономерностей (технология «информационной проходки») – ключевой элемент в стратегии корпорации Майкрософт, направленной на создание средств анализа статистики посещений веб-узлов. Они предназначены для работы в итеративном цикле, включающем следующие операции:
- Сбор информации о работе пользователей при просмотре страниц того или иного веб-узла и при поиске по нему.
- Анализ этой информации, позволяющий выявить закономерности и подготовить соответствующие прогнозы (с использованием технологии информационной проходки).
- Индивидуализированный подбор рекламы и веб-ресурсов для посетителей веб-узла, осуществляемый на основе такого анализа (например, показ баннеров для тех продуктов, которыми может заинтересоваться конкретный покупатель).
- Принятие решений о перенастройке действующих систем на основе данных, накопленных с использованием операций OLAP.
В идеальном случае такой процесс идет на веб-узлах электронной коммерции непрерывно, что позволяет максимально учитывать интересы покупателей и дает возможность этим узлам выгодно отличаться от своих конкурентов. Интеграция с сервером Commerce Server 2000 упрощает сбор сведений о перемещении пользователей по веб-узлу, данных о покупках и других торговых операциях, прочей информации об их действиях – в результате у менеджеров возникает целостное представление о работе веб-узла. Как следствие, у них появляется возможность изменять или создавать новые маркетинговые программы, проводить рекламные кампании, а также осуществлять коммерческое планирование и поддерживать личные настройки пользователей веб-узла. Собранные сведения также можно использовать в системах планирования ресурсов предприятия (ERP) и управления связями с потребителями (CRM), что позволяет регулировать поставки в зависимости от потребностей покупателей.
Связанные кубы данных и доступ к ним по протоколу HTTP
Поскольку объемы данных, которые компании собирают о своих покупателях, постоянно увеличиваются, компаниям приходится искать новые способы анализа и эффективного использования этой информации. Службы анализа данных сервера SQL Server 2000 используют две новые технологии, позволяющие выполнять анализ через Веб: связанные кубы данных и доступ к ним по протоколу HTTP. Благодаря этим технологиям пользователи получают возможность использовать для анализа кубы данных, которые принадлежат партнерам или продаются исследующими рынок компаниями.
Связанными называются кубы данных, которые определены и хранятся на других серверах анализа данных, в том числе на внешних серверах, находящихся за корпоративным брандмауэром. Конечные пользователи видят и используют связанные кубы так же, как и обычные кубы данных. Связанные кубы дают поставщикам данных возможность создавать, хранить и поддерживать какой-либо куб данных на одном сервере анализа данных, одновременно открывая его для доступа как связанный куб для множества других серверов. Передача данных происходит по протоколам HTTP и HTTPS. Связанные кубы используют сводные данные, полученные на основе исходных кубов и не требуют хранения собственных данных. Этот метод позволяет организации, с одной стороны, сохранять право собственности на куб данных и обновлять его, а с другой – предоставлять находящиеся в нем сведения для одновременного доступа многим потребителям. Благодаря такой технологии обеспечивается безопасность информации поставщиков данных, поскольку важные сведения можно хранить в источниках и кубах данных на защищенных серверах, но при этом они будут широко доступны для других серверов в виде связанных кубов. Кроме того, комбинируя данные из внешнего связанного куба, полученного от проводящей исследования рынка компании, и внутреннего куба, в котором содержатся собственные данные по сбыту, можно составить виртуальный куб данных. С его помощью достигается новый уровень аналитического понимания рыночной ситуации благодаря мгновенным оценкам доли рынка для определенного товара, а также относительных тенденций развития, охвата и потенциала этого рынка.
Важным фактором при проведении веб-анализа куба данных является гибкость этой операции, возможность использовать для нее разнообразные клиентские программы. Службы анализа данных сервера SQL Server 2000 используют встроенное средство поддержки протокола HTTP, обеспечивающий доступ к кубу по этому протоколу. Таким образом у организаций появляется возможность совместно использовать кубы данных или безопасно обращаться к удаленным кубам по протоколу HTTP через брандмауэр без необходимости открывать определенные порты веб-сервера.