
Нейрокомпьютерная обработка сигналов и изображений
| Вид материала | Документы |
- Нейрокомпьютерная обработка сигналов и изображений, 259.53kb.
- Нейрокомпьютерная обработка сигналов и изображений, 184.71kb.
- Нейрокомпьютерная обработка сигналов и изображений, 236.58kb.
- Нейрокомпьютерная обработка сигналов и изображений, 193.52kb.
- «Обработка изображений» Общая трудоемкость изучения дисциплины составляет, 15.75kb.
- Цифровая обработка многомерных сигналов, 307.08kb.
- Белорусский государственный университет применение информационных технологий при анализе, 187.23kb.
- Обработка и передача изображений, 213.76kb.
- Комплекс (умк) дисциплины «Цифровая и аналоговая обработка сигналов» для специальности, 290.97kb.
- Учебная программа дисциплины «Методы цифровой обработки сигналов и изображений» (СД., 220.56kb.
Нейрокомпьютерная обработка сигналов и изображений
Нейрокомпьютерная обработка сигналов и изображений
ПЕРСПЕКТИВНЫЕ ПРОГРАММНО-АППАРАТНЫЕ ЭМУЛЯТОРЫ НЕЙРОННЫХ СЕТЕй НА БАЗЕ МУЛЬТИЯДЕРНЫХ МИКРОПРОЦЕССОРОВ С ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРой
Аляутдинов М.А., Галушкин А.И., Троепольская Г.В.
ФГУП НИИ Автоматической Аппаратуры им. академика В.С. Семенихина
Проблема создания эффективных масштабируемых нейрокомпьютерных конфигураций является весьма актуальной в связи с расширением сферы применения нейросетевых технологий.
В настоящее время реализация нейросетевых алгоритмов осуществляется программной, программно-аппаратной эмуляцией и чисто аппаратными средствами[1]. Программно-аппаратные эмуляции выполняются на базе компьютеров с широко масштабным параллелизмом. Чисто аппаратными средствами реализации нейронных сетей (НС) являются многопроцессорные нейроподобные СБИС, ПЛИС и нейрочипы. Аппаратная реализация НС алгоритмов является самым быстродействующим, но и дорогостоящим вариантом.
На сегодняшний день достигнут предел увеличения вычислительной мощности одноядерных вычислительных процессоров, базирующийся на увеличении тактовой частоты и архитектурных инновациях[2].
Ведущие изготовители микроэлектронных компонентов для сохранения тенденций роста производительности, переходят на разработку многоядерных процессоров с новой архитектурой, обеспечивающих распараллеливание обработки данных.
Появление многоядерных процессоров является качественным скачком на пути создания эффективных супервычислителей, обладающих существенно более высокими показателями производительность/стоимость, по сравнению с существующими высокопроизводительными системами вычислений на базе суперЭВМ и кластерных систем.
Многоядерные процессоры в силу своих исключительных вычислительных возможностей являются наиболее перспективными средствами аппаратной поддержки нейросетевых и информационных технологий, связанных с интенсивными вычислениями.
Использование многоядерных процессоров предоставляет гибкие возможности в части варьирования конфигураций и масштабирования мощности вычислительных систем от персональных компьютеров, рабочих станций, серверов до кластерных систем [3].
Среди многоядерных процессоров в настоящее время наибольший интерес представляют многоядерные графические и вычислительные микропроцессоры.
Графические микропроцессоры с параллельной архитектурой. В последнее десятилетие наблюдается стремительное развитие графической аппаратуры или GPU(Graphics Processing Unit). Современные GPU содержат полностью программируемые параллельные геометрические и пиксельные процессоры с полным и мощным набором команд для выполнения арифметических и логических операций с поддержкой 32-битного формата векторных и скалярных операций с плавающей точкой. Для быстрой обработки больших графических наборов данных (вершин и фрагментов) используют потоковую модель обработки с параллелизмом. В связи с этим возникло направление по использованию GPU для неграфических вычислений, получившее название GPGPU (GP - General Purpose GPU). Оно стимулировалось двумя основными факторами:
-критерием производительность/стоимость. Вычислительная мощность современных GPU при приблизительно одинаковой стоимости превышает возможности центральных процессоров (CPU) персональных компьютеров;
-темпами роста производительности GPU (рис. 1), удваиваемой каждые 6 месяцев, что быстрее, чем рост производительности CPU, которая в среднем удваивается каждые 18 мес. (по закону Мура), и эта тенденция будет сохраняться, благодаря параллелизму, присущему аппаратуре современных GPU[4].
Используя массивный параллелизм и векторные процессоры, современные графические устройства способны исполнять многие из приложений, ранее реализованных на векторных (SIMD) суперкомпьютерах. В настоящее время сфера использования GPU расширяется, благодаря программируемости GPU на высокоуровневых языках программирования. На GPU сегодня эффективно реализованы задачи физического моделирования, операции линейной алгебры, решение дифференциальных уравнений в частных производных, обработка сигналов и изображений, нейросетевая обработка и др.
В настоящее время по своим показателям наилучшим является графический процессор GeForce 8800 (G80)ф. nVidia[5]. Его основные характеристики: технология 90 нм; 681 млн. транзисторов; унифицированная архитектура: массив 128 (блоками 8х16) скалярных ALU с плавающей точкой (поддержка FP 32бит точности в рамках стандарта IEE 754); 384 бит шина памяти; 6 независимых контроллеров памяти шириной 64 бита, поддержка GDDR4 (1.8Ггц); частота ядра 575 МГц (G80 GTX); ALU работают на удвоенной частоте (1.35ГГц для 8800GTX); масштабируемость архитектуры (реконфигурирование контроллеров памяти, процессорных блоков). Блок из 16 ALU (в контексте графической специализации) является шейдерным процессором. Каждый такой процессор снабжен собственным КЭШем первого уровня. Входные данные не кэшируются , а идут потоком. ALU работают на удвоенной частоте и, соответствуют или превосходят (в зависимости от операций в шейдере) 8 четырехкомпонентных векторных ALU предшествующих моделей GPU (G70) на равной базовой частоте ядра.

Рис. 1 Производительность современных GPU относительно CPU Intel Pentium 4
Графическая плата с чипом GeForce 8800 обеспечивает суперкомпьютерные возможности. Пиковая производительность плавающей арифметики нового ускорителя превышает любой из доступных сейчас настольных процессоров. NVIDIA приводит следующие показатели пиковой производительности передовых на сегодня GPU [5]:
Таблица 1. Характеристики пиковой производительности современных GPU
| Графический процессор | G71(nVidia) | R580(ATI) | GeForce 8800(nVidia) |
| Операции | Vec3+scalar MAD | Vec3+scalar MAD Vec3+scalar ADD | Scalar MAD+ Scalar MUL |
| Число параллельных процессорных элементов | 48 | 48 | 128 |
| Тактовая частота ALU(GHz) | 0.65 | 0.65 | 1.35 |
| Пиковая производительность GFlops(GMuls) | 125 | 125 | 345 |
NVIDIA также приводит цифры прироста от 10х и до нескольких сотен раз в зависимости от задачи при сравнении G80 c двухядерным Intel Core2 duo на частоте 2.66 ГГц [5]: Унифицированная архитектура G80 обладает гибкостью, достаточной не только для графических приложений, но и более серьезных задач - математического и физического моделирования, распознавания образов, обработки изображений, нейросетевых вычислений и других задач потоковой обработки. Для эффективной поддержки неграфических приложений для чипов NVIDIA создана среда программирования – “CUDA” (Compute Unified Device Architecture) -унифицированная вычислительная архитектура для различных задач, содержащую специальный SDK, API и компилятор. С, обеспечивающие быструю разработку и адаптацию программ, для исполнения на GPU.
Мультиядерные микропроцессоры CELL. В феврале 2005 года компания IBM совместно с компаниями Sony и Toshiba представила прототип нового процессора под кодовым названием CELL. Процессор основан на новой архитектуре компании IBM, которая называется “ CELLular architecture”[6]. Кристалл содержит 64-разрядное управляющее ядро с архитектурой Power и восьми синергетических 32-разрядных процессорных ядер (Synergistic Processing Element, SPE) c SIMD архитектурой, работающих на частоте порядка 3,2 ГГц, поддерживающих операции с плавающей запятой. Чип изготавливается по 90-нанометровой технологии и содержит 234 млн. транзисторов. Кэш-память L1 объемом 256 кбайт и L2 объемом 512 кбайт на каждое ядро. Производительность нового процессора составляет 250 GFlops. Современные процессоры Intel по меньшей мере в 10 раз медленнее, чем новый процессор CELL.
SPE соединяются по внутренней кольцевой шине Element Interconnect Bus, по которой передаются данные между единицами SPE, быстродействующей памятью и контроллерами ввода/вывода. Скорость обработки данных CELL может составить 16 Гбайт в секунду. CELL способен адресовать до 64 Гбайт памяти. CELL можно применять как одиночный процессор или в составе многопроцессорной системы - его шина ввода/вывода предусматривает возможность прямого соединения с другими CELL. Для соединения нескольких процессоров CELL используется специальный коммутатор.
Первоначально процессор CELL будет применяться в графических станциях Play Station 3, позже в компьютерах корпоративного класса, в серверах, суперкомпьютерах. Серверы на базе CELL будут ориентированы на задачи, требующие интенсивных вычислений: графической визуализации, обработки данных сейсморазведки, обработки космических изображений и картографии, шифрование и сжатие данных.
Мультиядерные микропроцессоры Intel Core. В ноябре 2006 г.- компания Intel представила первые четырехядерные процессоры нового поколения на базе многоядерной процессорной архитектуры Intel Core под шифром Kentsfield с названием Core 2 Extreme QX6700[7].
К инновациям, реализованными в новом поколении процессорной архитектуры Intel: Core относятся [10]:
-Технология Intel Wide Dynamic Execution призвана обеспечить выполнение большего количества команд за каждый такт (до четырех), повышая эффективность выполнения приложений и сокращая энергопотребление.
-Технология Intel Intelligent Power Capability, активируя отдельные узлы чипа только по мере необходимости, значительно снижает энергопотребление системы в целом.
-Технология Intel Advanced Smart Cache подразумевает наличие общей для всех ядер кэш-памяти L2, совместное использование которой снижает энергопотребление и повышает производительность. Технология Intel Smart Memory Access повышает производительность системы, сокращая время отклика памяти и оптимизируя, таким образом, использование пропускной способности подсистемы памяти.
-Технология Intel Advanced Digital Media Boost позволяет обрабатывать все 128-разрядные команды SSE, SSE2 и SSE3, широко используемые в мультимедийных и графических приложениях, за один такт, что увеличивает скорость их выполнения.
Процессоры Kentsfield состоят из двух двуядерных ядер на базе архитектуры Conroe, помещенные на единую подложку в единый корпус. Основные характеристики процессоров Core 2 Extreme QX670: производство по 65-нм техпроцессу; количество процессорных ядер - 4; число транзисторов 582 миллионов; рабочая частота - 2,67 ГГц; 1066 МГц системная шина; объем кэш-памяти второго уровня - по 4 Мбайт на ядро; потребляемая мощность - 120 Вт. Теоретическая пиковая производительность порядка 4х(10-12) = 40-50MFlops.Следующим шагом станут четыре процессора на едином кристалле с общим кэшем L2[8]. На середину 2007 года намечен переход на 45-нм техпроцесс. Это позволит начать в 2008 г. выпуск первых 8-ядерных процессоров[9].
Следующие поколения микропроцессоров на базе архитектуры Intel Core будут содержать ещё большее количество ядер на одном чипе. В 2009 году, благодаря субмикронной ультрафиолетовой литографии (EUV), Intel планирует перейти на техпроцесс 32 нанометра.
Мультипроцессоры Intel Core планируется использовать на серверных, настольных и мобильных системах.
Предполагается[5], что через 5-10 лет графические ускорители, идущие по пути все большей универсальности и гибкости и центральные процессоры, идущие по пути все большего параллелизма, сойдутся в едином продукте. Один чип будет содержать в себе набор, возможно, разнородных ядер, как выделенных вычислительных или графических, так и общего назначения.
Выводы. Современные и последующие поколения графических процессоров являются более предпочтительными для эффективной реализации на них нейрокомпьютерных конфигураций по сравнению с многоядерными микропроцессорами типа CELL и Intel Core. Это объясняется упрощением структуры параллельных ядерных элементов GPU, что позволяет реализовать при одинаковых техпроцессах и площадях большее число ядер и обеспечивать лучшие показатели производительность/стоимость. Вышесказанное можно отнести и к будущим гибридным мультипроцессорам с разнородными вычислительными и графическими ядрами.
В настоящей статье изложены результаты, полученные в рамках проекта по разработке пакета программ для решения инженерных задач с плотными системами уравнений со сверхбольшим числом неизвестных (тема ИТ-13.3/001. Решение Конкурсной комиссии Роснауки № 3/протокол от 04 июля 2005г. № 16). В проекте использовались современные графические платы с параллельной архитектурой для построения масштабируемых кластерных нейрокомпьютерных конфигураций и реализации на них нейросетевых алгоритмов обработки сложных сигналов, изображений и других задач [3].
Литература
- Аляутдинов М.А., Галушкин А.И., Назаров Л.Е. Методы распараллеливания и программно-аппаратной реализации нейросетевых алгоритмов обработки изображений”, Москва, “Нейрокомпьютеры” №2, 2003 , с.3-21
- Зюбин В. Многоядерные процессоры и программирование. "Открытые системы",#07-08, 2005 год // Издательство "Открытые системы" . u/os/2005/07-08/012.htm.
- Аляутдинов М.А, Галушкин А.И., Троепольская Г.В. Использование графических процессоров с параллельной архитектурой для построения масштабируемых нейрокомпьютерных конфигураций. Москва, “Нейрокомпьютеры” №8-9,2006 , с.18-28
- Jown D.Owens, David Luebke, Naga Govindaraju, Mark Harris, Jens Kruger, Aaron E. Lefohn, Timothy J. Purcell. A survey of General-Purpose Computation on Graphics Hardware. Eurographics 2005, State of the Art Reports, August 2005, pp.21-51
- Воробьев А., Медведев А. NVIDIA GeForce 8800 GTX (G80). com/video2/g80-part1.shtml
- Introduction to the Cell multiprocessor. by J. A. Kahle, M. N. Day,H. P. Hofstee,C. R. Johns,T. R. Maeurer, and D. Shippy. IBM journal of research and development. POWER5 and Packaging.Volume 49, Number 4/5, 2005
- Официальный релиз Core 2 Extreme QX6700 aka Kentsfield.: 03.11.2006. ссылка скрыта
- Чеканов Д.Core 2 Quad (Kentsfield): тесты первого четырёхядерного процессора Intel .u/cpu/intel_core_2_quadro_kentsfield/index.php
- Четырехъядерные процессоры Intel Kentsfield. -media.ru/articles/?prod_id=10165
- Романченко В. Эволюция многоядерной процессорной архитектуры Intel Core: Conroe, Kentsfield, далее по расписанию. 27/06/2006. s.ru/cpu/new_core_conroe/print.
PERSPECTIVE HARDWARE AND SOFTWARE EMULATORS OF NEURAL NETWORKS ON THE BASIS OF MULTICORE MICROPROCESSORS WITH PARALLEL ARCHITECTURE
Alyautdinov M., Galushkin A., Troepolskaya G.
Scientific Research Institute of the Automatic Equipment it Academician V.S. Semenikhin
The problem of creation effective scalable neurocomputers configurations is actual through of the expansion of sphere of application neuralnetwork technologies.
At present manufacturers of microprocessors for maintenance of tendencies of growth of performance pass to development of multicore processors with the parallel architecture, possessing essentially higher parameters performance/cost in comparison with existing systems of calculations on the basis of the super computer and cluster systems.
Among multicore processors now the greatest interest is represented with modern multicore graphic and computing microprocessors.
In paper modern graphic and multicore microprocessors with parallel architecture (G80 nVidia, CELL (IBM) and Intel Core) for creation effective by criterion performance/cost scalable neurocomputer configurations are considered.
In paper the results received within the frame of the project on development of the software package for the decision of engineering problems with dense systems of the equations with huge number of unknown variables (theme ИТ-13.3/001. The decision of Competitive commission Rosnauki № 3 / protocol from July, 04th 2005ú. № 16). In the project modern graphics processing units with parallel architecture for construction scalable cluster neurocomputer configurations and realization on them neuralnetwork algorithms of processing complex signals, images were used.
On the basis of the executed development and the analysis of tendencies of development of microprocessors the conclusion is done, that modern and subsequent generations of graphic processors are more preferable to effective realization on them neurocomputer configurations in comparison with multicore microprocessors of type CELL and Intel Core. It speaks simplification of structure of parallel core elements GPU that allows to realize at identical technology and the areas greater number of cores to provide the best parameters performance/cost.
«НЕЙРОМАТЕМАТИКА» - ОТКРЫТЫЙ ПАКЕТ ДЛЯ РЕШЕНИЯ СЛОЖНЫХ ПРИКЛАДНЫХ МАТЕМАТИЧЕСКИХ ЗАДАЧ С ИСПОЛЬЗОВАНИЕМ НЕЙРОСЕТЕВЫХ АЛГОРИТМОВ
Казанцев П. А.1, Скрибцов П.В.2
1ФГУП НИИ Автоматической Аппаратуры им. В.С. Семенихина НТЦ НК,
2ООО «ПАВЛИН ТЕХНОЛОГИИ»
1. Введение
В настоящее время теория нейронных сетей получила широкое распространение [1-4]. Также получило широкое распространение ПО для эффективного решения базовых нейросетевых алгоритмов. Однако применение мощного аппарата нейросетевых алгоритмов в коммерческих программных продуктах для решения сложных прикладных математических задач с большим числом неизвестных и размерностью пока не является общераспространенной практикой, а расценивается, скорее, как некоторая «экзотика». Из этого можно сделать вывод, что, несмотря на многие привлекательные свойства нейросетевых алгоритмов (объективная предрасположенность к распараллеливанию, адаптивность, помехоустойчивость, и др.), удобного программного инструмента для привлечения базовых нейросетевых алгоритмов к решению сложных прикладных задач на данный момент пока не существует, особенно если говорить о задачах, требующих аппаратной поддержки вычислений в виде специализированных процессоров или кластеров. Настоящий документ посвящен программному пакету «Нейроматематика», который является связующим звеном между базовыми нейросетевыми алгоритмами и решениями сложных прикладных задач, требующих аппаратной поддержки и/или кластерных вычислений.
В рамках предварительного исследования были изучены следующие комплексы математической обработки данных (в том числе и нейросетевые), имеющие наибольшую распространенность (см. таблица 1).
В большинстве своем эти продукты не предусматривают возможность работы в кластере или применения специализированных аппаратных ускорителей вычислений, за исключением пакета SAS Enterprise Miner Software, но он, в свою очередь, не является ориентированным на решение задач в нейросетевом базисе. Перечисленные нейросетевые комплексы предназначены для выполнения базовых нейросетевых алгоритмов и не могут быть напрямую использованы для решения прикладных задач конечными пользователями (операторами), за исключением случаев, когда пакет предлагает механизм генерации программного кода, который может встраиваться в пользовательское приложение, нацеленное на решение прикладной задачи. Однако код, генерируемый вышеупомянутыми пакетами, не всегда является оптимальным, поскольку отражает общность продукта с одной стороны, а с другой стороны не рассчитан на специализированную аппаратную (или кластерную) поддержку, например, код для матричных вычислений, сгенерированный компилятором Matlab’a нельзя использовать для вычислений в кластере или с применением аппаратных ускорителей.
Таблица 1. Перечень распространенных «нейропакетов».
| № | Комплекс | Компания Изготовитель | Ссылки |
| 1 | Matlab Neural Network Toolbox | The Mathworks Inc. | ссылка скрыта |
| 2 | NeuroSolutions | Neuro Dimensions | Нейропакет ссылка скрыта |
| 3 | Statistica Neural Networks | Stat Soft, Inc | Нейропакет ссылка скрыта |
| 4 | BrainMaker Pro | California Scientific Software | ссылка скрыта |
| 5 | NCSS & PASS | Number Cruncher Statistical Systems, Inc. | NCSS Statistical and Data Analysis Software v2004 Incl PASS (c) www.ncss.com ссылка скрыта |
| 6 | Neuro Explorer | Nex Technologies | ссылка скрыта |
| 7 | SAS Enterprise Miner Software | SAS Institute, Inc. | ссылка скрыта |
2. Структура пакета «Нейроматематика»
Пакет Нейроматематика представляет собой открытую1 систему-кластер, соответствующую парадигме «message-oriented cluster» (см. рис 1), позволяющую быстро создавать и отлаживать программные модули Решения Прикладных математических Задач (РПЗ) с применением нейросетевых алгоритмов, сохраняя максимально-эффективное использование доступных аппаратных средств.
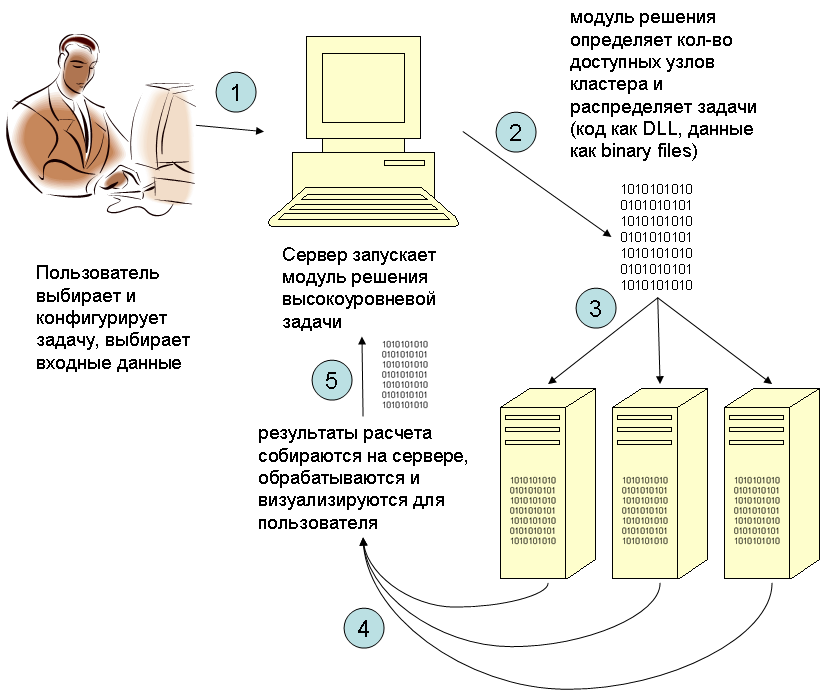
Рис. 1
Нейросетевой Программный Комплекс (НСПК) можно грубо разделить на 2 части – Платформа и наращиваемые Модули решения высокоуровневых (Прикладных) задач (см. рис. 2).

Рис. 2
Версия 1.0 пакета включает в себя Платформу (набор С++ классов и исполняемых «.exe» и «.dll» модулей) и 4 полнофункциональных готовых примера Модулей Решения Прикладных Задач (РПЗ) по темам аэродинамики, гидроакустики и электродинамики. Платформа содержит программный код (набор библиотек), предназначенный для выполнения базовых нейросетевых расчетов, управления аппаратными ускорителями вычислений, обеспечения функционирования базовых элементов пользовательского интерфейса и т.п. Функциональность платформы делится на серверную и клиентскую часть. Серверная часть обеспечивает следующие элементы функциональности:
- Система выбора и конфигурации выполняемых расчетных задач;
- Система управления кластером;
- Система импорта, предобработки внешних данных;
- Система отображения и редактирования загруженных данных;
- Подсистема графического представления данных;
- Система экспорта данных.
Клиентская часть обеспечивает функционирование следующих библиотек:
- базовых нейросетевых алгоритмов;
- математических объектов;
- аппаратных вычислений (в версии 1.0 – используется технология GPGPU [5]).
Платформа обеспечивает запуск расчетных заданий, порученных клиенту модулем решения высокоуровневой задачи.
Пользователи применяют возможности платформы в своих целях путем создания Модулей Решения Прикладных Задач. Каждый модуль РПЗ включает в себя алгоритмы и пользовательский интерфейс специфический для конкретной прикладной задачи, которые создаются с использованием и на основе арсенала средств, представляемого Платформой. При этом все РПЗ разделяют общий стиль создания. Платформа налагает стандарт, как на внутреннюю программную структуру, так и на пользовательский интерфейс модулей РПЗ. Это позволяет использовать одни РПЗ, как примеры или основу для создания других, и позволяет избежать типовых ошибок.
3. Архитектура подсистемы кластерных вычислений
РПЗ динамически связываются с Платформой путем применения технологии абстрактных базовых классов (интерфейсов) и библиотек динамического связывания, что обеспечивает возможность независимого улучшения расчетных алгоритмов и пользовательского интерфейса Платформы, без необходимости внесения изменений в РПЗ. В частности, платформа позволяет работать РПЗ с «абстрактным кластером», допуская наличие нескольких различных имплементаций подсистемы параллельного исполнения подзадач, коммуникации, загрузки начальных данных, и сборки результатов расчета. Таким образом, РПЗ, использующие подсистему работы с виртуальным кластером, могут быть без перекомпиляции запущены и отлажены на различных типах кластеров.
В версии 1.0 пользователь может выбирать между MPI- и Winsocket- реализациями подсистемы управления виртуальным кластером. Пользователь также может создать свою реализацию подсистемы управления «виртуальным кластером» на основе имеющихся примеров.
Почему не чистый MPI? Разработчики Message Passing Interface преследовали схожие цели. В основном, это средство описания кода, который параллельно работает в различных процессах, описанного в духе и стиле «консольного приложения» (с функцией main, и т.п.). Для разных систем существуют различные реализации MPI, при этом код, написанный с использованием MPI, может быть скомпилирован (теоретически без модификаций) на различных кластерных системах, имеющих различные реализации MPI. Однако его минусы заключаются в следующем:
- для запуска задач требуется запуск отдельного процесса MPIEXEC, что в случае, например, среды с графическим пользовательским интерфейсом2 требует (а) наличия кода запуска процесса MPIEXEC с соответствующими параметрами, (б) организации механизмов обмена данными между графической оболочкой и собственно, распараллеленными консольными программами, для обеспечения раздачи исходных данных и сбора результатов вычислений3;
- MPI не обеспечивает рассылку исполняемого кода по узлам сети, об этом должен заботиться либо пользователь системы, либо основной модуль, осуществляющий запуск параллельных вычислений (оболочка системы);
- код консольного приложения, написанного в стиле MPI должен определять номер узла, на котором он запущен, и делать соответствующие логические ветвления, если на различных узлах должен работать немного различный код;
В пакете «Нейроматематика» все эти функции берет на себя система.
Существует ограниченное число реализаций4 MPI. Написать собственную реализацию MPI суть задача более сложная (и более общая), чем предполагаемые усилия для имплементации интерфейса Менеджера Задач и Коммуникатор(а,ов), а именно определения минимально необходимого набора средств для реализации параллельных вычислений на имеющейся системе.
Интерфейс «Нейроматематики» также предполагает, что подзадача, работающая на отдельном вычислительном узле – это объект с набором call-back процедур, что выглядит более читаемо, отлаживаемо, чем код с множеством ветвлений. MPI в дальнейшем рассматривается как одно из средств имплементации менеджера задач в пакете «Нейроматематика».
Почему не чистый RPC? Организация RPC требует от разработчика совершения действий, не связанных с решением вычислительной задачи: вызова большого числа инициализирующих процедур, описания интерфейса вызываемых функций на языке IDL, компиляцию ILD файлов, и т.п. Все это лишнее для специалистов, желающих сконцентрироваться на написании кода, реализующего непосредственно вычисления. Если в качестве механизма запуска параллельного кода и коммуникации между процессами есть предпосылки для использования именно механизма RPC – его следует единожды использовать при реализации Менеджера Задач и Коммуникатора.
Почему не WinSocket? Аналогично RPC, механизм сокетов можно использовать для реализации интерфейса коммуникатора. Писать код с использованием чистых сокетов – не очень переносимо.
Для описания алгоритмов систем, реализующих параллельные вычисления в среде с набором параллельно работающих вычислительных узлов, предлагается общая модель, заданная в виде абстрактных базовых классов С++, названная SIPICS (Simple Interface for Parallel Independent Computation Systems или Простой Интерфейс для Систем с Независимыми Параллельными Вычислениями). Преимущество использования данного набора интерфейсов заключается в возможности написания системы управления вычислениями, ответственной за запуск параллельно-исполняемого кода и коммуникацию между узлами, с применением различных технологий (Message Passing Interface, Remote Procedure Call, и т. п.). При этом описание алгоритмов самих вычислений никак не изменяется и может работать с любой реализацией системы управления вычислениями, вне зависимости от используемой для этого технологии. Предполагается, что система решения некоторой задачи при помощи распределенных вычислений описывается только один раз, а затем может исполняться при помощи различных систем управления, разработанных и оптимизированных для текущих средств, имеющихся на данный момент. Подобный подход, позволяет сравнивать эффективность использования различных механизмов параллельного исполнения кода и коммуникации между вычислительными узлами, не изменяя исходных текстов, посвященных решению самой вычислительной задачи. Дополнительно, это позволяет разделить работу между группой исследователей, занимающихся разработкой параллельного алгоритма и группы, занимающейся реализацией средств запуска кода и коммуникации между узлами, но при этом, позволяя каждой группе разрабатывать и отлаживать свои решения не на бумаге, а с использованием пока имеющихся реализаций (например, прошлых версий, эмуляторов или заглушек). Более того, разработчики имеют возможность начинать набирать и компилировать код, даже не имея никакой реализации, ориентируясь только на интерфейсы.
С точки зрения исследователя, занимающегося разработкой алгоритма параллельного счета некоторой задачи, совершенно все равно, какой механизм в системе имеется (или используется) для обеспечения параллелизма. При решении распараллеливаемой задачи разработчик может, конечно, учитывать особенности реализации той или иной аппаратной системы, но если алгоритм распараллеливания создавать, опираясь на принцип минимизации обмена данными между параллельно работающими подзадачами, его эффективность будет пропорциональна эффективности реализации системы запуска, исполнения кода и коммуникации между узлами сети. Для разработчика алгоритма параллельных вычислений было бы хорошо «не думать» о средствах, а сконцентрироваться на самих вычислениях, которые и так обычно слишком сложны, чтобы отвлекаться на детали реализации механизмов запуска, исполнения кода и коммуникации. SIPICS позволяет разработчику параллельного алгоритма «абстрагироваться» от конкретной вычислительной платформы и описать (и единожды скомпилировать) свой алгоритм в виде библиотеки c динамическим связыванием (Dynamic Link Library), который затем может быть использован с различными реализациями систем управления задачами без необходимости даже перекомпилировать свой код.
В версии 1.0 продукта «Нейроматематика» построена удобная система распределения начальных условий на узлы кластера, визуальные средства диагностики и отладки состояния подзадач, сбора и объединения результатов, на сервере для последующей визуализации пользователю. К примеру, для того, чтобы оператор системы мог принять на экране сервера текстовое сообщение от одной из исполняющихся подзадач (с фиксацией точного времени, параметров расчетного узла кластера, имени задачи) достаточно одной строки кода вида comm.reportStatus(“Hello”);
Одно из удобных средств разработанных для пользователя системы – монитор состояния подзадач (см. Рис. 3). Монитор позволяет просматривать в иерархическом виде узлы кластера, их параметры, задачи, запущенные на узлах и сообщения, получаемые сервером от подзадач. На основе принятых сообщений, система позволяет собирать данные для построения временных диаграмм (по сути – график «кто, когда кого, сколько ждал и считал»), что крайне важно для оптимизации и диагностики эффективности работы параллельного алгоритма.
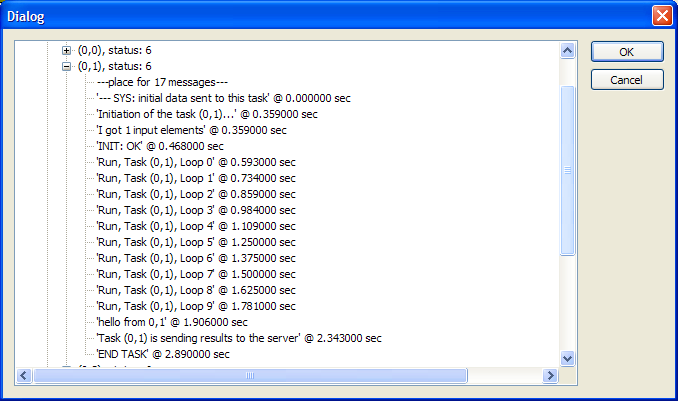
Рис. 3. Монитор состояний подзадач кластера.
Основные понятия (интерфейсы) системы.
Задача – объект, который создается системой на отдельном вычислительном узле. При этом данный объект обладает набором стандартных call-back процедур, которые вызываются системой для задания начальных данных, произведения непосредственно вычислений, и выгрузки итоговых данных. Также у объекта имеется набор служебных call-back процедур для определения статуса задачи, сброса ее в начальное состояние, и т.п. В данном документе предполагается, что каждая параллельно выполняемая подзадача может быть описана на языке С++, как множество некоторых функций или объектов и быть скомпилирована в отдельный исполняемый модуль (DLL). Это налагает ограничение возможности использования подобной системы для распараллеливания с применением специальных аппаратных средств, у которых ограничены возможности по коммуникациям и требуется использование специальных команд или парадигм программирования. То есть, если узел не умеет запускать процессы в виде исполняемых «exe» или «DLL» модулей, то данную систему применить нельзя5. Приятной особенностью «задачи» в пакете «Нейроматематика» является наличие полноценного имени (а не просто номера), позволяющего отражать структуру разбиения вычислений на подзадачи. Например, задача может иметь имя вида «(0,1)», что означает «я – задача, соответствующая элементу объема, с координатами 0,1». Это чрезвычайно удобно при отладке, особенно при сложной структуре разбиения данных. Обыкновенный и привычный числовой номер задачи является частным случаем «имени».
Менеджер Задач – объект, занимающийся запуском параллельных вычислений и ответственный за выдачу средств обмена данными между параллельно работающими узлами. Реализация менеджера задач может быть построена с использованием концепций нитей (threads) или процессов (process) и оптимизирована для многоядерных процессоров или для многопроцессорных систем.
Коммуникатор – объект, которым снабжается каждая задача, осуществляющий синхронную и асинхронную отправку данных другим узлам вычислительной сети, а также ответственный за синхронный прием данных. Менеджер Задач может выдавать Задачам различные имплементации коммуникаторов, например, в случае разнородной вычислительной среды. Средства коммуникации между процессами могут быть реализованы при помощи любых механизмов, начиная от TCP/IP и заканчивая разделенной памятью (shared memory) в зависимости от доступных аппаратных средств и протоколов.
Менеджер Данных – вспомогательный объект, отвечающий за создание начальных данных и сбор результатов, а также определения очередности сбора результатов. Например, совокупные результирующие данные от всех задач могут не умещаться в памяти центрального узла, и необходима их запись в файл в определенной последовательности. Поскольку сложно прогнозировать последовательность завершения вычислений на узлах кластерной сети, у некоторых задач, будет «заморожена» пересылка результатов до получения результатов от других задач.
4. Основные используемые технологии
В версии «Нейроматематика» 1.0 используются следующие технологии:
- Операционная система Windows XP/2000 как среда функционирования
- Microsoft Visual Studio 2003, как среда разработки
- язык С++ , как базовый язык программирования Платформы и модулей РПЗ;
- библиотека «Microsoft Foundation Classes (MFC)» для организации пользовательского интерфейса и общего функционирования системы;
- OpenGL, как средство визуализации объемных данных;
- nVIDIA/ Cg, как средство управления графическими процессорами, которые используются как аппаратные ускорители нейросетевых алгоритмов;
- MPI / MPICH, как средство для одной из имплементаций подсистемы работы с «виртуальным кластером»;
- Winsockets, как средство альтернативной имплементаций подсистемы работы виртуальным кластером.
5. Перспективы развития
Текущая версия системы, пока скорее представляет собой спроектированный прототип, или сформированный «скелет», готовый к развитию. В следующих версиях пакета, предполагается наращивание нейросетевых алгоритмов, развитие интерфейсов и имплементаций для различных кластеров и устройств аппаратной поддержки вычислений. Также предполагается создание дополнительных примеров модулей РПЗ общего назначения, таких например, как модулей решения СЛАУ большой размерности нейросетевыми методами.
Литература
- Галушкин А.И. Теория нейронных сетей. // Радиотехника, Москва 2000
- Галушкин А.И., Цыпкин Я.З. Нейронные сети: история развития теории. // Радиотехника, Москва. 2001
- Галушкин А.И О современных направлениях развития нейрокомпьютеров.//Нейрокомпьютер 1,2,Радиотехника.1997.
- Галушкин А.И Нейрокомпьютеры. // Радиотехника , Москва. 2002
- GPGPU - General Programming on Graphics Processing Units // ссылка скрыта
«NEUROMATHEMATICS» - OPEN SYSTEM FOR SOLVING COMPLEX APPLIED MATH PROBLEMS USING NEURAL NETWORK ALGORITHMS
Kazantsev P.1, Skribtsov P.2
1 V.S. Semenikhin Scientific Research Institute of Automatic Equipment, 2 Pawlin Technologies, Ltd
“Neuromathematics” is an open system designed to simplify creation and debugging of the complex applied math problems solutions based on neural network algorithms keeping maximum possible efficiency in hardware and/or cluster computations.
Version 1.0 includes Platform (a set of C++ classes, dynamic link libraries and executables) and 4 fully-functional ready samples of the Applied Task Solution (ATS) plugins in the field of aerodynamics, hydroacustics and electrodynamics. The Platform now contains code (set of libraries) designed for the basic neural computations, control of the hardware accelerators (based on GPGPU technology), support GUI, etc. Users of the Platform apply its features in their own interest by creating ATS plugins. Each plugin include algorithms and GUI widgets specific for the certain task solution, which are made on the basis of the Platform components. All plugins share the common style of development for the intrinsic computations and GUI. This makes it possible to use sample plugins as the starting point for developing and extending new plugins and avoid common mistakes.
ATS plugins are dynamically linked with the Platform by means of the abstract classes (interfaces) and DLLs approach, which makes it possible to perform independent improvement of the calculation algorithms and GUI of the Platform without the need of recompiling the ATS plugins. In particular, the Platform allows ATS plugin to work with “abstract cluster” and have several different subsystems implementations for the parallel tasks execution, communication, initial data distribution, resulting data collection, reporting and user control. ATS plugins written to work this “abstract cluster” can be run on different clusters without recompilation (provided the system compatibility). For example, in version 1.0 of “Neuromathematics” user may switch between MPI and Winsocket implementations for the “abstract cluster” on the fly. Users are welcome to create their own implementations of the “abstract cluster” by deriving from the existing implementations or using them as examples.
For now the current version resembles more the prototype or the “skeleton”, ready for the further elaboration, rather than the end system. In the next versions it is planned to develop additional neural network algorithms, GUI improvement, interfaces extension, creating implementations for the different cluster types and hardware accelerators. Additional sample ATS plugins will be created, such as plugin for solving high-dimensional systems of linear equations using neural network approach.
1 «Открытость» системы заключается в возможности самостоятельного создания «третьими сторонами» модулей решения высокоуровневых задач и запуска их в среде НСПК.
2 Графический пользовательский интерфейс – неотъемлемая часть любой современной программной системы обработки данных имеющих сложную структуру, размерность, большой объем, и т.п.
3 как правило, данные должны скапливаться, например, в коде, запущенном на узле с нулевым номером, но как их дальше визуализировать? Значит, программа должна иметь ветвление «если я на нулевом узле, я отвечаю за сбор всех данных и потом должна выгрузить результаты туда-то». Все это доставляет массу неудобств, затрудняет отладку и отвлекает от главной цели.
4 Причем для Windows имеющаяся реализация MPI известна не самой лучшей скоростью обмена данными.
5 например, GPU алгоритмы задавать при помощи SIPICS невозможно, поскольку нельзя на пиксельном процессоре запустить exe-процесс. Однако, если возможно параллельное исполнение специализированного кода на наборе ПЭВМ с GPU, то SIPICS для данного случая тоже применим.
Цифровая обработка сигналов и ее применение
Digital signal processing and its applications