
Работа с базами данных
| Вид материала | Документы |
- Проектирование базы данных, 642.58kb.
- «Прикладная информатика (по областям)», 1362.72kb.
- Программа дисциплины Системы управления базами данных Семестры, 22.73kb.
- Системы управления базами данных, 313.7kb.
- Администрирование системы управления базами данных Sybase Adaptive Server Anywhere, 89.38kb.
- Тема Базы данных. Системы управления базами даннях (12 часов), 116.1kb.
- Развитие объектно-ориентированных систем управления базами данных, 122.52kb.
- Урок №10. Тема: Работа с базами данных в Excel, 119.05kb.
- Системы управления базами данных (субд). Назначение и основные функции, 30.4kb.
- Базовая учебная программа дисциплины «системы управления базами данных» для студентов, 80.99kb.
Глава 17 Автоматизация обработки
документов
Компьютер предназначен для работы с документами, имеющими электронную форму. В то же время, нам часто приходится иметь дело с бумажными изданиями и документами: журналами, книгами, письмами, служебными записками и т. д. Чтобы в работе с информацией такого рода тоже можно было использовать компьютер, необходимы средства преобразования бумажных документов в электронную форму.
Если предполагается, что документ содержит в основном текстовую информацию, то можно выделить следующие основные этапы такого преобразования:
- в ходе сканирования при помощи устройств оцифровки изображения производится создание электронного образа (изображения) документа;
- процесс распознавания позволяет преобразовать электронное изображение в текстовые данные (с сохранением элементов форматирования оригинала или без них);
- для документов, исполненных на иностранном языке применяют дополнительные средства автоматизированного перевода на другой язык.
17.1. Преобразование документов
в электронную форму
Сканирование документов
Процесс создания электронного изображения бумажного документа напоминает его фотографирование и требует применения соответствующего устройства. Сегодня в качестве такого устройства выступает сканер. Такие устройства, как цифровые камеры, пока не могут обеспечить для документов стандартного формата качество изображения, которое гарантировало бы их надежное распознавание.
Основной рабочий элемент сканера включает источник света, используемый для освещения документа, и светочувствительную головку, воспринимающую отраженный свет. Универсальные сканеры, в отношении которых нет специальных требований по функциональным возможностям, качеству и скорости сканирования делятся на три основные категории.
Ручной сканер протягивается над поверхностью документа вручную. Он обеспечивает минимальное качество сканирования, в частности, непригоден для сканирования документов, содержащих иллюстрации.
Листовой сканер способен сканировать отдельные страницы, протягивая их мимо светочувствительного элемента Его недостатком является невозможность сканирования книг и журналов без разборки на отдельные страницы.
В планшетном сканере подвижный светочувствительный элемент перемещается в ходе сканирования внутри корпуса устройства. Сканируемый документ располагается напротив прозрачного окна в корпусе прибора. Этот вид сканера лишен недостатков, присущих типам, рассмотренным выше.

Сканер является внешним устройством и подключается к компьютеру через специальный разъем. При высоком разрешении и большой площади сканируемого документа объем передаваемых данных оказывается очень большим и требует производительной линии передачи. Малопроизводительные сканеры используют порт принтера. Наиболее быстрые устройства подключаются через интерфейс SCSI (Small Computer System Interface).
Разные модели сканеров понимают разные управляющие команды. Чтобы избежать разнобоя, был принят универсальный стандарт взаимодействия сканера и приложений. Этот стандарт называется TWAIN. Приложение посылает команды драйверу TWAIN, который преобразует их в инструкции, распознаваемые сканером. Таким образом, для приложения перестает иметь значение конкретная модель сканера. Операционная система Windows 98 поддерживает интерфейс TWAIN, а все современные сканеры совместимы с ним и предоставляют необходимые драйверы нижнего уровня.
Сканирование через посредство интерфейса TWAIN осуществляется следующим образом. Сначала следует включить сканер. Команда сканирования располагается в приложении в меню Файл (например, в программе Imaging соответствующий пункт так и называется — Сканировать). После выбора этой команды открывается диалоговое окно драйвера TWAIN, вид которого зависит от модели сканера (рис. 17.1). В этом окне задают параметры сканирования: черно-белый или цветной режим, разрешение, коррекция яркости и контрастности. Большинство сканеров позволяют также произвести предварительное черновое сканирование с низким разрешением и по его результатам точно задать область сканирования — часть страницы документа.
После настройки всех параметров следует щелкнуть на кнопке Сканировать (надпись на кнопке может быть иной). Процесс сканирования происходит автоматически, и изображение передается в приложение. Диалоговое окно драйвера TWAIN автоматически не закрывается, так что, например, в многооконных графических редакторах (таких как Adobe PhotoShop) можно сразу провести сканирование нескольких изображений.
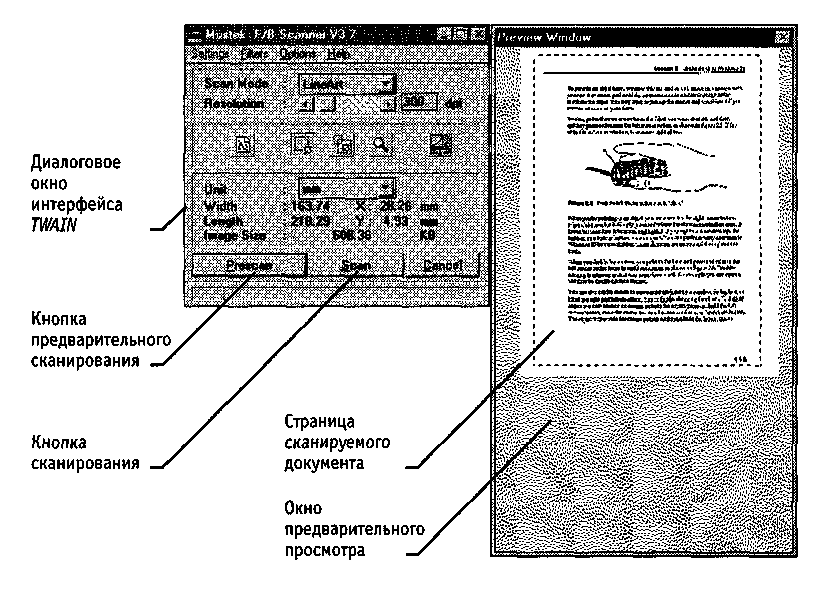
Рис. 17.1. Диалоговое окно интерфейса TWAIN может выглядеть
по-разному — его вид определяется драйвером сканера
Распознавание документов
Этап, распознавания документа состоит в преобразовании электронного изображения (фактически набора цветных или черно-белых точек) в текстовый документ. Ранее для описания этого процесса обычно использовался термин OCR (Optical Character Recognition), который соответствует одному из используемых методов. При таком подходе происходит «сравнение» элемента изображения с эталонными вариантами начертания символов, после чего выбирается наиболее подходящий символ. Этот подход требует использования специального комплекта шрифтов, но дает на нем наилучшие результаты. Современные алгоритмы распознавания не привязаны к конкретному начертанию символов, так же, как человек способен узнавать буквы при любых начертаниях (и даже при значительных искажениях).
В ходе распознавания сначала в изображении выделяются крупные элементы текста: колонки, абзацы, отдельные текстовые блоки (например, подрисуночные подписи), ячейки таблиц. Этот этап называют сегментацией, он может выполняться автоматически или вручную. После этого выполняется автоматический этап распознавания: блоки разбиваются на строки, строки — на отдельные символы, каждый из которых распознается независимо и помещается в итоговый текстовый документ.
Работа с программой Fine Reader
Все операции, необходимые в ходе преобразования бумажного документа в электронную форму, могут быть выполнены с помощью программы Fine Reader (рис. 17.2). Эта программа способна выполнять сканирование и распознавание текстов на разных языках, в том числе и смешанных двуязычных текстов. С ее помощью можно выполнять пакетную обработку многостраничных документов, а также настраивать режим распознавания для улучшения соответствия электронного документа бумажному оригиналу при плохом качестве последнего или использовании в нем шрифтов, далеких от стандартных.
Основные операции обработки бумажного документа в программе Fine Reader выполняются с помощью панели инструментов Scan&Read. С точки зрения этой программы, процесс обработки документа состоит из пяти этапов:
• сканирование документа (кнопка Сканировать);
• сегментация документа (кнопка Сегментировать);
• распознавание документа (кнопка Распознать);
• редактирование и проверка результата (кнопка Проверить);
• сохранение документа (кнопка Сохранить).
Сканирование документа. На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать на панели инструментов Scan&Read. В программе FineReader сканирование может производиться как через драйвер TWAIN, так и в обход его. Первый способ используют, когда требуется точная настройка параметров сканирования, когда документ включает цветные иллюстрации, которые необходимо сохранить, а также когда разные страницы многостраничного документа сильно различаются по качеству. Второй вариант обеспечивает максимальную скорость и удобство сканирования. Выбор используемого варианта осуществляется при помощи флажка Показывать диалог TWAIN-драйвера сканера (Сервис > Опции > Сканирование).
Процесс сканирования осуществляется автоматически и требует от пользователя только вспомогательных операций, таких, как смена сканируемой страницы. Возможность вмешательства в работу программы заблокирована размещением на экране специального диалогового окна, уведомляющего о том, что идет сканирование, и позволяющего прервать это процесс.
По завершении сканирования значки всех обработанных страниц отображаются в окне Пакет. В основной части рабочей области появляется окно Изображение, содержащее изображение текущей страницы. Добавлять страницы в пакет можно не только путем сканирования, но и путем открытия файлов с изображениями, имеющихся на компьютере.
Сегментация документа. Второй этап работы — сегментация, разбиение страницы на блоки текста. Естественный порядок распознавания — по строкам, расположенным на странице сверху вниз и идущим от левого края до правого. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции.
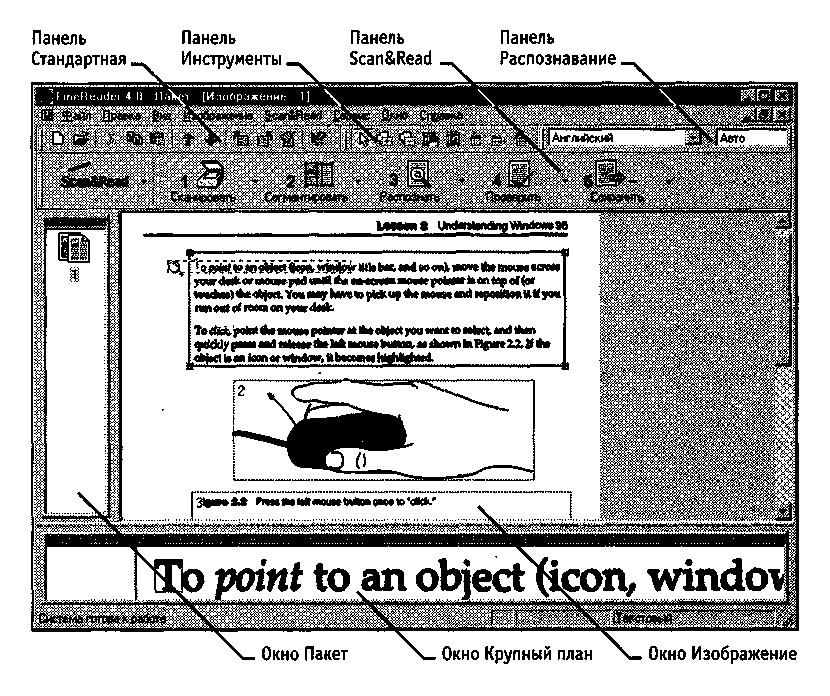
Рис. 17.2. Рабочее окно программы FineReader в процессе
распознавания отсканированного документа
Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке. Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать на панели инструментов Scan&Read) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
Если структура страницы очень сложная, удобнее использовать ручную сегментацию или ручное редактирование результатов автоматической сегментации. Блоки отображаются в виде цветных прямоугольников с номером в левом верхнем углу. Новый блок создают протягиванием мыши по диагонали прямоугольника. Текущий блок помечается выделенной линией, а его углы — прямоугольными маркерами. С помощью этих маркеров можно изменить размер или положение блока.
Команды редактирования блоков выведены на панель Инструменты. Они позволяют:
- объединить два блока в один (Добавить часть блока);
- удалить фрагмент блока (Удалить часть блока);
- изменить положение блоков (Переместить блоки);
- изменить порядок нумерации блоков (Перенумеровать блоки);
- изменить разбиение таблицы на ячейки (Добавить вертикаль, Добавить горизонталь, Удалить линии);
Разные типы блоков обрабатываются программой по-разному. Чтобы изменить тип блока, надо щелкнуть правой кнопкой мыши в его пределах и назначить новый тип с помощью меню Тип блока в контекстном меню. Программа Fine Reader поддерживает следующие типы блоков:
- текстовый (Текст) — на этапе распознавания преобразуется в текст;
- табличный (Таблица) — представляет собой набор ячеек, каждая из которых преобразуется в текст по отдельности;
- изображение (Картинка) — включается в документ без изменений как графическая иллюстрация, если формат сохранения преобразованного документа допускает вставные объекты;
- лишний (Нераспознаваемый) — игнорируется;
- содержащий штрих-код (Штрих-код) — распознается как штрих-код.
Распознавание текста. Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован. В ходе процесса отображается диалоговое окно Распознавание, позволяющее прервать процесс. Кроме того, в этом окне отображаются сообщения, указывающие на наличие проблем при распознавании. Проблемы обычно вызываются неверными настройками или плохим качеством распознаваемого изображения. Если же дело в каких-то шрифтовых особенностях распознаваемого документа, применяют распознавание с обучением.
Распознавание с обучением. Распознавание с обучением состоит в формировании эталона, который используется в ходе распознавания в дальнейшем. Эталон настраивается так, чтобы соответствовать определенному документу или группе однотипных документов. Чтобы создать эталон, используют команду Сервис > Редактор эталонов > Новый эталон. После этого надо указать имя эталона и щелкнуть на кнопке ОК. Режим распознавания с обучением включается при настройке параметров работы программы (Сервис > Опции > Распознавание). На панели Обучение следует выбрать нужный эталон и установить флажок Распознавание с обучением.
Когда в ходе распознавания с обучением программа FineReader обнаруживает символ, который не может интерпретировать однозначно, на экран выдается диалоговое окно Ручное обучение эталона (рис. 17.3). Программа указывает элемент изображения, вызвавший сомнения, и показывает, как именно он будет интерпретирован. Если допущена ошибка, можно указать нужный символ в поле Символ или уточнить область распознавания с помощью кнопок Сдвинуть влево и Сдвинуть вправо.
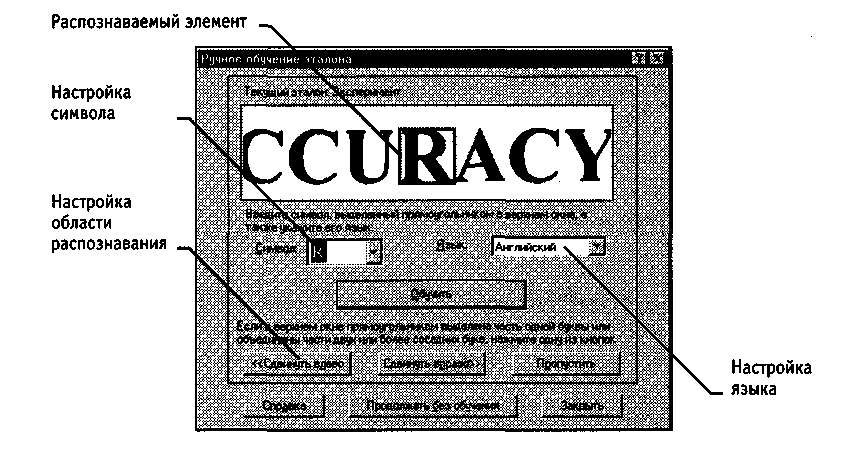
Рис. 17.3. Ручное «обучение» механизма распознавания текста
Затем надо щелкнуть на кнопке Обучить. Необходимые сведения сохраняются и используются при дальнейшем анализе изображения. Если число ошибок невелико, можно продолжить распознавание в обычном режиме щелчком на кнопке Продолжать без обучения.
Редактирование документа. Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad (панель для форматирования открывается при помощи команды Вид > Панели инструментов > Форматирование). Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить на панели инструментов Scan&Read.
Сохранение документа. По щелчку на кнопке Сохранить на панели инструментов Scan&Read запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки.
Обработка бланков
Бланки, или формы, представляют собой особый род документов. Они используются как анкеты, бюллетени для голосования, опросные листы и состоят из постоянной части, содержащей информацию, используемую в ходе заполнения бланка, и переменной части, куда при заполнении бланка заносятся данные. В ходе обработки бланков требуется получить внесенные в него данные и представить их в виде, удобном для дальнейшей обработки. При этом часто приходится иметь дело с тысячами однотипных бланков.
Для обработки бланков используется автономное приложение FineReader Forms. Процесс работы с бланками несколько отличается от работы с обычными документами. Вначале подготавливается шаблон, который содержит все постоянные и переменные зоны бланка. Этап сегментации заменяется наложением шаблона, то есть его совмещением с постоянными элементами бланка. Это позволяет определить местонахождение переменных элементов бланка и провести их распознавание. Данные, полученные с отдельного бланка, рассматриваются как строка таблицы или как отдельная запись базы данных. Содержимое отдельного поля бланка соответствует ячейке таблицы.
Для создания шаблона требуется электронное изображение отдельного бланка, хотя бы и незаполненного. Чтобы создать шаблон, надо в приложении FineReader Forms дать команду Файл > Новый, после чего указать имя пакета форм и папку для хранения отсканированных бланков. Затем необходимо отсканировать или выбрать готовое изображение, которое будет использоваться в качестве основы шаблона.
Сам процесс создания шаблона состоит в ручной сегментации бланка. При этом кроме окна Редактор шаблонов открыто также диалоговое окно Параметры. Следует определить как блоки, охватывающие фиксированные элементы бланка, так и те, которые содержат области, подлежащие заполнению. Блоки, соответствующие постоянным элементам, используются как приводные метки. Чтобы исключить такой блок из процесса распознавания, следует щелкнуть на нем правой кнопкой мыши и выбрать в контекстном меню команду Тип блока > Статический текст.
Параметры блока задают на вкладке Блок диалогового окна Параметры. Для каждого распознаваемого блока надо установить флажок Экспортируемый блок, а также указать имя поля базы данных. Информация из этого блока будет заноситься в указанное поле. После того как все нужные блоки созданы и настроены, следует щелкнуть на кнопке Закрыть на панели инструментов. При этом производится проверка, обеспечивают ли заданные блоки возможность однозначного наложения шаблона на бланк.
В результате сканирования заполненного бланка, наложения шаблона и распознавания, полученные данные представляются в виде формы, содержащей названия полей и данные, полученные при распознавании. Сохранение данных производят в формате, ориентированном на последующую обработку средствами электронных таблиц или баз данных, например, в виде электронной таблицы Excel (файл .XLS).
Практическое занятие
Упражнение 17.1. Сканирование документа
- Включите сканер.
- Запустите программу Imaging (Пуск > Программы > Стандартные > Imaging).
- Откройте крышку сканера, положите документ на окно сканера текстом вниз, закройте крышку.
- Дайте команду Файл > Сканировать.
- Средствами открывшегося диалогового окна драйвера ТТВД/ЛГ проведите предварительное сканирование документа.
- Средствами диалогового окна драйвера ТТОД/ЛГ выделите на документе область, подлежащую сканированию.
- Средствами диалогового окна драйвера TWAIN задайте черно-белый режим и разрешение сканирования.
- Средствами диалогового окна драйвера TWAIN проведите сканирование.
- Закройте диалоговое окно драйвера TWAIN.
- Ознакомьтесь с тем, как выглядит отсканированный документ. Увеличьте масштаб изображения, чтобы оценить качество воспроизведения отдельных символов.
- Сохраните отсканированный документ в формате TIFF для использования в следующем упражнении.
У
пражнение 17.2. Преобразование изображения в текстовый документ
- Включите сканер.
- Запустите программу FineReader (Пуск > Программы > ABBYY FineReader > Fine Reader 4.0 Professional).
- Откройте крышку сканера, положите документ на окно сканера текстом вниз, закройте крышку сканера.
- Щелкните на кнопке Сканировать на панели инструментов Scan&Read.
- Дождитесь окончания сканирования. Обратите внимание на появление значка отсканированного документа на панели Пакет и окна Изображение.
- Щелкните на кнопке Сегментировать на панели инструментов Scan&Read. Изучите результат автоматической сегментации.
- Щелкните на кнопке Распознать. Ознакомьтесь с распознанным текстом в окне Текст.
- Сохраните распознанный текст в виде текстового файла.
- Откройте текстовый файл в программе Блокнот и еще раз убедитесь в правильности распознавания. Закройте программу Блокнот.
- Дайте команду Файл > Открыть и выберите изображение, созданное в предыдущем упражнении.
- Выберите это изображение в окне Пакет и проведите его распознавание в соответствии с пп. 6-8 данного упражнения.
- Сравните результаты распознавания при сканировании через TWAflV-драйвер и в обход его. Сравните трудоемкость этих операций.
У
пражнение 17.3. Ручная сегментация изображения1. Включите сканер.
15 мин
- Запустите программу Fine Reader (Пуск > Программы > ABBYY Fine Reader >Fine Reader 4.0 Professional).
- Откройте крышку сканера, положите документ на окно сканера текстом вниз, закройте крышку.
- Щелкните на кнопке Сканировать на панели инструментов Scan&Read и дождитесь окончания сканирования.
- Щелкните на кнопке Сегментировать на панели инструментов Scan&Read.
- Щелкните на кнопке Распознать на панели инструментов Scan&Read. Ознакомьтесь с тем, как проведено упорядочение распознанного текста в соответствии с автоматической сегментацией. Оцените пригодность полученного документа.
- Закройте окно Текст. Полученный документ предварительно сохраните для сравнения.
- Щелкните в окне Изображение правой кнопкой мыши и выберите в контекстном меню команду Удалить все блоки.
- Сформируйте блоки вручную, выделяя отдельные элементы документа.
- Чтобы блоки, содержащие иллюстрации, не распознавались как текст, щелкните на каждом из них правой кнопкой мыши и выберите в контекстном меню команду Тип блока > Картинка.
- Щелкните на кнопке Перенумеровать блоки на панели Инструменты. Задайте последовательность блоков, щелкая на них в том порядке, в каком их содержимое должно включаться в окончательный документ.
- Щелкните на кнопке Распознать на панели инструментов Scan&Read. Сохраните полученный документ.
- Сравните документы, полученные в результате автоматической и ручной сегментации.
У
 пражнение 17.4. Создание шаблона
пражнение 17.4. Создание шаблонадля распознавания бланков
-
- Включите сканер.
- Запустите программу FineReader Forms (Пуск > Программы > ABBYY FineReader > Fine Reader 4.0 Forms).
- Откройте крышку сканера, положите бланк на окно сканера текстом вниз, закройте крышку.
- Дайте команду Файл > Новый.
- Задайте имя пакета и место его размещения, после чего щелкните на кнопке Далее.
- Установите переключатель Создать новый и щелкните на кнопке Далее.
- Введите имя шаблона и щелкните на кнопке Далее.
- Установите переключатель Отсканировать и щелкните на кнопке Далее. Дождитесь окончания сканирования. Щелкните на кнопке Готово.
- Создайте блоки, охватывающие постоянные поля («разметку») бланка. Для каждого такого блока на вкладке Блок диалогового окна параметры задайте тип Статический.
- Создайте блоки, охватывающие переменные (заполняемые) поля бланка. Для каждого такого поля установите флажок Экспортируемый блок и задайте имя поля базы данных (Поле БД).
- Завершив разметку бланка, щелкните на кнопке Закрыть на панели инструментов.
- После закрытия редактора шаблонов снова отсканируйте тот же бланк, но уже для распознавания (кнопка Сканировать на панели инструментов Open&Read).
- Щелкните на кнопке Наложить шаблон на панели инструментов Open&Read.
- Щелкните на кнопке Распознать на панели инструментов Open&Read.
- Ознакомьтесь с заполненной формой, полученной в результате распознавания. Сохраните документ в виде таблицы Excel.
17.2. Автоматизированный перевод документов
К средствам автоматизации перевода можно отнести два вида программ: электронные словари и программы перевода. Электронные словари представляют собой средства для перевода отдельных слов, отображаемых на экране или имеющихся в документе. Удобство их использования состоит в возможности немедленно получить перевод неизвестного слова без поиска его в отдельном толстом томе. Программы перевода получают на входе текст, выполненный на одном языке, и выдают текст на другом языке, то есть автоматизируют перевод текста.
Электронные словари удобны для профессиональных переводчиков, которые выполняют большую часть работы по переводу вручную. Их также могут использовать лица, в целом знающие иностранный язык, если надо не обеспечить перевод документа, а просто ознакомиться с его содержанием.
Надежный и качественный автоматический перевод документов с одного языка на другой (мы будем говорить в основном о переводе с английского на русский) пока остается недостижимым идеалом. Причин для этого множество, и главная из них состоит в том, что перевод текста не сводится к переводу отдельных лексических единиц. Преодолеть этот барьер современные программы автоматического перевода пока не могут.
Тем не менее, современные средства автоматизации перевода достигли того уровня, который позволяет эффективно использовать их на практике. Дело в том, что технический текст, в отличие от художественного, использует ограниченное число языковых конструкций и более ориентирован на однозначную интерпретацию. Среди используемых лексических единиц встречается большое число технических терминов, имеющих совершенно определенный смысл в рамках данной научной или технической дисциплины. Это значительно упрощает процесс перевода и позволяет в отдельных случаях автоматически получать текст, близкий к результату ручного подстрочного перевода.
Программы автоматического перевода имеет смысл использовать для перевода технических текстов в следующих случаях:
- при абсолютном незнании иностранного языка;
- при необходимости получить перевод быстро, даже ценой снижения его качества (например, это относится к переводу Web-документов);
- для перевода на иностранный язык (умения читать иноязычные тексты недоста точно, чтобы научиться объясняться на иностранном языке);
- для быстрого создания первоначального черновика («подстрочника»), используемого в ходе подготовки полноценного перевода.
Работа с программой Promt 98
Для автоматизированного перевода технических текстов можно, например, использовать программу Promt 98. Она позволяет переводить документы с английского языка на русский и с русского на английский. Чтобы обеспечить правильный перевод терминов, относящихся к определенной научной дисциплине, используют специализированные словари, в которых для слов, используемых как термины, предлагается в качестве перевода не «обиходное», а специальное значение.
Если программа Promt 98 установлена на компьютере, для ее запуска можно использовать Главное меню (Пуск > Программы > Главное меню > PROMT 98 > PROMT 98), значок PROMT 98 на Рабочем столе или значок программы на панели индикации (команда PROMT 98 в контекстном меню этого значка).
Одновременно для обработки может быть открыто несколько документов. Окна документов имеют необычный вид (рис. 17.4). Они разбиваются на три отдельные области: две из них предназначены для отображения оригинала текста и сформированного перевода, а третья представляет собой информационную панель, предназначенную для вывода информации о переводимом документе и специальных настройках.
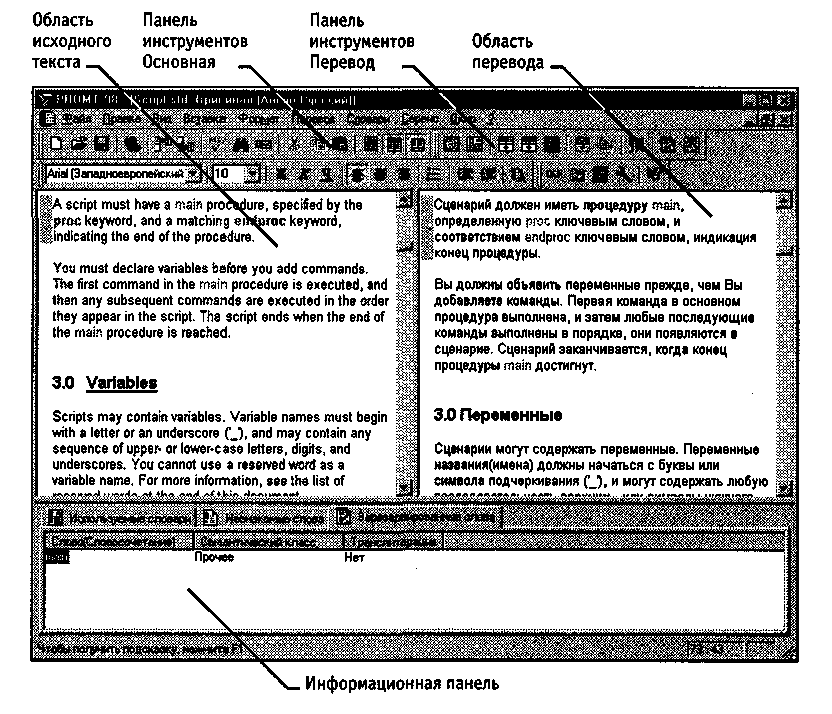
Рис. 17.4. Рабочее окно системы автоматизированного перевода Promt 98
Чтобы произвести перевод имеющегося документа с использованием заданных по умолчанию настроек, применяют следующий порядок действий.
- Сначала необходимо открыть документ на языке оригинала (кнопка Открыть на панели инструментов Основная). Нужный документ выбирают в диалоговом окне Выберите документ. Формат открываемого файла выбирают в раскрывающемся списке Тип файлов.
- После выбора файла появляется диалоговое окно Конвертировать файл. В нем можно уточнить реальный формат документа, хранящегося в файле, если он не соответствует типу файла или когда тип файла может соответствовать нескольким разным форматам документа.
- Документ загружается и отображается в области исходного текста. При вертикальном разбиении окна документа эта область располагается слева. Если
предполагается длительная работа над переводом текста, его сохраняют как
документ программы Promt 98 (файл с расширением .STD).
- Определение языков оригинала и перевода рассматривается как направление перевода. Чтобы выбрать направление перевода, используют кнопку Изменить направление на панели инструментов Перевод.
- Чтобы перевести весь текст целиком, используют кнопку Весь текст на панели инструментов Перевод. В ходе выполнения перевода на экране отображается диалоговое окно Перевод текста с индикатором хода работы. Перевод текста помещается (при вертикальном разбиении окна) в правую область. Для удобства последующего редактирования перевод снабжается цветовой разметкой: неизвестные программе слова выделяются красным цветом, а зарезервированные слова, которые не надо переводить, — зеленым.
Текст, помещенный в областях окна программы Promt 98, можно редактировать (и оригинал, и перевод). Чтобы заново перевести отредактированный абзац, используют кнопку Текущий абзац на панели инструментов Перевод. Текущий абзац — это абзац, в котором располагается текстовый курсор. Он выделяется голубой полосой вдоль левого края.
6. После того как работа с документом в программе Promt 98 завершена, его сохраняют в одном из общепринятых форматов. Для сохранения только оригинала (возможно, отредактированного) служит команда Файл > Сохранить > Исходный текст. Чтобы сохранить переведенный текст, применяют команду Файл > Сохранить > Перевод. В обоих случаях можно сохранять как содержимое документа, так и его элементы форматирования, сохраняющие, по возможности, оформление оригинала.
Чтобы продолжить работу с текстом позднее, удобнее сохранить его двуязычный вариант, так называемую билингву (Файл > Сохранить > Билингву). Информация сохраняется в виде неформатированного текста, причем абзацы оригинала и перевода чередуются.
Контроль качества перевода
Качество перевода определяется полнотой используемых словарей и учетом грамматических правил. При переводе можно как применять стандартные ресурсы программы, так и добавлять собственные.
Работа со словарями. Правила перевода отдельных слов (терминов) определяются использованием словарей. Для каждого переводимого документа задается набор применяемых словарей. Словари просматриваются в определенном порядке, и, как только переводимое слово обнаружено в каком-то из словарей, дальнейший просмотр прекращается. Программа Promt 98 использует при переводе три типа словарей.
- Генеральный словарь содержит общеупотребительную лексику и бытовые значения слов. Он используется всегда и притом самым последним, если слово не найдено ни в одном из других словарей. Изменение этого словаря невозможно.
- Специализированные словари содержат термины из различных областей знаний, причем значение переводимого термина выбирается в соответствии со специализацией словаря. Одни и те же слова могут иметь совершенно разный смысл в разных технических дисциплинах, так что выбор нужного словаря обеспечивает правильное использование специальной терминологии в переводе. Редактирование специализированных словарей не допускается, но их можно подключать или отключать при переводе документа.
- Пользовательский словарь формируется пользователем вручную. В него можно включить слова, отсутствующие в других словарях, или представить более точный перевод каких-то из терминов. Пользовательские словари можно произвольно создавать и редактировать. Применяют пользовательские словари обычно в первую очередь, до специализированных и генерального.
Узнать, какие словари используются при переводе, можно на вкладке Используемые словари на информационной панели. Порядок перечисленных словарей соответствует порядку их использования. Генеральный словарь в этом списке не указывается. Чтобы задать иной набор словарей или изменить их порядок, следует щелкнуть на соответствующей вкладке информационной панели правой кнопкой мыши и выбрать в контекстном меню пункт Изменить список словарей.
Настройка производится в диалоговом окне Словари. Чтобы отключить словарь, надо выбрать его в списке и щелкнуть на кнопке Отключить. Добавление словарей производится с помощью кнопки Подключить. Для создания нового пользовательского словаря служит кнопка Создать. Чтобы изменить порядок просмотра словарей, надо выбрать перемещаемый словарь и использовать для его передвижения по списку кнопки Вверх и Вниз.
Транслитерация и резервирование. Не все слова требуют перевода. Обычно без изменений оставляют имена собственные. Иногда при этом используют транслитерацию — запись, использующую другой алфавит, но соответствующую написанию или произношению слова на исходном языке. В частности, транслитерация повсеместно используется при передаче иностранных имен и фамилий. Транслитерация не считается переводом.
Иногда необходимо отказаться от перевода целых абзацев. Например, нелепый результат даст попытка перевода исходных текстов программ. То же самое можно сказать и обо всех других случаях, где используются не значения слов, а сами слова как ключевые.
Чтобы зарезервировать слово, его надо выделить и щелкнуть на кнопке Зарезервировать слово на панели инструментов Перевод. В открывшемся диалоговом окне Зарезервировать слово можно уточнить написание, указать смысловую категорию, к которой относится данный термин, а также установить флажок Транслитерировать, если нужна транслитерация. Все зарезервированные слова заносятся в список на вкладке Зарезервированные слова на информационной панели, а в самом документе выделяются зеленым цветом.
Чтобы указать на то, что абзац не требует перевода, надо установить текстовый курсор внутрь данного абзаца и щелкнуть на кнопке Оставить абзац без перевода на панели инструментов Перевод. Зарезервированный абзац также отображается зеленым цветом. Если резервирование слов или абзацев произведено после выполнения перевода, то для того, чтобы данные настройки вступили в силу, надо произвести перевод соответствующих абзацев заново.
Если приходится работать с тематически связанными документами или документом, разбитым на несколько отдельных файлов, следует использовать общий список зарезервированных слов. Чтобы сохранить список зарезервированных слов в отдельном файле, следует щелкнуть на вкладке Зарезервированные слова информационной панели правой кнопкой мыши и выбрать в контекстном меню пункт Сохранить список. Для загрузки такого автономного списка в документ используется команда Загрузить список из этого же контекстного меню.
Пополнение словаря. При автоматическом переводе реальных документов часто приходится сталкиваться со словами, которые программа перевода не смогла найти ни в одном из допустимых словарей. Эти слова заносятся в список на вкладке Незнакомые слова на информационной панели и выделяются в тексте документа красным цветом.
Слова могут быть неопознаны по разным причинам. В число их могут входить:
- опечатки в оригинале документа;
- для документов, преобразованных в электронную форму, ошибки распознавания;
- собственные имена, требующие резервирования;
- слова, отсутствующие в словарях.
В первых двух случаях необходимо отредактировать исходный текст, в третьем — зарезервировать слово и только в последнем случае необходимо занести слово в пользовательский словарь. При этом кроме собственно значения слова в переводе необходимо задать грамматические правила изменения форм этого слова и его сочетания с другими словами. В самом простом режиме работы (Начинающий) программа автоматически добавляет недостающие формы слова по заданному образцу.
Для того чтобы внести слово в словарь, надо выделить его и щелкнуть на кнопке Словарная статья на панели инструментов Перевод. В диалоговом окне Открыть словарную статью нужно указать начальную форму слова и выбрать словарь, в который будет внесено это слово. После этого откроется диалоговое окно Словарная статья, используемое для добавления слова (рис. 17.5).
Выберите вкладку, соответствующую нужной части речи, установите переключатели, описывающие свойства данного слова, и щелкните на кнопке Добавить. В диалоговом окне Перевод укажите перевод слова, также в начальной форме. Если откроется диалоговое окно Тип словоизменения, надо щелкнуть на имеющейся в нем кнопке (для глаголов она называется Спряжение) и указать, как выглядят запрашиваемые формы слова. В заключение может быть задан вопрос о том, для каких форм исходного слова применим данный перевод и как они выглядят.
Имеющиеся словари можно также просматривать и редактировать. Для этого надо дважды щелкнуть на названии словаря на вкладке Используемые словари на информационной панели. Словарь открывается, и на экран выводится список включенных в него слов. Дважды щелкнув на любом слове, можно отредактировать соответствующую словарную статью. Результаты такого редактирования всегда заносятся только в пользовательский словарь.

Рис. 17.5. Средство наполнения пользовательского словаря
Дополнительные средства перевода
Кроме основного приложения, в состав программы Promt 98 входят дополнительные средства, предназначенные для быстрого автоматического перевода, выполняемого без активного контроля со стороны пользователя.
Так, средство пакетного перевода файлов (Пуск > Программы > PROMT 98 > File Translator) предназначено для автоматического перевода файлов в фоновом режиме. В левой части окна этого приложения располагается список файлов, ожидающих перевода — очередь перевода. Добавить файл в очередь можно при помощи кнопки Добавить на панели инструментов. В правой части окна располагаются элементы управления, позволяющие задать все настройки правил перевода, используемые в основной программе Promt 98. Теряется лишь диалоговый характер работы.
Когда очередь перевода сформирована, следует выбрать пункт Перевод! в строке меню. При наличии свободных ресурсов начнется последовательный перевод файлов, включенных в очередь. По завершении перевода исходный файл покинет очередь. Непосредственно по ходу работы можно добавлять в очередь новые задания, удалять задания, менять порядок их обработки. Самый быстрый способ добавления файла в очередь на перевод состоит в использовании пункта Отправить > File Translator в контекстном меню значка файла. Чтобы включить эту функцию, надо дать в программе File Translator команду Настройки > Параметры > Разное и установить флажок Добавить пункт в меню «Отправить».
Для быстрого перевода неформатированного текста можно использовать приложение QTrans (Пуск > Программы > PROMT 98 > QTrans). Оно не содержит никаких средств открытия или сохранения документов, так как предполагается, что переводимый текст вводится на верхнюю панель окна программы вручную или переносится туда через буфер обмена (рис. 17.6).

Рис. 17.6. Рабочее окно программы QTrans
Чтобы перевести текст (перевод появится на нижней панели), следует щелкнуть на кнопке Перевести. Перевод начинается автоматически при выборе направления перевода с помощью одноименной кнопки или при вставке данных из буфера обмена. Чтобы сохранить полученный перевод, его следует поместить в буфер обмена при помощи кнопки Копировать перевод, после чего произвести вставку в той программе, в которой этот текст будет использован.
Наибольшую ценность функция оперативного перевода представляет для документов Интернета. Сегодня большинство страниц используют английский язык, поэтому шансы найти нужную информацию именно на англоязычной странице максимальны. Для «синхронного» перевода Web-страниц предназначено приложение WebView (Пуск > Программы > PROMT 98 > WebView).
Приложение WebView представляет собой полноценный броузер, эквивалентный по своим возможностям программе Internet Explorer. Отличие от обычных броузеров состоит в том, что окно программы разбито на две части. В верхней части страница отображается в том виде, в каком она получена из Интернета. Одновременно с началом загрузки страницы в нижней части окна начинает формироваться ее перевод. При этом переводу подвергается только текст, входящий в состав страницы, а адреса, на которые указывают гиперссылки, а также иллюстрации и другие вставные объекты отображаются без изменений. Переходы по гиперссылкам можно осуществлять как с верхней, так и с нижней части страницы.
Для поиска нужной информации на англоязычных серверах Интернета используют англоязычные поисковые системы. Приложение WebView позволяет производить поиск в Интернете с использованием ключевых слов, переведенных на английский язык.
Чтобы воспользоваться этой функцией, надо щелкнуть на кнопке Поиск в Web на панели инструментов. Диалоговое окно Поиск в Интернет содержит три вкладки, обеспечивающих три разных способа формирования запроса на поиск. После того как указаны ключевые слова и выбрана поисковая система, сформированный запрос, содержащий уже переведенные ключевые слова, отображается в специальном поле, чтобы можно было визуально проверить его правильность.
После щелчка на кнопке ОК запрос направляется в указанную поисковую систему. Web-страница, сформированная этой системой, как обычно, отображается в верхней области окна программы WebView, а в нижней части отображается ее перевод, точно так же, как и для любой другой Web-страницы.
Практическое занятие
Упражнение 17.5. Автоматический перевод текста
- Запустите программу Promt 98 (Пуск > Программы > PROMT 98 > PROMT 98).
- Дайте команду Файл > Открыть и выберите открываемый документ.
- Выберите используемый формат файла в диалоговом окне Конвертировать файл и щелкните на кнопке ОК.
- Откройте вкладку Используемые словари на информационной панели. Ознакомьтесь со списком используемых словарей. Щелкните на этой вкладке правой кнопкой мыши и выберите в контекстном меню команду Изменить список словарей.
- Отключите все словари, кроме одного специализированного тематического словаря по теме документа (и, возможно, пользовательского).
- Щелкните на кнопке Весь текст на панели инструментов Перевод.
- Ознакомьтесь с переводом текста. Обратите внимание на вид абзацев, которые не следовало переводить.
- Выделите фрагменты, которые не следовало переводить, и щелкните на кнопке Оставить абзац без перевода на панели инструментов Перевод. Обратите внимание на изменения в отображении оригинала и перевода.
- Оцените качество автоматического перевода.
- Сохраните документ во внутреннем формате программы Promt 98 (Файл > Сохранить документ). Закройте документ и откройте его снова, убедившись, что в этом случае можно продолжить работу в точности с того места, на котором она была остановлена.
- Сохраните переведенный текст (Файл > Сохранить > Перевод) в формате, учитывающем форматирование документа (MS Word 6.0/7.0 for Windows). Откройте сохраненный документ с помощью программы WordPad и просмотрите его содержание.
- Сохраните документ в виде билингвы (Файл > Сохранить > Билингву).
13. Откройте сохраненный документ в текстовом редакторе Блокнот. Используя английский и русский варианты текста, попробуйте окончательно сформировать правильный и грамотный перевод исходного документа.
У
пражнение 17.6. Редактирование словаря- Запустите программу Promt 98 (Пуск > Программы > PROMT 98 > PROMT 98).
- Дайте команду Файл > Открыть и выберите открываемый документ.
- Выберите используемый формат файла в диалоговом окне Конвертировать файл и щелкните на кнопке ОК.
- Щелкните на кнопке Весь текст на панели инструментов Перевод.
- Откройте вкладку Незнакомые слова на информационной панели.
- Просмотрите список слов, незнакомых программе. Попробуйте разыскать их в англо-русском словаре, чтобы выяснить, какие из них действительно требуют перевода.
- В списке на вкладке Незнакомые слова на информационной панели дважды щелкните на слове, требующем перевода.
- В диалоговом окне Открыть словарную статью уточните начальную форму слова и щелкните на кнопке ОК.
- В диалоговом окне Словарная статья выберите вкладку, соответствующую части речи, к которой принадлежит добавляемое слово.
- Установите переключатели, описывающие свойства слова, и щелкните на кнопке Добавить.
- В диалоговом окне Перевод введите начальную форму для слова или словосочетания, используемого в качестве перевода, и щелкните на кнопке ОК.
- При появлении запросов, касающихся дополнительных грамматических форм исходного слова или перевода, введите необходимые данные.
- При необходимости внесите в пользовательский словарь и другие слова, требующие перевода, как описано в пунктах 8-12.
- Повторно щелкните на кнопке «Весь текст» на панели инструментов Перевод. Изучите, как изменился перевод в связи с пополнением словаря.