
М. В. Ломоносова Факультет вычислительной математики и кибернетики В. Г. Баула Введение в архитектуру ЭВМ и системы программирования Москва 2003 Предисловие Данная книга
| Вид материала | Книга |
Содержание15. Архитектурные особенности современных ЭВМ. 15.1. Конвейерные ЭВМ. |
- М. В. Ломоносова Факультет вычислительной математики и кибернетики Кафедра математической, 6.81kb.
- Н. И. Лобачевского Факультет Вычислительной математики и кибернетики Кафедра Математического, 172.6kb.
- Н. И. Лобачевского Факультет Вычислительной Математики и Кибернетики Кафедра иисгео, 4000.54kb.
- М. В. Ломоносова факультет Вычислительной Математики и Кибернетики Диплом, 49.56kb.
- Методы интеллектуального анализа данных и некоторые их приложения, 29.22kb.
- М. В. Ломоносова Факультет Вычислительной Математики и Кибернетики Кафедра Системного, 124.67kb.
- Н. И. Лобачевского Факультет Вычислительной математики и кибернетики Кафедра Математического, 169.45kb.
- Московский Государственный Университет им. М. В. Ломоносова. Факультет Вычислительной, 104.35kb.
- М. В. Ломоносова Факультет Вычислительной Математики и Кибернетики Реферат, 170.54kb.
- М. В. Ломоносова Факультет вычислительной математики и кибернетики Руденко Т. В. Сборник, 1411.4kb.
15. Архитектурные особенности современных ЭВМ.
Исследуем сейчас следующий вопрос: оценим скорость работы различных устройств ЭВМ. Оперативная память современных ЭВМ способна читать и записывать данные примерно каждые 10 наносекунд (нс), 1 нс = 10-9 сек., а центральный процессор может выполнить команду примерно за 1–2 нс. После некоторого размышления становится понятным, что "что-то здесь не так".
Действительно, рассмотрим, например, команду add ax,X . Для выполнения этой команды центральный процессор должен сначала считать из оперативной памяти саму команду (это 4 байта), затем операнд X (это ещё 2 байта), потом произвести операцию сложения. Таким образом, центральный процессор потратит на выполнение этой команды 6*10+2=62 нс. Спрашивается, зачем делать центральный процессор таким быстрым, если всё равно 97% своего времени он будет ждать, пока команды и данные не будут считаны из оперативной памяти на регистры? Налицо явное несоответствие в скорости работы оперативной памяти и центрального процессора ЭВМ.
Данная проблема на современных ЭВМ решается несколькими способами, которые мы сейчас рассмотрим. Сначала оперативную память стали делать таким образом, чтобы за одно обращение к ней она выдавала не по одному байту, а по несколько байт сразу. Для этого оперативную память разбивают на блоки (обычно называемые банками памяти), которые могут работать параллельно. Этот приём называют расслоением памяти. Например, если память разбита на 8 блоков, то за одно обращение к ней можно сразу считать 8 байт, при этом байты с последовательными адресами располагается в разных блоках. Таким образом, за одно обращение к памяти можно считать несколько команд или данных.
Скорость работы оперативной памяти современных ЭВМ так велика, что требуется какое-то образное сравнение, чтобы это почувствовать. Легко подсчитать, что за одну секунду из памяти можно прочитать 8*108 байт. Если считать каждый байт символом текста и учесть, что на стандартной странице книги помещается примерно 2000 символов, то получается, что за 1 секунду центральный процессор можно прочитать целую библиотеку из 80 томов по 500 страниц в каждом томе.
Легко, однако, вычислить, что, несмотря на такую огромную скорость, оперативная память продолжает тормозить работу центрального процессора. Проведя заново расчёт времени выполнения команды add ax,X мы получим:
10 нс (чтение команды) + 10 нс (чтение числа) + 2 нс (выполнение команды) = 22 нс.
Как видим, хотя ситуация и несколько улучшилась, однако всё ещё примерно 90% своего времени центральный процессор вынужден ждать, пока из оперативной памяти поступят нужные команды и данные. Для того, чтобы исправить эту неприятную ситуацию, в архитектуру компьютера встраивается специальная память, которую называют памятью типа кэш, или просто кэшем.
Кэш работает так же быстро, как и центральный процессор, т.е. может, например, выдавать по 8 байт каждые 1-2 нс. Для программиста кэш является невидимой памятью в том смысле, что эта память не адресуемая, к ней нельзя обратиться из программы по какой-либо команде чтения или записи.1 Центральный процессор работает с кэшем по следующей схеме.
Когда центральному процессору нужна какая-то команда или данное, то сначала он смотрит, не находится ли эта команда или данные в кэше, и, если они там есть, читает их оттуда, не обращаясь к оперативной памяти. Разумеется, если требуемой команды или данных в кэше нет, то центральный процессор вынужден читать их из относительно медленной оперативной памяти, однако копию прочитанного он обязательно оставляет в кэше. Аналогично, при записи данных центральный процессор помещает их в кэш. Особая ситуация складывается, если требуется что-то записать в кэш, а там нет свободного места. В этом случае по специальным алгоритмам, которые Вы будете изучать в следующем семестре, из кэша удаляются некоторые данные, обычто те, к которым дольше всего не было обращения. Таким образом, в кэше накапливаются, в частности, наиболее часто используемые команды и данные, например, все команды не очень длинных циклов после их первого выполнения будут находиться в памяти типа кэш.2
Память типа кэш строится из очень быстрых и, следовательно, дорогих интегральных схем, поэтому её объём сравнительно невелик, примерно 5% от объёма оперативной памяти. Однако, несмотря на свой относительно малый объём, кэш вызывает значительное увеличение скорости работы ЭВМ, так как по статистике примерно 90-95% всех обращений за командами и данными производится в память типа кэш. Теперь наша команда add ax,X будет выполняться за 2+2+2=6 нс.3 Как видим, ситуация коренным образом улучшилась, хотя всё равно получается, что центральный процессор работает только 30% от времени выполнения команды, а остальное время ожидает поступления команд и данных. Для того, чтобы исправить эту ситуацию, нам придётся снова существенно изменить архитектуру центрального процессора.
15.1. Конвейерные ЭВМ.
Как мы уже говорили, современные ЭВМ могут одновременно выполнять несколько команд, для этого они должны иметь несколько центральных процессоров, либо центральный процессор такого компьютера строится по так называемой конвейерной (pipeline) архитектуре. Рассмотрим схему работы таких конвейерных ЭВМ.
Выполнение каждой команды любым центральным процессором можно разбить на несколько шагов. Можно выделить следующие основные шаги выполнения команды.
- Выбор команды из оперативной памяти (или кэша) на регистр команд.
- Определение кода операции (так называемое декодирование команды).
- Вычисление исполнительных адресов операндов.
- Выбор операндов из оперативной памяти (или кэша) на регистры арифметико-логического устройства.
- Выполнение требуемой операции (сложение, умножение, сдвиг и т.д.) над операндами на регистрах арифметико-логического устройства.
- Запись результата операции и выработка флагов.
В конвейерных ЭВМ центральный процессор состоит из нескольких блоков, каждый из которых выполняет один из перечисленных выше шагов команды. Теперь понятно, что эти блоки можно заставить работать параллельно, обеспечивая, таким образом, одновременное выполнение центральным процессором нескольких последовательных команд программы. На рис. 15.1 приведена схема работы центрального процессора конвейерной ЭВМ, направление движения команд на конвейере показано толстой стрелкой. Одновременно на нашем конвейере находится шесть команд.
И
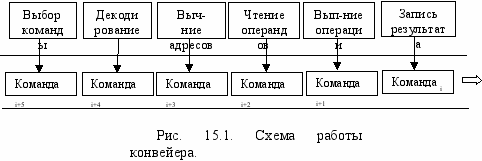
з показанной схемы понятно, почему такие ЭВМ называются конвейерными. Как, например, на конвейере автомобильного завода одновременно находятся несколько машин в разной стадии сборки, так и на конвейере центрального процессора находятся несколько команд в разной стадии выполнения. Отметим хорошее свойство любого конвейера: хотя выполнение каждой команды, как в нашем примере, занимает шесть шагов, однако на каждом шаге с конвейера "сходит" полностью выполненная команда. Таким образом, использование такого рода конвейера позволяет, в принципе, в шесть раз повысить скорость выполнения программы.
Вот теперь мы достигли соответствия скорости работы центрального процессора и памяти. Действительно, предположим для простоты, что каждое из шести устройств на конвейере выполняет свой этап обработки команды за 1 нс, тогда каждая команда выполняется за 6 нс и за это время она успевает произвести все необходимые обмены командами и данными с памятью. В то же время, как мы уже отмечали, скорость выполнения потока команд центральным процессором получается в 6 раз больше за счёт работы конвейера.
Разумеется, не всё обстоит так хорошо, как кажется с первого взгляда. Первая неприятность поджидает нас, если одна из следующих команд использует результат работы предыдущей команды, а это случается очень часто по самой сути вычислительных алгоритмов. Например, пусть есть фрагмент программы:
add al,[bx]
sub X,al
inc bx
inc di
Для второй команды этого фрагмента нельзя выполнять операцию вычитания, пока первая команда фрагмента не запишет в al свой результат, т.е. не сойдёт с конвейера. Таким образом, вторая команды будет задержана на третьей позиции конвейера (на четвёртой позиции уже надо читать операнд al, а от ещё не готов). Вместе со второй командой из нашего примера остановится и выполнение следующих за ней команд и на конвейере образуются два "пустых места". Ясно, что скорость выполнения всей программы может при этом сильно упасть. Зная такую особенность работы конвейера центрального процессора "умный" компилятор может изменить порядок команд в машинной программе, получив, например, такой эквивалентный фрагмент: 1
add al,[bx]
inc bx
inc di
sub X,al
Здесь, как легко увидеть, конвейер уже не быдет пустовать. Другая неприятность случается, когда на конвейер поступает команда условного перехода. Будет ли после выполнения этой команды производится переход, или же продолжится последовательное выполнение команд, выяснится только тогда, когда команда условного перехода сойдёт с конвейера. Так спрашивается, из какой же ветви программы выбирать на конвейер следующую команду?
Обычно при конструировании конвейера принимается какое-либо одно из двух решений. Во-первых, можно выбирать команды из наиболее вероятной ветви условного оператора (например, очевидно, что для команды цикла loop повторение тела цикла значительно более вероятно, чем выход из цикла). Во-вторых, можно поочерёдно выбирать на конвейер команды из обеих ветвей (разумеется, в этом случае половина команд будет выполняться зря и их "недоделанными" придётся выбросить с конвейера).
Далее, как мы уже отмечали ранее, конвейер весьма болезненно реагирует на прерывания, так как при этом производится автоматическое переключение на другую программу и конвейер приходится ощищать от частично выполненных команд предыдущей программы.2
На этом мы закончим наше краткое знакомство с архитектурными особенностями современных ЭВМ и перейдём к сравнению между собой ЭВМ разных классов.